





はじめに
はじめまして!2023年9月にAIスペシャリストのインターンシップに参加させていただきました、柳( @ynt0485 )と申します。普段は数理最適化や機械学習関連の研究を行っています。
今回のインターンでは、DeNAが運営するX(旧Twitter)アカウントの投稿文を自動生成するというタスクに取り組みました。この記事では、どのような工夫によって生成の精度を上げることができたのかについて紹介します !
課題内容
概要
初めに、今回のタスクの概要についてお話します。
近年の大規模言語モデルの発展により、文章の自動生成は様々な分野での活用が期待されています。特に、ある分野に特化させた文章の生成はクリエイティブの制作やサービス専用のチャットボットの構築に利用することが できます。
そのため、今回は特定分野に特化させた文章生成の1つとして、あるX(旧Twitter)アカウントの過去の投稿文を用いて新たな投稿文を自動生成するというタスクに取り組みました。
ベースラインの説明
投稿の自動生成にあたり、DeNAが運営しているアカウントの過去の投稿データを共有していただきました。リプライでない投稿を除くと、過去の投稿データは約800件ほど存在しています。ここから、2023年6月の投稿をテス トデータとし、この期間の投稿を過去の投稿をもとにして生成することを目指します。
なお、今回のインターンシップではメンターの方が事前に構築されていたベースライン(簡単なアルゴリズムで出せるアウトプット)を改善していくという形で取り組みました。そのため、はじめにベースラインの概要について紹介します。
ベースラインのステップは大きく以下の4つになっています。

まず、STEP1では各投稿からキーワードを抽出するという処理を行います。ベースラインでは各投稿をMecabで形態素解析した上でtf-idf値を計算し、tf-idf値が高い上位5件をキーワードとして抽出しています。
次に、STEP2では予測対象である2023年6月の各日について、どのキーワードを用いて投稿を生成するか、STEP1で抽出したキーワードの情報をもとに決定します。ベースラインでは、去年の同じ日を基準として近い日付からキ
ーワードを選択しています。例えば、2023年6月1日の投稿を生成する場合は、2022年6月1日の投稿からキーワードを選択します。一方で、2022年6月1日の投稿が存在しない場合は2022年5月31日の投稿からキーワードを選択し
ます。
なお、今回の問題設定では1日に5件の投稿を生成することを想定しているため、キーワードも各日につき5件選択しています。
STEP2までで各日に使用するキーワードが決定したので、STEP3ではキーワードをもとにChatGPT APIを用いて投稿文を生成します。 なお、生成の際はfew-shot learningを行っており、OpenAI APIの Embeddings を用いてキーワードと投稿文のベクトルを取得後、キーワードと類似した過去の投稿文を探索して以下のようにmessagesに追加しています。
messages = [
{"role": "system", "content": "You are a very helpful assistant."},
{"role": "user", "content": f"美容・健康に興味がある女性に対してTwitterでアプローチしたいです。"},
{"role": "assistant", "content": "わかりました。可能であれば参考になる投稿を教えて下さい。"},
{
"role": "user",
"content": f"""{過去の投稿文}""",
},
{"role": "assistant", "content": "ありがとうございます。具体的にどのキーワードでツイートがほしいですか?"},
{
"role": "user",
"content": f'''keyword = {今回生成に使用するキーワード} でお願いします。''',
},
]
最後に、STEP4では生成した投稿文と実際の投稿文を用いて定量的な評価指標を計算します。今回は機械翻訳の評価でよく用いられるBLEUスコアに加え、STEP3でも用いたEmbeddingsを生成した投稿文と実際の投稿文について 計算し、そのコサイン類似度を計算することで、文章の意味の観点から生成した投稿文が実際の投稿文にどれだけ近いかを評価しています。また、各日5件の投稿文が生成されるため、各日の評価は5件のうちの最大値を用い ています。
ベースラインの改善
それでは、ここから実際に取り組んだ改善ポイントについて紹介していきます。
キーワード抽出
まずはじめに、STEP1でのキーワード抽出の改善点を考えます。ベースラインを動かした結果得られるキーワードの例が以下になりますが、いくつか問題点があります。
- 「!?」のような記号が含まれている
- 「言う」「せい」などトピックを表しているとは言えない単語が含まれている

キーワード抽出の精度が低い場合、生成の際に使われるキーワードに意味のない単語が含まれてしまう可能性があるため、適切なキーワードが抽出されるかつ、無駄なキーワードが含まれないような状態を目指していきます 。
上記のような目的を達成するために、EmbedRank[1]という手法を導入します。EmbedRankはキーワード抽出の手法の1つで、文書のベクトルとキーワードのベクトルを利用します。
EmbedRankでは以下の手順でキーワードを抽出します。
- 品詞などの情報を用いて文書の中からキーワードの候補を絞り込む
- Doc2VecやBERTを用いて文書とキーワード候補のベクトルを取得する
- 各キーワード候補のベクトルについて文書ベクトルとのコサイン類似度を計算し、高いものをキーワードとして抽出する (今回はコサイン類似度の閾値を設定し、それを超えるものをキーワードとしています)
さらに、EmbedRankではキーワードを追加する際、それまでにキーワードとして選択されたものとの類似度を考慮した指標を導入することで、キーワード同士が似通ったものにならないようにしています。
上記の例に対してEmbedRankを適用した結果が以下になります。なお、ベクトルの取得にはSentence BERTの「sonoisa/sentence-bert-base-ja-mean-tokens-v2」[2]を利用しました。
結果を見ると、適切なキーワードが含まれていることに加え、tf-idfで抽出されていた不要なキーワードが抽出されなくなっていることがわかり、改善を確認することができました。シンプルな手法かつ性能が高いため、私 自身もその他のキーワード抽出のタスクでも利用できる可能性があると感じました。

キーワード選定
次に、STEP2の改善についてお話していきます。
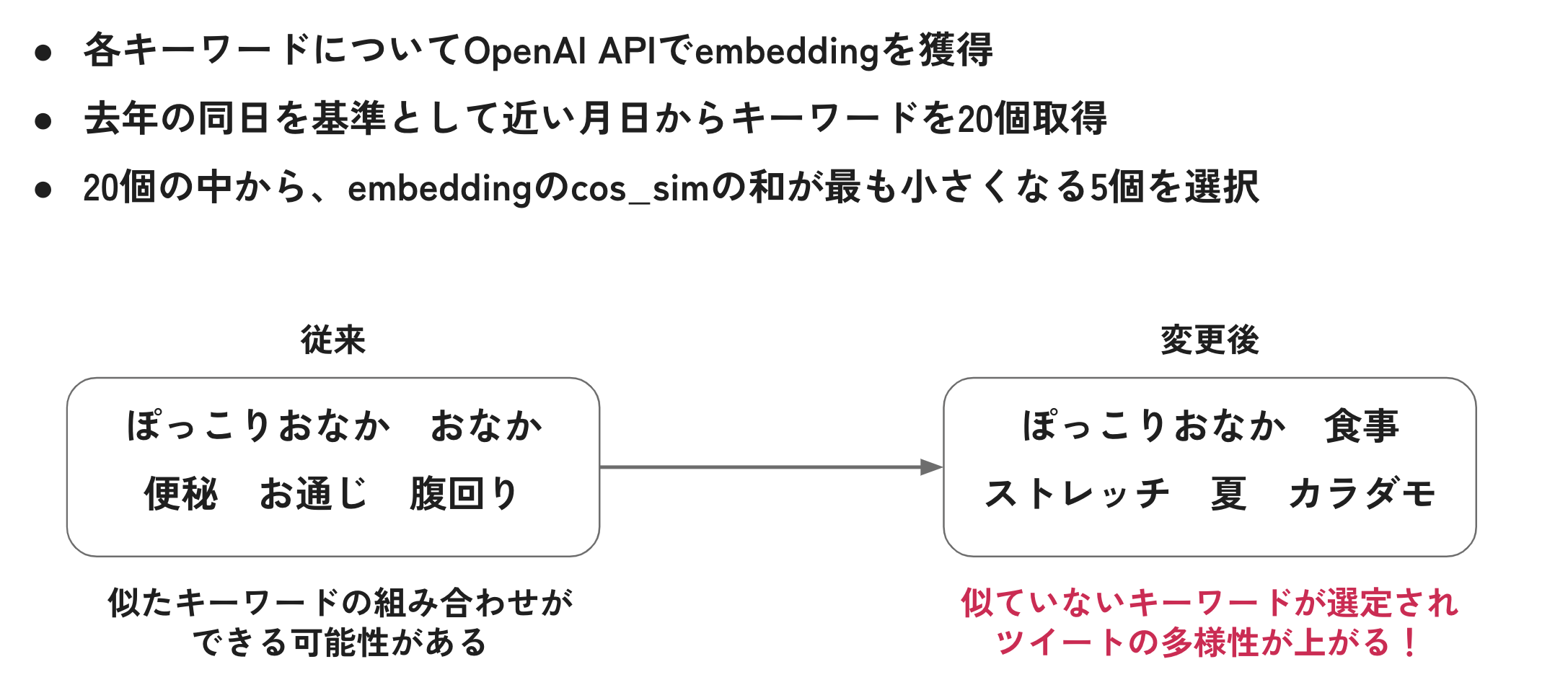
STEP2では、テストデータである2023年6月の各日について使用するキーワードを5個ずつ選定していましたが、これによって選ばれたキーワードの組み合わせを確認した時、「5個のキーワード同士が似通ることがある」とい う課題があることに気づきました。
例えば、選ばれたキーワード5件の中に「ぽっこりおなか」「おなか」「おなかまわり」の3つが存在する場合、5件投稿文を生成しても3件は同じような投稿文になり、投稿文のバリエーションが少なくなってしまいます。ま た、今回の評価指標では各日の評価は5件のうちの最大値を用いるため、1個でも評価の高い投稿文が生成されることが重要になります。そのため、各日で使用するキーワードに多様性を持たせることで、精度を向上させるこ とができるのではないかと考えました。
そこで、今回はOpenAI APIのEmbeddingsを用いて、多様性のあるキーワード集合を作ることにしました。具体的には、STEP2で選定するキーワードを各日20個に増やし、その20個のキーワードのベクトルを取得します。その後 、20個の中からベクトルのコサイン類似度の和が最も小さくなる(=似通っていない)5個をキーワードとして選択します。これにより、キーワード同士の多様性を持たせることができます。
実験結果
ここまでの取り組みによって、評価指標がどれだけ改善したかを確認します。実験の結果、コサイン類似度およびBLUEは以下のようになりました。
| 実験名 | コサイン類似度 | BLEU |
|---|---|---|
| ベースライン | 0.8500 | 0.024 |
| EmbedRank | 0.8610 | 0.011 |
| キーワード多様性 | 0.8589 | 0.017 |
| EmbedRank + キーワード多様性 | 0.8612 | 0.010 |
結果を見ると、それぞれの導入手法とその組み合わせによってコサイン類似度がベースラインより改善していることがわかります。一方で、BLEUはやや悪くなっていますが、ベースライン時点でもBLEUは低い値であったこと や、BLEUは意味的な類似を評価する指標ではないことから、インターンシップ中はコサイン類似度を主な評価指標として実験を進めていました。
OSSモデルのFine-tuning
目的
続いて、STEP3の投稿文の生成について、検証した内容をお話します。
STEP3では、ChatGPT APIを用いて投稿文を生成していました。しかし、ChatGPT APIに依存したアルゴリズムを運用していく場合、API終了や料金の改定などに従う必要があり、運用に不安が残ります。そこで、今回はOSSモデ ルのFine-tuningによって、どれだけ実用的な生成が可能になるか(どれだけChatGPT APIに近づくことができるか)を検証することにしました。
学習設定
次に、OSSモデルの選定や学習設定について紹介します。
まずはじめに、モデルの選定についてです。日本語に対応した大規模言語モデルは数多く存在しますが、今回は以下の理由から「stabilityai/japanese-stablelm-base-alpha-7b」[3]を選択しました。
- 商用利用が可能
- A100×1枚で学習が可能なモデルサイズ
- JGLUEスコア[4]での性能が他モデルと比較して高い
続いて、学習データセットについてです。投稿データを以下のinstruction形式のデータセットに整形し、学習に用いました。
{
"instruction": "美容・健康に興味がある女性に対して訴求するTwitterの投稿文をキーワードから生成してください",
"input":[EmbedRankで抽出したキーワード],
"output":[実際の投稿文]
}
また、今回は商用利用の関係でbaseモデルを利用しているため、投稿データセットだけではinstruction形式の回答を十分に学習することができないと考え、一般的なinstructionデータセットである「kunishou/databricks-d olly-15k-ja」[5]を同時に学習に利用することで、約16,000件の学習データを用意しました。
次に、学習設定についてです。学習では大規模言語モデルを効率よく学習することのできるLoRA[6]を利用しています。パラメータ等については以下の通りです。
- 使用GPU:A100-40GB×1枚
- 学習手法:LoRA
- r : 32
- lora_alpha : 64
- lora_dropout : 0.05
- lr:2e-4
- epoch数:2(約6時間)
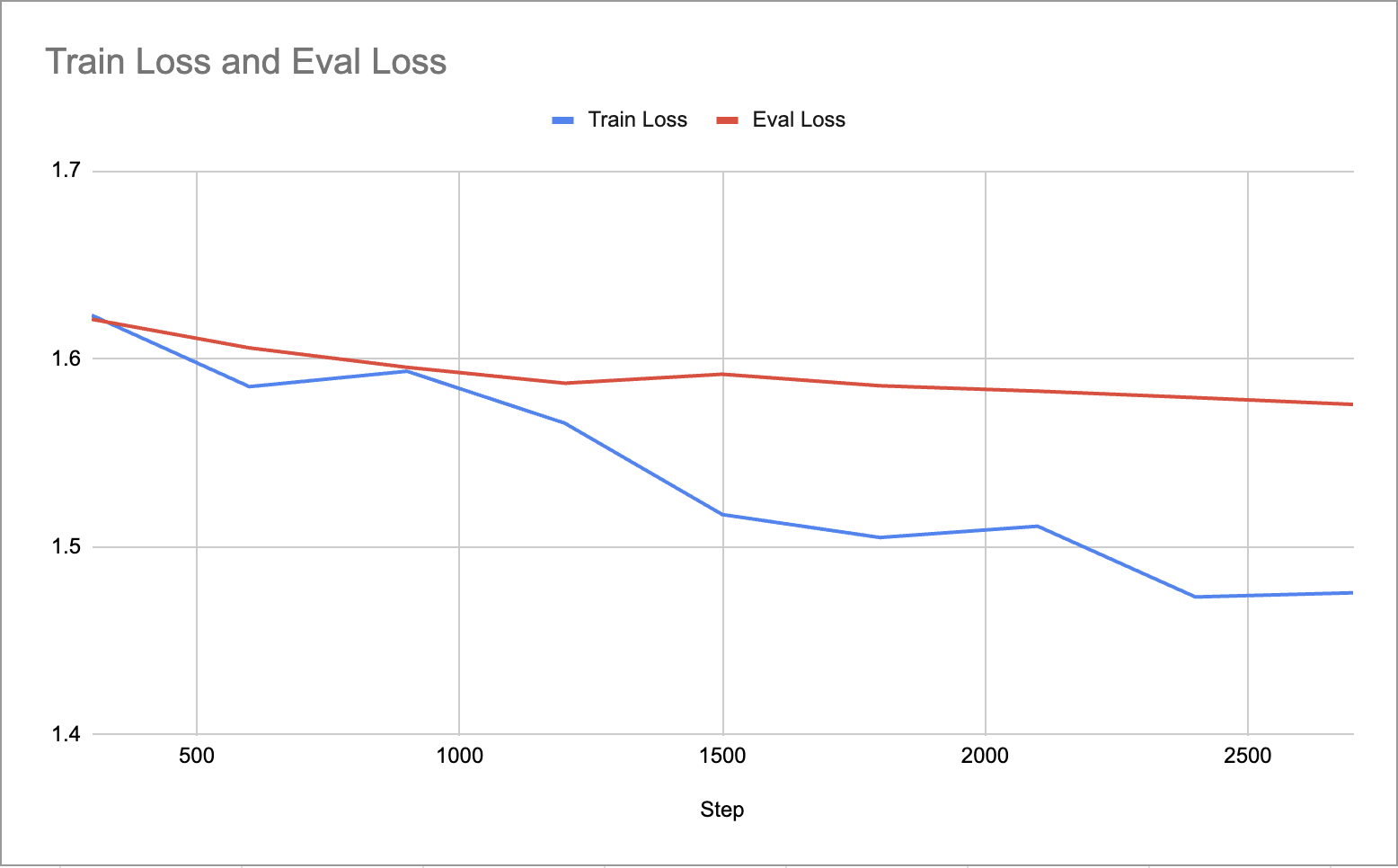
以下は学習時のLossの推移です。大幅にEval Lossが減少しているといったことはありませんが、概ね安定して学習が進んでいることがわかります。
生成結果
ここまでの設定を踏まえて、Fine-tuning前と後で生成された投稿文を比較してみます。以下の例は、「美容・健康に興味がある女性に対して訴求するX(旧Twitter)の投稿文をキーワードから生成してください。」というpr omptに対してキーワードを入力した結果です。

Fine-tuning前は説明文のような文体になっていたり、promptを繰り返すような出力になっていますが、Fine-tuning後は自然な投稿文が生成されていることがわかります。
次に、ChatGPT APIとFine-tuning後のモデルで同様の比較を行います。

文章の流暢さや絵文字の使い方に差はあるものの、ChatGPT APIとほぼ同等の質の投稿文が生成できていることがわかります。たった16,000件程度のデータセットでここまで自然な投稿文を生成できるのは驚きでした!
今後の課題
最後に、今後の課題について紹介します。今後の課題としては以下のようなものが考えられます。
- 直近の投稿と内容が被らないようにするといった工夫
- いいね数などと併せて反響の良い投稿の特徴を分析し、生成に活かす
- その他の評価指標の導入
このうち、「その他の評価指標の導入」についてはインターンシップ終盤に追加で実験を行ったので、簡単に内容を紹介します。
今回の取り組みではBLEUおよびベクトルのコサイン類似度を使用していました。一方で、Fine-tuning前と後の結果を見ていると、文法がおかしな投稿文でもテストデータとのコサイン類似度がある程度大きくなっていること がわかり、コサイン類似度がそもそも日本語として自然かどうかを適切に評価できていない可能性があります。そのため、言語モデルが出力する単語の予測確率によって文章の自然さを定量化するMLM-Scoring[7]や、テキス トの生起確率分布間のKL Divergenceを用いて文章の自然さを定量化するMAUVE[8]などの評価指標を導入することで、より適切な評価を行うことができるのではないかと考えています。
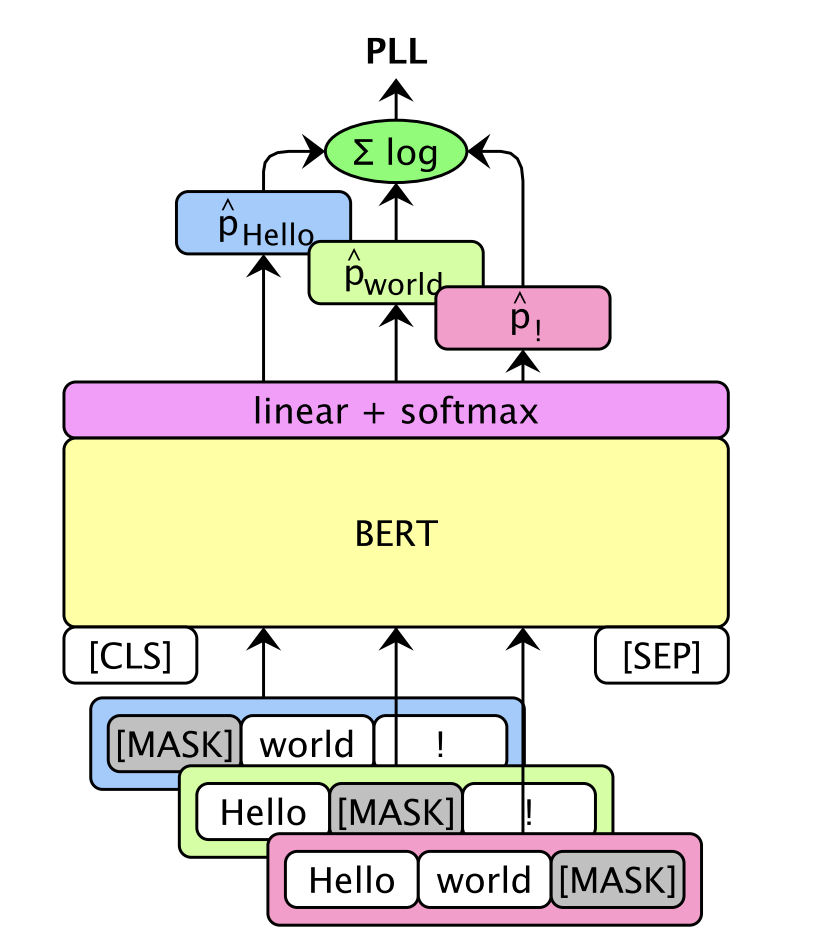
ここで、MLM-Scoringについては実際に実験を行いました。MLM-Scoringは各単語をMASKしたときの単語の予測確率の対数尤度の和をスコアとします。これにより、スコアが高い=modelがMASK部に入ると思った単語と実際の単 語が一致している→自然な文章であるというような解釈が可能になります。
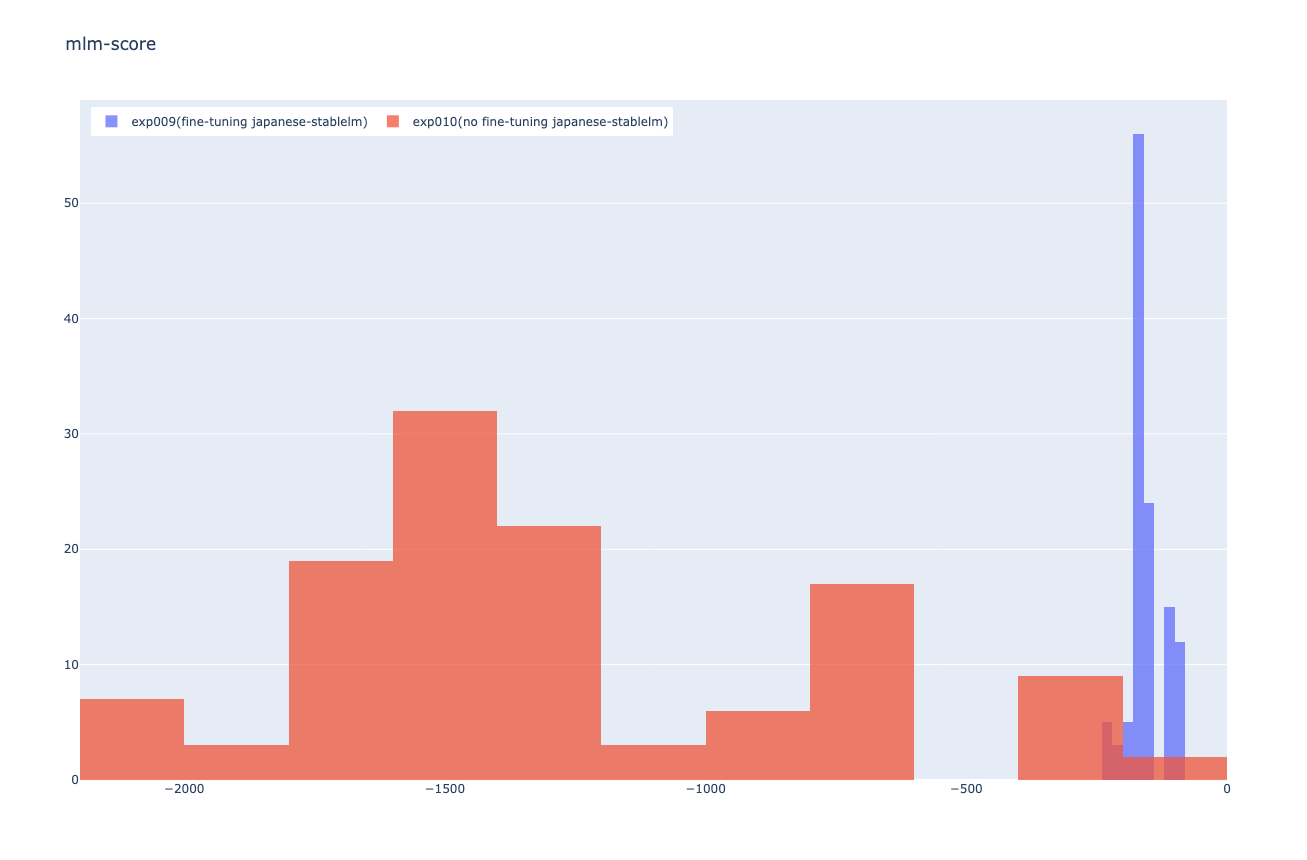
実際に、Fine-tuning前と後で生成した投稿文のMLM-Scoringの分布が以下になります。Fine-tuning後の方が分布が右に寄っている(スコアが高くなっている)ことがわかり、Fine-tuning後の方が自然な文章を生成できてい ることがわかります。
一方で、MLM-Scoringでは言語モデルにおける各単語の生起確率を使用するため、X(旧Twitter)の投稿文のように通常の文章とは少し文体が異なるものについては評価が人間の感覚と一致しない可能性が考えられます。その ため、投稿データを用いて言語モデルの事前学習を行うなどの工夫によって、より適切な評価を行うことができるのではないかと考えています。
まとめ
今回のインターンシップではX(旧Twitter)投稿文の自動生成アルゴリズムの改善及び、大規模言語モデルのFine-tuningによる検証を行いました。既存のアルゴリズムの改善をしたり、実用ができそうな投稿文の生成をOSS モデルのFine-tuningによって実現することができました。
また、今回は投稿文の自動生成というタスクでしたが、過去の情報からキーワードを選定し、文章を生成するというアルゴリズムは広告文の自動生成などにも応用可能であるため、さらなる発展の可能性を感じています。
インターンを通じて
インターンシップ中はメンターの方をはじめとして、様々な社員の方々とコミュニケーションを取ることができました。タスクを進めるにあたっての相談だけでなく、DeNAの強みやキャリアパスについても丁寧にお話をして くださり、技術力の高さに加えて、社員の方々の暖かさを直接体感することができました。非常に充実した3週間だったなと感じています!
改めまして、この度はインターンシップに参加させていただき、ありがとうございました!
参考文献
[1]Bennani-Smires, K., Musat, C., Hossmann, A., Baeriswyl, M., & Jaggi, M. (2018). Simple unsupervised keyphrase extraction using sentence embeddings. arXiv preprint arXiv:1801.04470. [2]https://huggingface.co/sonoisa/sentence-bert-base-ja-mean-tokens-v2 [3]https://huggingface.co/stabilityai/japanese-stablelm-base-alpha-7b [4]https://wandb.ai/wandb/LLM_evaluation_Japan/reports/Nejumi-LLM—Vmlldzo0NTUzMDE2?accessToken=u1ttt89al8oo5p5j12eq3nldxh0378os9qjjh14ha1yg88nvs5irmuao044b6eqa [5]https://huggingface.co/datasets/kunishou/databricks-dolly-15k-ja [6]Hu, E. J., Shen, Y., Wallis, P., Allen-Zhu, Z., Li, Y., Wang, S., … & Chen, W. (2021). Lora: Low-rank adaptation of large language models. arXiv preprint arXiv:2106.09685. [7]Salazar, J., Liang, D., Nguyen, T. Q., & Kirchhoff, K. (2019). Masked language model scoring. arXiv preprint arXiv:1910.14659. [8]Pillutla, K., Swayamdipta, S., Zellers, R., Thickstun, J., Welleck, S., Choi, Y., & Harchaoui, Z. (2021). Mauve: Measuring the gap between neural text and human text using divergence frontiers. Adva nces in Neural Information Processing Systems, 34, 4816-4828.


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。