





こんにちは、IT 基盤部の 萩行 です。大規模ゲームタイトルのインフラを運用しております。
私の所属しているグループでは数千台規模のインスタンスを管理しており、インスタンス数に比例してインスタンスの基盤障害が多く発生しています。
本記事ではインスタンス基盤障害に対して、どういう仕組みで対応を自動化したかをお伝えいたします。
基盤障害対応の自動化以前
これらのインスタンスは、重み付けラウンドロビンの機能を持つ internal DNS を使用して、負荷分散・冗長化を実現しています。
インスタンスの障害時には、独自のヘルスチェッカーが通信不可を検知し、該当インスタンスの重みを 0 にします。その結果、リクエストが故障インスタンスに振り分けられないようになり、サービス影響を数秒程度におさえる仕組みになっています。
しかし、その後の復旧処理に関しては、オペレータが手動で対応していました。
インスタンスの役割ごとに復旧手順が異なるため、それぞれの手順書を参照しながら、各種ツールを実行することで、復旧させていました。
インスタンスの障害の頻度としては、多い時で1日に数台程度、1週間に10数件程度のインスタンス障害が発生していました。
その度に、アラート対応として約20分から30分程度の対応工数がかかるという問題がありました。
基盤故障対応を自動化する仕組み
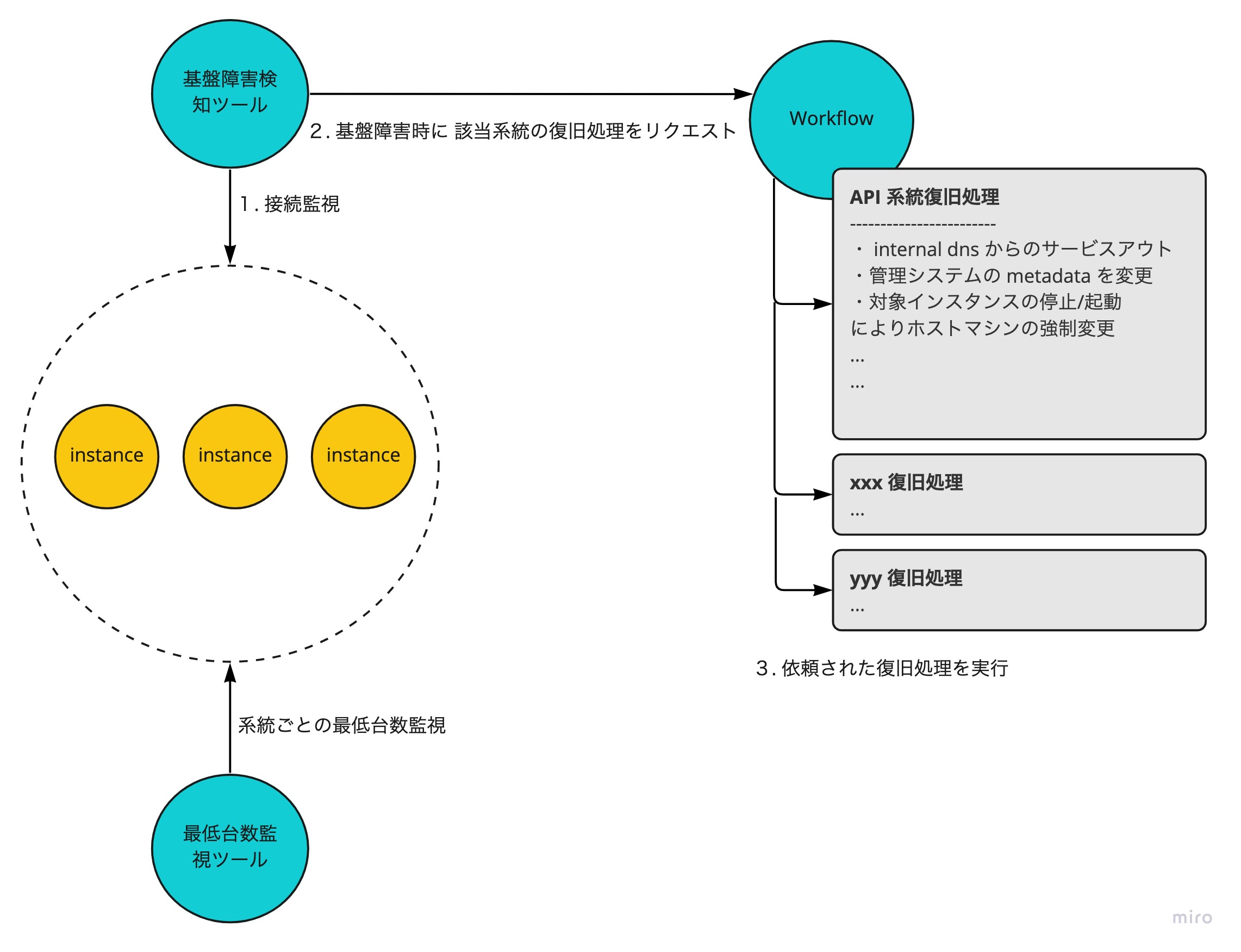
基盤障害対応の自動化は、基盤障害検知ツールとインスタンスのオーケストレーター( Workflow という内製ツール)により実現しています。
自動化処理の大まかな流れとしては、以下のようになっています。
基盤障害検知ツール
基盤障害検知ツールでは、各種インスタンスに対して定期的に接続確認を実施しています。
その結果、接続できない期間が閾値を超えた場合は(リトライ間隔を指数関数的に増加させ、リトライに4回失敗した場合)、内製の Workflow に該当のインスタンスの復旧処理を実行するように依頼します。
基盤障害かどうかは AWS の場合であれば、Amazon CloudWatch のシステムステータスチェックの値で確認することができます。
しかし、システムステータスチェックの値が正常の場合でも、基盤障害のような事象に何度か遭遇しています。このため、実際にインスタンスへの接続確認を実施しチェックしています。
もし、何かしらの理由によりインスタンスの復旧処理が行われない場合に備えて、active なインスタンスの最低台数をチェックする仕組みを入れています。この監視によりインスタンスが規定台数に満たない事に気付けるようになっています。
また、単一インスタンスの基盤障害ではなく、ゾーン障害やリージョン障害などの障害も起こることがあります。
ゾーン障害やリージョン障害などの広い範囲の障害が発生した際に、全てのインスタンスに対して復旧処理を実施すると、復旧処理が途中で異常終了し、その後の復旧対応がさらに大変になることもあります。
そのため、一定期間内に異常があるインスタンス数の検知閾値をもち、閾値以上の障害を検知した場合は、広い範囲の障害が起きている可能性があるため、自動復旧はしないようにしています。
復旧処理
復旧処理を依頼された Workflow は、依頼されたリクエストを元に登録されている復旧処理を順次実行します。
Workflow で実行する復旧処理は、インスタンスの役割毎に定義しています。
例えば、API Server の役割を持つインスタンスで障害が発生した際は、以下のような処理が実行されます。今まではこれに相当する処理を手動で行うことで復旧させていました。
- internal dns から 対象のインスタンスをサービスアウト
- 内製の管理システムの metadata を変更
- 対象インスタンスを監視除外
- 対象インスタンスの停止/起動 によりホストマシンの強制変更
- 対象インスタンスへの接続確認
- API Server daemon の起動
- 対象インスタンス の API Server の release version が、サービスインされている API Server の release version と同様であるかの確認
- 対象インスタンスへの監視が全て正常であることの確認
- 内製の管理システムの metadata を変更
- internal dns に対象インスタンスをサービスイン
処理の前後で処理依存がない場合は並列で実行しており、なるべく早く復旧作業が完了するようにしています。
Autoscale 対象インスタンスの障害の場合は、以下のように各種処理が実行されます。
- internal dns から 対象のインスタンスをサービスアウト
- 内製の管理システムの metadata を変更
- 対象インスタンスを監視除外
- 対象インスタンスの削除(台数調整は Autoscale により実施)
今回入れたインスタンス基盤障害の自動化の仕組みにより、多い時で1日に数台程度、1週間に10数件程度発生していたインスタンス障害が自動で復旧するようになっています。
インスタンスの予定されたイベント(再起動等)などの際も、今回の仕組みを使用し自動化が可能になります。
終わりに
今回は大規模なインスタンスを管理している上で、インスタンス数に比例して起きるインスタンス基盤障害の対応について紹介いたしました。
もし詳細にご興味をお持ちの方やシステムをより進化させるために一緒に取り組んでくださる方がいらっしゃれば、ぜひ DeNA に join してください。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。