





はじめに
こんにちは。ネットワークグループの林です。 すっかり時間が経ってしまったのですが、少し前に起こしてしまったネットワーク障害について振り返ります。
1つのインタフェイスの設定ミスが、拠点全体に波及する大きなネットワーク障害へと繋がってしまいました。 同様の障害を繰り返さないためにも、起きたことと今後の対策について書いておきたいと思います。
何があったのか
ある平日の19時頃、とある拠点の L2 スイッチについて、機器設定の変更作業を開始しました。 作業内容は description の修正、VLAN 定義の追加、Trunk ポートの許可 VLAN の追加など、細々したものでした。
この時、私はこれらを軽微な作業だと考えており、 実施時間帯の考慮もしていなければ作業報告もしていませんでした。 19時という時間についても、弊社の一般的なオフィス拠点では帰宅者が多くなる時間ではありますが、 この時は特に業務時間を避けての時間設定ではなく、たまたまこの時間になったというだけでした。 また、対象拠点はオフィスではありませんでした。
作業対象の機器は Cisco Catalyst 2960L 15台で、一括設定後に1台ずつの微調整をしていた20時過ぎ、 対象の拠点から障害発生の連絡がありました。 弊社ではリモート勤務が一般的であるため、この作業の際も遠隔で作業をしており現地にはいませんでした。
連絡を受けた時、ネットワークグループの監視からアラートは出ていませんでした。 障害の対象はお客様影響のある特定システムの端末で、通信ができないため営業に問題が出ているという報告でした。 端末起因の可能性もあるが、ネットワークに問題がないか確認してほしいという内容で、 機器アラートが出ていなかったため、第一報の時点では作業影響の可能性をあまり考えていませんでした。
その後、他のネットワークグループメンバーの調査と現地からの報告もあり、 徐々に状況が分かってくると、原因は不明だがとにかくネットワークが悪そうということだけは確実になってきました。
- 報告を受ける30分前には、すでに対象拠点内での不具合発生報告が出始めていた (作業開始時刻は30分以上前で時間は合致)
- 一部はすぐに解消、別の場所では現在も継続、不特定多数の端末で問題が起きている
- 障害が出ているシステムの端末がサーバに接続できない、または接続できていても通信がかなり遅い
- アラートが出るほどではないが、対象拠点のメインスイッチの CPU 使用率が上がっている
- 対象拠点で MACFLAP のログが大量に出ている
原因箇所は明確にならないままですが、ひとまず何かやっていたのは私だけなので作業起因であることは間違いなく、作業の切り戻しを始めました。 切り戻し開始から30分ほど経った頃、復旧し始めたと連絡がありました。 対象台数と変更箇所が多かったこと、切り戻しの手順を作っていなかったことにより時間がかかってしまいましたが、 1台の機器のインタフェイス設定を元に戻したところで復旧したことが分かりました。
障害の影響
私たちネットワークグループでは、DeNA 本体および子会社の多くの拠点のネットワークを運用しています。 運用する拠点は大小20拠点以上あり、利用者が数名程度の小規模拠点から数百人以上の拠点まで様々です。 主に弊社従業員が利用するオフィス拠点、お客様の利用もある店舗拠点、その他の特殊な拠点やデータセンタなど用途は多岐にわたり、利用者や利用時間帯もそれぞれに異なります。
障害が起きた拠点はその中でも特に大きな拠点の1つでした。 また、この拠点はオフィス拠点ではないため障害発生時は営業時間であり、対象拠点の業務全体に多大な影響が及ぶことになってしまいました。
作業背景
そもそも何をしたかったのかと言えば、機器の設定方針を揃える作業を実施していました。 背景として、これまですべて手作業で設定していた各拠点の機器設定を、 全拠点で統一化して構成管理しようというプロジェクトがあり、今回の設定変更はその統一化作業の一環でした。
稼働中の拠点が対象であるため、基本的に現状の設定そのものに問題があるということはなく、
ip dhcp snooping limit rate 100 の rate を揃えるとか、description のフォーマットを揃えるとか、
やらなくても稼働に影響はないが、今後の運用のためにもやっておきたい、といった作業がほとんどでした。
つまり、拠点利用者からの要望での設定変更ではなく、かつ定常の軽作業のつもりで事前連絡をしていなかったため、 拠点側が把握していない状態での作業となってしまっていました。
障害の原因
障害箇所の構成としては、上流から L2 スイッチが SW1-SW2-SW3 のように接続されており、一番下流の SW3 が今回の作業対象でした。
作業内容の1つとして、機器間での VLAN 設定の統一作業がありました。
定義の削除は行わない方針で、VLAN 定義の追加、または、allowed vlan の追加を行っていました。
障害の直接的な原因は、SW3 の1つのインタフェイスに以下の設定を投入したことでした。
これは、SW2-SW3 の間の接続インタフェイスの allowed vlan の指定の削除、つまり全 VLAN を許可する設定です。
スイッチ間の接続ポートは、LACP による LAG で2本の物理リンクを束ねて冗長化しているのですが、
今回は以下の設定を、SW3 の LAG を構成する物理ポートの片方のみに投入してしまいました。
interface GigabitEthernet0/15
no switchport trunk allowed vlanLAG を構成するポートの設定は揃っている必要があるため、片方のみに異なる設定を入れてしまったことは問題ですが、 設定ミスを見つけた際にも、直感的には LAG のリンクが down するという状態に思えました。 しかし、今回はこの Trunk の許可 VLAN の不整合をきっかけにループが発生し、 対象機器の配下のみならず拠点全体に影響してしまう障害へと繋がってしまいました。
事後の検証
調査
MACFLAP の大量発生、その他状況的にもループ状態に陥っていたことは間違いありません。 ただ、当時の状態を精査すればするほど、なぜループが起きたのか分からなくなっていきました。 なぜなら、設定ミスのあったポートは監視上は down していたため、物理的なループ構成はできていなかったように見えたからです。 そのため、厳密にはループと呼んでよいかというと微妙な点もあるかとは思いますが、フレームの溢れた当時の状態をここではループと表現します。
具体的には以下のような構成で、ループが実際に発生したという結果から考えれば Gi0/15 と Gi0/16 がどちらも up してかつ独立して通信していたはずです。そして、それによりループ構造ができあがってしまっていたと考えられます。
対象箇所の構成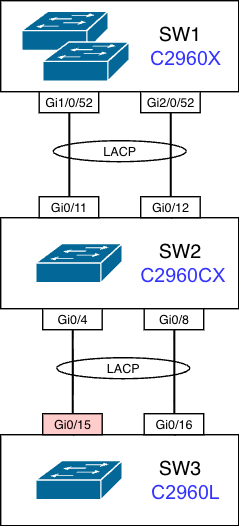
前提として Gi0/15、16 は元々 LAG で束ねて使用していたので、Gi0/15 に誤った設定を投入して LAG が正常動作しなくなった場合、Gi0/15 は down するはずです。
実際に障害時のポート状態を後から Prometheus で確認したところ、Gi0/15 は ifOperStatus=2 (down) でした。
つまり、単純に考えれば Gi0/16 だけが独立して動作していたはずで、ループが発生するようには見えませんでした。
また、STP も有効化されており、より一層ループを起こせそうには見えませんでした。
正しい設定
interface Port-channel1
description To_SW2_Po1
switchport trunk allowed vlan 10,20,30
switchport mode trunk
(省略)
interface GigabitEthernet0/15
description To_SW2_Gi0/1
switchport trunk allowed vlan 10,20,30
switchport mode trunk
channel-group 1 mode active
(省略)
interface GigabitEthernet0/16
description To_SW2_Gi0/2
switchport trunk allowed vlan 10,20,30
switchport mode trunk
channel-group 1 mode active
障害中の設定
interface Port-channel1
description To_SW2_Po1
switchport trunk allowed vlan 10,20,30
switchport mode trunk
(省略)
interface GigabitEthernet0/15
description To_SW2_Gi0/1
switchport mode trunk <---- (誤った設定) trunk allowed vlan の指定をここだけ削除
channel-group 1 mode active
(省略)
interface GigabitEthernet0/16
description To_SW2_Gi0/2
switchport trunk allowed vlan 10,20,30
switchport mode trunk
channel-group 1 mode active
検証
状況に曖昧な点が多かったため、実機で検証を行うことになりました。
障害時と同様の構成で SW1-SW2-SW3 のように接続し、SW2-SW3 の間の Po について、SW3 側の片方の IF の allowed vlan を削除しました。
まずは手元にあった 2960C 2台で、SW2/3を模して簡易的に実験しましたが、再現しませんでした。 片方のポートが普通に Po から外れ、残ったポートで普通に通信が続きました。設定を変えたポートは down し、通信は途絶えました。
Prometheus での観測結果では、対象のポートは障害中 ifOperStatus=2 (down) だったため、監視結果とは合致します。しかし、これだとループは発生しません。
他メンバーにも協力してもらい、設定を完全に揃える、機種を揃えるなどしたところ、特定の機種でのみ再現することが判明しました。
検証の結果は以下の通りです。
| 機器の組み合わせ | 対象ポートとその対向ポートの状態 | ループの発生 | 挙動の詳細 |
|---|---|---|---|
| 2960C - 2960C | 両端 down | なし | LAG は正常に suspend し、対象リンクの通信は遮断された。 |
| 2960S - 2960S | 対向は up | なし | 片方が up していても LAG は suspend し、対象リンクの通信は遮断された。 |
| 2960C - 2960S | 対向は up | なし | (同上) |
| 2960C - 2960L | 両端 down | 発生 | 障害時の状態と完全一致。down 状態のポートをフレームが通過していた。 |
| 2960S - 2960L | 対向は up | 発生 | 対向ポートが up しているので若干状況は異なるが、同上。 |
障害発生箇所とまったく同じ機器の組み合わせ、つまり SW2 を 2960C、SW3 を 2960L とし、2960L の1ポートで allowed vlan を削除したところ、ループの発生を確認できました。
検証でループが再現した時、Status: up、Protocol: down で ifOperStatus=2 になることも確認でき、観測事実とも一致することを実証できました。
また、STP は有効でしたが、Protocol: down のため、STP から見たときに対象のポートは down しており、独立してしまった物理ポートが STP の管理対象にならなかったと考えられます。
そのため、正常なリンクは変わらず forwarding、設定ミスのあるリンクは管理対象外のため block されずでリンクが2本ある状態ができてしまいました。
まとめると、2960L の仕様なのかバグなのか、2960L がやや特殊な動作をしたために、Po の片方の VLAN 不整合による Protocol: down によってループが発生していたと言えます。
ただ、2960L は EoL 済みの製品であり、ここで製品仕様への懸念を取り上げたいわけではありません。
また、今回問題があったのは運用であり、後述しますが機器の問題ではないという結論となりました。このため、障害後の対応としてもこの機器のリプレイスは行っていません。
※バグ報告も見当たりませんでした。また、障害時のバージョンは最新です。
何がよくなかったか
原因が判明したところで、今回の対応で何が良くなかったのかという点を振り返りたいと思います。 主な項目は以下です。
- 複数台まとめて設定変更したために、対象が多く原因機器の特定に時間がかかった。
- 上記に加えて、切り戻し手順も用意していなかったため、戻しにも時間がかかった。
- 末端の機器であっても全体影響を及ぼしかねないという視点が抜けていた。
障害自体も問題ですが、今回は発覚が遅れた点、および復旧までに時間がかかってしまった点も大きな問題でした。 今回の障害の大まかな時系列は以下です。
- 19時頃 作業開始。数分後には障害発生原因となる設定を投入。
- アラートが出ず、この時点では異常に気が付かなかった。
- 20時頃 現地より不具合報告。これにより障害が発覚。
- 調査を開始し、ログの異常等に気が付き始める。
- 21時頃 原因不明のまま切り戻しにより復旧。
- 切り戻し直後、現地から復旧報告をもらう。
- 22時頃 継続していた調査の中で原因箇所が明確になり、他の影響がないことを確認して一次対応を完了。
まず、障害発覚の遅れについてですが、これの要因は主に以下です。
- 作業中に機器リソースを確認していなかったため、異変に気がつくことができなかった。
- リソースの確認は設定投入後の最終確認項目には入っていたが、障害時にはまだ別の作業が継続しており確認作業に入っていなかった。
- 問題の設定投入後、すぐに Warning ログの増加、対象機器の CPU 使用率の増加が始まるが +10% 程度であったためリソースのアラートの検知はなかった。
- 対象ポートのインタフェイス監視が元々設定されていなかった (事後調査にて判明)。
- 設定していたはずの LACP の監視が無効になってしまっていた (事後調査にて判明)。
通常、スイッチ間の接続インタフェイスには監視を入れているのですが、対象機器は構築時に設定を忘れられてしまったのか、元から監視設定が入っていませんでした。 また、LACP の監視については、直前に別件での監視修正不備があり、こちらもたまたまこのタイミングで抜けてしまっていました。 このため、ポートの up/down も LACP の suspend もどちらも検知できない状態になってしまっていました。
また、障害発覚後の復旧に時間がかかった点については、複数台を同時に操作していたという点が大きな問題でした。 これにより、障害対象の絞り込みに時間がかかり、障害箇所の特定に時間がかかり、 その間に切り戻し作業を1台1台実施するにあたっても台数が多いことにより時間がかかってしまいました。
今後の対策
機器リプレイスの検討
今後の対策として、C2960L を即座に廃止する必要があるかどうかという点についても検討しました。
重要な点は同じ状況がまた発生してしまうかどうかということですが、C2960L が特殊だとしても、今回のような作業起因以外で「自然に片側 suspend」という状態は考えにくいと思われます。 自然に片方のリンクが駄目になるケースでは、物理的にリンクが損傷していることになるので論理的に使われ続けるということは考えにくいためです。
結論として、急ぎでのリプレイス等の対応は行わないことになりました。
監視の見直し
前述の直接的な監視の不備については即座に修正を行いました。 ただ、それ以前の問題として、そもそもこの障害の少し前から、監視の閾値変更を行う際には必ずレビューを通すというルールが明確化されていました。 しかし、人間のやることなので、私が安易にこの障害を起こしたように、うっかりレビュー依頼を忘れてしまうこともあると思います。
特に、ネットワークグループでは軽微な閾値変更は日常的に多数実施してきており、これまでそれを個人の判断でそれとなく行ってきたという背景がありました。 これがよくないということで、監視の変更はすべてレビュー必須となりました。 また、今回の障害を受け、アラートルールを定義しているリポジトリの PR は、レビュワの承認なしではマージできないように設定を変更しました。
現在はこの PR ルールによる強制にかかわらず、レビューを受けることがグループ全体で根付いた状態になっています。 また、PR の AI 自動レビューも有効化し、人力以外でも不備を発見できるように設定しています。
その他の対策
障害の原因究明後、グループ内で改めて、ネットワーク変更作業についてのルールの確認を行いました。 前述のレビュールールの明確化に加え、作業前の周知を徹底することなど、具体的なルールの見直しと認識合わせを行いました。 これまでは、作業前の周知基準が人によって異なるといったこともありましたが、軽微な作業であっても自己判断せず周知するルールとなりました。 それでも万が一はあり得るので、当たり前ではあるのですが、拠点の責任者等と日程調整をする、拠点の運用スケジュールを把握し興行日を避けるなどの作業日時のルールについても改めて認識を合わせました。
また、手順確認、切り戻し手順の作成基準等についても話し合いました。 すべての作業で切り戻し手順を作ることは現実的ではないため、影響の大きいメンテナンスや今回のような複数台作業など、いざ切り戻すとなった時に時間がかかる作業では作成するなど、手順についても改めてルールを確認しました。
加えて、当時と今とで大きく状況が変わる点として、この1年で急速に AI 活用が進んだことが挙げられます。 今であればひとまずログを AI に見せるということができたと思いますし、それによりすぐに原因にたどり着くことができたように思います。 ネットワークグループでも日々の業務やアラートの解析等への AI 活用を進めており、日頃からネットワーク運用業務で AI を利用しているのですが、振り返ってみても、今回は AI での事前レビューや障害時の状況解析が有効な事案であったと思います。
まとめ
作業ミス、不測の事態、バグ、様々な理由で作業時には障害が発生する可能性があります。「だから、事前調整をしてメンテナンス時間を確保する」という、当たり前のことをできていなければなりませんでした。
その上で、万一の時に対応できるよう事前に準備する、人力ではなく仕組みで防ぐことができる部分は対策するというところを検討し、今回ブログにまとめました。
今後、私自身が一番気を付けるということは言うまでもありませんが、うっかり軽はずみな作業をしそうになった時、「そう言えばこうやってやらかしていた人がいたな。ちゃんと確認してからにしよう」と、思い出してもらえたらと思います。


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。