





こんにちは、IT 基盤部の Wei です。大規模ゲームタイトルおよびゲームプラットフォームのインフラを運用しております。
私のグループが運用しているシステムでは Auto Scaling を導入してからもうすぐ2年が経ちます。
この2年で Infra System の構成は徐々に変わってきました。今回は Auto Scaling という観点から、現時点の Infra System の構成がどのようになっているかをご紹介します。
Instance の台数管理
Auto Scaling を導入する前、Instance の台数管理は人手でした。台数管理には必要台数の計算から Instance の構築・撤去まで Instance 関連の処理が全て含まれるため、人手で行うには多くの工数が掛かります。また、人手で対応するため想定外のトラフィックが押し寄せた場合に台数を増やすのに時間が掛かるというケースも多々ありました。更に、人手だと管理頻度にも限界があり、余剰リソースを持つ時間帯が多く、それゆえ無駄なコストも掛かっていました。
以上の課題を解決するため、Instance の台数管理を自動化する必要があります。当時マネージドの Auto Scaling サービスで我々のシステムの要件を満たすものはなく、また Spot Instance との併用時に求められる柔軟性などを考慮し、Auto Scaling システムは独自に実装することにしました。ちなみに、このシステムは現時点では GCP の Managed Instance Group と連携するなど、一部マネージドサービスの機能も取り込んでいます。
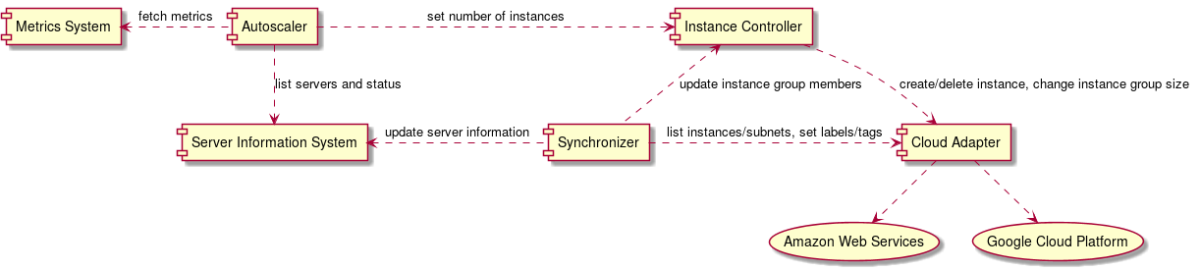
台数管理システムには大きく2つの Component があります。台数維持を担当する Component (以下、Instance Controller)と台数計算を担当する Component (以下、Auto scaler)です。
Instance Controller は、設定された台数を維持することを目標にします。サーバが落ちたら自動的に Instance を作成しますし、Instance 台数が設定値を上回ったら Instance を撤退します。Instance Controller に対する入力は必要台数の総数のみですが、単に台数を足すだけではなく様々な事情を考慮する必要があります。Spot Instance と On-demand Instance の比率をどうするのか、複数の Instance タイプをどのように混在させるのか、どの Availability Zone に Instance を立てるのかなど。例えば Spot Instance が枯渇したら On-demand Instance を利用する必要がありますし、特定の Instance タイプの在庫が枯渇した場合は別な Instance タイプを利用する必要があります。ちなみに、なぜ種類が多いか以前の記事 DeNA の QCT マネジメント を参考できると思います。
一方、Auto scaler は必要台数を計算して Instance Controller に伝えます。台数の計算は、Metrics (基本的にCPU) に基づいていますので、Metrics 集計システムが必要です。一般には CloudWatch、Prometheus などが使われますが、我々のシステムはここも独自実装になっています。フラッピングを避けるため、Auto scaler は CPU 利用率が一定の範囲内に収まるように指示を出します。具体的には CPU 使用率が60%を超えたら台数を増やし、40%を下回ったら台数を減らす、という具合です。そして、Instance の構築はどれだけ高速化を頑張っても数分単位で時間が掛かるため、瞬間的になトラフィック増には間に合いません。そのようなケースは事前に予測可能なことがほとんどなので、事前に台数を増やしておくことで対応しています (そのようなスケジューリング機能も持っています)。

Instance の作成
DeNA にはサーバのメタデータを管理するための専用のシステムが存在します。これは主にオンプレ環境でサーバを維持管理するために必要なシステムでした。クラウドの IaaS 環境においても、このサーバのメタデータ管理システムが必要です。
このメタデータ管理システムと連携するため、Synchronizer と呼ばれるコンポーネントを開発しました。オンプレ環境においてはこのシステムに登録する作業は人手で行なっていましたが、IaaS 環境においては Terrafrom や Google Managed Instance Group や AWS Auto Scaling Group などと連携する必要があり、その処理を自動化するために Synchronizer が必要です。
クラウドのリソース情報をメタデータ管理システムと連携させるにはもう一つ問題があります。それは利用するクラウドの種類が増えるたびに、そのクラウド専用のロジックを実装する必要があることです。この問題を解消するため、我々は Cloud Adapter と呼んでいる抽象化層を実装しました。例えば、Instance にアタッチする Volume として AWS であれば EBS、GCP であれば Persistent Disk がありますが、これらはVolume という概念で抽象化しています。こうすることで他システムからはクラウドサービスの違いを意識することなく統一した Interface で扱うことが可能です。
ちなみに、Interface 自体は、Protocol Buffers で定義しています。例えば、Instance の定義:
message CloudInstance {
string id = 1;
cloud.CloudProvider provider = 2;
string zone = 3;
string name = 4;
// Private IP of first NIC
string private_ip = 5;
// Public IP of first NIC
string public_ip = 6;
// Subnet Reference of first NIC
cloud.ResourceReference subnet_ref = 7;
string instance_type = 8;
map<string, string> label = 9;
google.protobuf.Timestamp launch_time = 10;
string fqn = 11; // Fully qualified name such as self-link, ARN, etc.
...
}以上で、Instance を作成したら同時にメタデータ管理システムにも登録することが可能になります。同時に Instance の Life cycle も開始されます。
Instance の Life cycle 管理
Instance を作成したら、OS 設定、アプリケーションコードのデプロイ、テスト、監視設定などの作業を行います。この一連の作業はこれまで専用のスクリプトで行なっていましたが、スクリプトだと以下のような問題がありました。
- スクリプトがどんどん太り、メンテナンスコストが増え続ける
- 長大なスクリプトは冪等性を担保することが難しい
- 処理の途中からリトライさせるような処理を書きづらい
- スクリプトの実行ホストが落ちた場合に構築・撤去処理自体が失敗する
- 構築・撤去処理がどこまで進んでいるのか見えづらい
- 構築・撤去処理の負荷分散がしづらい
- 構築・撤去処理の並列実行やパイプライン化が難しい
- 実行してるスクリプトを丁寧にキャンセルしにくい
構築台数が増えれば増えるほど、上記の問題は顕在化してきます。この問題を解消するため、Workflow というシステムを開発しました。
Workflow は大きく2つの Component から成ります。タスクの管理とディスパッチを行う Scheduler とタスクを実際に実行する Executor です。Scheduler と Executor はそれぞれ冗長化していますので、数台落ちても Workflow の実行に与える影響は軽微です。Workflow は各処理に対してリトライやタイムアウトを設定することが可能です。またタスクの単位を小さくすることで冪等性も実装しやすくなります。
Workflow は Jenkins のように設定したタスクを順番に実行していきます。さらに、Workflow はタスクの分散処理、パイプライン化、自動リトライ、依存関係を考慮したタスクの実行などを行うことができます。Workflow で実行するタスクを設計する上で二つ重要なポイントがあります。1つ目は各タスクに冪等性を持たせること、2つ目はタスク間の依存関係を減らすことです。この2つを満たすことでタスクの途中失敗を減らすことができます。
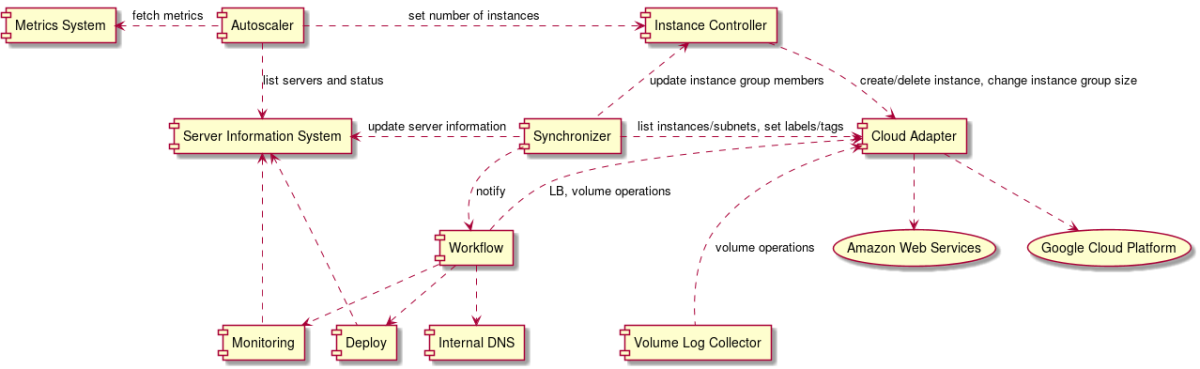
Instance の構築タスクは前述の通り様々ありますが、その中で一番難しいのはアプリケーションのデプロイです。デプロイの方法次第では、その処理自体が非常に時間が掛かってしまいます。この問題には、事前に最新のアプリケーションをデプロイした Image を用意しておき、そこから Instance を作成するという方法で対処することにしました。
Instance の撤退
Instance の Life cycle の終わりは、Instance をサービスから完全に切り離し、Instance 自体を削除することです。メタデータ管理システムからの削除も行う必要があります。これで Instance の撤退が完了だと思いますが、実はそうではないです。Volume の Life cycle も考慮する必要があります。
なぜ Volume の Life cycle と Instance の Life cycle が違うかというと、主にログ回収のためです。ログの回収は、エラーログなど即時転送しているログもありますが、データ量によって即時転送していないログもあります。さらに、転送先(例えば Fluentd サーバや Stackdriver Logging など) の障害が起きる可能性があります。障害のタイミングによってログを即時に回収できない場合もあります。溜まっていたログを転送するために、その間 Instance を起動し続けるのは非効率ですし、AWS Spot Instance や GCP Preemptible Instance などは Instance は短時間で削除されてしまうので、Volume の Life cycle と Instance 分けるのは一つの案になります。
そのため、Instance を撤去するときは Instance はそのまま削除しますが、ログがある Volume はまだ消さないようにします。我々のログ回収システムは、使い済みの Instance の Volume を mount して、中身を S3 や Google Cloud Storage に転送しています。ちなみに、転送したログは、AWS Athena と Google BigQuery を活用して、検索することも可能です。
まとめ
今回は Auto Scaling の観点から、私のグループの Infra System の構成を大ざっぱに紹介しました。構成はそんなに複雑ではないですが、様々な問題に対処するため、工夫を凝らしています。そして、紹介したシステムは一気に完成したのではなく、最初は簡単なスクリプトから始まり徐々に進化してきました。現在でもまだ進化中です。もし詳細にご興味をお持ちの方やシステムをより進化させるために一緒に取り組んでくださる方がいらっしゃれば、ぜひ DeNA に join してください。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。