






※こちらは先日実施された DeNA インフラエンジニア / SRE MEETUP で話した内容を Blog 記事化したものです!
はじめに
こんにちは。 IT 基盤部の安藤です。 IT 基盤部にて、ゲームプラットフォーム及びオートモーティブ事業のインフラの運用を主に担当しております。
大規模システムの運用を経験し、どんな規模のサービスでも管理できるようになりたい。そう思っているインフラエンジニア、SREの方々は多いのではないでしょうか?
DeNA グループ全体のシステム基盤を横断して管理しているインフラ部門、IT 基盤部。その IT 基盤部では多くの新卒入社エンジニアがゼロから経験を積み、それら大規模なシステムを管理してくための様々な学びを得ています。
本記事では、「そういった大規模システムを管理するための学び」について、若手エンジニアが入社して行った具体的な経験を IT 基盤部配属後にどんなタスクをやるか、IT 基盤部ではどんな振る舞いを要求されるか、私自身が IT 基盤部で働いてみてどんな学びを得たか という流れでお伝えします。
IT 基盤部配属後にどんなタスクをやるか
まずは私の経験について説明します。

1年目は主に下記の業務を行いました。
- 既存環境のキャッチアップ
- 通常運用 (アラート対応や問い合わせ対応)
- 中規模なタスクの実施
新入社員一人ひとりに対してメンターが付き、そのメンターとともに業務を進めていきます。 既存環境のキャッチアップは「本番環境で動いているサーバと同等のものを開発環境の AWS EC2 インスタンス上に作成する」という課題を通して行います。 また、IT 基盤部は内製ツールを多く利用しており、それらの使い方は日々の通常運用の中で学んで行きます。
配属から約6ヶ月頃、キャッチアップが進み通常運用業務になれたタイミングで、3ヶ月程度掛けて行う中規模なタスクがアサインされます。 私の場合は、オートモーティブ事業のとあるサービスで、新機能のテストを行うための sandbox 環境を1から構築するというものでした。
上図の「DeNA で利用されるクラウドアカウントの作成・管理フローの改善」はグループの業務とは別の特殊なものでした。 当時、私はインフラ以外に運用工数や作業工数の削減というものにも興味があったため、進んで手を挙げて取り組んでいました。 詳細は パブリッククラウドアカウント作成自動化について をご参照ください。 このようにやりたいことが明確であれば、グループの垣根を超えて業務をすることも可能です。
2年目は主に下記の業務を行いました。
- 通常運用 (アラート対応や問い合わせ対応)
- 大規模なタスクの実施
2年目になると、より大規模なタスクがアサインされます。 1年目のタスクと違う部分は、実施期間の長さ・関係者の数・任される範囲等です。
私の場合は 「モバゲーを構成する複数のコンポーネントをオンプレミスから AWS アカウント上に移行する」 というタスクがアサインされました。 また、クラウド移行中に発生した問題の調査や再発防止策の検討も行いました。
IT 基盤部で要求される立ち振る舞い について説明する際に2年目でやったことの詳細をお伝えします。
そして、3年目は主に下記の業務を行っています。
- 通常運用 (アラート対応や問い合わせ対応)
- 大規模なタスクの実施・管理
3年目となると他事業部や他社との関わりも増え、任される業務の範囲も更に広がります。 私はインフラ運用を外注しているタイトルの AWS アカウントのコスト削減を実施していました。
また、2年目と大きく違う点として、他メンバーのタスクの管理などが求められることがあります。 私は新入社員のメンターと担当サービスの OS のマイグレーション業務の管理等を行っています。
以上が、私が今までやってきたことの概略です。
私以外に IT 基盤部に配属された人がどのようなことをやっているかも気になると思うのでいくつか紹介しておきます。
例えば、2019 年に入社した新卒だと、1年目の中規模なタスクとして「一部の環境の MySQL のバージョンアップ」、2年目の大規模なタスクとして「モバゲーのデータストアサーバのクラウド移行」を実施していました。そして3年目は「モバゲーのデータストア周りの構成変更」といったよりチャレンジングなタスクに携わりスキルアップを図っています。 翌年 2020 年に入社した新卒だと、1年目の中規模なタスクとして「とあるサービスへの新しいツールの導入」、2年目の大規模なタスクとして「とあるオートモーティブのサービスのクラウド移行」を行いました。 2021 年に入社した中途だと、1年目の中規模なタスクとして「とあるオートモーティブのサービスの OS のマイグレーション及び構成管理ツールの導入」という業務を進めてもらっています。
他のメンバーが取り組んでいた、グループの垣根を超えた業務の例を他にあげると AWS アカウントを横断して SSH ポート全開放を検知・修復する仕組みを導入した話 があります。
タスクの規模や内容は多少異なるとは思いますが、IT 基盤部に配属された人は皆同じように少しずつできることを増やしスキルアップしていっています。
IT 基盤部ではどんな振る舞いを要求されるか
続いて IT 基盤部で求められる振る舞い について、私が実際に経験した業務を元に説明します。
モバゲーコンポーネントのクラウド移行
私は配属2年目にモバゲーの複数のコンポーネントをオンプレミスから AWS アカウント上に移行するタスクがアサインされました。 私が実際に担当したのは下記の項目です。
- サーバの構築
- セキュリティの担保
- 技術負債の返済
- クラウド上での運用方法の確立
1つずつ説明していきます。

サーバ構築では、移行先の AWS アカウントを作成し、ネットワークを設計する所から始め、スペックと台数の見積もりを行い、サーバを切り替えるところまでを担当しました。
特定のインスタンスの障害や AZ 障害が発生したとしてもサービスを提供し続けられるよう 発生しうる問題を考慮して仕組みを考える力 や、データセンターの解約日は決まっていたので、期日までに移行を完遂させる計画性、作業の進捗を可視化し、管理者が管理しやすい状態を作ること 等が求められました。
また、クラウド移行作業ではセキュリティの担保も求められました。
モバゲーのようなレガシーな環境では、改修難易度の問題で古いバージョンのミドルウェアやモジュールを使っている箇所があります。
いずれは根本対応を行う必要がありますが、期限の決まっているクラウド期間中に対応することは不可能だったため代わりにリスクを減らす対応を取りました。
具体的には、古いミドルウェアを使っている環境は AWS アカウントをモバゲー本体が稼働しているアカウントと切り離し最低限の通信のみを許可しました。 万が一外部から攻撃を受けたとしても被害を最小限に抑える為です。また古い OS を使い続けること自体がリスクだったため、クラウド移行を期にマイグレーションも行いました。

技術負債の返済では、 OS のマイグレーションに合わせて、複数のミドルウェアのメジャーアップデートを行いました。
実際に私がクラウド移行でアップデートを行ったのは Nginx, Squid, MySQL です。
特に MySQL に関しては、オンプレミスのサーバ上で動いていた MySQL をそのまま EC2 に載せ替えるのではなく、Aurora に移行しました。
マネージドサービスの Aurora を利用したほうが、管理するサーバの台数が減り、AWS コストと運用工数の両方を削減できるからです。
セキュリティや技術負債はレガシーなシステムと向き合う上で重要な課題であり、現状を維持するだけでなく改善し続ける力 が求められます。
最後に運用方法の確立では、上図に書かれている項目の運用方法を1から考えるという業務を行いました。
- オンプレミスと AWS の違い
- 他のモバゲーコンポーネントとの AWS アカウントの分離
- ミドルウェアのバージョンアップやマネージドサービスの利用
等によって今まで出来たことが出来なくなり、逆にクラウドに行ったからこそ出来ることが増えた為です。
サービスが継続し続ける限り、運用し続けなければならない為、作業者にとって無理の無いものにする必要があります。
また、システムの構成が変化したり、問題が生じたりした場合も、それらに合わせて運用方法を変える必要が出てきます。
このように、想像力を働かせ、人間にとって無理のない、将来的な拡張や修正を阻害しない仕組みを考える力 というものも IT 基盤部では求められます。
クラウド移行中に発生した問題の調査と再発防止策の検討
続いて、DeNA で未知の問題や障害に直面した際に行うことや IT 基盤部で求められることについて説明します。
クラウド移行中に発生した問題

モバゲーのクラウド移行の終盤、オンプレミスからクラウドにトラフィックの向き先を切り替えたタイミングで EC2 上で稼働している Memcached, Redis 全台に急に接続できなくなるという問題が発生しました。
サーバリソースは潤沢で、CPU, Memory 共に余裕のある状態でした。
当時は原因が不明だったため、即座にオンプレミスに切り戻し、サポートケースを切って AWS に調査をお願いしました。
調査していただいた結果、原因は「 Security group の connection tracking (接続追跡) の上限 に引っかかってしまっていた」というものでした。 このセキュリティグループの接続追跡は無限に行えるものではなく、上限があるそうです。 この上限に引っかかるとその EC2 インスタンスへのあらゆる通信が一時的に行えなくなります。
しかし、この接続追跡の具体的な仕様は非公開で、接続追跡の現在値(接続追跡数)や上限値も不明です。
さらに、問題が起こった当時は、接続追跡数が上限に引っかかったことを検知する術もありませんでした。
現在は、
Monitor network performance
という仕組みで、接続追跡数が上限値に引っかかっているかどうかは確認することが出来るようになっています。

サポートケースで、セキュリティグループを利用しない構成への変更というワークアラウンドを提示していただけましたが、 モバゲーのインフラ構成を大きく変更させる必要があり、クラウド移行期間中の実施は不可能と判断し断念しました。
しかし、この接続追跡数の問題が解消しないことには安全にクラウド移行を進められないため、 接続追跡数の仕様と現在値を知り、上限に近づいていることを検知する仕組みの導入がクラウド移行のブロッカーとなりました。
そこで、私達は接続追跡数と相関のある観測可能なパラメータの調査を行い、擬似的に接続追跡数を監視する仕組みを作成しました。 また、接続追跡数は他のクラウド環境でも起こりうる問題だったため、 モバゲー固有の機能としてではなく、他のインフラ環境でも利用可能な監視方法にしました。
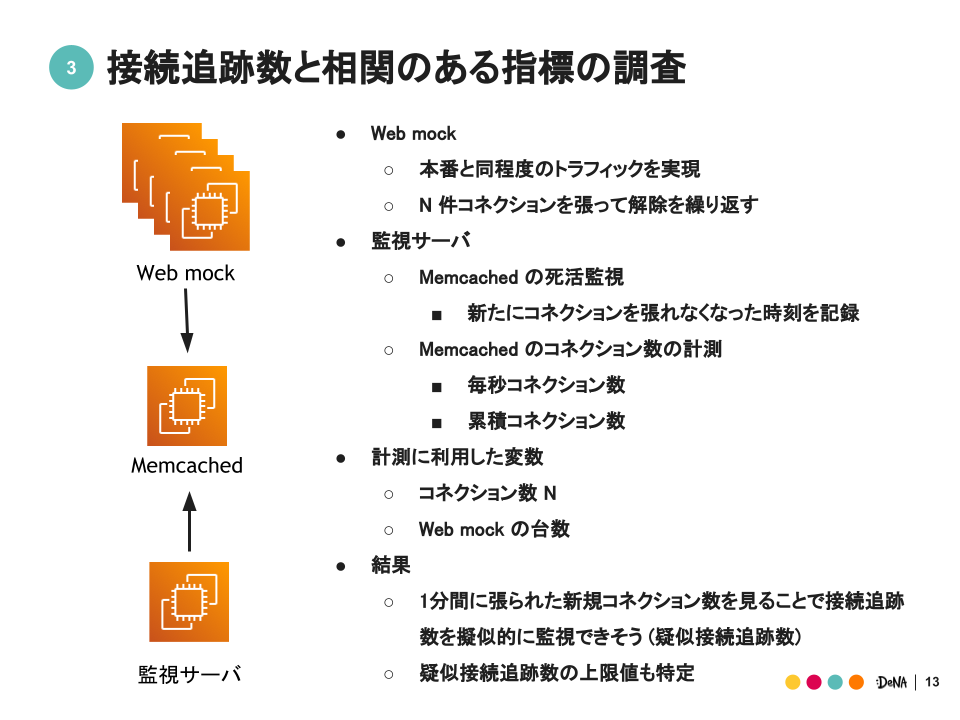
では具体的に私達がどうやって接続追跡数と相関のあるパラメータを特定したかについて説明します。
実験環境として上図のような環境を用意しました。
Web mock と Memcached は実際に問題が起きた時と同じ状況を再現しています。
本番と同程度のトラフィックを準備するため Web mock は複数台用意しています。
Web mock から memcached に n 件コネクションを張ったら解除する、というのをひたすら繰り返してもらいます。
監視サーバは下記の2つの役割を持っています。
- Memcached の死活監視
- Memcached に張られているコネクション数の計測
コネクション数は /proc/net/snmp の ActiveOpens と PassiveOpens から確認できます。
実際に Web mock から Memcached に貼るコネクションの数や、Web mock の台数を変えながら計測結果を確認すると、 変数をどのように変えても1分間に貼られた新規コネクション数が一定値になると新たにコネクションが張れなくなることに気付きました。 インスタンスタイプを変えて実験した場合も、同じく1分間の新規コネクション数が一定になると接続できなくなりました。 これによりコネクションが張れなくなる値、擬似的な接続追跡数の上限値を特定できました。
1分間に張られた新規コネクション数を見ることで接続追跡数を擬似的に監視できそうです。私達はこれを疑似接続追跡数と呼んでいます。

次に現在、実際に DeNA のサーバで動いている監視バッチの詳細を説明します。
事前準備として EC2 上で稼働する全てのサーバで毎秒 netstat の値を記録するデーモンを稼働させました。
監視バッチは 10 分おきにデーモンのログを取得し、そのログから直近 10 分間での疑似接続追跡数の最大値を計算します。
疑似接続追跡数が上限値に近づいていたらアラートが飛ぶ、という仕組みです。
再度お伝えしますが、この監視は接続追跡数の監視ではなく、疑似接続追跡数の監視となります。 実際の接続追跡数の仕様は不明で他にも隠れたパラメータが存在する可能性があります。 そこで、問題が万が一発生した場合は早期に検知し、問題を最小限に抑えられるように一部スペックの小さいカナリアサーバをサービスインしています。 これは疑似接続追跡数の上限がインスタンススペックに比例して増えるという仕様を利用しています。
実績として、この監視を導入してから現時点まで接続追跡数関連の障害は0に抑えられています。
IT 基盤部ではこういった未知の問題や障害の調査をすることは珍しくありません。
そのため事象を根気強く観察する力や得られた情報から自分なりの答えを導き出す力等が求められます。
得られたスキルや気付き
最後に私が今までの IT 基盤部の業務で得られたスキルや気付きをお伝えします。

まず一番大きく変わった部分は 事象に対する向き合い方 です。
前章でお伝えした通り、IT 基盤部では未知の問題に多く直面します。
また、インフラエンジニアは強力な管理者権限を持っているため、出来ることやその影響度合いも大きいです。
雑な作業を行ってステークホルダーに影響を与えたりするとあっという間に信頼を失います。時には1つのミスが会社に大きな損害を与えることだってあります。
こういった環境に身を置くことで、「他者の言うことを鵜呑みにせず裏取りを行う」「前提を疑う」といった習慣が付きました。

2つ目の大きな変化はレガシーなシステムに対する苦手意識の解消です。
巷では下記のようなレガシーシステムに対する意見をよく聞きます。
- 学びがない・将来役に立たない
- レガシーシステムに関わらなくても良い
- レガシーシステムの運用は辛い
これらの意見に対して私はこう考えるようになりました。
- 学びがない・将来役に立たない
これは No だと思います。
レガシーシステムの運用を通して、動き続けるシステムを作るために必要な知識を学べるからです。
モバゲーは 2006 年から続くゲームプラットフォームで、機能追加・脆弱性対応・EOL 対応・人の入れ替わり等、様々な問題を経て今も動き続けているシステムです。 そのモバゲーの運用改善を行うことで、システムへの深い理解、高いシステム設計力、トラブルシューティング能力が身に付きます。
- レガシーシステムに関わらなくても良い
こちらに関しても No だと思っています。
長いエンジニア人生、レガシーシステムと一度も関わらずに過ごすことはおそらく不可能だからです。
現時点で新しい技術を使ってシステムを構築したとしても、それらはいずれレガシーシステムになります。
一応、「新しいものを作って転職」を繰り返すことで回避することは可能ですが、それだと前述の 動き続けるシステム に触れることができません。
- レガシーシステムの運用は辛い
はい、辛いです。
私も配属当初は折り合いをつけるのに苦労しました。
ただ実際にモバゲーというサービスを利用しているユーザがたくさんいること。
また、モバゲー運用の辛さや重要性を上長やマネージャ陣が理解しており、最終的には評価として返ってくること。
レガシーシステムの運用改善で得られる経験やスキルが自分の今後のキャリアにとってプラスになること。
これらを理解したことである程度は不満なく働けるようになりました。
おわりに

今回お伝えした内容をまとめると
1.経験の有無に関わらずチャレンジングなタスクがアサインされます。
本人のやる気があればグループや部署、会社の垣根を超えた仕事も可能です。
2.動き続けるシステムを作る能力が身に付きます。
IT 基盤部では日々以下のような能力が求められます。
- 期日までに移行を完遂させる計画性
- 作業の進捗を可視化し、管理者が管理しやすい状態を作る能力
- 現状を維持するだけでなく改善し続ける力
- 人間にとって無理のない、将来的な拡張や修正を阻害しない仕組みを考える力
こういった環境に身を置くことでこれらの能力は飛躍的に伸びます。
3.事象への向き合い方が変わります
DeNA では日々未知の問題や障害に直面します。
これらの問題に対して正面から立ち向かうことで 事象を根気強く観察する力 や 得られた情報から自分なりの答えを導き出す力 を磨くことが出来ます。
4.レガシーシステムに対する苦手意識解消の手助けになる
DeNA は レガシーシステムがユーザに必要とされていることやレガシーシステムの運用改善を通して得られるスキルがあることを実感できる環境です。
また、マネージャ陣がレガシーシステムの重要性や運用のツラミを理解しており、最終的には評価として返ってくる環境でもあります。
本記事が、インフラ・SRE に興味のある方たちの参考になれば幸いです。
最後までお読みいただき、ありがとうございました。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。