





こんにちは!k-jun です。IT基盤部にて大規模ゲームのインフラに携わっているインフラエンジニアです。この記事では、モニタリングコンポーネントの Prometheus、Grafana、Alertmanager を冗長化した事例をご紹介させて頂きます。
モニタリングとは
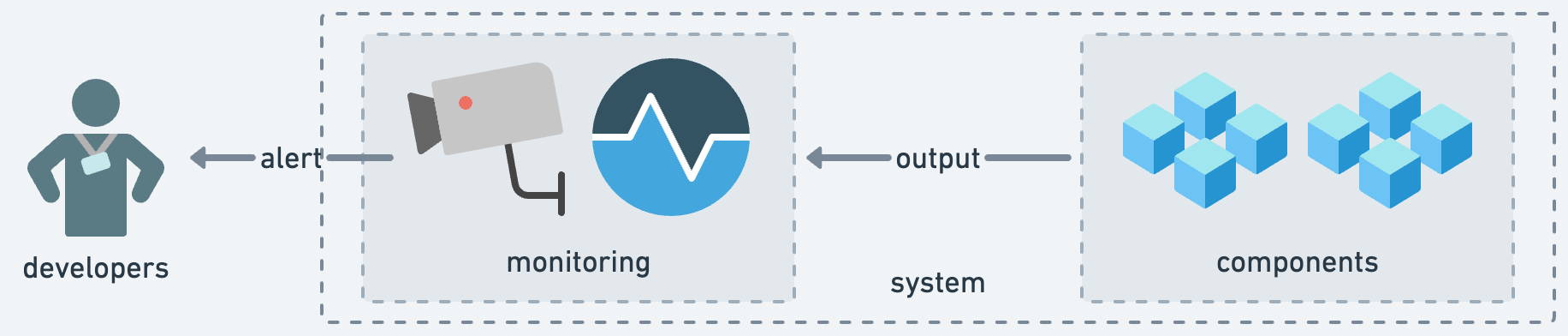
モニタリングとは、システムやコンポーネントの振る舞いを観察し出力をチェックすることです。システムはコンポーネントで構成され、各コンポーネントの状態は絶えず変化しています。モニタリングとは、この刻一刻と変動する状態を、出力を通して可能な限り明らかにするという試みそのものです。
モニタリングの責務は主に 2つ、状態の可視化と異常の検知です。状態の可視化とは、コンポーネントから出力されるログ・メトリクスを元に、状態把握の手助けとなるダッシュボードを提供することです。異常の検知とは、システムがある閾値を超えて好ましくない状態へ陥った際に、システムの開発者へ自動で通知することです。
モニタリングはこの 2つの責務により、多くのシステム上で重要な役割を果たしています。我々のシステムも例外では無く、モニタリング無しではシステムとして成り立たないと言っても過言ではありません。
冗長化のニーズ
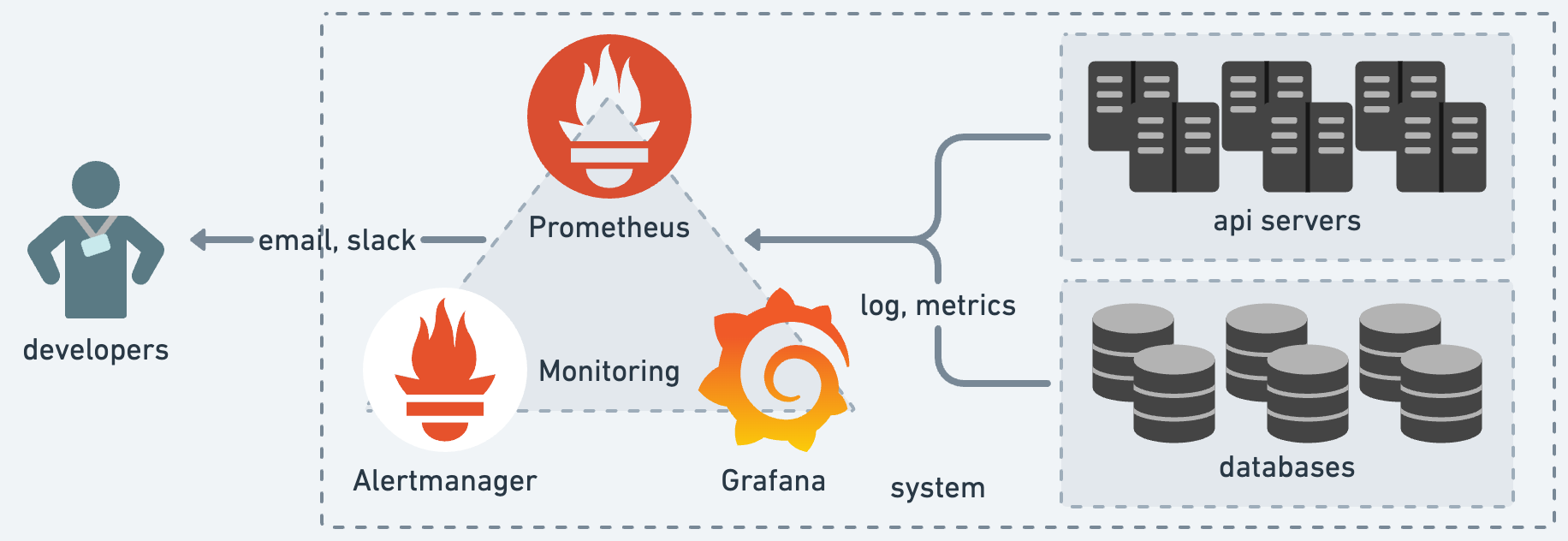
モニタリングコンポーネント冗長化の目的は、より確実なシステムの安定稼働です。我々の運用するシステム上では、モニタリングコンポーネントとして Prometheus、Grafana、Alertmanager の 3つを採用しています。これら 3つのコンポーネントに、我々はメトリクスの保存・可視化、アラートの検知・発火の 2つを委ねています。
メトリクスの保存・可視化は Prometheus と Grafana によって賄われ、問題の原因究明・キャパシティプランニングに役立ちます。過去の現象をメトリクスから確度高く推測する、未来に起きうることを正確に予測する。いずれもモニタリングの大切な役割であり、システムに欠かせません。
アラートの検知・発火は Prometheus と Alertmanager によって実現され、システムの継続的監視という形で重宝します。監視はまさに我々の目であり耳であり、システムからの悲鳴を日々アラートとして届けてくれています。この機構は開発・運用の両面で品質担保の根底を担っており、常時正常に稼働することが求められます。
メトリクスの保存・可視化、アラートの検知・発火の 2つは、システムを守る城壁です。モニタリングコンポーネントの非冗長化は、この城壁に亀裂が入っていることを意味します。このため今回、より堅牢なシステムを目指し、モニタリングコンポーネントの冗長化に乗り出すこととなりました。
冗長化の手法
Prometheus、Grafana、Alertmanager いずれのコンポーネントも、仔細は違えど大筋として状態を複製・移動するという方針を取っています。冗長化の本質は、コンポーネントレベルでの状態管理をアーキテクチャーレベルへ引き上げることです。このため、各コンポーネントで管理していた状態を複数台で共有する、状態管理を他コンポーネントへ移動するといった手法を用いています。
冗長化 in Alertmanager
Alertmanager はアラート発火を司るコンポーネントです。Prometheus 側で検知されたアラートを、ルーティングに従ってシステムの開発者へ通知します。状態として過去の発火履歴とサイレンス設定を持っており、これに応じてアラートの重複排除・通知制御を管理しています。
Alertmanager の冗長化方針はクラスター化です。これは公式ドキュメントにて推奨されている方法であり、避ける理由もありません(2023-08-06 時点)。クラスター化した Alertmanager は、発火履歴とサイレンス設定を共有し始め、冗長性を持ったコンポーネントとして動作するようになります。
https://prometheus.io/docs/alerting/latest/alertmanager/#high-availability
Alertmanager の冗長化手法を説明するにあたって、全体把握のため図を作成しました。① から ③ の順に変更を実施しており、最終的に 2台の Alertmanager で冗長構成を取っています。
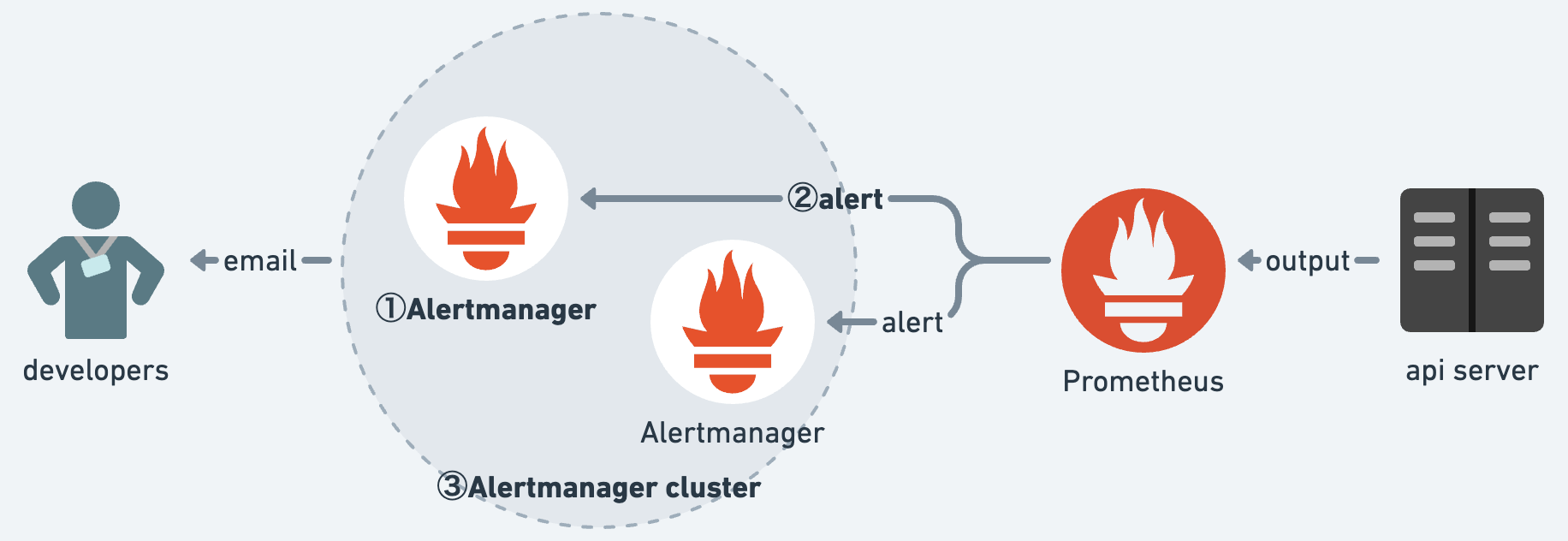
① まずは、Alertmanager を増設します。特段変更する箇所は無く、既存と同じ設定で構築するのみです。ここからは、新しく作成したものを 新 Alertmanager、既存のものを 旧 Alertmanager と呼ぶことにします。
② 続けて Prometheus 側の設定を変更し、Prometheus アラート検知の連絡先に新 Alertmanager を追加します。新 Alertmanager が加わったことにより、どちらかの Alertmanager が機能不全に陥ってももう片方が補完しアラートを通知します。
# prometheus.yml
...
alerting:
alertmanagers:
- static_configs:
- targets:
- alertmanager1:9093
+ - alertmanager2:9093
...
③ 最後に Alertmanager をクラスター化します。Alertmanager が増えるに伴い、発火履歴とサイレンス設定の状態も 2つずつになります。クラスター化はこれを 1つへ統合し、アラートの重複発火・サイレンス設定の反映漏れを防いでくれます。
$ alertmanager
--config.file=/etc/prometheus/alertmanager.yml
+ --cluster.listen-address=0.0.0.0:9094
+ --cluster.peer=alertmanager1:9094
+ --cluster.peer=alertmanager2:9094
モニタリングコンポーネントの一角、Alertmanager をクラスター化により冗長化しました。Alertmanager は機能の独立性が高く冗長化の難度も低いため、最初の冗長化コンポーネントとして適しています。残りのコンポーネントも Grafana、Prometheus と影響度と難度の低い順に冗長化を進めていきます。
冗長化 in Grafana
Grafana はメトリクスの可視化を司るコンポーネントです。Prometheus 側で収集・保存されたメトリクスを、ダッシュボードを用いて可視化します。状態としてダッシュボードを構成する JSON を保持しており、デフォルトでは Grafana ローカルディスクの SQLite へ格納されています。
Grafana の冗長化方針は、状態管理の譲渡です。Grafana はダッシュボード JSON の保存先として SQLite の他に MySQL が用意されています。外部の MySQL へ状態管理が譲渡されると、Grafana 自体は非状態管理化し複数台構成が取れるようになります。
https://grafana.com/docs/grafana/latest/datasources/mysql/
Grafana の冗長化手法を説明するにあたり、Alertmanager と同様に図を作成しました。①、② の順に変更を実施しており、最終的に 2台の Grafana で冗長構成を取っています。
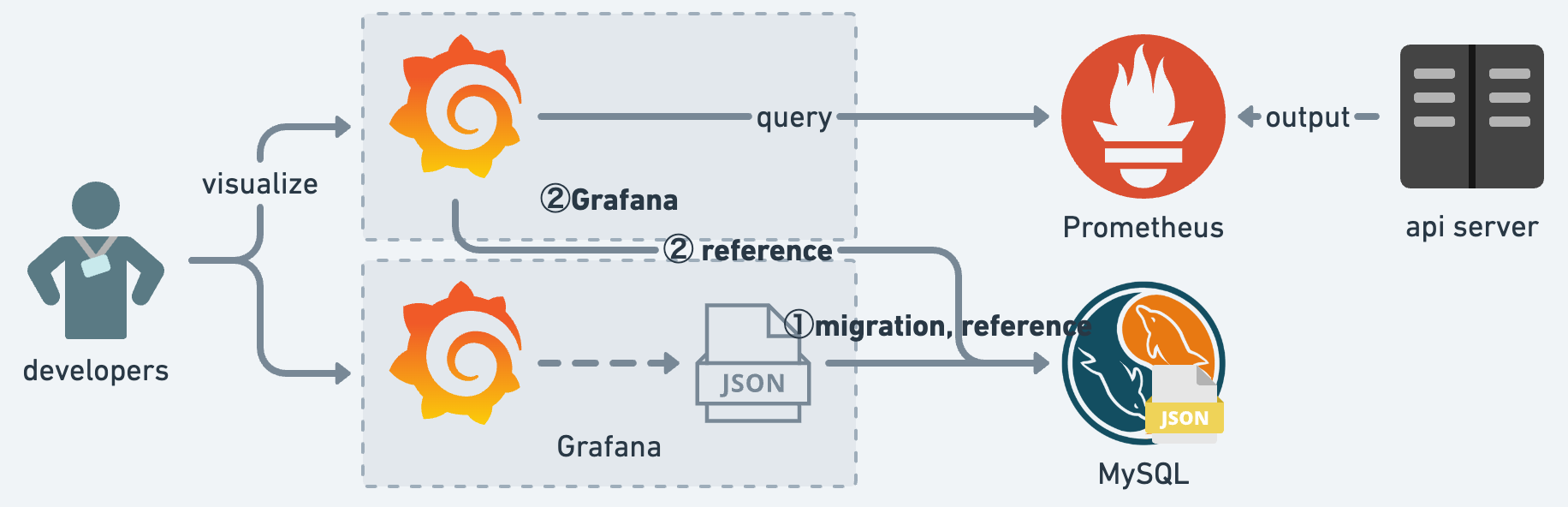
① 最初に取り組むのは、保存場所の移動です。Grafana ローカルディスクの SQLite から MySQL 用のダンプファイルを作成し、MySQL へリストアします。なお、SQLite から MySQL の変換は database-migrator を参考にしています。MySQL へリストア後は Grafana の設定ファイルを書き換え、ダッシュボード JSON の参照先を MySQL へ向けています。
https://github.com/grafana/database-migrator
# grafana.ini
...
-;type = sqlite3
-;host = 127.0.0.1:3306
-;name = grafana
-;user = root
+type = mysql
+host = mysql:3306
+name = grafana
+user = root
# If the password contains # or ; you have to wrap it with triple quotes. Ex """#password;"""
-;password =
+password = root
...
② 残すは、新しく Grafana を構築するのみです。Alertmanager と同様に、詳細設定は既存のものと全く同じにしておきます。これにより、ダッシュボード JSON が 2つに分裂することを防ぎ、1つの JSON で管理・運用することが出来るようになります。
モニタリングコンポーネントの 2つ目、Grafana を状態管理の譲渡により冗長化しました。ステップ数は Alertmanager より少ないものの、SQLite から MySQL への変換箇所が煩雑のため 2番目に冗長化しています。最後に影響箇所が最も大きく、慎重を期す Prometheus を冗長化していきます。
冗長化 in Prometheus①
Prometheus はメトリクスの保存、アラートの検知を司るコンポーネントです。システム内のエージェントからメトリクスを回収し、時系列データの TSDB 形式でローカルディスクへ格納しています。保持している状態は、まさにこの TSDB 形式のメトリクスデータです。
Prometheus の冗長化方針は多少複雑です。というのも、公式ドキュメントにて提案されている手法には、2点ほど懸念点があるためです(2023-08-08 時点)。提示されているのは Prometheus を複数台用意する手法であり、これによりアラートの検知に関しては冗長性が確保されます。加えて、Alertmanager は重複発火を防ぐ機構があるため、同じアラートが複数発火することもありません。
Can Prometheus be made highly available?
Yes, run identical Prometheus servers on two or more separate machines. Identical alerts will be deduplicated by the Alertmanager.
https://prometheus.io/docs/introduction/faq/#can-prometheus-be-made-highly-available
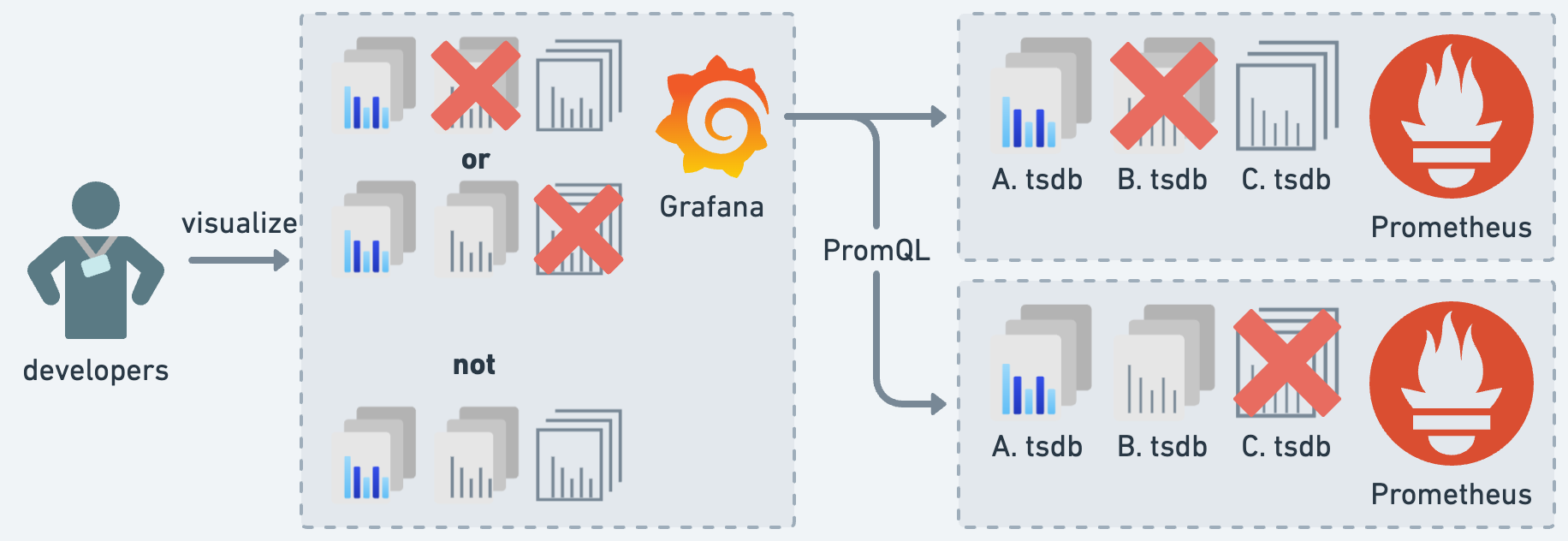
懸念点の 1つ目は、メトリクスの可視化です。Grafana のデータ参照は、バランシングはあると言えど 1度に 1台の Prometheus から行われます。このため、いずれの Prometheus にもメトリクスデータに欠損が生じていると、常に不完全なメトリクスデータを可視化することになります。これは Grafana にメトリクスデータの統合参照の機能が存在しないため発生する懸念です。
懸念点の 2つ目は、メトリクスの保存です。Prometheus は TSDB をローカルディスクへ格納する都合上、大きなディスク容量を要求し続けます。また、何らかの要因で Prometheus がローカルディスクごと復旧不能になると、保存されていたメトリクスデータを全損します。これは Prometheus にメトリクスデータの永続性が無いため発生する懸念です。
これらの懸念点を解消した上で冗長化を進めるべく、Prometheus の冗長化方針として Thanos を導入することにしました。
Thanos とは
Thanos とは Prometheus 用の拡張ツールセットであり、CNCF インキュベーションプロジェクトの 1つです。Thanos は Prometheus の冗長化を目的に設計されており、複数の Prometheus への統合参照、メトリクスデータの永続性などにより冗長化を達成します。
今回扱う Thanos コンポーネントは Thanos Sidecar 、 Thanos Store Gateway 、 Thanos Query 、 Thanos Compactor の 4つです。Thanos コンポーネントは全て冗長化可能であり、Store API でコンポーネント間の通信をしています。Prometheus、Grafana、Thanos コンポーネントの関係性を以下の図に示しました。
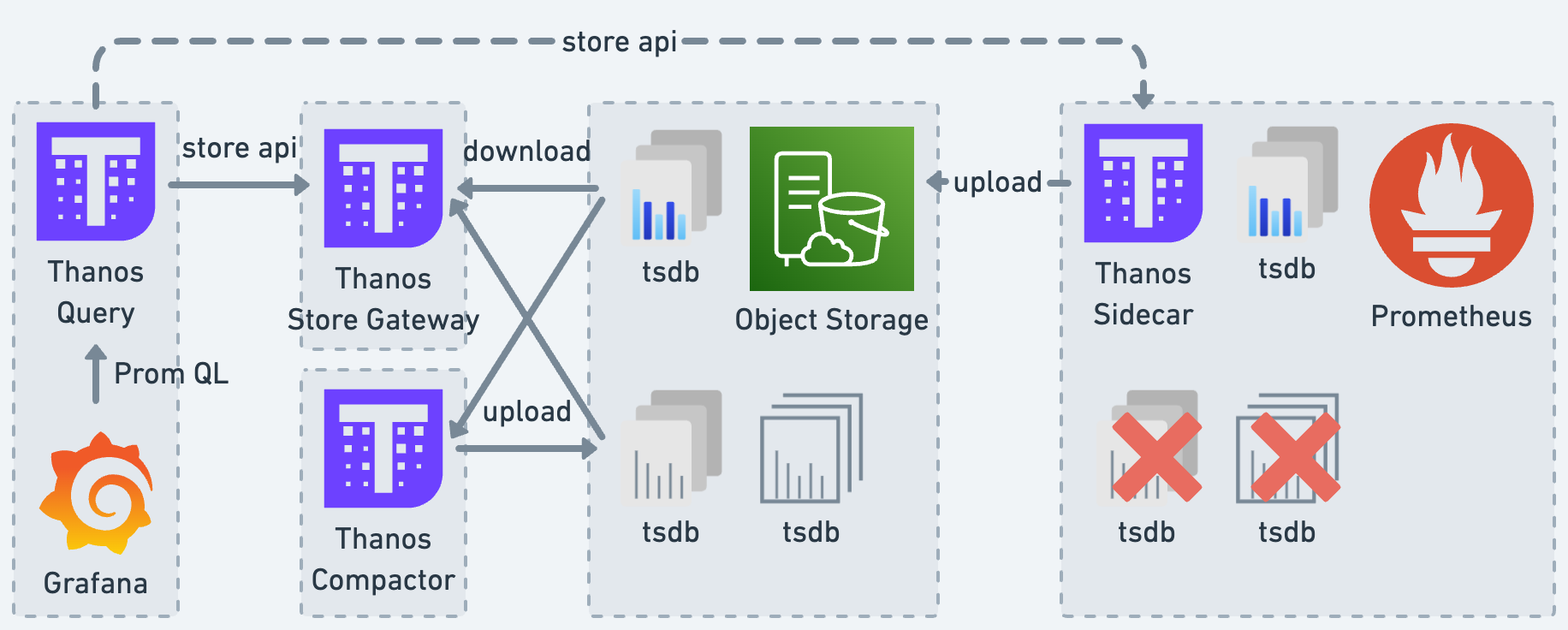
Thanos Sidecar は、メトリクスデータをアップロードするコンポーネントです。Prometheus と同じサーバー上で動作し、吐き出された TSDB をオブジェクトストレージへアップロードします。これらに加えて、 TSDB 化される以前の Prometheus のメモリ上に存在するメトリクスデータへの参照も担っています。
Thanos Store Gateway は、メトリクスデータを参照するためのコンポーネントです。オブジェクトストレージへアップロードされた TSDB を、要求に応じてダウンロードし引き渡します。また、ダウンロードされた TSDB は、キャッシュされ以降の参照で利用されます。
Thanos Query は、メトリクスデータの統合参照のためのコンポーネントです。複数の Thanos Sidecar や Thanos Store Gateway へメトリクスデータを問い合わせ、得られた結果を 1つの時系列データとして統合し Grafana へ提供しています。
Thanos Compactor は、メトリクスデータを圧縮するコンポーネントです。Thanos Sidecar がオブジェクトストレージへアップロードした TSDB は、時間とともに保存料金・検索時間が増えていきます。これを軽減するため、Thanos Compactor が TSDB のダウンサンプリングを行い、データ量を削減しています。
冗長化 in Prometheus②
Thanos の導入により、Prometheus は先の懸念点を払拭しより高度な冗長性を得ます。メトリクスの可視化は、Thanos Query の統合参照により欠損箇所を補填したグラフが閲覧可能に。メトリクスの保存に関しても、外部のオブジェクトストレージを利用することで、ローカルディスクとは比べ物にならない永続性を確保しています。
Prometheus の冗長化手法を説明するに伴い、これまでと同様に図を作成しました。① から ④ の順に変更を実施しており、最終的に 2台の Prometheus で冗長構成を取っています。
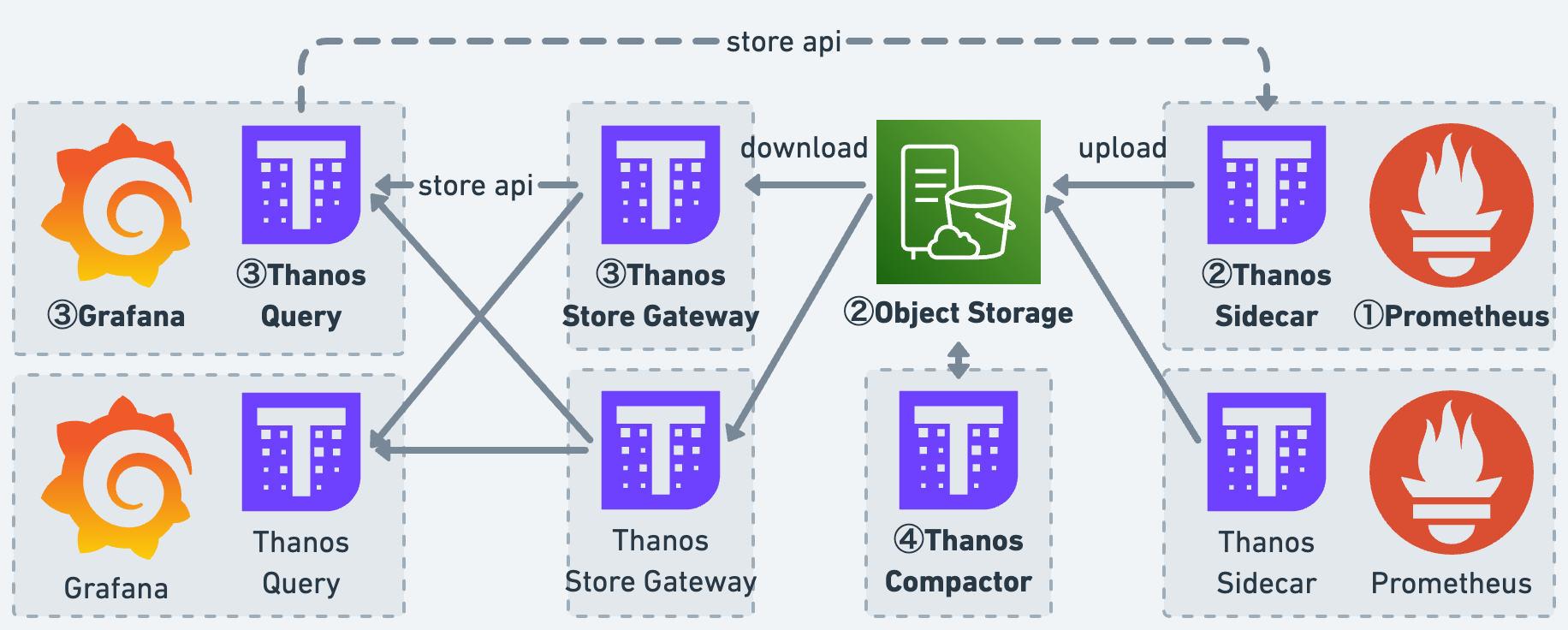
① まずは、Prometheus の設定を Thanos に合わせて編集します。External Label は、Thanos が個々の Prometheus を混同しないためであり、Prometheus ごとにユニークな値を設定します。なお、External Label は Alertmanager の重複発火の要因ともなるので、アラート検知時には取り除きます。更には Thanos Sidecar のアップロード最中に TSDB が圧縮されないよう、Retention も無効化しています。
https://thanos.io/tip/thanos/storage.md/#external-labels
# prometheus.yml
global:
...
+ external_labels:
+ replica: xxx
alerting:
+ alert_relabel_configs:
+ - regex: replica
+ action: labeldrop
...
$ prometheus
--config.file=/etc/prometheus/prometheus.yml
--storage.tsdb.path=/prometheus/tsdb/
+ --storage.tsdb.max-block-duration=2h
+ --storage.tsdb.min-block-duration=2h
② 次に、Thanos Sidecar を導入します。S3/GCS などのオブジェクトストレージを用意し、TSDB をアップロードすることで永続性を確保します。これにより Prometheus は、メトリクスデータの保存と Grafana の参照からある程度開放されます。
③ 続けて、Thanos Store Gateway と Thanos Query を導入します。Thanos Query は直近のメトリクスデータは Thanos Sidecar から、それ以外は Thanos Store Gateway から取得しています。加えて、Grafana のデータソース参照先も Thanos Query へ変えておきます。
④ 最後に、Thanos Compactor を導入します。メトリクスデータをダウンサンプリングすることで、Thanos Query からの検索がある程度高速化します。仕上げとして Prometheus の TSDB 保持期間を狭め、これまで蓄積されていた TSDB を削除します。
$ prometheus
--config.file=/etc/prometheus/prometheus.yml
--storage.tsdb.path=/prometheus/tsdb/
--storage.tsdb.max-block-duration=2h
--storage.tsdb.min-block-duration=2h
+ --storage.tsdb.retention.time=3d
モニタリングコンポーネントの本丸、Prometheus を Thanos 導入により冗長化しました。これにて、モニタリングに関連する3つのコンポーネント全てを冗長化しました。
冗長化の効果
モニタリングコンポーネントの冗長化は、システム全体、及び我々のチームに対していくつかの効力を発生させました。これらは不可抗力的に発生したもの、狙っていたもの、副次的に発生したものなどに分けられますが、概ね肯定的な効果です。
不可抗力的な効果は、技術的負債の返済です。今回は冗長化の前段階準備として、様々なことを調整しています。具体的には、各サービスの開発・検証・本番環境における Prometheus、Grafana、Alertmanager のバージョンの最新化と共通化。MySQL の CentOS から Ubuntu への OS 更新と EOL が切れた MySQL からのアップグレード。他にも特定環境のみに導入されていた VictoriaMetrics の撤廃など。正直なところ、これらのほうがよっぽど大変だったのは内緒です。
狙っていた効果は、前述の通りシステムの安定稼働です。モニタリングコンポーネントが冗長化したことにより、Grafana のメトリクス欠損、Prometheus のディスク容量管理など多くのことから開放されました。運用面の取り回しも良くなり、Prometheus の柔軟なスペック変更、OS 更新作業などが気軽に行えるようになっています。
副次的な効果は、Prometheus への監視集約です。Prometheus の安定性が向上したことにより、チーム内で Prometheus に対する信頼性が向上し新 Exporter の作成、監視項目の移行などが進みました。今後は Nagios や Cron に分散している他の監視スクリプトも Prometheus へ集約することを目指しています。
もちろんこれら効力の裏側には、アーキテクチャーの複雑化、インフラコストの増額などのデメリットが潜んでいます。これらを克服するべく、本ブログにて各コンポーネントの解説やインスタンスタイプの調整などを行っています。結果として、コストの維持とシステムのクオリティを両立し、QCD を体現する良い事例となりました。
おわりに
本記事では、モニタリングコンポーネントの Prometheus、Grafana、Alertmanager を冗長化した事例をご紹介しました。それぞれの冗長化手法、特に Thanos については Grafana Mimir 、 VictoriaMetrics など代替手法も多く、今の状態が最善であるとは言い切れません。それでもなお、疑いの目を持ちより良いシステムを目指して改善すること、迅速に変化し続けることこそが答えへ向かうための最善手だと僕は信じています。
我々 DeNA は技術により難題を解決し利用者に Delight を届けるべく、新技術に絶えず挑戦し続けています。
私たちは、DeNA グループ全体のシステム基盤を横断して管理しているインフラ部門に所属しています。こちらでチームの紹介をしていますので、ぜひご覧ください。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。