





はじめに
こんにちは、AIシステム部でコンピュータビジョン研究開発をしている唐澤(@Takarasawa_)です。 我々のチームでは、常に最新のコンピュータビジョンに関する論文調査を行い、部内で共有・議論しています。今回はObject Tracking編として唐澤 拓己が調査を行いました。
過去の他タスク編については以下をご参照ください。
論文調査のスコープ
2018年11月以降にarXivに投稿されたコンピュータビジョンに関する論文を範囲としており、その中から重要と思われるものをピックアップして複数名で調査を行っております。今回は主にObject Tracking技術に関する最新論文を取り上げます。
Object Tracking の位置付け
Object Tracking とは物体追跡という意味で、動画中で変化・移動していく物体を追跡するタスクです。動画中の物体を認識する上で基本的なタスクといえ、様々な応用面がありながらも、未だにチャレンジングなタスクとして存在しています。
Object tracking は、動画像中で指定されたひとつの物体を追跡する Single Object Tracking(SOT)、複数の物体を同時に追跡する Multiple Object Tracking(Multi-Object Tracking、MOT)に大別され、与えられる動画像の時間(フレーム数)が短いもの(Short-term)と長いもの(Long-term)でさらに異なるアプローチが取られることが多いように感じます。動画像の長さによりアプローチが異なるのは、時間が長い動画像においてある物体を見失った際(見失ったあとの全ての時間を失敗とみなされるため)低い評価を得てしまうことに起因して occlusion(物体が他のものに隠れてしまうこと)への対策等に重きが置かれるためだと思われます。
今回の論文紹介では最も中心的な、Short-term の SOT タスクに対して提案されている論文を紹介いたします。(以下、Object Tracking とはこのタスクのことを指して述べます。)
前提知識
Object Tracking
動画像と、その動画像の初期フレームにおける物体の位置が矩形(bounding box)として与えられ、次フレーム以降の同一物体の位置を bounding box として検出するタスクです。
このタスクの難しい点は、追跡する中で対象物体の外観が未知の状態へ変化していくこと(照明条件の変化や物体そのものの変形、見えない側面への視点の変化など)と、追跡中に生じる occlusion や他物体の交わりなどの外的影響に大別される印象です。また、物体検出との大きな違いとして基本的にクラスに依存しない物体全般へのタスクでありつつ、同クラスであっても異なる物体かの判断が必要な繊細な検出であることが挙げられるかと思います。
また、動画タスクの需要のひとつとして精度だけでなくリアルタイム性が重視されることが多く、速度と精度のバランスについてはよく議論される内容です。
アプローチ
Object Tracking に対して深層学習を用いた近年の主要なアプローチに、対象物体に対してオンライン学習を行うCorrelation Filter 系アプローチ、オフラインで汎用的な類似性マップを出力するための学習を行うSiamese Network 系アプローチがあり、今回紹介する論文に関わりが深いためそれぞれ概要を紹介いたします。他にもそれらを複合的に使用したものや物体検出タスクと併せてタスクを解くアプローチなど手法は多岐にわたります。
参考:https://github.com/foolwood/benchmark_results/
Correlation Filter 系アプローチ
Correlation Filter系アプローチは、基本的には与えられた目標画像(target template)に対してオンライン学習を行うことでターゲット特有の追跡モデルを獲得するアプローチのひとつで、得られた目標画像から正例と負例のサンプリング、それらのデータを用いて目標画像特有の識別器を学習、という流れであることが一般的です。オンライン学習により目標画像特有の識別器を学習するアプローチは比較的昔からある手法で、識別器に Boosting や SVM を用いる手法も存在します。その中で特にCorrelation Filter 系アプローチは、探索画像(search region)において物体に該当する場所をフィルタにより畳み込み演算を行った時に大きな値となるように学習を行います。
物体周辺からランダムサンプリングされていた従来手法に対して、このアプローチではまずピクセル単位でシフトさせることで密にサンプリングを行います。密にサンプリングされた画像群は巡回行列として扱うことができ、フィルタを用いた巡回行列に対する畳み込み演算(巡回畳込み)は、離散フーリエ変換を用いて簡単に計算できるという特性を用いて高速なオンライン学習を実現しています。(畳み込み演算と CNN などに用いられる畳み込み(convolution)は厳密には異なる計算です。)
現在は学習済み識別モデルにより得られた複数解像度の特徴マップに対してフィルタの学習を行うことが主流となっています。また、オフライン学習との複合的なアプローチも見られます。
Siamese Network 系アプローチ
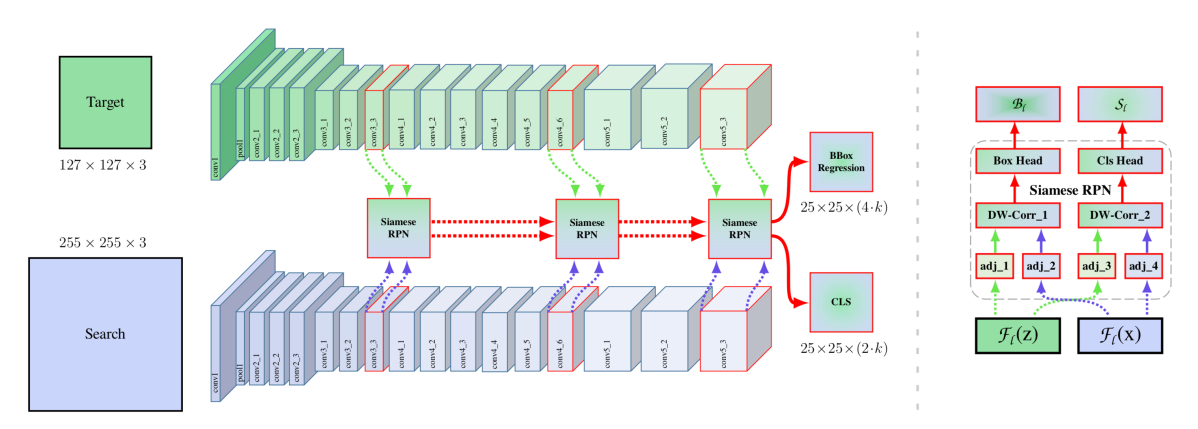
Siamese Network 系アプローチは、Object Tracking の問題を、目標画像(target template)から抽出される特徴表現(feature representation)と探索画像(search region)から抽出される特徴表現間の、相互相関(cross-correlation)により得られる汎用的な類似性マップ(similarity map)を学習することで解決を図ります。
ネットワーク構造は以下の図のように2つのネットワークで構成されており、Siamese Networkとはこの特徴的な2つのネットワークで構成される構造を指し、Object Trackingタスクでなくても用いられる言葉です。一方のネットワークは目標画像から、他方のネットワークは探索画像から特徴マップを抽出し、目標画像から抽出された特徴マップを用いて探索画像から抽出された特徴マップを畳み込むことで類似性マップを獲得します。応答マップ(response map)と呼ばれることもあります。学習の際は類似性マップが正解となるように学習を行い、追跡の際は類似性マップを元に追跡を行います。
このアプローチの基本となる手法として、SiamFC(ECCV2016 workshop)[1] と SiamRPN (CVPR2018)[2] の2つの手法が存在します。SiamFC はより直感的な考え方で、類似性マップは正解の存在する場所のグリッドの値が大きくなるように学習されます。SiamFCはこのアプローチが類似性マップを計算する処理も畳み込み(convolution)で表現されるため全体の構造が fully convolutional(FC)であることに名前が由来しています。他方で SiamRPN は、物体検出手法の代表的な手法のひとつである Faster R-CNN 中で使用されている物体候補領域を予測する region proposal network(RPN)を参考に、各グリッドに bounding box の基準となるアンカーを設定し、各グリッドは、各アンカーの物体らしさとアンカーの bounding box の正解への座標と幅と高さへの補正値を出力するように学習します。基本的には後者のほうが精度が良くなる傾向にあります。これらの2つの手法の提案された年代から、まだこれらの Object Tracking 手法の発達が浅いことがわかります。

SiamFC アーキテクチャ図。各特徴量を共通のネットワークφを用いて取得し、畳み込みを行うことで類似性マップを出力しています。( [1] より引用)
![]()
SiamRPN アーキテクチャ図。SiamFC と同様に Siamese Network を通したあと region proposal network のように物体らしさを出すブランチと bounding box の回帰を行うブランチにより結果が出力されます。( [2] より引用)
全体的な特徴として、Correlation Filter系アプローチと異なり基本的にはオフラインで学習を行い追跡時には重みを固定することが多いため(追跡時に学習を行わないため)、近年の高精度な手法らの中では追跡速度が速いことがあげられます(参考)。他方で欠点としてオンラインで目標画像の学習を行っていないため、目標物体と類似した物体のような紛らわしいものという意味のディストラクタ(distractor)に弱いことがよく述べられます。現在ではディストラクタなどの問題に対処するためオンライン学習をとりいれた手法や、特にディストラクタ認知モジュール(distractor-aware module)を備えた DaSiamRPN(ECCV2018)[3] などの手法も提案されており DaSiamRPN は今回紹介する CVPR2019 の論文中でも state-of-the-art として比較されることが多い手法となっています。
Siamese Network 系アプローチは Object Tracking のリアルタイム性の需要から、精度と速度のバランスの良さについて言及されることが多く、近年発達してきており今回紹介する論文も大半がこちらです。
参考文献
[1] Luca Bertinetto, Jack Valmadre, João F. Henriques, Andrea Vedaldi, Philip H.S. Torr. "Fully-Convolutional Siamese Networks for Object Tracking." ECCV workshop (2016)
[2] Bo Li, Wei Wu, Zheng Zhu, Junjie Yan. "High Performance Visual Tracking with Siamese Region Proposal Network." CVPR (2018 Spotlight)
[3] Zheng Zhu, Qiang Wang, Bo Li, Wu Wei, Junjie Yan, Weiming Hu."Distractor-aware Siamese Networks for Visual Object Tracking." ECCV (2018)
関連するデータセット
- OTB(object tracking benchmark)2013, 2015:VOTと共にデファクトスダンダートとされるデータセット
- VOT(visual object tracking)2013〜18:ICCV/ECCVで毎年開催されるコンペで公開されるデータセット。ICCV2019もコンペ開催中。
- 2014から bounding boxが回転したものを用いられるようになった。(通常は画像軸と平行な bounding box)
- 2018から long-termのデータセットも導入
- LaSOT(large-scale single object tracking):最も新しく導入されたデータセット(ECCV2018)
- 他に TrackingNet(2018)、UAV123(2016)など。
動画の長さと動画数についての各データセットのプロット(LaSOTより引用)
![]()
評価指標
- AUC(area under curve):正解とみなす overlap の threshold を変化させてできる precision の変化をプロットした際の曲線の下側の面積(area under curve)。いずれの threshold でも precisionが大きいほうが良いため大きいほうが良い。
- Robustness:VOTで使用される評価指標。追従中に overlap が0になってしまったときを追従失敗とみなし、1つの動画シーケンスに対して何回追従失敗するか。
- EAO(expected average overlap):VOTで使用される評価指標。accuracy と robustness を組み合わせた概念。複数動画長の各条件で追跡のoverlapの平均を算出し、それを全条件にて平均したスコア。ただしこの時追跡失敗後の overlapは全て0とみなされる。
論文紹介
【SiamMask】 "Fast Online Object Tracking and segmentation: A Unifying Approach"(CVPR 2019)
論文:https://arxiv.org/abs/1812.05050
要約
従来の SiamFC, SiamRPN に Mask を出力するブランチを追加し、object tracking と semi-supervised video object segmentation を同時に解く SiamMask を提案。また、併せて segmentation mask を用いて適切な bounding box を付与することで tracking のスコア自体も向上。
提案内容
- 従来の SiamFC, SiamRPN に Mask を出力するためのブランチを追加することで、object tracking と semi-supervised video object segmentation を同時に解く SiamMask を提案
- Siamese network において Target template と Search region からそれぞれ抽出される feature map 間の畳込み演算は depth-wise convolution を採用し、multi-channel の response map を使用する。(従来は通常の畳込みを行い single-channel の response map が出力される。)
全体のArchitecture
(a)three-branch 構造. SiamRPN は元々2つのブランチが存在するためこちらに該当。
(b)two-branch 構造. SiamFC は元々が1つのブランチしか存在しないためこちらに該当。
- *d の部分が depth-wise convolution.
- Mask ブランチにおける hφ は1x1 conv を2つ重ねた2 laye rの conv net。mask は各グリッドで直列化された状態で表現される。
![]()
(画像は本論文より引用)
Mask ブランチのアウトプットから Mask 画像への Upsampling
- 高解像度レベルの特徴マップを取り入れて refinment しつつ Upsampling を行う
![]()
(画像は本論文より引用)
Upsampling の際、高解像度を取り入れる部分の詳細 Architecture(図は U3 について)
![]()
(画像は本論文より引用)
Mask ブランチからアウトプットされるスコアマップ
- 各グリッドに該当グリッドを中心としたTarget画像サイズのMaskが格納される
![]()
(画像は本論文より引用)
Bounding box の付与方法。Box ブランチによる出力も行われるが、Maskを用いてより詳細な回転を含む適切な bounding boxの付与を付与する。
- 赤: Min-max 通常の画像軸に平行な外接矩形。
- 緑: minimum bounding rectangle(MBR)。segmentation mask を包含する bounding box の中で最小となる box の選択。
- 青: *従来研究で提案された optimization によりえられる bounding box。ただし計算コストが非常に大きい。
![]()
(画像は本論文より引用)
学習に使用する損失関数
- g は depth-wise convolution。
- h は Mask ブランチ. m はそれにより出力される mask。
![]()
- yn は ±1。RoW(各グリッドのこと)が mask 部分に該当するかどうか。
- yn がポジティブ(1+yn は yn がネガティブなときに0)な RoW に対してのみ全ピクセルについて binary logistic regression loss を算出して総和を取る。
![]()
- 2ブランチのときと3ブランチの時の全体の損失。mask 以外に関しては通常の SiamFC、SiamRPN のロスでsimはsimilarity mapのロス、score, box はRPNのそれぞれのロスを表す。λ は影響度の調整を行うハイパーパラメータ。
![]()
実験結果
VOT-2016, VOT-2018 を用いて visual object tracking の評価。
bounding box の付与の仕方の違い。(VOT-2016)
- 比較対象の oracle の表記は ground truth 情報を用いたもので、各手法のスコアの上限の評価に相当しているとのこと。
- Fixed:アスペクト比を固定した場合の ground truth。SiamFC に対応。
- Min-max:画像軸並行の制約条件。SiamRPN に対応。
- MBR:SiamMask に対応。
- 従来の手法は ground truth が回転された bounding boxでありながら、画像軸に平行な bounding box を出力している。
- binary mask を使用するだけで画像軸に平行な bounding box の出力に対して大幅な差をつけられる。
![]()
(表は本論文より引用)
他手法との比較
- SiamMask:3ブランチ(SiamRPNの拡張)
- SiamMask-2B:2ブランチ(SiamFCの拡張)
- 従来手法に対して大きな差で上回る。
![]()
(表は本論文より引用)
Siam RPN++: Evolution of Siamese Visual Tracking with Very Deep Networks (CVPR 2019 oral)
論文:https://arxiv.org/abs/1812.11703
要約
Siamese network 系アプローチのバックボーンは従来 AlexNet 等モデルであり、ResNet 等のモデルでは精度が落ちることが知られている。それを学習時にターゲットが中心に偏らないサンプリング方法で対処し、multi-layer の類似度マップ、depth-wise な畳み込みを用いて深いモデルの良さをさらに発揮するモデルを提案。
提案内容
- Siamese network 系アプローチのためのサンプリング方法の提案(spatial-aware sampling strategy)
- Response map による追従では双方の特徴の不変性(translation invariance)が必要。
- 他方で深いネットワークは、ネットワークを深くするために padding が多く含まれており、これが translation invariance を崩している。
- また通常、学習の際に response map の中央にターゲットが来るような学習がされており、そのため translation invariance が崩れているネットワークでは中心に response がでやすくなるバイアス(center bias)が学習されてしまっている。
- これに対して学習のサンプリングの際にランダムに適切な大きさの shift を行う spatial-aware sampling strategy を提案。
- 深いモデルをさらに効果的に使用するため multi-layer の類似度マップを使用する multi-layer aggregation を提案。
- tracking は粗い特徴から細かい特徴まで見るべきだが、従来はネットワークが浅かったため有効に利用できていなかった。
- depth-wise cross correlation filter の使用。(SiamMaskと同一の提案)
- Up-channel していた SiamRPN に比べ、パラメータの数が減り、パラメータの数のバランスがよくなるとのこと。
- 学習の収束が容易となる。
spatial-aware sampling strategy
- 学習時のサンプリングの際にランダムなshiftを加えて学習を行った結果。rand shift range はランダムな shiftの範囲の最大値。
- データセットごとに適切なshift(VOTの場合、±64)が存在することを指摘。
![]()
(図は本論文より引用)
multi-layer aggregation
- 各層の特徴マップから得られる response mapは重みづけて総和。
- (画像は本論文より引用)

depth-wise cross correlation layer と従来の cross correlation layer との違い。
(a) SiamFCにおける cross correlation layer
(b) SiamRPNにおける cross correlation layer
(c) 提案された depth-wise cross correlation layer
実験結果
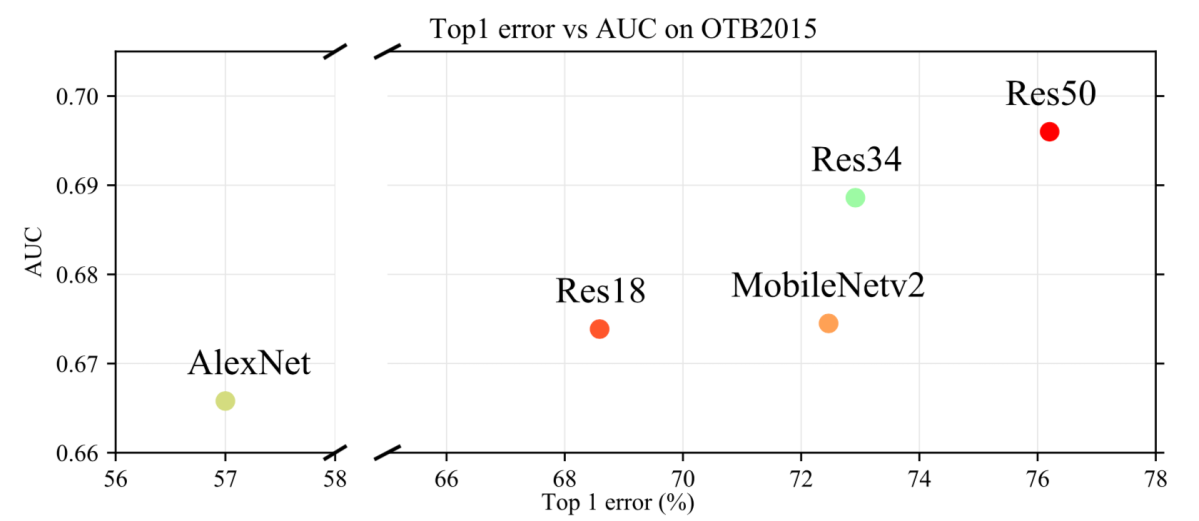
OTB2015データセットを用いてバックボーンによる精度の比較。
- 横軸は ImageNetに対する分類精度を表す、top1 accuracy on ImageNet(論文中では top1 accuracyとあるが図は top1 errorとあり記述ミス。)
- 分類タスクと同じ傾向でバックボーンによる精度向上を行えるようになったことが示唆される。
multi-layer、depth-wise correlation に関する ablation study。
- depth-wise cross correlationは全体的に精度向上に寄与。
- multi-layerに関しては、
- 2種の組み合わせ:いずれの組み合わせでも精度向上してほしいが、conv4独立に勝ててるのはconv4, 5の組み合わせのみ。
- 3種の組み合わせ:最も良い精度となり multi-layer aggregationの有効性を示唆。
![]()
(表は本論文より引用)
depth-wise cross correlation による response mapの出力の図示
- tracking はクラス依存しないタスクであるが、クラスごとに反応する response mapが異なる。
![]()
(画像は本論文より引用)
他手法との比較
- 精度に関しては上昇しているが、その反面robustnessは下がる。
![]()
(表は本論文より引用)
速度と精度との比較
- mobile netにも適用
![]()
(グラフは本論文より引用)
他データセット、UAV123, LaSOT, TrackingNetへも実験を行っており、また、VOT2018 long-termへのtracking performanceについても論文中では実験され比較されている。
Deeper and Wider Siamese Networks for Real-Time Visual Tracking (CVPR 2019 Oral)
論文: https://arxiv.org/abs/1901.01660
要約
Siamese network系アプローチのバックボーンは従来 AlexNet 等モデルであり、ResNet 等のモデルでは精度が落ちることが知られている。その原因を詳細に解析し、Paddingの悪影響を対処する新モジュールの提案をメインとした、deep/wide なモデルを提案する。
提案内容
- 分析:Siamese network系アプローチの(ResNetやInceptionなどへの)バックボーンの単なる置換の際のパフォーマンスの低下に関する詳細な定量的分析、(特にpaddingに対する)定性的分析。
- stride、最終層におけるreceptive field、出力するfeature mapのサイズに対する詳細な分析。それを踏まえたネットワーク構造へのガイドラインの提示。
- 特にPaddingでは、Siamese networkで response map を出力する際のpadding付近の他部分に対する一貫性のなさを定性的に指摘。
- 新しいResidual モジュールの提案:従来の residual unit や inception module からpadding の影響する部分をクロッピングした Cropping-Inside Residual (CIR) Units 等の提案。
- Cropping-Inside Residual (CIR) Units
- Downsampling CIR (CIR-D) Units
- CIR-Inception Units
- CIR-NeXt Units
- ネットワークの提案: receptive field size、 strideの分析とともに、CIR Unitモジュールを含めたネットワークを提案
Cropping-Inside Residual (CIR) units、Downsampling CIR(CIR-D)units
(a)通常の residual unitの構造:3層の conv layer + skip connection。
(a')CIR unitの構造:residual unit の出力後、padding の影響を受ける部分をクロッピングする。
(b)通常の down sampling residual unitの構造:skip connection部分についても conv の stride を2にして down sampling される。
(b')CIR-D unitの構造:residual unit の内部では down sampling せず、出力後(a')と同様に padding の影響を受ける部分をクロッピングしたあと、maxpooling によって down sampling するようにする。
![]()
(画像は本論文より引用)
他モジュール図
- Inceptionモジュール、ResNeXtについても同様にクロップするモジュールを提案。
![]()
(画像は本論文より引用)
response mapの可視化
- 左上がpaddingバイアスの小さいような物体が中心に位置している状況。
- 左上以外について従来のresnetアーキテクチャでは適切に検出できていない。
![]()
(画像は本論文より引用)
実験結果
OTB-2015、VOT-2016、VOT-2017を用いて評価。
ベースラインである AlexNet をバックボーンとした場合との比較。
- いずれもベースラインの精度を提案手法が上回る。
![]()
(表は本論文より引用)
ベースラインである AlexNet のバックボーンを ResNet と単に置換した場合と提案手法との精度比較。
- 実際に単に置換した場合では、 AlexNet の場合より悪くなるが、提案手法では精度が向上している。
![]()
(画像は本論文より引用)
他手法との比較
![]()
(表は本論文より引用)
ATOM: Accurate Tracking by Overlap Maximization(CVPR 2019)
論文:https://arxiv.org/abs/1811.07628
要約
従来のオンラインで学習される target classifier では高次な知識を要する複雑なタスクには限界があることを指摘し、それに加え、高次な知識をオフラインで学習する target estimator を組み合わせることで正確な tracking を実現。
*IoU-Netの前提知識を多く用いるため、IoU-Netの論文についても後に紹介する。
提案内容
物体検出タスクで提案された、検出された bounding box と ground truth の IoU(Intersection over Union)を予測する IoU-Net、それにより予測されたIoUを目的関数とし、IoU が最大となるように refinementを行う手法を tracking に応用し、target estimator を構築する。
target estimator
- IoU-Net はクラス依存なしで汎用的に行うことは難しく、現論文では class ごとにモデルの学習を行っている。
- そのため、IoU-Netの入力に target image を特徴として加えることで target 特有の IoU-Net となるように学習を行う。
- modulation based network を追加することで、target image の特徴は modulation vector として付加させる形で取り入れる。
target classifier
- target 画像に対してオンラインで学習し、targetかどうかの分類を行う。出力は 2D グリッドマップ。
- conv の2層構造で、オンライン学習のため Gauss-Newton法と、Conjugate Gradientを組み合わせて解く。
オフライン学習済み target estimator と target classifier のオンライン学習を組み合わせた Tracking の流れ
- target classifier の適用。粗く target の存在する場所を特定する。
- 候補領域の生成。confidence が最大となる座標、ひとつまえの bounding box の幅と高さから最初の候補領域を生成する。このとき局所最適を避けるため一様分布のノイズを加えて10通りの候補領域を生成する。
- IoU-Net ベースのリファインメントを行なった後、IoU スコアが高い3つの bounding box を平均してtracking 結果とする。
- 結果を用いてオンライン学習により target classifier を更新する。
テスト時の全体図
- IoU predictor は reference image(target image)を modulation vector として取り入れる。
- Classifier はターゲット画像に対してオンラインで学習がされている。
![]()
(画像は本論文より引用)
全体のアーキテクチャ詳細図
![]()
(画像は本論文より引用)
実験結果
他手法との定性的な実験結果の比較
- DaSiamRPN は先にも紹介した Siamese network 系アプローチの最も良いとされる手法。UPDT はcorrelation filter に基づく手法。
- UPDT は target state estimation コンポーネントがないためアスペクト比が異なるものを扱えない。
- DaSiamRPN は bounding box regression を採用しているが変形や回転に弱い。
![]()
(画像は本論文より引用)
様々なデータセットによる比較。全てのデータセットで最も良い精度となっている。
- NFS、UAV
![]()
(グラフは本論文より引用)
- Tracking Net
![]()
- LaSOT
![]()
- VOT2018
![]()
(表は本論文より引用)
【IoU-Net】 "Acquisition of Localization Confidence for Accurate Object Detection"(ECCV 2018)
論文:https://arxiv.org/abs/1807.11590
*先に紹介した ATOM に与える影響が非常に大きいため紹介。
要約
通常のCNNベースの物体検出手法は classification confidence は出力されるが、localization の confidence については出力されず物体検出の confidence として乖離があることを指摘。検出された bounding box と ground truth の IoU を予測する IoU-Net を提案する。
提案内容
- 検出された bounding box と ground truth の IoU を予測する IoU-Net を提案
- 出力される IoU = localization confidence を得ることができる。
- 予測したIoUを利用したIoU-guided NMSを提案。
- 予測したIoUを目的関数とした、最適化ベースの bounding box refinement 手法を提案
- この中で、refinement を行うための、出力に対して bbox の座標を用いて微分可能な Precise RoI Pooling を提案。
classification scoreとlocalization scoreの不一致についての具体例
![]()
(画像は本論文より引用)
IoU-Net アーキテクチャ
- RPNで検出される RoIに 小さい揺らぎを与え IoU を ground truth として IoU ブランチを学習。
![]()
(画像は本論文より引用)
IoU-guided NMS
- classification score でなく、localization confidence の高いものから優先した NMS(non-maximum suppression)。
- 通常の NMS と同様に thresholdを超えて重複ボックスを消す際は、classification scoreは高い方を採用する。
- 要するに結果として、 NMS で bounding box をマージする際、localization confidence, classification confidence の良い方を互いに採用し、bounding box は loacalization confidence が高いものを採用するということ。
![]()
Optimization-based bounding box refinement
- localizaton confidence score が最大となるように、勾配を用いて bounding box の座標の補正を行う。
- そのため 出力に対して bbox の座標を用いて微分可能な Precise RoI Pooling を提案。
Precise RoI Pooling
- bilinear でfeature map を補完して連続値の座標に対して特徴量の値を定義。その後連続座標に対して(average poolingの場合でいえば)積分して面積で割ることでpoolingを行う。
![]()
(画像は本論文より引用)
おわりに
今回は Object Tracking という分野におけるコンピュータビジョンに関する最新論文をご紹介しました。 冒頭でも述べましたが、Object Tracking はまだまだ発達途上な印象を受けます。今回紹介した Siamese network 系アプローチについても、ResNet 等のバックボーンの使用が Oral に取り上げられており、深いモデルによる特徴抽出の恩恵を享受することの難しさが分野の共通認識として存在していたことが感じ取られます。とはいえまだまだこれからも発達し様々な場面で利用されてくると考えられます。DeNA CVチームでは引き続き調査を継続し、最新のコンピュータビジョン技術を価値あるサービスに繋げていきます。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。