





本記事の概要
本記事では、私がインターンシップで取り組んだ音声変換における話者性制御技術の研究開発について紹介します。 まず、声質変換・プロンプト制御について説明し、デモを交えながら概要を紹介します。 次に、現状の研究とその課題を説明し、それらの課題に対しての我々の提案手法を紹介します。
はじめに
8 月から約 1 ヶ月の間、AI スペシャリストコースのインターンシップに参加した西邑です。 普段は音声変換や音声合成の研究・開発をしたり、さまざまな趣味を楽しんで日々過ごしています。
早速ですが、まずは基本知識となる声質変換について説明していきます。
声質変換とは
声質変換 (Voice Conversion) とは、入力の音声の内容やその話し方を保ったまま、特定の話者の声に変換した音声を生成する技術です。 例えば以下のように、とある人の音声を七声ニーナ1の声に変換することができます。
入力音声 (JSUT コーパス2 の音声)
参考音声 (七声ニーナ)
変換した音声 (七声ニーナ風音声)
結果としては、「なんとなくそれっぽい」くらいのクオリティになっているかと思います。もちろん、現在の技術ではもう少しクオリティを上げることは可能です。ここでは「zero-shot」という方法を用いて変換を行ないました。 これは、モデルの学習に変換したい対象の音声 (ここでは七声ニーナの音声) を利用しないという意味であり、より難しい条件での結果になっています。なぜそのような条件を利用しているかは後ほど説明したいと思います。
プロンプト制御とは
2022 年 11 月、ChatGPT 3 と呼ばれるサービスが登場しました。 これは OpenAI 社が提供するサービスで、人工知能チャットボットです。 これ以前も人工知能チャットボットと会話できるサービスは存在していましたが、それまでを遥かに超える自然な対話を可能としており、世界中で今なお話題になっています。
この技術は GPT3 4 という巨大言語モデル (LLM) をベースとしており、強化学習を用いて人間に好ましい返答をするようにモデルを学習することで、人間にかなり近い自然な返答ができるものになりました。 技術的詳細は省きますが、この技術で一番面白い点は「プロンプト」と呼ばれる指示文を与えることで、あらゆるタスクに対応できるようになった点です。
プロンプトの例
user:
以下の文章を英語に翻訳して:
こんにちは!DeNA でインターンをしている、西邑と申します。よろしくお願いします。
ChatGPT:
Hello! I'm Nishimura, currently interning at DeNA. Nice to meet you!
以前は翻訳を行いたい場合は翻訳に特化したモデルを作成する必要がありました。しかし ChatGPT では「翻訳して」というプロンプトを与えるだけでそれが可能になっています。 また、単に訳すだけでなく「論文風に」等のスタイル変更もある程度可能になっていることが、このプロンプト制御の素晴らしい点だと思います。
プロンプト制御可能な音声合成技術: Prompt TTS 5
声質変換とプロンプト制御
プロンプト制御は上述したほかにも、Stable Diffusion 6 に代表される画像生成のプロダクトでも用いられています。 では、自然言語処理・画像生成ときて主題である音声分野はどうでしょうか。 残念ながら、少なくとも現時点 (2023/09) でプロンプトで制御可能な声質変換のプロダクト等は自然言語処理や画像生成のプロダクトのように多くの人が気軽に使える状況には達していません。というのも、未だ音声分野では実現が難しい部分が多く研究途上といった状態にあるからです。
そこで、まずここでは Microsoft の研究を簡単に紹介します。これを通して「音声 x プロンプト」現在の状況と課題を説明します。
Prompt TTS 5
まず、この論文で提案されているのは TTS、つまり text-to-speech で日本語では音声合成と呼ばれるモデルです。声質変換では話し手の音声を入力とし、変換したい声質に変換して出力しますが、TTS では入力としてテキストを使用します。入力されたテキストを指定した話者の声質で話した音声を出力するモデルとなっています。
さて、提案された TTS モデルは以下の図のようなものになっています。
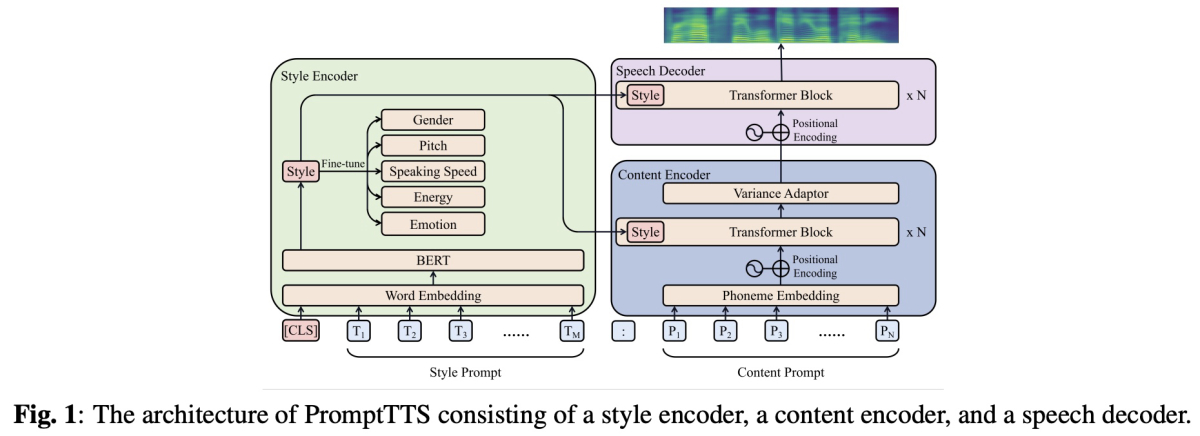
この論文で用いられた Style Prompt の例が下の表になります。

このようなペアデータは、この当時公開されたデータセットとして存在していなかったため、著者たちが新たに作成しました。
PromptTTS の課題
以上が PromptTTS の概要になります。一見これでプロンプト制御による音声合成は達成されたかのように思われますが、一つ大きな欠点があります。それは「適切なプロンプトデータの大量の用意が難しい」という点です。
今回、先述したように確かに著者らはプロンプトデータを用意しました。しかしこれは自然言語処理や画像生成分野で見られるものと次の点で異なります:
- データ数が少ない
- 専門家による「設計された」プロンプトであり、完全に自由なプロンプトではない
まず一点目ですが、論文内で著者たちが LibriTTS 7 というデータセットに対して作成したプロンプトは 26588 個 (訓練データ) になります。一見多そうに見えますが、音声以外の分野においては何億ものデータを使うのが一般的で、桁が違います。近年の生成 AI の爆発的進化の背景には「大規模なモデルを大規模なデータで訓練する」という共通項があり、これに従うためにはまだまだデータを準備する必要があるということです。
そして二点目ですが、これは一点目と関連しています。このように少ないデータでうまくモデルを訓練するには、ある程度入力データのバリエーションは少ない必要があります。そのため、たとえば一般の人に自由に質問等をして集めたプロンプトデータでは学習がうまくいかない、ということが予想されます。そのため著者らは設計されたプロンプトを用意したと思われますが、これだと当然 ChatGPT のようにあらゆるユーザーの入力に対して望ましい出力を得ることは難しくなってきてしまいます。
提案手法
さて、上述したような課題に対処するために、我々は次の二つの工夫を行いました。
- プロンプトではなく、タグを利用する
- モデル全体を一度で訓練せず、話者情報のみに注目し、これをタグ情報から生成する
工夫 1 点目: タグの利用
「PromptTTS の課題」で説明したように、プロンプトデータを大量に集める必要がありますが、これは非常に難しい話で少なくともインターンの期間に取り組める話ではありません。そのため、我々も PromptTTS のように設計されたプロンプトを考えます。特に、我々は「柔らかい女性の高い声」といった自然言語で記述したプロンプトではなく、「(女性, 高い)」といったようなタグデータをプロンプトとして扱うことにします。この工夫によって、先述したような入力のバリエーションが大きく学習が難しいといった問題を防ぐことができます。
これはもちろん「問題を簡単にしすぎなのではないか」という批判ができますが、本質的には PromptTTS と同様のことを行なっていると考えています。PromptTTS では入力のプロンプトを事前学習済みの BERT 8 を用いて情報を圧縮し取り出しています。これは入力のプロンプトからタグのように重要な情報のみを取り出していることとほとんど等価であると考えられるためです。
今後としては、このようなタグデータで ChatGPT 等を利用してプロンプトを作成することで、より実応用に近いモデルが作れると考えています。
工夫 2 点目: 話者情報に注目
PromptTTS ではプロンプトを入力して Style を獲得し、これを別のモジュールに条件づけるといったモデルを一貫して訓練していました。これは訓練プロセスが簡素になったり、明示的な中間特徴量を挟まないことによる精度向上などのメリットはありますが、一度に訓練するモデルのパラメータサイズが大きくなり、少ないデータでの学習が難しくなってしまいます。
そこで我々は、話者情報を直接モデル化することで、「話者情報を生成するモデル」と「話者情報を条件付けとして声質変換を行うモデル」の二つへ分解しました。これにより、少ないデータでの汎化性能向上が期待されます。
今回はこの話者情報として、x-vector 9 を利用しました。これはニューラルネットワークを利用して、音声から話者の情報のみを取り出すように訓練したモデルになっています。
全体の流れ
さて、ここまで我々の提案手法の工夫を説明しました。これらを踏まえて、実際に作成したシステムについて図とともに説明します。
- 声質変換モデルの作成
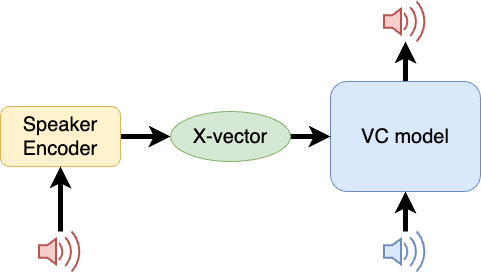
まずは、上図のように x-vector を条件付けとする声質変換モデルを訓練します。
- x-vector 生成モデル: Speaker Generator の作成
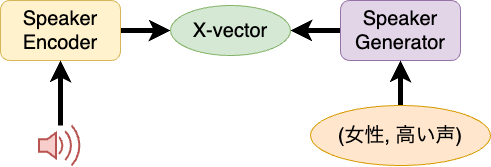
ここが我々の手法の肝になっています。先述したようにタグデータを入力とし、出力として x-vector を返すようなモデルを作成します: これを、Speaker Generator と呼びます。このようなモデルを作成することで、いろいろなタグの組み合わせに対応した x-vector を生成できるようになります。 今回は、この Speaker Generator の実際のアーキテクチャとして、Latent Diffusion model 10 を採用しました。
- 生成した x-vector による推論
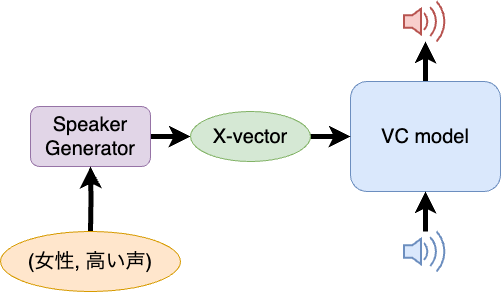
最後に、実際に声質変換を行う際には、このように入力音声とタグデータを入力することで、タグに対応した話者の声質へと音声を変換することを期待します。
結果
以上の手法を用いて、実際に音声を変換した結果をここに掲載します。 その前に、まずは実験条件について記載します。VC model は、社内で事前に用意されたモデルを使用しました。なお、データセットに記載している社内内部データの合計ファイル数は約 80,000 です。
データセット |
JVS 11 + 社内内部データ |
Speaker Generator |
Latent Diffusion model 10 |
タグデータ |
(性別, F0 ラベル). F0 ラベルは性別ごとに 4 段階で作成 |
F0 計算手法 |
Harvest 12 |
実際に出力した音声がこちらです。次のような結果が得られました:
入力音声 |
|
(男性, 0) |
|
(男性, 1) |
|
(男性, 2) |
|
(男性, 3) |
|
(女性, 0) |
|
(女性, 1) |
|
(女性, 2) |
|
(女性, 3) |
音声を聞いてもらえればわかるように、確かに声の高さを 0 から 2 等へと増やすと、実際の音声の高さも高くなっていることが確認できました。
また、これ以外にも今回用いたモデルはランダム性を含んでいるため、以下のようにランダム性を制御する random_seed を変更することによって様々な種類の話者を生成することができます。
タグデータ |
(女性, 3) |
|---|---|
seed = 0 |
|
seed = 1 |
|
seed = 2 |
|
seed = 3 |
一方で、次のような課題もあります:
- VC model の訓練に利用した話者への依存
x-vector をうまく生成できても、VC model 側の zero-shot 性能、つまり未知の話者に対する処理性能が高くないとうまく変換ができません。 これはもちろん訓練データをより多くすることで対処が可能ですが、それ以外にもモデルアーキテクチャ自体の工夫によって zero-shot 性能を上げることは可能です (例: BigVGAN 13)。 こちらは今後の課題としたいと思います。
まとめ
今回我々は、プロンプト制御可能な声質変換を達成するために、次の工夫を取り入れたモデルを提案しました:
- プロンプトではなくタグデータを利用
- 話者情報を直接生成
その結果、次の結果を得ました:
- 性別・声の高さを制御可能に
- ランダムに様々な話者を生成可能
今後の課題としては、これらが考えられます:
- zero-shot 性能の高い声質変換モデルの提案
- 大規模プロンプトデータの収集
最後に
最後になりましたが、改めてお世話になったメンターの近藤さん、園部さん、そして音声グループの皆様にお礼申し上げます。 成果に関してはここにまとめた通りですが、インターンシップでは当然これ以外の学びもあり、非常に充実した日々でした。 特に、渋谷オフィスに出社した日に行われた社内ゲーム大会が印象に残っており、こんなに楽しい会社は他にないくらい良い雰囲気でした。また機会があればぜひ皆さんと交流出来たらと思います。改めて、ありがとうございました。
参考文献
-
AI を用いた音声変換サービスのプロトタイプ 「VOICE AVATAR 七声ニーナ」を一般に公開 誰の声でも、キャラの声に変換 ↩︎
-
Ryosuke Sonobe, Shinnosuke Takamichi, and Hiroshi Saruwatari. “JSUT corpus: free large-scale Japanese speech corpus for end-to-end speech synthesis.” arXiv preprint arXiv:1711.00354 (2017). ↩︎
-
Tom Brown et al., “Language models are few-shot learners.” Advances in neural information processing systems 33 (2020): 1877-1901. ↩︎
-
Zhifang Guo et al., “PromptTTS: Controllable text-to-speech with text descriptions.” ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 2023. ↩︎
-
Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J. Weiss, et al., “Libritts: A corpus derived from librispeech for text-to-speech,” in Conference of the International Speech Communication Association (Interspeech), 2019, pp. 1526–1530. ↩︎
-
Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova, “Bert: Pre-training of deep bidirectional transformers for language understanding,” in Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL), 2019, pp. 4171– 4186. ↩︎
-
David Snyder et al., “X-vectors: Robust dnn embeddings for speaker recognition.” 2018 IEEE international conference on acoustics, speech and signal processing (ICASSP). IEEE, 2018. ↩︎
-
Robin Rombach et al., “High-resolution image synthesis with latent diffusion models.” Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2022. ↩︎
-
Shinnosuke Takamichi, Kentaro Mitsui, Yuki Saito, Tomoki Koriyama, Naoko Tanji, and Hiroshi Saruwatari, “JVS corpus: free Japanese multi-speaker voice corpus,” arXiv preprint, 1908.06248, Aug. 2019. ↩︎
-
Masanori Morise, “Harvest: A High-Performance Fundamental Frequency Estimator from Speech Signals.” INTERSPEECH. 2017. ↩︎
-
Sang-gil Lee et al., “Bigvgan: A universal neural vocoder with large-scale training.” arXiv preprint arXiv:2206.04658 (2022). ↩︎




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。