





はじめに
AIシステム部の西野剛平です。AIシステム部ではAI研究開発グループに所属しており、Computer Visionの技術を中心に研究開発を行っています。
8/30にAI技術に関するイベントSHIBUYA SYNAPSEの第1回目を弊社内にあるSakuraCafeにて開催し、そこで現在私が関わっている「スマートショップ実現に向けた取り組み」に関してご紹介させて頂きました。 今回は、エンジニアブログという事もあり、イベントで発表した内容のうち、特に技術的な内容について紹介したいと思います。


SHIBUYA SYNAPSEとは
昨今のAI技術は深層学習を中心に目まぐるしく進化しており、それとともにビジネスへの適用も着実に行われてきております。SHIBUYA SYNAPSEは、このような環境において、企業×大学や、プランナー×エンジニアといった異なるバックグラウンドを持つ参加者の有機的なつながりにより、価値あるサービスの共創の場を提供することを目的に設立されました。より詳細な情報に関しては SHIBUYA SYNAPSEのホームページ をご覧いただければと思います。
今回は、SHIBUYA SYNAPSEの記念すべき第1回目で、東京大学の山崎俊彦准教授をメインスピーカーにお招きし、山崎先生からは「魅力」の予測や解析に関してのご紹介をして頂きました。また、イベントの最後には懇親会もあり、AIに対して様々な携わり方をしている方同士での意見交換が広く行われるなど、大盛況のうちにイベントを終わる事ができたのではないかと思います。


スマートショップの実現に向けた研究
インターネット上でのサービスにおいては、お客様に合った最適なコンテンツの配信、ログ情報からお客様の行動を解析して迷わない導線に改善するなど、日々サービスを快適にご利用頂く工夫が行われております。しかし、リアルな店舗においてはそのような最適化はあまり行われていないため、快適なサービスを提供するという点では、まだまだ改善の余地があるのではないかと考えております。 私たちは、AI技術を活用することで、リアルの店舗においても一人一人のお客様の状況に合わせた接客やリアルタイムの商品推奨など、今までにないショップ体験の提供ができないかを考え、将来のスマートショップの実現を見据えた研究開発を行っています。

姿勢推定技術を活用した同一人物の再認識
スマートショップの実現のためには、店内でのお客様の状況を把握する技術の確立が不可欠です。その第一ステップとして、定点カメラからの映像を元に、深層学習ベースの姿勢推定技術を活用した、同一人物の再認識技術の開発を行いました。
本手法は、人物の検出と検出された人物の同定を繰り返し行っていくというのが大枠の流れとなっており、この人物の検出タスク部分に姿勢推定技術を利用したのは、高精度であるというのが一番の理由ですが、その他にも将来性を考慮したいという意図があります。姿勢推定では一般的な検出器で検出される人の矩形情報を得られるだけでなく、各体のパーツを表す器官点情報までも同時に検出することができます。これらの情報は非常に有用で、今後別のタスクを解く必要が発生した場合でも、有益な情報として利用できる可能性は高いと考えています。今回紹介する人物同定の技術においても、この器官点情報を利用する事により、高精度でリアルタイムに同一人物の再認識を実現しています。
一般的なトラッキングにおける問題点
例えば、粒子フィルタをベースとしたような一般的な物体追跡においては、フレーム間の画像変化を基に追跡を行うため、フレーム間隔が長い場合(フレームレートが小さい場合)はフレーム間の画像変化量が大きくなってしまい、追跡は極めて困難になってしまいます。

また、正確な検出器を前提とした場合は、ある時刻tで検出された人と次のフレーム時刻t+1で検出された人の対応付けを行う事により同一人物判定をする事ができます。 例えば、簡易にトラキングを実現する方法として、Intersection over Union(IoU)の結果を利用する方法が考えられ、それぞれのフレームで検出された人の矩形(BoundingBox)同士、各々の組みでIoUを求め、その値が大きいもの同士を同一の人物とします。


ただし、この場合もフレーム間での人の移動量が大きい場合には、IoUの値が0となってしまい追跡が破綻してしまいます。
実サービスを見据えた場合、コスト対効果を意識しなければいけないため、限られた計算リソースで実行する事を想定する必要があります。その上で、リアルタイムに処理するとなると、フレームレートが低くなってしまうというのは、ある程度は前提事項として許容しなければいけない事でないかと考えています。(実際、紹介しているリアルタイムデモ映像のフレームレートは1.7fps程度となっています。)したがって、前述したようなフレームレートが低い場合に発生してしまう問題に対応できるような人物追跡手法を設計する必要があります。
今回紹介する手法は、こういった低いフレームレートやオクルージョンが発生するケースを特に意識しており、姿勢推定によって得られた器官点情報を上手く利用することで、そのような状況下においてもロバストに同一人物の再認識を行えるなるような手法を考案しました。
デモ映像
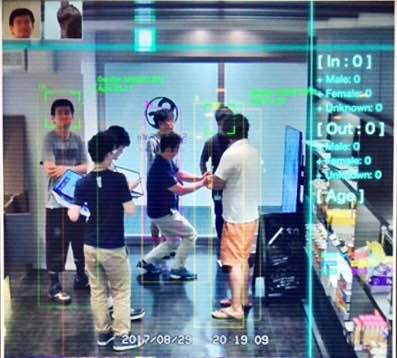
弊社SakuraCafe内で行ったリアルタイムデモ映像になります。
姿勢推定技術によって検出した人物を矩形で囲っています。その上に表示されている番号はその人物を識別するためのIDで、同じ番号の場合は同一人物と認識されています。また、今回技術の詳細は紹介しませんが入店と退店のタイミングや、年齢および性別の推定もリアルタイムに行っております。赤色の線が入店、青色の線が退店を表し、顔が正面を向いた際に表示される矩形に年齢と性別の推定値を表示しています。
全体の構成
本手法は下記の要素で構成されています。
- フレーム画像から人物の器官点の検出
- 1つ前のフレームで検出された人物と今回検出された人物の同じ器官点同士で色の照合
- 1つ前のフレームで検出された人物と今回検出された人物の位置の照合
- 2と3の結果から総合的に判断し、人物の同定
1から4の手順を動画の各フレームに対して逐次行っていくことで、連続的に同一人物の再認識を実現しています。
姿勢推定技術に関して
まずは、姿勢推定技術を使って、フレーム画像中から人物、および器官点の検出を行います。器官点は複数人数の器官点を同時に検出し、検出されたそれぞれの器官点はどの人物のどの体の部分に対応しているかを認識します。下の写真は検出された、鼻、首、左肩、左手、右肩、右手、左腰、左足、右腰、右足の10個の器官点になります。

色差の計測
各器官点の色を取得します。各器官点を中心とした局所領域からピクセルのRGB値を取得し、それをL*a*b*色空間に変換した後、CIE2000で色差を計測します。色差は1つ前のフレームで検出された人物と今回検出された人物の同じ器官点同士での計測になります。

色差を類似度に変換
色差を色の類似度として扱いたいので、色差dを1.0 〜 0 の定義域に射影する下記の関数を導入し、それを類似度S(d)とします。

この関数自体はただのシグモイド関数で、係数αやバイアスΒのパラメータ値は、おおよそ下記の要件に合うように調整しています。

色の類似度の計算
色差の計算方法、およびそれを類似度に変換する式を説明しましたが、もう少し具体的な例で説明したいと思います。時刻tのフレームでPersonAという人を検出、時刻t+1でPersonBという人を検出したと仮定し、これらに対し「色の類似度」を求める手順を示します。

各器官点毎にL*a*b*色空間に変換した後、CIE2000色差を計算し、類似度を求めます。各器官点毎の類似度が全て求まったら、それらの平均を取り、最終的にその値をPersonAとPersonBの「色の類似度」とします。上記はその計算過程をイメージした表になります。見切れや隠れなどにより検出されなかった器官点がどちらか一方にでもある場合は、類似度50%となるようにしています。(これは、その器官点を使用しない場合に比べ、器官点1つあたりの類似度への寄与率が高くなり過ぎないようにするための措置です。)
位置の尤度
追跡中の人物は最初の検出フレームからその移動の軌跡をすべて保持しています。したがって、これまでの移動情報を基にその人物が次のフレームにいる位置をガウス分布でモデル化する事ができます。これを尤度関数とし、実際に次のフレームで人が検出されたら、その位置情報をそれぞれの尤度関数にあてはめることにより、尤もらしさを求める事ができます。ちなみに、実際のデモ映像では人に対して相対的にブレが少ない首の器官点位置を利用しています。

上記は、追跡中の3人の軌跡情報を基にガウス分布でモデル化したイメージ図になります。次のフレームでの各人の予測位置は赤色で書かれている部分で、これまでの移動量が大きいほど次フレームでの予測位置は遠くに、分散は大きくなります。
総合尤度の算出
色の類似度、および位置の尤度から総合尤度を計算し、その値から同一人物の判定を行っていきます。例えば、前のフレームでPersonAとPersonBの2人を追跡しており、現在のフレームでPersonCとPersonDとPersonEの3人を検出した場合について考えてみます。

前のフレームと現在のフレームで検出された全ての人の組み合わせに対し、色の類似度および位置の尤度を計算し、その積を総合尤度とします。この例では下記のようになります。

これを総合尤度の高い順で並べ替え、ある閾値以下(ここでは0.02を利用)のものを除外すると下記のようになります。

これを上から順に人物同定していきます。「前フレーム」欄か「現在のフレーム」欄のどちらかに既出の人物が含まれる場合、その行は無視します。これを最後の行まで行い最終的な結論を出します。この例においては下記のような結果となります。
これを動画の各フレームに対して連続的に行っていく事で、高精度な同一人物の再認識を実現しています。
最後に
SHIBUYA SYNAPSEの開催当日は、このブログに書かせて頂いた内容をご紹介しつつ、会場内でリアルタイムにそれを体験できるデジタルサイネージのブースも用意しました。
発表している内容をその場で実際に体験できるという事で、参加された方々にも興味を持っていただき、非常に良い試みだったと思っています。 SHIBUYA SYNAPSEは今後も2回3回と続いていく予定なので、このブログを読んで興味を持って頂ければ幸いです。是非、次回のご参加を検討して頂ければと思います!




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。