





Introduction
Hi, I am Hiroto Honda, an AI R&D engineer at DeNA Co., Ltd. Japan. The research engineers in my computer vision (CV) team survey and discuss the latest CV papers every day. This time, we would like to share a part of our survey results on cutting-edge computer vision papers. Authors: Plot Hong, Toshihiro Hayashi and Hiroto Honda .
Contents
- Quick Summary
- Scope of the survey
- What is Human Recognition?
-
Papers
- CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark (CVPR2019 Oral)
- Deep High-Resolution Representation Learning for Human Pose Estimation
- Monocular Total Capture: Posing Face, Body, and Hands in the Wild (CVPR2019 Oral)
- Parsing R-CNN for Instance-Level Human Analysis
- 3D Hand Shape and Pose Estimation from a Single RGB Image (CVPR2019 Oral)
- Conclusion
Quick Summary
- Five arXiv papers regarding human and hand pose estimation, markerless motion capture, and body part segmentation are surveyed
- Using a multi-person pose estimation method on a region of interest is effective for crowded scenes.
- Keypoint localization accuracy can be improved by taking advantage of high resolution features.
- 3D human pose and mesh are estimated from a monocular RGB image. In addition to 3D pose estimation methods, deformable 3D mesh model, graph CNN, and synthetic data are utilized.
Scope of the survey
The survey covers CV papers that were submitted to arXiv in November 2018 or later. We have picked the papers which we thought important and researched the details. In this report we introduce cutting-edge papers on human recognition, such as pose estimation.
What is Human Recognition?
In this report we introduce human recognition methods which aim at estimating human pose, human parts area or motion capture information using RGB images as input. The human recognition methods are grouped into two categories: top-down and bottom-up approaches. The top-down methods first detect the human instance regions and investigate each instance afterwards. The bottom-up ones first detect the body parts or joints in the whole image and group them afterwards. The methods we introduce this time are categorized as top-down approaches and single-person recognition. The following tasks are included in human recognition:
- Pose Estimation: a task to find and localize the human body parts such as eyes, shoulders and knees.
- Dense Human Pose Estimation: a task to localize dense body part points corresponding to the 3D model of human bodies.
- Markerless Motion Capture: a task to obtain motion capture output without using markers.
- Human Parsing: a segmentation task for body parts such as hair, face and arms.
The popular datasets used for human recognition are:
- MS-COCO is the de-facto dataset which includes annotations for object detection, segmentation, and keypoint detection.
- MPII, PoseTrack are the datasets for 2D keypoint detection.
- DensePose is the dataset for dense human pose estimation and includes body point annotation corresponding to the human 3D model.
- Human3.6M is the 3D human pose dataset.
- MHP is the dataset for human body part parsing.
- STB is the dataset for 3D hand pose estimation.
Papers
CrowdPose: Efficient Crowded Scenes Pose Estimation and A New Benchmark (CVPR2019 Oral)
Summary
An occlusion-robust pose estimation method, and the new dataset to better evaluate in crowded scenes
Proposed Method
Pose estimation pipeline
- YOLOv3 (*1) is adopted for human bounding box detector and AlphaPose (*2) used with modification as a single-person pose estimator (SPPE) within each box.
- AlphaPose originally calculates training loss on the single person's keypoints as ground truth even if another person's keypoints are within the target image. The proposed method calculates joint-candidate loss which takes all the keypoints within the image into account.
- The joints detected in all the regions are mapped on the input image. The keypoints which are detected more than twice in different ROIs and close to each other are grouped into joint nodes.
- All the joint nodes are grouped and integrated by persons at the Global Association step.
CrowdPose dataset
A new dataset called CrowdPose is introduced. The dataset contains 20k images and 80k human instances and the crowdedness of the images is controlled so that the newly introduced Crowd Index satisfies uniform distribution.
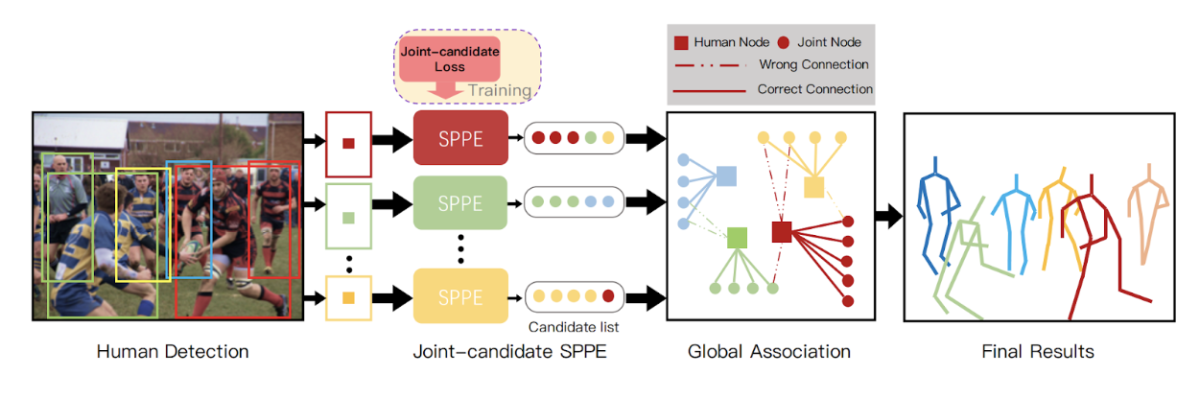
Figure A1: Pipeline of our proposed method. Single-person pose estimator (SPPE) estimates all the keypoints existing within the ROI. At the global association step all the keypoints detected in ROIs are grouped together by person.
Results
The relationship between the mean average precision (mAPs) of the de-facto methods and the Crowd Index on the COCO dataset is shown in Fig A2 (left). The mAP drops by 20 points from Crowd Index < 0.1 to > 0.9. When we look at the dataset, in the MSCOCO dataset (persons subset), 67.01% of the images have no overlapped person. On the other hand newly proposed CrowdPose dataset has uniform distribution of Crowd Index (Fig. A2 right).
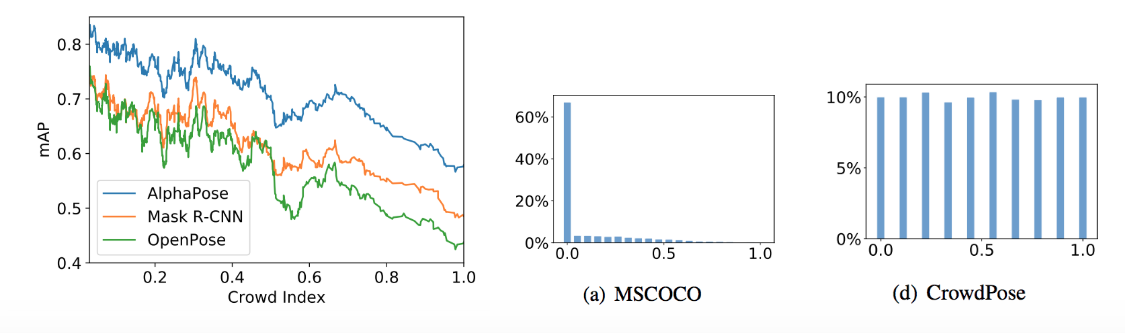
Figure A2: Relationship between Crowd Index and landmark average precision on COCO dataset (left), Crowd index distribution on MSCOCO (center) and CrowdPose (right).
The benchmark is carried out on the CrowdPose dataset (Fig. A3). The proposed method surpasses the popular methods such as OpenPose, Mask R-CNN, AlphaPose, and Xiao et al.’s method (*3).
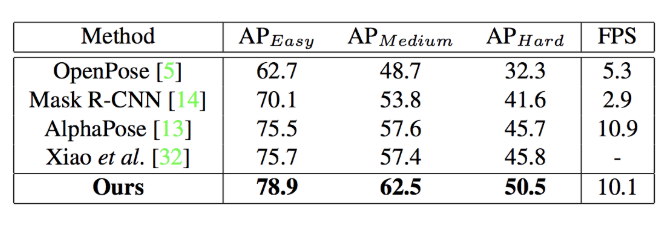
Figure A3: Benchmark results on the CrowdPose dataset.
The proposed method surpasses Mask R-CNN, AlphaPose and Xiao et al.’s method.
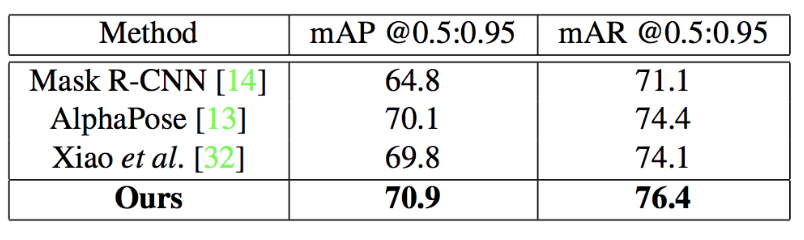
Figure A4: Benchmark results on MS-COCO test-dev.
Links
Paper: https://arxiv.org/abs/1812.00324
*1 a popular real-time object detection model proposed in 2018.
*2 AlphaPose: single-person pose estimation model and is also referred to as multi-person pose estimation (RMPE).
https://arxiv.org/abs/1612.00137
*3 the method of Xiao et al. was state-of-the-art when ‘Crowdpose’ was developed but had not been open-sourced yet. The authors seem to have re-implemented Xiao et al.’s method. Crowdpose uses YOLOv3 as a human region detector to compare with the method. PyTorch repo open-sourced in Aug. 2018:
https://github.com/Microsoft/human-pose-estimation.pytorch
Deep High-Resolution Representation Learning for Human Pose Estimation
Summary
A strong and accurate single-person pose estimation network which maintains high-resolution representations through the whole process.
Proposed Method
Existing single-person pose estimation (SPPE) methods rely on the high-to-low (downsampling) and low-to-high (upsampling) framework, such as theHourglass network or U-Net. The proposed High-Resolution Net (HRNet) is composed of Parallel multi-resolution subnetworks, where high-resolution representations are maintained through the whole process. As shown in Fig. B1, the feature maps at scale 1x are maintained and interact with the other scales. This network design enables spatially precise keypoint heatmap estimation. The input image goes through two convolution layers with stride=2 before entering HRNet, which means the input feature map is at 4x scale compared with the input image. Therefore the 1x, 2x, 4x, and 8x scales in HRNet shown in Fig. B1 correspond to 4x, 8x, 16x, and 32x scales respectively. The channel widths of the feature maps at the four scales are 32, 64, 128, and 256 respectively (HRNet-W32 setting). The feature maps of different scales are integrated (summed up) after being upsampled by strided 3x3 convolution or downsampled by 1x1 convolution and nearest neighbor operation. The final layer of the network still consists of feature maps at four scales, and only 1x-scale feature map which empirically has highest accuracy is used as output. The loss function is the mean square error with ground-truth keypoint heatmaps.
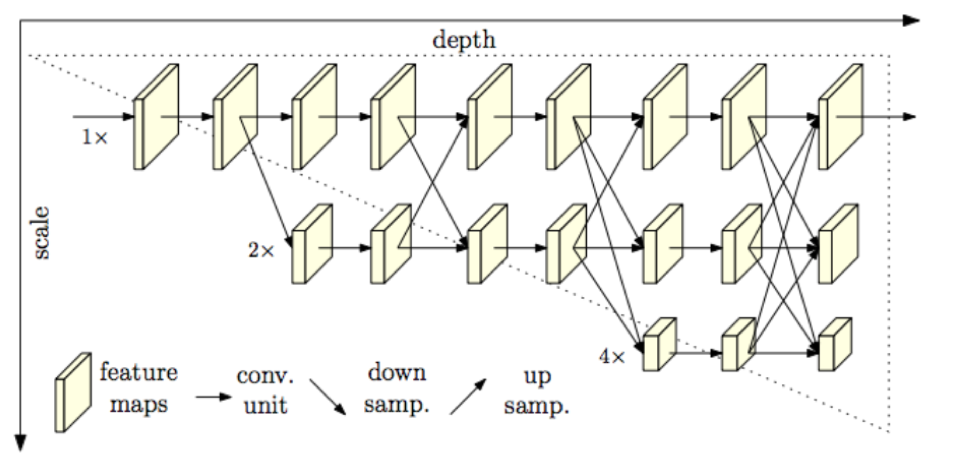
Figure B1: Proposed HRNet. 1x, 2x, and 4x scales in the figure correspond to 4x, 8x and 16x scale compared with the input image.
Results
Multi-person pose estimation results using HRNet outperforms the Simple Baseline method (ECCV Posetrack challenge 2018 winner) and significantly improved precision-speed tradeoff as shown in Fig. B2. The computation complexity comparison between network components of HRNet and Simple Baseline with ResNet50 + deconvolution upsampling is shown in Figure B3. The total computation complexity of HRNet is 7GFLOPs, smaller than 9GFLOPs (Simple Baseline), which is because upsampling layers that have the dominant (~60%) computation cost are integrated in HRNet. Fig. B4 shows the visualization results of HRNet on MPII and COCO dataset. Benchmark results on COCO test-dev dataset is shown in Fig. B5. The HRNet achieves 75.5% AP, which is significantly higher than existing popular methods: OpenPose 61.8%, Mask R-CNN 63.1%, Cascaded Pyramid Network (CPN) 73.0%, Simple Baseline 73.7%, and also higher than CrowdPose (70.9%). HRNet achieves the best accuracy on PoseTrack dataset as well.
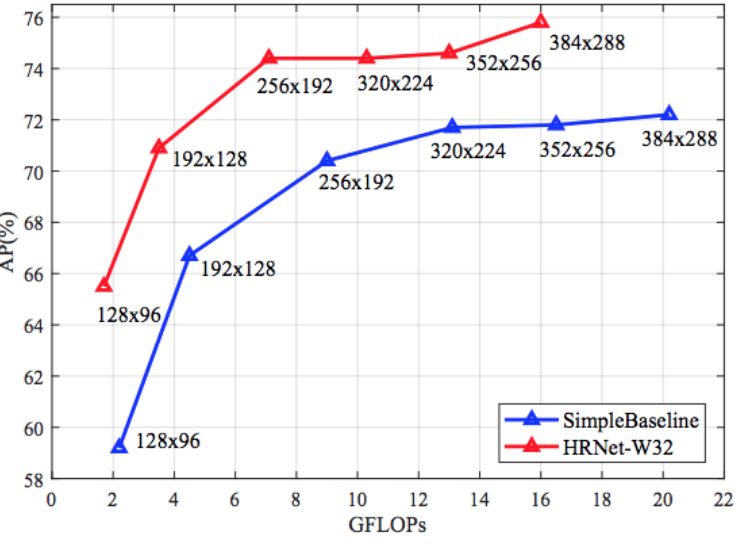
Figure B2: Comparison between SimpleBaseline on tradeoffs between average precision and computation cost.
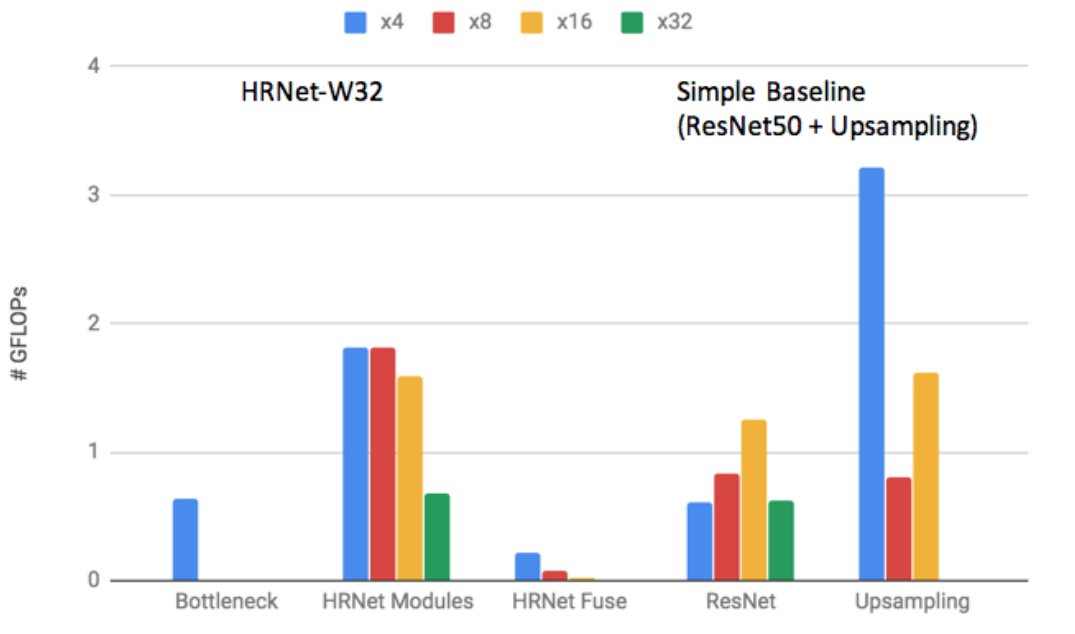
Figure B3: Computation complexity comparison between network components of HRNet and Simple Baseline (ResNet50).

Figure B4: visualization results on MPII (top) and COCO (bottom) datasets.
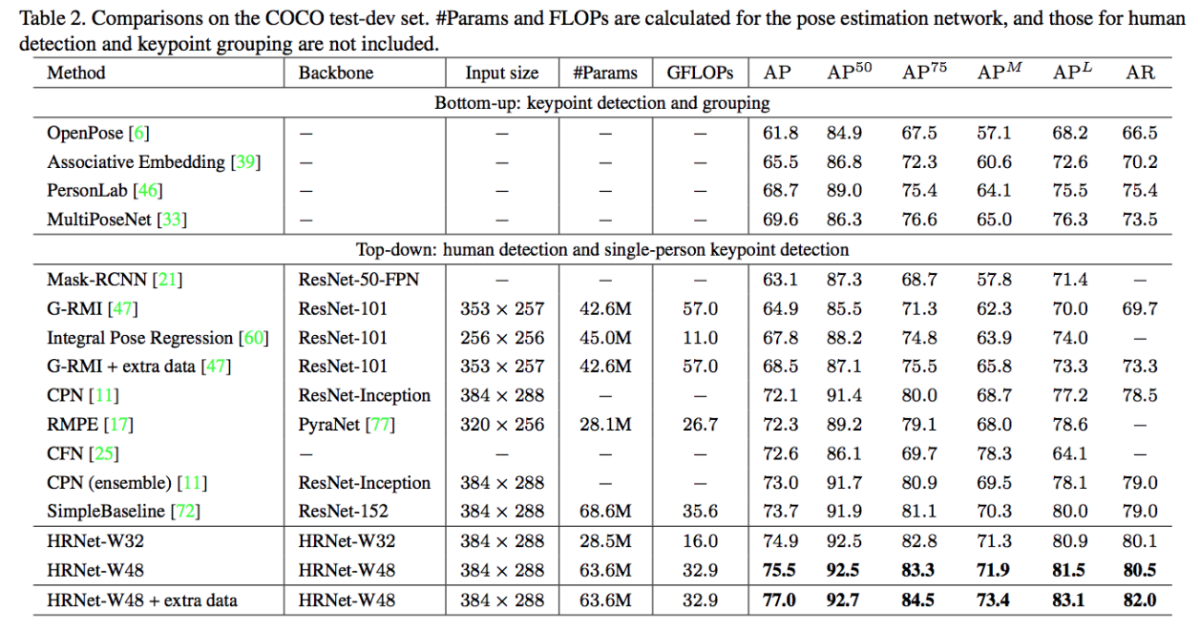
Figure B5: benchmark results on COCO test-dev.
Links
Paper:
https://arxiv.org/abs/1902.09212
PyTorch implementation:
https://github.com/leoxiaobin/deep-high-resolution-net.pytorch
Monocular Total Capture: Posing Face, Body, and Hands in the Wild (CVPR2019 Oral)
Summary
A markerless motion capture method to extract the motion of body, face, and fingers from a monocular image or video using a 3D deformable mesh model.

Figure C1: 3D total body motion capture results from monocular images.
Proposed Method

Figure C2: Total capture pipeline of the proposed Method which consists of CNN part, mesh fitting part, and mesh tracking part.
Proposed pipeline consists of three stages as shown in Fig. C2.
- CNN part: an input image at the ith frame is fed to CNN to obtain joint confidence maps and part orientation fields which represents 3D orientation information of body parts.
- Mesh fitting part: estimates human motion by adjusting the parameters of the deformable 3D mesh model frame by frame. The 3D mesh model proposed in Total Capture is used.
- Mesh tracking part: improves temporal consistency across frames by using the image and the parameters of the mesh model at (i - 1)th frame.
Part Orientation Fields L represents the 3D vectors between keypoints as shown in Fig. C3, which is similar to Part Affinity Field used in OpenPose.
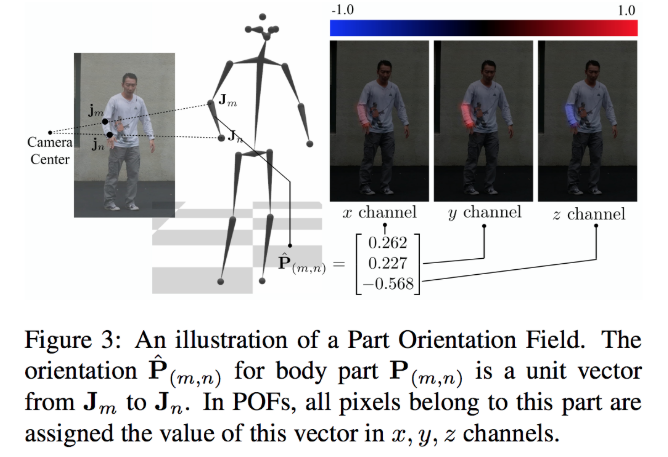
Figure C3: Part orientation field. The 3D vectors between keypoints are inferred as a heatmap.
The new dataset is collected using CMU Panoptic Studio . 834K body images and 111K hand images with corresponding 3D pose data are obtained (not available so far).
Results
The proposed single framework achieves comparable results to existing state-of-the-art 3D body pose estimation or hand pose estimation methods as shown in Fig. C4 and C5.

Figure C4: Benchmark results of 3D pose estimation on Human3.6M dataset.
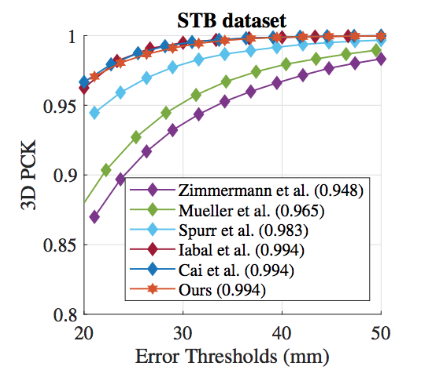
Figure C5: Benchmark results of 3D hand pose estimation on STB dataset.
Links
Paper:
https://arxiv.org/abs/1812.01598
Video:
https://www.youtube.com/watch?v=rZn15BRf77E
Parsing R-CNN for Instance-Level Human Analysis
Summary
A high-accuracy R-CNN method for human instance recognition tasks such as human body parts parsing and Dense Pose estimation.
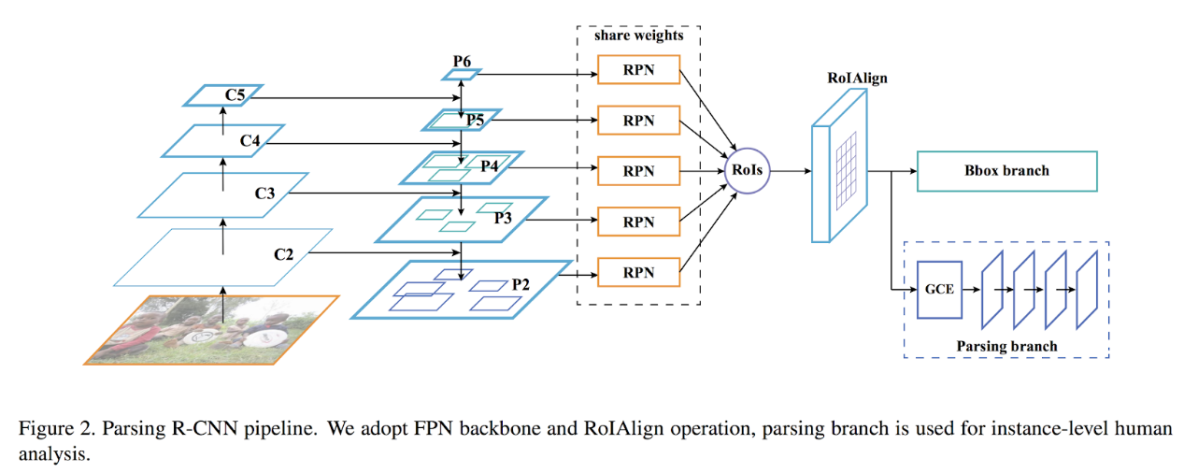
Figure D1: The Parsing R-CNN pipeline. Feature Pyramid Network is used as backbone and Bbox branch and Parsing branch are applied to cropped ROIs.
Proposed Method
- Feature extraction part: a similar structure as Feature Pyramid Network (FPN) is employed, except that proposals separation sampling (PSS) is used for cropping. PSS selects the ROI proposed by the Region Proposal Network (RPN) only from the P2 scale that has the highest spatial resolution.
- Bbox Branch: bounding box regression is carried out for cropped ROIs.
- Parsing branch: newly proposed Geometric and Context Encoding (GCE) module is adopted to perform human body parts parsing or dense pose estimation on the ROIs. GCE is composed of Atrous spatial pyramid pooling (ASPP) (*1) to capture features with an enlarged receptive field, and a Non-local Neural Network(*2) to integrate non-local features. Both ASPP and the Non-local part contribute to improving accuracy. Four convolution layers are inserted after GCE, which is empirically better than before GCE. (Figure D1).
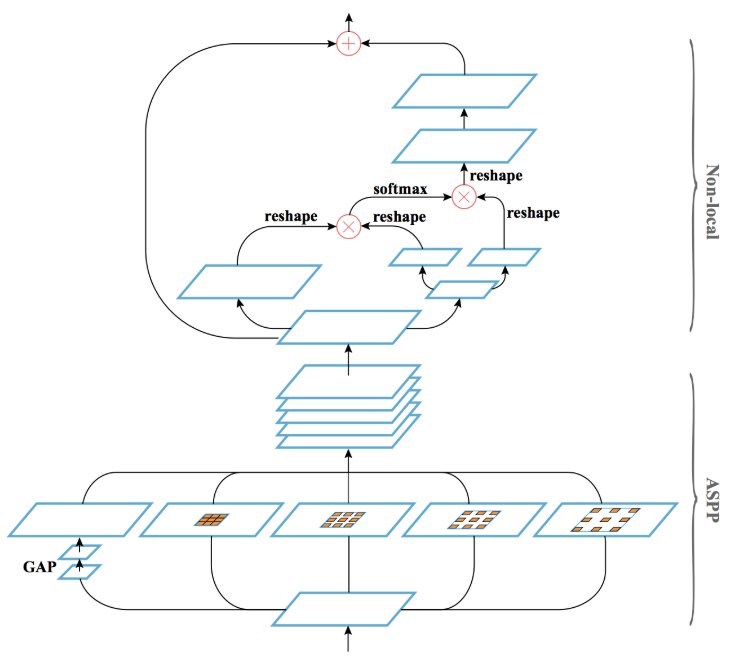
Figure D2: Geometric and Context Encoding module that is the part of Parsing branch shown in Fig. D1.
Results
The proposed method outperforms all state-of-the-art methods on CIHP (Crowd Instance-level Human Parsing), MHP v2.0 (Multi-Human Parsing) and DensePose-COCO benchmarks (Figure D3 and D4).

Figure D3: (a) input image (b) Inference result on DensePose task (c) input image (d) Human Parsing Results
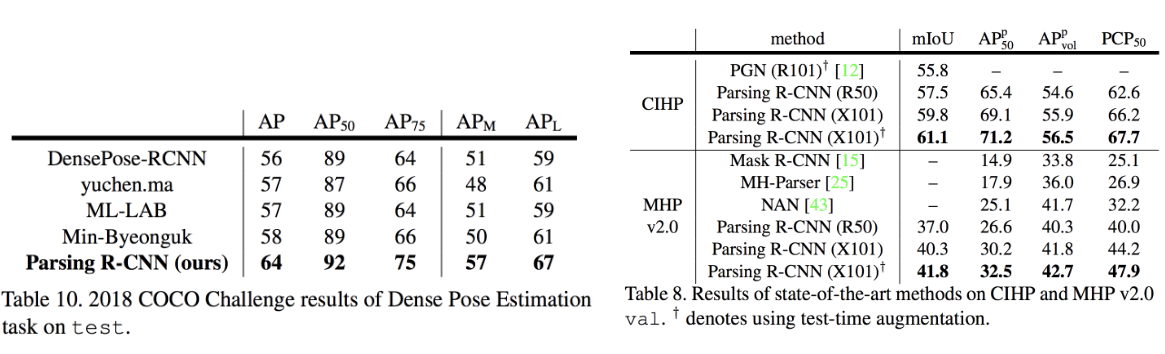
Figure D4: 2018 COCO Dense Pose challenge results (left), human parsing benchmark results on CIHP and MHP datasets (right)
Links
Paper: https://arxiv.org/abs/1811.12596
*1 Atrous spatial pyramid pooling is the module that can improve semantic segmentation performance. By operating dilated convolutions with different dilation rates in parallel, the receptive field of the network is enlarged. paper:
https://arxiv.org/abs/1802.02611
*2 Non-local Neural Network is the method to integrate similar but non-local features. paper:
https://arxiv.org/abs/1711.07971
3D Hand Shape and Pose Estimation from a Single RGB Image (CVPR2019 Oral)
Summary
3D hand pose and 3D mesh estimation from an RGB image, which can run in real-time on GPU at over 50fps (Fig. E1).
Proposed Method
This paper proposes a 3D hand mesh and pose estimation method from a single RGB image utilizing Graph CNN and synthetic data. The 3D mesh data have the graph structure by nature, which is why Graph CNN is effective. Synthetic data are used for training because 3D mesh annotation is extremely laborious and costly. More specifically, the network is trained under supervision of synthetic data with 3D mesh annotations and fine-tuned with weak supervision by the RGBD real-world data. 3D hand joint locations are regressed from the reconstructed 3D hand mesh by using a simplified linear Graph CNN (Fig. E2).
Pipeline(Fig. E2, E3)
- 2D heatmap estimation using stacked hourglass network
- ResNet encodes the heatmap and the image features into latent feature vectors
- 3D mesh inference from the latent feature vectors by Graph CNN
- 3D keypoints estimation from the 3D mesh by Linear Graph CNN
Loss functions for training on synthetic data:
- heat-map loss: keypoint estimation loss on the 2D images
- 3D pose loss: L2 loss of 3D keypoint estimation
- mesh loss: composed of four losses - vertex loss, normal loss, edge loss and Laplacian loss.
Loss functions for fine-tuning on real data:
- heat-map loss: the same as the one on the synthetic data.
- depth map loss: smooth L1 loss between ground truth and the depth maps rendered by differentiable renderer from the mesh.
- pseudo-ground truth loss: pseudo-ground truth mesh is generated using the pretrained models and the ground truth heat-maps. Edge loss and the Laplacian loss are applied as the pseudo-ground truth mesh loss to guarantee the mesh quality.
Results
Although there are no existing methods where 3D mesh is reconstructed from RGB images, the method can produce accurate and reasonable 3D hand mesh compared with baseline methods. As for 3D hand pose estimation, the method outperforms state-of-the-art methods (Fig E4). On STB dataset, higher AUC than Monocular Total Capture is achieved. The pipeline can run at 50FPS on GTX 1080.

Figure E1: Inference results by the proposed methods. Not only 2D / 3D keypoints but also 3D mesh are generated. Results on the synthetic dataset (top), on the real-world dataset (center) and on the STB dataset (bottom).
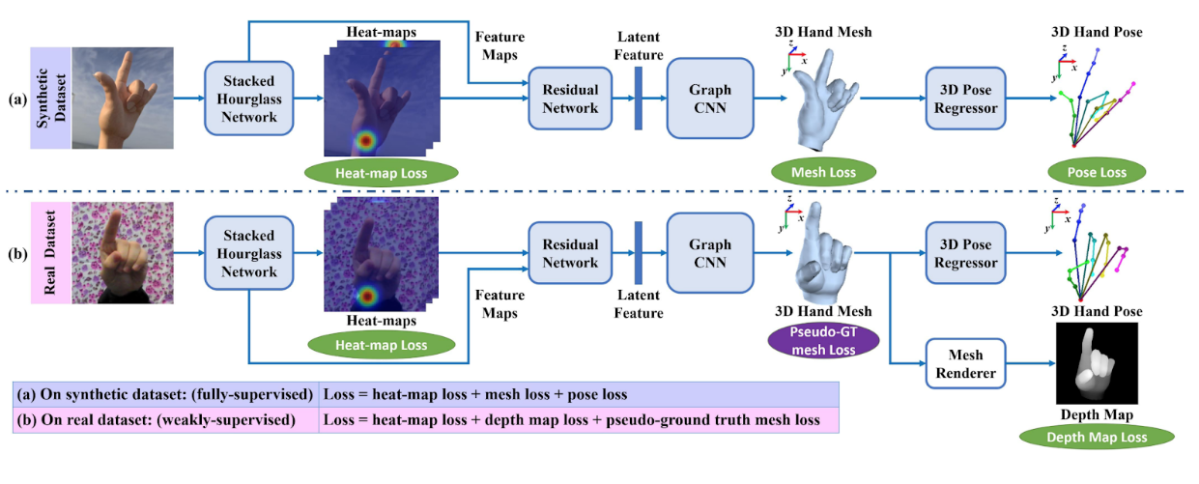
Figure E2: Training pipeline of the proposed method. (a) fully supervised training on the synthetic dataset and (b) fine-tuning on the real image dataset without 3D mesh or 3D pose ground truth in a weakly-supervised manner.
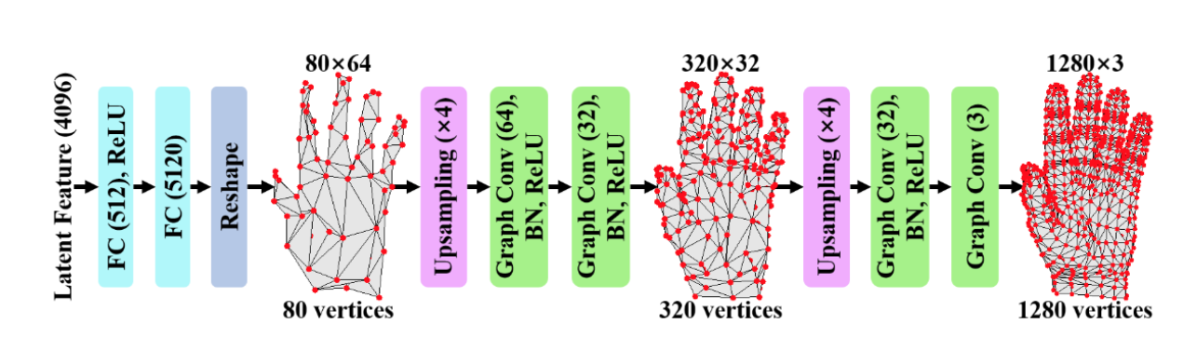
Figure E3: Graph CNN architecture which generated 3D hand mesh from a latent feature vector.
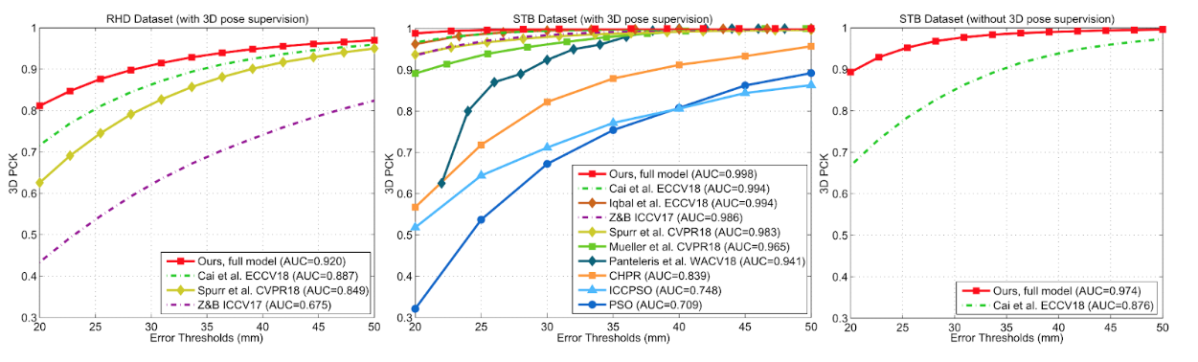
Figure E4: Benchmark results. Results on the RHD dataset (left), on the STB dataset (center), and on the STB dataset without 3D hand pose supervision (right).
Links
Paper: https://arxiv.org/abs/1903.00812
Conclusion
In this report, we have introduced the latest papers regarding human recognition, specifically pose estimation, hand pose estimation, markerless motion capture, and body part segmentation.
Human pose estimation is getting more and more accurate and able to detect the keypoints that are occluded by other instances. Using a multi-person pose estimation method on a region of interest is effective for crowded scenes. Keypoint localization accuracy can be improved by taking advantage of high resolution features.
3D human (hand) pose and mesh are estimated from a monocular RGB image. In addition to 3D pose estimation, deformable 3D mesh model, graph CNN, and synthetic data are utilized.
Further progress will be made on human recognition techniques and novel attempts and applications will appear every year. We will keep updated on the cutting-edge research to innovate our products and services.




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。