





はじめに
ソリューション事業本部プラットフォーム開発部で10月よりインターンをしていた石川です。 インターンの業務でGKEの新しい運用モードであるGKE AutopilotのAutoscaling性能について検証したので、本記事ではその紹介をします。
GKE Autopilotとは
GKEの運用モードはStandard、Autopilotの2つが用意されています。 Autopilotは2021年2月にリリースされたばかりの新しいGKEの運用モードです。
AutopilotがStandardと大きく異なる特徴として、Nodeの管理をサービス管理者が行うか、GCP側でマネージドで提供するかという点が挙げられます。
下記の図では、Standard、Autopilotのアーキテクチャを示しています。背景が水色の部分がGKE側でマネージドで提供する機能、黄色の部分が開発者が管理する機能なのですが、Standardと比べ、AutopilotではNodeの管理までマネージドで提供されていることがわかります。
GKE StandardとAutopilotの構成図(筆者作成)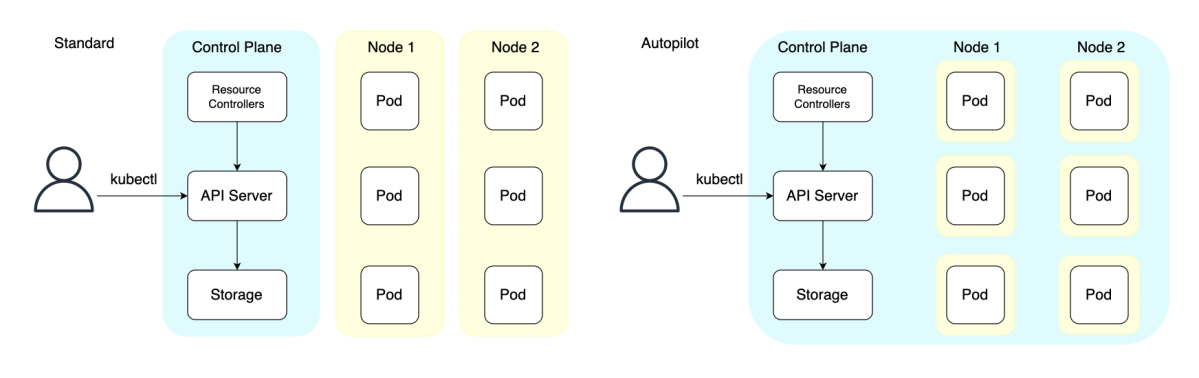
従来のStandardでの運用では、サービス開発者がNodeの管理を行う必要があり、運用を最適化するためにかなりの時間を割く必要がありました。 例えば、Nodeのマシンタイプの設定、Autoscale周り、バージョン管理などが挙げられます。
そこで、Autopilotで運用することでNodeの管理をする必要がなくなり、サービス開発者はワークロードに集中することが可能になります。
Pros/Cons
今回検証を行った上で、私が考えるAutopilotのプラス面、マイナス面を説明します。
Pros
Nodeを管理する必要がなくなり、ワークロードの運用に集中できる
これはAutopilotの一番の利点です。Nodeの管理には考えることも多く、ワークロードに集中できることは非常に大きなメリットになります。
NodeごとではなくPodごとの課金体系となるため、使用していないNodeに対しての課金を減らすことができる
Standardは起動しているNodeの台数分の課金体系ですが、AutopilotではPod単位のため、使用料のみの課金体系になっています。マネージドな分料金は割増になりますが、単に課金額だけを見るのではなく人的コストなども含めた総合的なコストを加味して検討するのがオススメです。
セキュリティ強度が向上される
Autopilotは、NodeへのSSHアクセスや設定の変更、privileged Podの使用が許可されていないため、セキュリティ強度が向上します。
Cons
kubernetesエコシステムと連携すると不具合が起きる場合がある
Autopilotでは、プロセスに一定の権限を与える
Linux capabilities
が
一部
を除いて制限されています。例えばサービスメッシュの機能を持つことで有名な
Istio
などは内部でプロキシを立ち上げるためにNET_ADMINが許可されている必要がありますが、Autopilotでは無効化されているので使用できません
(該当資料)
。ただ、Autopilotでサービスメッシュを扱うために、
AnthosServiceMesh
が最近サポートされるようになったのでこちらを使うことができます。
Standardでサポートされている機能が一部使えない
GPU, TPUの使用やAutopilot内での Admission Webhookの制限 など、Standardでよく使用される機能が制限されています。
パフォーマンス向上目的でのNodeのパラメーターチューニングは不可能である
Nodeの設定の変更は許可されていないため、sysctl等を使ってのパラメーターチューニングはできません。
まとめると、AutopilotはNodeの管理が不要になって、ワークロードの運用に集中できますが、開発されて間もないことから、サポートされていない機能がいくつかあります。また、Nodeへのアクセス制限から、自分たちで設定をチューニングすることは許可されません。利点は大きいですが、その分、制限されることも多いので、チームやサービスの状況から導入するかどうかを検討する必要があります。
GKEのAutoscalingについて
下記で行ったGKE Autopilotの性能実験では、NodeのAutoscalingにフォーカスしました。 ここで、GKE Standardの場合のAutoscalingの仕組みを紹介します。
GKEのAutoscalingを行う場合に、PodのスケールではHPA、 VPA、MPA、NodeのスケールではClusterAutoscaler、NodeAutoProvisioningなど、複数の種類があります。 今回はGKEがマネージドで提供するClusterAutoscaler、NodeAutoProvisioningのみの説明します。
ClusterAutoscaler
ClusterAutoscalerはGKEがマネージドで負荷に応じてNodeを水平スケーリングする機能です。
Cluster Autoscaler図(筆者作成)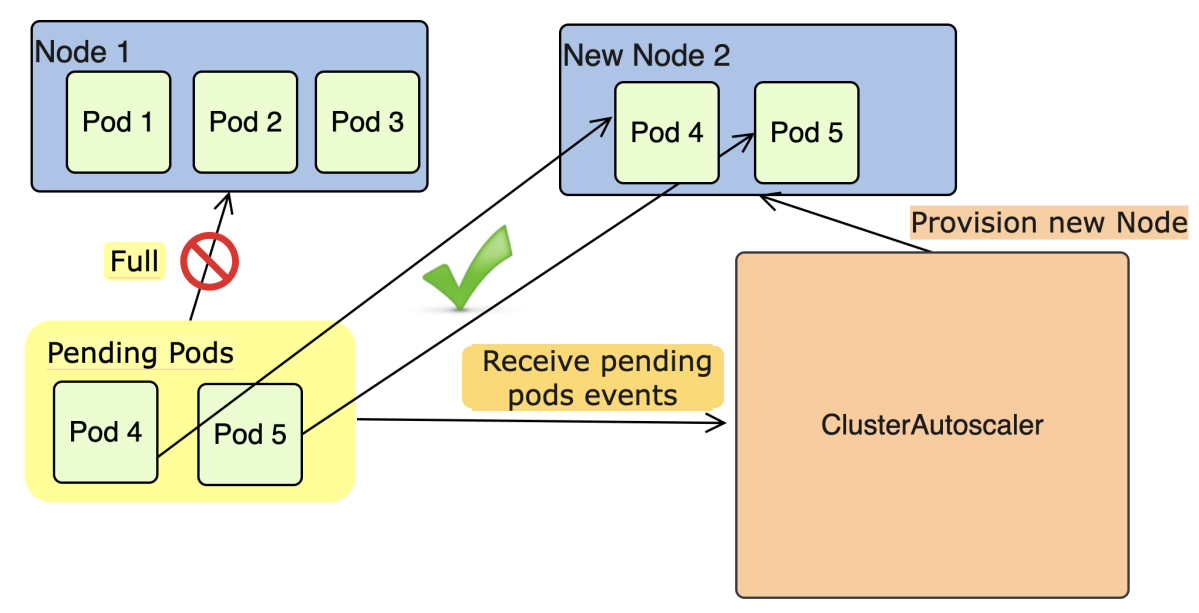
既存のNodeでは収まりきらない量のPodが要求される場合にClusterAutoscalerは自動的にNodeを追加します。
上の図では、リソースが満ちたNode1に割り当てることができないPod4、Pod5をClusterAutoscalerが検知して、新しいNodeを作成してPodの割り振りを行っています。これにより、サービスを落とすことなく、自動的にNodeのスケールアウトを行うことができます。
NodeAutoProvisioning
NodeAutoProvisoningはClusterAutoscalerの拡張機能であり、負荷に応じてNodeそのものの設定の最適化を自動で行います。
NodeAutoProvisioning図(筆者作成)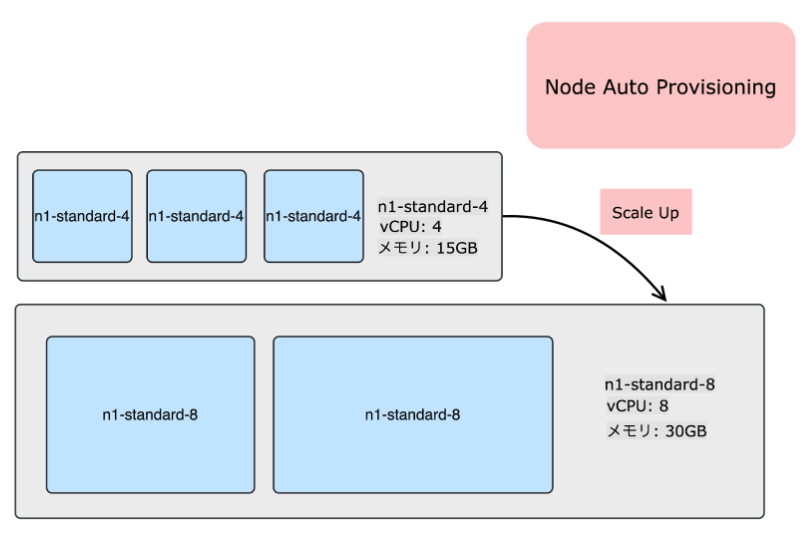
リソースのリクエスト状況を監視し、負荷に応じてNodePoolを新たに作成し、Nodeのリソースの最適化を行います。
例えば上の画像で、Podのリソースの要求が大きく、現状のNodeのインスタンスタイプでは最適化されてない場合、NodeAutoProvisioningはNodeに割り当てるCPUやメモリを大きくさせ、Nodeのスケールアップを行うことができます。
性能検証
それでは、実際に行った検証結果に移ります。
検証内容
検証内容として、StandardでClusterAutoscaler、NodeAutoProvisoningを有効にしたクラスタ、Autopilotクラスタをそれぞれ構築し、 Pod、Nodeのスケーリングの時間を比較を行いました。
目的
検証を行う目的ですが、GKEクラスタを実運用する際に、ClusterAutoscaler、NodeAutoProvisoning、Autopilotモードのスケーリング性能に問題がないかを確かめるということに設定しました。
比較対象(クラスタ構成)
- Standard、CA (ClusterAutoscaler) を有効化したクラスタ
- Standard、CA + NAP (NodeAutoProvisioning) を有効化したクラスタ
- AutoPilotクラスタ
比較項目
比較項目として、Podの台数を(1~30, 1~100, 1~200)までそれぞれ増やし、Podが全て用意されるまでの時間、Nodeが用意されるまでの時間をそれぞれのクラスタで計測を行いました。(また、Podはコマンドで一括で増やしました)
検証に使用した設定ファイル
今回の検証で使ったmanifestです。 コンテナイメージにはnginxを使用しました。
apiVersion: apps/v1
kind: Deployment
metadata:
name: experiment-scaling
spec:
selector:
matchLabels:
run: experiment-scaling
replicas: 1
template:
metadata:
labels:
run: experiment-scaling
spec:
containers:
- image: nginx:stable
name: experiment-scaling
ports:
- containerPort: 80
resources:
limits:
cpu: 100m
requests:
cpu: 100m
実験結果
以下が実験結果です。
Node台数の推移結果
Node台数の推移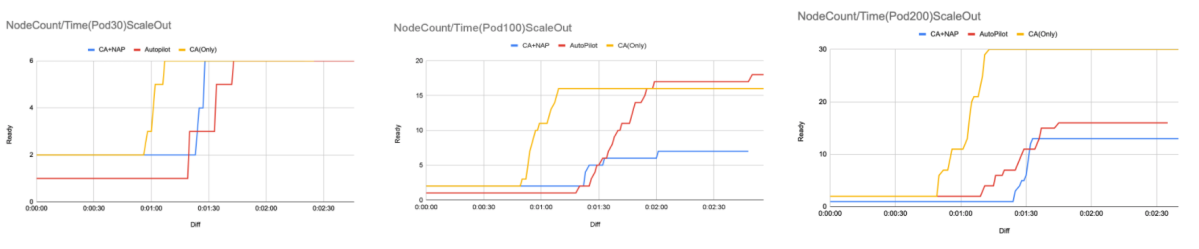
ClusterAutoscalerのみの場合、Nodeの起動はPod30台で1分ほど、200台で1分半で立ち上がり、非常に早く起動するという結果がわかります。 また、NodeAutoProvisioningを入れた場合、Autopilotの場合はClusterAutoscalerに比べて30秒ほど遅くなる結果が得られました。Pod台数が100の時のみ、グラフの波形が変わりましたが、他の二つはほぼ似通ったスケールをしていたこともわかりました。
各構成のマシンタイプ
| CA Only | CA + NAP | Autopilot | |
|---|---|---|---|
| 30Pod | e2-medium (2core) | e2-highcpu-2 (2core) | e2-standard-2(2core) |
| 100Pod | e2-medium (2core) | e2-highcpu-2 (2core), e2-highcpu-4(4core) | e2-standard-2(2core) |
| 200Pod | e2-medium (2core) | e2-highcpu-2 (2core) | e2-standard-2(2core) |
要求されるPod台数に応じてNodeAutoProvisioningを有効化した場合とAutopilotの場合では割り当てるマシンリソースが変更されました。このことから、適切なマシンリソースを算出してClusterに割り当てるために、NodeAutoProvisioningとAutopilotでは多少の時間がかかったことが予想されます。
Pod台数の推移結果
Pod台数の推移
Nodeの起動後にPodが起動するため、今回の検証ではClusterAutoscalerのみの場合が一番早くPodが用意されました。Nodeが全て起動されてからPodが起動するまでの時間の差はどの場合も15秒〜30秒ほどで、その中でもイメージのプルに5秒〜15秒、schedulerの配置などで残りの時間がかかっていました。今回はコンテナイメージにnginxを使用しましたが、もしもコンテナイメージがもっと大きいものであると、この時間はさらに大きくなると予想されます。
実験まとめ
以上の実験から、以下のことがわかりました。
- Podを200台構成した場合でも大体2分程度で用意されることがわかり、ClusterAutoscaler、NodeAutoProvisioning、Autopilotを使用したクラスタは一定のサービスの基盤として十分な速度でスケーリングが行われる
- ClusterAutoscalerのみの場合はNodeの起動時間が少し早くなる
- NodeAutoProvisioningを有効化した場合やAutopilotの場合、適切なリソースを算出する時間がかかるのではないか
- また、規模や負荷がこれより大きくなった場合にNodeの最適化がどの程度速度に影響を及ぼすかは今後検証していきたい
- NodeAutoProvisioningを有効化した場合、Autopilotで構築したクラスタと似た挙動をする
- Autopilotの場合もNodePoolの最適化を行うために、NodeAutoProvosioningと同様な機能を用いていると予想される
まとめ
本記事ではGKEのAutoScaling機能、性能実験の紹介を述べました。GKEではマネージドで強力なスケーリング機能が備わっているため、うまく活用してインフラにかかるコストを減らしていくことができます。
今回はPodがの台数が200台まで、コンテナイメージが小さいもの、一度に台数を上げるようなシナリオで性能実験を行いましたが、台数がもっと多い場合、コンテナイメージが大きい場合、徐々に台数を増やす場合など、様々なシナリオが考えられます。クラスタの構成を検討する際には必ず運用するサービスの特性を考える必要があります。
おわりに
今回のインターンではオフライン出社(WeWork渋谷)に何度かさせていただいたり、チーム内はもちろん、チーム外の若手の方々やシニアの方々ともランチを組んでいただいて、技術の話からキャリアの話までお話を伺うことができました。DeNAの社員は皆、バックグラウンドが様々で技術力が高く、非常に良い経験となりました。これからも技術を楽しみながら、残りの学生生活を過ごしていきたいと思います。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。