





リアルタイム音声変換
こんにちは、AIシステム部の橘と申します。本記事では、 TechCon で講演予定でした、エンタメ活用へ向けたAIによる音声生成のPart2として、音声変換についてご紹介します。 Part1の音声合成については こちら をご覧ください。
サンプル音声・デモは以下になります。
目次
背景
音声合成のパートでもあったように、近年、音声技術の発展が急速に進展しており、様々なアプリケーションで用いられてきています。

音声技術を用いたのアプリケーション例
スマートスピーカを例に取ってみても、音声認識、音声対話、音声生成など複数の音声技術を組み合わせることで実現されています。
DeNAでは音声技術の中でも、エンタメ・ゲームといったDeNAの事業領域と相性の良い音声生成技術(音声合成・変換)にフォーカスし、技術開発に取り組んでいます。
以降は、音声変換の仕組みとDeNAでの取り組みについてご紹介します。
音声変換とは?
音声変換とは、発話の内容を変えず、声を任意の声に変換する技術です。男性や女性、様々な声に変換することが出来ます。
音声合成はテキストから音声を生成しますが、音声変換は音声から音声を作り出す技術になります。
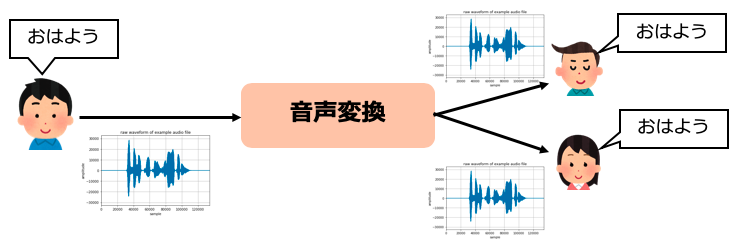
音声変換の概要
音声変換の応用先
音声変換には以下のような応用例が挙げられます。

音声変換の応用先
代表的な応用先としての動画・音声コンテンツ配信でのバーチャルキャラ向けや、配信者の匿名化を目的とした利用から、その他にもテーマパークなどのショーの吹き替え、カラオケでの歌手本人になりきり、ラジオアナウンサーの代役などが挙げられます。
DeNAでは
SHOWROOM
、
pococha
など動画のライブ配信に力を入れています。
これらの事業と音声変換とを組み合わせることにより、新たなシナジーが期待できます。
DeNAでの音声変換の取り組み
続いて、DeNAでの音声変化の取り組みについて、3つの項目に分けて紹介します。
- ライブ配信事業 x 音声変換のシナジー
- 誰の声でも目標とする人の声に変換するシステムの開発
- iPhone向けリアルタイム音声変換システムの開発
1. ライブ配信事業 x 音声変換のシナジー
SHOWROOMでは、iOS向けに SHOWROOM V と言うサービスを展開しています。 これは、スマートフォン1台だけで手軽に誰でも今すぐに、バーチャルキャラクターになれるサービスです。 バーチャルキャラクターになりきって、動画のライブ配信を行うことが出来ます。
しかしSHOWROOM Vに限らず、スマートフォン向けのライブ配信アプリのほとんどが、音声変換機能は未搭載であり、現状多くの配信者は自身の声で配信しています。 そのため、音声変換を利用する場合は、別途アプリや専用機器を用意する必要があります。 この準備の敷居の高さゆえ、スマートフォンでのライブ配信で音声変換を利用するためのコストが高くなってしまいます。
以下では、スマートフォンでのライブ配信に焦点を当て、それに向けた音声変換システムの開発について紹介します。
スマートフォンでのライブ配信に向けた音声変換システムの開発
バーチャルキャラクターを使った動画配信について、現状よく見られる音声とキャラクターの組み合わせは以下のような表でまとめることが出来ます。

配信者・バーチャルキャラクターの性別の違いによる音声の配信状況
今回は、この中でも音声変換のよく利用される配信者が男性、バーチャルキャラクターが女性といった異性の組み合わせに着目します。
先述の通り、ライブ配信アプリに音声変換機能が搭載されているケースはほとんどなく、音声変換を利用する場合、別途アプリや専用機器を利用する必要があります。 加えて、有力アプリはPC向けソフトや専用機器であるため、ユーザとしてこれらの音声変換アプリをライブ配信に利用するとなると、PCや専用機器とスマートフォンとの連携が必要となり、準備コストが高くなってしまいます。 また開発者としては、これらのシステムをライブ配信アプリに組み込むとなった場合、既存システムの改修が必要となるため、開発コストの増加に繋がります。
そこで、ユーザ、開発者にフレンドリーなシステムとして、スマートフォンで利用でき、plugin形式で気軽に導入しやすいシステムを開発することを目指します。
下記に、目指す音声変換システムの構成例を示します。
スマートフォン上で音声変換処理を実行することにより、既存システムでも簡易に導入出来ることを狙っています。
このシステムをSHOWROOMと連携し、SHOWROOM Vへ組み込めるよう、開発を進めています。
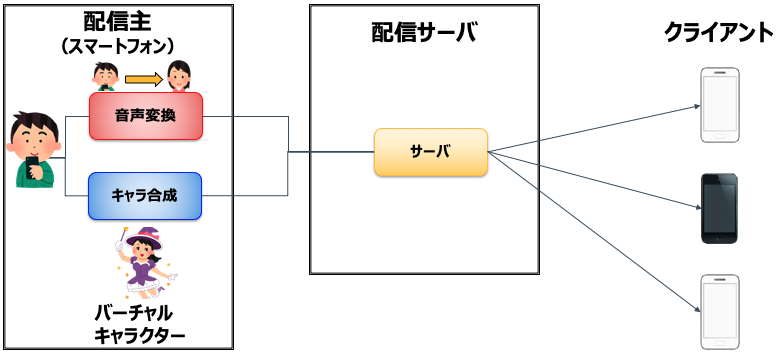
配信アプリへの音声変換システム組み込みの構成例
2. 誰の声でも目標とする人の声に変換するシステムの開発
適用先として、バーチャルキャラクターを用いたライブ配信サービスを想定し、気軽にスマートフォンで利用できることを目指して、音声変換システムを開発いたしました。 その内容について紹介します。
音声の調整手順
以下に音声変換の処理の概要を示します。
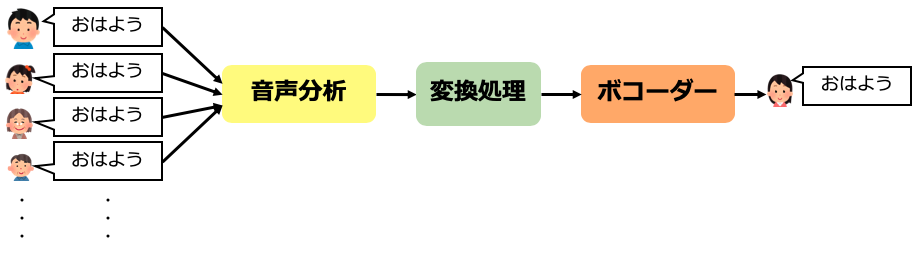
音声合成と同じく大きく3つのモジュールで構成されます。
入力された音声を分析し、特徴量を抽出する音声分析部、その後、特徴量に変換処理を行う変換処理部と、最後に変換された音響特徴量から音声を生成するボコーダーです。
変換処理部で、どのような調整により、音声が変換されるかを説明します。
まず音声分析部で、音声をスペクトル包絡とF0と言う音響特徴量に分解されます。
ここで、スペクトル包絡は声質を表し、話者の声の特徴を、F0は声の高さを表し、イントネーションや言い回しを示します。
スペクトル包絡を制御することで声を太くしたり、細くしたり、F0を制御することで、声を高くしたり、細くしたりできます。
調整した音響特徴量にボコーダーを適用することで、変換された音声が生成されます。
ボコーダーはOSSである
WORLD
[1, 2]を用いています。
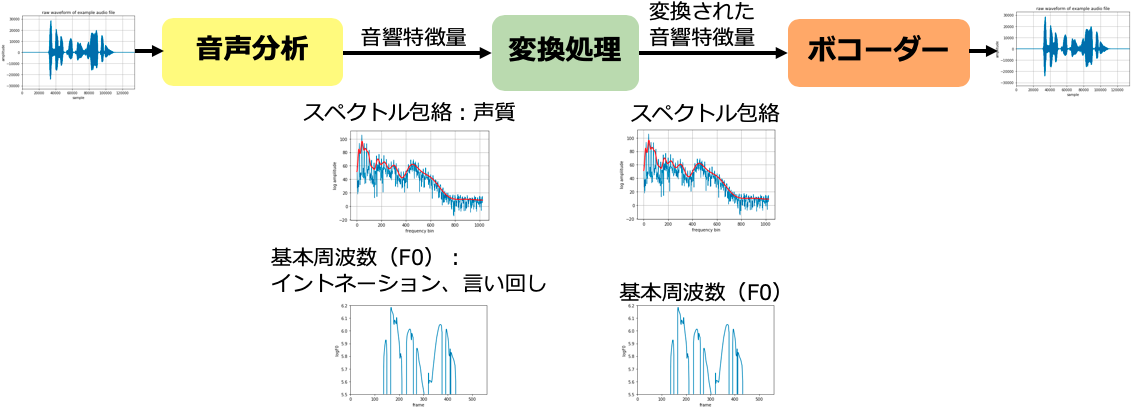
音声の調整手順
以下に調整した場合の音声をサンプルを示します。
原音
声を細く
声を太く
声を高く
声を低く
目標話者への音声変換は、スペクトル包絡とF0を目標話者のものに変換することで実現されます。 目標話者を複数用意することで、希望する音声に変換することでき、またこの音響特徴量ごとに変換する話者を変えることもでき、声質はAさん、声の高さはBさんといったことも可能となります。 さらに、変換された音響特徴量を調整することができ、自分好みにカスタマイズすることも出来ます。
一般的に変換処理を行うために、機械学習モデルが用いられます。 機械学習モデルは元の話者から目標話者への音響特徴量の対応づけを学習します。 我々のシステムでもディープラーニングを利用して学習したモデルを用いています。
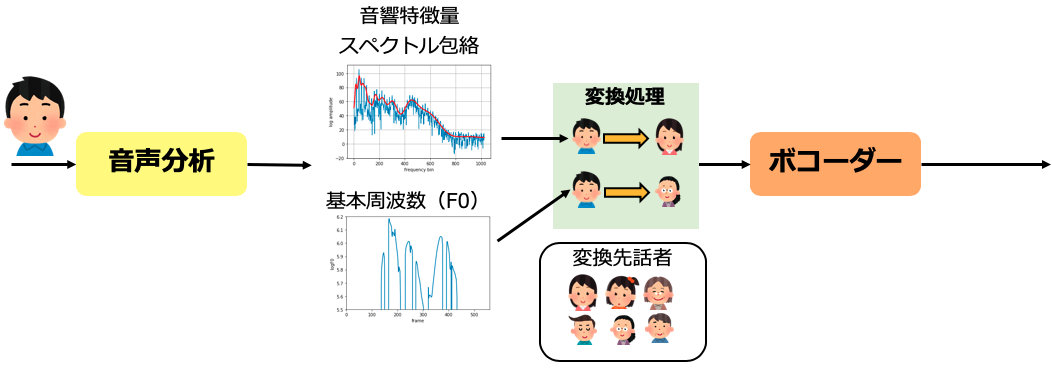
音声変換の処理フロー
目標話者の声への変換手法
元話者から目標話者の声へと変換する手法は、下図のように、大きく分けて2種類が提案されています。
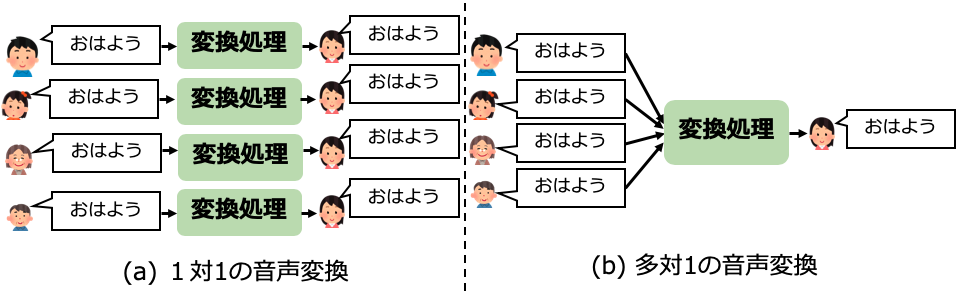
(a)の1対1の音声変換は、元話者ごとに変換処理を行う手法で、音声変換の主流となっている手法です。 元話者から目標話者と同じ発話内容を収録し、その音声の対応づけを学習します。 Voice Transformer Network [3]や AttS2S-VC [4]など非常に高品質な変換手法が提案されています。
1対1の音声変換の課題
1対1の音声変換には以下のような課題が挙げられます。
-
元話者の収録音声が必要
元話者と目標話者の対応づけを学習するため、元話者の音声が必要となってきます。 -
その場で変換モデルを作成する必要
元話者ごとに変換モデルが必要となるため、元話者の音声収録後に変換モデルを作成する必要があります。 -
変換モデルが元話者ごとに必要
元話者ごとに作成するコストや変換モデルの管理、運用といったことも必要となります。
これらの課題について開発者視点でみてみますと、音声ペア作成のための事前収録のために、システムが改修であり、またアプリの操作手順も複雑化します。 次に、上述したように変換モデルをユーザごとに作成する必要があるため、変換モデルごとの作成するコストが発生し、またそれらを管理・運用するコストも必要になってきます。 以上により、既存システムへの音声変換の導入コストが上がってしまいます。
多対1の音声変換の利点
(b)の多対1の音声変換は、 Sunら の手法[5]や、Liuらの手法[6]が代表的手法として挙げられます。 こちらは、一つの変換モデルで、複数話者の入力に対応することができ、元話者の収録を一切必要としません。 一方で、変換モデルの学習コストが高くなることが課題として挙げられますが、事前に変換モデルを作成することが出来るため、音声変換時には問題にはなりません。
今回の用途では、システム改修のコストやライブ配信向けのためユーザが多様であることに鑑み、(b)の多対1の音声変換手法をベースに開発を進めました。
開発手法:誰の声でも目標話者の声に変換できる音声変換
ライブ配信アプリでは、性別・年齢など配信主の特性は多様であることが想定されるため、下図のように誰にでも適用可能で、誰でも目標とする話者に変換できるシステムを目指しました。
目指す音声変換システム
ベースラインの手法では、どんな話者からの入力にも対応するため、一度入力音声をある特徴量で共通化し、その共通化された特徴量から目標話者の声の特徴量を生成するようにしました。 こうすることで、どんな話者の音声も目標の話者の音声に変換することを可能としました。 それでは、変換処理の手順に説明します。
1. 変換モデルの学習
変換処理は、ディープラーニングを用いて学習した変換モデルを適用することで行われます。 変換モデルは2つのモデルから構成されます。 1つは入力音声を共通化するためのモデル、もう一つが共通化された特徴量から目標話者の音響特徴量を生成するモデルです。 これらの2つのモデルは別々に学習され、最後に学習モデルを連結することで、どんな話者の入力も目標の話者の声に変換することが出来ます。
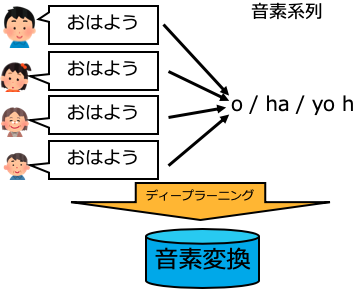
1.1 入力音声の共通化
入力を共通化するために、入力音声を音素の系列に変換します。音素とは、音の区切りを示す単位です。
日本語では、母音(/a/、/i/、/u/、/e/、/o/)、子音(/k/、/s/、/j/など)を1つの音素とします。
例えば「おはよう」は「/o/h/a/y/oh」といった音素系列に変換できます。
音声を音素系列に変換することで、どんな話者の音声であっても、音素に共通化することが出来ます。
ここで音素変換モデルは、大量の話者の音声データと音素系列との対応づけを学習します。
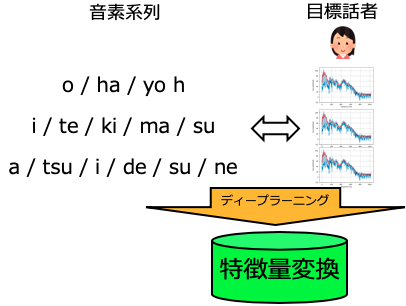
1.2 音素系列から目標話者の特徴量を生成
音素変換モデルとは別に、音素系列から目標話者の音響特徴量を生成するモデルを学習します。 音響特徴量は、スペクトル包絡のみを対象する場合[5]、スペクトル包絡とF0を対象とする場合[6]があります。
2. 音声の変換
音声を変換する際は、1.で作成した変換モデルを下図のように、入力音声に適用することで、変換音声を生成します。 以下の図は、我々の手法のベースとなっているSunらの手法の変換手順を示しています。 Sunらの手法では、音素系列からF0を生成しないため、F0は元話者の平均と分散が目標話者のものになるように線形変換処理を適用したものを用いています。
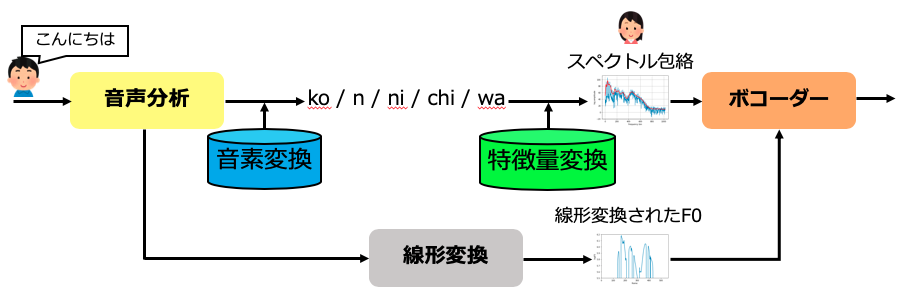
このような仕組みで、誰が話しても、目標とする話者の音声に変換することが可能となります。
3. 既存手法からの改良
我々はSunらの手法をベースに以下の改善に取り組みました。
-
日本語への適用
日本語コーパスを用いて作成しました。音素変換モデル学習にはSpontaneous Speech Corpus of Japanese [7] 、特徴量変換モデル学習には21話者42,000文の音声データを用いています。 -
複数話者化に対応
上記にあるように特徴量変換モデルは、複数話者を混合して学習しています。 音声変換時は目標話者のidを指定することで、指定した目標話者の音声に変換することが出来ます。 -
リアルタイム化のためにディーブラーニングのアーキテクチャを見直し
計算コストの面から、LSTM-RNNベースのネットワークから、CNNベースのものに変更しました。 詳細は [8] をください。 -
音質改善
音質改善の取り組みの一つが、音素変換モデルと特徴量変換モデルに敵対的生成ネットワークの仕組みを導入しました[8]。 また、この手法に更なる改善を加えました。その結果を下記に示します。
サンプル音声
- 元話者が男性
元話者音声
目標話者音声1(男性)
変換音声(男性→男性)
目標話者音声2(女性)
変換音声(男性→女性)
- 元話者が女性
元話者音声
目標話者音声1(男性)
変換音声(女性→男性)
目標話者音声2(女性)
変換音声(女性→女性)
このように、元話者のイントネーションは保持しつつ、声質のみ変換できています。 これらの音声をベースにして、声質や声の高さを調整するで更なるカスタマイズも可能です。
ボコーダー
今回はiPhone実機上での動作を想定しています。そのため、計算リソースはPCやサーバと比較すると非常に限られてものとなってしまいます。
その現実的な制約のもとで、技術選定を行いました。
WaveNet
[9]や
WaveGlow
[10]に代表されるneural vocoderは非常に高音質な音声を生成する反面、計算コストが非常に高いです。
CPUで動作するneural vocoder、
MelGAN
[11]も提案されてきておりますが、リアルタイム音声変換という用途を考えると、まだ計算コスト的には厳しい状況です。
現状のneural vocoderを利用することは難しいと考え、今回はWORLDを用います。
iPhone向けリアルタイム音声変換の開発
開発した音声変換システムをiOS向けに組み込みを行いました。
組み込みまでのフローは下図の様になっています。
iOSから簡単に呼び出せる様、
Unity
のプラグイン形式として、実装しました。
音声分析部とボコーダー(WORLD)はC++でライブラリ化し、それらをUnityから直接呼び出しています。
また、音声変換モデルはディープラーニングフレームワークの一種である
pytorch
で開発しました。
学習済みpytorchのモデルをApple社が提供している機械学習フレームワークの
coreML
の形式に変換し、swiftを経由することで、音声変換モデルをUnityから呼び出してます。
そして、UnityプロジェクトをXcodeに変換し、iOSから呼び出しています。
このように既存のフレームワークを用いて、効率的に開発しました。
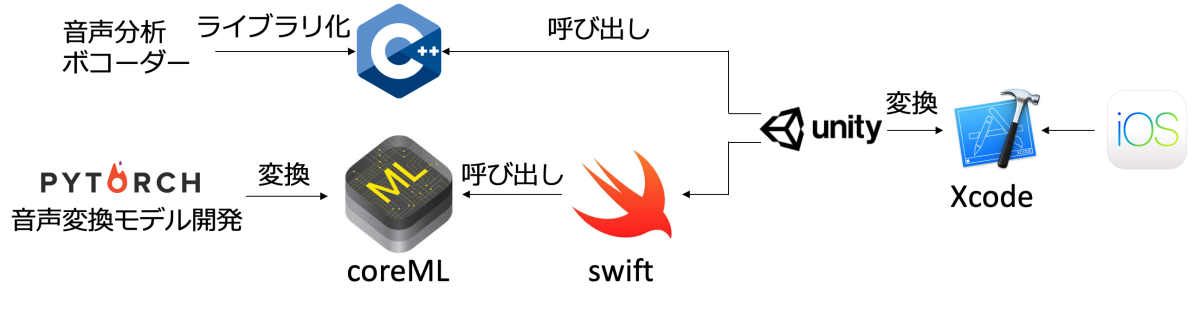
音声変換モデルのiPhone組み込みまでのフロー
リアルタイム音声変換デモ
iPhone上で音声変換システムを動作させたデモになります。
iPhone付属のマイクを使って録音しています。
音声変換のまとめ
- ライブ配信シーンにおける音声変換の利用状況について触れ、DeNAで取り組んでいるスマートフォンでのライブ配信アプリへの音声変換の組み込みについて紹介しました。
- 誰の声でも目標とする人の声に変換するシステムを開発しました。
- 音声変換システムをリアルタイム化し、iPhoneに組み込みました。
参考文献
[1] M. Morise, F. Yokomori, and K. Ozawa, “WORLD: a vocoder-based high-quality speech synthesis system for real-time applications,” IEICE transactions on information and systems, vol. E99-D, no. 7, pp. 1877-1884, 2016.
[2] M. Morise, “D4C, a band-aperiodicity estimator for high-quality speech synthesis,” Speech Communication, vol. 84, pp. 57-65, Nov. 2016.
[3] C. W. Huang, T. Hayashi, Y. C. Wu, H. Kameoka, and T. Toda, “Voice Transformer Network: Sequence-to-Sequence Voice Conversion Using Transformer with Text-to-Speech Pretraining,” arXiv preprint arXiv:1912.06813.
[4] K. Tanaka, H. Kameoka, T. Kaneko, and N. Hojo, “AttS2S-VC: Sequence-to-sequence voice conversion with attention and context preservation mechanisms,” In ICASSP, pp. 6805-6809, May, 2019.
[5] L. Sun, K. Li, H. Wang, S. Kang, and H. Meng, “Phonetic posteriorgrams for many-to-one voice conversion without parallel data training,” IEEE International Conference on Multimedia and Expo (ICME), pp. 1-6, July, 2016.
[6] L. J. Liu, Z. H. Ling, Y. Jiang, M. Zhou, and L. R. Dai, “WaveNet Vocoder with Limited Training Data for Voice Conversion.” In Interspeech, pp. 1983-1987, Sep., 2018.
[7] K. Maekawa, H. Koiso, S. Furui, and H. Isahara, “Spontaneous speech corpus of Japanese,” Proc. LREC, pp.947–952, May 2000.
[8] Y. Saito, K. Akuzawa, and K. Tachibana, “Joint adversarial training algorithm of speech recognition and synthesis models for many-to-one voice conversion using phonetic posteriorgrams,” Proc. ASJ, Autumn meeting, 2-4-2, pp. 963–966, Sep. 2019. (in Japanese)
[9] A. van den Oord, S. Dieleman, H. Zen, K. Simonyan, O. Vinyals, A. Graves, and K. Kavukcuoglu, “Wavenet: A generative model for raw audio.” arXiv preprint arXiv:1609.03499, 2016.
[10] R. Prenger, R. Valle, and B. Catanzaro, “Waveglow: A flow-based generative network for speech synthesis.” In ICASSP, pp. 3617-3621, Apr., 2019.
[11] K. Kumar, R. Kumar, T. d. Boissiere, L. Gestin, W. Z. Teoh, J. Sotelo, A. d. Brebisson, Y. Bengio, and A. Courville, “MelGAN: Generative Adversarial Networks for Conditional Waveform Synthesis.”, arXiv preprint arXiv:1609.03499, 2019.



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。