





はじめに
はじめまして。2025年度DeNA AIスペシャリストサマーインターンシップに参加し、共同で研究に取り組んだ雨宮佳音と増田瞬です。 本記事では、私たち2人がチームとして挑戦した研究内容や、インターンを通して得た学びについて紹介します。 まずはそれぞれ簡単に自己紹介をします。
自己紹介
- 雨宮佳音:慶應義塾大学修士1年。大学ではファッション分野におけるマルチモーダルAIの研究をしています。
- 増田瞬:筑波大学修士1年。大学では画像合成に関するAI技術の研究を行っています。
本記事の内容
今回のインターンシップでは、「画像・動画入出力を伴うAI対話インターフェースの調査・プロトタイプ作成」というテーマに取り組みました。4週間のインターンシップ期間の中で、動画像を利用したAI技術の調査、そこから動画像を入力にすることで生まれる価値について考え、その価値を生かしたプロトタイプの考案と実装を行いました。本記事では、調査やプロトタイプ作成を通して感じた画像・動画AIの持つ可能性や課題と、技術を組み合わせてアプリケーションを作る面白さをお伝えできれば幸いです。
こんな人に読んでほしい
- DeNAのサマーインターンシップに興味がある人
- 画像・動画の理解および生成AIの技術の活用に興味がある人
- 技術の組み合わせによって新たなアプリケーションを作ることに興味がある人
AI対話インターフェースの可能性
AI対話インターフェースの概念
AIとの対話と聞くと、皆さんは何を思い浮かべますか?多くの方が、ChatGPTのようなテキストベースのチャットAIや、Siriのように音声でやり取りするAIアシスタントを想像するのではないでしょうか。これらはまさに、テキストや音声を介してAIとコミュニケーションをとるAI対話インターフェースの代表例です。
映像活用によるAI対話の拡張
今回のインターンシップのテーマは、このAI対話に画像・動画という視覚的な情報を加えることで、どのような新しい価値が生まれるかを模索することでした。
私たちは映像がなければ解決できないような課題を解決するプロトタイプを提案しようと考えました。そこで、動画像を扱うことで、どのような「新しい価値」を生み出せるのかを考えました。
映像情報の追加は、AI対話インターフェースに大きく3つの価値をもたらすと考えました。1つ目は、人間の視覚的な情報をAIに伝えることです。たとえば、私たちの姿勢、表情、身振りといった非言語情報は、テキストや音声だけでは伝えきれない豊かな情報を含んでいます。これをAIが理解できるようになれば、より深い対話が可能になります。
2つ目は、AIが処理した情報を視覚的に人間に伝えることです。AIが単にテキストや音声で返答するだけでなく、アバターの口の動き、目の動き、顔の表情などを通して情報を伝達することで、より直感的で親しみやすい対話体験を創出できます。
そして3つ目は、これらの映像情報を活用することで、AIは受け身な存在から、能動的なコミュニケーションを仕掛ける存在になるということです。たとえば、ユーザーの様子を察知してAI側から話しかけるといった、人間同士の自然な対話に近いインタラクションが実現できるかもしれません。
プロトタイプ 〜 FitVision Trainer 〜

プロトタイプ開発の背景
今回のインターンシップで私たちがプロトタイプとして開発したのは、AIによる筋トレ支援ツール「FitVision Trainer」です。皆さんは筋トレを継続できていますか?一人で筋トレを続けるのはなかなか難しいと感じる方も多いのではないでしょうか。モチベーションの維持や、正しいフォームでの実施は、一人ではハードルが高いものです。
パーソナルトレーニングは効果的ですが、1時間あたり数千円というコストや、時間・場所の制約があります。そこで私たちは、「いつでも、どこでも、気軽に頼れるAIトレーナーがいたら、多くの人が筋トレを楽しめるようになるのではないか」と考え、このプロトタイプ開発に着手しました。
FitVision Trainerの概要
FitVision Trainerは、一人での筋トレを強力にサポートするAIトレーナーアプリケーションです。ユーザーの表情や動きを映像で捉え、それに基づいてAIがユーザーの調子や悩みに応じたアドバイスを提供したり、適切なフォームや回数を指示したりします。
アプリケーションの基本フロー
このアプリケーションは、大きく「相談フェーズ」と「筋トレフェーズ」の2つのフェーズで構成されています。
- 相談フェーズ: ユーザーの調子や今日の悩みをAIがヒアリングし、その日の体調や目標に合わせた最適な筋トレ種目や回数を提案します。ユーザーの手振りや表情などから、やる気や疲労度を察知し、適切な声かけをすることを目指しました。
- 筋トレフェーズ: 実際に筋トレを行うフェーズです。AIがユーザーの筋トレ回数を正確にカウントし、ペースに合わせて応援の言葉をかけます。また、フォームが崩れた際にはリアルタイムで指摘し、正しいフォームへの軌道を視覚的に可視化してサポートします。
このように、映像情報を活用することで、FitVision Trainerはユーザーの状況を深く理解し、パーソナルトレーナーさながらのきめ細やかなサポートを提供することを目指しました。
アプリケーションのデモ
技術調査とプロトタイプ実装
FitVision Trainerを実現するために、私たちは多岐にわたるAI技術の調査と実装に取り組みました。ここでは、各フェーズでどのような技術を採用し、どのような挑戦と課題に直面したのかを具体的にご紹介します。
相談フェーズの技術要素
相談フェーズでは、ユーザーの言葉だけでなく、表情や視覚的な情報から状況を理解し、人間のように自然な対話を行うための技術を検討しました。

動画理解VLM
まず、ユーザーが映ったWebカメラの映像から、ユーザーの発話内容に加えて、表情や動作を理解するため、動画理解VLM (Vision-Language Model) を利用しました。モデルに対してはWebカメラの映像を入力し、後段の処理に用いるトレーナーの発話内容や表情を出力します。
VLMの性能比較
いくつかの動画理解VLMについて、それらのキャプション生成の精度と速度を比較検討しました。実験対象のVLMは、SmolVLM2-500M-Video-InstructやQwen2.5-VL-7B-Instructといったオープンモデルと、Gemini-2.5-flashやGemini-2.5-proのようなクローズドモデルです。実験では、2秒程度の動画から人物の動作や表情、そこから伝えたいメッセージを推論させ、その推論精度、および速度をT4 GPU環境で評価しました。結果として、Gemini-2.5-flashの思考なしモードが精度と速度の両方の観点から望ましいと考え、プロトタイプ作成において採用しました。
Gemini APIの便利機能
- 会話履歴を考慮した回答生成:ユーザーとの対話に一貫性を持たせるため、Gemini APIが提供する会話履歴を保持する機能を利用しました。これにより、過去の発言内容を踏まえた、より自然な応答が可能になりました。(参考:Gemini APIで質問応答のチャット1)
- 構造化出力による出力形式指定:出力テキストを特定の形式(JSONや列挙型など)で受け取ることで、後続の処理で扱いやすくできます。プロンプトで出力形式を指定することも可能ですが、エラーのリスクがあるため、Geminiの構造化出力機能を活用しました。(参考:構造化出力2)
- fine-tuning:今回はインターン期間の短さの関係で実験は行いませんでしたが、Gemini APIはfine-tuningの機能も提供しています。社員の吉田さんがGitHubに事例を共有しています。(参考:birdwatcherYT/gemini-ft-test3)想像していたよりも簡単にできることに驚きました。
音声合成
AIトレーナーからの応答をユーザーに自然に伝えるため、音声合成技術を使用しました。プロトタイプにおいては、GoogleのText-to-Speech AIを採用しました。本モデルの音声合成速度は、日本語43文字の文章に対して約0.61秒と高速であり、リアルタイムに近い対話において大きなメリットとなりました。また、単純なテキスト読み上げだけでなく、SSML(Speech Synthesis Markup Language)タグを使用することで、発音、音量、ピッチ、話す速度などを細かくカスタマイズし、より人間らしい、感情豊かな音声表現を目指しました。
アバター生成
AIトレーナーの視覚的な存在感と表現力を高めるために、画像生成モデルを利用したアバターの生成と表情・姿勢の編集に取り組みました。ユーザーに親しみを感じてもらえるアバターを作成し、AI対話体験の質を高めることを目指しました。
アバター画像生成
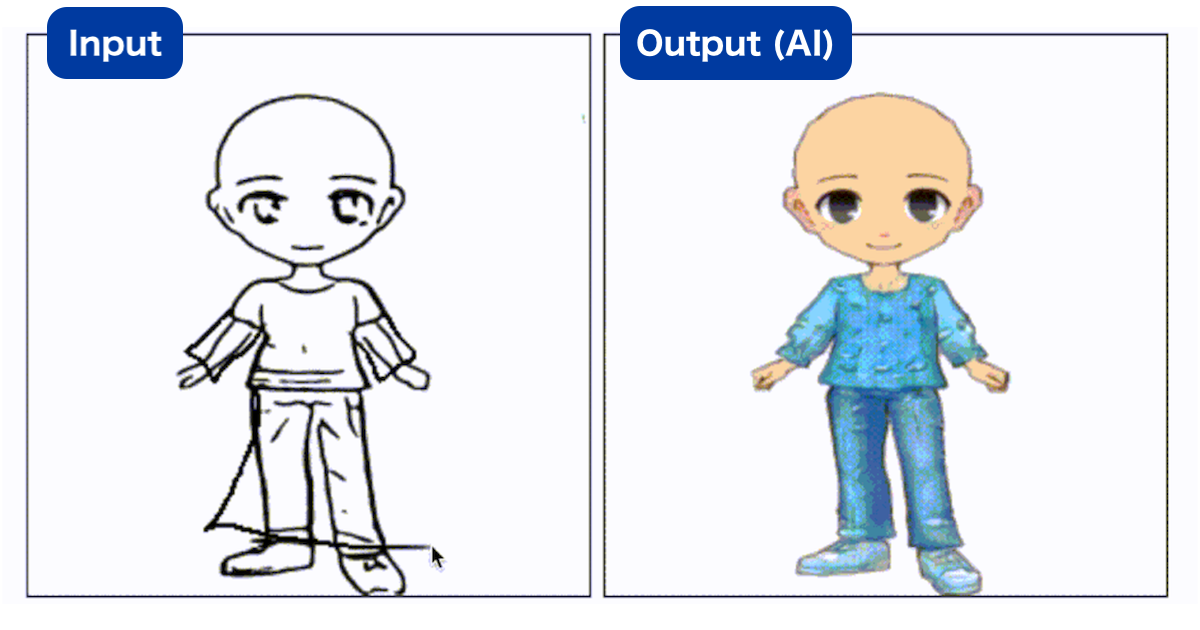
アバターの生成にはNano Banana4という画像生成モデルを利用しました。Nano Bananaは高品質な最新の画像生成モデルで注目を集めています。今回のアバター生成では、”a man”のような性別や見た目を左右する情報をテキストとして与え、アバターを生成しました。人の見た目は概ね高品質で、アバターとして十分に使えそうな見た目であると感じました。
将来的には生成AIを利用してユーザーが希望のアバターを作成することを目指しています。その上で、現状の課題は生成結果によって画角が安定しないという部分だと感じました。アプリの使用によって、顔がこのくらいの位置にこのくらいの大きさであってほしいなど、ある程度のフォーマットが定まっていると思いますが、現時点では希望の画角を得るためには壁打ち(試行錯誤)が必要です。アバター生成時の壁打ちを軽減する方法として、構図を指定する画像や線画などを事前にフォーマットとして準備して、画像生成時に組み合わせることが考えられます。



表情の編集
アバターの表情をAIの感情に合わせて変化させることで、より表情豊かなアバターとのAI対話を実現しました。今回は、事前に数種類の表情パターン(笑顔、悲しみ、怒りなど)を生成しておく方法としました。GANベースの手法など、リアルタイム性のある手法は存在しますが、今回は品質を優先する方法を取りました。
結果を確認してみると、かなりそれらしく表情が編集できていることがわかります。



フォームの可視化
実際のパーソナルトレーナーのように、アバターが正しいフォームを実演・可視化することで、ユーザーの理解を深めることを試みました。フォームを可視化するために、今回はNano Bananaを利用してフォームに合わせてポーズを制御することに挑戦しました。今回は、アームカールという肘の曲げ伸ばしによって二の腕を鍛える筋トレのフォームを、コマ送り形式でアバターに再現してもらうことを目指します。
テキストによる条件付け
まずはテキストのみによる条件付けでポーズを制御しようと考えました。まず、結果の一番左の画像のような直立のアバター画像に対して「アームカールを行って」という風に指示すると、左から2番目のアームカールの代表的な肘を曲げた動きとなりました。そこで、次に左から二番目の画像と組み合わせて、「肘の角度を少し広げて」などコマ送りの他のコマに対応するような指示を与えましたが、結果としては左から三、四枚目のようにそこまでうまくいきませんでした。テキストだけでは、腕や肘の微妙な角度の指定が難しいと感じました。また、テキストによる条件付けは壁打ちが前提になっていて、種目数が増えたときにあまり適さない方法だと考えます。




画像による条件付け
次に試したのは、画像を利用したポーズの制御です。これが可能となれば、画像を事前に準備すれば、それに沿ってポーズの制御を行うようにすることで、コマ送り作成を自動化できます。Nano bananaでは、画像を複数枚参照した状態で、テキストと組み合わせて画像を生成できます。なので、今回は、片方の画像のポーズに、もう片方の画像のポーズを合わせることができるか実験しました。一番左の人物の姿勢を、真ん中の人物の姿勢に変更するように指定した結果が一番右の結果です。確認すると、姿勢が反映できていないことがわかります。また、自分自身の画像を利用したときは、アバターに体型差が反映されて、アバターの腕が細くなるなど、姿勢以外の情報も一緒に伝わってしまうことがありました。プロンプトエンジニアリングで改善する可能性はありますが、現状ではこの方法もポーズの制御に適した方法ではありませんでした。



ちなみに、今回は時間の関係で取り組めませんでしたが、一般的にControlNet5などの追加モジュールを利用してローカルで動かせるモデルをファインチューニングすることで、ポーズの制御が行えることが知られています。そのため、独自のデータセットなどを利用して学習することで、より高品質なポーズの制御が行えると考えられます。また、学習ベースのモデルであれば、テキストプロンプトが不要で、ポーズの制御に特化したモデルを学習可能で、自動化に近づきます。ただ、筋トレのフォームは、細かい関節の捻り方や、指の曲げ方まで考える必要があるため、通常のポーズの制御よりも難しいタスクだと考えられます。
筋トレフェーズの技術要素
筋トレフェーズでは、ユーザーの動きを正確に検知し、リアルタイムでフィードバックするための技術を検討しました。

骨格推定
ユーザーの筋トレフォームをリアルタイムで分析するため、骨格推定技術を用いました。プロトタイプにおいては、Google MediaPipeを採用しました。Face Detection、Hands、Pose、Holisticなど、多岐にわたるランドマーク推定モデルが提供されており、今回はPoseモデルを中心に活用しました。
ランドマーク座標を用いた筋トレの回数判定
MediaPipeで取得した身体各部位のランドマーク座標を用いて、筋トレのUP動作とDOWN動作を判定し、それに基づきカウントを行いました。このとき、動画の画角に左右されないよう、角度や相対位置の情報を用いて判定を行いました。現状は種目ごとの閾値を事前に定義していますが、将来的にはAIが自動で閾値を定義できれば、種目追加が容易になると考えられます。

ペース判定
筋トレ中にユーザーが「きつい」と感じているときをAIが察知し、応援の言葉をかけることでモチベーション維持をサポートしました。具体的には、筋トレの一定区間をN分割し、各区間の通過時間を測定し、平均通過時間と比較してN倍以上の時間がかかっている場合に「きつい」と判定するよう実装しました。
フォームガイドラインの可視化
映像入出力インターフェースの強みを活かし、ユーザーの画面に直接フィードバックを重ねて表示するガイドラインを実装しました。たとえばアームカールであれば、「肘を固定し、40度から160度の弧を描く」といった具体的な注意点を、ユーザーが映った映像に対して重畳する形で視覚的に示すことで、ユーザーが直感的にフォーム改善できるよう支援しました。
フォーム改善
骨格推定の結果に基づき、AIがユーザーにフォーム改善のアドバイスを提供します。Geminiを活用し、ユーザーの骨格情報からフォームの課題を特定し、音声でフィードバックを生成しました。1カウントごとにフォームを指摘するリアルタイムフィードバックと、1セット全体のフォームを総括するフィードバックの両方を実装しました。
リップシンク
リップシンクとは、発話内容(音声、テキスト)に合うように、画像や動画の人物・キャラクターの口元の動きを生成する技術です。これを利用すると、生成された音声に合わせて、アバターの口元を動かした動画を作ることができます。今回は、AIトレーナーが発話する際に、アバターの口元を音声に合わせて動かすリップシンク技術を検討しました。
まず、今回のプロトタイプでは、リップシンクの手法を選ぶ上でいくつかの基準がありました。私たちのプロトタイプでは、アバターとユーザがリアルタイムに対話できることを目指しています。なので、推論が高速な手法を選ぶ必要があります。また、ユーザが作成したアバター画像1枚からリップシンクを生成したいと考えています。そのため、動画による事前学習が不要で、画像1枚から生成できるような手法を選ぶ必要があります。
そこで、今回選んだのがMuseTalk6という手法です。この手法は、画像の顔領域を取り出して、その下半分を音声に合わせて編集するというシンプルな作りになっています。そのため、画像1枚からリップシンク動画の生成が可能になっています。結果は以下の動画の通りです。結果を確認すると、音声に沿って口元が動いている一方で、上半分が固定され動きがないため、不気味な動画となってしまっています。
この不気味さが残るという課題に対して、瞬きのある動画を生成してからリップシンクを行うことで、不気味さが軽減するのではと考えました。また、個人的に人間の見た目に寄せた状態であることが、不気味さをさらに増していると考えたため、よりデフォルメされたキャラクターなど非現実な表現を取り入れることで不気味さが軽減されると考えています。
また、リアルタイムでの利用には生成時間の長さが障壁となりました。フレームレートを落としても一文あたり7〜10秒程度かかり、リアルタイム対話には不向きであると判断しました。今回のプロトタイプには、数字など事前に文言の決まっている部分に試験的にリップシンクを入れました。
プロトタイプ外で試した技術探求
プロトタイプ開発の過程で、私たちはさらにいくつかの技術的な探求を行いました。最終的にプロトタイプには組み込まれませんでしたが、AIの可能性の検証につながったと考えているので、その一部を紹介します。
効かせたい筋肉のセグメンテーション
筋トレではよく「どこどこの筋肉を意識して効かせるんだ!」という意識すると筋トレ効果が上がるみたいなことを言いますよね。この筋肉の部位をAIがその場で可視化してくれたら意識をしやすいですが、現実世界では筋肉に色をつけることはできないので、そこに機械学習を利用した筋トレ支援の意味があると考えました。
しかし、セグメンテーション手法は可視な領域の分割をするものがほとんどで、いくつかの手法を試しましたが、筋肉のような実際に見えない部分をセグメンテーションすることは難しかったです。ここは、独自のデータセットなどによる学習で改善する可能性があります。
VLMによるフォーム指導の可視化
筋トレをしていて、フォームをどう直せば良いのか、言葉だけではわからない場面があると思います。そこで、VLMによって、画像内にどのようにフォームを直すべきか矢印などで書き込みさせる方法で、フォームの指導ができないかを考えました。
しかし、検証に利用したNano Bananaによって生成された画像では、指示がわかりにくい場面が多く、またユーザ自体の見た目が変化してしまうという問題がありました。筋トレに限らず、姿勢・イラストなどの画像に対する添削、修正を画像に書き込むタスクは、Nano Bananaでもそこまで得意ではない印象で、特化したモデルが学習できれば面白そうだと感じました。

今後の展望
今回のFitVision Trainerプロトタイプは、映像を活用したAI対話インターフェースの可能性を示す第一歩です。まだ完成には程遠く、たくさんの課題を見つけたので、その一部を紹介します。
- ユーザーデータ収集と改善サイクルの構築: ユーザーの利用データを収集し、それをAIモデルの改善や機能拡充に繋げる仕組みを構築することが不可欠です。アバターが親しみやすい存在となることで、データ収集を有利に進められるかもしれません。
- 種目増加時のパイプライン自動化: 現在は特定の筋トレ種目に特化していますが、多様な種目に対応できるよう、種目定義、フォームのコマ送り生成、指摘用判定準備などのパイプラインを自動化していく必要があります。
- ユーザーの希望に応じたアバター生成とモーション指導: ユーザーが自分好みの見た目のアバターを生成し、そのアバターが正しい筋トレフォームを実演するモーション指導ができるようになれば、さらにパーソナライズされた体験を提供できます。
技術検証を通じた学びと課題
事業部からのフィードバック
インターンシップ期間中、私たちはDeNAの事業部の方々から貴重なフィードバックをいただく機会がありました。これは、技術的な視点だけでなく、事業やユーザー体験の視点から自身の開発を見つめ直す上で非常に大きな学びとなりました。
たとえば、初めにAIによるパーソナルトレーナーを作るときは、人間のパーソナルトレーナーをAIによって代替するものを想定していました。しかし、フィードバックでは、「人間には出来ないことができて、AIによる価値が示せる」というアドバイスをいただきました。AIが人間を真似ることを考えるのではなく、人間ができないことをAIができるようにするというのはとても重要な観点で、サービスなどのビジネス面だけでなく、研究の時のアイデアにも活かせる考え方だと感じました。
フィードバックを通じて、AIの持つ無限の可能性を考えさせられるような夢のある議論をできてとても楽しかったです。また、まだ明確に見えていなかった研究と開発の違いも、このフィードバックを通してはっきりした気がしました。
インターンシップ全体の学び
今回のインターンシップを通じて、私たちは多くの学びを得ました。
雨宮佳音の学び
私は「大学での研究とは異なる成長をしたい」ということを目的に、今回のインターンシップに参加しました。具体的には、AI技術をサービスに応用する際に必要な、ビジネス的な思考力を身に付けたいと考えていました。結果として、この目的は達成されたと実感しています。
まず、今回設定していただいたテーマは、「画像・動画入出力を伴うAI対話インターフェースの調査・プロトタイプ作成」とかなりぼんやりしており、「どのようなサービスにするか」から検討しました。サービスの決定が4週間の中で1番苦労しましたが、画像や動画など視覚情報を活用する意味の大きい、いい問題設定を考えられたと思っています。今回このテーマを与えていただけたからこそ、ビジネス的な観点についてよく考えることができました。
また、事業部の方からフィードバックをいただける機会を設けていただいたことも、大きな成長に繋がりました。技術のことを一番に考えていると見えなかった問題が、多くあることに気付かされました。実際にサービスとしてリリースしたら爆売れしそうな夢のあるアドバイスもいただき、学びを得たとともにわくわくしました。
増田瞬の学び
私は「大学で研究している画像生成が実際にどのように応用できるのかを知りたいです」ということを目的に、今回のインターンシップに参加しました。このインターンシップを通じて、画像生成の持つ可能性や課題点について知ることができ、有意義な時間を過ごせたと感じています。
まず、今回のテーマを通じて、普段研究で触れている画像合成以外にも、音声合成やリップシンクなどさまざまな技術に触れて、アプリケーションの流れの中に組み込むことができました。また、ブログに書いた以外にも、Few-shotなセグメンテーション手法や、モーション生成手法など、調査の中で幅広い技術に触れることができました。さらに、サービスを見据えて調査をすることで、実用の面ではどのような点が課題となるのかも知りました。
また、インターンシップ全体で社員の方と話す機会を多くいただきました。その中で、社員の皆さんが持つ考えを伺うことができて、将来のキャリアについて考えるヒントをたくさん得られました。
おわりに
DeNAのサマーインターンシップは、私たちにとって非常に刺激的で、あっという間の4週間でした。研究で取り組んでいる生成AIという分野が、社会のためにどのように役に立つのか知りたいと思っていた中で、生成AIの持つ無限の可能性を体感できて嬉しかったです。
このインターンシップ期間中に支えてくださったメンターの皆様には、心より感謝を申し上げます。技術的にも、ビジネス的にも、さまざまな角度で興味深い議論ができたこと、とても嬉しく思います。たくさんのフィードバックの機会を設定してくれたことにも感謝しています。とても学びの多い時間となりました。また、事業部の皆様も、フィードバックをくださりありがとうございました。
最後までお読みいただき、ありがとうございました。


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。