





はじめに
皆さんこんにちは。DeNA AIシステム部の李天琦(leetenki)です。DeNAのAIシステム部では、物体検出、姿勢推定、アニメ生成等、様々なComputer Vision技術の研究開発に取り組んでいます。また、AIシステム部では世界の最新技術トレンドをキャッチアップするために、年一回国際会議に自由に参加する機会が設けられています。今回は、ドイツ ミュンヘンで開かれたComputer Visionに関する世界トップの国際会議の一つである「ECCV 2018」について、AIシステム部のメンバー5名で参加してきましたので、その内容について紹介したいと思います。また、今回は聴講としてだけでなく、DeNAからもWorkshop論文が1件採録され、濱田晃一(下図右)と私(下図左)の2人で発表してきましたので、その様子についても紹介したいと思います。

ECCVとは
ECCVの正式名称は「European Conference on Computer Vision」で、CVPR、ICCVと並ぶComputer Vision分野における世界三大国際会議の一つです。ちなみにComputer Visionというのはロボット(コンピュータ)の視覚を指し、広義は画像認識、映像認識の技術分野全般を意味しています。そのComputer Visionの分野において世界三大国際会議の一つがこのECCVです。そして近年ではDeep Learningを始めとするAI技術の飛躍的な進歩により、あらゆるComputer Vision分野でDeep Learningを使う事が当たり前になってきているので、ECCVでもDeep Learningの手法を応用した論文が大半の割合を占めるようになりました。
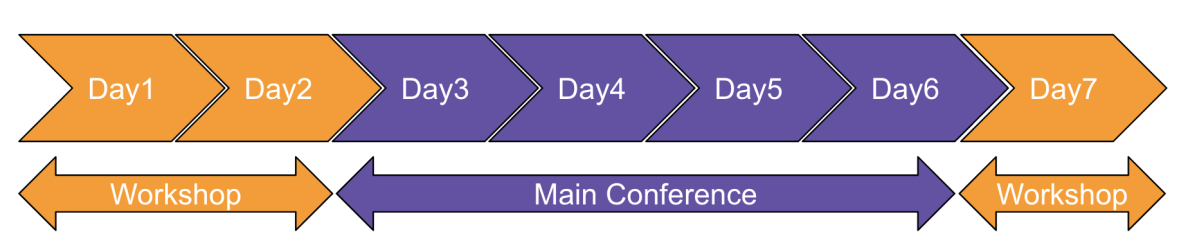
今年の開催期間は9/8〜9/14の7日間です。最初の2日と最終日は特定のテーマに絞ったTutorial & Workshopで、あいだの4日間がMain Conferenceです。また、Main Conferenceの4日間では、Expoと呼ばれるスポンサー企業の展示会も並行して行われ、世界をリードするIT企業の最新の研究成果や製品などが展示されました。
開催場所
今年の開催場所はドイツのミュンヘンで、GASTEIG Cultural Centerという、劇場・図書館・大学が一体となった大型文化施設を貸し切って会議が開かれました。

近年AI技術への注目の高まりを受けて、ECCV参加者は年々増加し、今年は参加者も採録論文数も過去最高となりました。統計によれば、今年の投稿論文数は2439本で、採録論文数は776本でした。そして今回のECCV参加人数は3200人以上と、ECCV 2016の時と比べて倍以上にものぼっています。


セッションの様子
ECCVに採録された論文のうち、評価の高かったものはOralと呼ばれる口頭発表形式のセッションで発表されます。その場でデモを行うものもあります。それ以外はPosterと呼ばれるセッションで発表され、著者と直接ディスカッションを行うことができます。

ネットワーキングイベント
Main conference期間中、初日の夜に「welcome reception」と、3日目の夜に「congress dinner 」という2つの公式ネットワーキングイベントが開催されました。今回は時間の都合でcongress dinnerには参加できませんでしたが、初日のwelcome reception partyでは立食パーティ形式で世界各国の研究者達と親睦を深める事ができました。

また、会議公式のイベントとは別に、多くのスポンサー企業が会場近くのカフェやクラブを貸し切って、独自のネットワーキングイベントを開催していました。今回濱田と私が発表したFashion, Art and Design Workshopでも独自に懇親会を開催していたため、そちらにも参加し、世界各国のFashion, Art関連の研究者と仲良くなる事ができました。
受賞論文
今回ECCVで発表された論文の中で、受賞されたものをいくつか紹介します。
- Implicit 3D Orientation Learning for 6D Object Detection from RGB Images まず、今年のECCV Best Paperに選ばれたのが、こちらのImplicit 3D Orientation Learning for 6D Object Detection from RGB Images (Martin Sundermeyer et al.) です。
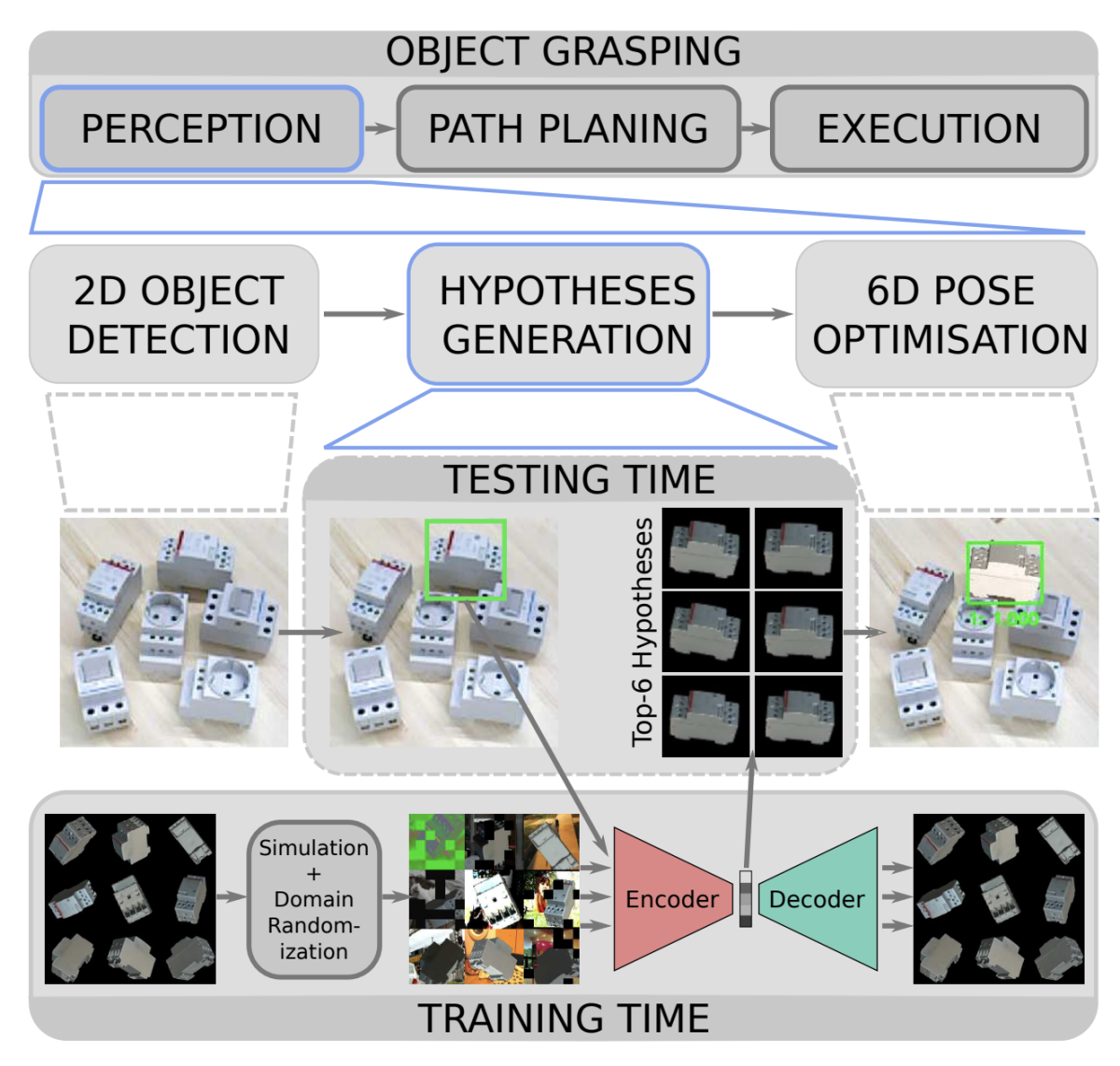
この論文を一言で要約すると、6D物体検出(3次元空間座標だけでなく3方向の向き姿勢情報も含んだ検出問題)を高速に行う事ができ、かつ6Dのラベル付き教師データがなくても学習可能という画期的な手法です。ただし、6Dラベル付き教師データの代わりに、検出対象となる物体の3D CADデータが必要となる点に注意が必要です。 もう少し具体的に全体の処理の流れを説明すると、まず入力となるRGB画像に対してSSDを用いて対象物体のBounding Boxを推定し、その後、推定されたBounding Box領域から物体の姿勢情報を推定するという処理を行います。実は後半のBounding Box領域から物体の姿勢情報を推定する部分がこの論文の一番の重要なポイントで、ここで独自のAugmented AE(AutoEncoder)というものを提案しています。
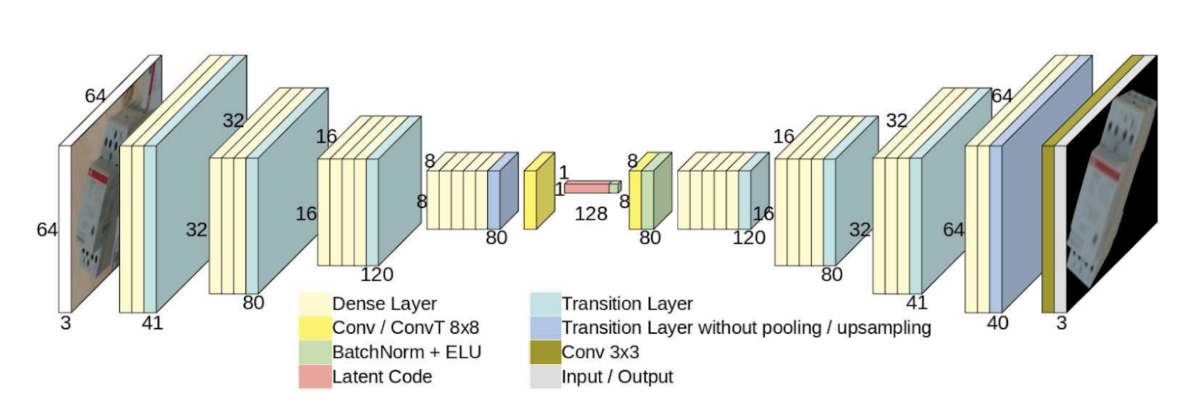
このAugmented AEというのは、背景や遮蔽を含んだ物体画像を入力した時に、背景や遮蔽を取り除いて対象物体だけが映る画像を出力するように訓練されたCNNです。このネットワークを訓練するには、背景を含む物体画像とそうでない画像のペアの教師データが必要ですが、そこでCADデータを使い、ランダムに集められた背景画像と合成した人工的なデータセットで学習を行います。また、あらかじめ対象物体のあらゆる姿勢の画像をCADデータから生成し、Augmented AEで潜在表現を計算しておいて、データベースに蓄積しておきます。これによって、テスト時に検出されたBounding Box領域をAugmented AEのEncoderに入力して、得られた潜在表現とデータベースにある潜在表現の照合検索を行う事で、高速に姿勢情報を推定する事ができます。
- Group Normalization 次はHonorable Mentionを受賞した2本の論文のうちの1つであるGroup Normalization (Yuxin Wu et al.) を紹介します。
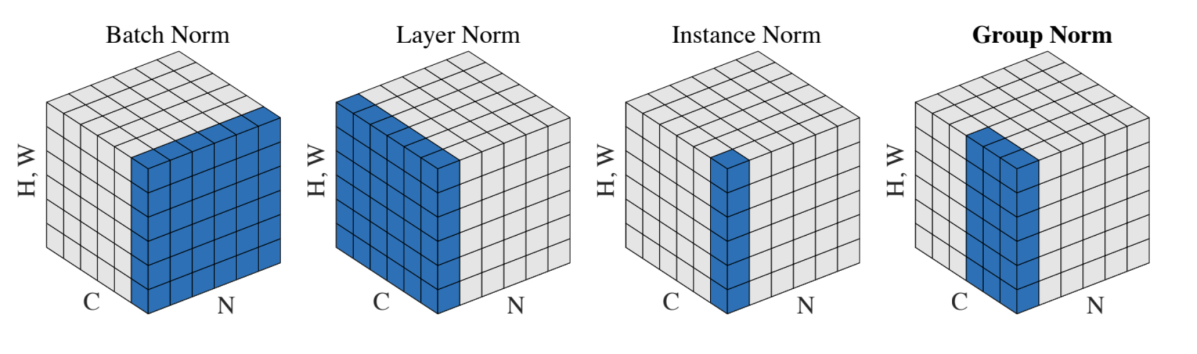
こちらの論文はかの有名なKaiming He氏も共著に入っており、とてもシンプルでかつ有用なDeep Learningにおける正規化手法です。通常、Deep Learningの学習にはバッチ正規化 (Batch Normalization) という手法がよく使われますが、その性能はバッチサイズの大きさに依存し、バッチサイズが小さくなるにつれて不安定になるという問題があります。そこでこの論文では、バッチ単位ではなく、入力チャンネルをいくつかのグループに分け、各グループ単位で正規化するというアイデアを提案しています。これにより、バッチサイズが小さい場合でも有効な正規化を実現しています。
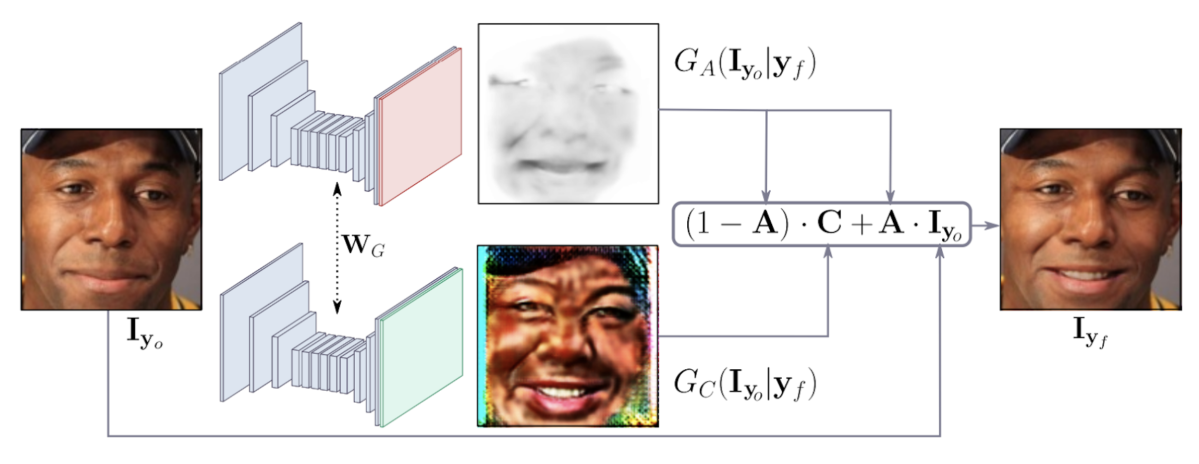
- GANimation:Aanatomically-aware Facial Animation from a Single Image 最後に紹介する論文が、2本のHonorable Mention受賞Paperのうちのもう1本であるGANimation:Aanatomically-aware Facial Animation from a Single Image (Albert Pumarola et al.) です。
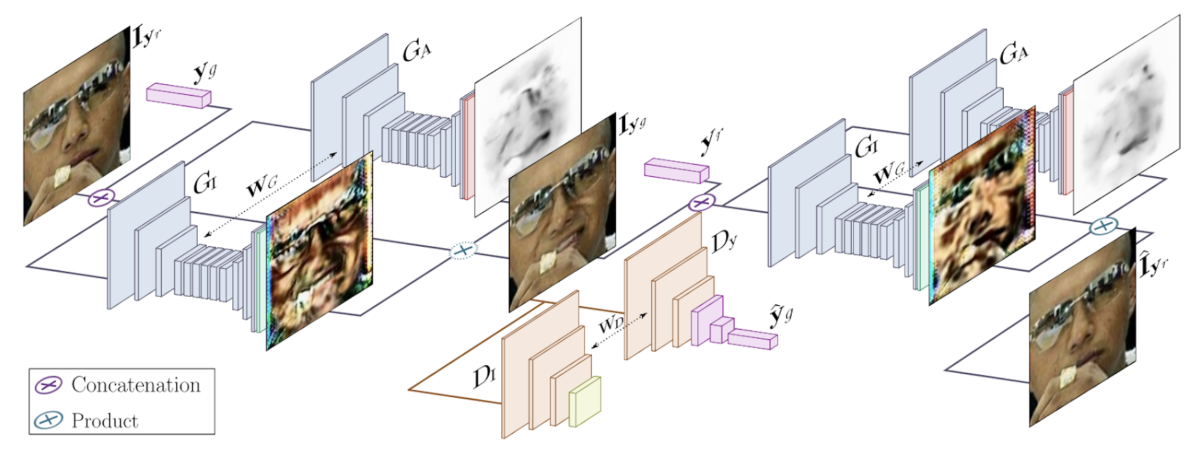
こちらの論文では、最近AI分野で注目を集めている敵対的生成モデルのGAN (Generative Adversarial Network) を使った顔表情生成の手法を提案しています。キーとなるアイディアは、顔画像を生成する際に、入力画像に加えて「Action Units (AU)」と呼ばれる条件変数も一緒にGeneratorに入れることです。このAUというのはもともと心理学の分野におけるFacial Action Coding Systemで用いられる概念で、人間の顔のそれぞれの表情筋に対応する30種類のAUの組み合わせで7000以上の表情を表現できるとのことです。このAUを条件変数として一緒に使うことでよりリアルかつ自在な顔表情を生成できるようになります。既存手法のStarGANでは離散的な表情変化しかさせられなかったのに対し、連続的に表情を変化させられるところがポイントです。また、表情に関係しない部分を保持したまま表情のみを変えるためにAttentionを利用するという工夫もなされています。
DeNAのPoster発表
今回、会議最終日のFirst Workshop on Computer Vision for Fashion, Art and Design Workshopにて、DeNAからも1件の採録論文ががあり、First Authorの濱田と私の2人で発表を行いました。


こちらが今回発表してきた『HD高解像度の全身アニメ生成』の論文 (Full-body high-resolution Anime Generation with Progressive Structure-conditional Generative Adversarial Networks) です。この論文では、各解像度で構造条件付けられたGeneratorとDiscriminator を進歩的に成長させるGANs (PSGAN) により、従来難しかった、構造一貫性を持った高解像度での生成を実現しています。また、DeNAではこれまでにMobageサービスで蓄積してきた10万点以上のアバターの3Dモデルデータを保有しており、それを活用してPose情報付きの独自のアバターデータセットも構築しています。
より詳細な内容はこちらのプロジェクトページで解説していますので、興味ある方はぜひこちらをご覧ください。
全体の感想
今回のECCV2018で、私としてもDeNAとしても、初めての大きな国際会議での論文発表を行いました。私は聴講として毎年CVPRにも参加していますが、一番大きな違いはネットワーキングのしやすさだと感じました。学会で新しく知り合った研究者と雑談する時、必ずと言っていいほど「今回のカンファレンスでどんな論文を発表するんだい?」のような質問を聞かれます。聴講での参加ですとそこで話題が途切れてしまいますが、発表者として参加するとそこから論文の話が広がり、より広く交流を深める事ができました。DeNAでは毎年国際学会に参加する機会が設けられていますので、次回行く時もできれば論文発表者として参加し、更に言えば本会議でのOral発表も目標に目指したいと思います。
参考文献
- Martin Sundermeyer, Zoltan-Csaba Marton, Maximilian Durner, Manuel Brucker, Rudolph Triebel. Implicit 3D Orientation Learning for 6D Object Detection from RGB Images.
- Yuxin Wu, Kaiming He. Group Normalization. arXiv:1803.08494 [cs.CV]
- Albert Pumarola, Antonio Agudo, Aleix M. Martinez, Alberto Sanfeliu, Francesc Moreno-Noguer. GANimation: Anatomically-aware Facial Animation from a Single Image. arXiv:1807.09251 [cs.CV]




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。