





はじめに
こんにちは。 IT 本部 IT 基盤部 第三グループの岡崎です。 IT 基盤部では、組織横断的にさまざまなサービス・プロダクトのインフラ運用を行っており、サービスの安定的な稼働や、運用の改善などに取り組んでいます。
本記事では、我々が利用検証を進めているオブザーバビリティツールの1つである Dynatrace において、取り込まれるログ内の個人情報をマスキングする方法についてご紹介します。 Dynatrace においてログをマスキングする方法としていくつかのアプローチが提供されていますが、それぞれのアプローチの特徴を把握し、自身の要件に合わせた選択ができるようになることを目的としています。
Dynatrace とは?
まずはじめに、今回取り扱う「Dynatrace」というサービスについて簡単にご紹介します。
Dynatrace は、AIOps とアプリケーションセキュリティを統合し、エンドツーエンドでのオブザーバビリティ(可観測性)を確保するためのプラットフォームです。 サービス内にエージェント(OneAgent)を導入するだけで、インフラレイヤーからアプリケーションレイヤーまで大量のデータを、データのコンテキストを保持した状態で収集できます。 収集したデータを元に、システムの状態の可視化や AI による自動的な分析、システムになにか問題が発生したときに問題を把握しその根本原因を自動的に分析することなどが可能です。
個人情報保護の重要性
上記で説明した通り、Dynatrace はシステムが生成する大量のデータを収集し、自動的に分析することで、新たなインサイトの取得や作業の自動化を行います。 しかしシステムが生成するデータには、ユーザーの氏名やメールアドレスといった個人情報が意図せず含まれてしまう可能性があります。 個人情報が含まれるデータを外部に送信することは、情報漏洩のリスクに繋がるほか、各国の法規制やコンプライアンス要件に違反する可能性があります。 情報漏洩や法規制への違反は企業の信用失墜や多額の罰金につながることもあり、その影響は甚大です。
また、これらの個人情報はそもそもデータとして出力されないようにすることが個人情報保護の観点からはもっとも理想的であるといえますが、すでにログに吐き出されてしまっているケースや、多層防御の観点でデータ送信時に個人情報を含んでいないか改めてチェックしたいというケースが考えられます。
このような場合、各システムから Dynatrace にデータを送信し、それが Dynatrace に取り込まれるまでの間に何らかの方法で個人情報が含まれないようにする必要があります。 今回は Dynatrace が収集する多くのデータのうち、ログにおける個人情報のマスキングの手法について説明します。
Dynatrace におけるログマスキングの主要アプローチ
Dynatrace は、ログデータ内の個人情報をマスクするための機能としていくつかのアプローチを提供しています。 これらのアプローチは、情報をマスクするタイミングに応じて大きく2つに分類されます。
ここからは、それぞれのアプローチについて具体的な内容と、その特徴を説明します。
エージェントによるマスキング
仕組み
各システムが出力したログは、リソース内に配置されたエージェント(OneAgent)によって収集され、Dynatrace に送信されます。 この OneAgent において、ログ送信前にマスキング処理を実施します。
マスキング対象文字列として識別する正規表現と、置き換え後の文字列をセットでルールとして定義し、OneAgent が捕捉したログデータに対して処理を行います。
詳細な情報については公式ドキュメントも参考にしてください。1
設定例
Dynatrace 上の設定から、Log Monitoring > Sensitive data masking にアクセスすると、ルールの管理が可能です。
デフォルトでいくつかのビルトインルールが用意されており、個別のルールを追加することも可能です。
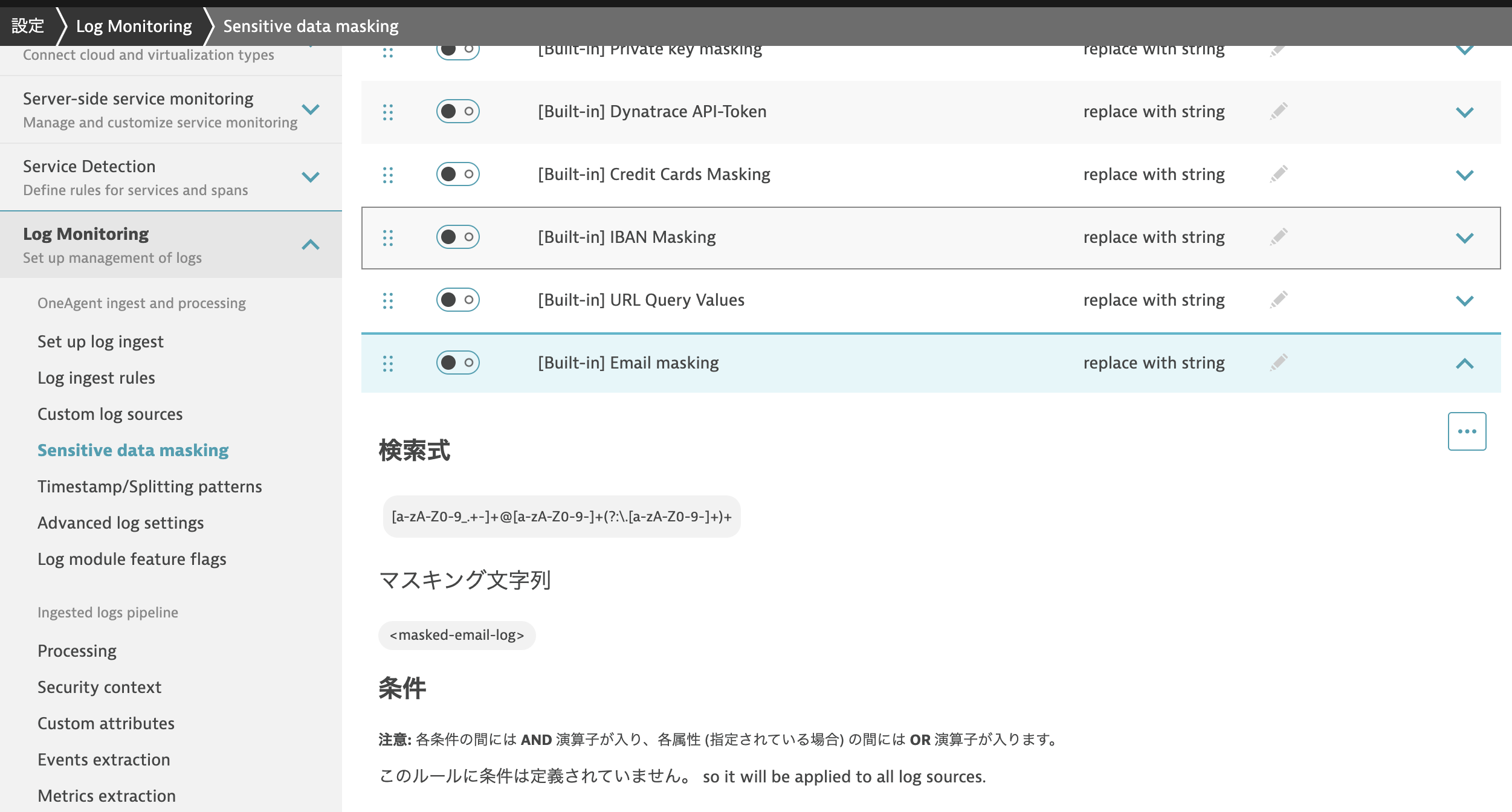
上記はビルトインルールの1つである、メールアドレスのマスキングルールです。
[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+(?:\.[a-zA-Z0-9-]+)+ という正規表現にマッチする文字列を、<masked-email-log> という文字列に置き換えるルールとなります。
このように固定の文字列に置き換えることも可能ですが、SHA256 を用いたハッシュ化も可能です。
また、上記ルールには設定されていませんがルールの適用条件を設定することもできます。
ホスト名、コンテナ名、タグ、ログのソースなどのパラメータと一致するものだけにルールを適用できます。
メリットとデメリット
マスキングの処理が各リソース内にインストールした OneAgent 内で完結するため、個人情報がリソースの外に露出することがありません。 これにより、より安全性を高めることができます。
一方で、このアプローチによって実現可能であるのは、あくまで正規表現によって捕捉した文字列を別の文字列に置き換えるということのみです。 よって「ログの中にメールアドレスが含まれている場合にマスキングする」といったようなケースには対応できますが、「ログの中にある特定の文字列を含む場合、そのログ行全体を取得しない」といったようなルールは設定できません。 また、一般的な正規表現と比較してサポートされていない構文も存在するため、複雑なマスキングロジックは実現できない可能性があります。2
ログ処理パイプラインによるマスキング
仕組み
OneAgent によって収集されたログは Dynatrace に送信され、Dynatrace 内部に保存される前に OpenPipeline 3 というパイプラインを通過します。 OpenPipeline は Dynatrace 上でさまざまなソースからのデータを取り込み、処理するための機能です。 処理するデータの1つとしてログも対象とすることができ、単純なログのマスキングに限らず、さまざまな処理が可能な強力な機能です。
パイプライン内には複数のステージが存在し、各ステージで所定の処理を行うことが可能です。 一連のステージ内の処理を通して、Dynatrace がどのようにデータを構造化、分離、保存するかを定義します。 パイプラインで処理されたデータは最終的にストレージに送信され、保存されます。 以下に各ステージで実現可能な処理の例を示します。
- Processing
- ログのフィールドの追加・削除・変更
- ログスキーマの変換
- ログ行の削除
- Metric extraction
- ログ行を解釈し、メトリックとして抽出
- Data extraction
- ログ行を抽出し、別のデータ型として別のパイプラインに再取り込みする
ログのマスキング・フィルタリングという今回の用途では、Processing ステージの処理を変更します。
また OpenPipeline では
DQL(Dynatrace Query Language)
と呼ばれるクエリ言語が利用可能です。
DQL にはさまざまな関数が用意されており、正規表現のみと比較して柔軟性・表現力が格段に向上します。
さらに DQL からは
DPL(Dynatrace Pattern Language)
と呼ばれるパターン言語が利用可能です。
DPL はデフォルトでさまざまなマッチャーが用意されており、IPADDR と書くだけで IP アドレスをマッチさせることができるほか、正規表現のように任意の文字列をマッチさせることも可能です。
これら DQL, DPL を組み合わせることで、複雑なマスキングロジックも実現可能です。
詳細な情報については公式ドキュメントも参考にしてください。4
設定の流れ
Dynatrace の Settings アプリ(Classic ではないアプリ)から Process and contextualize > OpenPipeline > Logs にアクセスし、Pipelines のタブからカスタムパイプラインの作成が可能です。
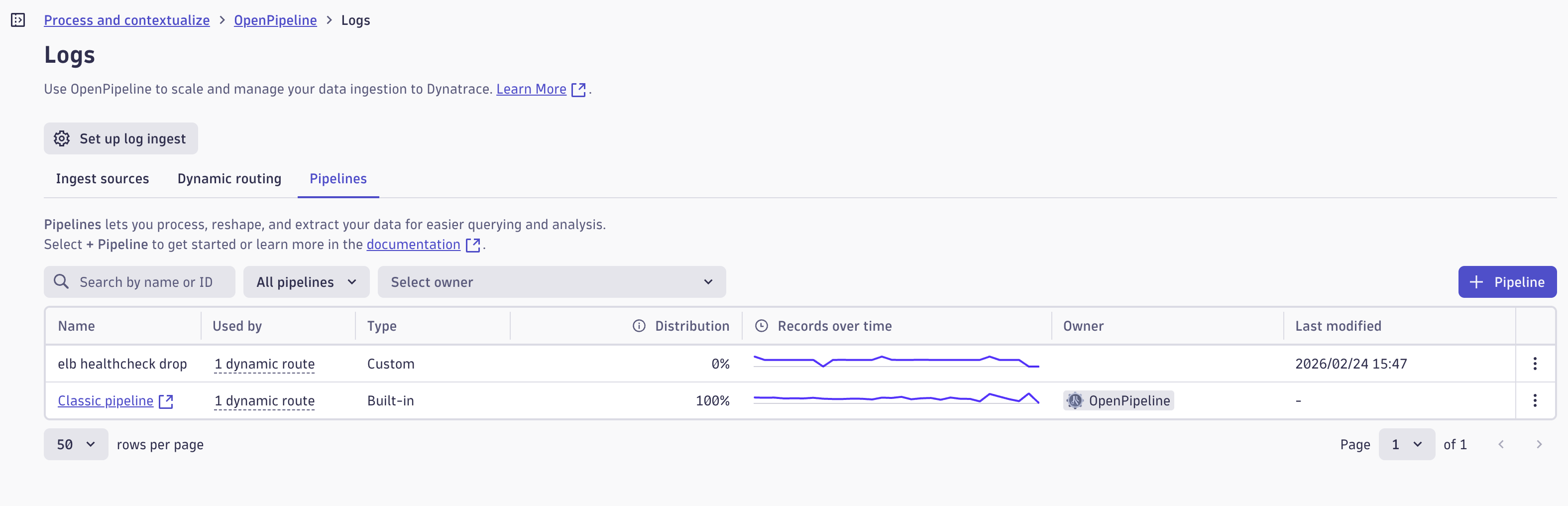
今回は Processing ステージの処理を変更します。
具体的な処理の設定例については後述します。
カスタムパイプラインを作成したあとは、パイプラインへのルーティング設定を行います。
取り込まれたログはいずれかのパイプラインによって処理されますが、特定のログをどのパイプラインによって処理するかルーティング設定が必要です。
Settings アプリの Process and contextualize > OpenPipeline > Logs 内の Dynamic routing のタブからルーティング設定が可能です。
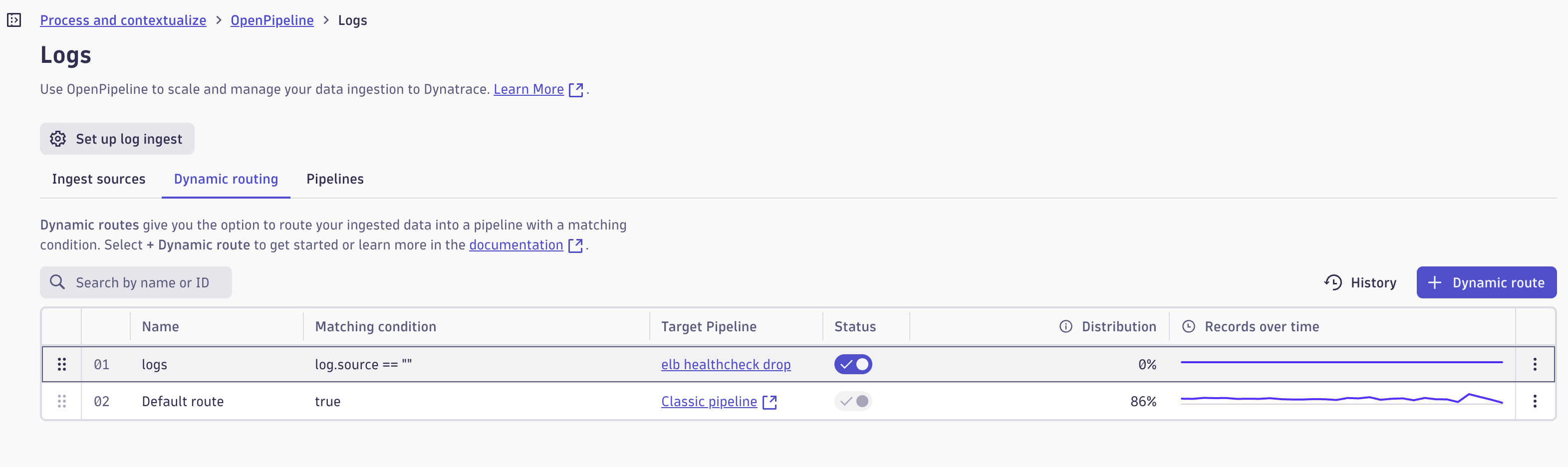
Matching condition にルーティング対象のログの条件を設定し、Pipeline において転送先のパイプラインを指定可能です。
設定例
Processing ステージにおける具体的な設定例をいくつか紹介します。
対象となる文字列のマスキング
OneAgent によるマスキングと同様の、特定の文字列を別の文字列に置き換える方法について紹介します。
今回はログの中に含まれる IP アドレスを別の文字列に置き換えることを想定します。
各ステージでは Processor と呼ばれる処理の組み合わせによって期待する動作を定義します。
ここでは DQL プロセッサを使い、文字列の置き換えを DQL で表現します。
Matching condition によって対象となるログを指定し、DQL processor definition にて実行する処理を定義します。
DQL processor definition には以下のクエリを設定します。
fieldsAdd content=replacePattern(content, "IPADDR", "<ip_address>")
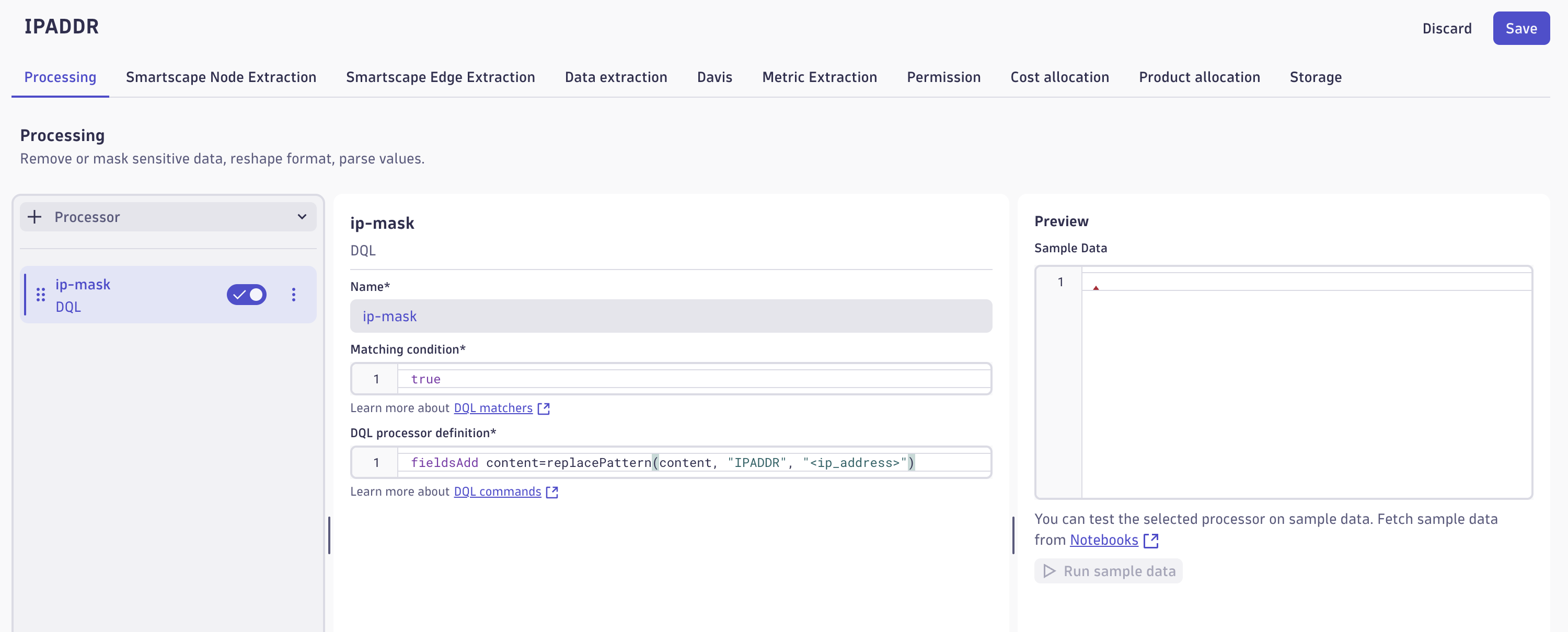
前述の通り、IPADDR は DPL で定義されているマッチャーです。5
IPv4/IPv6 それぞれのパターンにマッチする文字列を捕捉できます。
パイプラインを通す前の JSON と、パイプラインを通したあとの JSON のイメージを以下に示します。
// 変更前
{
"content": "IP Address is 192.168.0.1"
}
{
"content": "IP Address is 2001:db8::1"
}
// 変更後
{
"content": "IP Address is <ip_address>"
}
できることとしては OneAgent によるマスキングと同様ですが、DQL/DPL を利用することでより柔軟性の高いマスキングが可能です。
IPADDR の他にも、クレジットカード番号にマッチする CREDITCARD といった事前定義されたマッチャーを利用することも可能ですし、文字列や数値を対象としたマッチャーを組み合わせることで捕捉対象とするパターンを自分で定義することも可能です。
詳細は DPL のドキュメントをご覧ください。6
ログ行のフィルタリング
次に、ある文字列を含むログ行をフィルタリングする、すなわちログ行ごと取り込まないという方法について紹介します。
今回はアクセスログにおいて、ELB からのヘルスチェックによるログのみを除外することを想定します。
ここでは Drop record プロセッサを利用します。
Matching condition に以下のクエリを指定します。
matchesPhrase(content, "ELB-HealthChecker")
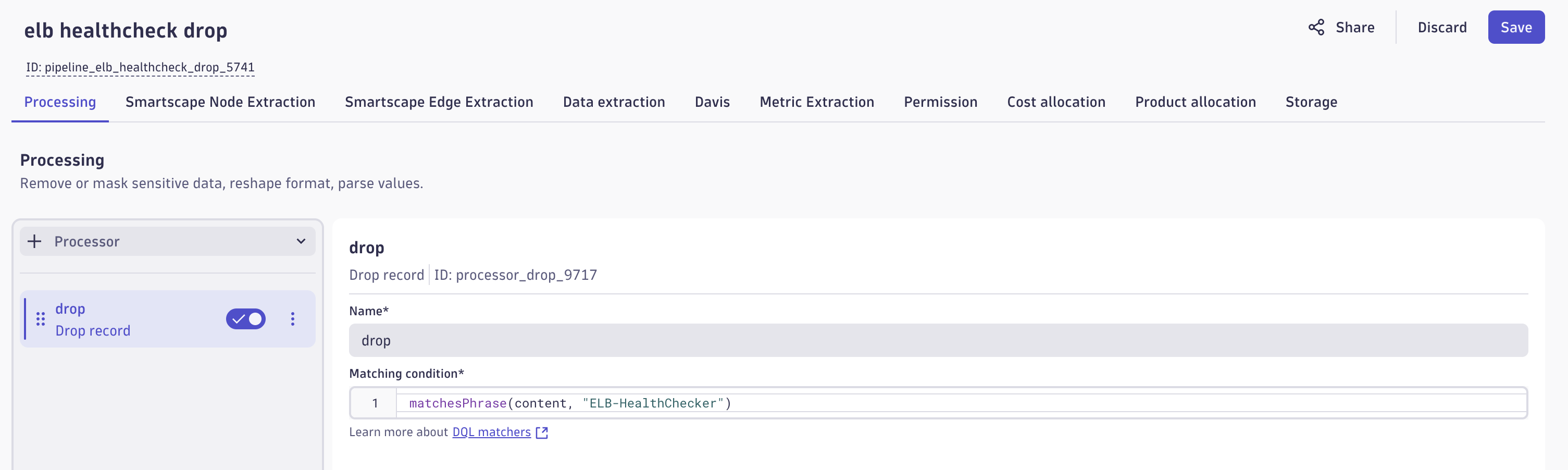
このように設定することで、ログの中に ELB-HealthChecker の文字列を含むログがドロップされます。
あるログの中に複数個のマスキングしたい情報が含まれている場合、それぞれの文字列を正規表現や DPL を利用してマスキングするのは面倒となる可能性があります。 この方法を利用すると、特定のコンポーネントが出力するログすべてをドロップするなど、より広範囲を対象として条件を設定することが可能です。
ここでは機能の概要を示すためにアクセスログのフィルタリングを示しましたが、対象とする文字列を個人情報によく含まれるものとしたり、DPL を利用して任意のパターンを捕捉するようにしたりすることで狙った文字列を含むログをフィルタリングすることができます。
メリットとデメリット
正規表現のみのルール設定と比較して、DQL/DPL を利用した柔軟なマスキング・フィルタリングルールを作成できます。
しかし、パイプラインの処理は Dynatrace 上のリソースで実行されるため、個人情報を含むログがシステムの外部に出力されることになります。 自身の環境から一切個人情報を露出しないという要件にはマッチしません。 ただし送信されるデータがまったく保護されないということではありません。 OneAgent から Dynatrace へのデータ送信時を含む、Dynatrace におけるデータセキュリティ管理全般については公式ドキュメントをご覧ください。7
2つのアプローチの比較と選択
Dynatrace におけるログマスキングのアプローチのそれぞれの違いについて、改めてまとめます。
マスキングの実行場所とセキュリティの観点
- エージェントによるマスキング
- 自身の環境内のリソースにインストールした OneAgent において処理が実行されます
- マスキングされたデータが Dynatrace に送信・保存されます
- パイプラインによるマスキング
- 自身の環境から Dynatrace にログが転送され、Dynatrace サービス上に存在するパイプラインによって処理が実行されます
- マスキングされていないデータが一時的に Dynatrace 側に取り込まれます
設定ルールの柔軟性・カスタマイズ性
- エージェントによるマスキング
- 静的な正規表現パターンによってルールを設定します
- 利用できる正規表現にも一定の制約が存在します
- 正規表現の範疇を超えるルールは設定できないため、複雑な要件には対応できない可能性があります
- パイプラインによるマスキング
- DQL/DPL を利用した柔軟なルールを指定可能です
適切なアプローチの設計指針
上記の比較を踏まえ、要件に合わせた適切なアプローチを選定する一例を示します。
- 厳格な個人情報管理を優先する場合
- 個人情報が外部に露出するリスクを最小限にしたい場合、エージェントによるマスキングが適しています
- しかし正規表現だけでは設定したいルールを実現できない可能性があり、その場合はログそのものの構成を修正する必要があります
- 柔軟なルール設定が必要な場合
- 既存のログは修正できないが特定の条件だけマスキングしたいなど複雑なルールが存在する場合、パイプラインによるマスキングが適しています
また、ここまで紹介した2つのアプローチは二者択一ではなく、組み合わせて利用することが可能です。 基本的にはエージェントによるマスキングを行いつつ、複雑な要件に対してはパイプラインによる処理を行うということも可能です。
まとめ
本記事では、Dynatrace におけるログデータ内の個人情報マスキングにおいて、2つの主要なアプローチをご紹介しました。
1つは、利用者の環境下にインストールされたエージェントにおいてマスキングを行う、「エージェントによるマスキング」です。 このアプローチはマスキングの処理が利用者の環境下で完結するため個人情報が外部に送信されず、高いセキュリティレベルを実現します。 しかし設定可能なルールの柔軟性が低く、意図したルールを実現できない可能性があります。
もう1つは、ログが Dynatrace サービスに送信された後、保存される前に行われるログ処理パイプライン(OpenPipeline)内でマスキングを行う「ログ処理パイプラインによるマスキング」です。 このアプローチは DQL/DPL を利用したルール設定の大きな柔軟性を提供します。
採用するアプローチの選定においては、自社のセキュリティ・コンプライアンス要件や設定したいマスキングルールの内容に合わせて検討する必要があります。 本記事が、皆様の Dynatrace における最適なログマスキング手法の検討の一助となれば幸いです。
-
https://docs.dynatrace.com/docs/analyze-explore-automate/logs/lma-log-ingestion/lma-log-ingestion-via-oa/lma-sensitive-data-masking ↩︎
-
2026年3月時点で、採用されている正規表現エンジンは re2 となっています。 https://docs.dynatrace.com/docs/analyze-explore-automate/logs/lma-log-ingestion/lma-log-ingestion-via-oa/lma-sensitive-data-masking#create-rule ↩︎
-
https://docs.dynatrace.com/docs/analyze-explore-automate/logs/lma-use-cases/methods-of-masking-sensitive-data#mask-logs-ingest ↩︎
-
https://docs.dynatrace.com/docs/platform/grail/dynatrace-pattern-language/log-processing-network#ipaddr ↩︎
-
https://docs.dynatrace.com/docs/platform/grail/dynatrace-pattern-language/log-processing-grammar ↩︎
-
https://docs.dynatrace.com/docs/manage/data-privacy-and-security/data-security/data-security-controls ↩︎




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。