





本記事の概要
この記事では、以前 DeNA からリリースした音声変換サービス「七声ニーナ」にクロスリンガル音声機能を追加した結果について紹介します。
まず、音声変換及びクロスリンガル音声変換について概要を紹介します。 次に、音声変換での現状の問題点およびこれを解決するための既存の方法と私たちが試みた方法を説明します。 最後に、この方法で生成したサンプルを聞いて結果の品質を検証しようと思います。
はじめに
こんにちは。東京大学工学部電気系工学専攻 1 年の朴浚鎔 @nonmetal_ と申します。 8 月から約 1 ヶ月の間、AI スペシャリストコースのインターンシップに参加させてもらいました。 普段は音声に関わる色々な研究をしていて、エンタメ関連で様々な創作をするのが趣味です。
音声研究を始めたきっかけの一つが「七声ニーナ」で音声を作ったことでしたので、今回のインターンシップ参加は個人的にとても感慨深かったです。
クロスリンガル音声変換とは
ゲームやアニメなど、エンターテインメントコンテンツの海外進出に欠かせないものとしてはローカライズが挙げられます。 これは単にテキストを翻訳するだけでなく、キャラクター音声などを吹き替えするなどの行為も伴います。 このようなローカライズを行う場合には現在、言語ごとに異なる声優に音声収録を依頼し、これにより各国の言語での自然な音声をアニメーションにつけ直す必要があります。
しかし、このような解決方法では、元のキャラクターの声色と口調を複数の言語間で一貫して維持することは困難です。 私たちは、これらの問題に対する解決策として「クロスリンガル音声変換」を提案します。
音声変換(Voice Conversion)とは、音声の言語情報や話し方を保ったまま、声質を別人のように変換する技術です。
通常、機械学習による音声変換には、変換対象話者(ターゲット話者)の学習データが必要です。 そのため、多くの音声変換システムでは、ターゲット話者が話せる言語と同じ言語の音声しか変換することができません。 例えば、英語音声を変換する場合、ターゲット話者が英語で話す音声が必要となり、ターゲット話者の英語音声が手に入らない場合、発音・アクセントなどが不自然な音声が生成されます。
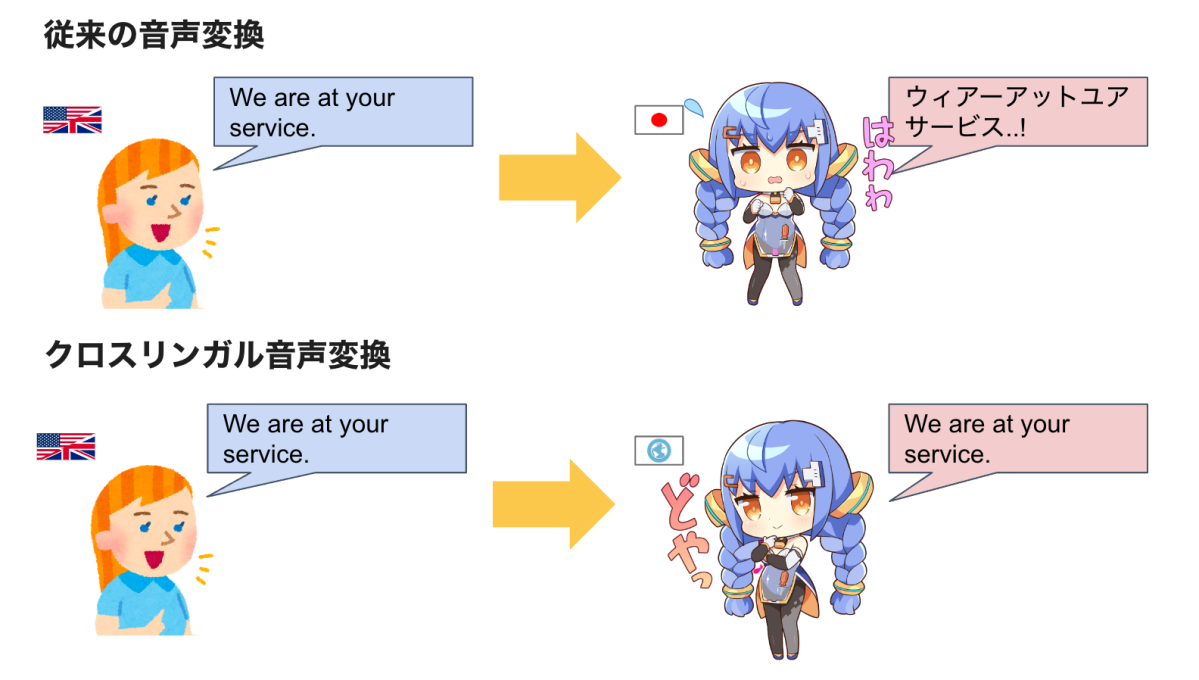
そこで、クロスリンガル音声変換によって、ターゲット話者が話せる言語と異なる言語の音声も変換できるようにします。
クロスリンガル(Cross-Lingual)とは、ある言語でできたことを他の言語でも可能にすることです。 つまり、クロスリンガル音声変換とは、ターゲット話者が話せる言語でできる音声変換を他の言語でも可能にする技術のことで、他の言語でも音声の言語情報や話し方を維持したまま、ターゲット話者の声色で話せるようになることを意味します。
クロスリンガル音声変換の場合、肉声より自然性が劣るものの、全ての言語で同じように音声変換が可能になるため、変換先の言語は考慮せず変換元となる発話の言語のみを考慮すればよいという長所が存在します。 したがって、高品質のクロスリンガル音声変換が実現されれば、低コストで声質を変えることなく、キャラクターに自然な外国語を話してもらうことができます。
今回のインターンシップでは、事業応用を考慮し、このような利点を持つクロスリンガル音声変換の最新手法を検証し、変換品質低下の原因となる訛り、韻律、品質などの問題を解決するための方法について調査しました。 具体的には、上記技術を「七声ニーナ」の改良に用いて、 4 ヶ国語が話せる「七声ニーナ 多言語バージョン」の実現を目指しました。
事前学習済みモデルを利用したクロスリンガル音声変換
音声変換モデルの基本的な構造
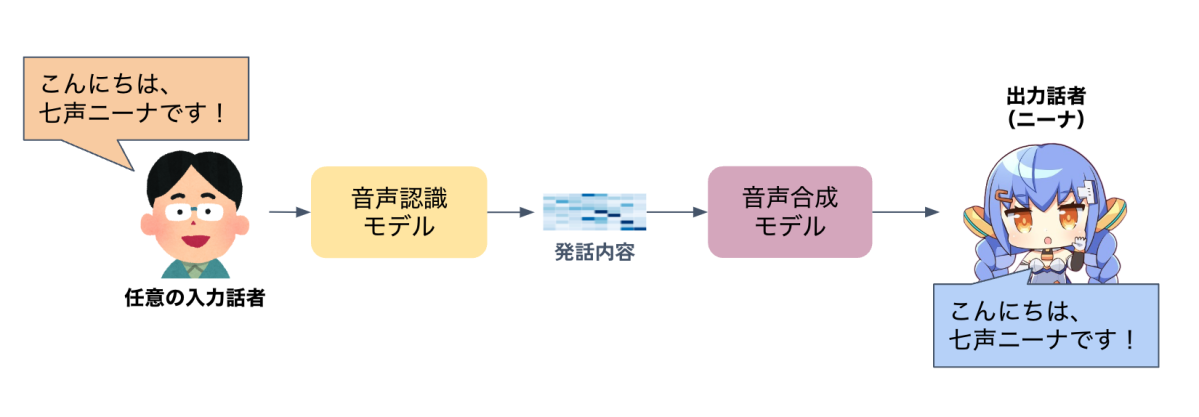
まず、DeNA で開発していた音声変換モデルの基本的な構造について説明します。音声変換モデルは、通常、入力音声から言語情報などの特徴量を抽出する音声認識モデルと、入力された特徴量から発話音声を生成する音声合成モデルの 2 つに分けられます。
従来の音声変換モデルでは、音声認識モデルから言語特徴量を抽出する際に音素事後確率(Phonetic Posteriorgram; PPG)のような、音素ベースの特徴量を使用していました。 しかし、言語学的に、ある言語では使用される特定の音素が他の言語では使用されないため、必然的に発話誤りや訛りといった問題が発生します。 これを解決する方法として、大量のデータによって事前学習されたモデルで、多言語に対応する特徴量を生成する手段を採用しました。
私たちは、事前学習済みモデルと、音声合成モデルを結合したシステムを使用して検証を行いました。事前学習済みモデルは、複数の言語のデータで学習し、 Encoder として用いました。これにより、日本語にはない音素、発話長などの特徴量も抽出しやすくなりました。音声合成モデルは、ターゲット話者の音声データと事前学習済みモデルで抽出した中間特徴量から発話音声を生成することができる Neural Vocoder です。
複数の音声変換モデルの検証
これを元に、まず、ニーナの日本語データだけで学習を行いましたが、サンプルのような結果となり、うまく変換できませんでした。
🇬🇧 元の音声 |
ニーナの日本語データで学習した変換音声 |
|---|---|
韻律は概ね正しく反映することができたものの、日本語ではなく他の言語についての変換であるため、他の言語を日本語の音素だけでは表現できず、発話が乱れる問題が確認されました。
これらの問題を解決するために、いくつかのオープンソースで試された方法を検証してみました。 そのうち DDSP-SVC[3]というオープンソースでは、上記のような事前学習済みモデルによる特徴量抽出の後、音声合成モデルによって波形生成を行った上で、音声の後処理として品質改善のために Diffusion[4]モデルを使用する手法が提案されており、高品質な音声生成を可能にしていることがわかりました。
さらに、音声合成モデルを事前に多数の言語で学習することで、予めアクセントエラーを防ぐことができました。
複数の音声変換モデルから目標音声へのクロスリンガル化
このような背景から、複数のモデルを組み合わせて、従来の音声変換及びオープンソースの品質を超えるクロスリンガル音声変換システムを実現することを目標にしました。 日本語話者の音声で 4 ヶ国語音声を生成するために最終的に選択したクロスリンガル音声変換システムの構造は次のとおりです。
最終的なクロスリンガル音声変換システムの構造
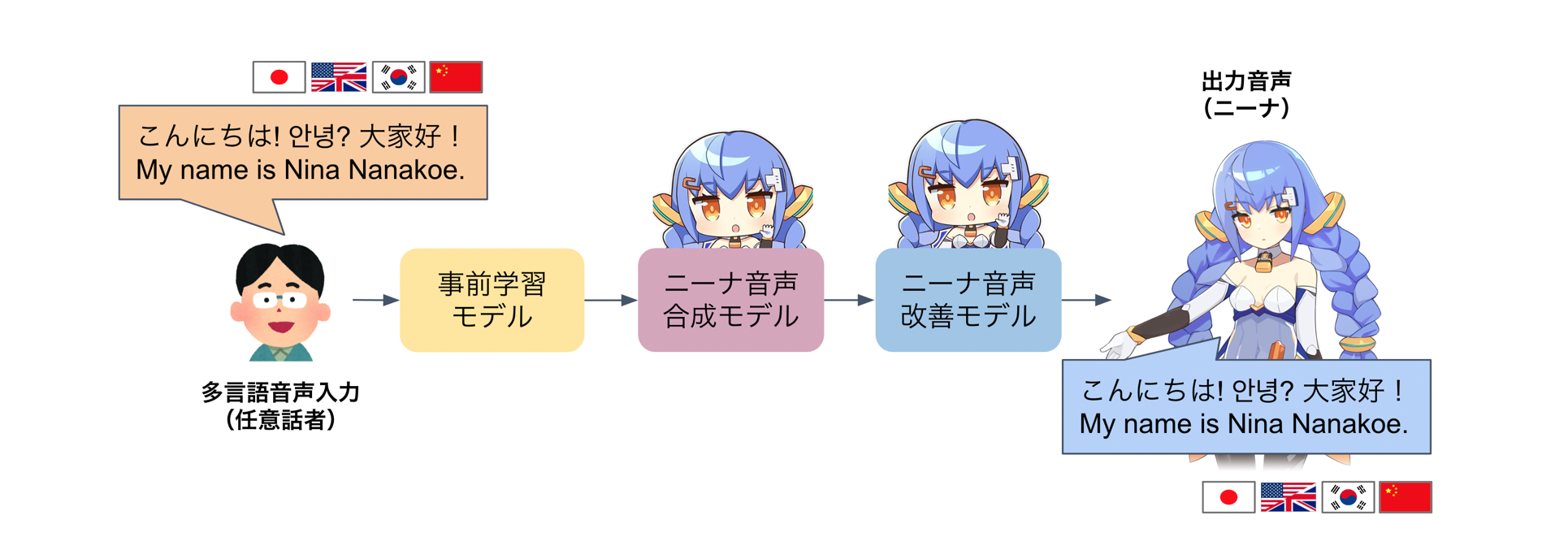
事前学習済みモデルによって任意話者の音声入力から中間特徴量を抽出した後、この特徴量からニーナの声色で合成するニーナ音声合成モデルで再構成し、そして音声の品質を改善するニーナ音声改善モデルを経て最終的に出力音声が変換されます。 図中の事前学習モデルとニーナ音声合成モデルは、ぞれぞれ前述の事前学習済みモデルと Neural Vocoder を指します。 そして、ニーナ音声合成モデルで生成された結果を Diffusion に基づく音声改善モデルを用いて品質向上させ、最後に、事前学習された Neural Vocoder によって音声を再構成します。
音声合成モデル全体の構成及び学習方法
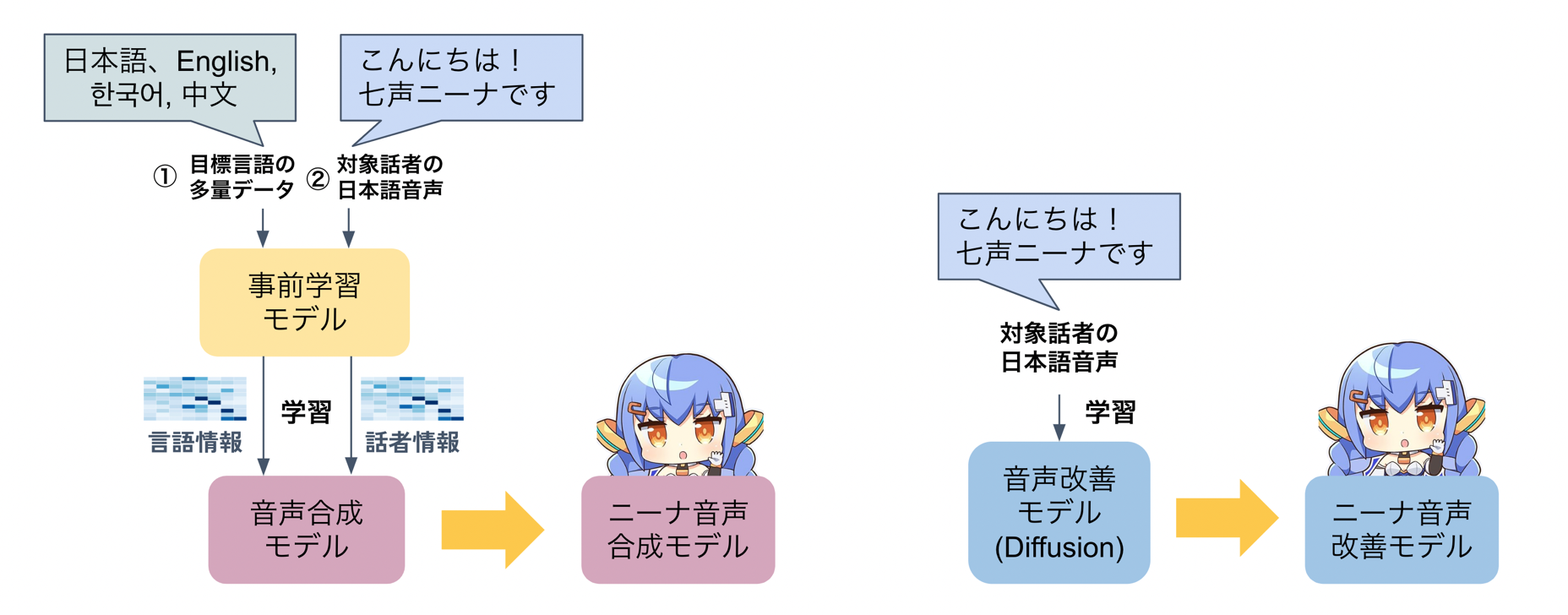
これらニーナ音声合成モデル、ニーナ音声改善モデルからなる音声合成モデル全体を、ニーナの声色で訛りがなく話せるように学習します。
まず、ニーナ音声合成モデルを、目的言語となる 4 ヶ国語で学習します。 工夫点として、話者が似たような 4 ヶ国語のデータを事前学習に用いることで、各言語における発話誤りを減らすことができました。
次に、ファインチューニングによって話者を制御します。 上記のように学習されたモデルをニーナの音声でファインチューニングすることで、ニーナの声色で音声を生成できるようにします。
最後に、音声改善モデルである Diffusion も同様に、ニーナの音声でファインチューニングします。これにより、ニーナ音声合成モデルにより出力された音声を音声改善モデルに入力したときに話者性が変わらないようにします。
音声サンプル
これらのモデルで構成されたクロスリンガル音声変換手法によって、各言語の音声をニーナの声色に変換した結果のサンプルを紹介します。
元の音声 |
事前学習済みモデルと ニーナ音声合成モデルを用いた変換音声 |
さらに音声改善モデルを 用いて品質向上した音声 |
|
|---|---|---|---|
🇯🇵「こんにちは! 七声ニーナです。」 |
|||
🇬🇧 “Hi, everyone! My name is Nina Nanakoe.” |
|||
🇰🇷 “안녕! 난 나나코에 니나라고 해.” |
|||
🇨🇳「大家好! 我叫七声妮娜。」 |
この構造によって、従来の手法と比較して、話す内容やイントネーションをよく維持したまま、高音質の音声変換が可能になったことが確認できました。
まとめ
冒頭で述べたクロスリンガル音声変換における訛りや品質の問題について、複数の言語で事前学習されたモデルを用いた特徴量抽出や、目標言語でのモデル学習後に行うターゲット話者でのファインチューニングなどの改良によって、大幅に品質改善することができました。 今後としては、このシステムをリアルタイムで動作させるようにすることや、訛りの程度を制御できるようにすること、さらにはイントネーションの除去及び付与について工夫したいと考えています。
最後に
インターンシップの中では、メンターの方をはじめ DeNA 音声グループの方々に、研究アイデアから開発環境のトラブルシューティングまで、細かいサポートをいただけてとても助かりました。 そして、エンターテインメントがテクノロジーと出会い、より高い価値を生み出すことができることを改めて感じました。研究室での研究とはまた違った、研究結果をもとにこれを応用してプロダクトにつなげることができる環境が印象的で楽しかったです。
DeNA のサマーインターンシップは、研究者としてもエンジニアとしても一歩前進できる非常に素晴らしいプログラムです。これを見て少しでも興味を持った方は是非申し込んでみてください!
参考文献
[1]
理想の声を目指して 〜七声ニーナの音声変換技術からライブ配信応用へ〜
[2]
事前学習モデルを用いたクロスリンガル声質変換
[3]
DDSP-SVC: Real-time end-to-end singing voice conversion system based on DDSP
[4] Rombach, R. et al. High-Resolution Image Synthesis with Latent Diffusion Models,
arXiv:2112.10752



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。