





はじめに
こんにちは、AIシステム部でコンピュータビジョンの研究開発をしております宮澤です。 我々のチームでは、常に最新のコンピュータビジョンに関する論文調査を行い、部内で共有・議論しています。前回は Human Recognition編 ということで我々が読んだ最新の論文をご紹介しましたが、今回は3D Vision編をお届けします。今回論文調査を行なったメンバーは、奥田 浩人、宮澤 一之です。
論文調査のスコープ
2018年11月以降にarXivに投稿されたコンピュータビジョンに関する論文を範囲としており、その中から重要と思われるものをピックアップして複数名で調査を行っております。今回は3D Vision編として、主に2次元画像から3次元情報を復元する技術に関する最新論文を取り上げます。
前提知識
カメラで得られる2次元画像から3次元情報を復元するためには、複数の視点から撮影した画像が必要であり、単一のカメラ(単眼カメラ)を動かしながら撮影する方法、2つ(以上)のカメラを並べて撮影する方法などがあります。前者における最も有名な技術としてはSfM(Structure from Motion)、後者ではステレオビジョンなどが知られています。いずれもコンピュータビジョン分野では非常に古くから研究されてきた技術ですが、昨今ではディープラーニングを取り入れる動きが活発です。そこで今回は、最新論文を単眼カメラを用いる技術とステレオカメラを用いる技術とに分け、さらにそれらの中でディープラーニングを利用しているものをご紹介いたします。
今回ご紹介している論文でよく使われているデータセットは以下の通りです。
- The KITTI Vision Benchmark Suite :車載カメラデータセットのデファクトスタンダート。ステレオカメラ、LiDAR、GPSなど豊富なセンサデータに対する様々なベンチマークを含む。今回紹介する論文に関係するベンチマークとしては、ステレオカメラの視差推定やシーンフロー(3次元オプティカルフロー)推定などがある。
- Scene Flow Datasets :ステレオカメラのデータセット。CGで生成しているため、左右カメラの視差、オプティカルフロー、シーンフローの完全な真値が利用可能。
- TUM RGB-D SLAM Dataset and Benchmark :RGB-Dカメラのデータセット。カメラによる自己位置推定などの精度評価に用いられる。
- ETH3D Benchmark :多視点カメラのデータセット。屋内・屋外双方のデータが含まれる。画像からの3次元復元精度の評価のため、レーザスキャナにより計測した高精度な3次元データを含む。
目次
単眼カメラを用いる手法
- SfMLearner++: Learning Monocular Depth & Ego-Motion using Meaningful Geometric Constraints (WACV2019 Oral)
- Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving (CVPR2019 Poster)
- Learning the Depths of Moving People by Watching Frozen People (CVPR2019 Oral)
- Neural RGB→D Sensing: Depth and Uncertainty from a Video Camera (CVPR2019 Oral)
ステレオカメラを用いる手法
- Group-wise Correlation Stereo Network (CVPR2019 Poster)
- GA-Net: Guided Aggregation Net for End-to-end Stereo Matching (CVPR2019 Oral)
- StereoDRNet: Dilated Residual Stereo Net (CVPR2019 Poster)
- Deep Rigid Instance Scene Flow (CVPR2019 Poster)
単眼カメラを用いる手法
SfMLearner++: Learning Monocular Depth & Ego-Motion using Meaningful Geometric Constraints (WACV2019 Oral)
要約
教師なしのデプス学習手法であるSfMLearnerに対しエピポーラ拘束を導入することで精度を改善
提案手法
単眼映像から教師なしでデプス推定を学習可能なフレームワークとして、SfMLearnerがCVPR2017で提案された。これは、推定したデプスとカメラ運動からある時刻のフレームを他時刻のフレームにワープして重ね、両画像の差異をロスとしてCNNを学習するというものである。SfMLearnerでは、シーン中の移動物体やオクルージョン箇所を推定してロスへの寄与率を変えているが、提案手法ではこれを改善し、より幾何的に妥当な結果を得るためにエピポーラ拘束を導入している。具体的には、5点アルゴリズムにより基本行列Eを求めてエピポーラ方程式を得たうえでこれを満たさない点のロスへの寄与率を下げている。
結果
KITTIによるSfMLearnerとの比較を図A1に示す。左から順に、入力画像、真値、SfMLearner、提案手法である。SfMLearnerと比較して、提案手法の方が正確なデプスが得られていることがわかる。

図A1:KITTIにおけるSfMLearnerとの比較。
また、他の従来手法との比較結果を図A2に示す。これを見ると、図A1と同様にSfMLearnerよりも提案手法の方が高精度であるが、GeoNetやDDVOといった最新手法(いずれもCVPR2018で発表された)には劣っている。しかし、これらの手法はネットワークのパラメータ数が多い、非線形最適化を必要とするなど提案手法に比べて計算量が大きいことが欠点として挙げられる。
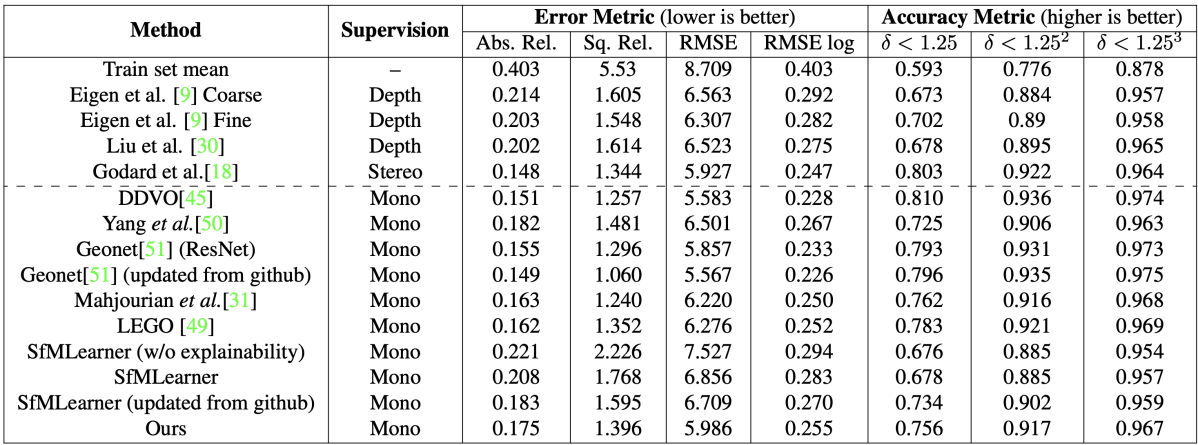
図A2:KITTIにおける評価結果。
リンク
論文: https://arxiv.org/abs/1812.08370
Pseudo-LiDAR from Visual Depth Estimation: Bridging the Gap in 3D Object Detection for Autonomous Driving (CVPR2019 Poster)
要約
画像から得られたデプスマップを擬似的にLiDARから得られたデータのように変換し、既存の3次元物体認識手法を適用可能にすることで精度を改善。
提案手法
3次元物体認識においては、LiDARから得られる高精度な3次元データを用いる場合に比べて画像から推定したデプスマップを用いる場合は精度が大幅に低下する。一般には画像によるデプスの推定精度が低いことが原因とされがちだが、本論文ではデータの表現方法に問題があると指摘している。例えば、2次元のConvolutionでは、画像中で隣接する物体同士は異なる距離にあっても統一的に扱われてしまったり、物体の距離の違いによるスケール変化などが考慮されない。そこで本論文では、画像から得られたデプスマップをそのまま利用するのではなく、擬似的にLiDARから得られたようなデータに変換することでこの問題の解決を図っている。このようにすることで、これまでに提案されてきたLiDARデータを対象とした3次元物体認識技術をそのまま流用することが可能となる。この流れを図B1に示す。

図B1:提案手法のパイプライン。
本論文の主眼はあくまでもデータの表現方法であり、デプス推定や3次元物体認識にはどのような手法を用いても構わないとしている。論文中ではデプス推定には一般的なステレオカメラの視差推定を利用し、3次元物体認識にはfrustum PointNetとAVOD(Aggregate View Object Detection)の2種類を用いている。
結果
KITTI2015を用いて従来手法との性能比較を実施。結果を図B2に示す。従来の画像ベースの手法と比較して提案手法では大幅に精度が改善していることがわかる。また、アプローチが異なる2種類の3次元物体認識手法のいずれにおいても大きな改善が得られており、提案手法が幅広い手法に適用可能であることが示唆されている。
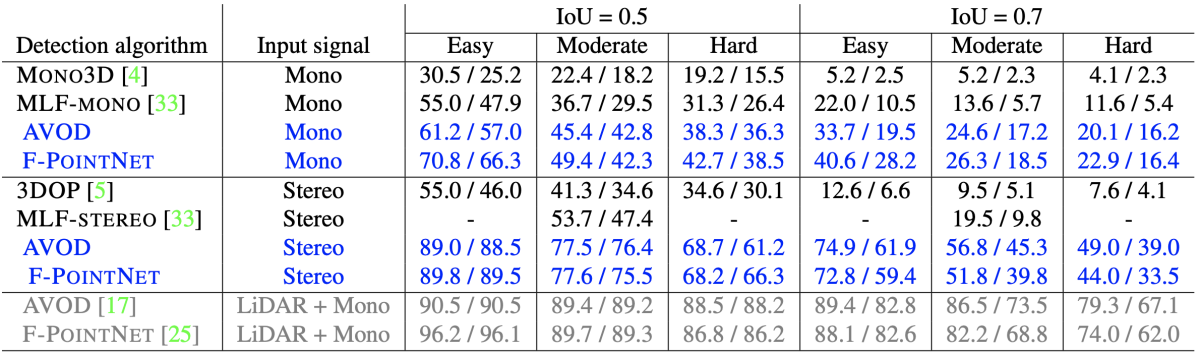
図B2:KITTI2015における評価結果。それぞれ3Dとbird’s-eye-viewに対するAverge Precisionをスラッシュで区切って示している。青が提案手法、グレーが実際にLiDARを用いた場合。
リンク
論文: https://arxiv.org/abs/1812.07179
Learning the Depths of Moving People by Watching Frozen People (CVPR2019 Oral)
要約
静止した人物を移動カメラで撮影したマネキンチャレンジの映像を学習に利用することで、従来は困難であった複雑な動きをする人物を含む映像のデプス推定を実現。
提案手法
人間など複雑な動きをする対象を移動するカメラで撮影した映像からSfM(Structure from Motion)やMVS(Multi-View Stereo)でデプスを推定することは非常に難しく、データドリブンな機械学習ベースの手法を用いるとしてもデプスの真値を持つ学習データを膨大に集めることは現実的でない。そこで本論文では、インターネット上に大量に存在する"マネキンチャレンジ"の映像を用いることを提案している。マネキンチャレンジとは、人々が様々な姿勢でマネキンのように静止し、そのシーン中をカメラで移動しながら撮影するというものである。こうした映像では人々が静止しているためMVSによるデプス推定が可能であり、これを真値として画像からデプスを推定するニューラルネットを学習させることができる(図C1)。

図C1:提案手法における学習の流れ。マネキンチャレンジの映像からMVSでデプスを求め、これを真値として画像からデプスを推定するネットワークを教師あり学習する。
単一のフレームからデプスを推定するだけでは、多視点画像から取得可能なシーンの幾何的な情報が利用できないため、提案手法では人以外の背景領域について運動視差を求めてネットワークへの入力としている。ネットワークへの入力を図C2に示す。ネットワークには参照画像Ir、人領域を指定するマスク画像M、人以外の背景領域から運動視差により求めたデプスマップDpp、コンフィデンスマップC、またオプションとして人のキーポイントマップKが入力される。コンフィデンスマップとは、入力として与えるデプスマップの信頼度を表現したマップであり、視差の一貫性や大きさ、エピポーラ制約などを考慮して求める。ネットワークはこれらを入力として受け取り、MVSにより得られたデプスを真値として学習することで、マスクされた人領域のデプスを補間し、かつ、背景領域のデプスをリファインすることができるようになる。

図C2:提案手法における入力データ(a)〜(d)と教師データ(e)。
結果
自ら構築したマネキンチャレンジデータセット、およびTUM RGBDデータセットにより従来手法との比較を行っている。TUM RGBDでの比較結果を図C3に示す。従来手法に比べ、提案手法では大幅に真値に近いデプスマップが得られていることがわかる。

図C3:TUM RGBDにおける評価結果。右2列が提案手法により推定されたデプスマップ。
リンク
- 論文: https://arxiv.org/abs/1904.11111
- プロジェクトウェブサイト: https://mannequin-depth.github.io/
Neural RGB→D Sensing: Depth and Uncertainty from a Video Camera (CVPR2019 Oral)
要約
カメラからのデプス推定において、デプスを単一の値としてではなく確率分布として求めることでベイジアンフィルタにより時間方向にデプスを集積して精度を改善。
提案手法
提案手法では、通常のRGBカメラからのデプス推定において、従来手法のように画素ごとに単一のデプス値を求めるのではなく、取りうるデプスの確率分布を求めている。このようにすることで、ベイジアンフィルタの枠組みを利用して時系列方向にデプスを集積し、デプスの不確定性を減らすと共に精度や安定性を向上させることに成功している。提案手法の概要を図D1に示す。
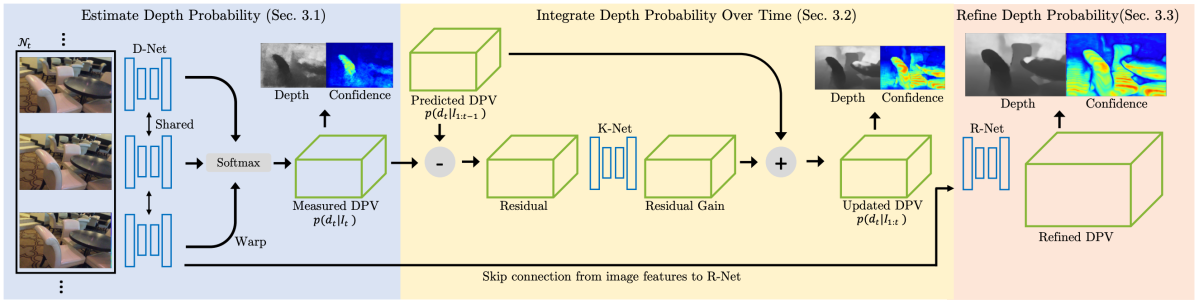
図D1:提案手法の概要。入力としてある時間区間のフレーム群を受け取り、DPV(Depth Probability Volume)を出力する。
図D1に示すように提案手法は入力フレームからDPV(Depth Probability Volume)を生成するD-Net、DPVを時間方向に統合していくK-Net、DPVの空間解像度を向上させるR-Netの3つから成る。DPVはp(d; u, v)で表され、画素 (u, v) がデプスdを持つ確率である。D-NetではPSM-Netを利用して複数の入力フレームのそれぞれから特徴抽出を行い、取りうる視差に対するコストボリュームを求めてSoftmaxをかけることでDPVを生成する。この段階で、空間解像度は入力画像の1/4となる。K-Netは、ベイジアンフィルタの枠組みを利用してDPVを時間方向に統合し、デプスの不確定性を減少させる。R-Netは低解像度のDPVと入力画像から抽出した特徴マップを受け取り、DPVを入力画像と同じ解像度にまでアップサンプルする。最後に、DPVから参照フレームにおけるデプスマップおよびその信頼性を表すコンフィデンスマップが生成される。
結果
7-Scenes(屋内シーン)やKITTI(屋外シーン)などのデータセットで従来手法との比較を行なっている。結果を図D2、図D3に示す。7-Scenesにおいては従来手法のDeMoNやDORNを上回る精度となっているが、KITTIでは同等程度となっている。

図D2:7-Scenesにおける評価結果。

図D3:KITTIにおける評価結果。
リンク
ステレオカメラを用いる手法
Group-wise Correlation Stereo Network (CVPR2019 Poster)
要約
ステレオカメラにおける視差推定で用いられるコストボリュームの計算のためのGroup-wise Correlationを提案。
提案手法
ステレオビジョンでは、取りうる視差に対して左右画像のマッチングコスト(SSDやSADなど)を計算することでコストボリュームを求め、そこからコスト最小となるような視差を選ぶことで視差推定を行う。近年では、CNNで左右画像から特徴量を抽出し、それらの相関計算あるいはConcatenationによりコストボリュームを求める手法が登場しているが、相関計算では単一チャネルの相関マップしか得られず、またConcatenationでは類似度情報が得られないという欠点がある。これらの欠点を解決するため、本論文では、抽出した特徴をグループに分け、グループごとに相関を求めるGroup-wise Correlationを提案している。また、求めたコストボリュームの局所的なコストを集約することでrefineする3D Aggregation Networkについても従来手法から精度と速度の改善を図っている。全体のパイプラインを図E1、3D Aggregation Networkのアーキテクチャを図E2に示す。
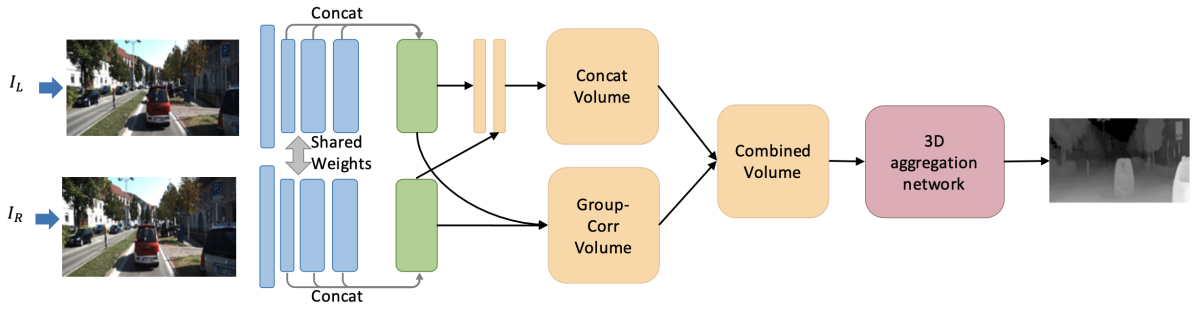
図E1:提案するGroup-wise Correlation Networkのパイプライン。特徴抽出、コストボリューム生成、3D Aggregation Network、視差推定の4つのパートから成る。

図E2:3D Aggregation Networkのアーキテクチャ。先頭に3D Conv、それに続いて3つのHourglass型3D Convを配置。
結果
Scene FlowおよびKITTIを用いてAblation Studyと従来手法との性能比較を実施。KITTI2015における評価結果を図E3に示す。KITTI2015では、視差の外れ値の割合(D1)を背景画素(bg)、前景画素(fg)、全画素(all)のそれぞれについて評価しており、図3はそれらをまとめたものである。また、図3におけるAllとNocは、それぞれ全画素を評価対象とした場合と、オクルージョンのない画素のみを評価対象とした場合である。いずれの評価尺度においても、提案手法(GwcNet-g)は従来手法よりも高い精度を示している。
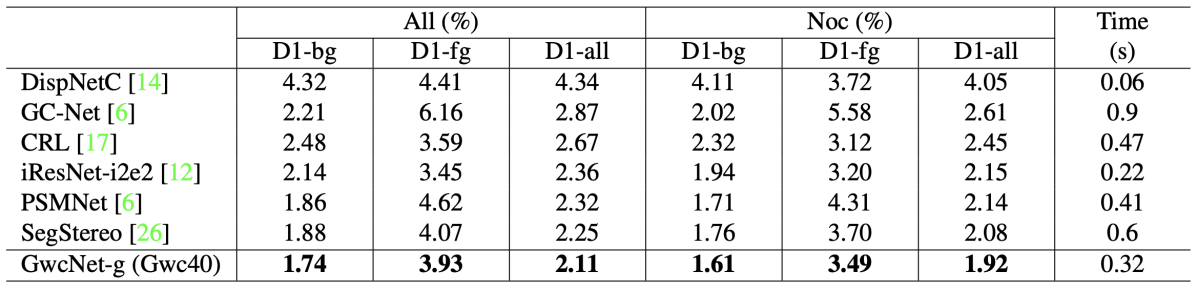
図E3:KITTI2015における評価結果。
リンク
- 論文: https://arxiv.org/abs/1903.04025
- Pytorch実装: https://github.com/xy-guo/GwcNet
GA-Net: Guided Aggregation Net for End-to-end Stereo Matching (CVPR2019 Oral)
要約
ステレオカメラにおける視差推定で用いられるコストボリュームにおいて、マッチングコストの集約を行うための新たなレイヤを提案。
提案手法
ステレオビジョンでは、取りうる視差に対して左右画像のマッチングコスト(SSDやSADなど)を計算することでコストボリュームを求め、そこからコスト最小となるような視差を選ぶことで視差推定を行う。このとき、近傍での視差がなめらかとなることを拘束条件として利用するため、ローカルおよびグローバルなコストの集約が行われる。本論文では、ニューラルネットを使った視差推定において、このコスト集約を行うためのレイヤであるSemi-Global guided Aggregation(SGA)レイヤとLocal Guided Aggregation(LGA)レイヤを提案している。アーキテクチャ全体とSGAレイヤ、LGAレイヤの概要を図F1に示す。
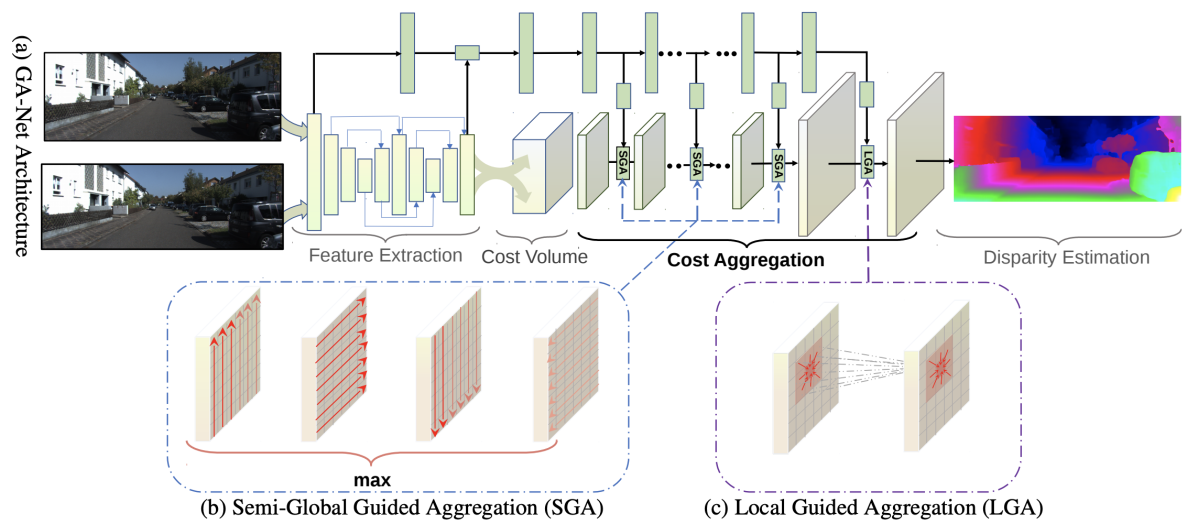
図F1:(a)アーキテクチャの全体像。ステレオカメラの左右画像からHourglass型CNNで特徴抽出を行ってコストボリュームを生成し、これがCost Aggregationブロックの入力となる。(b)SGAレイヤでは上下左右の4方向についてグローバルなコスト集約を行う。(c)LGAレイヤは視差推定の前にコストボリュームを局所的にリファインする。
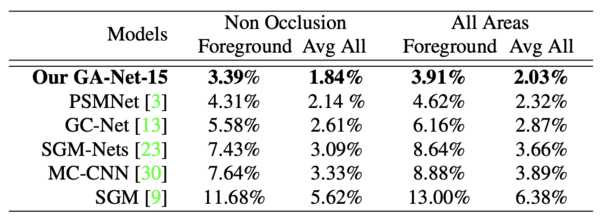
結果
Scene FlowおよびKITTIを用いてAblation Studyと従来手法との性能比較を実施。KITTI2015における評価結果を図F2に示す。いずれの評価尺度においても、提案手法(GA-Net)は従来手法よりも高い精度を示している。
KITTI2015における視差推定の結果例を図F3に示す。1行目が入力画像、2行目と3行目が従来手法(それぞれGC-NetとPSMNet)による視差推定結果、3行目が提案手法による視差推定結果である。矢印で示されているように、特にテクスチャのない領域について提案手法は従来手法よりも優れた性能を示していることがわかる。
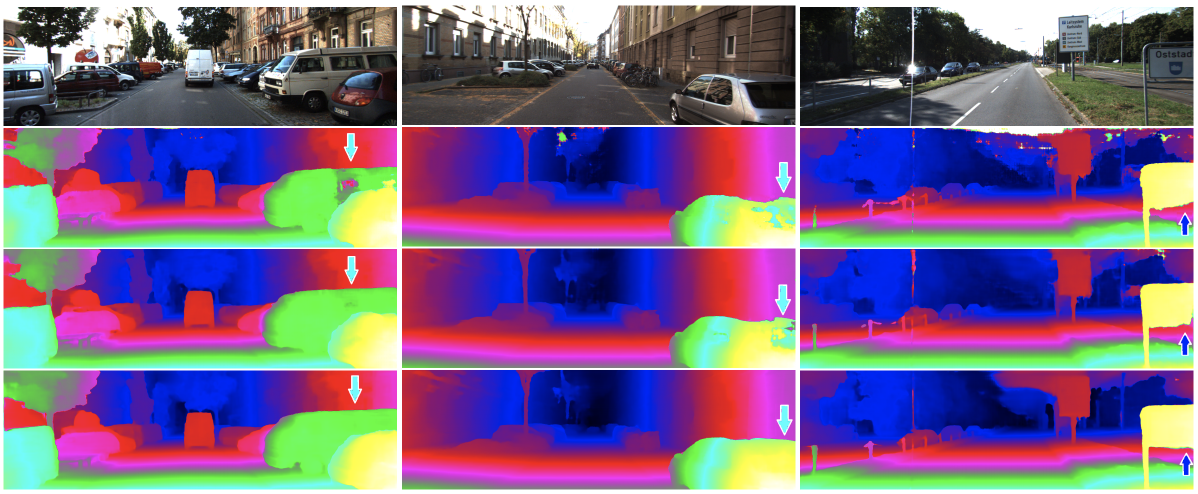
図F3:推定結果の従来手法との比較。1行目が入力画像、2行目がGC-Net、3行目がPSMNet、4行目が提案手法による視差推定結果。
リンク
論文: https://arxiv.org/abs/1904.06587
StereoDRNet: Dilated Residual Stereo Net (CVPR2019 Poster)
要約
ステレオカメラにおける視差推定で用いられるコストボリュームのフィルタリングに3D Dilated Convolutionを利用し、さらに新たなネットワークを導入して推定視差の高精度化を実現。
提案手法
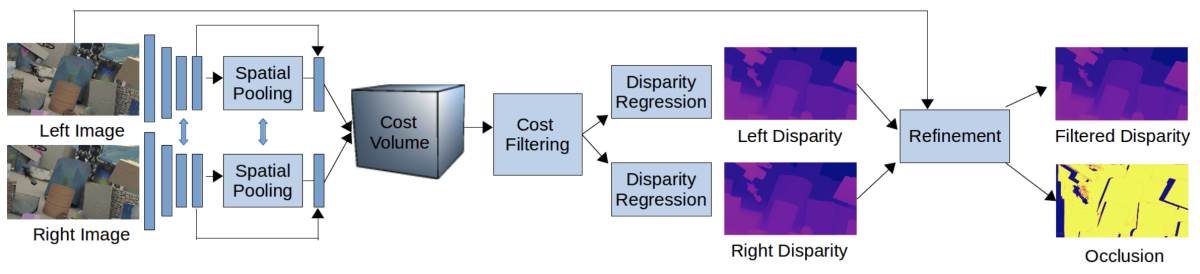
図G1:StereoDRNetのアーキテクチャ。
本論文が提案するStereoDRNetのアーキテクチャを図G1に示す。提案手法は、大きく分けて特徴抽出、コストボリュームに対するフィルタリング、視差の高精度化から成る。提案手法における新規的な提案の1つがコストボリュームのフィルタリングに図G2に示すように3D Dilated Convolutionを用いている点であり、これにより従来手法と比較して計算量をほぼ半減している。また、ショートカット接続を持つ残差ブロックをスタックしており、各ブロックからそれぞれ視差マップを生成してロスを求めている(図G2では3ブロック)。
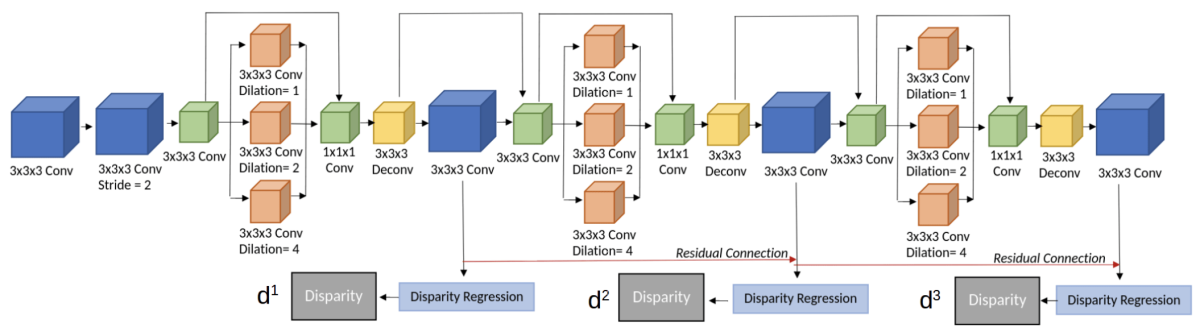
図G2:3D Dilated Convを用いたコストフィルタリング。
また、推定した視差を高精度化するためのブロック(図G3)を取り入れている点も本論文における新規提案である。ここでは、推定した視差を用いて右画像を左画像の視点にワープし、ワープした画像と左画像との残差マップを求める(図G3におけるEp)。さらに視差マップについても同様にして残差マップを求め(図G3におけるEg)、両マップをCNNに入力することで視差マップの精度改善を図っている。
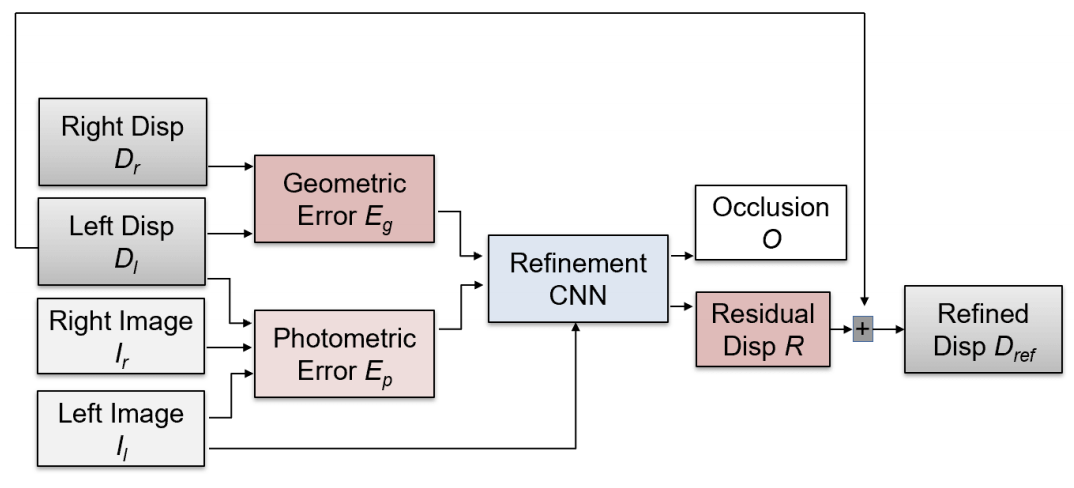
図G3:視差高精度化のためのブロック。
結果
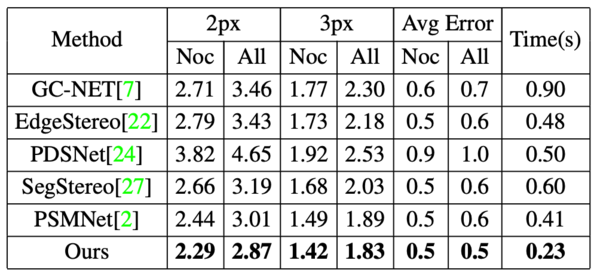
Scene Flow、KITTIおよびETH3Dを用いてAblation Studyと従来手法との性能比較を実施。KITTI2012とKITTI2015における評価結果を図G4と図G5に示す。KITTI2012ではいずれの従来手法よりも高い精度を示しており、またKITTI2015でも背景領域(bg)の視差推定では高い精度を達成している。また、Dilated Convolutionの利用により計算時間についても他手法よりも高速となっている。

また、屋内シーンの3次元計測における結果を図G6に示す。同図下段は真値(左列)からの誤差を示しているが(赤い領域ほど誤差が大きい)、提案手法(中央列)は従来手法(右列)よりも誤差が小さいことがわかる。
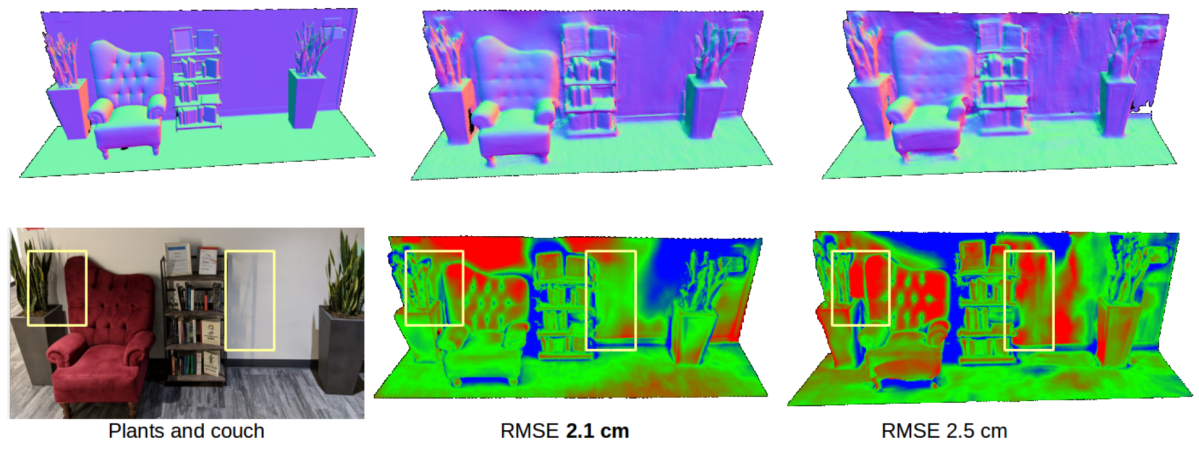
図G6:屋内シーンの3次元計測結果。左から順に、構造光投影による結果(真値)、提案手法による結果、PSMNetによる結果。
リンク
論文: https://arxiv.org/abs/1904.02251
Deep Rigid Instance Scene Flow (CVPR2019 Poster)
要約
シーンフロー推定を各インスタンスに対するエネルギー関数の最小化問題として捉え、リカレントネットにより効率的にガウス・ニュートン法を実装することで精度と速度を改善。
提案手法
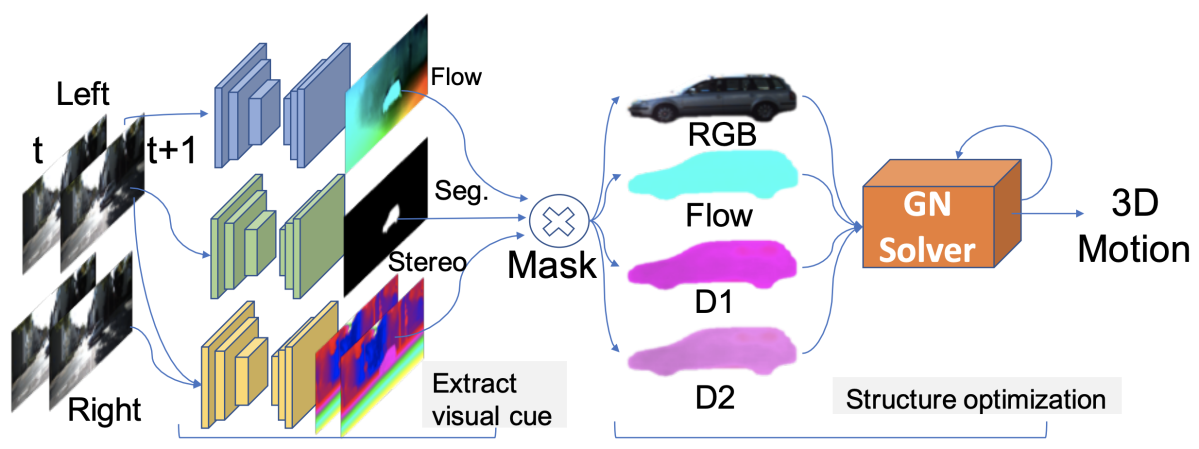
図H1:提案手法の概要。
自動運転向けに車載カメラで得たステレオ映像からシーンフロー(各点の3次元動きベクトル)を推定するため、背景の動き(エゴモーション)と各インスタンスの動きを個別に求める手法を提案。図H1に示すように、まずVisual Cueとして既存手法を用いてステレオ映像に対してインスタンスセグメンテーション、視差推定、オプティカルフロー推定を行う。そして、背景を含む各インスタンスについてPhotometric Error、Rigit Fitting、Flow Consistencyを評価するエネルギー関数を定義し、これを最小化することでシーンフローを求めている。各エネルギーの意味は以下の通りである。
- Photometric Error:画像間で対応づけられた点同士は見た目が一致する
- Rigid Fitting:推定されるシーンフローは視差およびオプティカルフローから得られる3次元運動と一致する
- Flow Consistency:推定されるシーンフローを2次元画像に投影した結果はオプティカルフローと一致する
提案手法では上記エネルギー関数をガウス・ニュートン法で解くことでシーンフローを推定している。ガウス・ニュートン法はリカレントニューラルネットワークで実装することが可能であり、GPUの利用により従来手法よりも大幅な高速化を実現している。
結果
KITTI scene flowデータセットにより従来手法との比較を行い、処理時間と精度の両面で従来手法よりも高い性能を示すことを確認(図H2)。特に現時点で最も性能が高いISF(Instance Scene Flow)モデルとの比較では22%の誤差削減と800倍の高速化を実現している。
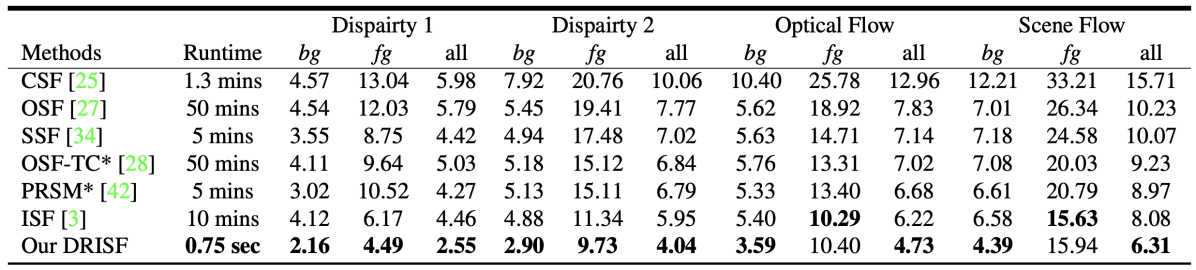
図H2:KITTI scene flowデータセットにおける評価結果。
リンク
論文: https://arxiv.org/abs/1904.08913
おわりに
Human Recognition編 に続き、今回は3D Vision編ということでコンピュータビジョンに関する最新論文をご紹介しました。主に2次元画像からの3次元情報復元という非常に古くから研究されてきた分野について取り上げましたが、昨今ではディープラーニングの導入によって精度やロバスト性、汎用性の観点でさらに進展が見られています。また、単純に全てをディープラーニングに置き換えるのではなく、これまでに長く研究されてきた伝統的なアルゴリズムを踏襲しつつ、その一部にディープラーニングを組み込むことで性能を向上させるようなアプローチが増えてきているように感じます。
カメラからの3次元情報復元は、車載カメラでのシーン認識など幅広い応用が可能な重要技術であり、ディープラーニングによる性能向上のおかげでますます適用範囲が拡大していくと考えられます。今後もDeNA CVチームでは最新技術の調査を継続し、コンピュータビジョン技術を新たなサービスに繋げて世の中にデライトを届けるべく頑張っていきます。




{kind=link}
{kind=link}
最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。