





はじめに
初めまして、東京大学情報理工学系研究科修士課程2年の松永裕太です。8/16~9/9にAIスペシャリストコースの就業型インターンシップに参加しました。 大学では普段、音声合成の研究に取り組んでいます。 本記事では、インターンシップで取り組んだ「AIを用いた音声編集」について紹介します。
本記事の概要
サマーインターンでは、収録された音声データを編集する仕組みの開発に取り組みました。この記事では、音声編集とは何か、これまでにどんな音声編集技術が開発されたか、そして今回どんな音声編集技術を開発したか、について紹介します。また、開発した音声編集技術による編集結果のサンプルや今後の展望などを紹介します。
音声編集とは
音声編集は、与えられた音声の一部の言語情報を編集し、新たな音声を生成する技術です。新たな音声をゼロから生成する音声合成とは異なり、編集しない箇所は収録された音声そのままの音響情報を利用します。これにより、音声合成では再現することが難しいオリジナルの表現を維持したまま、新しく高品質な音声を生成することを可能にします。こうした技術は、IPキャラクターの音声のような表現豊かな音声コンテンツの制作に活かすことができます。そして、近年著しい普及を見せている、YouTubeや映画、オンラインの教育コンテンツなど、様々な音声メディアの制作で活用が期待できます。
さらに具体的な応用場面として、ポストプロダクション編集が挙げられます。ポストプロダクション編集とは、完成したプロダクト(収録済みの音声など)を後から修正することです。音声コンテンツを収録する際に、音声収録後に台本が変更になることがあり、そのような場面では再収録ではなく収録済み音声を編集した方が効率的です。そのためには、収録済み音声を編集できる音声編集技術が必要となります。

これまでの音声編集
これまでに様々な音声編集技術が開発され、利用されてきました。ここではその概要と、それぞれの利点・欠点を紹介します。
従来の技術: 収録済み音声を切り貼りする形式
音声編集を実現する最も簡単な方法として、収録済みの音声を切り貼りすることで音声を編集する方法があります。こうした方法は、従来から音声制作の現場で使用されていましたが、韻律のミスマッチが起きる、編集後の音声が収録データにない場合がある、という課題がありました。
そこで近年では、深層学習を使った音声編集技術が提案されています。
深層学習による音声編集1: CampNet
CampNet [1] は、収録された音声を直接編集する深層学習モデルです。このモデルを使って、単語の挿入や削除、置き換えなどを行うことができます。 しかしこの手法では、次に紹介する EdiTTS のように学習済み音声合成モデルは使用できず、音声編集用の新たなモデルの学習が必要となります。
深層学習による音声編集2: EdiTTS
EdiTTS [2] は、CampNet のように新たにモデルを学習せず、学習済み音声合成モデルを使って音声を編集する技術です。この手法を使って、合成音声のテキスト内容の置き換えや、合成音声のピッチの修正を行うことができます。しかしこの手法では、合成音声のみを編集でき、収録された音声をそのまま編集することはできません。
この手法では合成音声を編集しますが、これは編集後の音声を合成するのと変わらないのではないか、という疑問が生じます。
提案する音声編集の仕組み
概要
今回のインターンでは、収録音声を直接編集可能な音声編集技術の実現に取り組みました。従来の EdiTTS では、音声合成モデルによる合成音声のみ編集でき、収録音声を直接編集できないという課題があります。そこで、収録音声を直接編集できるように EdiTTS を改良しました。
この音声編集システムは、編集前の収録音声と編集後のテキストを入力とし、学習済み音声合成モデルを用いて音声編集を行い、編集後の音声を出力します。以下にその概要を表す図を示します。

このシステムを実現するには何をすれば良いのでしょうか? まず、従来の EdiTTS では、音声合成モデルによる合成音声を編集するため、収録音声の編集に対応させる必要があります。 また、EdiTTS は英語に特化した仕組みであるため、日本語への対応を行う必要があります。 これらの取り組みについて順に紹介します。
EdiTTS を収録音声の直接の編集に対応
EdiTTS の詳細
EdiTTS では、GradTTS [3] という音声合成モデルを使用します。これは、昨今画像生成で話題の Diffusion の仕組みを使用した音声合成モデルです。 Diffusion には、クリーンなデータにノイズを付与する順過程と、ノイジーなデータからノイズを除去する逆過程の、2つの過程があります。GradTTS の推論では、この逆過程を用います。 基本的な音声合成モデルの構造は、テキストから粗い音声の特徴量を推定する Encoder (言語特徴量を推定するモデルを含む) と、粗い音声の特徴量から詳細な音声の特徴量を推定する Decoder から構成されます。GradTTS では、この粗い音声の特徴量から詳細な音声の特徴量を推定する過程を、ノイジーなデータからノイズを除去する Diffusion 逆過程とみなし、高品質な音声を合成します。
次に、EdiTTS の仕組みについて説明します。 まず、GradTTS の Encoder を用いて、編集前テキスト・編集後テキストから、それらに対応する粗い音声の特徴量を推定します。次に、それらの特徴量を結合し、所望の編集後音声の粗い音声特徴量を得ます。そして、GradTTS の Decoder を用いて、粗い音声特徴量をより精緻な音声特徴量(メルスペクトログラム)に変換します。
新技術: 収録音声の直接編集に対応した EdiTTS
前節で説明した EdiTTS の仕組みでは、編集前のテキストから推定された粗い音声の特徴量を使用していました。この部分を、編集前の収録音声を分析して得られた音声の特徴量を使用するように変更すれば、音声の直接の編集が可能になるのではないか、と考えました。
その概要図を以下に示します。この方法ではまず、収録音声から分析された音声特徴量の編集部以外の箇所と、編集後テキストから合成された編集部の音声特徴量を結合し、Decoder に入力します。そして、Decoder は、結合された特徴量における編集部とそれ以外の箇所の接続が自然となるように、音声特徴量を変換します。このプロセスにより、接続の自然な編集後音声が合成されます。
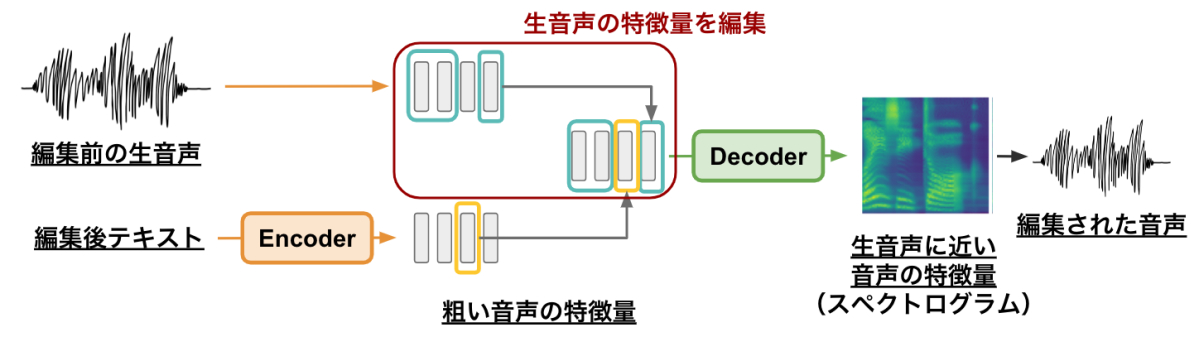
日本語音声データへの対応
音声合成では、テキストを音素列に変換し、音声合成モデルに入力します。また、日本語の音声と英語の音声で使用される音素の種類が異なります。そこで私は、音素の種類と音素分析方法の変更を行いました。 また、EdiTTS で用いられていた音声データと、今回用いる音声データでは、サンプリング周波数がそれぞれ 22.05 kHz, 48 kHz と異なっています。音声合成では、音響モデルによって推定された時間周波数特徴量から音声を合成する部分にボコーダを用いますが、そのボコーダが対応するサンプリング周波数は固定値です。そこで我々は、サンプリング周波数 22.05 kHz に対応したボコーダを 48 kHz に対応したボコーダに変更しました。また、ボコーダには Multi-band MelGAN [4] を使用しました。
音声サンプル
実際に音声編集を行なったサンプルを紹介します。
| 編集前の収録音声 | 提案法による編集後音声 | GradTTSで合成した編集後音声 |
|---|---|---|
「あのイケメンが関東に行っちゃうの?」 |
「あのイケメンが地方に行っちゃうの?」 |
「あのイケメンが地方に行っちゃうの?」 |
「いつもは1000個ですが、1500個お願いします。」 |
「いつもは1000個ですが、3000個お願いします。」 |
「いつもは1000個ですが、3000個お願いします。」 |
「わたしは桜エビが好きだから日替わりにしよっと。」 |
「わたしは辛い物が好きだから日替わりにしよっと。」 |
「わたしは辛い物が好きだから日替わりにしよっと。」 |
まとめと今後の展望
今回のインターンでは、収録音声を直接編集できる音声編集技術を開発しました。合成音声を編集する既存技術 (EdiTTS) を改良することで収録音声を直接編集することを可能にし、編集を簡単に行えるスクリプトの実装や日本語データへの対応に取り組みました。この技術には、元音声の韻律を保持した編集ができ、音声合成が難しい長い文も編集できるという利点があり、様々な音声メディアにおける利用が期待できます。
しかし、今回開発した手法には、表現力の高い音声 (感情的な音声など) では未だに韻律のミスマッチが発生することや、音声合成モデルの問題で編集部分の合成が上手く行っていないことがある、という課題があります。今後、これらの課題を解決した音声編集技術を開発できれば、実用化へとさらに近づくことができるでしょう。
インターンの感想
今回のインターンでは、メンターの方や他のチームメンバーの社員の方に、非常に密にコミュニケーションをとって頂き、細かいアドバイスやフィードバックを頂きながら開発を進めることができました。そのおかげで、作業に行き詰まることなく、最後までインターンを楽しむことができました。また、既存技術の実装とその改良を通して、既存技術やその周辺技術の理解を深められたことも貴重な経験となりました。さらには、DeNA さんの様々な社員の方と接することができ、自由で社員の皆さんが楽しんで働いていらっしゃる雰囲気を直接見て知ることができたので、今回のサマーインターンに参加して良かったです。
参考文献
[1] CampNet: Context-Aware Mask Prediction for End-to-End Text-Based Speech Editing
[2] EdiTTS: Score-based Editing for Controllable Text-to-Speech
[3] Grad-TTS: A Diffusion Probabilistic Model for Text-to-Speech
[4] Multi-band MelGAN: Faster Waveform Generation for High-Quality Text-to-Speech



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。