





はじめに:この記事について
こんにちは、IRIAM で SRE を担当している 井早 と申します。本記事は、Google Cloud Next Tokyo 25 でのセッション「少数のインフラ人員でビジネスと組織のスケールに耐える Google Cloud の設計と運用のエッセンス」の内容を、技術ブログとして再構成したものです。
IRIAM の SRE チームが、急激な事業成長と組織拡大の中で、いかにしてシステムの複雑性をコントロールし、少人数での運用を可能にしているか。その核心にある「インターフェース」中心の設計思想について解説します。
なお、本セッションの動画アーカイブは、以下で公開されています。
IRIAM とは?
IRIAM(イリアム)は一言で言い表すと、「キャラでつながるライブ配信」サービスです。キャラクターを通じたライブコミュニケーションによって、なりたい自分でつながり合える、そんな居場所の提供を目指したサービスとなっております。

IRIAM は、キャラクターの描かれた 1 枚絵のイラストをアップロードすると、それをキャラのアバターとして動かせるようにする「自動モデリング機能」を提供しており、誰でもすぐに気軽に 2D キャラクターでキャラ配信を行うことができます。また、 0.1 秒というレイテンシを抑えた通信によって、まるですぐそばにいるかのような、リアルタイム性の高いライブ配信を実現しています。

課題:ビジネスと組織の急成長がもたらす複雑性
そんな「IRIAM」はおかげさまで、近年著しい成長を遂げています。サービス開始から数年で、1 日あたりの配信数は約 24 倍に、それを支える社員数は 3 倍に増加しました。
このスケールに伴い、インフラも複雑化の一途を辿りました。利用する Google Cloud サービスは 20 種類から 50 種類以上に増え、SRE チームの責務もプラットフォーム運用や信頼性維持といった従来の領域に加え、データ基盤整備や SRE 文化の啓蒙など、多岐にわたるようになりました。

しかし、責務が拡大する一方で、運用負荷が比例して増大したという感覚はありません。その背景には、変化に対して常に最適解を選択できるシステムの柔軟性があります。そして、その柔軟性の源泉こそが、私たちがシステム設計の根幹に据える「設計思想」なのです。
解決策:インターフェース中心設計という思想
IRIAM の SRE は、システムを構築・運用するうえで、常に以下の 4 つの設計思想を重要視しています。
- 信頼性と金銭コスト
- 大前提として、ビジネス上の要求を満たせるか
- 変更のしやすさ、柔軟性
- システムは疎結合か、将来の変更・移行・廃止に耐えられるか、ベンダーロックインを避けられるか
- 技術の安定性と将来性
- 採用技術は標準化されているか、開発は活発か、サポート期間は長いか、枯れているか
- 運用のしやすさ、手のかからなさ
- 可観測性(Observability)は確保できるか、Auto Scaling/Healing は可能か、自動化や IaC 化はできるか
これらの観点はすべて重要ですが、今回のセッションおよび本記事では、とくに「変更のしやすさ、柔軟性」と「技術の安定性と将来性」の 2 つに焦点を当てて解説します。
議論を進めるにあたり、本記事で用いる主要な用語「疎結合」「標準化」「インターフェース」について、おさらいを兼ねて定義を明確にしておきます。
- 疎結合
- システムやプログラムの構成要素同士の依存関係を弱く保つこと
- 標準化
- 複数のシステムが共通で理解・利用できるよう、技術や仕様を統一すること
- インターフェース
- システム同士がやり取りするための接点・取り決め。本来の意味である「境界面」「接点」を意図しており、「システムとシステムの切断面」とも表現できます

これらの定義に基づき、私たちが柔軟性と将来性を確保するために掲げる原則は、以下の 2 点に集約されます。
- システム間に明確なインターフェースを定義し、疎結合にする
- インターフェースには標準化された技術を用いる
複数のシステムが接続・連携する際には、例外なく必ずインターフェースが発生します。これを意識せずに放置すると、意図しない密結合が自然に発生し、将来の変更容易性を損なう「負債」となってしまいます。
そのため、インターフェースを将来にわたってコントロールできるよう、意識的に設計・選択することが極めて重要です。
適切に設計されたインターフェースは、システムの変更容易性に直結します。インターフェースが疎結合であれば、接続している片方のシステムを容易に入れ替えたり、技術的負債を捨てやすくなります。これにより、将来の変更、移行、あるいはサービスの終了といった事態にも耐えうる柔軟性を維持できるのです。
この思想に基づき、私たちはインターフェースに標準化された技術を採用することを基本方針としています。もし適切な標準技術が存在しない場合は、「ベンダーロックインするくらいなら自作する」という考えのもと、インターフェースを自作することも検討します。
実践例:IRIAM における 3 つのインターフェース活用術
この設計思想が、IRIAM のシステムアーキテクチャにどう具体的に反映されているか、3 つの事例を挙げて解説します。
1. 「コンテナイメージ」によるコンピューティング基盤の抽象化
アプリケーションの実行ランタイムとして、標準化されたインターフェースである「コンテナイメージ」 を採用しています。これにより、アプリケーションコードにほぼ手を加えることなく、ビジネス要件に応じて最適なコンピューティング基盤を柔軟に選択・移行することが可能です。
移行例 1: GKE から Cloud Run への移行

管理画面サービスは、当初 VPC 内データベースへの接続要件から GKE で稼働していましたが、VPC Access Connector などの登場により Cloud Run が VPC 接続に対応したため、より構成がシンプルで Scale to zero も容易な Cloud Run へ移行しました。
移行例 2:Cloud Run から GKE への移行

ログ収集サービスは、当初構成のシンプルさと VPC アクセスが不要だったことから Cloud Run を採用していましたが、サービスの成長に伴うログ流量の増加で常時稼働が前提となったため、よりコスト効率に優れる GKE へ移行しました。
これらの移行が容易なのは、Cloud Run と GKE 両者が「コンテナイメージ」という共通のインターフェースをサポートしているからに他なりません。
2. 「make コマンド」による CI/CD パイプラインの共通化

CI/CD パイプラインでは、特定の make コマンド群をインターフェースとして規定しています。各アプリケーションリポジトリは、言語やデプロイ先(GKE, Cloud Run など)にかかわらず、make docker-build や make deploy-env といった共通のターゲットを実装します。
これにより、デプロイを実行する GitHub Actions のワークフローは、各リポジトリの詳細な実装を意識する必要がなくなります。Action とアプリケーションが疎結合になるため、それぞれを独立して更新できるというメリットがあります。
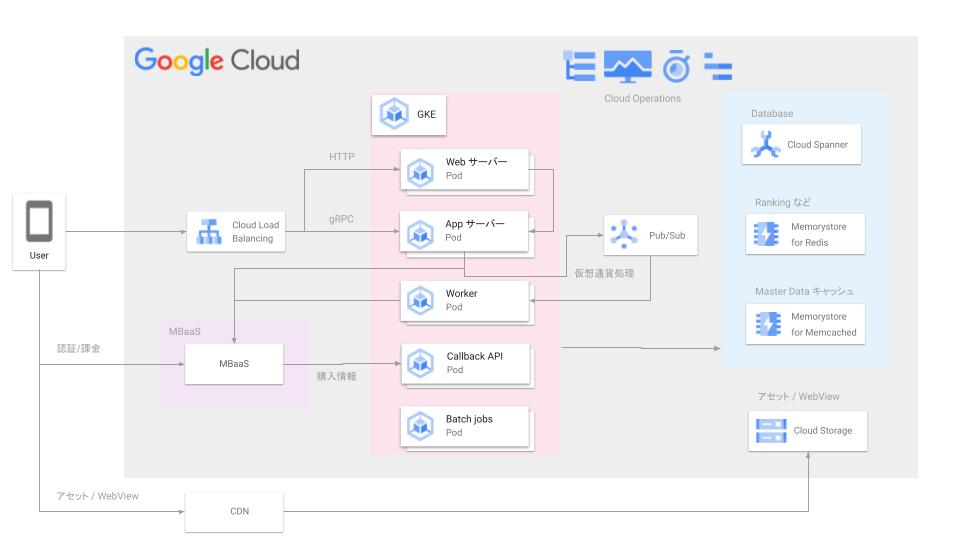
3. 配信サーバーエコシステムにおける 2 つの重要なインターフェース
IRIAM のコア機能であるリアルタイム配信は、複数のサービスが連携する複雑なエコシステムによって実現されています。

このエコシステムは、主に以下のコンポーネントで構成されています。
- 配信サーバー群: GCE や他クラウドのインスタンスからなるマルチクラウド構成で、モーションデータや音声の送受信を担う心臓部です
- API サービス: GKE 上で稼働し、ライバーやリスナーからのリクエストを受け付ける窓口となります
- 配信サーバー管理サービス: Cloud Run で構築され、配信サーバーの割り当てやライフサイクルを管理します
- Cloud Pub/Sub: コメントやギフトといったリアルタイム性の高いメッセージを各サーバーへ迅速に届けます
- 監視・分析基盤: Cloud Logging, Cloud Trace, Prometheus などで構成され、システムの健全性を保ちます
では、実際にユーザーがどのようにこれらのコンポーネントを使っているのか、ライバーとリスナーの体験に沿ってご説明します。
- 1: 配信の開始
- まず、ライバーがアプリ上で「配信開始」を行うと、リクエストが API サービスに送られます。リクエストを受け取った API サービスは、配信サーバー管理サービスに、配信サーバーの割り当てを依頼します。配信サーバー管理サービスは、利用可能な配信サーバーを選び出し、ライバーに割り当てます
- 2: データ送受信
- ライバーは、割り当てられた配信サーバーに対し、アバターのモーションデータと音声を送信します。リスナーは、視聴したい配信に入室すると、その配信サーバーに接続し、サーバーからモーションデータや音声をリアルタイムで受け取ることができます
- 3: インタラクション
- また、リスナーは配信にコメントやギフトを送ることができます。これらのインタラクションは、一度 API サービスに送られ、API サービスはその情報を Cloud Pub/Sub にプッシュします。配信サーバーは Cloud Pub/Sub を購読(subscribe)しており、受け取った情報をライバーと他の全リスナーに送信します
このエコシステムにおいても、とくに重要なインターフェースが 2 つ存在します。
まず 1 つ目は、OpenTelemetry をインターフェースすることによるメトリクスデータ収集の標準化です。

GKE、Cloud Run、GCE、他社クラウドなど、さまざまな環境で稼働する全アプリケーションのテレメトリデータ(ログ・メトリクス・トレース)は、標準規格である OpenTelemetry をインターフェースとして収集しています。これにより、アプリケーション側は出力形式のみを意識すればよく、データの送信先(Google Cloud Observability や Prometheus など)は、コストや要件に応じて柔軟に切り替えることが可能です。
そして 2 つ目は、配信サーバー管理サービスをインターフェースとすることによるマルチクラウドの抽象化です。

配信サーバーは GCE と他社クラウドインスタンスによるマルチクラウド構成です。このインフラの差異を吸収するため、Go 言語で「配信サーバー管理サービス」を自作し、インターフェースとして機能させています。API サービスは、物理サーバーの所在を意識することなく、この管理サービスに対して「配信サーバーを割り当ててください」という標準化されたリクエストを送るだけで済みます。これにより、サービスとインフラの関心事を完全に分離しています。
まとめ
IRIAM の SRE は、ビジネスと組織の急激なスケールという課題に対し、「疎結合で標準化されたインターフェース」 ということを中心にした設計思想で向き合っています。
十分に設計されたインターフェースは、システムの複雑度を低減し、変更容易性を最大化します。この柔軟性こそが、私たちが少ない人数で、変化し続けるサービスを安定的に運用し続けられる理由です。
実際に Google Cloud Next Tokyo 25 に参加してみて
実際に参加してみた感想としては、例年以上に LLM 関連のセッションへ注目が集まっていると感じました。その分、一時期はメイントピックであった SRE のノウハウ共有に関するセッションは、テーマとしての比重が変化した印象を受けました。
そして、登壇にあたり資料の内容の壁打ちから締め切り直前のスライド修正へのご対応、そして当日のセッション進行まで、Google の皆様には大変お世話になりました。この場を借りて御礼申し上げます。 また、当日は Day2 の最後のセッションにもかかわらず、多くの方にご聴講いただきました。暑い中足をお運びいただいた皆様、誠にありがとうございました。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。