


In this article we will explain how we handle the generation of annotated data for computer vision related machine learning at DeNA. We will focus mainly in how we solved our problem by creating our own annotation system, Nota, and how it integrates into the ML workflow. We will describe our current system and some of the decisions we made, as well as the challenges we had to solve to get to the current solution.
My name is Jonatan Alama, I am a member of the Analytics Solution Engineering and the Machine Learning Engineering groups at DeNA. My team and I design, develop and operate web applications and other solutions for data related problems.
The problem obtaining accurate data
In the recent years there have been a lot of advancements in AI systems, and many of them are related to the computer vision field. We can train computers to interpret and try to understand what they see. For the training phase, we use what we call “Annotated images and videos”. Image annotation and image classification is a process done by humans in order to obtain a set of data that a computer can learn from using machine learning processes. It consists of marking objects inside an image, normally using basic shapes, and then categorizing the marked object. For basic tasks, there is data available for everyone to use for free, but when the problem to solve becomes more specialized, we need to create our own annotated data.
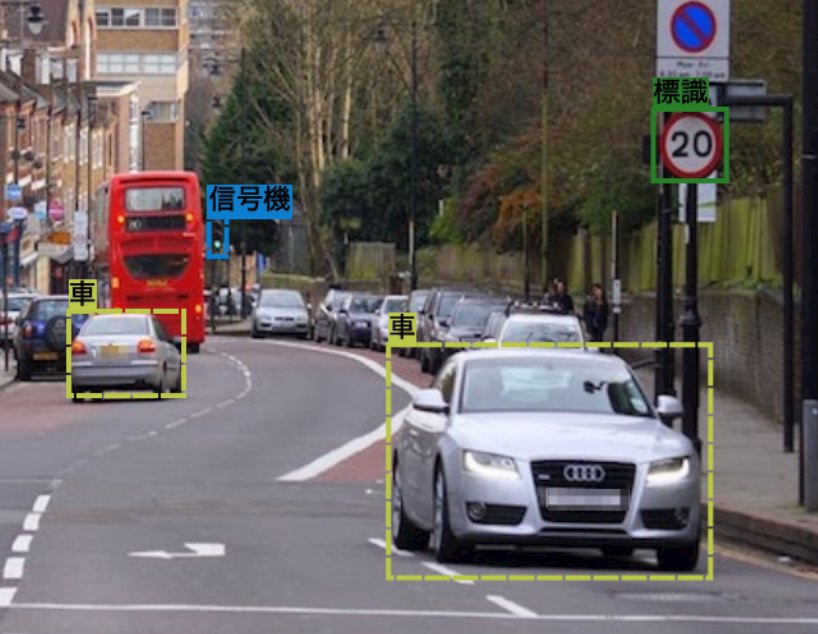
Shortly after joining DeNA in 2017, a new computer vision project needed to create its own annotation data in order to tackle some of the challenges it was facing. Outsourcing the annotation task to a third party might seem appealing if we consider only the cost, but this often results in less than optimal data accuracy and control over the process. Also, some of the images and videos we wanted to use could not be easily shared with a third party due to privacy concerns.
As a result, and because of the lack of an open standard, we decided to solve it in-house, and this is how the first prototype version of Nota was born.
Our computer vision machine learning flow
Being able to create a system from scratch also allowed us to design it in a way that integrates best with our machine learning processes. We also wanted to make it simple for the AI engineers and data scientists to provide the source data and to use the annotated results.
Even tough at some point we tried to integrate more deeply with some projects ML workflow by using web hooks and calls to AWS SQS or GCP Pub/Sub, in the end we decided to keep Nota deliberatively agnostic about what happens before and after the annotation process. The projects come and go, and the tooling is constantly changing, so it made more sense to focus in doing one task very well (data annotation) and let each project handle how they want to provide images and videos and how they want to consume the annotated data.
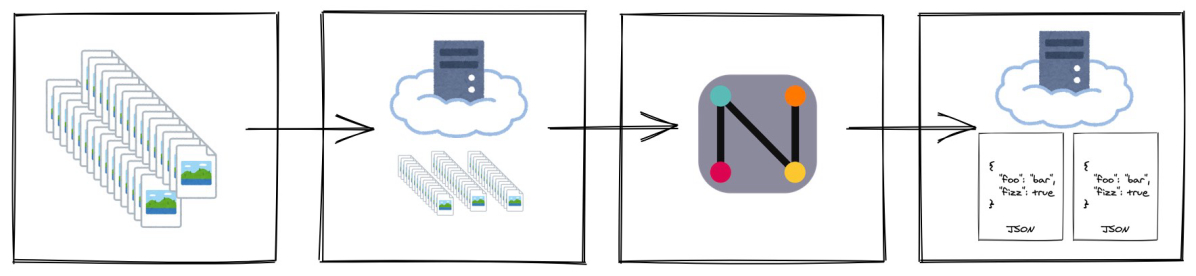
Most of the ML projects used cloud services such as AWS or GCP for data storage and computing, so it felt natural to use AWS S3 and GCS as the sources for the image and video files, as well as the destination for the annotated data results. It was designed in an extendable way so we can add other sources as needed.
The current process is normally as follows:
- The source images or videos are uploaded to an S3 bucket
- Nota scans the source searching for image or video files and stores a reference to all the files found
- The Annotation manager creates the tasks, and assigns annotators to them
- The annotators do the annotation
- After the annotation process has finished, the results are exported as JSON files back to the S3 bucket
- The JSON files are parsed and consumed in order to train models using cloud instances
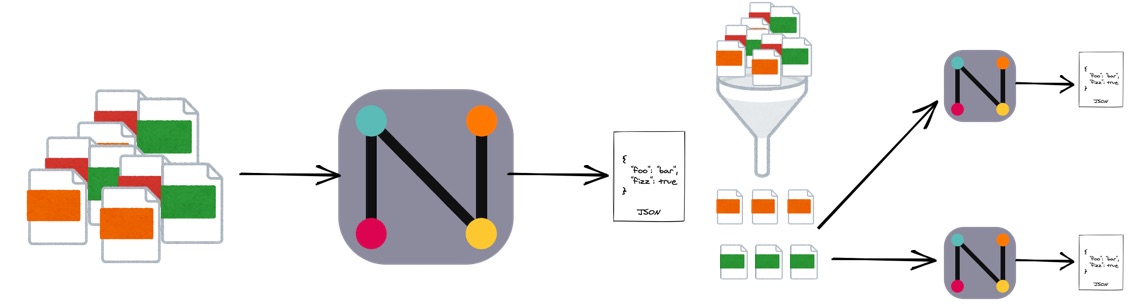
When a task was simple, setup was very simple. At the same time, we were able to create more complex workflows with multiple annotation steps by adding some extra steps in the middle. For example, the output of some annotation task might be used to filter the images that should be used in another annotation task.
Extendable, configurable
The first prototype was created to solve a specific problem, but we were almost sure that there would be more annotation requests in the future. It was clear from the start that if we could design a somehow configurable and extendable system, it could be reused to help other projects.
We designed a templating system written in JSON where the users can define the type of annotations required for each task. We started small, implementing only what was required, but the templating system and extendibility were there from the start. That way, when we got a requirement for a new type of annotation that was not supported, we added the UI plugin for it and made it available in the template system. This way little by little the number of supported annotation types increased.
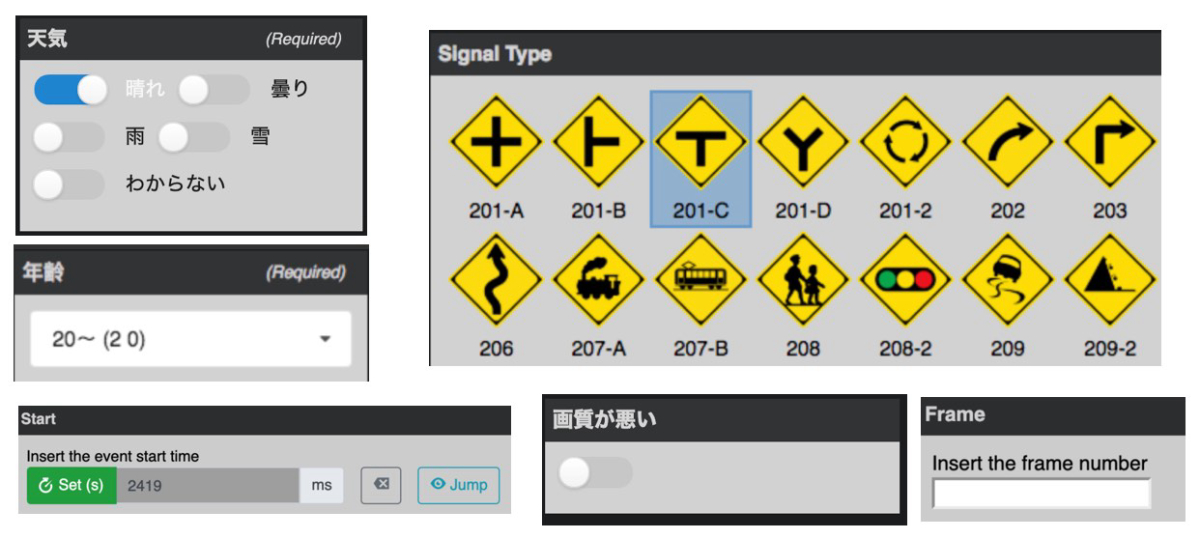
Nota’s main annotation UI is divided into three parts:
- Task items Area
- Annotation Area
- Classification Area
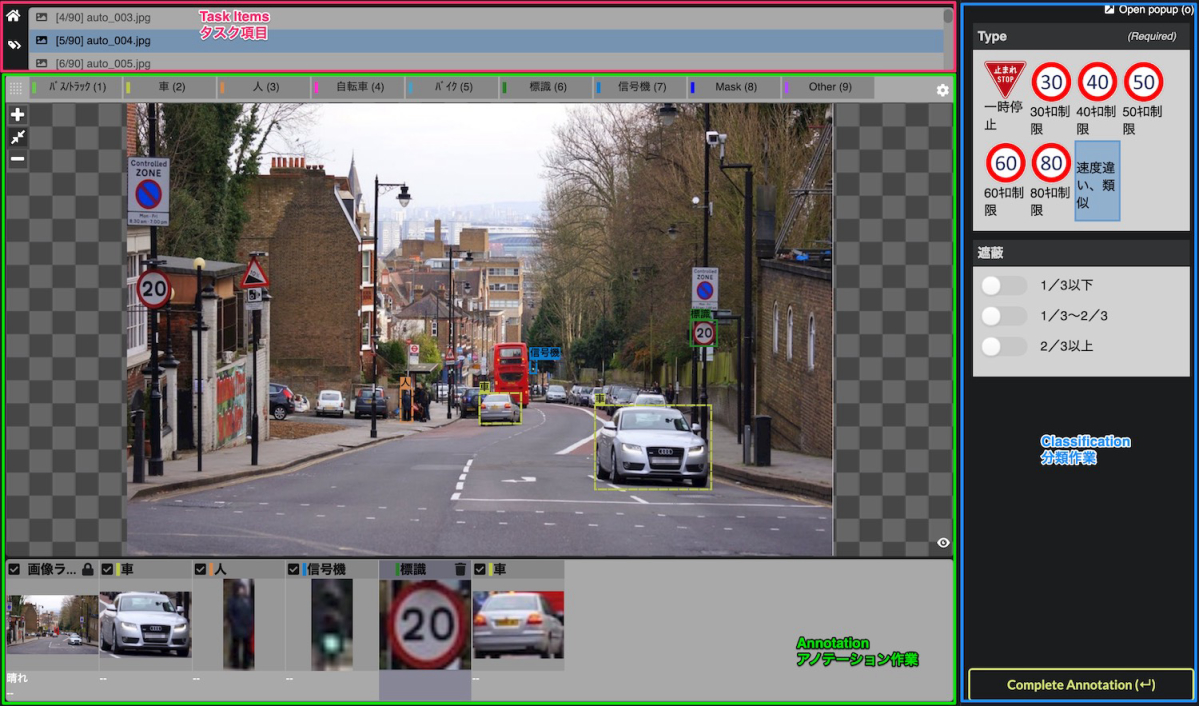
The Task Items Area is just a list of the assigned items by filename.
The Annotation Area is normally the area where most of the work is done. In the case of image annotation, currently it allows to create bounding box, polygonal segmentation and key point annotations. In the case of a video, the video is displayed here.

Once an annotation is created, the Classification Area allows to tag and classify using Boolean/single/multiple selectors, text labelling and other formats that we found useful. For video we also made event annotation possible by being able to read the current time of the video being played.
It is a work tool first
It was important to make Nota simple to use and integrate as automatically as possible with the ML projects. But the annotation process itself is done by humans. Nota becomes the main work tool for many annotators and their managers, and they spend most of their work time using it.
Image annotation is a repetitive task. We worked together with the annotation managers and the annotators, getting feedback and being able to iterate fast and fine tune the user experience. In many cases, we were able to improve the quantity and accuracy of the annotations with small UX improvements.

In other cases, this direct communication helped reduce small sources of stress that can led to burnout and lack of motivation for the users. For example, as the image resolution and size began to become bigger in some tasks, there was some delay when waiting for the next image to be ready. We were able to increase the overall annotation speed by adding a simple system that would eager load and prepare the next images in line.
Also, we early found out that not all users work the same way. For example, given the same results, one user might feel more comfortable using keyboard shortcuts while other might prefer to use a mouse most of the time. Having some custom settings for each user has proved to be good in some tasks.
Annotation management also became more and more important as the number of projects and annotators grew. We already had a quite good annotation system, but from a management point of view, it was becoming difficult to handle and have a clear overview of the status. We had different servers and URLs for each project, and many annotators had to work in different projects at the same time. All the task and assignment management were done in spreadsheets.
We decided it was worth it to focus in improving the management experience and we released Nota v2 in September of 2019. We moved from simple user/password login to use the company SSO, and added a unified project and user management view. Now managers could control the overall state and create, manage and assign projects and tasks to annotators from one place. And annotators could now focus on their tasks all from one place. This also allowed us to close redundant servers, reducing the server cost itself, and more importantly, the maintenance cost.
Designed for handling sensitive data securely
Nota server
One of the first design decisions made was that we did not want to store any image or video data in Nota itself, even temporarily. This was mainly for security and privacy reasons. Nota would save only a reference to the real file location, normally in S3, and then transparently stream it from the source to the client. Nota server side is written in Node.js, and this worked very well for us because of the native data streaming libraries and the asynchronous nature of JavaScript. Using Node.js Express framework and the AWS and GCP SDKs it was possible to create a stream and pass it directly to an API response, without requiring temporary files.
As we mentioned earlier, Nota only stores the reference to an image or video and the annotation data itself. This data contains the annotated objects coordinates inside the image and other classification labels and tags. Even if the image itself contains personal or sensitive information, the annotation data does not. Sometimes when annotating sensitive images, the images have to be deleted after the task is finished. Because we do not store any personal or sensitive information in Nota itself, we don’t have to perform any cleaning operations reducing the operation cost and security leaks. The images or videos can be deleted from the S3 bucket after the task is finished, and that’s it.
We still need to have access to the files so we can index them and then deliver them to the client. Even if the Nota servers do not store the images and videos, we still need to secure the access. Nota is currently running inside containers in AWS. Since most of the data sources are also located in S3, it is also easier for us to handle the permissions required to access S3 by using the AWS IAM system. Each project gives Nota the minimum possible permissions for accessing the files in their S3 buckets. The buckets are also secured and encrypted. We also provide terraform templates for creating and managing S3 buckets that are ready to use with Nota.
The Nota data structure itself is not complicated, so any database would have done the job. We opted for MySQL for simplicity and previous development experience. We also use redis for some caching and batch tasks queue management. Batch workers are used for slow tasks like indexing new images or videos from cloud storage sources and for exporting the annotation results.
Nota client
The Nota client is a single page web application written using React. We opted for a web application instead of a native application because web applications are easier to distribute, update and to integrate with our current systems, that are mostly cloud services. But the browser becomes the client, and this has some security risks. It is impossible to completely secure the images and videos when downloaded to the browser. We opted for disabling the browser integrated functionality for downloading images and videos. It is still possible to download the images using the browser developer tools, or to take screenshots, but it now requires an intentional behavior from the user to do so, and cannot be easily done by mistake. This measures together with the server access logs gives us the protection we need.
While being a web application, as we saw before, it is also the main work tool for annotators. We really wanted to make it as responsive as possible. As a result, most of the actions are designed as offline-first, saving to the server in the background without delays or interrupting the work.
Some takeaways
Even though Nota is now at a point where there are not many new feature requests, it has been really fun to build and we are looking forward seeing what’s next. Finally, some takeaways from building our annotation system, mostly from a web application developer point of view.
In order to build an application that is easier to maintain and extend, it is important to try to guess what the next requirements might be
The first request that made us build Nota was for a concrete case, but it was easy to see that we could also solve possible future problems by making it a bit more generic and we opted for investing a bit more of time designing the first version.
Of course, we also failed sometimes by putting too much effort into features that we thought would be important, but that ended up not being used much. But it is important to have a vision and to plan early accordingly, trying to keep a good balance between current requirements and future possible requirements.
Ask early, get feedback early
This is true even more when the application becomes a work tool for the users. We focused on user experience and usability from the start. We had the luxury of having the users close to us and we were able to prototype and get important feedback early on. Nota was going to be the only screen they would be looking at for hours, so we wanted them to be comfortable using it. And finally, never forget that…
…users are always better at it than developers
Users will use the application for hours, many more hours and in many more ways that you could ever have thought of. Users will get much better at it than you. Nota being a very interactive application, this has bitten us sometimes. Even if we tried to design and test for heavy use and abuse, users will perform actions faster than you could think of, and use [and break] the application in ways you could have never thought of.

最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。