





はじめまして。AI システム部の @moajo です。
普段はインフラからフロントエンドまで幅広く MLOps しています。
弊社 AI システム部のとあるプロジェクトで、老朽化した機械学習推論パイプラインを Airflow と SageMaker を組み合わせて再構築しました。
この記事では、新しい推論パイプラインの開発を通して得られた知見と、その具体的な実装についてご紹介します。
具体的なコード例を多めに載せているので、参考になれば幸いです。
この記事には以下のようなことが書いてあります。
- システム全体像と得られた知見
- SageMaker batch transform の使い方
- Airflow の使い方
この記事ではなんとなく以下を知っていることを前提とします。
- Airflow とは何か
- SageMaker とは何か
背景
このプロジェクトでは、以前から以下のような推論プロセスが運用されていました
- 外部アカウントの s3 バケットに元データ(動画)が継続的に追加されます。
- そのデータを自社で管理しているアカウントの s3 バケットにコピーします。
- データは時間のかかる前処理(without GPU)を適用します。
- その後、各種のモデルによる推論が行われます。結果は同じ s3 バケットに吐きます。
- モデルは GPU で動いたり、CPU で動いたりします。
- モデル間には依存関係がある場合もあるので、順番を考慮する必要があります。
いままで推論は単一の python スクリプトで実装され、ナイーブにすべてのモデルをロードして順番に推論を実行していました。
このコードは単一の EC2 GPU インスタンス上で実行されます。当然、計算リソースが限られるため、推論は並列化せずシーケンシャルに実行されました。
モデルの種類が少ないうちはこれでも十分だったのですが、推論パイプラインが肥大化していくにつれて様々な問題が表面化してきていました。
- モデルが GPU メモリに乗り切らない
- 推論コードにモデルのロード/アンロードを注意深く実装しなければならず、リサーチャーの負担に
- CPU 実行される推論時、GPU が遊んでしまう
- 単純に無駄コスト
- 推論に時間がかかる
- 並列計算できるはずの依存のないモデルも直列に計算している
そこで今回はこれらの問題を解決するため、Airflow + SageMaker で以下のようにパイプラインを刷新しました
- Airflow でコピースクリプトを定期実行し、外部バケットのデータを自社バケットにコピー
- コピーされた動画のメタデータが SQS にキューイングされる
- このキューのサイズによって auto scaling する ECS サービスによって、並列で前処理が行われる
- 前処理の結果は別の SQS キューに格納される
- 再び Airflow で SQS を ポーリングし、適当なサイズのバッチを切り出して各種の推論処理を順番に実行する
- 推論処理は SageMaker batch transform で行い、Airflow はこれをミニバッチ単位で起動して完了を待機する

結果的に新しいパイプラインを実際に実装・運用して、以下のようなメリット・デメリットがあると感じました。
- メリット
- SageMaker でモデルを疎結合にでき、実行コストを最適化できる
- いままであった無駄コストをカットできる
- Airflow は各種のワークフローを視覚的に一元管理できる点で優秀。実装も簡単
- 従来のパイプラインは実装が分散していて、保守性が低かった
- パイプラインのボトルネックが容易に把握できる点も良い
- ワークフローの拡大や計算の高コスト化に対してスケーラブル
- SageMaker はモデル毎に簡単にスケールアウトできる
- SageMaker でモデルを疎結合にでき、実行コストを最適化できる
- デメリット
- SageMaker のドキュメントが少なくて辛い
- Airflow のドキュメントも少なくて辛い
- AWS の場合 Airflow クラスタを自前で構築するのが手間。管理が面倒。(GCP は マネージドサービス がある)
- SageMaker はデバッグが辛い。動くようにするまでが大変
- モデルの実装はできていても、それを SageMaker で動作するように書き換えるのが高コスト
- batch transform を実行するのに 5 分くらいかかる。デバッグイテレーションに時間がかかる
全体的にはかなりいい状態に持ってこれたと思います。
ここからは、パイプライン全体で Airflow と SageMaker をそれぞれどのように使っているのか紹介していきます。
Airflow
Airflow はワークフローエンジンの一つで、python や bash などで書いたタスクを定期実行したり、実行順序を管理したり、再実行や監視などを行うことができます。
docker で動くサンプルとしては こちら が非常に参考になります このプロジェクトではこちらをベースに開発を進めました
実行環境
Airflow はスケーラビリティを担保するため、複数ホストで分散してタスクを実行できるように設計されています。
先程のサンプルリポジトリ
では docker-compose-CeleryExecutor.yml を指定して docker-compose でローカル実行できます。
docker-compose-LocalExecutor.yml は 1 ホストですべてを動かす起動オプションです。実運用ではあまり使わないでしょう。今回も使いません。
ちなみに
Celery
は分散実行のためのタスクキューの名前です。
docker-compose-CeleryExecutor.yml を見てみると以下のサービスで構成されているのがわかります。
- redis
- Celery のバックエンドとして使用
- postgres
- タスクの実行結果の保存用
- webserver
- webUI のサーバ。DAG の読み込みなどを行う
- flower
- Celery のモニタリングツール。無くてもいい
- scheduler
- タスクの実行順を決めて worker に流してくれる
- worker
- タスクを実行する
webserver,scheduler,workerはすべて同じイメージでコマンドを変えて実行しています。
環境変数やボリュームマウントはすべて同じものを指定します。(
アンカーとエイリアス
を使って DRY にすると管理が容易です。)
AWS 上では ECS サービスとして fargate 上で実行しています。基本的には上記の docker-compose-CeleryExecutor.yml そのままでいいですが、このプロジェクトではいくつか変更を加えました。
- Celery のバックエンドを redis から SQS に
- postgres は RDS に
Celery のバックエンドの変更はインスタンスの維持コストがなくなるので経済的にも管理の手間的にもうれしいです。
この変更は環境変数AIRFLOW__CELERY__BROKER_URLを書き換えるだけで実現できます。
今回は以下のようにして AWS とローカルでバックエンドを切り替えています。
if [ "$AIRFLOW__CORE__EXECUTOR" = "CeleryExecutor" ]; then
if [ "$USE_SQS_FOR_BROKER" != "" ]; then
echo "use sqs for broker"
AIRFLOW__CELERY__BROKER_URL="sqs://"
else
AIRFLOW__CELERY__BROKER_URL="redis://$REDIS_PREFIX$REDIS_HOST:$REDIS_PORT/1"
wait_for_port "Redis" "$REDIS_HOST" "$REDIS_PORT"
fi
fi
この設定により、 airflow-broker というキューが自動的に作成され使われます。
ディレクトリ構成
DAG の定義はdags以下に配置された python スクリプトが自動で読み込まれます。
このディレクトリは数秒毎、あるいは手動でにリフレッシュされるので、ローカルでの開発時はコンテナにマウントしておけば編集しながらすぐに動作テストができます。
このディレクトリは再帰的に探索されるので、ワークフロー毎にサブディレクトリを切るといいでしょう。
今回は、ワークフローごとのサブディレクトリに個別のリソースと DAG 定義のdag.pyを配置し、共通のオペレータはoperators以下にまとめました。
さらに、オペレータの呼び出しテストをoperators_test 以下に作りました。
なぜdags以下に作ったかと言うと、dags は Airflow にとって特別なディレクトリなので自動的に import path が通ったりして便利だからです。
タスクのシフト演算子
Airflow のタスクの依存関係の定義にはシフト演算子が便利です。
しかし、複雑な依存構造を表現しようとすると若干使い方にクセがあります。
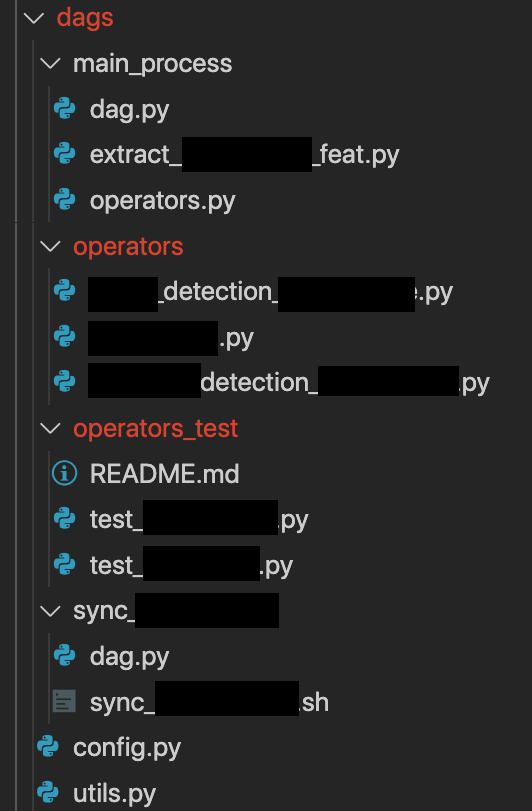
まずは基本の記法から。タスク aにタスクbが依存していることは、以下のように表現します
a >> b
## b << a でもOK
シフト演算子は 右側の値を返す ので、連続して書けます
a >> b >> c
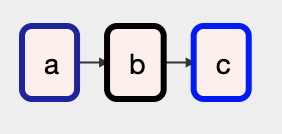
また、リストに対しての演算はブロードキャストされます
a >> [b >> c] >> d
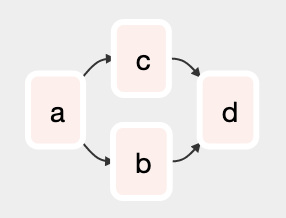
さて、注意が必要なのは以下のようなケースです
a >> [b1 >> b2, c] >> d
このコードは
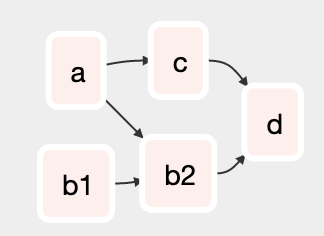
演算子が右辺値を返すことを考えれば当然ですが、直感的ではありません。
また、依存構造の定義を使い回すために関数化しようとしたときに不便でもあります。
ここで以下のようなラッパを作ると、
def wrap(op):
if not isinstance(op, list):
op = [op]
return OperatorWrapper(op, op)
class OperatorWrapper:
def __init__(self, lefts, rights):
self.lefts = [b for a in lefts for b in (a.lefts if isinstance(a, OperatorWrapper) else [a])]
self.rights = [b for a in rights for b in (a.rights if isinstance(a, OperatorWrapper) else [a])]
def __rshift__(self, other):
if not isinstance(other, OperatorWrapper):
other = wrap(other)
for lop in self.rights:
for rop in other.lefts:
lop >> rop
return OperatorWrapper(self.lefts, other.rights)
def __lshift__(self, other):
if not isinstance(other, OperatorWrapper):
other = wrap(other)
for lop in self.rights:
for rop in other.lefts:
lop << rop
return OperatorWrapper(self.lefts, other.rights)
def __rrshift__(self, other):
return (self >> other)._reversed()
def __rlshift__(self, other):
return (self << other)._reversed()
def _reversed(self):
return OperatorWrapper(self.rights, self.lefts)
wrap(a) >> [wrap(b1) >> b2, c] >> d
DAG 定義
DAG は、本番用とテスト用などで微妙に異なる複数のバリエーションを作ることがあります。
この際、共通部分を DRY にすることが重要です。
Airflow には DAG 中で別の DAG を呼び出す
SubDagOperator
がありますが、これは構造化のためというよりは DAG の呼び出しそのものが必要なケースでの使用を想定しているようです。動的にスケジューリングするので実行が遅かったり、
並列実行ができないなどの問題
もあるので使用には注意が必要です。
このプロジェクトでは、共通部分のタスクだけ切り出して依存関係を定義してから返す関数を実装し、DRY を実現しています。
以下はバケット間データコピーのタスクを一部改変して簡略化したものです。
def main(params, bash_cmd, angles):
today = datetime.now()
month_ago = today-relativedelta(months=1)
today_ops = [
BashOperator(
task_id=f'sync_data_today_angle_{angle}',
bash_command=bash_cmd,
xcom_push=True,
params={
**params,
'year': today.year,
'month': str(today.month).zfill(2),
'angle': angle,
},
)
for angle in angles
]
month_ago_ops = [
BashOperator(
task_id=f'sync_data_month_ago_angle_{angle}',
bash_command=bash_cmd,
xcom_push=True,
params={
**params,
'year': month_ago.year,
'month': str(month_ago.month).zfill(2),
'angle': angle,
},
)
for angle in angles
]
report_operator = PythonOperator(
task_id='report',
provide_context=True,
python_callable=reporter('return_value'),
)
return wrap(today_ops + month_ago_ops) >> report_operator
バリエーションのある DAG 定義は以下のような感じです。
with DAG(
'sync_data_main',
description='本番dag',
default_args=default_args,
max_active_runs=1,
schedule_interval='@hourly',
catchup=False
) as sync_data_main:
params = {
'src_bucket': os.environ.get('SRC_BUCKET'),
'dst_bucket': os.environ.get('DST_BUCKET'),
'queue_name': os.environ.get('QUEUE_NAME'),
'env': 'prod',
}
sync_data_main >> main(params, bash_cmd, angles)
with DAG(
'sync_data_dev',
description='開発用。コピー先バケットとsqsキューが異なる',
default_args=default_args,
max_active_runs=1,
schedule_interval=None,
catchup=False
) as sync_data_dev:
params = {
'src_bucket': os.environ.get('SRC_BUCKET_DEV'),
'dst_bucket': os.environ.get('DST_BUCKET_DEV'),
'queue_name': os.environ.get('QUEUE_NAME_DEV'),
'env': 'dev',
}
sync_data_dev >> main(params, bash_cmd, angles)
1 ファイルに複数 DAG を定義するとき、
as sync_data_mainの部分の変数名を同じにしないことに注意してください。 Airflow はグローバルに定義された DAG インスタンスを認識するので、同じにしてしまうと下の with 句で変数が上書きされてしまい、最後に定義した DAG しか認識されなくなります。
SageMaker
SageMaker
は学習と推論の両方を行える AWS のマネージド機械学習基盤です
SageMaker はいくつかのサブサービスから構成されていて、主要なものは
SageMaker notebook: jupyter notebook 環境を VPC 内に立ち上げられる- IAM と連携することでセキュアに実行できる。AI システム部ではよく使われている(気がする)
SageMaker batchtransform: 学習済みモデルのバッチ推論を行う- 実行すると専用のインスタンスを起動して推論、終わったらインスタンスは消える。
- モデルへの入出力は s3 バケットを経由する。
SageMaker endpoint: 学習済みモデルのリアルタイム推論を行う- モデルをロードしたインスタンスをエンドポイントとして立ち上げ、1 データ毎の HTTP リクエストに低レイテンシで応答する。
- モデルへの入出力はサイズが大きくなければ HTTP リクエストペイロードに乗せられる。そうでなければ s3 を経由する。
SageMaker training: モデルの学習を行う- ここで学習したモデルはそのまま
batchtransformやendpoint化できる。
- ここで学習したモデルはそのまま
などがあります。
今回はリアルタイム性が要求されないので batchtransform を使います。
SageMaker を使用することで、モデルごとにリソースを柔軟に無駄なく割り当てることができ、推論を並列化することが容易になりました。
batch transform 使い方
SageMaker ではまずモデルの実行のためのスクリプトを用意します。
以下のように、決められた名前の関数を実装します。各関数は適切なタイミングと引数で SageMaker から呼び出されます。
ちなみにこのコードはbatchtransform、endpointで共通で、一度書いてしまえばどちらでも使えます。
## serving.py
from sagemaker_containers.beta.framework import worker
from model import Model # 同じディレクトリにあるmodel.py
## モデルの読み込み。
def model_fn(model_dir):
model_path = os.path.join(model_dir, 'params.npz')
config = make_model_config(model_dir)
return Model(config, model_path)
## 入力データを受け取る。
## endpointの場合httpリクエストペイロードが、batchtransformの場合s3に置かれたファイルの中身が引数として渡される。
## その違いを意識する必要はない。
def input_fn(input_bytes, content_type):
if content_type == 'application/json':
# データパスを書いたjsonを受け取る場合
req_body = json.loads(input_bytes)
bucket = req_body['bucket']
data = get_data_from_s3(bucket, req_body['data_path'])
return data
else:
# 生データを受け取る場合
data = load_as_numpy_array(input_bytes)
return data
## 推論の実行。model_fnとinput_fnの結果が渡される。
def predict_fn(data, model):
prediction = model.predict(data)
return prediction
## レスポンスの生成
## 結果はendpointの場合レスポンスbodyに、batchtransformの場合s3にファイルとして書き出される。
## ここでも違いを意識する必要はない
def output_fn(prediction, accept):
with BytesIO() as f:
np.save(f, prediction)
return worker.Response(response=f.getvalue(), mimetype=accept) # 単にバイト列をreturnするだけでもいけた気がする
このスクリプトを使って以下のようにbatchtransformを呼び出します。
import boto3
import sagemaker
from sagemaker import Session
from sagemaker.local import LocalSession
from sagemaker.chainer.model import ChainerModel
from sagemaker.utils import sagemaker_timestamp
from utils import DataTransfer
def create_model(sagemaker_session, config, model_name, region_name):
parameters = {
'sagemaker_session': sagemaker_session,
'model_data': config['model']['path'],
'role': config['role'], # 実行用 IAM role
'env': config['env'],
'entry_point': 'serving.py'
'source_dir': 'models/hoge/', # serving.pyがあるディレクトリ
'dependencies': 'utils/', # source_dir以外の依存コードがあるディレクトリ
'vpc_config': get_vpc_config(region_name), # サブネット設定など
'framework_version': '5.0.0',
'py_version': 'py3',
'model_server_workers': 1,
'name': model_name,
}
return ChainerModel(**parameters)
def predict(model_name, data_infos, instance_count, bucket_name, mode, region_name):
data = [json.dumps(datainfo, indent=2) for datainfo in data_infos]
boto3_session = boto3.Session(region_name=region_name)
s3 = boto3_session.client('s3')
data_transfer = DataTransfer(s3, bucket_name, 'tmp/hoge')
data_transfer.send(data)
sagemaker_config = get_sagemaker_config()
if mode == 'aws':
sagemaker_session = Session(boto_session=boto3_session)
elif mode == 'local':
sagemaker_session = LocalSession()
m = create_model(
sagemaker_session,
sagemaker_config[mode],
model_name,
region_name,
)
transformer = m.transformer(
instance_count,
sagemaker_config[mode]['instance_type'],
accept='image/jpeg',
output_path=f's3://{bucket_name}/{data_transfer.output_dir}',
strategy='SingleRecord',
assemble_with=None,
output_kms_key=None,
env=None,
max_concurrent_transforms=None,
max_payload=None,
tags=None,
volume_kms_key=None,
)
transformer.transform(
f's3://{bucket_name}/{data_transfer.input_dir}',
job_name=None,
data_type='S3Prefix', # or "ManifestFile"
content_type='application/json',
compression_type=None, # or 'Gzip'
split_type=None, # 'None', 'Line', 'RecordIO', 'TFRecord'
input_filter=None, # "$[1:]", "$.features"
output_filter=None, # "$[1:]", "$.prediction"
join_source=None, # Input, None
wait=True
)
return [
np.load(BytesIO(it), allow_pickle=True)
for it in data_transfer.receive()
]
ここで出てくる DataTransferは s3 上に必要なデータを転送し、結果を読み出すための自作ユーティリティです。(中身は割愛)
なお、ここでは 1 データ 1 ファイルとして s3 に put する実装になっていますが、transformer.transformでsplit_typeを指定することで複数データをまとめて 1 ファイルにすることができるようです。
ちなみに今回は使いませんでしたが、endpointのデプロイは以下のようにします。
def deploy_endpoint(sagemaker_session, config, endpoint_name, region):
model = create_model(sagemaker_session, config, f'hoge-{endpoint_name}', region)
# deploy model to endpoint
model.deploy(
instance_type=config['instance_type'],
initial_instance_count=1,
endpoint_name=endpoint_name
)
パイプラインでの実装例
以上を踏まえた上で、推論パイプライン全体が Airflow と SageMaker をどのように組み合わせて実装されているかを紹介します。
データのコピー(sync)
冒頭の図にあった、外部バケットからデータをコピーして SQS にキューを投げるワークフローです。
1 時間おきに実行されます。
ディレクトリ構成
ではdags/sync_****/に実装されています。
本体の処理は aws-cli を使ってシェルスクリプトとして実装されています。
DAG 定義
に示したように BashOperatorでタスクを作成します。
BashOperatorではxcom_push=Trueとすることで標準出力の最後の行が xCom として出力されます。
max_active_runs=1 を指定しないと、sync が 1 時間で終わらなかった際に、次のスケジュールが並行して実行されてしまいます。
catchup=Falseを指定しないと、平行実行を制限したため保留されたスケジュールが、前のスケジュールの実行完了直後に改めて実行されてしまいます。
## 再掲
with DAG(
'sync_data_main',
description='本番dag',
default_args=default_args,
max_active_runs=1, # 平行実行されないように
schedule_interval='@hourly', # 1時間おきに実行
catchup=False # 実行していない過去のスケジュールをskip
) as sync_data_main:
SageMaker の呼び出し
SageMaker を呼び出して推論処理を行うワークフローは 2 つのモジュールに分かれています。
まず、(前処理後のデータが流れてくる)SQS キューをポーリングし、ミニバッチを作成する部分
そして、ミニバッチを SageMaker batchtransform で処理する部分です。
前処理完了のキューのポーリングとミニバッチの作成
Airflow には標準で
SQSSensor
が用意されていますが、最大 10 メッセージまでしか一度に取得できません(
SQS の API の制約
)。
ミニバッチにする上ではもう少し多くでもいいので、カスタムセンサーを実装しました。
カスタムセンサーは airflow.sensors.base_sensor_operator.BaseSensorOperator を継承したクラスを実装して作成できます。
from airflow.sensors.base_sensor_operator import BaseSensorOperator
class SQSBufferingSensor(BaseSensorOperator):
"""
標準のSQSSensorはメッセージを最大10しか取得できないので、無制限に取得できるようにした
"""
def __init__(self,
sqs_queue_url,
max_messages,
max_wait_seconds,
*args,
**kwargs):
super().__init__(*args, **kwargs)
self.sqs_queue_url = sqs_queue_url
self.start_time = None
self.message_buffer = []
self.max_messages = max_messages
self.max_wait_seconds = max_wait_seconds
self.session = boto3.Session()
def poke(self, context):
if self.start_time is None:
self.start_time = time.time()
sqs = self.session.client('sqs')
response = sqs.receive_message(
QueueUrl=self.sqs_queue_url,
MaxNumberOfMessages=min(10, self.max_messages - len(self.message_buffer)),
WaitTimeSeconds=5,
)
if 'Messages' in response and len(response['Messages']) > 0:
messages = response['Messages']
entries = [
{
'Id': message['MessageId'],
'ReceiptHandle': message['ReceiptHandle']
}
for message in messages
]
self.message_buffer.extend(messages)
elapsed = time.time()-self.start_time
if len(self.message_buffer) >= self.max_messages:
# max_messages以上のメッセージを受信したら終了
context['ti'].xcom_push(key='messages', value={'Messages': self.message_buffer})
return True
if elapsed > self.max_wait_seconds:
# max_wait_seconds経過したら数が足りなくても終了
context['ti'].xcom_push(key='messages', value={'Messages': self.message_buffer})
return True
return False
このセンサーは以下のような挙動をします。
- キューをロングポーリングして
max_messages個のメッセージを集めたら xcom で返します。 - ただし
max_wait_seconds秒経過したら、メッセージが規定数に届かなくても終了します。
また、xcom の出力は標準のSQSSensorと互換になるようにしています。
poke 関数はセンサーをインスタンス化するときに poke_intervalで指定する間隔で実行されます。
この関数が True を返すとセンサーは終了し、False を返すと継続します。
余談ですが SQS を使う際はメッセージ受信後すぐに削除するのではなく、すべての処理が完了してから削除するようにします。
これは処理中にエラーが発生したりして正常に完了しなかった場合、削除していなければ SQS は一定時間後に自動的にメッセージをキューに戻してくれるからです。これだけでリトライが実装できます。 この一定時間は可視性タイムアウトと呼ばれ、キュー毎に設定できます。ただし、最大 12 時間なので機械学習用途だと上限値に気をつける必要があります。
このようなカスタムセンサなどはプラグインとして実装するとよさそうです。
Airflow は pluginsディレクトリに以下からプラグインを探します。
plugins/__init__.py で以下のように AirflowPlugin を継承したクラスを定義します。
from airflow.plugins_manager import AirflowPlugin
from sensors import SQSBufferingSensor
class HogePlugin(AirflowPlugin):
name = 'hoge_plugin'
operators = []
sensors = [SQSBufferingSensor]
hooks = []
executors = []
macros = []
admin_views = []
flask_blueprints = []
menu_links = []
appbuilder_views = []
appbuilder_menu_items = []
global_operator_extra_links = []
Airflow はプラグインで定義されたモジュールを以下のようなパスでインポートできるようにしてくれます。
from airflow.sensors.hoge_plugin import SQSBufferingSensor
SageMaker 呼び出し
カスタムセンサで取得したミニバッチをSageMaker batchtransformで各モデルに投げます。
1 モデル 1 タスクとして実装することで、依存関係を Airflow で簡単に制御できます。
モデルごとにインスタンスが立ち上がるため、並列化やリソースの調整も容易です。
## あるモデルを呼び出すタスク例
## 他のモデルも大体同じ
def main(params, **context):
# 引数は params で渡す。
# params は Airflow のタスク詳細画面から確認できるので管理しやすい。
BUCKET = params.get('bucket')
INSTANCE_COUNT = params.get('instance_count')
SENDER_ID = params.get('xcom_sender_taskid') # ミニバッチを送出したタスクのid
REGION = params.get('region')
# xcomからデータを取得
data = context['ti'].xcom_pull(task_ids=SENDER_ID)
# overwriteまたはファイルがないときだけ処理
request_payload = [
{
'bucket': BUCKET,
'data1_path': get_data1_path(d),
'data2_path': get_data2_path(d),
'output_path': get_output_path(d),
}
for d in data
if d.get('overwrite') or not s3_file_exists(BUCKET, get_output_path(d))
]
if len(request_payload) == 0: # 空だったら何もしない
# タスクが大量にあるとログが一覧しにくくてデバッグが困難なので、ログを集約するタスクを用意している(後述)
report_message(context['ti'], 'result file is already exists. do nothing.')
return []
return predict(
'airflow-hoge',
request_payload,
INSTANCE_COUNT,
BUCKET,
'aws',
REGION,
)
DAG の定義以下のようになります。 上の関数を PythonOperator で呼び出します。
## 主要なモデルの依存定義
def extract_feat(xcom_sender_taskid, bucket, region):
return (
wrap(PythonOperator(
task_id='model1',
provide_context=True,
python_callable=model1.main,
params={
'xcom_sender_taskid': xcom_sender_taskid,
'bucket': bucket,
'instance_count': get_instance_count('model1'),
'region': region,
},
))
>> PythonOperator(
task_id='model2',
provide_context=True,
python_callable=model2.main,
params={
'xcom_sender_taskid': xcom_sender_taskid,
'bucket': bucket,
'instance_count': get_instance_count('model2'),
'region': region,
},
)
>> [
extract_other_feat(
xcom_sender_taskid=xcom_sender_taskid,
bucket=bucket,
region=region,
),
PythonOperator(
task_id='model3',
provide_context=True,
python_callable=model3.main,
params={
'xcom_sender_taskid': xcom_sender_taskid,
'bucket': bucket,
'instance_count': get_instance_count('model3'),
'region': region,
}
),
]
)
## 推論処理全体
def main_ops(xcom_sender_taskid, bucket, region):
return [
extract_feat(
xcom_sender_taskid=xcom_sender_taskid,
bucket=bucket,
region=region,
),
PythonOperator(
task_id='model4',
provide_context=True,
python_callable=model4.main,
params={},
),
PythonOperator(
task_id='model5',
provide_context=True,
python_callable=model5.main,
params={},
),
]
with DAG(
'main',
default_args=default_args,
catchup=False,
schedule_interval=timedelta(seconds=60 * 10), # 10分おきに実行
max_active_runs=1
) as main:
(
main
# SQSのポーリング
>> wrap(SQSBufferingSensor(
sqs_queue_url=INPUT_QUEUE,
max_messages=100,
max_wait_seconds=2 * 60,
task_id='wait_sqs',
poke_interval=10,
region=SAGEMAKER_REGION,
))
# メッセージの整形
>> PythonOperator(
task_id='parse_message',
provide_context=True,
python_callable=parse_message,
)
# メッセージが空だった場合以降の処理をskip
>> ShortCircuitOperator(
task_id='skip_if_messages_empty',
provide_context=True,
python_callable=skip_if_messages_empty,
)
# 推論処理本体
>> main_ops(
xcom_sender_taskid='parse_message',
bucket=BUCKET,
region=SAGEMAKER_REGION,
)
# 全タスクが正常終了していたら実行されるSQSメッセージの削除処理
>> PythonOperator(
task_id='delete_message',
provide_context=True,
python_callable=delete_message,
params={
'xcom_sender_taskid': 'wait_sqs',
'sqs_queue_url': INPUT_QUEUE,
'sqs_queue_region': SAGEMAKER_REGION,
}
)
# ログの集約
>> PythonOperator(
task_id='report',
provide_context=True,
python_callable=reporter(),
)
)
最終的に DAG 全体の構造は以下のようになっています。
(黒塗りが推論タスクです)

補足
SageMaker データ受け渡し
SageMaker 呼び出し時のリクエストペイロードは、データが複数箇所に分散しているためそのパスを書いた json を受け渡すようにしています。
この場合、serving.py で s3 からファイルを取得する処理を書く必要があります。
また、出力ファイルパスを固定にすることで重複した実行を防ぎ、ワークフローの冪等性を確保できます。
ワークフローが冪等であることは自動化されたパイプラインにとってとても重要です。
# overwriteまたはファイルがないときだけ処理
request_payload = [
{
'bucket': BUCKET,
'data1_path': get_data1_path(d),
'data2_path': get_data2_path(d),
'output_path': get_output_path(d),
}
for d in data
if d.get('overwrite') or not s3_file_exists(BUCKET, get_output_path(d))
]
ログ集約
ログ集約に使った report_message 関数です
以下のように実装しています。
xcom に reportというキーでメッセージを送信すると、reporter がそれを取得して表示するようにしているだけです。
## 自身の上流タスクを再帰的にすべて取得
def get_all_upstream_recursive(task):
res = []
processed_task_ids = set()
currents = [task]
while len(currents) != 0:
news = []
for c in currents:
for u in c.upstream_list:
if u.task_id in processed_task_ids:
continue
processed_task_ids.add(u.task_id)
news.append(u)
res.append(u)
currents = news
return res
def reporter(key: str = 'report'):
def _op(**context):
task_ids = [a.task_id for a in get_all_upstream_recursive(context['task'])]
reports = context['ti'].xcom_pull(task_ids=task_ids, key=key)
for id, report in zip(task_ids, reports):
if report is None:
print(f'no report from {id}')
continue
print(f"--------------report from {id}------------------------")
print(json.dumps(report, indent=2))
return _op
def report_message(ti, message):
ti.xcom_push(key='report', value=message)
以下のように、サマリーをひと目で確認できて便利です。
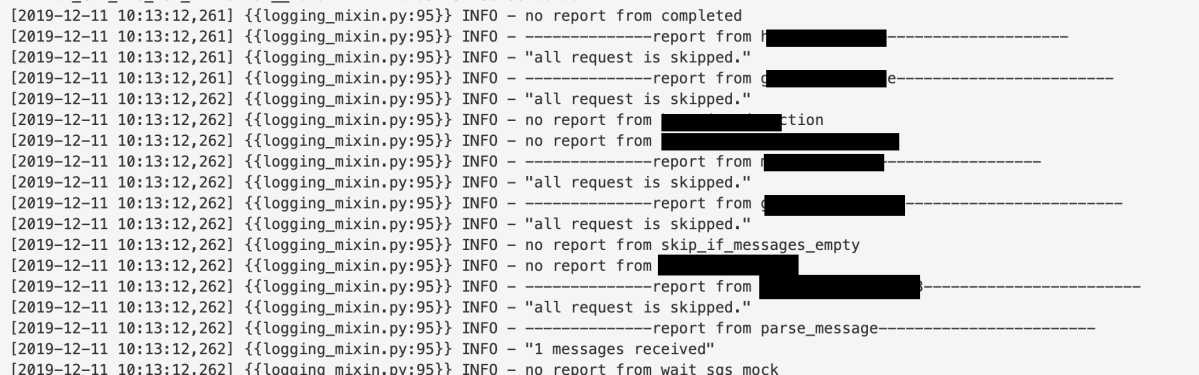
まとめ
この記事では Airflow と SageMaker で実装する推論パイプラインの全体像を具体的に紹介しました。
Airflow/SageMaker どちらも機能的な問題はあまりないですが、まだ成熟していないという印象です。
書き切れなかったハマリポイントや怪しい挙動がたくさんありました。
使ってみる際はこのあたりを覚悟して行くことをオススメします。
なお DeNA は AWS と密に連携しているので、SageMaker はバンバン使い込んでフィードバックし、協力してより良いものにしていこうと思っています。
今後の発展に期待です。
この実装例がみなさんの参考になれば嬉しいです。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。