





はじめに
こんにちは、IT基盤部の天野です。AWSやGCPを用いたゲームインフラを担当しています。
DeNAが運用している大型ゲームでは、ステートレスなサーバにスポットインスタンスを使用しています。
スポットインスタンスはAWSに中断(=shutdown)されることがある代わりに、コストを大幅に抑えることができるインスタンスです。
AWSのイベントで見かける資料では、定常的な負荷はリザーブドインスタンスや Savings Plans を利用し、さらに負荷が増える部分で万が一落とされても問題ない範囲をスポットインスタンスで運用することが推奨されていたりします。
しかし、DeNA では web、memcached、worker等のサーバにおいて、ほとんどのリソースをスポットインスタンスで運用し、それでいてサービスは絶対に落ちない自信を持っています。
実際に DeNA でスポットインスタンスを本番環境に利用し始めてからもう1年以上経ちますが、まだスポットインスタンスが原因でサービス影響を出したことはありません。
今回はその自信の根拠となった理由や、スポットインスタンスの可用性について紹介していきます。
スポットインスタンスの中断条件
はじめにスポットインスタンスの中断条件についておさらいしておきましょう。
- スポット料金が入札価格を上回ったとき
- AWS側でインスタンスの需要が高まったとき
1.の入札価格を上回ったときですが、これが原因で中断されることは、ほぼありません。と言いますのも、2017年12月以降は価格変動が緩やかになり、それ以降はスポット価格がオンデマンド価格以上に上がることを見かけなくなりました。そのため、入札価格をオンデマンドインスタンスと同額(デフォルト値)で入札しているかぎりは、これが原因で中断される可能性は、過去の実績に照らして極めて低いです。
2.のインスタンス需要が高まったときは、DeNAの環境でも頻繁に中断されているのを検知しています。これは時間指定でスポットインスタンスを使うスポットブロックであっても、同様に中断されます。(ですので,確実に中断をブロックすることは期待できません) また、検証では入札価格を10倍にしていようが、オンデマンド価格と同じにしていようが、同じ頻度で中断されていますので、中断対象を決定するロジックに入札価格は関係ないようです。インスタンスの稼働時間も関係なく、完全にランダムに対象が決定されているように見えています。
インスタンスが中断されるときは、その2分前に CloudWatch イベント または、インスタンスメタデータでそのことを検知することができます。
インスタンスプールに注目
AWSによるとインスタンス需要はAZ毎、さらにインスタンスタイプ毎に別々に管理されており、その単位をプールと呼んでいます。同一インスタンスファミリーであってもインスタンスのサイズが異なれば別のプールになります。
例えば、ap-northeast-1a の c5.2xlarge と c5.4xlarge は別プールですので、インスタンス需要は別々に管理されています。
他のユーザが特定のインスタンスタイプを大量に使用してリソース不足になったとしても、AZ毎の残リソースには偏りがあるようで、スポットインスタンスが中断され始めるタイミングにはわずかに差が生じます。複数のプールを混ぜて使用すれば、そのわずかな差により、同時に中断されるリスクは減り、可用性は高まります。
以下の図は2019年1月2日のプール毎のスポットインスタンスの台数を示しています。自然に中断されるのに任せて何も操作はしていません。
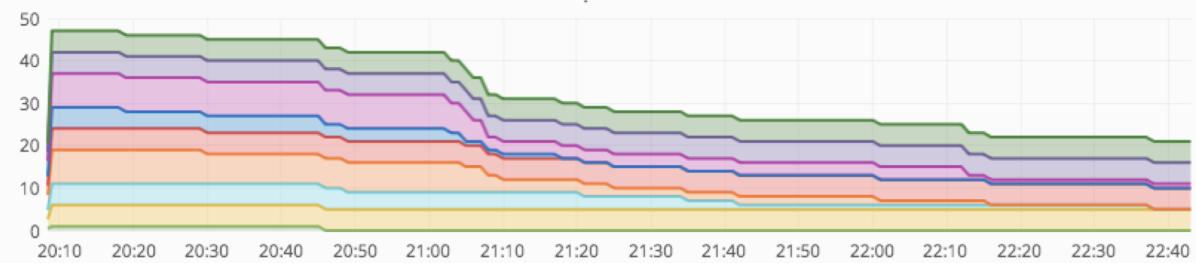
- 21:10 青色で示したインスタンスはほぼ中断される
- 21:40 水色で示したインスタンスがほぼ中断される
- 22:10 赤紫色で示したインスタンスが中断される
という具合に、わずかに時間をずらしつつインスタンスが減っているのがわかると思います。
スポットインスタンスのみで安定したサービスを提供するには
このように中断されるスポットインタンスですが、これを用いて安定したサービスを提供する方法を紹介していきます。
ここでは、スポットインスタンスのみを用いてサービスを提供した場合の故障率について計算してみます。
サーバの運用では、突発的な負荷の増加やインスタンスの故障に備えてある程度のリソースを残しておくのが普通です。目標となるCPU使用率を設定して、その使用率以下になるようにインタスタンス台数を設定したり、Auto Scaling で台数を増減させたりするのではないでしょうか。
仮に目標のCPU使用率を50%に設定したとしましょう。その場合、たとえ中断されたとしても、そのリソースが半分以下にならなければ、サービスに影響が発生しないことになります。 (計算を簡単にするために、突発的な負荷の増加や故障が、スポットの中断と同時に発生するという不幸はここでは考えないようにします)
あるスポットインスタンスが中断されても、新しいインスタンスは数分あれば起動してきますので、その起動してくるまでの間の数分間にインスタンス台数が半数を割り込むことが無ければ、サービスは安定して提供できることになります。
実測値を元に故障率を計算
ここからは、プール数と故障率の関係について、実測値を元に統計的な計算を試みようと思います。
まずは、DeNAで使用しているリージョンで、スポットインスタンスが比較的多めに中断された期間を紹介しましょう。
ここで紹介している数値は使用されるインスタンスタイプや時期、リージョン毎に異なると思われるので、この数値をそのまま信用せずに各自でデータを取得するのがよいでしょう。
| 時期 | 枯渇したプール | 関連しそうなイベント |
|---|---|---|
| 2018/11/20 21:00 〜2018/11/21 8:00 |
・c5.2xlarge 全AZ | ・感謝祭の直前 |
| 2018/11/23 22:00 〜2018/11/24 4:00 |
・c5.2xlarge 半数のAZ ・c5.4xlarge 半数のAZ |
・ブラックフライデー |
| 2018/11/26 20:00 〜2018/11/30 8:00 |
・c5.2xlarge 全AZ ・c5.4xlarge 半数のAZ |
|
| 2018/12/26 23:00 〜2018/12/27 5:00 |
・c5.4x 全AZ ・m5.4xlarge 半数のAZ ・c5.2x 半数のAZ |
・クリスマスセール |
| 2019/01/02 21:00 〜2019/01/05 5:00 |
・c5.4xlarge 全AZ ・m5.4xlarge 全AZ ・c5.2xlarge 全AZ |
・ニューイヤーセール |
ここから統計的な数値を出すために、モデル化を試みます。
これらの期間を1時間毎に区切り、その中でインスタンスがすべて中断されたプール数を数えていきました。そして枯渇したプール数を、使用していたプール数で割ることで、1プールあたりの枯渇確率を求めます。(ここではモデル化のために1時間以内に発生した枯渇を同時と捉えていますが、実際はもう少し余裕があります)
その結果、最大 15% の確率でプール枯渇が発生しうるという結果になりました。
同じインスタンスサイズであれば同時に枯渇しやすいという傾向はありましたが、概ね独立していました。
この数値を前提に、プール数別の故障率を計算していきましょう。
例えば目標CPU使用率が50%の場合、8プール中4プールまでは同時に枯渇しても問題なし、5プール以上が同時に枯渇したら故障(=サービス影響発生)として、捉えることができます。
独立した複数の事象が同時に発生する確率は二項分布で計算可能です。今回の場合は15%の確率で発生する事象が8個中5個以上、同時に発生する確率を求めればよいことになります。
8個中5個のプール枯渇は二項分布の累積確率で求めることができ、
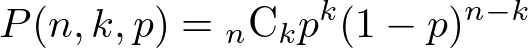
P(n=8, k=5, p=0.15) ≒ 0.00261157 となります。
EXCEL の関数では、 =BINOMDIST(5,8,0.15,0) で求めることができますので、お手元で実施される場合はこれを利用するとよいでしょう。
これを8個中6個の場合、8個中7個の場合、8個中8個の場合を足し合わせたものが、今回求めたい確率です。
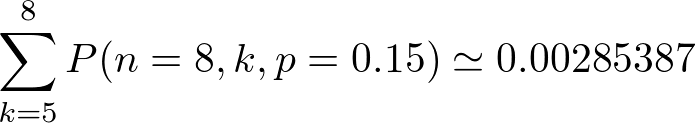
DeNAで1年間スポットを運用して、ここで数えたような複数プール枯渇が発生した回数は年間30回程度でした。
その場合の年間を通しての故障率は
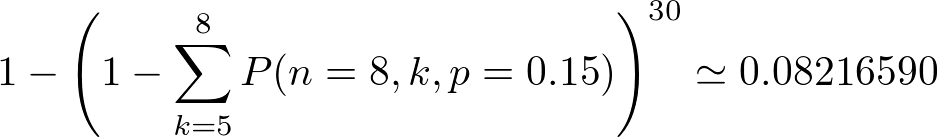
となり、1年あたりの故障率は8.2%、平均故障間隔(MTBF)はこの逆数で13年 となります。
こちらもお手元で計算される場合は、EXCEL で =1-(1-0.00285387)^30 という形で計算可能です。
目標CPU使用率50%における、プール数別の平均故障間隔(MTBF)を計算しましたので、以下に示します。
| プール数 | 年間故障率 | 平均故障間隔(MTBF) |
|---|---|---|
| 4 | 30% | 3.3年 |
| 8 | 8.2% | 13年 |
| 12 | 1.9% | 50年 |
| 16 | 0.48% | 210年 |
| 20 | 0.12% | 860年 |
DeNAではサービス影響に直接結びつく Webサーバはプール数を 20 に、たとえ落ちてもDBサーバへの負荷が高まるがなんとか耐えられる memcached は 10 といったように、インスタンス台数や重要度も天秤にかけながら個別に調整しています。
さらに、これらの数値を実測値に基づき定期的に見直し、どの程度の比率までスポットインスタンスを用いても問題ないかをチェックしながら運用しています。ちなみにリソース枯渇は2019年後半から比較的少なくなってきました。
復旧時間も含めて計算すれば可用性の数値も出せますが、オートスケールを使用している場合は即座にインスタンスが足されて10分程度でサービスが復旧しますので、可用性としての数値は非常に高くなってしまいあまり意味をなさないので、ここでは割愛します。
プール数を増やすために
DeNA ではプール数を増やすための工夫として、大きさの異なるインスタンスタイプを混ぜて使用しています。
具体的には、C5.2xlarge、c5.4xlarge、c5.9xlargeのインスタンスに、それぞれIPアドレスを1つ、2つ、4つ付与し、そのIPアドレス宛に負荷分散することで、プール数を増やしつつもインスタンスに均等に負荷を与えるような仕組みを作って運用しています。
このような仕組みを整えれば、旧世代のインスタンスを混ぜなくとも、プール数20は比較的容易に達成できます。
残念ながらスポットフリートや Auto Scaling グループだけではその実現は難しいので、多少の独自実装が入ってしまいますが、それこそがエンジニアの腕の見せ所でしょう。
最後に
本日はスポットインスタンスを用いてサービス提供した際の平均故障間隔についてご紹介しました。
エンジニアは新しい仕組みを導入するときに、その影響を関係各所に説明し、同意を得た上で推進することがあると思います。
この記事がそういったことの一助になれば幸いです。
2020/3/4 に開催する DeNA TechCon において、 クラウドコスト削減の実践 をテーマに登壇させていただく予定です。 ここでは書ききれなかったコスト削減の手法について紹介しますので、こちらも是非見にきてください。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。