





自己紹介
初めまして。京都大学工学部情報学科4回生の羽路悠斗です。8/16~9/9にAIスペシャリストコースの就業型インターンシップに参加しておりました。
普段は、テーブルデータの分析・機械学習エンジニアのアルバイトと、深層学習のプロジェクト型アルバイトをしています。Kaggleでは銀メダル2枚のKaggle Expert で、金メダルを獲れるよう精進しています。卒業研究では、表情認識への画像生成の活用に取り組む予定です。
本記事では、インターンシップで取り組んだ、ライブ配信アプリ「Pococha」の推薦の工夫について、執筆したいと思います。
取り組んだテーマ
本インターンシップで取り組んだテーマは、「ライブ配信アプリPocochaにおけるロングテールプラットフォームを実現するための推薦モデルの開発」です。
Pocochaのプロダクト設計においては、「ロングテール」なサービスを作ることを大事にしています。ロングテールとは、ある一部のコンテンツだけにトラフィックを集中させるのではなく、コンテンツの投稿ハードルを下げ、サービスを使う一人ひとりのユーザーそれぞれの居場所をつくるサービス構造のことです。1 この考え方に共感し、AIを活かしてプロダクトの課題を解決したいという想いもあり、本テーマに取り組ませていただくことにしました。
図1:ロングテールなプラットフォーム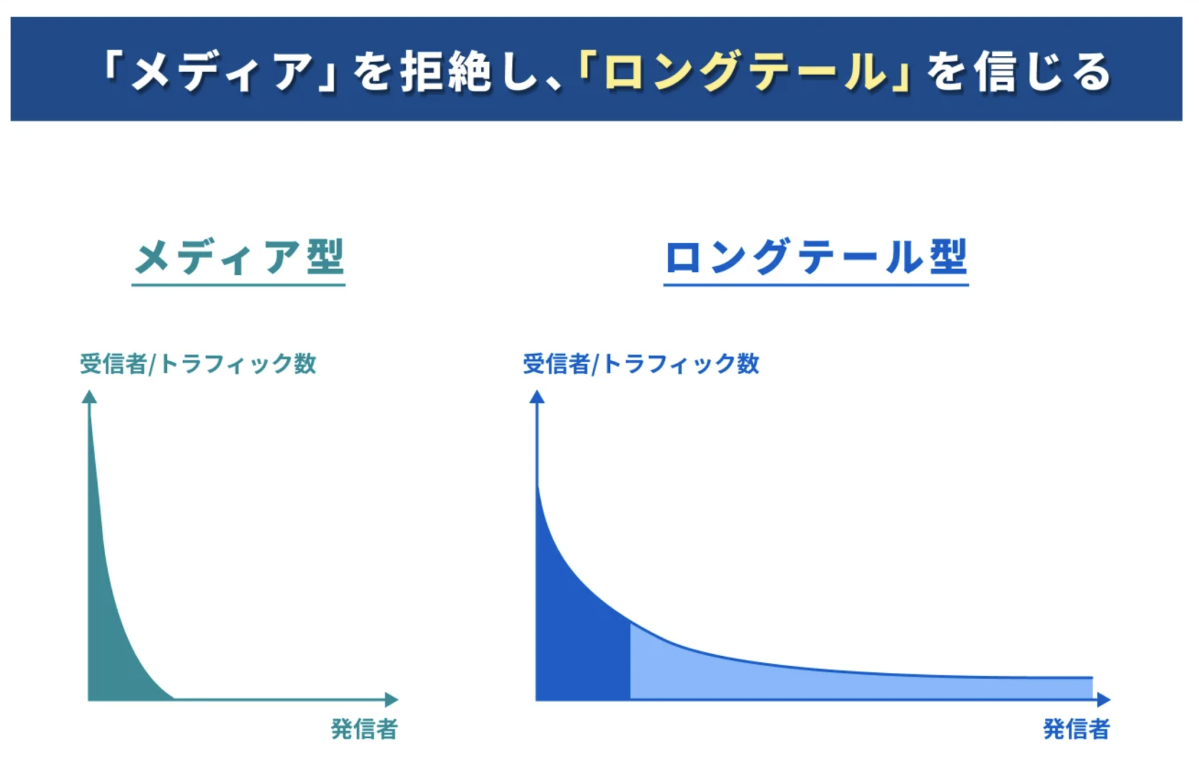
なお、今回の取り組みは、製品に組み込まれているモデルをそのまま使った検証ではないことをご留意ください。
本テーマにおける課題点
よりロングテールな構造の推薦モデルを目指すことは、テール層の配信者にとってはメリットがあります。ですが、それによって精度が下がり、視聴者の興味のある配信者を推薦できなくなってしまうと、視聴者側のUXに悪影響を与えます。よって、モデルの精度を保ちながら、テール層も拾いこぼさないような推薦モデルをいかに実現するかというのが、解決すべき課題であると言えます。
また、ロングテールというのは曖昧さを含む言葉であり、技術的にどう扱うかという観点では、議論の余地があります。事業に関わる方やPocochaの推薦モデル開発に携わる方と議論を重ね、今回は「より多くの配信者をできるだけ平等にカバーする」と定義することにしました。テール層がどの配信者かを定義せず、あくまでモデルの推薦結果にのみ注目することで、テール層と定義されなかった配信者が不利益を被ることを避けたいという意図です。
精度以外の観点で評価される推薦モデルの領域は “beyond accuracy"と呼ばれ、近年注目されている分野です。2016年に発表された”Diversity, serendipity, novelty, and coverage: a survey and empirical analysis of beyond-accuracy objectives in recommender systems”2において、よくまとめられています。
ベースライン
比較のためのベースラインの設計を説明します。なお、特に記載のない限りは、後述の実験においても、ベースラインと同様の設計です。
- モデル
- LightGBMを用いた
- 欠損地処理やスケーリングが不要な扱いやすさや計算時間の速さが理由
- 視聴者と配信者の組み合わせに対する、二値分類として解く
- ラベルは、初視聴後に該当月と来月のいずれかでコアファン(いわゆる推し)になるか
- 正例は初視聴からコアファンになった組み合わせ
- 負例はそれ以外の全ての組み合だが、学習時は初視聴からの非コアファンのみを用いた
- 負例比10倍にダウンサンプリング
- 未視聴の組み合わせも少数をランダムサンプリングして負例として混ぜる
- 推論時は、視聴者ごとに予測値の降順に並べ替えて、上位k人の配信者を推薦する(今回はk=500)
- オンライン推薦ではなく、バッチ推薦を行う想定
- 推論対象
- 過去4週間に視聴履歴があるユーザーを対象視聴者
- 過去1週間に配信履歴があるユーザーを対象配信者
- 学習、検証の分割
- 3, 4月の初視聴からのコアファンを学習データの正例とした
- 6月の初視聴からのコアファンを検証データの正例とした
- 検証時は対象の全配信者に対して推論するため、膨大な数の組み合わせの中から視聴者を2144人サンプリングした
図3:学習と検証の分割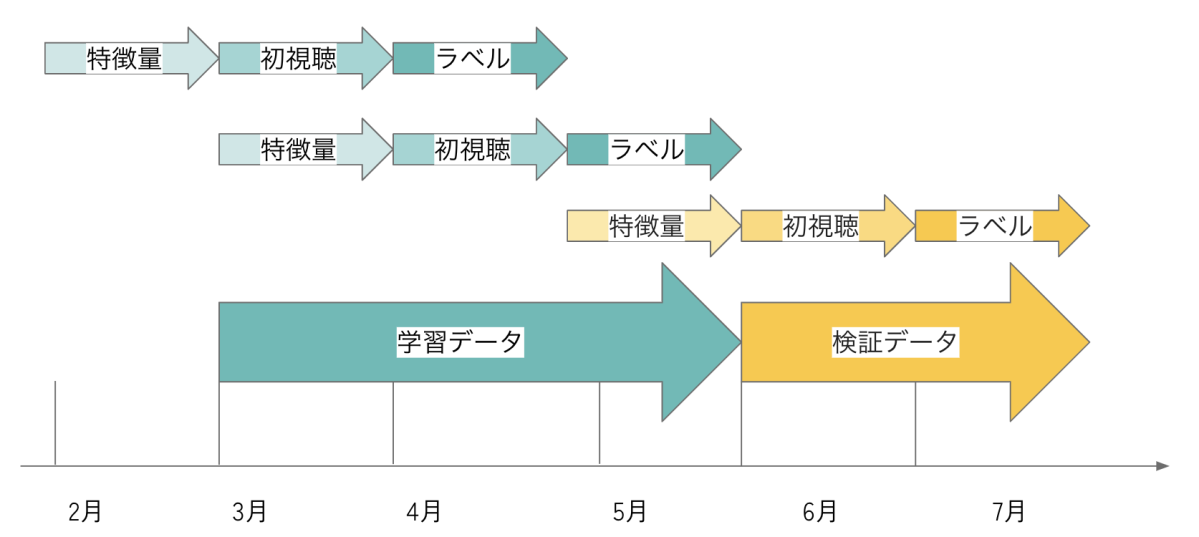
評価指標
評価指標の説明です。まず、既存のモデルで用いられている評価指標を説明し、次に、新たにロングテール性の評価のための指標を提案します。
既存モデルの評価指標
nDCG
nDCGは、推薦モデルの精度の指標としてよく用いられています。並べ替えの正しさを表す指標です。
CoverRateAUC
CoverRateAUCはロングテール性の評価のための指標です。top-kを変えながら、最低1回出現している配信者の割合をプロットし、AUCを評価します。より大きいほど、ロングテールな推薦ができています。
図4:Cover Rate AUC のグラフ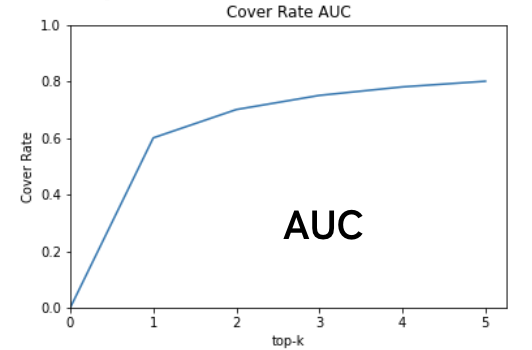
本指標は問題点があり、でたらめな推薦でもカバー率さえ高ければ評価される点と、最低1回でも出現すれば良いので出現回数の大小は無視して評価する点です。
新たな評価指標
以上の問題点に対処するために、新たに2つの評価指標の利用を提案します。
Positive Cover Rate AUC
1つ目が、PositiveCoverRateAUCです。top-kを変えながら、最低1回出現している「正例」配信者の割合をプロットし、AUCを評価します。先述のでたらめな推薦でも評価される点を改善したものです。いわば、良いロングテール推薦ができているかを見る指標です。
ジニ係数
2つ目が、ジニ係数です。元々は所得の不平等さを測る指標です。累積度数をx, 累積所得をyにプロットしたローレンツ曲線と、均等配分線y=xの間の面積を求めます。配信者の出現回数を所得とみなして適用します。小さいほど、より平等を表す指標です。出現回数の大小を無視していた点を改善します。
ロングテールな推薦手法の提案
ロングテールな推薦について、3つの取り組みを行いました。
取り組み1
図5より、出現回数が上位の配信者は、検証データの2144人の視聴者に対して、2000人以上に対して推薦されていることがわかります。そこで、配信者の出現回数に上限を設けることで、より広い層が推薦されるようになるのではないかと仮説をたてました。
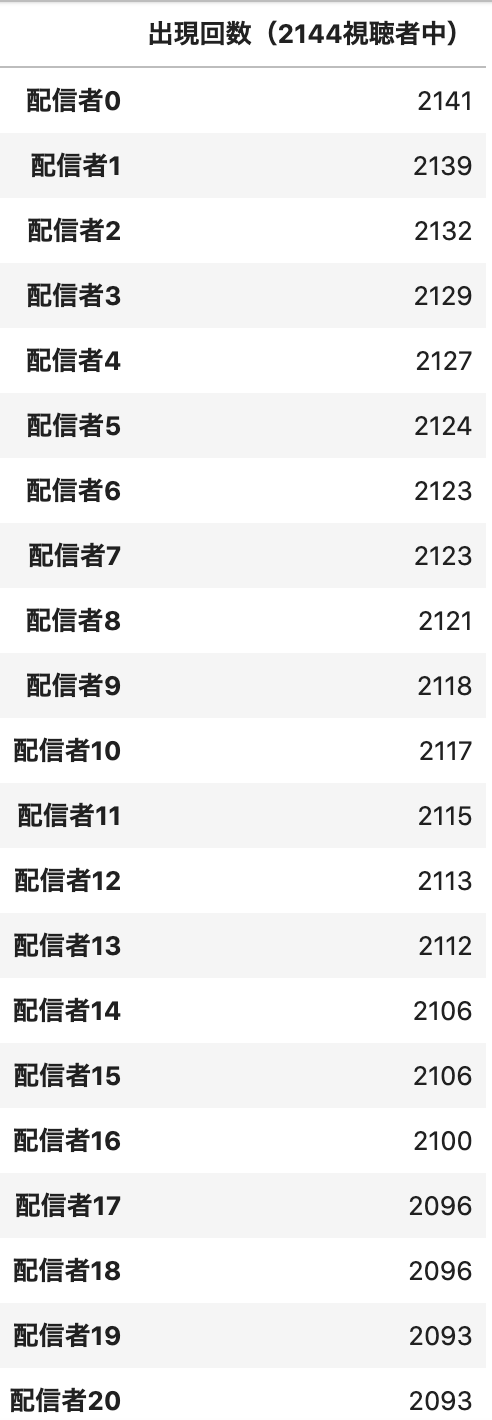
具体的な手法としては、上位から全視聴者の推薦配信者を見ていき、上限回数に達したら、以降の順位では除外するというものです。
下記の例を使って説明します。上限回数が2回と考えることにします。1位の推薦において、aaaはすでに2回出現しました。したがって、視聴者Cの2位でaaaを推薦することはできず除外され、3位のcccを繰り上げて推薦します。また、2位までの推薦でbbbが2回出現しました。したがって視聴者Aの3位でbbbを推薦することはできず除外され、4位が繰り上げられます。以上が手法の概要です。
| 視聴者 | 1位 | 2位 | 3位 |
|---|---|---|---|
| 視聴者A | aaa | ccc | bbb(除外) |
| 視聴者B | aaa | bbb | ddd |
| 視聴者C | bbb | aaa(除外) | ccc |
下記の表が結果です。検証データに対して、上限を500回に設定しました。精度を犠牲にせずに、ロングテール指標が改善しました。なお、なぜ精度がやや向上したのか詳しい事はわかりませんが、3つ目の手法とまとめて考察します。
| 手法 | nDCG | Cover Rate AUC | Positive Cover Rate AUC | ジニ係数 |
|---|---|---|---|---|
| ベースライン | 0.00346 | 0.224 | 0.00166 | 0.950 |
| 新モデル | 0.00415 (+0.00069) |
0.269 (+0.045) |
0.00236 (+0.00070) |
0.897 (-0.053) |
改善点としては、上限回数の決め方に影響を受ける手法であるため、最適な上限回数の探索や、順位に応じて上限回数を動的に変化させることが挙げられます。
取り組み2 (MMR)
Maximum Marginal Relevanceは検索結果の多様性向上のために用いられる手法で、より上位で表示されたページと類似のページの評価を下げるという手法です。3検索においては、上位ページを見た後は下位ページには異なる結果を望むだろうという考えから用いられており、閲覧者ごとに適用します。
しかし、ポコチャが目指すのは、各視聴者が様々な配信者と繋がることではなく、「サービスを使う一人ひとりのユーザーそれぞれの居場所をつくる」こと、すなわちプラットフォーム全体でのロングテール構造を目指せばよいので、全視聴者への推薦結果を考慮して適用します。
下記の表の例を用いて説明します。例においては、単純化して一致するものだけを類似とみなすとします。1位でaaaとbbbが推薦されました。すると視聴者Cの2位候補のaaaや視聴者Bの2位候補のbbb、視聴者Aの3位候補のbbbの予測値を下げます。以上が手法の概要です。実際は完全一致以外も考慮して、類似度指標を設計して、その値に応じて下げます。
| 視聴者 | 1位 | 2位 | 3位 |
|---|---|---|---|
| 視聴者A | aaa | ccc | bbb (↓) |
| 視聴者B | aaa | bbb (↓) | ddd |
| 視聴者C | bbb | aaa (↓) | ccc |
本手法は、類似度指標の設計が重要です。いくつかの類似度指標を設計しました。
まずJaccard係数です。各配信者には過去に視聴された視聴者がいます。その共通集合を和集合で割った値を類似度とします。Jaccard係数には課題があり、集合演算を含むため計算が重たいことと、ライブ配信アプリの性質上共通集合がほとんどゼロになることです。
そこで、配信者をベクトル化してコサイン類似度を計算することにしました。2種類のベクトル化手法を用いました。
一つ目はWord2Vec4 5を推薦システムに応用するItem2Vec6です。配信者を単語、視聴履歴をシーケンスと設定しました。パラメータは、論文を参考にWord2Vecのデフォルトから変更しました。7
二つ目はNode2Vecです。視聴履歴で有向グラフを作成し、視聴時間をエッジ重みとしました。
なお、本手法において、1分以下の視聴は、スワイプでの流し見とみなして、履歴から除外しました。
下記の表が結果です。精度を犠牲にせずに、ロングテール指標を改善できました。Jaccard係数については、計算量が非常に多くなってしまったため、今回は断念しました。
| 手法 | nDCG | Cover Rate AUC | Positive Cover Rate AUC | ジニ係数 |
|---|---|---|---|---|
| ベースライン | 0.00346 | 0.224 | 0.00166 | 0.950 |
| Word2Vec | 0.00355 (+0.00009) |
0.238 (+0.014) |
0.00173 (+0.00007) |
0.950 |
| Node2Vec | 0.00347 (+0.00001) |
0.215 (-0.009) |
0.00171 (+0.00005) |
0.950 |
いくつか改善点があります。最も重要なのが、今回は逐次的に類似度計算を行っており計算量が多いので、実用に向けて行列演算を駆使して高速化することです。他には、類似度ペナルティをかける強さの探索や、Node2Vecの代わりにGNNを用いて配信者埋め込みを行ってみるなどです。
取り組み3
学習データの分布特性を利用して重み付けなどをすることで、テール層についてうまく学習できるのではないかと考えました。手法としては大きく二つの方法があります。
一つ目は、配信者ごとにサンプル数を利用して重み付けします。log(サンプル数)+1の逆数に比例して重み付けします。
配信者の重み = 1 / ( log( サンプル数 ) + 1 )
二つ目は配信者ごとに負例比を調整します。こちらはさらに二つの手法を試しました。
一つは負例比をlog(元の負例比)+1にします。logを用いることで、配信者ごとの負例比の違いを、緩やかに均一化するようなイメージです。
配信者の負例比 = log( 元の負例比 ) + 1
もう一つはベースとなる負例比を具体的に設定したうえで、緩やかに近づけるというものです。具体的には、下記のような式を満たすように負例比を設定します。元の負例比 / ベース負例比にlogをかけることで、ベース負例比との違いを緩やかに縮めるイメージです。今回はベースの負例比を10としました。
負例比 / ベース負例比 = log( 元の負例比 / ベース負例比 ) + 1
下記の表が結果です。log(元の負例)+1の手法は、精度を保ったままロングテール指標が改善しました。他の手法はロングテール指標が改善しましたが、精度が悪化しました。
| 手法 | nDCG | Cover Rate AUC | Positive Cover Rate AUC | ジニ係数 |
|---|---|---|---|---|
| ベースライン | 0.00346 | 0.224 | 0.00166 | 0.950 |
| サンプル数重み付け | 0.00255 (-0.00091) |
0.252 (+0.028) |
0.00130 (-0.00036) |
0.941 (-0.009) |
| log(元の負例比)+1 | 0.00396 (+0.00050) |
0.396 (+0.172) |
0.000669 (-0.00991) |
0.896 (-0.054) |
| ベース負例比(=10) | 0.00141 (-0.00205) |
0.265 (+0.041) |
0.000480 (-0.00118) |
0.942 (-0.008) |
手法1や手法3のlog(元の負例比)+1で精度が向上している点について考察します。学習データには、配信者によって正例率が異なるというバイアスが、元々存在します。その影響で、推論時に一部の配信者が、より高いスコアを得やすくなります。このバイアスの影響が程よく除外された結果、視聴者との関連度がより正しく反映された推薦になった可能性があります。以上はあくまで推測であり、更なる検証が必要です。
改善点は、ニッチ派な視聴者の精度が下がるバイアス(メインストリームバイアス)に対処する重み付け手法が提唱されており8、それを試すことです。
提案手法の比較
最後に提案手法を比較します。さらに実験を重ねて、既存モデルに組み込めるか検証したいです。特に、パラメータ探索を行って各手法の精度を高めてから、異なる視点でのアプローチの手法間の比較を行いたいです。
| 手法 | nDCG | Cover Rate AUC | Positive Cover Rate AUC | ジニ係数 |
|---|---|---|---|---|
| ベースライン | 0.00346 | 0.224 | 0.00166 | 0.950 |
| 1. 最大出現回数 | 0.00415 (+0.00069) |
0.269 (+0.045) |
0.00236 (+0.00070) |
0.897 (-0.053) |
| 2. MMR | 0.00355 (+0.00009) |
0.238 (+0.014) |
0.00173 (+0.00007) |
0.950 |
| 3. 分布特性 | 0.00396 (+0.00050) |
0.396 (+0.172) |
0.000669 (-0.00991) |
0.896 (-0.054) |
まとめ
Pocochaではロングテール構造を大事にしています。今回の取り組みで、ロングテールの評価指標と推薦手法の提案を行いました。今後の実用化へ向けて、ドメイン知識がある事業部の方の視点で、目指すロングテール構造を実際に実現できているかを検証することも大切です。
本インターンでの学び
技術的な取り組みを記してきましたが、最後に、本インターンでの学びや、DeNAについて感じたことを書きます。
本インターンを通して、やりたいことベースで調べるリサーチ力がつきました。まさに同じ課題に取り組んでいる事例は、ほぼ見つけられなかったですが、類似の事例を探して応用することができ、成長につながりました。
ロングテールという課題は抽象的であり、技術領域に落とし込むのが難しかったです。しかし、事業部の方や推薦システムの開発に関わる技術者の方に面談をお願いして、快く引き受けてくださりました。メンターのあだちさんとサブメンターの藤川さんも、特に最初の方は何を話し合うのかも定まらない中、1on1を何度もしてくださりました。このように、インターン生に対してもフラットに接していただけて、心理的安全性が高い組織だと感じました。
DeNAはKaggleで実績を残している方が多い企業であり、個々の技術力が高い事は知っていましたが、組織としても魅力も感じることができた4週間でした。AIエンジニアを志望する学生であれば、参加して後悔することはないインターンだと思います。迷っていれば、是非応募してください!


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。