





はじめに
この記事は dbt Advent Calendar 2024 の24日目の記事です。
こんにちは、データ統括部の渡辺です。
今回話す内容は、プロジェクトの開発と同時並行でデータパイプラインの開発を安全に進めるための方法をまとめています。 また、検討した運用でデータサイズがスケールしても問題なくdbt testを稼働できる状態とプロジェクト開発中のデータ検証方法についてご紹介します。
弊社のプロジェクト開発について
弊社では、プロダクトの評価でリリース直後のデータ分析は重要視されているため、プロダクト開発と並行してデータ分析基盤を開発します。 そのデータ分析基盤を持って、リリース時の分析が円滑に実施できるように準備をしています。
体制としては、以下のロールごとにチームのプロジェクトでの責務が分かれています。
| ロール | 責務 |
|---|---|
| PM | プロジェクト全体の進行管理 |
| プロダクトの開発エンジニア | プロダクトの開発 |
| QA | プロダクトの動作が正しいことのテストと結果の報告 |
| アナリスト | ログ、データマートの設計と分析 |
| データエンジニア | データ分析基盤の構築・運用 |
次に、開発と運用のライフサイクルについて説明します。
ライフサイクルは、以下の図のようなイメージになります。
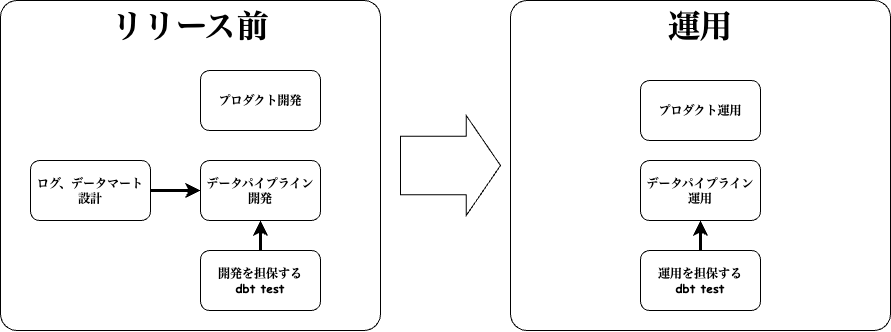
リリース前のフェーズ
プロダクトの開発に並行して、ログとデータマートの設計が行われ、それを実現するためにデータパイプラインを開発します。 開発しているデータパイプラインの処理が正しいことをdbt testを使って担保します。
運用のフェーズ
プロダクトが運用の中で様々なデータを生成し、それをデータパイプラインが処理します。 そのデータ処理が正しいことを運用向けのdbt testで担保します。
dbt testは、以下2つに種別されます。
- リリース前のデータパイプライン開発での正常性の担保
- 実装したロジックにエラーやバグを含まないか
- ソースデータがログ仕様などに準じていること
- 運用で発生した異常を検知し修正を行えるようにする
- ソースデータ由来の異常値をデータ利用者に提供していないか
- 開発段階で想定できていなかったデータのパターンの検知
dbtの標準のテスト機能と拡張パッケージ
本章では、dbtが提供するテスト機能とその拡張パッケージについて紹介します。
dbtが提供する標準のテスト機能について理解されている方は、次章の
テストコードの実装
からご覧ください。
dbtの標準のテスト機能
dbtは標準でデータに対する3つのテスト機能を提供しています
-
singular data test: 任意のSQLファイルに記述した内容のテストです。例えば、整数値が入るカラムに0未満が含まれないようにテストをするSQLを作れます。
-
generic data test: dbtが提供する自動生成するテストです。例えば、任意のカラムでnullのデータを含まないようにするなどのテストをします。
-
custom generic data test: 標準のgeneric data testと同様に自動生成したいテストコードを独自に作れるテストです。
以下が、generic data testが提供するテストタイプです。
| テストタイプ | 説明 |
|---|---|
| not_null | nullチェックをすることでデータの完全性をチェック |
| unique | データの一意性をチェック |
| accepted_values | enumなど特定の配列の値から逸脱しないかチェック |
| relationships | join元とjoin先のテーブルのキーの整合性をチェック |
singular data testとgeneric data test系の違いは、dbt build 実行時にそのモデルの処理後にテストの処理を実行する点です。
singular data testは、個別のテストとして実行されるため dbt build でテストが失敗してもデータパイプラインの実行は継続されます。
generic data testの機能で、dbt buildでモデルの実行はできたがテストに違反するものがあれば実行失敗として以降のパイプラインの処理を止めるようになっています。
それぞれのテストのサンプルを以下に示します。
singular data test
select
a
from
test_table
where
a < 0
test_table の a カラムに0未満があれば違反と判断するテストです。
generic data test
version: 2
models:
- name: test_table
columns:
- name: a
tests:
- unique
- not_null
- name: b
test_table の a カラムがユニークかつnullを含まないことをテストします。
custom generic data test
test macro
{% test less_than_zero(model, column_name) %}
with validation as (
select
{{ column_name }} as even_field
from {{ model }}
where {{ column_name}} < 0
)
select *
from validation
{% endtest %}
models.yml
version: 2
models:
- name: test_table
columns:
- name: a
tests:
- less_than_zero
- name: b
テスト用のマクロを作り、それを models.yml で読み出すことで、独自のgeneric data testを作ることができます。
より詳しい内容については、 dbt testの公式ドキュメント をご参照ください。
severityについて
テストが失敗した場合でも一律にデータパイプラインを止めるのではなく、エラーの重大度によっては許容できる場合があります。 重大度が高くないテストの場合は、severityという設定を用いることで、その重大度の設定を変更することができます。
severityのデフォルト値はerrorです。
dbt buildを実行したときに、severityがerrorのgeneric data test系が失敗したときにそのモデルの処理をエラーだと判別します。
エラーと判別されたモデルに依存するパイプラインの処理を止める仕組みを持っています。
依存する実行を進めてよいと判断できる場合は、warnに設定することができます。
また、severityの設定として違反する件数に応じてエラーのしきい値を変動させることができ柔軟に設定することができます。
以下に、severityを使った設定のサンプルを記述します。
version: 2
models:
- name: test_table
columns:
- name: a
tests:
- unique:
config:
severity: error
error_if: ">1000"
warn_if: ">10"
- name: b
このモデルは、a というカラムにuniqueのテストをしており、設定した値のレコード数がが11 ~ 1000個の間はwarnとして処理して1000を超えたらerrorになるように設定をしています。
また、10件以内の場合にはwarnすら出ないようになります。
より詳細な情報は、 dbtのsevrityのドキュメント を参照ください。
dbtのgeneric data testを拡張するパッケージ
標準のテスト機能に加えて、dbtのパッケージを導入することでさらにgeneric data testの項目を拡張することができます。
以下が代表的なパッケージになります
| パッケージ | 内容 |
|---|---|
| dbt-utils | 便利なmacroやgeneric data testを提供するパッケージ |
| dbt-expectations | Great Expectations package for Python にインスパイアを受けて作ったdbtパッケージでGreat Expectationsが提供するようなデータテストをdbtで使えるようにするのが目的 |
| elementary | データテスト結果のオブザーバビリティを可能にするパッケージでデータの異常性をチェックするgeneric data testを提供 |
テストコードの実装
前章までで説明した機能やツールをベースに、テストコードの実装を進めていきます。 様々なツールがある中での採用ポリシーを定めることでチームで統制の取れた開発中のツール利用ができます。
例として、定常運用するパイプラインの運用と追加実装を考慮し、テストコードの自作を避けてコードの管理コストを減らすような採用ポリシーとして進める場合について説明します。
ポリシーをクリアするために以下の流れで対応します。
- 目的に合致するツールの採用
- プロジェクトの開発段階に合わせたdbt data testの考慮事項の設定
- 考慮事項をクリアするための開発の対応
- ツールで提供されているテストケースの採用
後述するデータの検証は、開発中データの齟齬が無いかを見るためのものでここには適宜singular data testを採用しています。
目的に合致するツールの採用
以下のツールを採用して開発と生データのdata testを行いました。
| ツール | 採用理由 |
|---|---|
| dbt標準のテスト機能 | 標準で備えているテスト機能で対応できる箇所は極力そのテストを採用後述しますが、データの検証はgeneric data testで表現できないような複雑な条件も必要でそこに、singular data testを採用 |
| dbt-expectations | 非常に多くのテストケースを持ち、dbt標準のgenetic data testでカバーできない範囲をこのパッケージを入れることでほぼ解決することが分かり採用 |
| elementary | テストレポートを見やすく出力し共有する機能を使うため採用 |
📝 : dbt-utilsもgeneric data testを提供していますがdbt-expectationsと被るところも多くどれで書けば良いかチームで混乱が生まれるため明示的にdbt-expectationsに寄せるようにしました。
プロジェクトの開発段階に合わせたdbt data testの考慮事項の設定
以降の説明は、前提としてログやデータマート、データアーキテクチャとデータモデリングをある程度設計して実装をするフェーズでの話になります。
考慮する事項
プロジェクトの開発段階のデータパイプラインの開発では、以下を考慮する必要があります。dbt data testもそれに合わせた設定や設計をする必要があります。
- 抽出するデータが出揃っていないまたは、スキーマが確定していない状況
- 開発段階でもあり連携されるデータが必ずしもスキーマ通りになっているか不明
- 開発途中であるためログの実装内容やマスターが変更されることがしばしば発生する
これらのポイントに適切に対応することで、データパイプラインの開発をプロジェクトの進行と並行して進めることができます。
考慮事項をクリアするための開発の対応
上述した考慮事項をクリアするのに以下のイメージの様に対応しました。
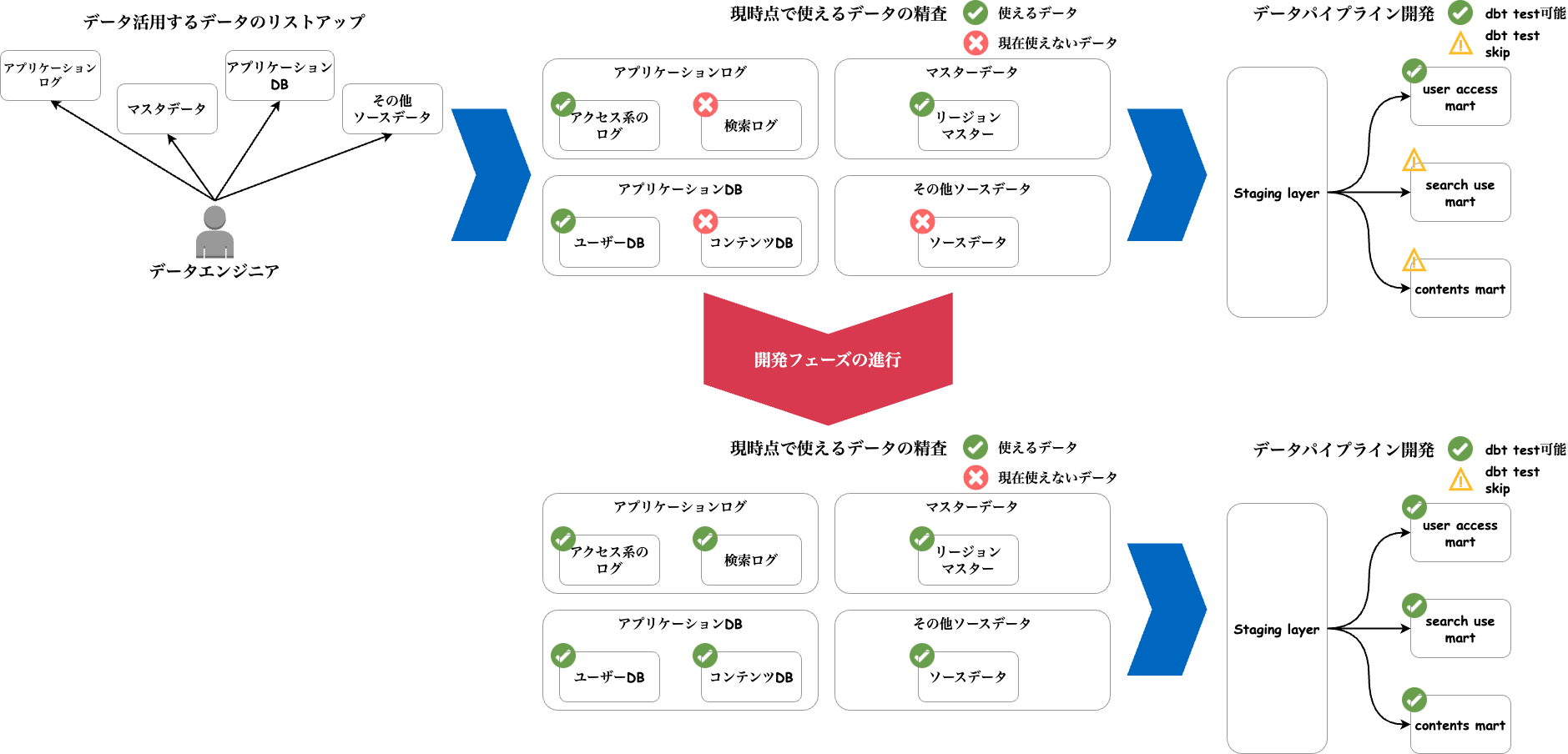
- データエンジニアがデータ活用するデータのリストアップ
- 各データの現状をまとめて使えるものでまだ使えないものをラベリング
- データモデリングのステージング層とマートの実装を行います
- それぞれのモデルは、開発状況に応じてdbtモデルのseverityの設定をします
並行してプロジェクトの開発も進みますので、その進行によってデータパイプラインの開発当時に使えなかったデータが使えるようになります。 その更新に合わせて順次severityの設定を適切なものに更新します。
このようにデータパイプラインの開発をプロジェクトの開発と並行して進めることができました。
ツールで提供されているテストケースの採用
| テストケース | 呼び出し元 | 説明 |
|---|---|---|
| not_null | dbt generic test | nullチェックをすることでデータ完全性をチェック |
| unique | dbt generic test | ユニークになるはずのカラムのユニーク性をチェック |
| accepted_values | dbt generic test | enumや特定の値しか持たないカラムの変化が無いかチェックす |
| relationships | dbt generic test | join先のテーブルのキーの整合性が取れているか |
| expect_table_row_count_to_be_between | dbt_expectations | テーブルに1件でもデータが有るか特にパーティションテーブルのような一部の日付が取れていない場合にこのテストが効く |
| expect_column_distinct_count_to_equal_other_table | dbt_expectations | 他テーブルと行数が同一かをチェックします行数の変化が発生しない結合をしているときに使う |
| expect_column_values_to_be_between | dbt_expectations | 任意の値の範囲にデータが収まっているチェックしますmax_valueを指定しないことでmin_valueの下限だけ設定ができる(逆も然り) |
| expect_table_row_count_to_equal | dbt_expectations | 任意のカラムでgroup by(複数可能)したときに一定の値を超えないかチェックします1個になるように設定して複合ユニークを見る |
| expect_column_values_to_not_be_in_set | dbt_expectations | 任意の値が入っていないことを担保 |
その他のdbt-expectationsのテストを確認したい場合は、 dbt-expectationsのパッケージのページ を参照ください。
定常運用するデータパイプラインにとりあえずテスト入れれば良いか?
データパイプラインを定常運用するのに、使うデータの値やロジックが問題無いか担保するためのテストが必要です。 データパイプラインが扱う全てのデータにテストを適用すると、その分テストのクエリを実行するための実行コストが発生します。
なので、テスト数が多ければ処理すべきテストのクエリが増えるデメリットがあります。 また、大きいサイズのテーブルへのテストもその分の実行コストが発生します。
そのため、定常的に運用するテストは、各チームで運用に影響を与えないかつ担保すべきものをまとめた指針を作るとよいと思います。
例えば、ゲーム事業のデータ分析基盤チームの一部タイトルでは以下の様にしています
- データパイプラインは全てパーティションテーブルとして作りそのテストには必ずパーティションのフィルターを設ける
- テーブル比較のような重いテストは、全てのテーブルに通さずに完全性を必ず担保すべきところにのみ入れる
一方でプロダクトの開発中のデータ検証は、生成されるデータがリリースに向けて実装が仕様書通りになっていることを確認するのが目的です。 このテストのタイミングは、定常的ではなくアドホックに確認するのに実行されるため必要なもの全て確認するのがよいと考えています。
データの検証方法について
次にデータの検証について説明します。 データの検証の目的は、ログやDBのスキーマとデータの中身が仕様書通りになっているか確認することです。 この確認をすることで以降のデータパイプラインの根本的な信頼性を担保します。
データの検証は、実際にログなどが実装されてデータを確認できるようになったタイミングで実施します。
データ検証フロー
以下のイメージのようにデータ検証を進めました。
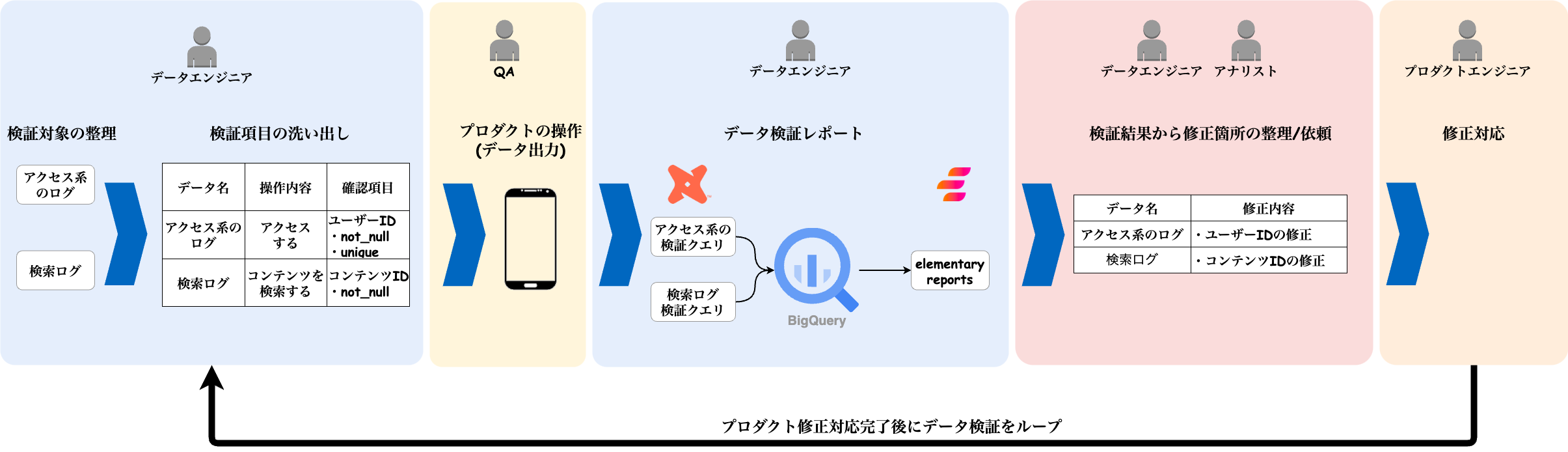
上図のように、データエンジニアがデータの検証を主導して修正のループを回すことでデータの検証と修正を行っています。
また、データの検証結果は、elementaryを使ってレポートを作っています。 以下のようなイメージのレポートが出来上がり、それを適宜アナリストにも確認いただくように対応しています。 これによって、アナリスト側でもテスト結果を把握し、テストが落ちた原因のデータをすぐ特定することができます。
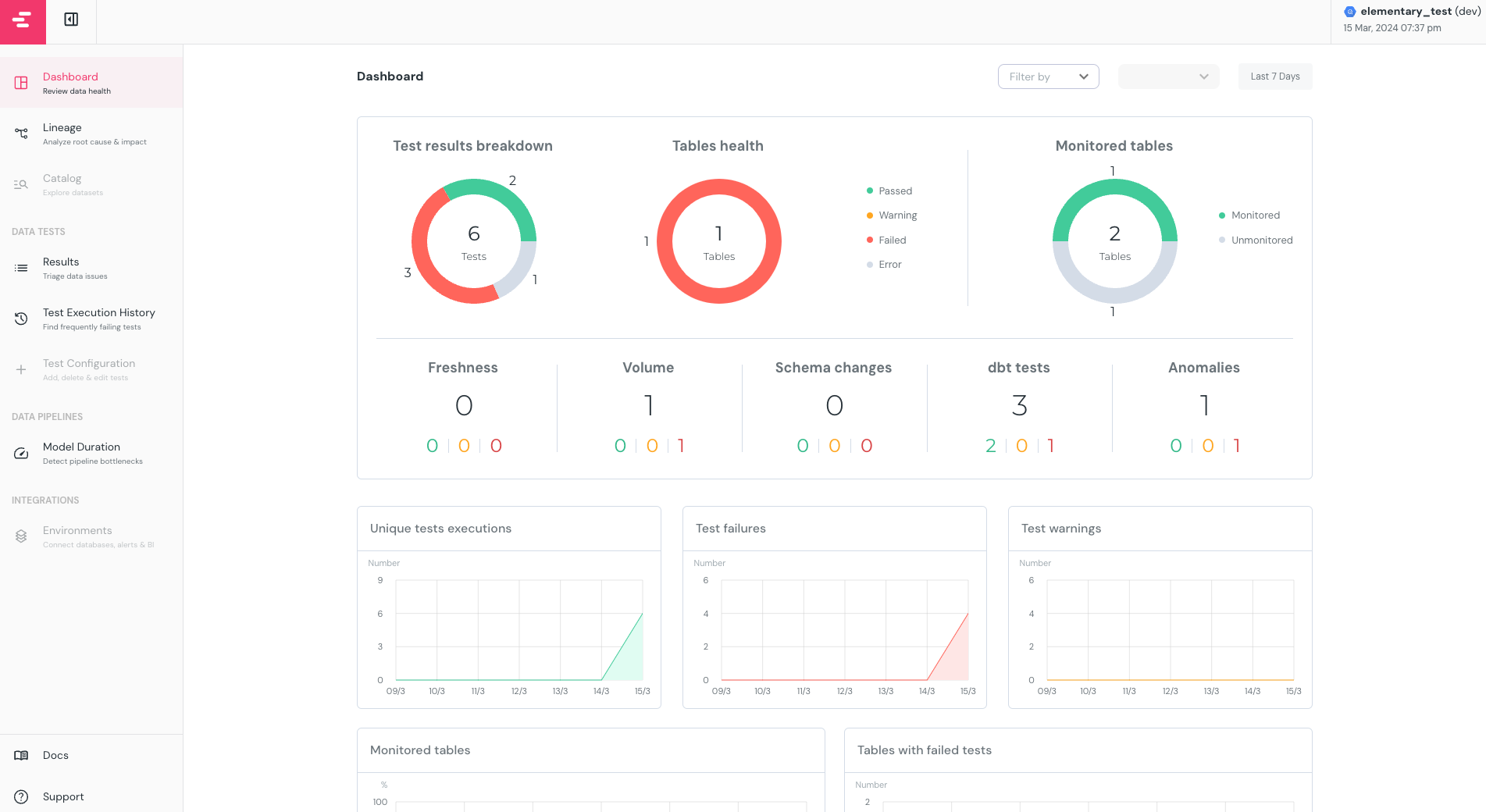
引用元:
https://engineering.dena.com/blog/2024/04/dbt-test-and-elementary/
elementaryのセットアップの詳細とそれを使ったデータ検証の手順については、以下ブログを参照ください。 https://engineering.dena.com/blog/2024/04/dbt-test-and-elementary/
まとめ
以上、プロジェクト開発と並行したdbt testの導入で、データサイズのスケールに耐えるdbt testの運用を実現する方法をご紹介しました。
dbt testは、パッケージを含む幅広いデータテストの方法を提供します。 その機能を扱うケースごとに目的とテストでカバーできることを照らし合わせることが重要だと考えています。
今後ともよりよいテスト方法をアップデートできるようにチームの話し合いと技術検証を進めていこうと思います。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。