





はじめに
こんにちは、AIシステム部でコンピュータビジョンの研究開発をしております本多です。 我々のチームでは、常に最新のコンピュータビジョンに関する論文調査を行い、部内で共有・議論しています。今回我々が読んだ最新の論文をこのブログで紹介したいと思います。
今回論文調査を行なったメンバーは、林 俊宏、本多 浩大です。
論文調査のスコープ
2018年11月以降にarXivに投稿されたコンピュータビジョンに関する論文を範囲としており、その中から重要と思われるものをピックアップして複数名で調査を行っております。今回はキーポイント検出の手法を用いた物体検出に焦点を当て、最新論文を取り上げます。
Short Summary
- CornerNet (ECCV18) の改良版と言える、キーポイント検出ベースの物体検出手法が続々と提案されている。
- いずれも検出ターゲット矩形の端や中央を、ヒートマップを用いて検出する手法である
- Single-shot型 (bottom-up) とTwo-stage型 (top-down) に分かれる
- いずれもCornerNetと同等ないし高い精度を示している
- Object as Points (CenterNet) の精度と速度のトレードオフ性能 (speed-accuracy trade-off) の高さが目立つものの、他手法とフェアな比較はできていない
図1は本稿で取り上げる各手法の検出点比較である。

図1: 各手法の検出点比較。(a) Faster R-CNNやYOLOなどアンカーを基準にboxを学習する手法 (b) CornerNet (c) Objects as Points (CenterNet) (d) CenterNet: Keypoint Triplets for Object Detection (e) Bottom-up Object Detection by Grouping Extreme and Center Points (f) Grid R-CNN
前提知識
物体検出
画像から物体の位置を矩形 (bounding box) として検出し、かつそれぞれの物体の種類(クラス)を分類するタスクです。- Faster R-CNN: 画像から特徴マップを抽出し、Region Proposal Networkで物体の存在する領域を検出、それぞれクロップしてHead Networkにて詳細な位置推定とクラス分類をおこなう。物体検出のデファクトスタンダード。
- Feature Pyramid Network (FPN): Faster R-CNNにおいて、複数のスケールでRegion ProposalおよびHead Networkの実行を行うことで、高精度に小さな物体を検出する。
- RetinaNet : FPNにおけるRegion Proposal Network部において、bounding boxの位置検出とクラス分類を完結することで高速化をはかっている。Single-shot検出器と呼ばれ、YOLOと同種の検出器にあたる。
キーポイント検出を用いた物体検出
今回、キーポイント検出の手法を物体検出に用いている論文を取り上げます。これら論文の源流となるのはECCV2018で発表されたCornerNetです。- CornerNet : bounding boxの座標を回帰によって学習するのではなく、左上と右下隅をキーポイントと見立てたヒートマップを学習する。人物姿勢認識におけるキーポイント検出にヒントを得ている。推定されたキーポイントは、embedding vectorの照合によりグルーピングする。
- Hourglass Network : ResNetなどのネットワークでスケールダウンしながら特徴抽出したのちに、アップサンプリング層によってスケールアップする、砂時計型のネットワーク。
関連するデータセット
MS-COCO 物体検出・セグメンテーション・人物姿勢等のラベルを含むデータセットで、recognition系のタスクではデファクトスタンダード。
参考:弊社エンジニアによるサマリー。本稿で取り上げる論文も紹介されている。
最近の物体検出
CVPR 2019 report
性能比較
今回紹介する4論文と、ベースラインとなるCornerNet及びRetinaNetとの性能比較を表1に示す。全ての論文をフェアに比較することは困難であるが、いずれも単一スケールでのテストに揃えて比較した。特に性能にインパクトがあると思われる実験条件をbackbone、他条件に記載した。
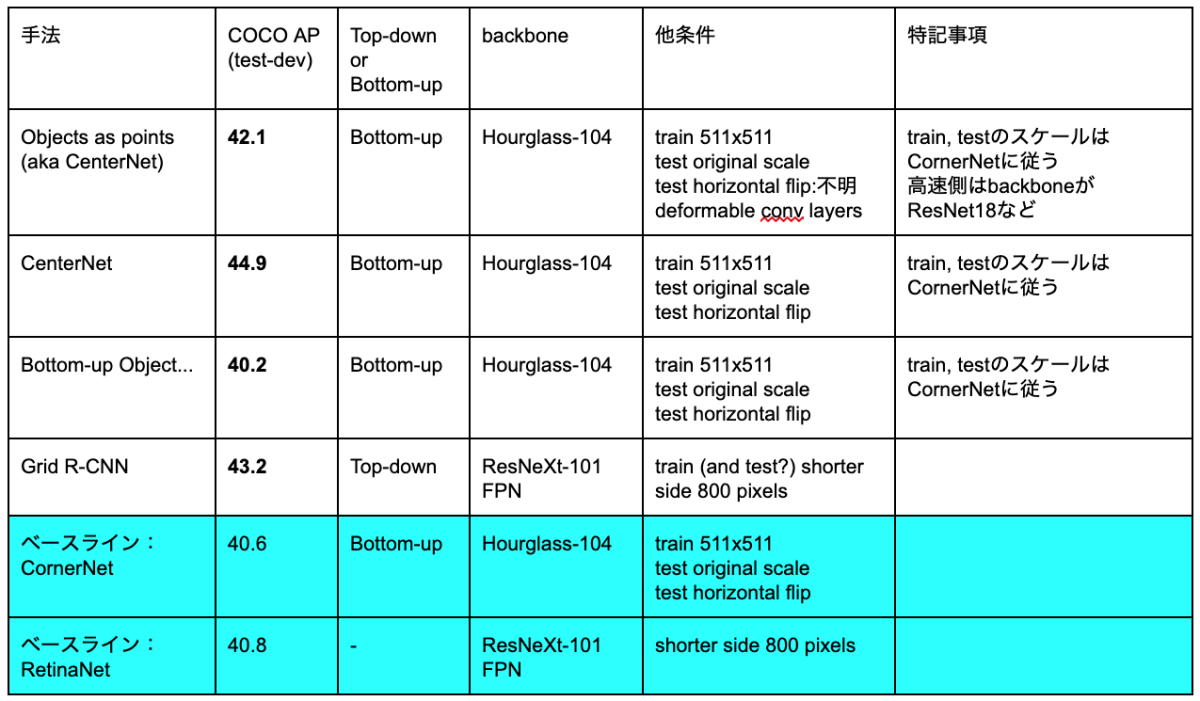
表1: COCO test-devによる各手法の性能比較。
論文紹介
Objects As Points
要約
bounding box中心のみをヒートマップで予測、大きさ・オフセット・クラスは各位置で回帰、速度と精度の良いトレードオフを実現する。
提案手法
クラスごとにbounding box中心をヒートマップとして学習する。Backboneは高速側から、ResNet18+upsampling, DLA34 [2], ResNet101, Hourglass104を用いている。upsamplingレイヤとしてbilinear inetrpolationとconvolutionを用いている。single-scale の高解像度特徴マップをヒートマップ出力に使う。
各グリッドではクラスごとの確率に加え, bounding boxサイズ及びグリッドからのオフセットを回帰学習する(図A1)。推論時は、各グリッドの近傍8グリッドと比較して最大または等しいconfidence値となる100のグリッドをピックアップする 。ピックアップされた複数のアンカーを用いるYOLOv3と異なり、アンカーが存在せず、bounding boxサイズを直接、クラス毎に出力する。
Lossの定義は
- ヒートマップ:CornerNet と同様、 focal loss の亜種を用いる。
- 中心のオフセット:L1 loss
- bounding boxサイズ:L1 loss
bounding boxのサイズ・オフセット推定チャンネルをタスクに応じて変更することで、3D bounding boxの推定や人姿勢推定にも適用できる(図A2)。
その他 Non-Maximum Suppression (NMS) を行っても精度が大きく変化しなかったため不使用。 ResNetとDLAでは、deformable convolutionレイヤをupsampling部に用いている。deformableレイヤはAP向上に寄与していると思われるが、本論文ではablation studyは行われていない。
結果
backbone 等の変更により精度-速度(レイテンシ)のトレードオフを測定、YOLOv3などの従来手法よりもトレードオフが改善した(図A3)。COCO test-devの評価では、高精度側でもCOCO AP=42.1 (single scale test) を示した(表A1)。
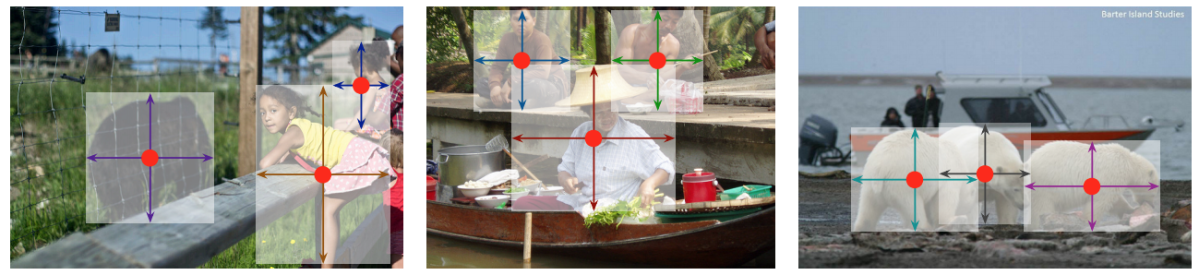
図A1:CenterNet手法の紹介。centerキーポイントの特徴としてbounding boxのサイズなどを学習させる([1]より引用)
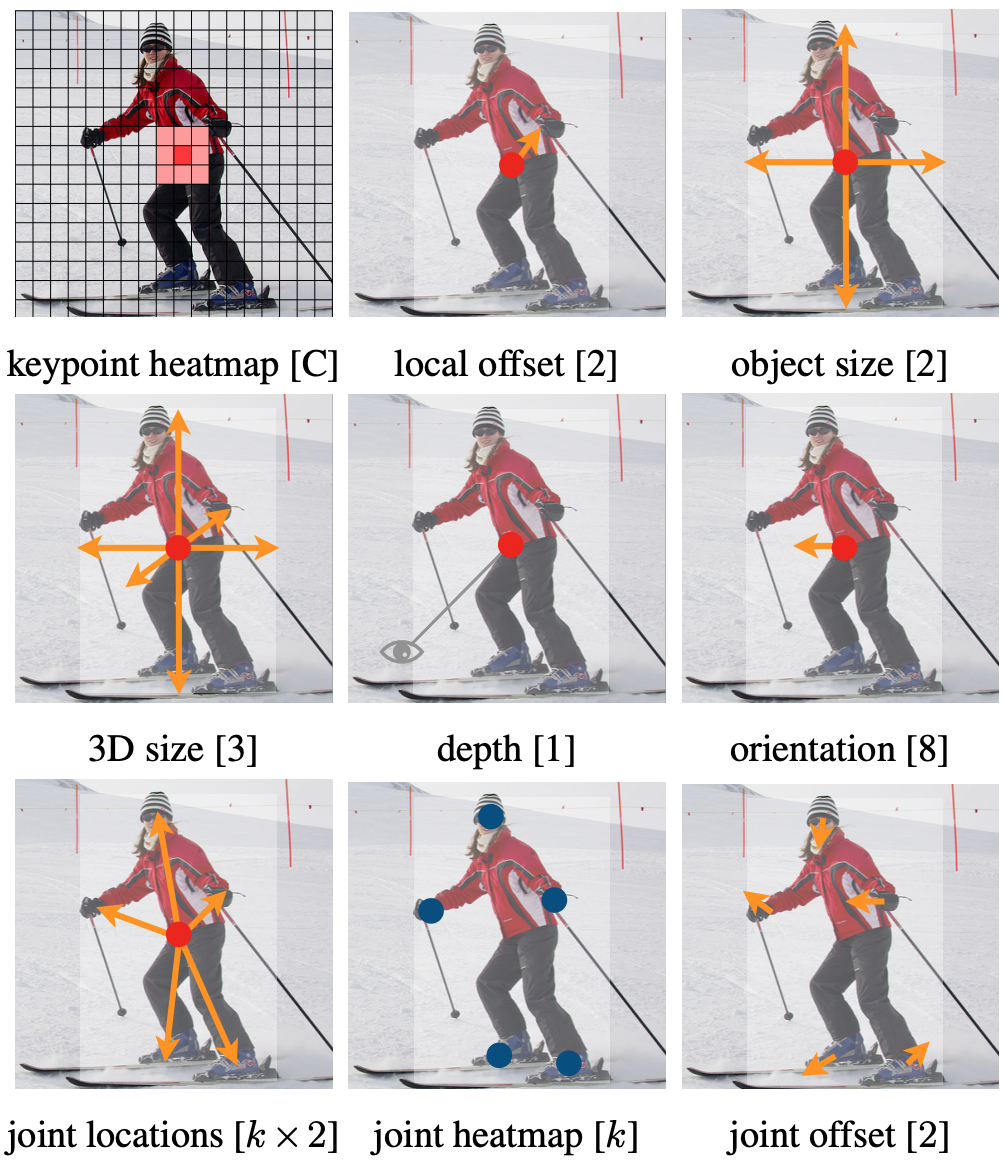
図A2:CenterNetの様々なタスクへの応用。上段:物体検出 中段:3D物体検出 下段:キーポイント検出([1]より引用)
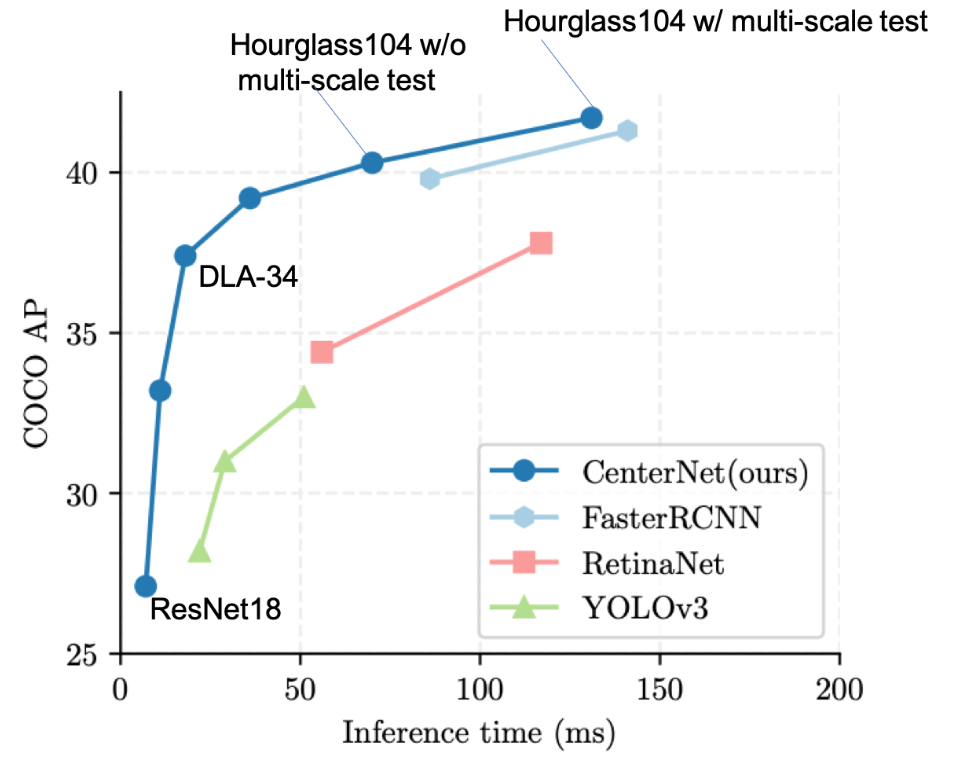
図A3:backboneネットワークやテスト条件を変化させたときの、推論時間とCOCO val APのトレードオフ。([1]より引用)
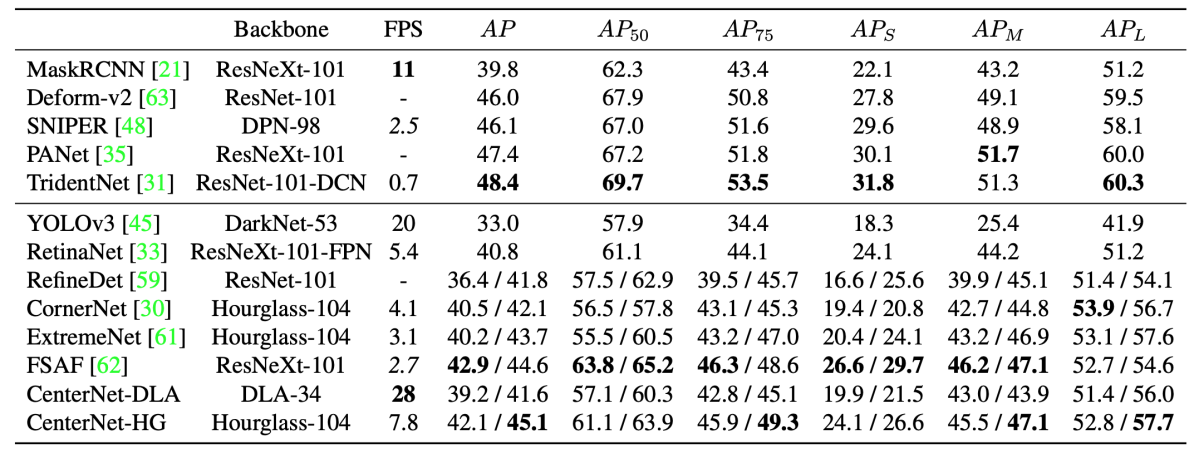
表A1:COCO test-devによるstate-of-the-art検出器との比較評価結果。上がtwo-stage、下がone-stage検出器。APが二種類記載されているものは、single-scale / multi-scale test を表す。([1]より引用)
リンク
[1]
https://arxiv.org/abs/1904.07850
[2] DLAネットワーク:
Deep Layer Aggregation
CenterNet: Keypoint Triplets for Object Detection
要約
CornerNet の改良版であり、コーナーだけでなく中心も予測することで正確性を向上する。
提案手法
CornerNetによって検出されたbounding boxには誤検出が多く、正解との重なり (IoU) が5%の条件においても32.7% がFalse Detectionとなっていた。一方2-stage detectorのようにROI poolingを用いると計算量が大きくなる。本論文では、図B1のように、CornerとCenterを照合することにより検出の正確性を向上する。また、CornerとCenterの3点のembedding情報のみをpoolingするため、ROI poolingのように計算量が大きくならない。
cascade corner pooling CornerNetで提案されているcorner pooling を、 bbox の端だけでなく内部も見るように cascade poolingとして改良する(図B2)。得られたembedding情報はcornerのグルーピング、およびオフセット推定に用いる。
center pooling CornerNetに対し、boxの中心を予測するheadネットワークを追加、corner pooling同様のcenter poolingによってembedding情報を得る(図B2)。このembedding情報は、cornerと異なりグルーピングには使用せず、中央点のオフセット推定にのみ用いる。
Loss lossは以下のように定義される。CornerNetにて提案されているlossに対し、中央点の項が追加されている。
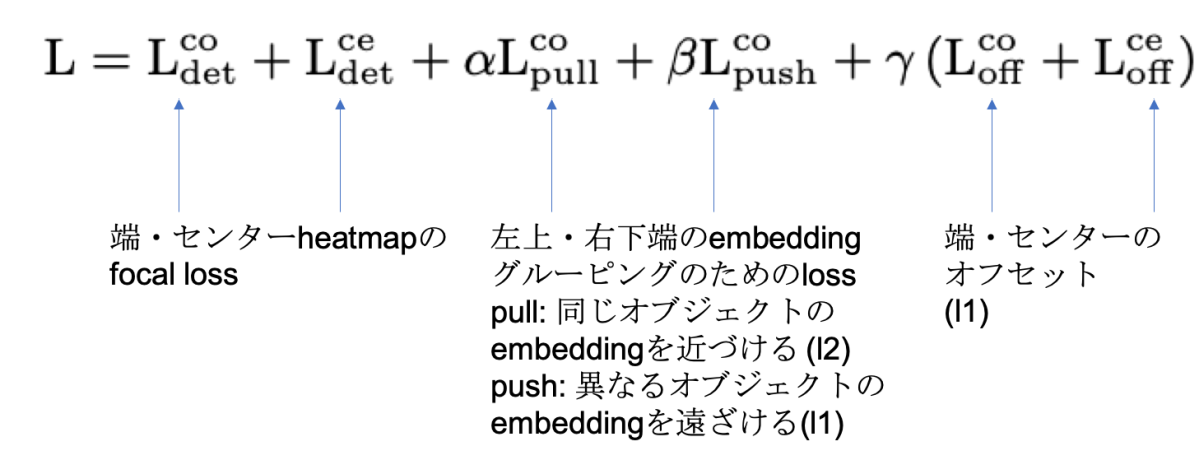
Inference時 Cornerのペアから予想される領域にCenterがあるかどうかでTripletを組み合わせる。
結果
CornerNet と同条件 (Hourglass101, single scale) で比較すると、COCO APが40.5 -> 44.9と大きく改善している(表B1)。
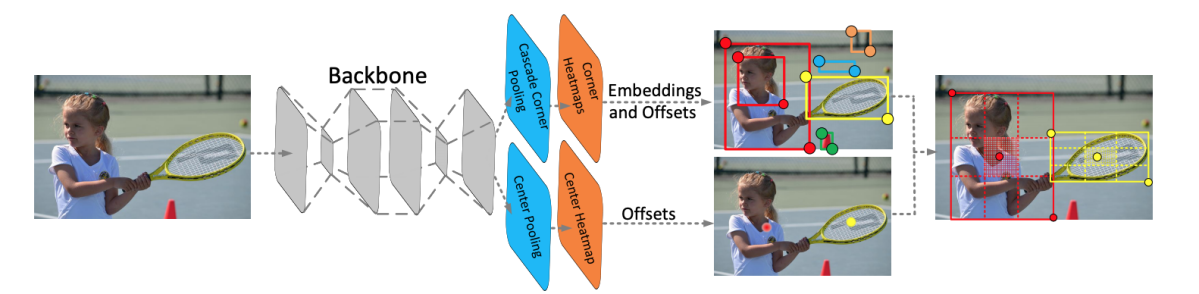
図B1 : CenterNetの全体構成図。上段がCornerブランチ、下段がCenterブランチ、最終的に統合する。([3]より引用)
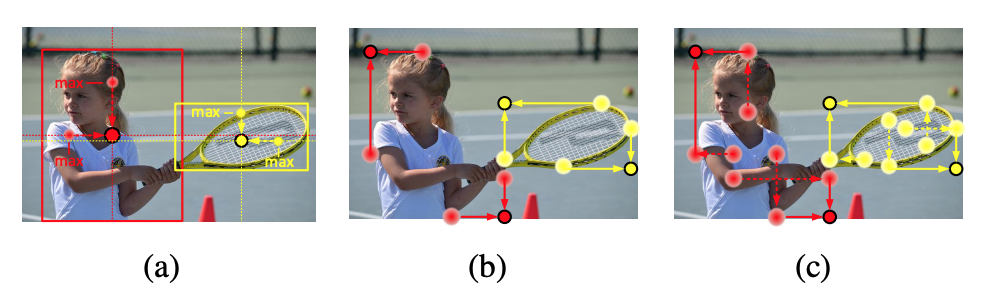
図B2 : Center Pooling(左)、Corner Pooling(中央)、およびCascaded Corner Pooling(右)([3]より引用)
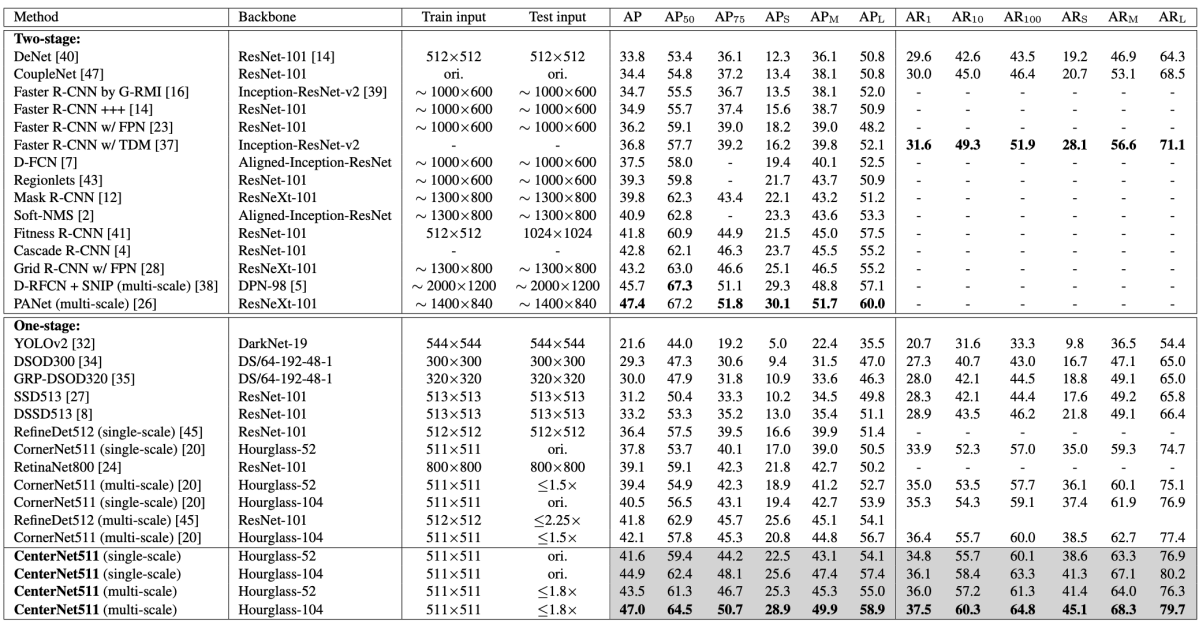
表B1 : COCO test-devによるベンチマーク結果。CenterNet511はsingle-scale testにおいて COCO AP = 44.9となっている([3]より引用)
リンク
[3]
https://arxiv.org/abs/1904.08189
Bottom-up Object Detection by Grouping Extreme and Center Points
要約
画像中の複数オブジェクトの上下左右の端点及び中央をヒートマップで求め、上下左右点と中央点を照合することでボトムアップでboxをグルーピングする。
提案手法
- Ground truthとして、bounding boxだけではなくinstance segmentation labelを用いる。boxとsegmentationマスクから、上下左右の端点と中央の正解座標を求める。
- Hourglassネットワークで画像全体から上下左右点・中央点のヒートマップを学習する(図C1)。
- 推論時には、上下左右点の組み合わせごとに、該当する中央点があるかどうかを照合し、スコアが高い場合にグルーピングする(図C2)。
- 端点と中央点を照合するという発想は、上述のCenterNet: Keypoint Triplets for Object Detectionと類似している。
結果
COCO test-devの結果、single scale同士だとCornerNetと同等のAP=40.2であり、multi-scaleではCornerNetを上回るAP=43.7となった(表C1)。 推論時に、端点を利用した多角形表示をすることも可能である(図C3)。
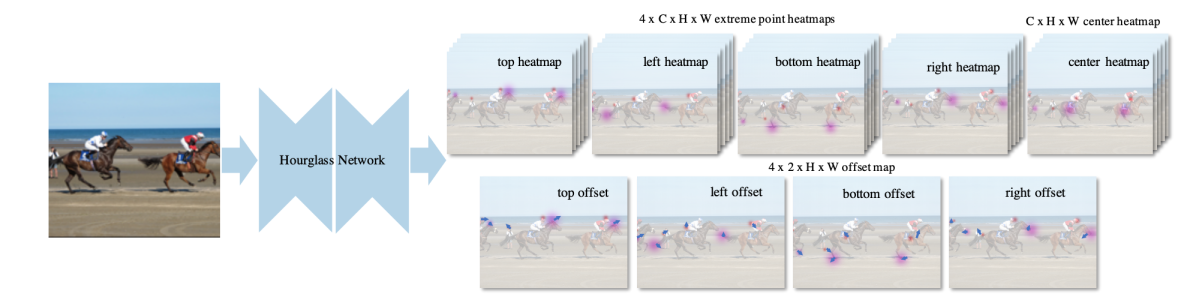
図C1: 推定フレームワーク。([4]より引用)
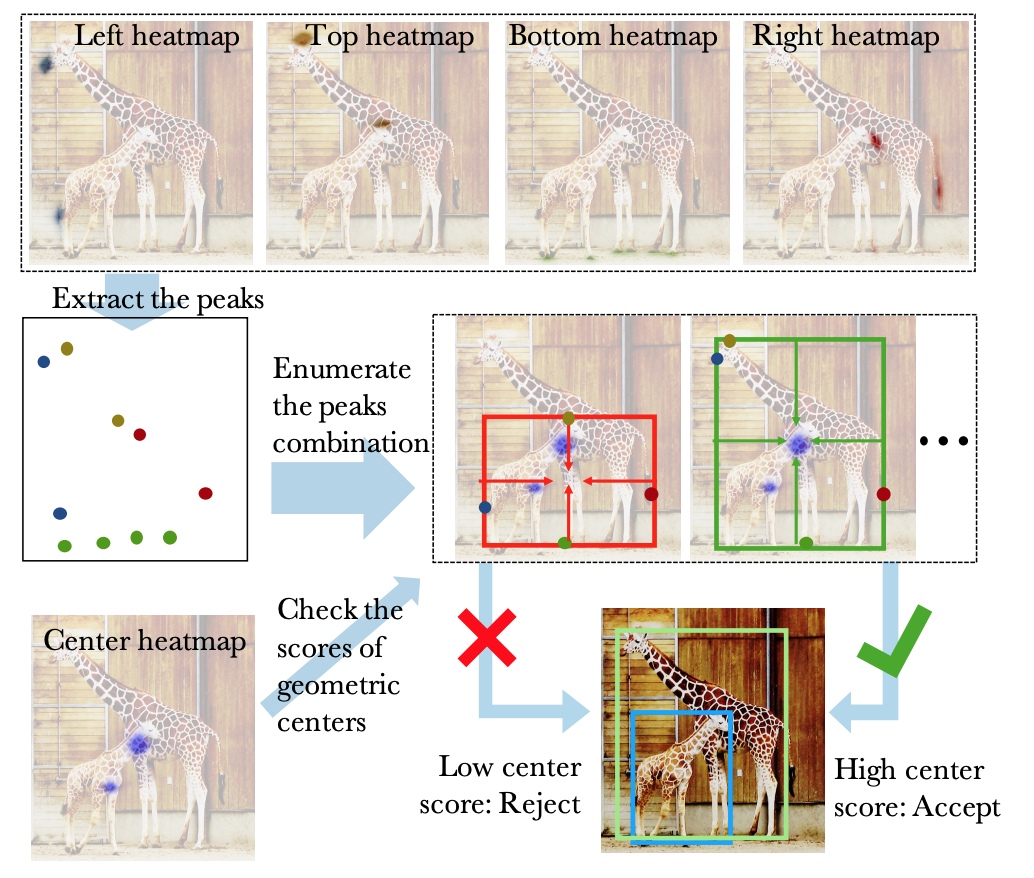
図C2: 推定された上下左右・中央のヒートマップから、bounding boxを決定するまでの流れ。([4]より引用)
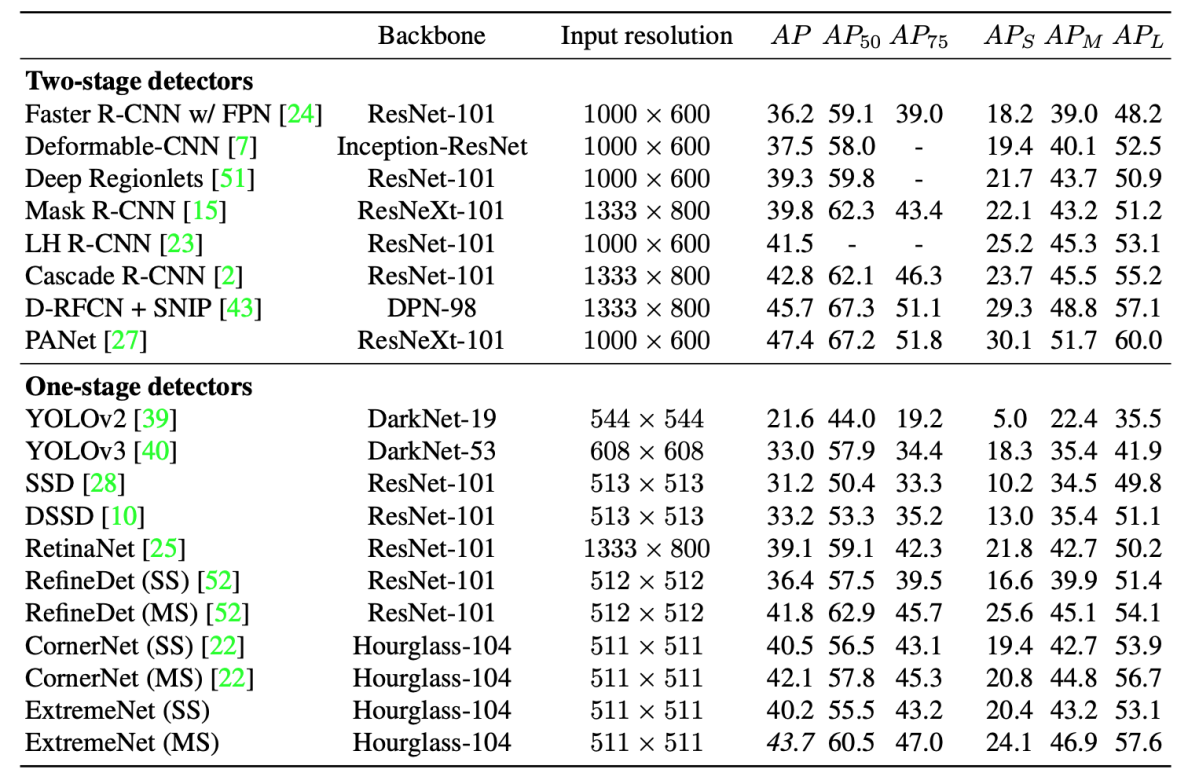
表C1: COCO test-devでの結果。SS=single scale test, MS=multi-scale test。SS同士ではCornerNetと同等のAPとなっている。([4]より引用)

図C3: 推論結果。([4]より引用)
リンク
[4]
https://arxiv.org/abs/1901.08043
Grid R-CNN
要約
2ステージ物体検出において、box座標をRegressionするかわりに、Boxのグリッド点をヒートマップで学習する。
提案手法
図D1のように、入力画像に対してbackboneネットワークで特徴抽出、Region Proposal NetworkおよびROIAlignでROIクロップをおこなう。ここまではMask R-CNNと同じである。
grid prediction branch:クロップしたfeature map (14 × 14) に対し、8層のdilated convolution層、および2層のdeconvolution層を経て、56 x 56 x (N x N) のfeature mapを得る。N x N はグリッドの点数であり、標準は3 x 3である。Ground Truthは正解グリッド点を中心とする+型の5画素がpositiveとされており、推定されたヒートマップとのBinary Cross Entropy Lossにより学習される。
アップデート版として公開されたGrid R-CNN plus [6]では、56 x 56のうち、実際にグリッド点が存在する28 x 28のみに限定して用い、またdeconvolutionをdepth-wiseとすることで高速化をはかっている。
feature fusion module(図D2):隣接するgrid点には空間的相関がある。feature fusion moduleでは隣のgrid点を用いてgrid featureを修正する。Fiを注目するgrid点のfeatureとすると、近隣のFjに対しいくつかの5x5 convolution層を通し、Tj->i(Fj)を作る。Fiとそれらの和を最終的なgrid featureとする。
推定時は、得られた各グリッドヒートマップにおいて、最大値をとる座標がピックアップされて元画像にマッピングされる。
結果
ResNeXt-101 Feature Pyramid Networkを用いた場合、COCO test-dev APが43.2となった(表D1)。 Faster R-CNNと同条件で比較すると、特に高IoUのAP (IoU=0.8 and IoU=0.9)において10%程度の改善となった。
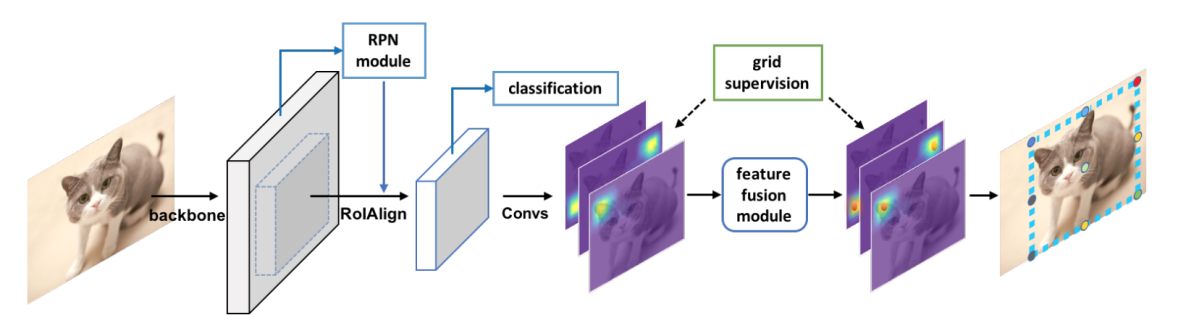
図D1 Grid R-CNNのパイプライン。([5]より引用)
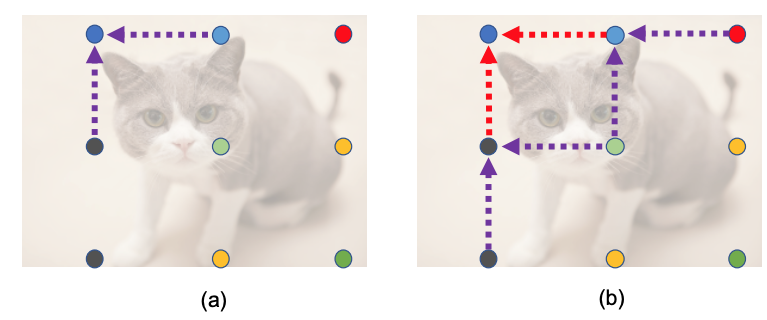
図D2 Feature Fusion Moduleの説明図。([5]より引用)
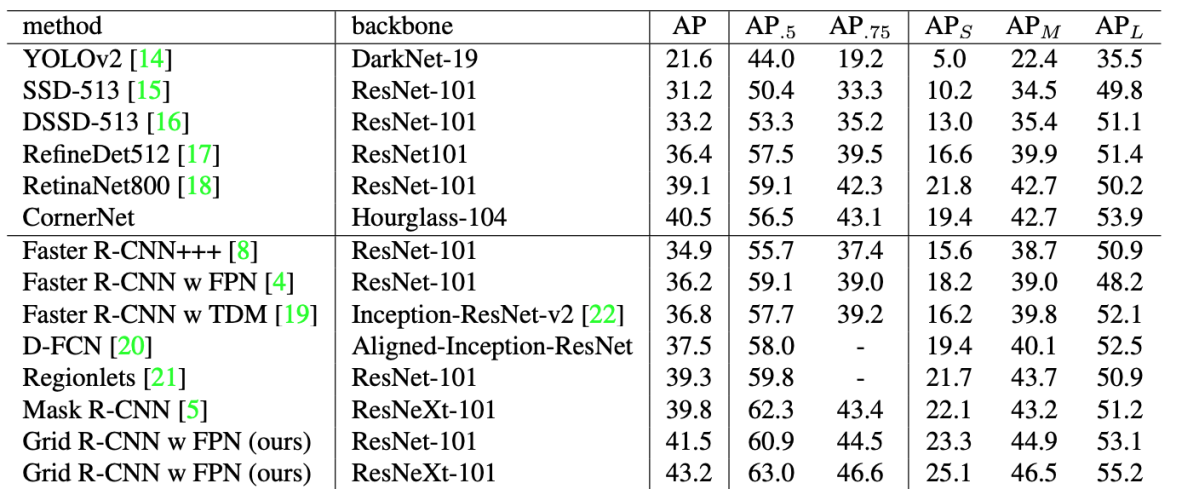
表D1: COCO test-dev評価結果。([5]より引用)
リンク
[5]
https://arxiv.org/abs/1811.12030
[6] Grid R-CNN plus:
https://arxiv.org/abs/1906.05688
おわりに
今回はキーポイント検出の手法を用いた物体検出の最新論文をご紹介しました。ECCV2018で提案されたCornetNetを皮切りに、キーポイントベースの物体検出が洗練されてきました。「物体をboxで検出する」というタスクの本質に迫っており、興味深いアプローチです。DeNA CVチームでは引き続き調査を継続し、最新のコンピュータビジョン技術を価値あるサービスに繋げていきます。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。