





この記事では 23 新卒、24 卒内定者が開発に参加した『 日比谷音楽祭公式おさんぽアプリ 2023 』 の開発の裏側をクライアント編、サーバ編の 2 回に分けてご紹介します。 今回はサーバ編をお届けします。
サーバチームを代表しまして、24 卒内定者の西川が本稿の執筆を担当します。
この記事の概要
- サーバチームの技術的挑戦
- ほとんどがインターンで構成されるチームの運用について
- 予想できない負荷への事前対策と本番での対応
日比谷音楽祭 2023 とおさんぽアプリ
『日比谷音楽祭公式おさんぽアプリ 2023』 (以下、おさんぽアプリ) は 2023 年 6 月 2~4 日の 3 日間で開催された 「 日比谷音楽祭 」のために開発されたアプリです。 日比谷音楽祭は親子孫3世代、誰もが気持ちのよい空間と、トップアーティストのライブやさまざまな質の高い音楽体験を、 無料で楽しめることを目的としたフリーでボーダーレスな音楽イベントです。
参加者が音楽祭を楽しめるように、おさんぽアプリでは以下のような機能が提供されました。
- 事前抽選で取得したチケットをアプリ上で登録し、入場に使用する機能
- 当日抽選がある公演の抽選に応募する機能
- イベントに関する情報の提供
- GPS を使用して公園内のマップ上に現在地を表示する機能
- 公園内に設置した QR コードを使用したウォークラリー機能
サーバチームについて
おさんぽアプリの開発においてサーバチームは API サーバだけでなく、 管理者用の Web アプリケーション(フロントエンドのデザインから)など、モバイルアプリ以外の全てを担当しました。
おさんぽアプリの開発は数年単位で続く事業ではなく、数ヶ月で企画からリリースまでを行うプロジェクトです。 そのため、様々なチャレンジができる場でもあります。 そこで、DeNA としては日比谷音楽祭の成功に加えて、開発の過程でどのような取り組み・チャレンジ・学習ができたかも重要視しています。
今年度のサーバ実装では、昨年度に実装された資産を活用可能な部分が多かったため、サーバチームでは技術的な挑戦を多く行いました。 昨年度も開発に参加した先輩方を中心に、昨年の反省を踏まえて導入した方が良い技術や使ってみたい技術を採用しました。 特に、昨年度は当日抽選の実行時の負荷により API のレスポンスが悪くなるというパフォーマンス面での問題が発生したことから、 パフォーマンスの改善や可用性を向上のための挑戦を多く行いました。
サーバサイドのアーキテクチャ
ここからはサーバチームの取り組みについて説明します。 はじめに、サーバサイドのアーキテクチャを以下に示します。 余談ですが、この図は excalidraw で作成されています。 先輩が使っているのを見て可愛いなと思い自分も使い始めましたが、便利なので最近は専ら excalidraw を使用しています。
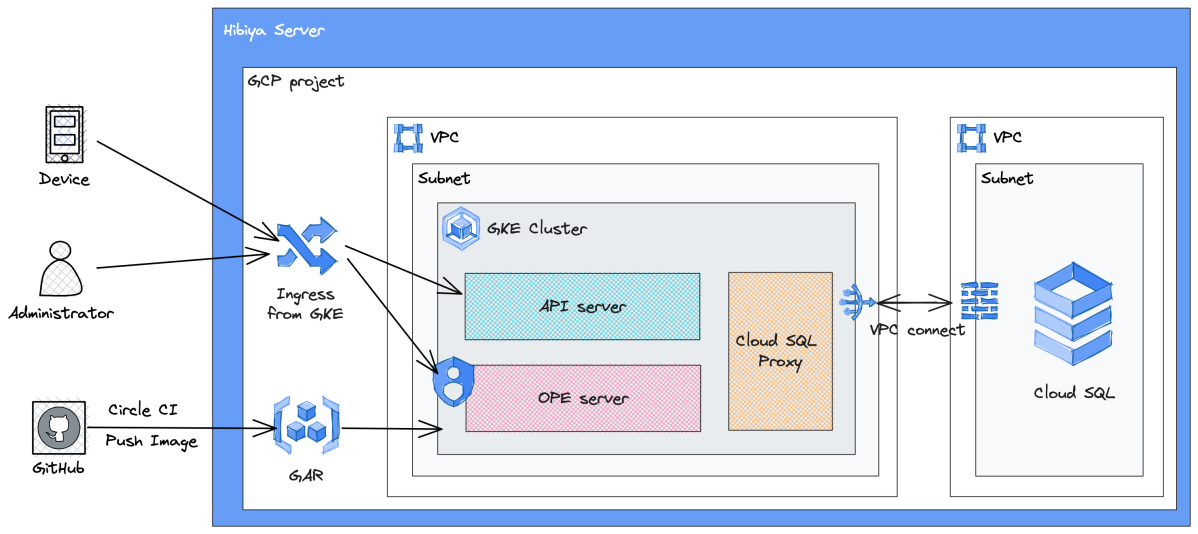
- インフラは Google Cloud 上に構築されている
- API サーバと管理者ツール (以下、OPE) のサーバは GKE 上で稼働している
- データベースは Cloud SQL
- GKE から Cloud SQL へのアクセスのために Cloud SQL Proxy を使用している
- CircleCI を使用してコンテナイメージを Artifact Registry にプッシュし、GKE にデプロイする
- Identity Aware Proxy (IAP) を使用して OPE へのアクセスを制限する
サーバチームの技術的挑戦
ここからはサーバチームの技術的挑戦として採用した技術の良かった点や失敗した点について紹介します。
Google Kubernetes Engine (GKE)
API サーバと OPE サーバが稼働する環境として Google Cloud 上の Kubernetes (k8s) サービスである Google Kubernetes Engine (GKE) を使用しました。 GKE を採用した理由には以下のようなものが挙げられますが、最大の理由は可用性の向上です。
- pod の死活管理を行い、正常稼働している pod の数を維持
- pod 数のオートスケーリングにより負荷に対して柔軟にリソースを管理
- GKE の Autopilot モードでは Node の管理が不要
GKE は強力なツールで、おさんぽアプリの開発に導入して良かったと感じていますが、 中長期的に運用するには運用コストの高さが懸念になります。 その理由は Kubernetes のバージョン更新が速く、それに伴い GKE も更新されていくからです。 GKE のマイナーバージョンのサポート期間は 14 ヶ月なので、それを見据えた運用が求められます。 おさんぽアプリの開発は数ヶ月単位の単発プロジェクトだったため、 技術的挑戦として GKE を導入することができましたが、 もしも、中長期的なプロジェクトだったならば GKE の導入は難しかったかも知れません。
GraphQL dataloader
昨年度の実装を踏襲し、サーバは GraphQL による API をクライアントに提供しました。 GraphQL とは Web API のためのクエリ言語です。 比較的新しい技術であり REST よりも学習コストは高いと言えますが、 開発手法やパフォーマンスの面で以下のようなメリットがあります。
- スキーマ駆動開発が可能
- 一回のリクエストで複数のリソースを取得することが可能
- クライアントが必要なリソースのみを返すことでオーバーフェッチを防止
一方で、GraphQL はその性質上、 N+1 問題が発生しやすいです。
N+1 問題を防ぐための方法にはいくつかの選択肢があります。
昨年度のサーバ実装では SQL で JOIN 句を使用して事前に必要なリソースを全てフェッチする方針を採用していました。
しかし、この方法では、JOIN するテーブルが増えることによる SlowQuery の発生や、
SQL 文が複雑になることによってコードの可読性が低下する問題がありました。
より GraphQL ライクな方法として dataloader を使用した方法があります。
dataloader は再帰的に取得されるリソースへのリクエストをキャッシュしてから、
バッチ処理として遅延読込することにより、N+1 問題の発生を防止します。
dataloader を使用することで、昨年度のサーバ実装で問題となった JOIN 句による SlowQuery の発生や可読性の低下が軽減されました。
開発チームには GraphQL に初めて触れるメンバーが多く、GraphQL のキャッチアップから始めたため dataloader の理解のための時間もかかりましたが、一度理解してしまえば GraphQL、dataloader 双方の恩恵にあずかることができ、 開発体験としても非常に良かったと感じています。 おさんぽアプリにおける dataloader の導入については開発チームに 23 卒内定者として参加された葉狩さんが YAPC::Kyoto でも 発表 されています。
Server-Side Rendering (SSR)
OPE (管理者ツール) は、我々エンジニアが日比谷音楽祭当日に管理者として PC から操作する Web アプリケーションです。 OPE には Server-side Rendering (SSR) 用フレームワークである Remix を採用しました。 SSR とは、サーバサイドで HTML を動的に生成して、レスポンスとしてクライアントに返す仕組みです。 サーバーサイドで予めデータを View に埋め込んで HTML を生成するようにすると、クライアント側の負担が軽減され、他の API 通信を行う必要も無くなります。 (一方でサーバの負荷は上昇しますが…)
ここから、SSR を採用した経緯とその功罪について説明します。 前提として、OPE は以下のような機能を提供します。
- チケット使用数などの各種モニタリング
- 当日抽選の実行
- アプリ上で表示する情報の管理
- アプリ利用者への通知発行
- エンジニア以外の日比谷音楽祭スタッフが閲覧する画面
OPE に SSR を採用した理由には以下のようなものが挙げられます。
- API サーバと OPE サーバの分離
- API サーバと OPE のバックエンドが同じサーバで稼働すると、どちらかの負荷が上昇した際に他方に影響を与える可能性があります。 昨年度は抽選実行時の負荷により API のレスポンスが遅くなったという経緯を踏まえ、API サーバと OPE を違う pod 上で稼働させることは必須でした。
- 今年度の設計では、API サーバと OPE の管理者画面、スタッフ画面の全てで認証方法が異なりました。 3 つの認証を同じサーバ上に実装するのは煩雑ですが、別サーバにすることで煩雑さを軽減できます。 特に今年は管理者画面の認証をインフラ側で実装したため、OPE サーバに実装した認証はスタッフ画面の BASIC 認証のみとなり、実装をスッキリさせることができました。 (昨年度は API サーバがほぼ完成してから OPE の認証を追加実装したため、かなり苦労したそうです。)
- リポジトリ管理コストの低減
- 上述のように、API サーバと OPE を分離するだけならば、CSR でも問題ありません。 しかし、OPE のバックエンドとフロントエンドでそれぞれ新たにリポジトリを用意すると、管理しなければならないリポジトリが 1 つ増え、管理コストが増加します。 そのため、フロントとバックエンドを同じリポジトリで管理するできる SSR が選択肢に上がりました。
ポピュラーな SSR 用フレームワークには Next.js などが存在します。 Next.js と Remix は、GET と POST のハンドラーが分けられる点や、Nested Routes が使える点で異なります。 Remix 使用経験のあるメンバーが少ないという点で、技術的挑戦の一環として Remix が採用されました。
SSR 自体に関する問題点は特になかったのですが、OPE サーバと API サーバの分離により データベースへのアクセス経路が OPE サーバと API サーバの 2 箇所になったことで苦労したことが 2 点あります。
1 点目は氏名の暗号化処理についてです。 個人情報保護の観点から、チケット情報に含まれる参加者の氏名は暗号化してデータベースに格納される必要があります。 TypeScript で実装されている OPE と Go で実装されている API サーバの両方で暗号・復号処理を実装する必要があり、 双方で使用しているライブラリの仕様を確認しながら実装しなければならない点で苦労しました。
2 点目は時刻情報の扱いについてです。 開発がある程度進んだタイミングで、OPE で表示される時刻とアプリ上で表示される時刻が一致していない問題が発覚しました。 時刻のズレが 9 時間単位だったので、どこかしらでタイムゾーンの設定に失敗していると見当をつけました。 各サーバのタイムゾーンや ORM 仕様を確認しながら対応することができましたが、 サーバが 1 つ増えたことにより問題を切り分けていく際の煩雑さが大きく増したように感じます。 そもそもデータベースのスキーマを決める時点で DATETIME 型ではなく TIMESTAMP 型を使用していればこのような問題は発生しなかったと後悔しています。
Rust で書いた CLI ツール
負荷試験を行うためのダミーデータの生成などを簡単に行うための CLI ツールをインフラチームで作成しました。 CLI ツールには以下の機能が求められました。
- 負荷試験で使用するダミーデータを生成する機能
- 生成したダミーデータや、本番用のデータを Cloud SQL に投入する機能
- 負荷試験を行う機能(可能なら)
CLI ツールはプロダクトには直接的に関係しないため、経験者が誰もいない挑戦をしようと考え、Rust で書くことを決めました。 結果として、所有権によるメモリ管理など、Rust にユニークな機能への理解が深まったので、技術的挑戦という目的を達成する事はできました。 個人的には、Rust のエラーハンドリングの方法が気に入りました。 もっと理解を深めて、今後の開発でも Rust を選択肢に入れることができるようにしたいと考えています。
一方で、技術選定という観点からは失敗がありました。 Rust 向けの負荷試験ライブラリに良いものがなかったことです。 Rust を使用することが決定してから、負荷試験のために使用できそうなライブラリの選定を始めました。 調べてみると、良さそうな選択肢がなく、かろうじて見つけた drill というツールを使用して実装を始めましたが、上手く使いこなせず、CLI ツールに負荷試験機能を実装することを断念せざるを得ませんでした。 最終的に、 vegeta という Go 言語で書かれたツールを使用して負荷試験を行いました。 目的の機能を実装するために使用可能なライブラリが存在すること、そのライブラリがどの程度有効なのか、 などの調査を技術選定の段階でもっとやっておくべきだったと反省しています。
リリースまでに苦労したことや反省点
ここまでは、サーバチームの技術的挑戦とその結果について述べてきました。 ここからは、それ以外の部分で開発中やリリース直前の対応で苦労したことや反省点について説明します。
ほとんどインターンで構成されるチームでの開発
おさんぽアプリの開発チームの特異な点としてチームのほとんどが学生のインターンで構成されていることが挙げられます。 年齢の近い人ばかりのチームでの開発は常にわいわいしており、とても楽しかったです。 一方で、それぞれに学校等の予定があり、稼働時間がバラバラな状況下でチーム内で情報や進捗の共有を行うことには苦労しました。 毎日の朝会と毎週の定例 MTG を設定していましたが、その曜日に稼働できない人には上手く情報を共有できないなど、 チーム内でプロジェクトに対する知識量に大きな乖離が生じていたと感じています。
チーム運用についての問題が顕在化し始めたタイミングで、アジャイルの進め方について全員で MTG を行いました。 2 時間やっても終わる気配がなかったことからも、当時のチーム運用に各々思うところがあったようです。

MTG を踏まえてスプリントレビューなど、チームの運用を改善するための取り組みを始めました。 結局廃止されてしまった取り組みも多々ありましたが、 期限があるプロジェクトの中でもトライアンドエラーでチームの運用を見直していけたのは良かったと思います。 4 月以降、23 卒の先輩方が入社に伴いチームから抜けて一気に人員が減少してしまいましたが、 なんとか開発チームが回ったのは、このタイミングでちゃんと話し合いをできたからだと感じています。
QA や脆弱性診断で指摘された事項への対応
アプリのリリース前に QA や脆弱性診断が行われ、仕様書と一致していない点や脆弱性に関して指摘されます。 重大な指摘に対して対応するのはかなり厄介で、場合によっては対応に数日かかります。 そのため、指摘事項に対して、対応に必要な工数やユーザへの影響度合いを鑑みて優先度をつけて対応する必要があります。 工数の観点から対応を諦めた指摘事項も多々ありましたが、 その旨を PdM と議論するような経験は学生で個人開発をしていると絶対にできない経験だったので新鮮でした。
我々が指摘された内容の中でもクリティカルな例をいくつか挙げます。
- GraphQL において DoS 攻撃される可能性がある
- 概要: GraphQL の dataloader を使用して、イベント会場情報とプログラム情報の双方向で再起的にリソースを取得することが可能であったため、 必要以上のリソースを取得するように改竄されたリクエストを多数送信されるとサービスが停止する可能性があった
- 対応: GraphQL のクエリ複雑度に制限を科すことで対応した
- ブルートフォース攻撃される可能性がある
- 概要: プレイガイドの事前抽選で取得したチケットをアプリ上で登録する際、チケット番号などの情報を使用するが、 該当 API に回数制限がないため、ブルートフォース攻撃が可能な状態であった
- 対応: 新たに Redis を用意してユーザごとに一定時間内の API へのリクエスト数を記録し、 一定回数以上リクエストしたユーザにはエラーを返すようにして対応した
- トランザクションの並列実行によりバグが発生する
- 概要: 複数端末で同時に同じ内容のリクエストを送信すると、トランザクションが 2 重で実行されてデータベースの整合性が崩れ、 それぞれの端末での表示内容がおかしくなる
- 対応: こちら の記事を参考に実装を修正することで対応できた
リリース直前かつ、人的リソースが限られる中で予想できていない指摘に対応するのは骨が折れましたが、 サポートエンジニアとして参加してくださっていた社員の方々の手助けもあり、なんとかやり切ることができました。 ログ周りの整備など、バグの原因を素早く発見できるような仕組みを早めに構築しておけば指摘事項への対応をもっと迅速に行うことができたと感じています。
事前の負荷試験と当日の対応
昨年度のおさんぽアプリでは、当日抽選実行時の負荷により API のレスポンスが悪くなるという課題がありました。 今年度の日比谷音楽祭は昨年度よりも参加者が増える見込まれていたため、 事前から負荷試験を行い、本番でサーバが安定稼働するように対策を練りました。
事前に実施した負荷試験
昨年も開発に携わった先輩方からの知見を踏まえて負荷試験を行うべきシチュエーションを以下のように想定し、負荷試験を行いました。
- DB への書き込みが発生する API、特に当日抽選応募のための API へのリクエストが集中する場合
- 当日抽選実行中に他の API へのアクセスが発生する場合
昨年のアクセスログ等が残っていなかったので、具体的に何 rps のスループットを出せばいいのか分からない状態から負荷試験が始まりましたが、 昨年の抽選応募者の総数等からある程度の目標値を算出し、スケーリングの方針を決めました。 結局のところ、 DB へのアクセスに使用するパラメータ等の微調整を行なったぐらいで、 残りは GKE の Horizontal Pod Autoscaling (HPA) に任せる方針を取りました。
当日の負荷と緊急での対応
事前に想定したシチュエーションでの負荷に対しては問題なくサーバを稼働させることができましたが、 想定できていなかった部分で API のレスポンスが悪くなってしまいました。 負荷によりアプリの通信エラーが発生したのは当日抽選実行後、自動で発行される抽選結果発表通知が発行された時でした。 ユーザが抽選結果を確認するためにアプリを開いたことで、チケット情報を取得する API へのリクエストが集中し、通信エラーが発生しました。 もともと、通知発行直後にアクセス数が増加することは把握できていたのですが、読み出し系の API については負荷試験を行なっていませんでした。
当日抽選は、6/3 に 1 回、6/4 に 2 回の計 3 回行われます。 上述の問題は 6/3 の抽選実行時に発覚しました。 昨年のデータから 6/4 の方が抽選応募者数が多くなることが予想されており、同じ問題が再発することは確実だと考えられたため、 次の抽選までに対策を講じることにしました。
メトリクスのダッシュボードを見ながら対応方針を議論し、最終的に以下のような方針を取りました。
- 通知発行の前に手動で pod 数を増やす
- リクエスト数の瞬間的な増加に HPA が追いつけないので手動での対応に切り替えました。
- 抽選実行と通知発行の間に数分の時間を開ける
- 事前に告知されている抽選実行の時刻に結果を確認するユーザと抽選結果発表の通知を見て結果を確認するユーザがいるはずなので、 抽選実行から通知発行までの時間を開けることでアクセスを時間的に分散させることを狙いました。
対策の結果、6/4 に行われた 2 回の抽選では API サーバが問題なく稼働することができました。 特に 2 つ目の抽選実行と通知発行の時間を空ける対策の効果はメトリクスに顕著に現れました。 下の図は最も抽選応募者が多かった Hibiya Dream Session 3 の抽選実行から抽選結果発表までの間のアクセス数を時系列で示したものです。 17:40 に抽選を行い、その 3 分ほど後に抽選結果発表の通知を発行しました。 抽選実行と結果発表通知の発行とで 2 つのピークがグラフに綺麗に現れています。
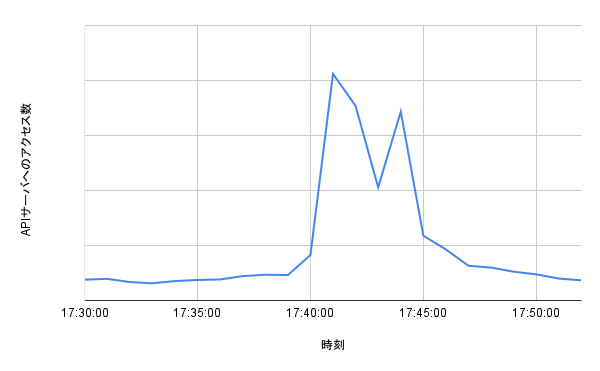
反省点としては、pod 数を手動で増強した際にかなり余裕をもたせた増強を行ったのでコストがかかってしまったことが挙げられます。 次回の日比谷音楽祭では pod 数の具体的な数値についても事前の負荷試験を通じて勘所を探ることで、 当日の負荷を捌きつつもコストを抑えることができるのではないかと考えています。 加えて、アクセス数やリソース使用率等のログを記録することができたので、 次回以降はより具体的な目標を持って負荷試験を行うことができると期待されます。
おわりに
おさんぽアプリの開発には例年、内定者が参加しています。 これまで関わってきた先輩方の遺した資産のおかげで、今年度は上手くやれたのかなと思います。
大きな裁量が与えられている環境での開発は非常に充実した経験になったと感じています。 また、23・24 卒内定者という歳の近いメンバーで議論したりアドバイスをしあいながらの開発はとても刺激的で楽しかったです。 個人的には、サポートエンジニアやプロダクトマネージャーを始めとする社員の方々が我々学生を対等に扱ってくださったことが印象的で、 DeNA Quality の “「こと」に向かう” や “発言責任、傾聴責任” ってこーゆーことなんやなと実感しました。
内定者としてこのような貴重な経験をさせていただき、本当にありがとうございました!




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。