





はじめまして、AI システム部の森紘一郎です。音声チームにおいて音声合成をはじめとする音声技術に関する研究開発を担当しています。本記事では、 TechCon2020 で発表予定だった内容についてブログ記事にまとめました。
このPart1の記事では音声合成に関する取り組みについて紹介します。また、 Part2の記事 では音声変換に関する取り組みについて紹介します。
音声合成のデモは こちら から確認できます。
概要
バーチャルキャラクターやスマートスピーカーなど音声を活用した新たなアプリケーションが広がっています。近年、発展が著しい深層学習は音声分野にも導入が進んでおり、自分好みの声で好きな言葉を喋らせることや、男性の声を女性の可愛らしい声に変換することが可能になってきました。本記事では、最新の音声AI技術を紹介するとともに、音声合成のエンターテインメント分野への導入の試みについて紹介します。
背景
近年、AI による音声技術を活用した新しいアプリケーションが広がりを見せています。

スマートスピーカー、スマートカー、オーディオブックの読み上げ、ロボットやバーチャルキャラクターとの対話、歌声合成などです。
これらのアプリケーションを支えているのが、音声合成、音声変換、音声認識、音声対話といった AI 音声技術です。近年、盛り上がりを見せている深層学習(Deep Learning)は、音声分野にも盛んに取り入れられており、これら AI 音声技術にも革命をもたらしています。
DeNA の取り組み
我々、音声チームでは、DeNAの事業領域であるエンタメやライブ配信など音声技術と親和性の高い領域に向けたコア技術の研究開発に取り組んでいます。主に音声生成技術(音声合成と音声変換)に注力しています。これまで進めてきた、または進めているプロジェクトをいくつか紹介します。
ハッカドール VTuber
1 つめは弊社サービスであった ハッカドール たちの VTuber 企画です。
ハッカドール 3 人(1 号、2 号、3 号)の声帯システムの動作テストという企画で、配信側がテキストを入力することによりダイレクトに合成音声に変換して配信されていました。
ほぼ 1 年前の企画だったのですが、この頃は合成音声の品質が十分ではなく、視聴者の皆さまからは「(声帯システムの)修理が必要 w」といった温かくも直球なコメントをいただいていました。この記事では、修理してバージョンアップした声帯システムをようやくお披露目できます。
「バーチャル警備システム」の音声合成
2 つめは、セコム株式会社様と進めている「バーチャル警備システム」の音声合成です。
衛(まもる)と愛(あい)という警備員のバーチャルキャラクターに対して音声合成エンジンを提供しています。
テキスト音声合成とは?
テキスト音声合成とは、テキストから人工的な音声を作り出す技術です。任意の文章を任意の声色で喋らせることができます。
iPhone の Siri、Amazon の Alexa、Google Home などでおなじみの技術かと思います。これらは全てテキスト音声合成技術で作られた合成音声で、背後では何らかのテキストを入力として音声を合成しています。
例えば、「これは音声合成のテストです。」という文章をテキスト音声合成エンジンへ入力すると、下のような合成音声に変換されます。
DeNA の音声合成の目指すところ
我々は、数年前から音声の研究開発の一環として音声合成に取り組んできました。音声合成のアプリケーションは幅広くありますが、主にエンタメやゲームなど弊社の事業領域と親和性の高い分野に向けて音声合成の活用を検討しています。
主に 3 つの目標に取り組んでいます。
- エンタメやゲームで使えるレベルの高品質で表現力豊かな合成音声の実現
- 萌え声や爽やかな男性の声などゲームキャラクタとして使えるようなバリエーション豊かな話者ラインアップ
- 音声の専門知識がない人でも使いやすい Web エディタや API の開発
これらの目標に対するこれまでの取り組みについて合成音声サンプルを交えて順に紹介していきます。
音声合成を構成する 3 モジュール
まず、そもそもテキストから音声をどのように生成するのか技術的な説明をします。音声合成は、入力がテキストで出力が音声です。この間は 3 つのモジュールに分割できます。
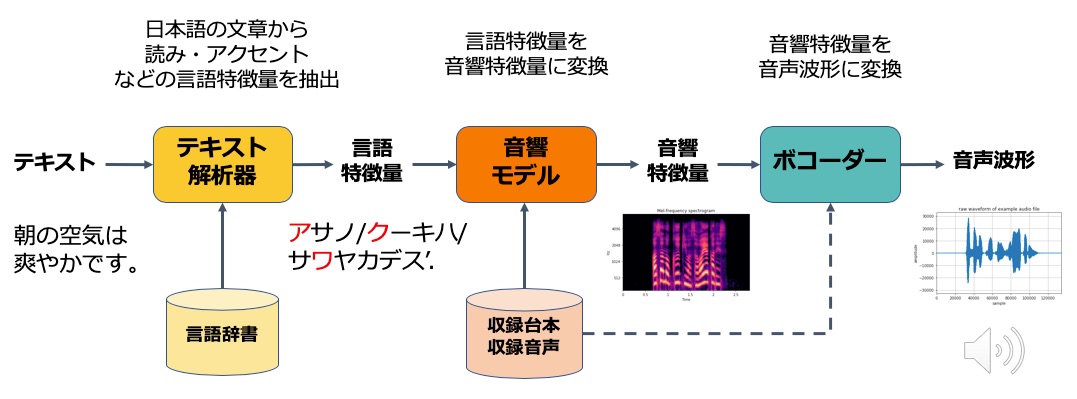
1 つめは、テキスト解析器です。日本語の文章から読みやアクセントなど音声の合成に必要となる言語的な特徴量を抽出します。
例えば、「朝の空気は爽やかです。」というかな漢字混じりの文章を言語解析すると「アサノ/クーキハ/サワヤカデス’.」のような表現に変換されます。漢字の読み、アクセント、句の切れ目などの情報が含まれます。これらの漢字の読みやアクセントなどの基本情報は言語辞書によって提供されます。
我々は、このモジュールに Mecab 、 OpenJTalk などのオープンソースソフトウェアを活用しています。
2 つめは、言語特徴量を音響特徴量に変換する音響モデルです。音響特徴量とは音声の波形を生成するために必要な特徴量です。例えば、スペクトログラムが使われます。音響モデルがテキストと音声の世界の仲介役を果たします。音響モデルを作るには、収録台本とそれを人が読み上げた音声が必要になります。
3 つめは、ボコーダーです。ボコーダーは音響特徴量を実際に人が聞こえる音声波形に変換します。
各ステップについて少し詳細を補足します。
音響特徴量
まずは基本となる音響特徴量についてです。
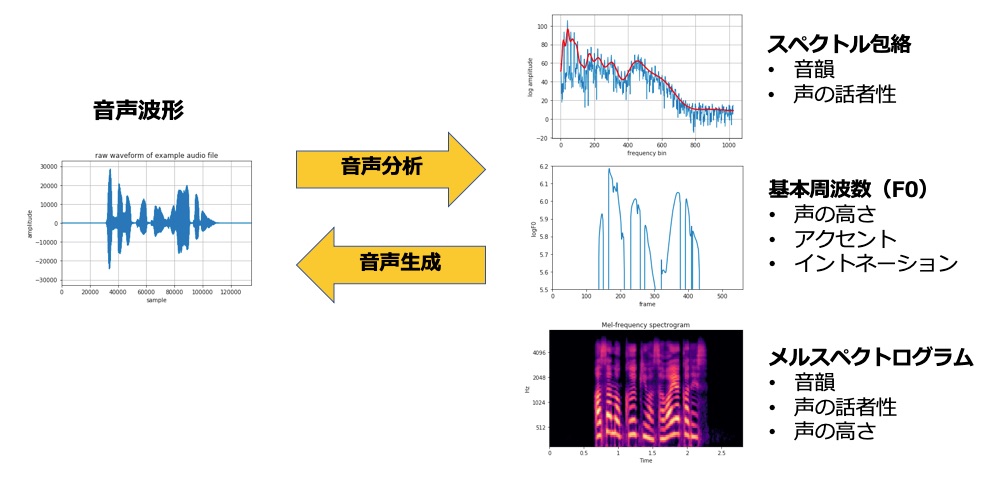
音声波形を分析することで、スペクトル包絡や基本周波数といった音響特徴量が得られます。
スペクトル包絡は、音声のスペクトルの概形を表しており、「アイウエオ」などの音韻や個人の声の違いを表します。また、基本周波数は声の高さ、単語のアクセント、疑問文で語尾が上がるといったイントネーションを表します。
メルスペクトログラムは、スペクトル包絡や基本周波数などの情報を包括的に含んだ音響特徴量で、最新の音声合成手法でよく使われる特徴量です。
これらの音響特徴量は音声から抽出できます。またこれらの音響特徴量からボコーダーを使って音声を再合成する・復元することも可能です。
音響モデルの作り方(学習)
音響モデルは、言語特徴量を音響特徴量に変換することでテキストと音声を仲介するモジュールです。
音響モデルは、機械学習(深層学習)によってデータから学習します。機械学習は、これを入力したらこういう出力になってほしいという正解データを与えることで、その変換規則・アルゴリズムを自動学習させられる技術です。
機械学習にはデータが必須ですが、音声合成のデータとは、収録台本と、合成音声を作りたい話者の音声です。
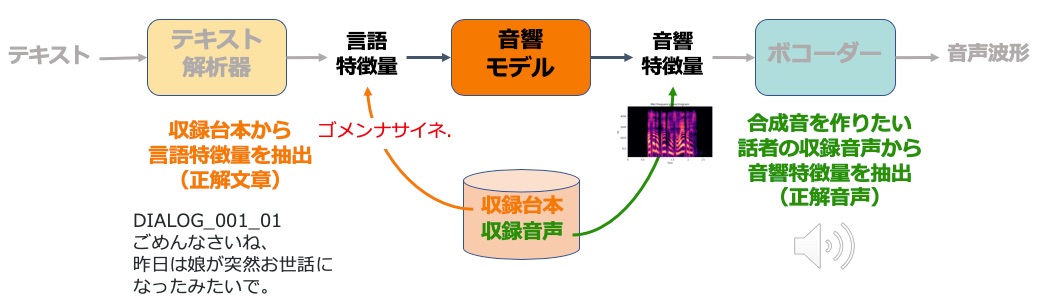
収録台本からは言語特徴量を、収録音声からは音響特徴量を抽出し、機械学習を使って言語特徴量を音響特徴量に変換する規則を学習させます。
テキストから音声への変換(生成)
一旦、音響モデルが学習できれば、任意の言語特徴量を入れることで音響特徴量を合成でき、ボコーダーで合成音声に変換できます。この合成された音響特徴量が肉声の音響特徴量に十分に近ければ肉声に近い合成音声が得られます。
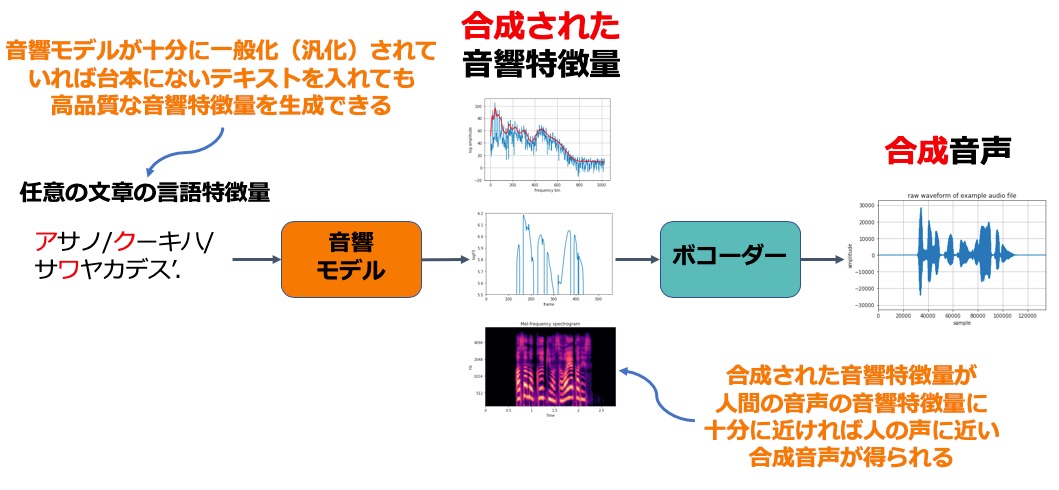
ここで重要なのが、音響モデルが十分に一般化されていれば、台本にないテキストを入れても高品質な音響特徴量を生成できるようになっていることです。このように学習時に与えていないデータに対しても正確な予測ができるようにすることを機械学習では汎化といい、音声合成においてもとても重要な評価軸になります。汎化が十分にできていないと入力するテキストによって品質が悪化します。
音響モデルにおける深層学習の活用
これまで音響モデルには隠れマルコフモデル(Hidden Markov Model: HMM)という技術がよく使われてきました。我々もいくつかのプロジェクトで隠れマルコフモデルによる音声合成を試してみたのですが、表現力豊かな音声を合成する上では限界があることがわかり、深層学習を活用した方式に切り替えを進めています。
音声合成への深層学習の導入は、2013 年あたりから様々なモデルが提案されています。
- DNN TTS [Zen et al. 2013]
- LSTM TTS [Fan et al. 2014]
- Deep Voice [Arik et al. 2017a]
- Deep Voice 2 [Arik et al. 2017b]
- Deep Voice 3 [Arik et al. 2018]
- Tacotron [Wang et al. 2017]
- Tacotron 2 [Shen et al. 2018]
我々は、既存手法の追試を繰り返し、
- 日本語への対応のしやすさ
- 音響モデルの学習に必要なデータ量
- 合成音声のイントネーションや品質の安定性
- 合成音声の品質と合成速度のトレードオフ
などを考慮してベース技術を選定、改良して活用しています。
LSTM TTS
ベース技術として活用している 1 つめの手法は、2014 年に提案された LSTM TTS です。
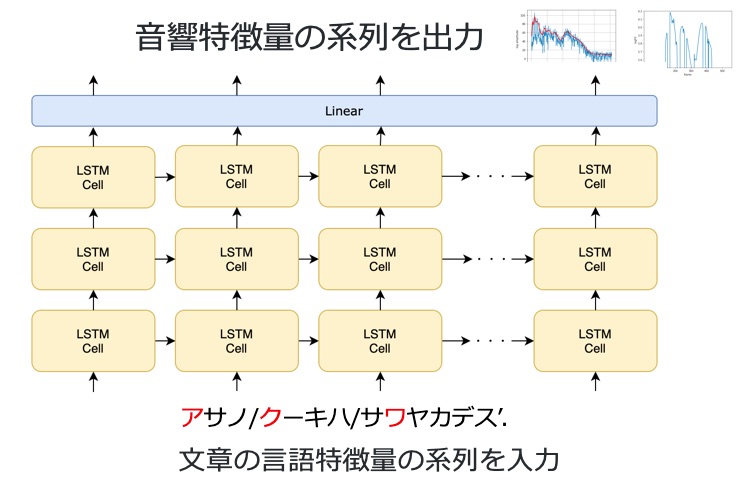
音響モデルに LSTM(Long Short Term Memory)と呼ばれるユニットをこのように格子状に配置したニューラルネットワークを使っています。この手法は、最先端の手法に比べて比較的処理が軽いわりに合成音声の品質が優れています。
Tacotron2
2 つめに検討している手法は、Google が 2017 年に提案した Tacotron2 です。
ほぼ人間の肉声に匹敵する合成音声を実現できたことで話題になりました。現在、もっとも高品質な音声合成モデルとして知られています。
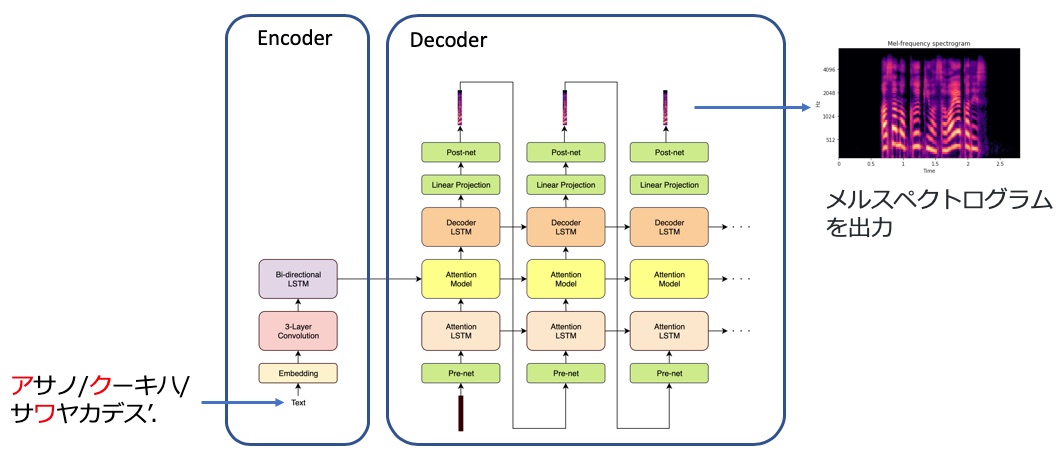
Encoder-Decoder 方式というアーキテクチャで、Encoder がテキストを処理し、その処理結果を Decoder に渡すことで音響特徴量を生成します。内部は非常に複雑なアーキテクチャなのですが、入力が言語特徴量、出力が音響特徴量で内部のパラメータを学習する点では LSTM TTS と同じです。
オリジナルは英語音声のみの実装ですが、日本語でも高品質の合成音声を出力できるように改造しています。
ボコーダーにおける深層学習の活用
次は音響特徴量を耳に聞こえる音声に変換するボコーダーです。ボコーダーは非常に重要なモジュールで合成音声の品質にダイレクトに影響します。
これまでは WORLD というオープンソースのボコーダーを活用してきましたが、より高品質な音声を合成するために深層学習を活用したNeural Vocoderの導入を検討しています。
Neural Vocoder は、音声研究では熱い分野ですでに様々な手法が提案されています。
- WaveNet [Oord et al. 2016]
- Parallel WaveNet [Oord et al. 2017]
- ClariNet [Ping et al. 2019]
- WaveRNN [Kalchbrenner et al. 2018]
- MelGAN [Kumar et al. 2019]
- SqueezeWave [Zhai et al. 2020]
学習に要な音声データ量、アプリケーションにおける制限などを考慮してベース技術の選定をしています。
WaveNet
現在の音質面での State of the Art は、Google が 2016 年に提案した WaveNet です。WaveNet も深層学習を活用し、音響特徴量を音声波形に変換する規則を学習するアルゴリズムです。
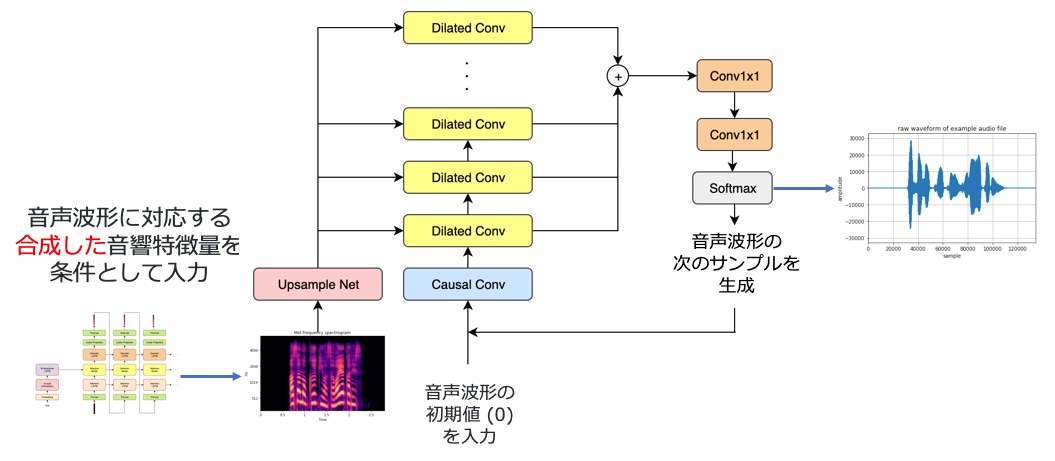
音声波形を 1 サンプルずつループを回すことで生成していきます。その際に、音響モデルで生成した音響特徴量を条件付けとして入力することでこの音響特徴量に対応した合成音声が生成されます。
先ほど紹介した Tacotron2 と WaveNet を用いて合成した日本語合成音声のサンプルです。どちらが合成音声でどちらが肉声か区別がつくでしょうか?
そんなアプリが存在するの?
みんな朝何時くらいに来るのかな?
実は最初の音声が合成音声で 2 つめの音声が肉声です。
このように WaveNet は非常に高品質な音声が生成できます。しかし、合成に必要な計算量が非常に大きいためリアルタイムな合成で使うのは難しいという課題があります。そのため、より計算量の少ない、別の技術も並行して検証しています。
音声合成実用化に向けた課題
音声合成を実用化する上でとても重要だと考えている課題がデータ量と品質の関係です。
基本的に収録した音声データが多ければ多いほど合成音声の品質も向上します。しかし、対象話者一人から大量に音声を収録するのはとても難しいです。
- 収録にかかる費用
- 音声のアノテーション費用
- 話者の疲労による声の変化
など理由は様々です。
あるプロジェクトで一人の声優から 1 万文章規模の音声を収録したことがありましたが、収録スケジュール調整や体調管理でとても苦労しました。
さらに提供する話者の数を増やしたい、例えば、 100 話者用意したい場合は、 1 話者 1 万文章として合計 100 万文章の収録が必要になり、現実的ではありません。
そのため、 少量の音声データから高品質な合成音声を作れるようにしたい! という需要は昔から存在しています。大量のデータが必要と言われる Deep Learning ではその重要性は増しています。
マルチ話者学習・転移学習
そこで、重要になるのがマルチ話者学習や転移学習といった技術です。この技術を使うと少量の音声から対象話者の合成音声を作り出せるようになります。
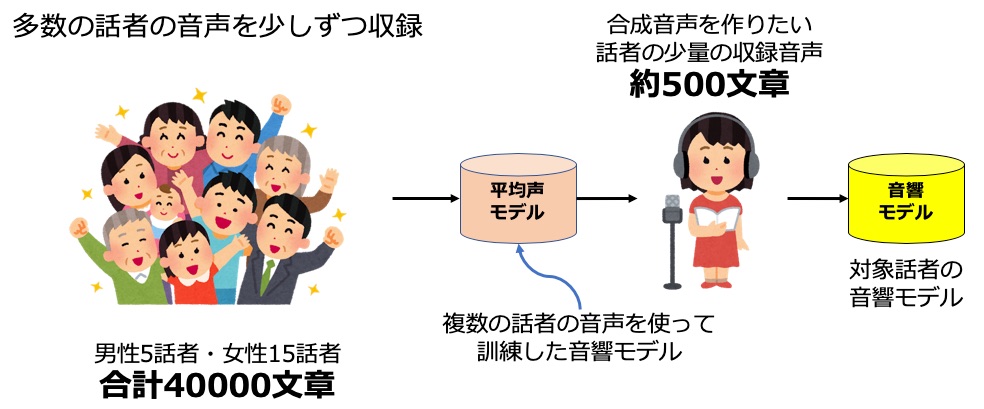
まず、前提として多数の話者の音声を少しずつ(例えば 2000 文章)収録しておきます。一人 2000 文章程度なら十分に収録できる規模です。
そして、これらすべての話者の音声を使って一つの音響モデルを学習します。音声分野では伝統的にこのモデルを平均声モデルと言います。
そして、本当に合成音声を作りたい対象話者は少量の音声(例えば、500 文章)を収録します。平均声モデルをベースにこの少量音声で追加学習することで対象話者の音響モデルを作り出します。
このような学習方法は転移学習と言われています。
具体例を見てみます。
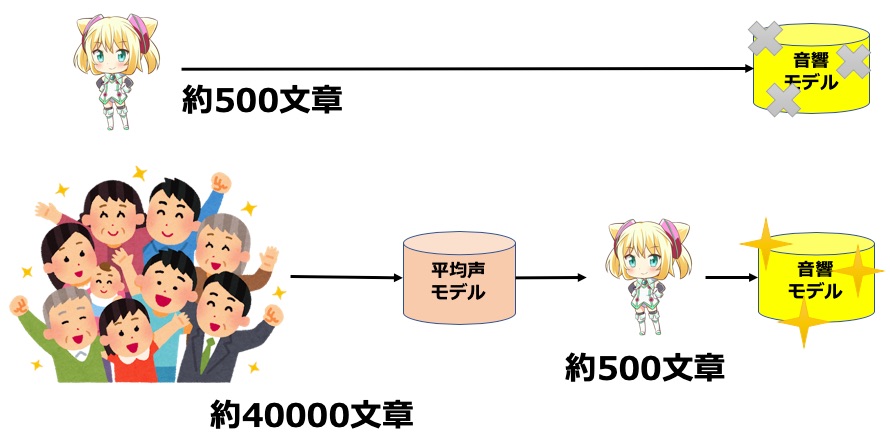
例えば、ハッカドール 1 号の声帯システムの研究時には 500 文章の収録にとどまりました。
最初、この 500 文章のみで音響モデルを学習してみたのですが、下の音声のようにボロボロの品質しか得られませんでした。
起こしてくれる必要はなかったのに(before)
その一方で、転移学習を使って 40000 文章のみんなの声をベースにしたら下の音声のように素敵な声に変わりました。
起こしてくれる必要はなかったのに(after)
このように転移学習を使うと少量の音声から高品質な音響モデルを作れるようになります。音質は良くなりますが、マルチ話者化することで学習が不安定になる場合があるため対策を進めています。
高品質で表現力豊かな合成音声を実現するために
先ほど紹介したマルチ話者学習による LSTM TTS で作った合成音声でここまでをまとめます。
最新の音声合成技術のキャッチアップと、試行錯誤を日々繰り返しています。
ビジネス適用を考えると音質だけでは不十分です。音質と計算量のトレードオフ、再現性、安定性、頑健性を高める工夫が必要になります。
最新の音声合成技術を統一されたインターフェースで、訓練、推論できるライブラリを開発しています。
バリエーション豊かな音声合成を実現するために
バリエーション豊かな音声合成を実現するために3つの工夫をしています。
1つめは、ゲームやエンタメで使いやすい多様な音声を収録していることです。読み上げ調ではない、より表情豊かで読みやすい対話シナリオの整備も並行して進めています。
2つめは、ゲーム・エンタメ事業部のコネクションを活用した声優事務所との協力です。これまで、様々な声色を持つ声優の収録にご協力いただきました。また、収録に際しても一定の声色、調子を保つなど工夫しています。
3つめは、バリエーション豊かな話者ラインアップの準備です。これまで 20 話者以上の様々な声色の音声データを整備し、音声合成の実験に活用しています。
合成音声サンプル
ここで、弊社で作成した音声合成エンジンを使った合成音声を紹介します。
まずは、弊社のハッカドールたちの合成音声です。マルチ話者化した LSTM TTS でそれぞれ 500 文章で学習した音声を使っています。

おはようございます!朝のハッカドール配信ですよ!
マスターさん、この部屋に来ちゃいましたね!
今日はとっても楽しかったです!

温泉は、疲れが癒されますね。
いいアイデアな気がしてきたわ。
それにしても、今日はいい天気ね。

あ、マスター、なんでこんなところにいるのさ。
みんな何しに来てるのかなー?
ちょっとくらいなら付き合ってあげてもいいけどー。
次の音声は様々な声色のキャラクターです。こちらもマルチ話者化した LSTM TTS でそれぞれ 2000 文章で学習しています。
これあげるわ。別にあんたのために作ったんじゃないんだからね!
私、本を読むのが大好きなんです。
わかりました。確認してまいりますので、少々お待ちください。
最後の音声は、マルチ話者化した日本語 Tacotron2 と WaveNet を使って合成した試作品です。2000 文章で学習しています。
でも誰もアタックしてないんじゃない?
何回か作れば、自然と覚えるわよ。
突然だけど、お父さんが帰ってきたみたい。
お迎えありがとうございます。
今日も一日ありがとうございました。
本当ですか!食が細いのが心配で。
このように最先端の音声合成技術は、読み上げに限定すればほぼ人間の品質にまで迫っています。一方、感情表現や演技が難しいという課題もあります。そのため、ゲーム・エンタメ分野において音響関連の実務にまつわる方々のサポート的な位置付けとして、新たな価値を提供できる使い方を模索しています。
使いやすい Web エディタ、API の開発
三つめの特徴は使いやすい Web エディタと API の開発です。IT 企業である弊社はフロントエンド・バックエンドの優秀なエンジニアが多数在籍しているため、仲間と協力してこれまでにない使いやすいツールの開発を目指しています。
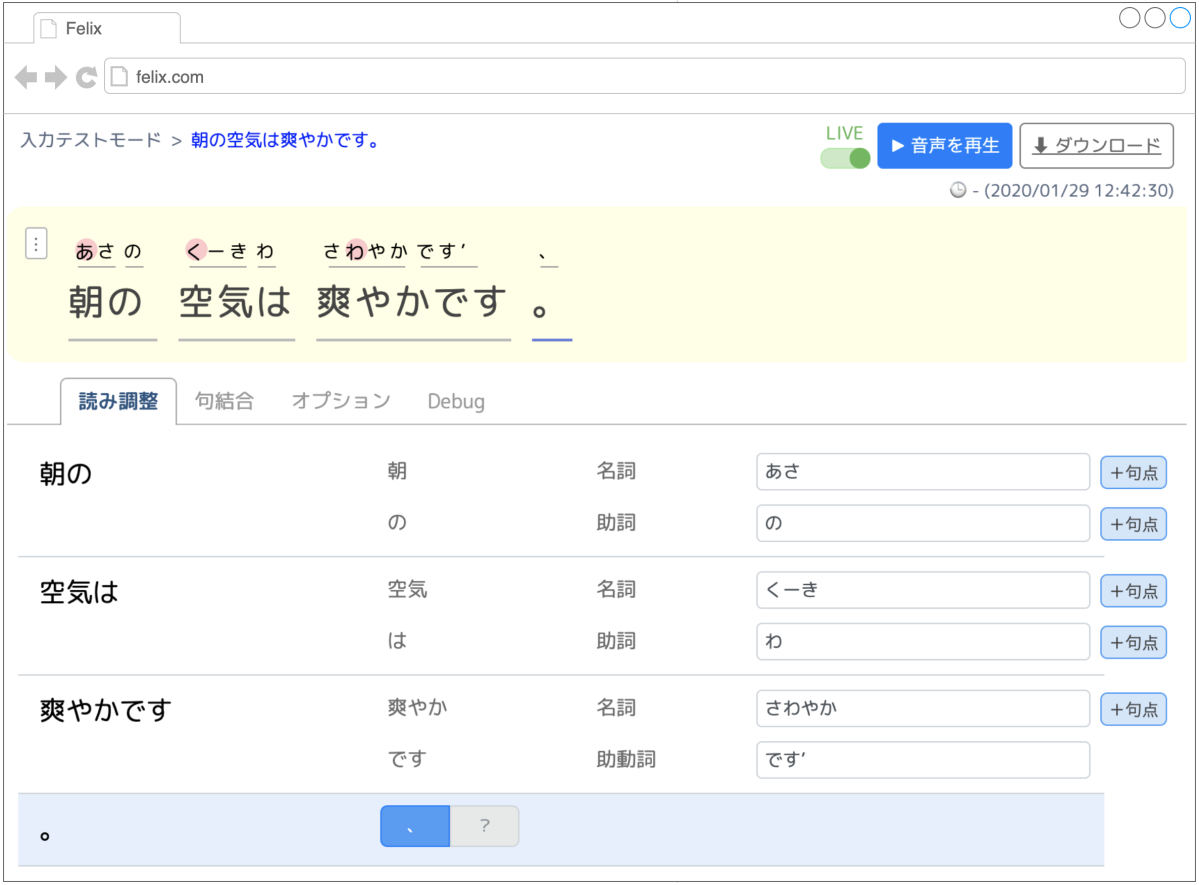
音声合成のコンテンツを作る上で必要になるのが音声合成エディタです。我々は Web 上で直感的な操作でインタラクティブに音声コンテンツを作成できる音声合成エディタを React.js で開発しています。読み・アクセント・イントネーション・話者の変更などが簡単な操作でインタラクティブにできます。
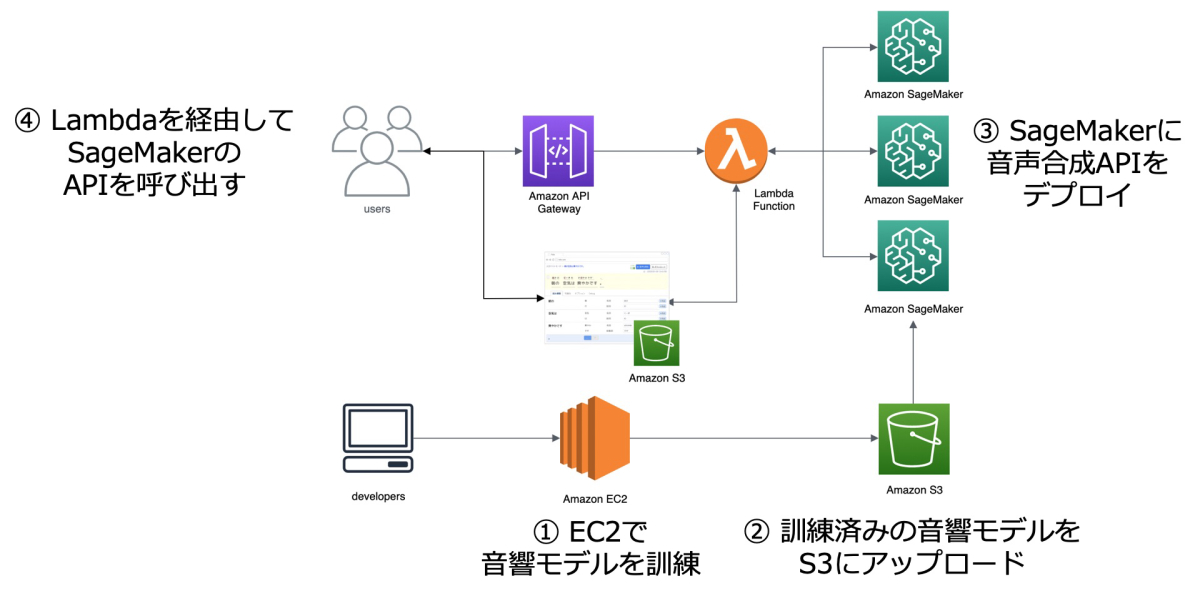
また、音声合成 API などバックエンドについては MLOps(Machine Learning Operations)のエンジニアと連携することでスケーラブルな API を AWS (Amazon Web Service) 上に構築しています。先進的な試みとして AWS の SageMaker を活用してスケーラブルな API を実装しています。
まとめ
最後は合成音声でまとめたいと思います!
高品質で表現力豊かな合成音声が作れます。
バリエーション豊かな話者を用意しました。
使いやすい Web エディタと API を開発しました。
参考文献
- [Zen et al. 2013] Statistical Parametric Speech Synthesis using Deep Neural Networks, ICASSP 2013.
- [Fan et al. 2014] TTS Synthesis with Bidirectional LSTM based Recurrent Neural Networks, INTERSPEECH 2014.
- [Arik et al. 2017a] deep voice: real-time neural text-to-speech , ICML 2017.
- [Arik et al. 2017b] deep voice 2: multi-speaker neural text-to-speech , NIPS 2017.
- [Arik et al. 2018] deep voice 3: scaling text-to-speech with convolutional sequence learning , ICLR 2018.
- [Wang et al. 2017] tacotron: towards end-to-end speech synthesis , INTERSPEECH 2017.
- [Shen et al. 2018] natural tts synthesis by conditioning wavenet on mel spectrogram predictions , ICASSP 2018.
- [Oord et al. 2016] wavenet: a generative model for raw audio , arXiv:1609.03499.
- [Oord et al. 2017] parallel wavenet: fast high-fidelity speech synthesis , arXiv:1711.10433.
- [Ping et al. 2019] clarinet: parallel wave generation in end-to-end text-to-speech , ICLR 2019.
- [Kalchbrenner et al. 2018] efficient neural audio synthesis , arXiv:1802.08435.
- [Kumar et al. 2019] melgan: generative adversarial networks for conditional waveform synthesis , arXiv:1910.06711.
- [Zhai et al. 2020] squeezewave: extremely lightweight vocoders for on-device speech synthesis , arXiv:2001.05685.



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。