





はじめに
こんにちは、AI技術開発部の加納龍一です。
DeNAはこれまで積極的にゲーム事業を中心に強化学習の事業適用に取り組んできていますが、そんななか気になる論文を目にしたので、論文紹介を兼ねてブログを執筆したいと思います。
論文のタイトルは SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning で、ここでRLとはReinforcement Learning (強化学習) のことを指しています。 強化学習を用いるよりも、GPT-4などの大規模言語モデルを用いて構築されたゲームAIの方が良いものとなったようなニュアンスのタイトルです。
強化学習とは
まず、ゲームAI(ゲームをプレイするAI)を構築する際に用いられる強化学習という技術について簡単に説明します。
前提として、ゲームの仕様は定まっているが、実際にそのゲームをプレイしたユーザーのログは存在していない状況を考えます。プレイログなどがあれば、それらを用いて教師あり学習などを行い次の行動を予測することができますが、今回はそれが難しいような状況でゲームAIを構築する問題設定を考えます。
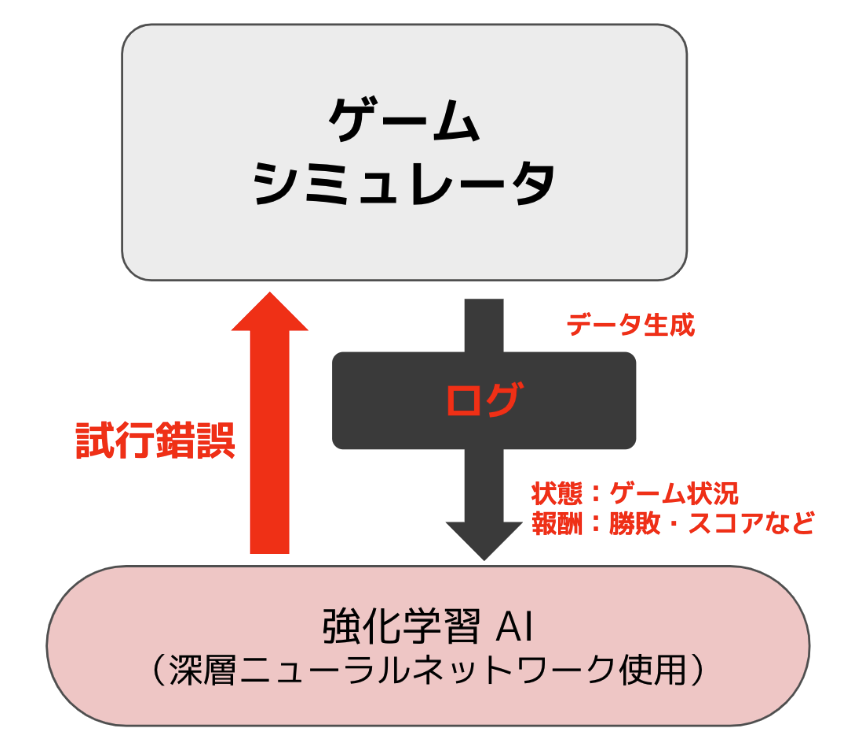
そのようなとき、強化学習では、実際にAIエージェントをシミュレータ上で動かしてみて、そのエージェントの状態や報酬をフィードバックしながら、エージェントを少しずつ良くしていくようなアプローチをとります。表現を変えると、シミュレータと相互作用しながら教師データを取得するところまでを内包した学習方法が強化学習と言えるでしょう。
この手法を用いると、原理的にはゲームシミュレータさえ存在していれば、どのようなゲームに対しても事前知識なしにうまくゲームをプレイできるエージェントを構築することができます。しかし、一方で学習の際には膨大な数のゲームシミュレータとのやりとりが必要となり、それが非常に大変な部分となります。
大規模言語モデルとは
基礎
大規模言語モデルは英語だとLarge Language Modelと呼ばれ、頭文字をとってLLMと表現されることも多いです。大規模言語モデルを語弊を恐れずに表現すると、非常に巨大な機械学習モデルを用いながら、入力の次に続く文章を予測していくような仕組みのことです。

上図は、ユーザーが「私は、りんごを」までの文章(プロンプト)を入力し、そこから先の文章を大規模言語モデルが生成して行っているような例となります。キーボードの入力補完を繰り返し行うようなイメージです。
インターネットなどに存在する大量の文章を収集してこれば、追加でラベルづけなどを行うことなくこのようなタスクを解くための学習用データは収集できます。
代表的な言語モデルとして、GPT(Generative Pretrained Transformer)と呼ばれる巨大な機械学習モデルがあります。ChatGPTなども、これらのGPTと呼ばれる言語モデルを活用している仕組みとなっています。
GPTは進化の途中であり、2023年3月に登場したGPT-4では、入力に自然言語のみでなく画像を使用できるようになったりしています。おそらく今後も、音声などの様々なデータが扱えるように進化していくのでは無いかなと思います。 本論文はGPT-4を使用したものとなっていますが、画像入力を扱うような機能はまだ世界的に公開されていないため、自然言語のみを入力としたモデルを扱っています。
ゲームAIでの活用可能性について
この大規模言語モデルを、ゲームAIへと応用させることができるのでしょうか??
大規模言語モデルをゲームAIへと活用するために最もシンプルに思いつくアイデアは、次の瞬間に取るべき行動を出力してもらい、その出力を実際のゲームに対して適用していくような枠組みとなります。

もしもこの手法が実現できるのであれば、強化学習における課題であったシミュレータとの膨大なの相互作用を通した高コストな学習が必要であるという課題を解決できるかもしれません。
しかしながら、この手法は学習のコストが少ない反面、他の観点で非常に大変なようにも思います。ゲームの状況を事細かに自然言語で記述する必要がありますし、ゲームごとに何をすれば成功に近づくのかなどを外部知識として入力しなければなりません。大規模言語モデルに行動のたびに推論をしてもらう必要もあるので、そのコストも膨大かもしれません。
具体的なアプローチや問題設定を論文内の詳細を説明しながら理解していけると全体像の理解もしやすくなっていくと思うので、具体的な論文内で紹介されている手法の説明に移っていきたいと思います。
大規模言語モデルをゲームAIへ適用する論文の紹介
SPRING: GPT-4 Out-performs RL Algorithms by Studying Papers and Reasoning という論文の紹介を本節では行います。
問題設定
CrafterというゲームAIのベンチマーク用に作成されたゲームを用います。このゲームは非常にシンプル化されたMinecraftのようなゲームとなっており、ダイヤモンドを造ったりゾンビを倒したりなど、アチーブメントが幾つも設定されており、それを目指してキャラクターを動かすようなものとなっております。

CrafterはPythonを使用されたことのある方であれば簡単に自分で遊んでみることもできるので、一度やってみるとイメージも湧くかもしれません。
$ pip install crafter pygame # 必要なライブラリのインストール
$ python -m crafter.run_gui # ゲームを起動
GPT4が学習データを収集した時期にはCrafterはリリースされておらず、完全に言語モデルとしては未知な状態のものです。本ゲームの仕様などは Crafterを発表した論文 にまとまっており、この論文がこれから紹介される手法においても非常に重要な役割を担います。
手法

上図が、論文で紹介されている手法をあらわしています。以下で、ひとつひとつ順に説明していきます。
1. 攻略本からの重要情報の抽出
まず、ゲームの仕様などを、
Crafterを発表した論文
(本節のタイトルではわかりやすく”攻略本”と表現しています)内からGPT-4を用いて抽出してきます。その結果、上図における中央でピンク色がかった部分の様な、ある種ゲームの情報をぎゅっと要約した文章を獲得します。
この際にも、論文のパラグラフごとに「このパラグラフはゲームの仕様やゲームの攻略に関して重要な情報を含んでいますか?」というような質問を行ったりしながら、大規模言語モデルを用いて頑張って重要な情報を抽出してきているそうです。
2. ゲーム情報の抽出
ゲーム画面に対して画像処理技術を適用することで、ゲーム情報を自然言語として抽出してきます。具体的に抽出されるようなゲーム情報の自然言語は以下のようなものです。
You took action noop.
You see:
- grass 1 steps to your west
- tree 6 steps to your north-east
You face grass at your front.
Your status:
- health: 9/9
- food: 9/9
- drink: 9/9
- energy: 9/9
ゲームの時間変化を表すため、現段階の情報とともに一つ前のステップの情報もこのように自然言語で保持するようです。
3. 取るべき行動の決定
1や2のステップで獲得できた情報を元に、実際にGPT-4を用いて次に取るべき行動を決定します。その際にも、単純に一度のGPT-4への問い合わせで完結するわけではなく、何度も何度も対話を行いながら、最終的にひとつの行動を決定するようにします。
具体的には、下に示されているq1からqaまでの9つの質問を、図に示されている様な順序構造に従いながら質問を順次行っていき、最終的にqaのノードでの質問である”Choose the best executable action from above”という問い合わせの出力を用いてゲーム内で行動を起こしていきます。
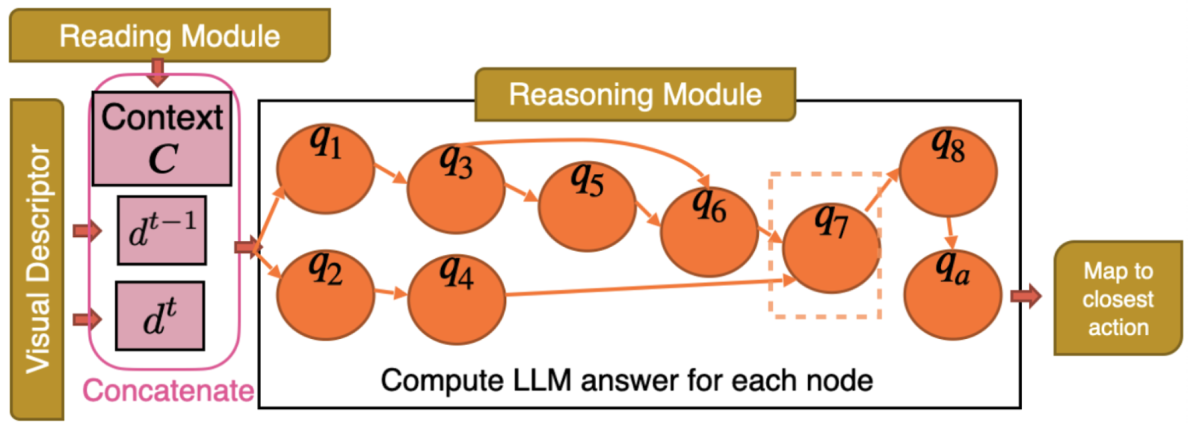
q1: 現在の観察範囲内のオブジェクトをリストアップしてください。それぞれのオブジェクトが提供するリソースとその要件について簡単に答えてください。
q2: プレイヤーが最後に行ったアクションは何ですか?
q3: リスト内の各オブジェクトについて、インタラクションの要件は満たされていますか?
q4: プレイヤーの最後のアクションは成功しましたか? そうでない場合、なぜですか?
q5: プレイヤーが追跡すべきトップ3のサブタスクをリストアップしてください。その優先度を5点満点で示してください。
q6: トップのサブタスクの要件は何ですか? プレイヤーは何から始めるべきですか?
q7: プレイヤーが取るべきトップ5のアクションとそれぞれのアクションの要件をリストアップしてください。全てのアクションのリストからのみ選択してください。その優先度を5点満点で示してください。
q8: リスト内の各アクションについて、要件は満たされていますか?
qa: 上記から最も良い実行可能なアクションを選んでください。
結果
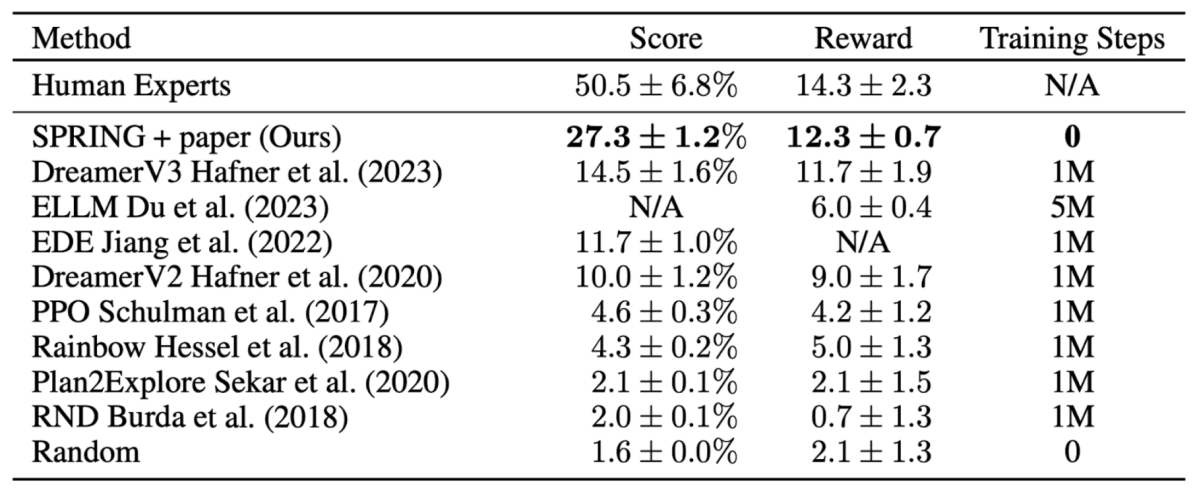
上図は、様々な手法を用いてCraftersに取り組んだ際のスコアやエージェントが得られた報酬(Reward)を示しています。Human Expertsには現状はまだ及ばないですが、 DreamerV3 などの強力な強化学習のアプローチと比較しても、大規模言語モデルを用いた手法は性能が高かったことが報告されております。また、モデルの訓練も行っていないということも強調されていました。
論文内にはひとつひとつの工夫ごとにどれだけの影響があるかを調査しているセクションもあります。長くなってしまうので詳細は割愛しますが、やはり攻略本(論文)の情報を使用することが非常に重要なようです。具体的には、上表におけるRewardが提案手法では12.3であるのに対して、攻略本(論文)の情報を使用することを辞めた場合には0.5まで減少してしまうことが報告されていました。ランダムな行動以下ですね。また、GPT4ではなくGPT3.5を使用すると12.3から3.3までRewardが落ちるということも報告されており、大規模言語モデルそのものの性能も非常に重要になってくるという示唆が得られているようでした。
強化学習と大規模言語モデル活用の比較
前節で示されたような結果は興味深く、一つユニークな進化の方向性として非常に重要になってくるのではないかなと思います。 一方、推論に要する時間や事前知識の有無など、前提条件に違いがある部分もあるため、全てにおいて強化学習に優っていると言えるような状況ではないと個人的には思います。例えば論文内では詳細は述べられていませんでしたが、おそらく推論に要する時間やコストなどは非常に大きなものとなってしまうことが予想されます。
そこで、強化学習を用いる場合と、今回の論文で示されている様に大規模言語モデルを扱う場合とでのメリットおよびデメリットをまとめてみようと思います。
強化学習を活用したゲームAI構築
- メリット
- ゲームシミュレータさえあれば、どんなゲームでも事前知識なしに学ぶことが可能
- 基本的に行動ごとに一度モデルの推論処理を行えばよい
- デメリット
- 学習に非常に時間がかかる
大規模言語モデルを活用したゲームAI構築
- メリット
- モデルの学習が不要 (事前に学習されているものを使用する)
- デメリット
- ゲームを攻略するための事前知識が必要
- ゲームの状態や事前知識などを全て自然言語で表現する必要がある
- ひとつの行動を得るためにも、巨大なモデルで多段の推論処理を行う必要がある
改めてこう見てみると、両者はメリットやデメリットも大きく異なっており、得意な部分と苦手な部分は明瞭に分かれています。事前知識を何らかの形で活用することが可能なゲームにおいては、ひょっとしたら大規模言語モデルの活用は今後も価値があるものとなっていくかもしれません。
一方、Crafterのようにシンプルなゲームであったため今回は大規模言語モデルの活用における弱点はなんとか乗り越えることができているのかなと思いますが、より複雑なゲームとなる場合には、より難易度も上がってくるのかなと思います。このように困難も多数存在していますが、例えば画像や音声など、言語以外にも多様な入力を扱うことのできる大規模言語モデルが民主化された頃には、ゲーム状態を自然言語で記述する手間というのはかなり削減される様になるのではないかなと思います。
強化学習と大規模言語モデルは排他なものではないため、うまく組み合わせたような手法も出てきたりしているようです。今回は扱いませんが、また別の機会で扱えると良いなと感じています。
おわりに
いかがだったでしょうか。今回紹介した論文以外にも似た観点の手法は多数提案されてきており、大規模言語モデルの応用はまさにいま非常に注目されている分野なのかなと感じています。
大きな推論のコストなど、学習が不要となる代わりに様々な弱点も持ち合わせる手法ではありますが、近年の科学の発展の中で、思っているよりも近い将来に今回紹介したようなアプローチが実用レベルになっていくような未来もあり得るのではないかなと思います。


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。