





はじめに
インフラエンジニアの天野です。
DeNA Advent Calendar 2021 の1日目として、ここでは DeNA TechCon 2021 Autumn で登壇させていただいた、「数百 shard のデータベース運用を最適化する手法」についてお話していきます。
録画は冒頭に挙げた YouTube に上がっていますので、よろしければそちらもご覧ください。スライドは以下にございます。
DeNA では様々なインフラの運用を自動化してきましたが、データベースの運用にはまだ一定の工数がかかっています。 ここでは、大規模ゲームを例に、DeNA が今まで取り組んできたデータベースの運用最適化の手法について紹介していきます。
大規模ゲームにおけるデータベースの特徴
- MySQL 互換
- リリース直後の膨大なリクエストを捌くために数百 shard の水平分割
- 台数が増えると故障台数も増えて運用負担
- リリース後の負荷が落ち着いてから、shard 統合とコスト最適化
- IOPS 性能が求められるストレージ
- 新機能実装の度に必要なクエリ最適化
- 大型イベントの度に発生するスペック調整
世間から期待されるゲームタイトルですと、リリース直後はアクセスが殺到し膨大なリクエスト数が来るため、データベースに大きな負荷がかかります。 オンラインゲームでは、常にユーザのセーブデータをサーバ側で保存しながらプレイが進行するため、データベースの負荷は高くなります。 それを捌くために水平分割を行いますが、しばらくするとリクエスト数は落ち着いてくるため、分割した多数のデータベースの維持コストが負担となってきます。そのために shard の統合が必要となります。
shard 統合後であっても、依然として多数のデータベースサーバを並べているため、故障する台数も多くなり、運用負担は高いです。
さらに、イベントや大型アップデートのタイミングでリクエスト数が大きく上昇するため、スペックアップが必要になることもあります。
そのため、以下のような要件が必要となってきます。
- 低コスト低スペックなサーバと、高コスト高スペックなサーバを自由に切り替えたい
- 様々な運用を自動化したい
- 自由に shard 統合と分割をしたい
この問題を解決するために、私たちは以下のようなアプローチを行ってきました。
第一世代システム
まず最初に行ったのは、内製のスクリプトによる様々な運用自動化です。
Slave 故障時は自動的に切り離し
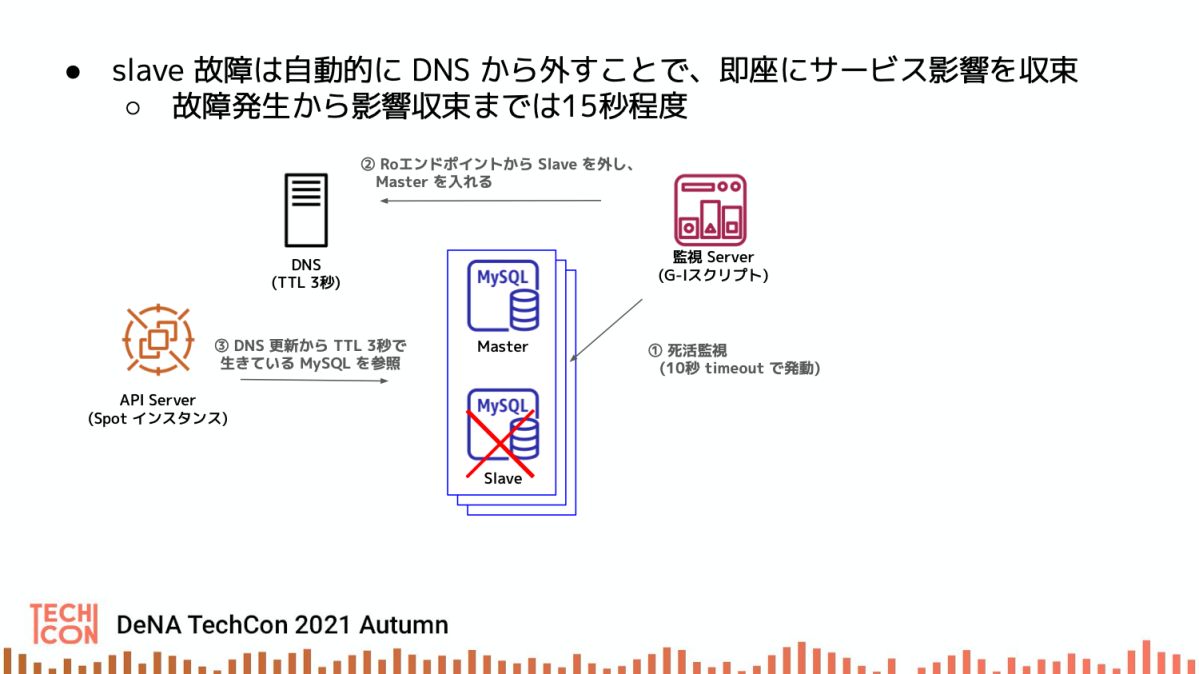
Slave サーバが死んだときは10秒の timeout で該当サーバを DNS から切り離し、代替エンドポイントに切り替えることで、サービスを継続しています。
最大でも15秒程度でサービス影響は収束するため、プレイ中のユーザ体験としては、「エラーが発生したが、もう一度やり直したら問題なく進行できた」ということになり、致命的なことにはなりません。
この仕組みでは DNS レコードの更新が即座に行われる必要があり、それは Amazon Route 53 等のマネージド DNS では実現できないため、自前で DNS サーバを立てて運用しています。
Master 故障時は MHA による自動 Failover
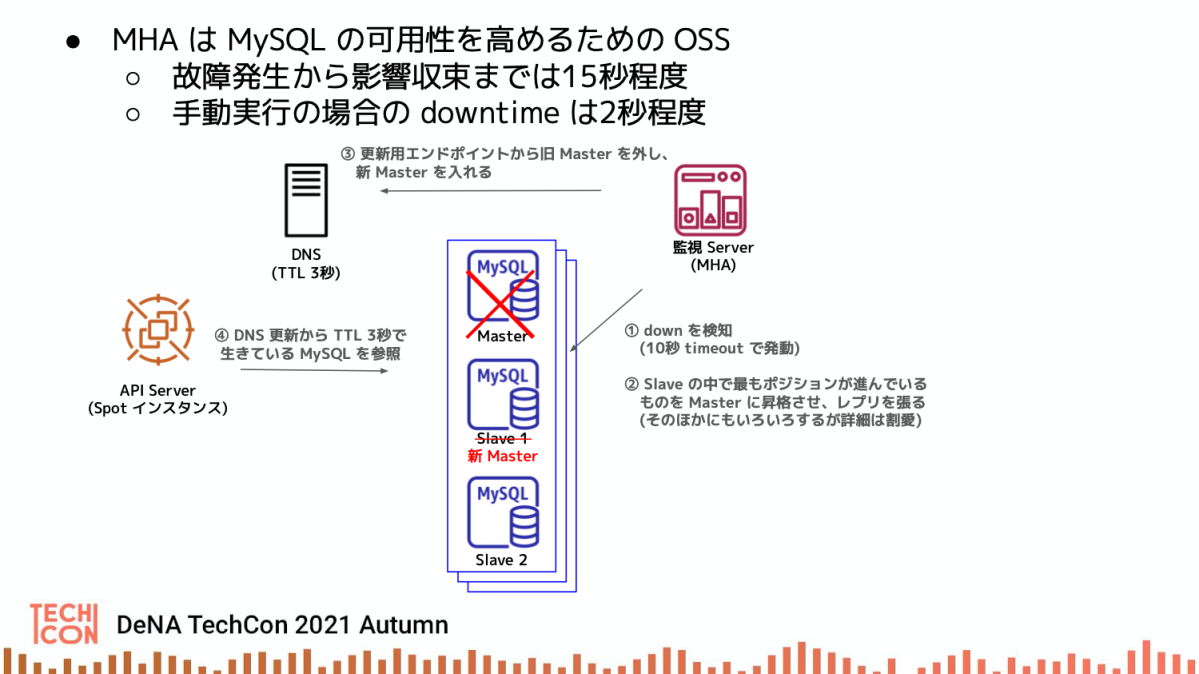
Master 故障時も自動で Failover することでユーザ体験を損なわないようにしています。 Failover には MHA という仕組みを用いています。
MHA は手動で Failover を実行した場合は、ほぼ2秒以内の断時間で切り替わるのでユーザにほとんど影響を出しません。 これを利用すれば、スペックの異なる Slave を準備して切り替えることでスペックアップも行えます。ユーザ影響はほとんどないので、サービス中断を告知する事無しにサーバのスペック変更が行えるため、要件1の自由なスペック変更を満たすことができます。
Slave はコマンド1つで自動複製
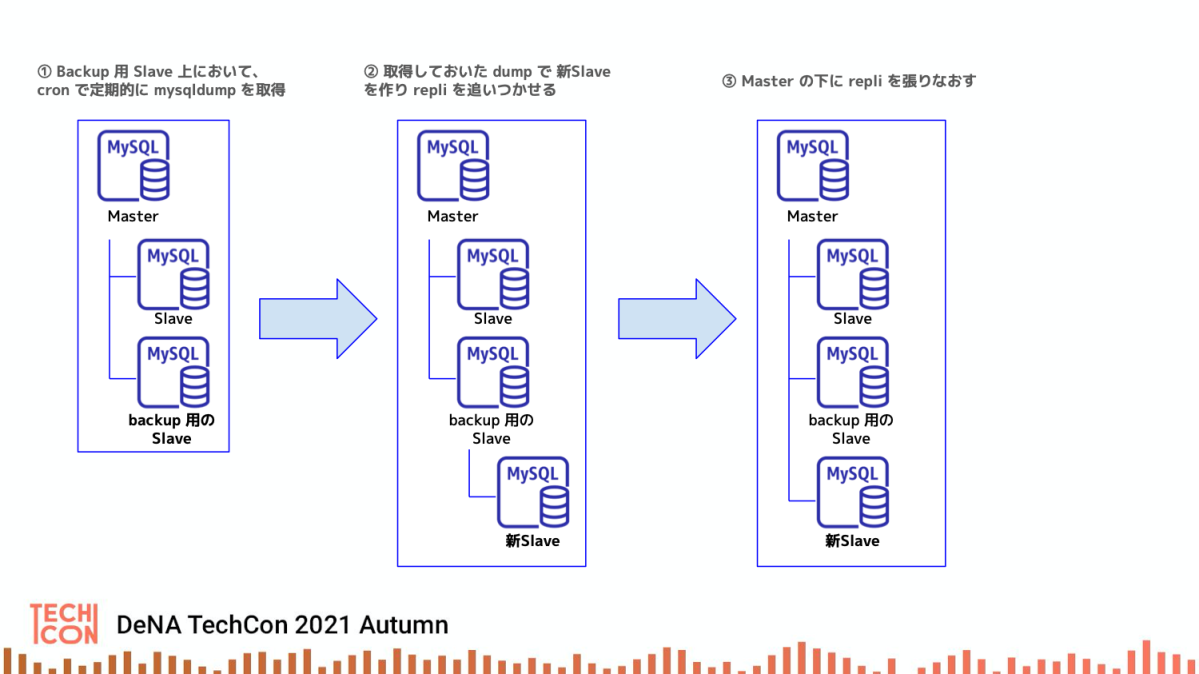
故障したデータベースサーバは、代替機を準備する必要があります。DeNA では一度故障したデータベースはレプリケーションの整合性を保証できないため、基本的には再利用せずに、破棄しています。
そのために、オペレータがコマンドを1つ投入するだけで、代替機を構築できるような仕組みを作り込んでいます。
処理内容としては、毎日 mysqldump を取得しておき、それを代替機に流し込んで replication を追いつかせた後に Master にぶら下げ直すということをしています。mysqldump を取得するサーバには大きな負荷がかかるので、低遅延な参照が必要な slave サーバとは別に準備しています。
コマンド1つで複製とはしていますが、故障後にすぐに代替機構築に移って良いかは、データベースの壊れ方により対処が異なるため、完全自動化は行わずにオペレータへ判断を委ねています。
これらにて要件2である各種処理の自動化に努めています。
マルチインスタンスによる shard 統合
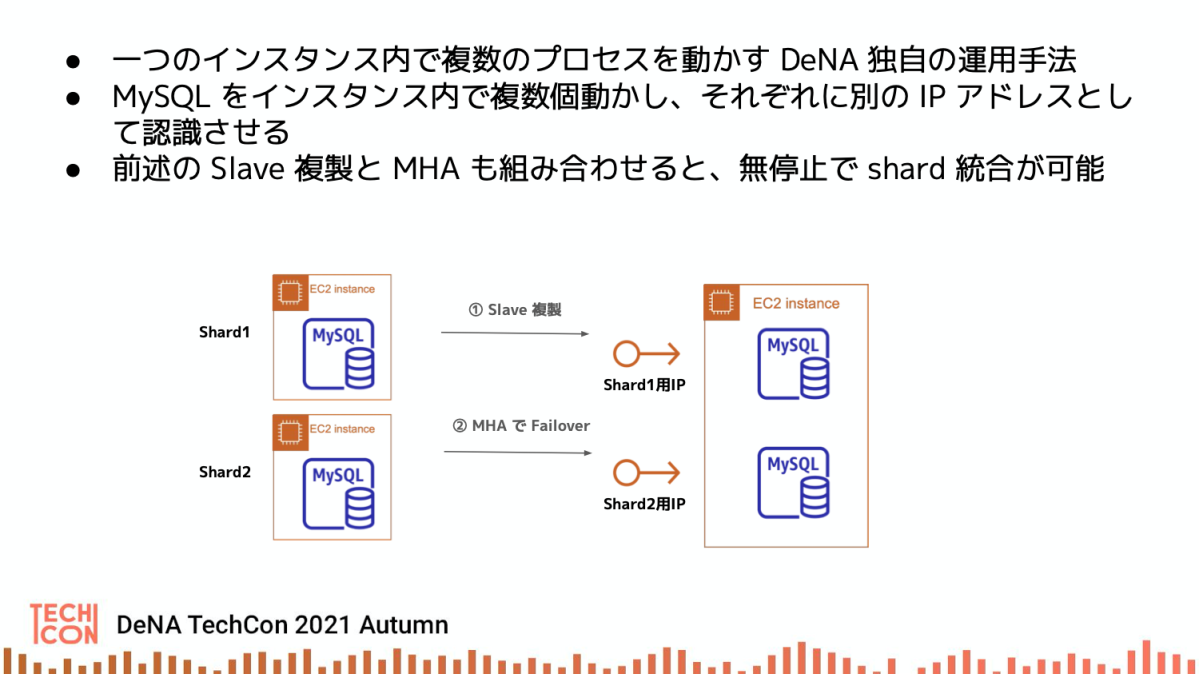
以前にこちらのブログでも紹介させていただいた、オンラインでの無停止 shard 統合の手法です。
-> MySQLサーバのMulti Instance化によるコスト最適化方法
マルチインスタンスとは、MySQL のプロセス自体を一つのサーバ内に複数配置して、それぞれに別のIPアドレスを付与することで、あたかも複数の MySQL が1台のサーバで動いているかのようにみせる DeNA 独自の手法です。
先ほどの、自動複製ツールもこの手法に対応させているので、マルチインスタンスも1コマンドで作れるようにしています。その後に、MHA で Master を切り替えれば、要件3の自由な shard 統合と分割が可能となります。
第一世代システムの問題点
- 故障時には手動介入が必要
- 故障の仕方によって状況はいろいろであり、判断を挟む必要がある
- そのため、故障対応の完全自動化には至っていない
- ゲームイベント毎にサーバのスペック変更が面倒
- 運悪く同じホストに載っていて、同時多発的に故障する場合もある
故障時に手動介入が必要となることが運用負担となっています。
低コストを追求しようとすれば、データベースサーバのスペックを頻繁に調整せねばならず、その対応工数も大変です。
また、我々はデータベースサーバに AWS の i3 や i3en タイプのインスタンスを使用するのですが、これらのインスタンスは利用者数が少ない為か、同一ホストコンピュータ上に我々の複数のインスタンスが乗るケースがあるようで、1台のホスト故障で複数台のインスタンスが故障してしまい、対応が忙しくなるというケースもありました。
第二世代システム
- Aurora MySQL 5.7
- さすがに数百 shard を運用するのはキツかったのでマネージドを導入
- shard 統合は停止メンテ
- IaaS 同様に1コマンドでいろいろ可能な便利スクリプト群を整備
- 独自の Aurora 高速 Failover
- 元々20秒程度の downtime だったものを 5秒程度に短縮
とあるゲームタイトルにおいて、既存の2倍以上の shard 数を準備する必要があったことから、故障対応の完全自動化を求めて AWS の Aurora を採用しました。
故障時の対応は AWS が マネージドで全て実施してくれるため、その点は大きく改善されました。shard統合時は、停止メンテナンスを入れて対応することで、妥協しています。
独自の Aurora 高速 Failover
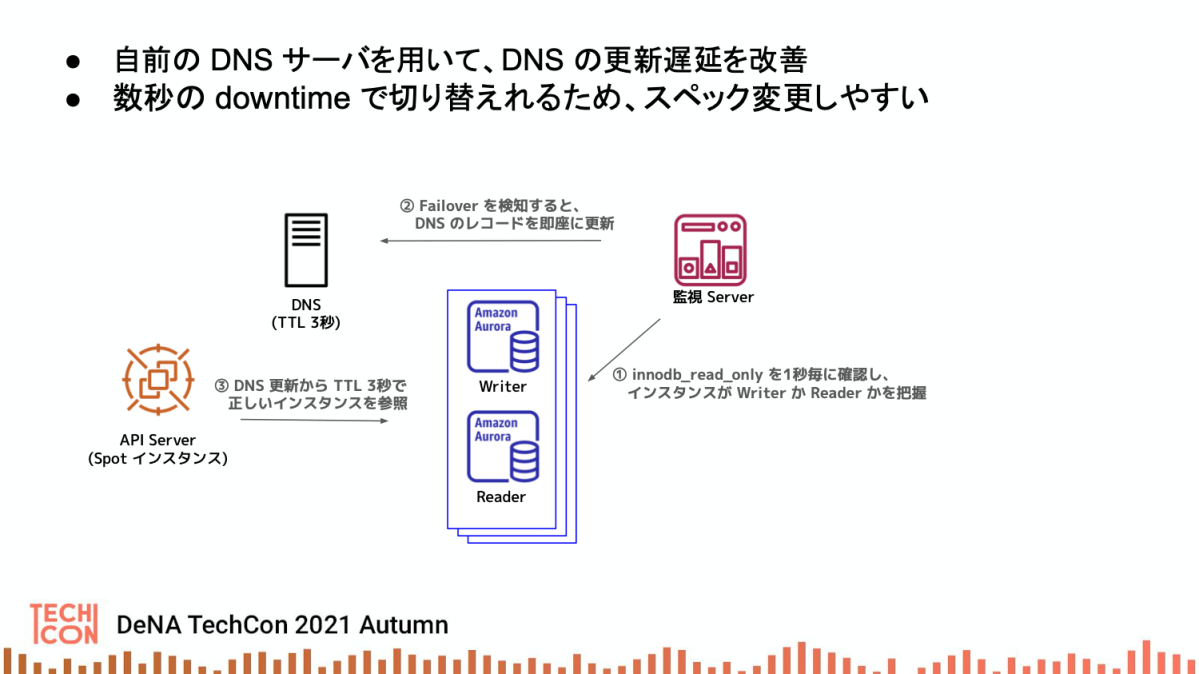
Aurora のインスタンスタイプ変更は、目的とするスペックの Reader を立てて Failover させることで、最小限の影響時間で切り替えることが可能です。
通常の手動 Failover は 20〜30秒程度の断時間が発生するのですが、ユーザへの影響を少なくして、もっと手軽に Failover できるようにしたいと考えました。 そこでこの仕組みを入れることで Failover 時の断時間を数秒にまで短縮させています。
詳細はこちらのブログでも説明していますので、よければご覧ください。
-> Auroraの高速フェイルオーバーと無停止での切り替え
第二世代の問題点
- コストが高い
- ゲームイベント毎に DB インスタンスのサイズ変更は面倒
- shard 統合が気楽にできない
- AWS にベンダーロックインされる
Aurora にも問題点はあります。
一つは、やはり IaaS に比べるとコストが高いことです。
イベントの度にインスタンスタイプを変更して回るのも、手間となっています。
現在検討中の次世代システムの候補
そこで現在は、Aurora Serverless v2 と TiDB に期待しています。
Aurora Serverless v2
- インスタンスの CPU とメモリが自動でスケールアップ・ダウン
- スケーリングは瞬時に行われる
- 同じリソースを使う場合は既存の Aurora より割高
- 可用性は既存の Aurora と同程度(らしい)
- 故障時は既存の Aurora と同じく Failover もする(らしい)
- 既存のAurora MySQL からの移行は簡単(だろう)
Aurora Serverless v2 はこの記事の執筆段階(2021/12/1時点)ではまだリリースされていませんが、インスタンスのスケーリングがミリ秒のオーダーで瞬時に行われるとのことなので、現在の Aurora 運用の懸念点となっていたタイプ変更が面倒な問題の解決が期待できます。 リリースされて使えるようになることが待ち遠しいですね。
TiDB
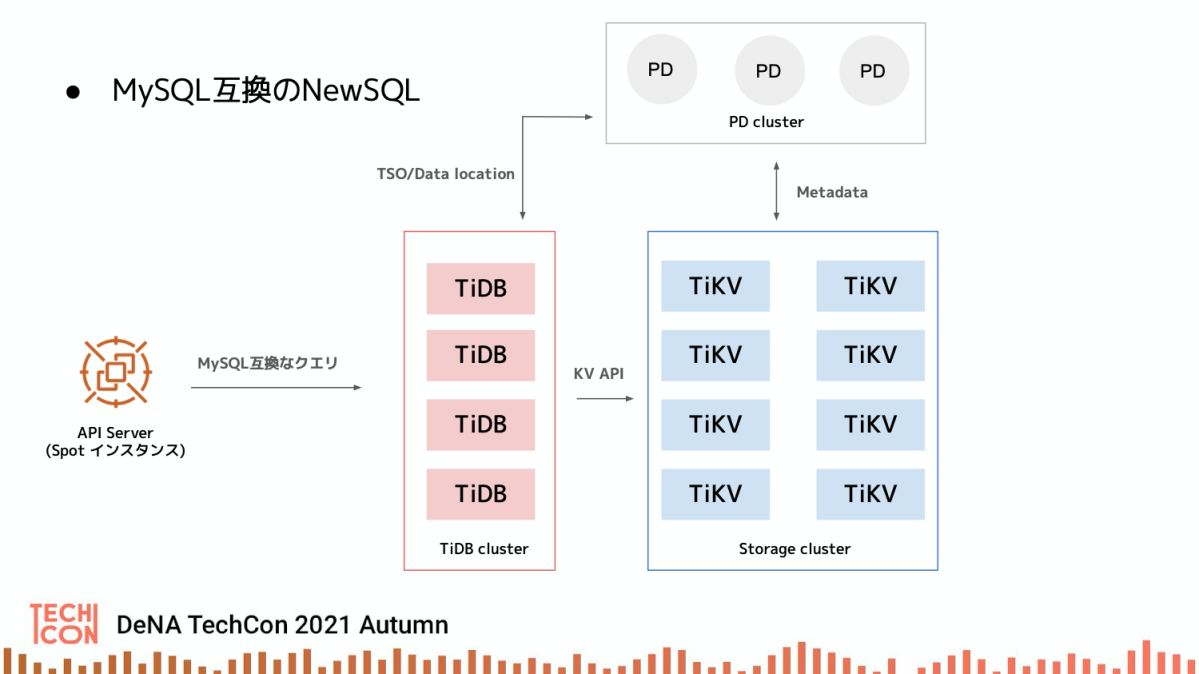
TiDB は MySQL との互換性が高い NewSQL のデータベースであり、主に3つのコンポーネントから構成されています。
- Key-Value でデータを格納する TiKV
- MySQL 構文を処理して TiKV にアクセスする TiDB
- それらのメタデータを管理する PD
これを使えば様々な問題が解決できそうに思えており、検証を進めています。
検証結果は、 2021/12/15 に開催する DeNA インフラエンジニア / SRE MEET UP#3 のオンラインイベントで、発表する予定ですので、よろしければご視聴をお願いします。
終わりに
今回は DeNA のインフラチームが考えてきたデータベース運用の最適化手法についてご紹介させていただきました。
今後もさらなる利便性とユーザ体験の両立を目指して、改善していきたいと思います。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。