





はじめに
こんにちは、IT 基盤部 23 新卒の葉狩と申します。
IT 基盤部は、全社を横断してシステム基盤の運用・管理をしている組織です。 その中でも私は大規模ゲームタイトルのインフラを運用するチームに所属しています。
学生時代の私はインターンや個人の開発において「とにかく動くものを作る」ために新しい技術を使ってきました。 しかし、入社後に振り返ったとき、その根底にどんな仕組みがあるかを深く追求してこなかったことを実感し、浅い理解しかできていなかったことに課題を感じていました。そんな中、配属後にアサインされたタスクで、改めて技術に対し、深く追求して調べることの重要性を学びました。
本記事では、そんな新卒エンジニアが IT 基盤部に配属されて最初のタスクでどんなことに取り組み、何を感じたのかを紹介します。
全体の流れとして、最初にタスクについて詳細に説明した後、 タスクを通して感じた 3 つのことについてお話しします。
配属後最初のタスク – T2D マシンシリーズの調査
タスクの概観
配属直後にアサインされたのは、GCP の T2D マシンシリーズの調査タスクです。 このタスクの目的は「我々の環境に T2D を導入した場合にコスト削減できるかを判断すること」でした。
ベンチマーカーを使用して処理性能を計測し、元々使用していた E2 インスタンスよりもコスト面で優れていると判断したため T2D インスタンスに切り替えました。そして、結果として、Web サーバーのコストを 17% 削減できました。
それでは、次からタスクの詳細について見ていきます。
1. 情報の整理
1-1. T2D と E2 の違い
T2D と元々我々の環境で使用してきた E2 には複数の違いがありますが、ここでは SMT(同時マルチスレッディング)の有効/無効という違いにフォーカスします。
SMT とは CPU のコアを 2 つ以上の論理コアに分割して、それぞれでプロセスを実行できる機能です。
例えばスレッド数が同等の t2d-standard-8 と e2-standard-8 を比較した場合の違いを、 公式ドキュメント を参考に以下の表にまとめました。
| CPU Platform | core/thread | メモリ | SMT | |
|---|---|---|---|---|
| t2d-standard-8 | AMD EPYC Milan | 8/8 | 32GB | OFF |
| e2-standard-8 | Intel Skylake、 Broadwell、 Haswell、 AMD EPYC Milan、 EPYC Rome、 |
4/8 | 32GB | ON |
t2d-standard-8 とは異なり、 e2-standard-8 は SMT の効果によりコア数の倍のスレッドを所有しています。
E2 マシンシリーズはインスタンス作成時に CPU の種類が決まり、利用者側では指定できません。 我々の環境では、Intel Skylake が大部分を占めていたため、本記事で取り扱う E2 の CPU は Intel Skylake として進めます。
1-2. コスト面の比較
コストについても確認します。
我々が元々使っていたのは E2 マシンシリーズの中でも e2-custom-8-12288 という、スレッド数が 8 でメモリの容量が 12GB の カスタムマシンタイプ です。
これに対して T2D マシンシリーズは、カスタムマシンタイプが存在しないため、コア数が同等である t2d-standard-4 マシンタイプを比較対象としました。
| オンデマンド料金1 | core/thread | メモリ | ||
|---|---|---|---|---|
| t2d-standard-4 | $123.36 | 4/4 | 16GB | |
| e2-custom-8-12288 | $160.54 | 4/8 | 12GB |
e2-custom-8-12288 と t2d-standard-4 を比較すると t2d-standard-4 の方が価格は安くなっています。 そのため、パフォーマンス面で e2-custom-8-12288 と同等かそれ以上であれば移行した方がお得です。
[1] us-central1 での月額です。 ↩︎
2. インスタンスの性能実験
情報を整理したところ、t2d-standard-4 は e2-custom-8-12288 よりも安く、コア数やメモリの容量が近いこともわかりました。 しかし、SMT の有効/無効の違いや CPU 自体の違いがあり、パフォーマンス面での懸念が残ります。
その懸念を解消するために、性能実験をしました。
2-1. 実験の目的
実験の目的は 2 つあります。
ひとつめは単純に t2d-standard-4 と e2-custom-8-12288 に性能の差がないかを比較することです。 もし、性能の差がほとんどないか、t2d-standard-4 の方が良い結果になれば移行する判断材料として有用です。
ふたつめは SMT 有効から無効に移行した際の影響について確認することです。 SMT は CPU のコアを 2 つ以上の論理コアに分割し、それぞれでプロセスを実行することで処理性能を向上させる機能です。 Intel では、HT(ハイパー・スレッディング)と呼ばれており、有効時には最大 30% の性能向上が認められると発表されています2。
一方で、計算リソースやキャッシュリソースはコア内の論理コア間で共有するため、それらへのアクセスが増えると、リソースの取り合いが起こります。
このように SMT にはプラスとマイナスの面が存在しますが、この影響が処理性能に対してどう作用するかを明らかにし、SMT 有効である e2-custom-8-12288 から無効である t2d-standard-4 への移行の判断材料としたいと考えました。
[2] Deborah T. Marr, Frank Binns, David L. Hill, Glenn Hinton, David A. Koufaty, J. Alan Miller, Michael Upton. "ハイパー・スレッディング・テクノロジのアーキテクチャとマイクロアーキテクチャ". https://www.intel.co.jp/content/dam/www/public/ijkk/jp/ja/documents/developer/vol6iss1_art01_j.pdf ↩︎
2-2. 実験手法
これらの目的を達成するために実験手法を考えました。
ひとつめの目的に対応する実験手法では各インスタンスの CPU の最大処理性能を計測します。
ふたつめの目的に対応する実験手法では CPU 使用率ごとの処理性能を計測します。 SMT 有効ではリソースの取り合いに起因して CPU 使用率が高い時に処理性能へ影響を与えると考えられるためです。
そして、この 2 つの目的の検証のために CoreMark というベンチマーカーを使用しました。 CoreMark は、特定の処理が 1 秒間に何回行えたかを意味する CoreMark スコアを算出します。 そのため、CPU のスループットを求めることができて、処理能力という観点で 2 つの異なるインスタンスを比較しやすいです。
それでは、実験手法について詳細に説明します。
2-2-1. 最大処理性能の計測
GCP 上でマシンタイプ同士の CPU 性能を比較するために t2d-standard-4 と e2-custom-8-12288 を用意し、この 2 つのインスタンスに対して CoreMark で負荷をかけます。
CoreMark で計測する際には実行するスレッド数をDMULTITHREAD というオプションで指定できます。ここでは、対象となるインスタンスの保持するスレッド数を指定します。
また、ベンチマーク処理の実行回数を ITERATIONS というオプションで指定します。このオプションは実験内で特定の回数を指定することが推奨されており、さらに、CoreMark では 10 秒以上の計測時間が必要なため、今回はその条件を満たす十分に大きな値として 1,000,000 に調整しました。
# t2d-standard-4 の場合
make ITERATIONS=1000000 XCFLAGS='-DMULTITHREAD=4 -DUSE_FORK' REBUILD=1
# e2-custom-8-12288 の場合
make ITERATIONS=1000000 XCFLAGS='-DMULTITHREAD=8 -DUSE_FORK' REBUILD=1
2-2-2. CPU 使用率ごとの処理性能の計測
CPU 使用率ごとの処理性能の計測では、性能の比較実験で使用した 2 つのマシンタイプに加えて、e2-standard-8 の SMT 有効/無効インスタンスを用意し SMT を変数とした対照実験ができる体制を整えました。
そして、前述した DMULTITHREAD オプションを利用してスレッド数を任意に変更することでベンチマーク中の CPU 使用率をコントロールし、CPU 使用率ごとの処理能力を求めました。
# CPU 使用率 50% のときの例
# スレッド数を確認
grep -F 'processor' /proc/cpuinfo | wc -l
8
# ベンチマークの実行
make ITERATIONS=1000000 XCFLAGS='-DMULTITHREAD=4 -DUSE_FORK' REBUILD=1
3. 実験結果の分析
3-1. t2d-standard-4 と e2-custom-8-12288 の性能差の確認
実験結果から t2d-standard-4 と e2-custom-8-12288 の価格と処理性能をまとめると以下のようになりました。
| CoreMark スコア | オンデマンド料金 | core/thread | メモリ | |
|---|---|---|---|---|
| t2d-standard-4 | 117,972 | $123.36 | 4/4 | 16GB |
| e2-custom-8-12288 | 105,428 | $160.54 | 4/8 | 12GB |
結果を見ると、t2d-standard-4 はコストと CoreMark スコアの両面で e2-custom-8-12288 よりも優秀です。移行した場合、パフォーマンスを維持したまま一ヶ月あたりのコストを下げられることが予想できます。
3-2. SMT による影響の検証
もうひとつの目的である SMT による処理性能への影響を確認します。
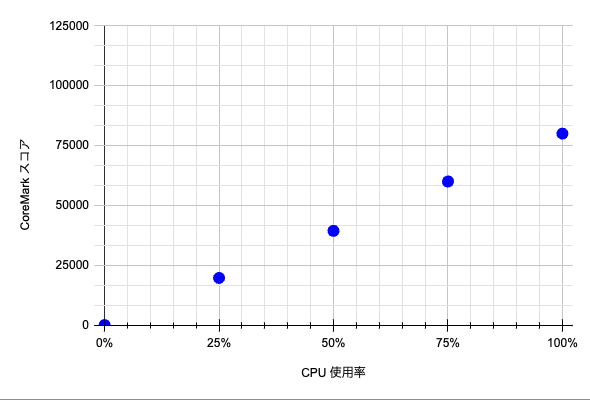
ここでは SMT による影響を正確に確認するために CPU 使用率ごとの処理性能を計測しました。 e2-standard-8 の SMT 有効/無効インスタンスの結果を確認します。
| e2-standard-8(SMT 無効) | e2-standard-8(SMT 有効) |
|---|---|
 |
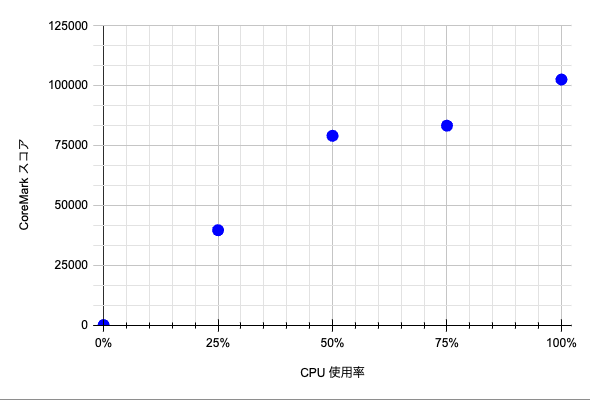 |
グラフを見ると明らかに CPU 使用率ごとの処理性能の推移に違いがあります。
SMT 無効インスタンスでは、CPU 使用率と処理性能は比例しています。 しかし、SMT 有効インスタンスでは、CPU 使用率が 50% までは CoreMark スコアが比例して上昇しそれ以降は緩やかに推移しています。
おそらく、SMT 有効インスタンスでは CPU 使用率が 50% を超えたあたりで計算リソース、またはキャッシュリソースの取り合いが起こり、処理性能の伸びが鈍化したのではないかと考えられます。
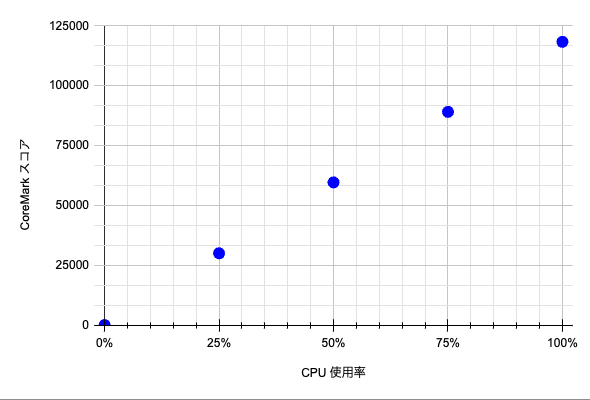
t2d-standard-4 と e2-custom-8-12288 の場合でも確認してみます。
| t2d-standard-4 | e2-custom-8-12288 |
|---|---|
 |
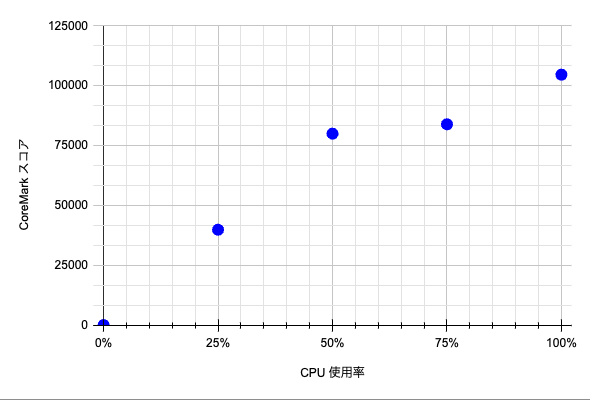 |
こちらも CPU 使用率と処理性能の関係が異なっています。
CPU 使用率 100% 時点では、t2d-standard-4 の方が e2-custom-8-12288 よりも処理性能が高いです。 しかし、一方で、CPU 使用率 50% 以下の状況では、e2-custom-8-12288 の方が t2d-standard-4 よりも処理能力が高くなっています。
3-3. オートスケーリングの閾値についての考察
CoreMark を使った測定の結果、SMT 有効/無効の場合に CPU 使用率ごとの処理性能の推移が異なることがわかりました。
そして、その結果 Web サーバーのオートスケーリングにおける目標 CPU 使用率の閾値を変更する必要があるという考えに至りました。
この閾値を決める際には、Web サーバーが処理可能な最大リクエスト量を常に現在の 2 倍以上に保つという原則のもと、試行錯誤を重ねてきました。(こちらの倍率についてはプロジェクトにより異なりますが、本記事では 2 倍として進めます。)
この考えを持って、CoreMark の実験結果を再度比較します。
| t2d-standard-4 | e2-custom-8-12288 |
|---|---|
|
|
SMT 無効の t2d-standard-4 の場合 CPU 使用率と処理能力が比例して推移しているため、計算上、CPU 使用率が 50% の時に、仮に 2 倍の処理量が来ても耐えることができると考えられます。
一方で、SMT 有効の e2-custom-8-12288 の場合は CPU 使用率と処理能力が比例しておらず、CPU 使用率 50% の時点から 2 倍の処理量を捌くことはできそうにないです。 2 倍の処理量に耐えられるのは CPU 使用率がだいたい 30 - 40% くらいまでに見えます。
このように、e2-custom-8-12288 と t2d-standard-4 では SMT 有効/無効の影響で 2 倍の処理量に耐えられる CPU 使用率の上限が異なります。 これは、要求されるクォリティを確保した上でコストを最適化するようなオートスケーリングの閾値が異なるということです。
通常、閾値を上げると既存のサーバーがより高い CPU 使用率まで使用されることになります。その結果、サーバー数の増加が抑えられてコスト効率が高められます。 しかし、閾値を上げすぎると急な負荷の上昇に対応できず、最悪の場合システムが停止してしまう可能性も考えられます。 そのため、要求されるクォリティを保てるギリギリの高さに閾値を設定することで、コストパフォーマンスの最大化をはかります。
e2-custom-8-12288 で我々が試行錯誤して調整してきた閾値と、今回の実験結果が示す t2d-standard-4 での閾値が異なるため、t2d-standard-4 への移行の際にはオートスケーリングの閾値を調整する必要があると考えられます。
4. 実際に運用しているアプリケーションでの負荷試験
CoreMark を使った測定の結果、SMT が有効/無効の場合に CPU 使用率ごとの処理性能の推移が異なり、その結果、オートスケーリングの閾値が異なることがわかりました。
ただ、一方で、実際に我々が運用している Web サーバーは DB などのミドルウェアとの接続によって I/O 待ちの時間が多いです。そのため、CoreMark のような CPU の計算リソースに対して負荷をかけ続ける「計算特化型」のワークロードとは異なります。
そこで、実際のワークロードでも CoreMark での実験と同等の結果が出るのかを確かめるため、より実際の使用状況に近い条件で負荷試験を行いました。
本来ならば、CoreMark での実験と同じく GCP 環境、かつ、e2-standard-8 で行ったように対照実験をするべきです。 しかし、今回は都合上そのような環境を用意できず、AWS 環境で SMT 無効な C7a と SMT 有効な C6a の 2 つのインスタンスを用いました。
4-1. 実験手法
それでは、実験手法について説明します。
今回の実験では、実際のユーザーの利用を模したシナリオを用意し、同時並列数を増やすことで複数のユーザーが利用している状況を再現し、実際のワークロードに近い状況でアプリケーションのスループットを計測しました。
前述した通り、AWS の環境しか用意できませんでしたが、それでも目的である 「SMT 有効/無効による CPU 使用率ごとの処理性能の推移の仕方が CoreMark と実際のワークロードとで同じかどうかを確認すること」は達成できると判断し実験しました。
4-2. 実験結果
以下が実験結果です。
| C7a.2xlarge | C6a.2xlarge |
|---|---|
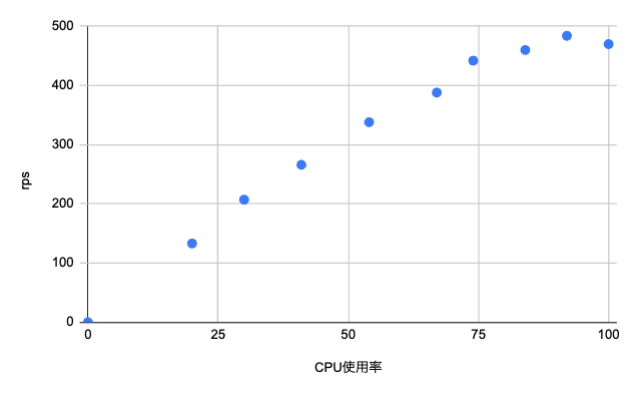 |
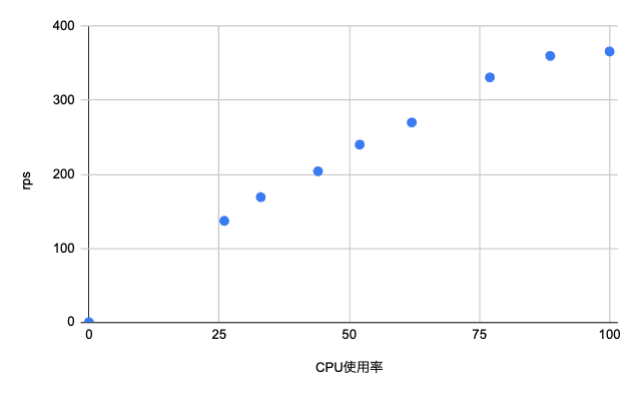 |
CoreMark の計測結果と異なり、SMT 有効/無効による処理性能への影響はないように見えます。
どちらも CPU 使用率 80% ぐらいまでは比例して推移していますが、それ以降は処理性能が鈍化しています。 さらに、2 倍の処理量に耐えられる CPU 使用率の上限についても 30 - 40% の範囲に収まっているように見えます。
5. T2D 導入の成果
実際のアプリケーションでの実験結果から、CoreMark の実験で見られた処理性能の推移の違いは我々のワークロードでは起こりませんでした。 そのため、閾値の調整をしなくても、今までのパフォーマンスを維持したままコスト削減ができるとチームで合意が取れて、T2D インスタンスを我々の環境に導入できました。
結果として、我々の環境での Web サーバー全体にかかっていたコストのうち 17% を削減できて、最初のタスクとしても良い成果が残せました。
最初のタスクを通して感じたこと
1. 最初に研修ではなく実タスクにアサインしてもらえる
驚いたのは、最初に研修タスクではなく、実際のタスクにアサインされたことです。
配属後は覚えることも多く、研修形式のタスクで徐々に慣れていく働き方を想像していました。 しかし、最初に取り組んだ「T2D マシンシリーズの調査」というタスクは研修のために用意されたものではなく、実際にチームのタスクとして管理されていたものでした。
このように抽象度の高いタスクを経験して、メンターに壁打ちをしながら進めていったことで、正解のないタスクに対してどのように取り組むかを考え、自分の足りていない点や目指すべき方向性を再認識できました。 また、同時に、最初のタスクでコスト削減という成果が挙げられたことによって大きな自信にもなりました。
2. 早さよりも正確さを大事にする
早さよりも正確さを大事にするということも感じました。
CoreMark を使った実験結果では、SMT 有効/無効のインスタンスを比較すると CPU 使用率ごとの処理能力の推移の仕方が異なることがわかりました。
しかし、チームに共有して議論する中で「実際のアプリケーションでも同じ結果になるのか」という疑念が湧いてきて、その疑念について検証するために、たくさんの方々の協力のもと「実際のアプリケーションでの負荷試験」を行いました。
結果は先ほど紹介した通り、実際のアプリケーションのワークロードでは、SMT の有効/無効による大きな違いは見られませんでした。
実験結果を鵜呑みにして、実際のアプリケーションでも誤認したまま運用していたら、思わぬ障害につながっていた可能性もあったと肝を冷やした経験でもあり、最後の砦として品質にこだわるという DeNA の一面を実感できた経験でもあります。
3. 技術を深く追求することは楽しい
タスク全体を通して、深く理解することに重きを置ける環境だと強く感じました。 メンターからも「浅い理解に留めず、時間をかけてでも深く掘りきることを意識しながら調査してほしい」と随所でアドバイスをもらっていたため、とにかく 1 つの技術を調べて根底や成り立ちを理解することに努めました。
特に、深く調べて良かったと感じたのは、SMT について調査したときでした。
はじめは、私自身 CPU 周りの知識が全くなかったため、調べていてもどんな機能なのかイメージができませんでした。 しかし理解を諦めることなく、深く掘り切るというアドバイスをもとに一段深く調査して、SMT の根底にある CPU の基本的な構造や動作について学びました。
結果として、SMT を有効にした場合と無効にした場合とでどんなことが起きているのかを現象として捉えることができるようになり、解像度がグッと高まりました。 CPU などの知識がない中でひとつひとつ調べながら学習していくのは大変でしたが、知識が結びついて現象を理解できた時は「楽しい」という気持ちが湧いてきたことが印象に残っています。
まとめ
配属前の私は、深い理解をせずに「とにかく動くものを作る」ために技術を使ってきたことに漠然とした不安を感じていました。 しかし、配属後にアサインされた「T2D マシンシリーズの調査」タスクを通して、技術の表面的な理解を超えて、深く掘り下げることの重要性と楽しさを実感しました。
DeNA の IT 基盤部では、最初のタスクから課題に対して深く掘り進めて調べ上げるという働き方ができます。 技術に対して深く向き合う働き方がしたいと考えている方はぜひ IT 基盤部で一緒に働きましょう。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。