





はじめに
DeNA の森と申します。これまで、音声感情認識、音声合成、音声変換など音声 x AI の研究開発に従事してきました。現在は、リアルタイム音声変換の開発に注力しています。
本記事では、DeNA で開発している音声変換技術を活用した七声ニーナというサービスからライブ配信応用へ向けた取り組みまでご紹介します。
本記事は DeNA TechCon 2022 で発表した
をベースに執筆したものです。上のリンク先に発表のアーカイブ動画もありますので興味のある方はぜひご覧ください。
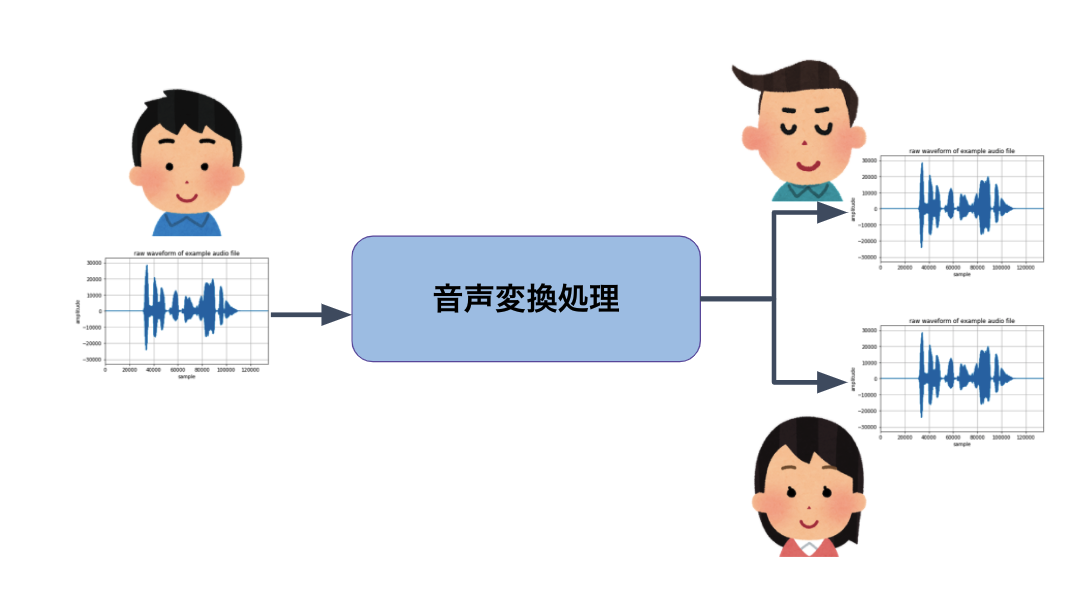
音声変換とは
音声変換(Voice Conversion)とは、発話内容を変えずに、話者性を変える音声 AI 技術です。たとえば、以下のように男性の声を女性の声に変えることができます。

入力音声
変換音声
この例では「こんにちは」という発話内容を変えずに、話者性(声色)だけを男声から女声に変えています。
音声変換のアプリケーション
DeNA では音声変換のアプリケーションとしてゲーム・エンタメ領域での適用を想定して開発を進めています。例えば、自分の声をよりかっこいい・かわいい・好みの声に変えて動画配信をしたり、VTuber のようにアバターキャラクターになりきってライブ配信をしたり、オンラインゲームで特定のキャラクターの声になりきって音声チャットしたりといったさまざまなアプリケーションが考えられます。
最近、流行のメタバースにおいても見た目(アバター)だけではなく、声も変えたいというニーズはいずれ出てくると考えています。

発話内容と声色の分離
ここで声を変えるために具体的に何をすればよいのか踏み込んで考えてみます。

人間の音声は音声波形で表すことができます。この音声波形には何を喋ったかという発話内容、話者特有の声色、声の抑揚を表すイントネーション、感情などがすべて含まれています。音声変換はこのような様々な情報が含まれる音声を、発話内容と声色に分離し、発話内容はそのままで声色のみを別の声色に変えるタスクと定義できます。
このようなごちゃまぜになっている情報のもつれを解きほぐして特定の情報に分離することを disentangle といいます。最近流行の深層学習(Deep Learning)は、この disentangle や convert が効果的にできる手法と考えられており、音声変換の研究においても深層学習が幅広く使われています。
Q. ボイスチェンジャーとは何が違うの?
ボイスチェンジャー(Voice Changer)も音声変換(Voice Conversion)も声色を変える技術という点では共通です。まったく同じ意味で使っているケースもありますが、我々はボイスチェンジャーは音声信号処理(ピッチ&フォルマント変換)に基づくアプローチで、音声変換は音声データと機械学習に基づくアプローチと区別しています。
ボイスチェンジャーは、純粋な音声信号処理のため低遅延で安定性は高いというメリットはありますが、まったく同じパラメータでも利用者の地声によって変換音声の声色が変わってしまうというデメリットがあります。またいい声を作るには裏声を出すなど利用者側の熟練がある程度必要です。
一方、音声変換は、機械学習(最近は深層学習)を使って入力の声色から変換対象の声色への変換規則を音声データから自動学習させるアプローチです。誰の声でも完全に変換対象の声色に変えることも可能です。熟練も不要で誰でも使えるメリットがあります。一方で処理が重く、遅延が大きいというデメリットもあります。
本発表では音声変換、特に深層学習を活用した音声変換について書いています。
Q. 音声認識や音声合成とは何が違うの?
音声変換は、音声認識や音声合成といった音声 AI 技術と密接に関わっています。音声認識は、音声をテキストに変換する技術、音声合成は、その逆でテキストを音声に変換する技術です。

音声変換では、音声から発話内容を取り出す部分が音声認識、発話内容から音声に変換する部分が音声合成と関連があります。さらに言うと音声から話者性を取り出す部分は話者認識と関連しています。このように音声変換はさまざまな音声 AI 技術の総合力が試されるタスクと言えます。
ここで強調しておきたいのが音声認識でテキストを書き起こして、そのテキストをテキスト音声合成(TTS: Text-to-Speech)で合成しているわけではないということです。詳細は省きますが、テキストより細かい単位の音素をさらに抽象化した表現を用いています。
音声変換の処理フロー
音声変換では主に 3 つのモジュールから構成されます。Content Encoder、Speaker Encoder、Decoder です。

Content Encoder は入力音声から発話内容を抽出するモジュールです。Speaker Encoder は誰の声になりたいかという話者性を抽出するモジュールです。特定のキャラクターの声だけに変換したい場合は Speaker Encoder を省略できます。Decoder は発話内容と話者性から変換音声を生成するモジュールです。Content Encoder、Speaker Encoder、Decoder はそれぞれニューラルネットワークで作られており、そのパラメータは深層学習で自動的に学習されます。
音声変換の多くの手法がこの 3 つのモジュールから構成されていますが、細部を見るとさまざまなアプローチが考えられます。
- 学習に書き起こしテキストが必要かそうでないか?
- 音声を波形領域で処理するか、スペクトル領域で処理するか?
- Encoder と Decoder にどのようなニューラルネットのアーキテクチャを用いるか?
- 発話内容や話者性にどのような特徴量を使うか?
- 品質重視の手法なのか?変換速度重視の手法なのか?
主なアプローチ
現在の最先端の音声変換研究では、主に
- 音声認識ベースのアプローチ
- 音声合成ベースのアプローチ
- Autoencoder ベースのアプローチ
- GAN(Generative Adversarial Network)ベースのアプローチ
の 4 つのアプローチがあり、その中でさまざまな手法が提案されています。
本記事ではそれぞれのアプローチの細部には触れませんが、いろんなやり方があるんだなというのを実感していただければと思います。それぞれのアプローチの詳細を知りたいかたは音声チームメンバが書いた「 DeNA 目線で見る 音声変換の最先端 」を参照してください。
音声チームではこれまでさまざまな手法を検討してきましたが、今回紹介する七声ニーナという Web サービスでは、音声認識ベースのアプローチを採用しています。
VOICE AVATAR 七声ニーナ
次に、我々が開発した VOICE AVATAR 七声ニーナ(2022 年 3 月 31 日をもってクローズしました)という音声変換 Web サービスを紹介します。七声ニーナはブラウザで簡単に音声変換を体験できるサービスです。誰の声でも七声ニーナというキャラクターの声に変換できます。
七声ニーナでは以下のような特徴を持つ音声変換を目指しました。
- 誰の声でも七声ニーナの声に変換できること。この特徴を Any-to-One といいます
- 利用者は音声を事前収録しなくても使えること
- 変換音声の品質がよいこと
- 音声変換に GPU が不要で CPU でできるほど高速であること
- 入力音声のイントネーションや感情が変換音声に反映されること
七声ニーナのデモ動画です。
七声ニーナの音声変換アーキテクチャ
七声ニーナの音声変換アーキテクチャについて少し詳しく紹介します。

誰の声でも七声ニーナの声色に変換するために入力音声から音素表現を抽出する音声認識ベースのアプローチを採用しました。入力音声を音素認識モデルで音素表現に落とし込むことで入力話者の話者性を完全に消すことができます。音素表現には入力音声の話者性に関する情報がまったく含まれないためです。
音素認識モデルは大規模な音声コーパスで訓練しており、利用者ごとの音声収録は不要です。また音声生成モデルは音素表現から七声ニーナの音声を生成するように学習しており、七声ニーナの声色を完全に再現できます。
また CPU でもリアルタイム動作できるほど軽量で高速な音素認識モデルと音声生成モデルを組み合わせたアーキテクチャを使いました。
入力音声のイントネーションの反映
さまざまな構成で実験を繰り返し、先に挙げた 5 つのニーズはだいたい満たせそうという感触が得られました。ところが最後の 1 つである入力音声のイントネーションや感情が変換音声に反映されるという要求が難題でした。話者性を消すために用いた音素表現が仇になって本来は残したいイントネーションの情報も消えてしまうという課題に突き当たりました。

この問題を解決するために、入力音声から声の高さを表すイントネーションの情報を取り出し、それを音声生成モデルに注入するというアプローチを取りました。新たにイントネーションを予測するモジュールを追加するのではなく、音素認識とマルチタスクで同時に求めたり、イントネーションを正規化・量子化するなどの細かい工夫を施しています。このような工夫により入力音声のイントネーションを変換音声に反映させることができるようになりました。
実際にどのように反映されたかのデモです。
日本語は文章がまったく同じでもイントネーションによって方言や意味が変わる言語です。入力音声のイントネーションを正確に変換音声に反映することは音声変換でとても重要な課題です。
1 つめの例は、東京アクセントと大阪アクセントで「ありがとう」をいいわける例です。
入力音声
変換音声にイントネーションが反映されない…
変換音声にイントネーションが反映された!
2 つめの例は「いい人じゃない」を 3 通りのイントネーションでいいわける例です。同じ文章でもイントネーションを変えると真逆の意味になります。
入力音声
変換音声にイントネーションが反映されない…
変換音声にイントネーションが反映された!
七声ニーナに欲しい機能
このような経緯で七声ニーナで使われる音声変換アルゴリズムを開発してきました。多くの方に使っていただき多くのフィードバックをいただきました。バッチ変換の品質改善についてもまだまだ課題はあったのですが、ニーナでほしい機能について調査した結果、リアルタイム音声変換のニーズが多くあることがわかりました。やはり音声変換の使い方としてライブ配信や音声チャットでキャラクターになりきって配信したいニーズが一定数あるのではないかと感じます。
リアルタイム音声変換に向けて
七声ニーナは、変換したい音声をすべて録音したあとに、音声変換して、再生するというバッチ変換という枠組みのアプリケーションでした。しかし、バッチ変換の使い道はかなり限定されます。
たとえば、七声ニーナの活用例として音声合成の代わりにナレーション音声として使った方がいてとても興味深かったです。
しかし、ライブ配信や音声チャットで音声変換を使うには七声ニーナのアプローチでは難しく、録音とほぼ同時に変換音声を再生(配信)するリアルタイム変換がどうしても必要になります。ここからは七声ニーナの公開後にリアルタイム変換を目指した過程を一部紹介します。
リアルタイム音声変換の作り方
バッチ変換をリアルタイム変換にするには、音声をブロックという短い単位に分割し、ブロックごとに録音・変換・再生を繰り返す処理が必要です。

リアルタイム音声変換の実装では 2 つのバッファを使います。入力音声を保存しておく入力リングバッファと変換音声を格納しておく出力リングバッファです。リングバッファは終点と始点がつながった配列のようなデータ構造です。

マイクから入力した音声は入力リングバッファに蓄積されます。音声変換アルゴリズムは指定のブロックサイズだけ音声が蓄積されたら入力リングバッファから取り出して音声を変換します。変換音声は出力リングバッファに格納し、スピーカーから出力します。
このような処理をループで繰り返すことでリアルタイム音声変換が実現できます。ブロックベース音声変換は非常に高速に動く必要があります。変換処理が重すぎると入力リングバッファがあふれてしまいますし、出力リングバッファが空になって音が途切れてしまいます。
また原理上必ずいくらかの遅延が起こります。遅延は入力音声がマイクに入ってからスピーカーから出るまでの時間と定義します。おもな遅延はブロックが満たされるまでバッファリングを待つ遅延と変換にかかる遅延です。
この枠組みを使って自分の声を七声ニーナの声にリアルタイムに変換したデモ音声を紹介します。
リアルタイムにニーナに変換した音声
入力音声と変換音声を重ね合わせて再生しています。変換音声が少し遅れて再生されますがこれは遅延のためです。比較的よく変換できているように思えますがまだまだ課題があります。
ライブ配信応用で要求される音声変換
ライブ配信応用で要求される音声変換として
- 安定性
- 低遅延
- 声色の多様性・制御性
の 3 つが特に重要な要素だと考えています。
安定性とは、変換音声が何を話しているか明瞭で容易に聞き取れることです。
低遅延とは、遅延が短いことです。配信者の多くは変換音声をヘッドフォンで聴きながら配信しているそうです。自分の話し声を少し遅らせて(50〜200 ミリ秒)聴きながら話すと話しづらくなる現象が知られていますが、そのような現象が起きないほど遅延が短いことが期待されます。具体的には 50〜70 ミリ秒が期待されています。
声色の多様性・制御性は、配信者のキャラクターにあった、自分好みのオリジナルな声色を簡単につくれることです。配信者全員が同じキャラクターの声で配信したいわけではないという意味です。
七声ニーナのアプローチで実現できるか?
安定性と低遅延のトレードオフ
これらのライブ配信応用で重要となるニーズに対して七声ニーナの技術で達成できるかを詳細に検証してみましたが、残念ながら厳しいという結論になりました。なぜ厳しいかといいますと・・・

一番大きな理由が安定性と低遅延のトレードオフです。安定性をあげようとすると遅延が長くなり、遅延を短くしようとすると安定性が下がります。
遅延を短くするためには、音声変換モデルを軽量化・最適化して高速化することが必要です。実はここはある程度できていて、考えうるかぎりの高速化のための工夫がなされています。
低遅延を阻む最大の問題は変換速度ではなく、変換に必要な音声をバッファリングするところにあります。このブロックサイズを短くすればするほど低遅延化することができます。しかし、このブロックサイズを短くするほど、音素認識の精度が下がる、つまり安定性が下がって、何をしゃべっているかわかりにくくなってしまいます。逆に安定性をあげようとすると、このブロックサイズを長くする必要があり、遅延は大きくなっていきます。
七声ニーナのリアルタイム変換の実装ではブロックサイズを最低でも 300 ミリ秒以上は取らないと変換品質が大幅に悪化することがわかっており、これ以上の低遅延化は難しいと判断しました。
声の多様性

次に声の多様性についてですがこちらも七声ニーナのアプローチでは難しいです。七声ニーナでは Any-to-One モデルを想定して作られており、誰の声でも七声ニーナの声色にすることができます。音声生成モデルを七声ニーナの音声だけを使って学習しているためです。逆にいうと七声ニーナの声色以外を生成することができない手法になっています。
ライブ配信応用に適した音声変換アプローチは?
現在、七声ニーナから得られた知見をもとにライブ配信応用に適したアプローチを模索しています。
- 安定性を上げるために明示的な音素認識を使わない
- 低遅延化するためにブロック長を短くしても安定性が高い
- 七声ニーナの声色だけでなく、パラメータを操作することでさまざまな声色を作り出せる
ような手法です。試行錯誤段階ですがこのような結果が得られています。
リアルタイム変換の新しいアプローチ
まだ品質がいまいちですが、安定性が高く、低遅延な変換が実現できそうな感触を得ています。近いうちにどこかの場で新しいリアルタイム音声変換の成果をお見せできればと思っています。
まとめ
今後、ライブ配信やメタバースなど音声変換の需要は高まると期待しています。その第一弾として VOICE AVATAR 七声ニーナをリリースしました。音声変換のさらなる活用のためにはリアルタイム変換が必須です。ライブ配信活用を目指して、安定性、低遅延、声の多様性や制御性を重視したリアルタイム音声変換技術を作りたいと考えています。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。