





はじめに
こんにちは。インフラエンジニアの松浦です。 IT 基盤部に所属し、全世界向けのゲームタイトルのインフラ運用を担当しています。
先日あるプロジェクトで Google Kubernetes Engine (以降 GKE) でインフラを構築することになり、そこで GKE のコスト削減のために、 ノード 数削減すなわち Pod 集約率の向上 (1台のノードで出来るだけ多くの Pod を動かす) に取り組みました。
今回はそこで行ったことをご紹介します。
概要
今回のプロジェクトでは、 Kubernetes (以降 K8s) の Horizontal Pod Autoscaler 使用してアプリケーション Pod をオートスケールさせます。 このため、スケールアウト・スケールイン後 (Pod の増減により クラスタオートスケーラー (以降 CA) がノードを増減させた後) でも、Pod 集約率が高くなっていることをゴールとします。
Pod 集約率は、ノード単位で下記のように定義することにします。 $$ Pod 集約率 = \frac{リソースリクエスト}{割当可能なリソース}$$
Pod の設定の一つに リソースリクエスト がありますが、これは Pod 内の各コンテナで必要とする CPU とメモリ等のリソース量を指定したものです。 K8s スケジューラ はこのリソースリクエストを元に、どのノードにどの程度 Pod を配置するかを決定します。
GKE コンソールからクラスタ>ノードと辿ると、ノード単位での リクエストされた CPU・割当可能な CPU 等が確認できます。これらの値が近いほど Pod 集約率が高いと言えます。
Pod 集約率の変化もわかるように、下記のような Monitoring ダッシュボードを作成して確認していきました。
ダッシュボードサンプル の Terraform コード
resource "google_monitoring_dashboard" "sample_dashboard" {
dashboard_json = <<EOF
{
"displayName": "${local.sample_dashboard.display_name}",
"mosaicLayout": {
"columns": 12,
"tiles": [
{
"height": 4,
"widget": {
"title": "Node Memory Requests / Available",
"xyChart": {
"chartOptions": {
"mode": "COLOR"
},
"dataSets": [
{
"plotType": "LINE",
"targetAxis": "Y1",
"timeSeriesQuery": {
"prometheusQuery": "sum(kube_pod_container_resource_requests{resource=\"memory\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ((kube_pod_status_phase{phase=~\"Pending|Running\"} == 1))) by (node) / max(kube_node_status_allocatable{resource=\"memory\"}) by (node)\n"
}
}
],
"timeshiftDuration": "0s",
"yAxis": {
"label": "y1Axis",
"scale": "LINEAR"
}
}
},
"width": 6,
"yPos": 24
},
{
"height": 4,
"widget": {
"title": "Node CPU Requests / Available",
"xyChart": {
"chartOptions": {
"mode": "COLOR"
},
"dataSets": [
{
"plotType": "LINE",
"targetAxis": "Y1",
"timeSeriesQuery": {
"prometheusQuery": "sum(kube_pod_container_resource_requests{resource=\"cpu\",job=\"kube-state-metrics\"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ((kube_pod_status_phase{phase=~\"Pending|Running\"} == 1))) by (node) / \nmax(kube_node_status_allocatable{resource=\"cpu\"}) by (node)\n"
}
}
],
"timeshiftDuration": "0s",
"yAxis": {
"label": "y1Axis",
"scale": "LINEAR"
}
}
},
"width": 6,
"xPos": 6,
"yPos": 24
}
]
},
"name": "projects/${local.sample_dashboard.project_number}/dashboards/${local.sample_dashboard.id}"
}
EOF
}
このダッシュボードサンプルでは、ノード単位で、ステータスが Pending または Running である Pod のリソースリクエスト合計を割当可能なリソースで割ったものを、
PromQL
を使用して表示しています。
Managed Service For Prometheus
を使用してメトリクスを取得することを想定しており、
kube-state-metrics
の導入が必要です。
ダッシュボードではなく、Monitoring > Metrics Explorer > CODE EDITOR で、下記のように PromQL だけを指定して確認することもできます。
sum(kube_pod_container_resource_requests{resource="memory",job="kube-state-metrics"} * on (namespace, pod, cluster) group_left() max by (namespace, pod, cluster) ((kube_pod_status_phase{phase=~"Pending|Running"} == 1))) by (node) / max(kube_node_status_allocatable{resource="memory"}) by (node)
リソースリクエストの決定
リソースリクエストが大きすぎると、ノード上で起動できる Pod が減ってしまい、Pod 集約率は低くなってしまいます。よってまずは適切なリソースリクエストを決定し設定しておく必要があります。
Pod 内の各コンテナが使用する CPU やメモリは、Pod に負荷をかけながら、kubectl top pod を実行することで確認できます。
kubectl top pod ${POD_NAME} --containersまた Monitoring ダッシュボード > GKE Compute Resources - Workload View > CPU usage by container・Memory usage by container でも確認できます。
これを参考に、Pod 内の各コンテナに必要であろう値をリソースリクエストとして設定します。
これでスケールアウト後の Pod 集約率をある程度改善できました。
マシンタイプの決定
リソースリクエストの調整によってある程度の改善はできましたが、メモリに比べて CPU に関しては Pod 集約率がまだ低い状態でした。
アプリケーションによって使用する CPU とメモリの量と比率は異なるので、そのアプリケーションの Pod が適切に収まるスペックのマシンタイプを選択する必要があります。
今回は既存のマシンタイプに適切なものが無かったので、 カスタムマシンタイプ を定義して使用しました。
これで Pod が使用する CPU とメモリの比率に合ったリソースを持つノードになり、さらに Pod 集約率を改善することができました。
スケールイン後の Pod 集約率改善
ここまでの設定値の状態で、負荷を増減させてスケールアウトやスケールイン時の Pod 集約率を確認したところ、スケールアウト時は最適な集約率が維持できていましたが、スケールイン時は期待した集約率になりませんでした。
GKE には 自動スケーリングプロファイル という設定があり、下記のいずれかを選択できます。
balanced: デフォルトのプロファイル。optimize-utilization: クラスタ内で余剰リソースを保持するよりも使用率の最適化を優先させます。
この設定を optimize-utilization に変更すれば使用率の最適化が優先され、結果的に Pod 集約率も上がると考え、変更してみました。
しかしこの設定だけでは Pod 集約率は上がりませんでした。
GKE コンソール>クラスタ>対象のクラスタ>ログ>オートスケーラーログを確認したところ、下記のような
noScaleDown・no.scale.down.node.pod.not.enough.pdb のログ
が出ていました。
※ ログサンプル
{
"insertId": "63bed721-f0de-4d2f-be2f-2d405e8dc470@a1",
"jsonPayload": {
"noDecisionStatus": {
"measureTime": "1676365117",
"noScaleDown": {
"nodesTotalCount": 9,
"nodes": [
{
"reason": {
"parameters": [
"my-application-ccbfd99c8-8fwcv"
],
"messageId": "no.scale.down.node.pod.not.enough.pdb"
},
以下略このログは対象の Pod に十分な PodDisruptionBudget (Pod 停止予算、以降 PDB) が残っていないためスケールインできないことを表しています。
PDB は、同時に停止できる (又は同時に起動している必要のある) Pod のレプリカ数を指定する設定です。「PDB が残っていない」というのは、何らかの理由でレプリカが必要数分起動しておらず、PDB の設定を守るためにこれ以上 Pod を停止できないことを表しています。
もともと安全のためにアプリケーション Pod の PDB は maxUnavailable: 1 (同時に停止できるレプリカ数は最大 1 個) で設定していたのですが、これを maxUnavailable: 10% (同時に停止できるレプリカ数は必要なレプリカ数の最大 10%) に変更したところ、ログは出なくなりスケールインできるようになりました。
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:
name: my-application-pdb
spec:
maxUnavailable: 10%
selector:
matchLabels:
app: my-applicationこのように PDB 設定が厳しすぎるとスケールインのブロッカーとなってしまうようです。
これでスケールイン後の Pod 集約率を上げることができました。
スケジューラと CA の実装について
前述の通り、今回は GKE の自動スケーリングプロファイルを optimize-utilization に変更し PDB を調整することで Pod 集約率を改善できました。
今回行った設定が関係していると思われる部分に関して、仕様や実装をもう少し確認してみました。
GKE の実装
※ GKE や K8s のドキュメントでは、スケールインのことがスケールダウンと記述されています。
GKE のドキュメントの optimize-utilization の説明 には下記のようにあります。
- クラスタ オートスケーラーはクラスタをより積極的にスケールダウンします
- Pod 仕様のスケジューラ名が gke.io/optimize-utilization-scheduler に設定されます
この点から GKE 標準のスケジューラと CA の実装について、下記のように推測しました。
- 実装は github で公開されているものと基本的に同じはず ( GKE のドキュメント内には K8s ドキュメントや github への参照リンクがあるので )
- optimize-utilization を設定した場合の変化
- スケジューラのプロファイルに optimize-utilization-scheduler (
NodeResourcesFit プラグイン
のスコアリングストラテジが
MostAllocatedに変更されたもの ) が追加され、スケジューラを指定していない Pod についてはこのプロファイルでスケジュールされると思われる - CA のパラメータ
scale-down-utilization-thresholdはデフォルトの 0.5 より大きくなると思われる
- スケジューラのプロファイルに optimize-utilization-scheduler (
NodeResourcesFit プラグイン
のスコアリングストラテジが
スケジューラ
K8s のスケジューラは スケジューリングフレームワーク と呼ばれる設計で作られています。
下記図のように拡張点があり、ここに プラグイン を登録し、各処理を実装・変更できます。
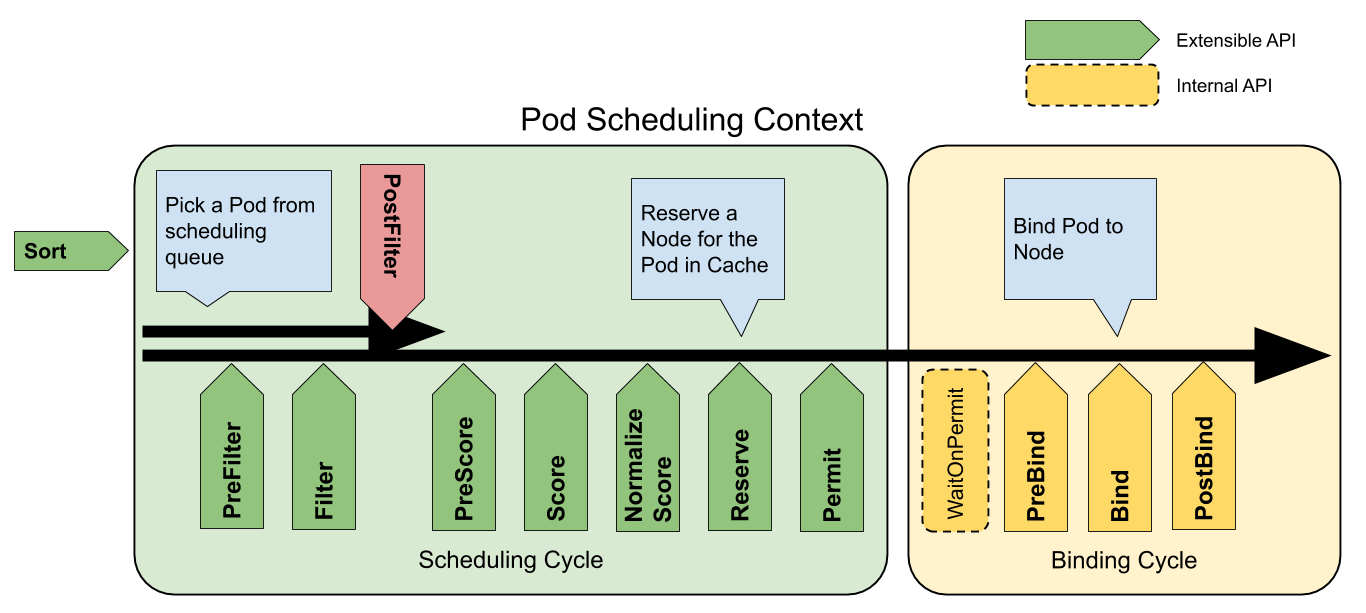 ※
https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling/624-scheduling-framework
より転載
※
https://github.com/kubernetes/enhancements/tree/master/keps/sig-scheduling/624-scheduling-framework
より転載
前述の NodeResourcesFit プラグインは図のスケジューリングサイクルの拡張点 Score などに登録するものです。
またそのスコアストラテジ MostAllocated で動くスコアリングロジックは、Pod 集約率が高いノードほど高スコアになり、優先して Pod が配置されます。
このため、スケールインする際の Pod の移動 (削除するノードから Pod を削除し別のノードで起動させる) において、Pod が集約されやすくなります。
ちなみにデフォルトのスコアストラテジ LeastAllocated の場合は、逆に Pod 集約率の低いノードに優先して配置さるため、集約されにくくなります。
コード上では下記のように実装されていました。
※ tag=v1.24.11 を確認しています
- main 関数 でコマンド作成
- コマンド実行
- コマンド引数とオプションに基づいてスケジューラを作成
- スケジューラ実行
- 1つの Pod に対するスケジュール処理を実行
- Pod をノードリスト内のいずれかのノードにスケジュール
- Pod に適合するノードをフィルタリング
- 複数の候補ノードがある場合はスコアプラグインで優先順位を付ける
- 優先順位をつけたノードの中から1つを選ぶ
CA
CA の起動パラメータ
scale-down-utilization-threshold
はスケールイン対象とするノードの Pod 集約率のしきい値を指定するものです。このしきい値を下回るノードが削除候補となります。よってこの値を大きくすることでより多くのノードが削除対象となる可能性があります。
スケールインでは PDB も考慮されます。
CAはノードの終了を開始する前に、そこにスケジュールされている Pod の PDB で少なくとも 1 つのレプリカを削除できることを確認します。
例えば PDB 設定が maxUnavailable: 1 の場合、1個でも起動できていないレプリカがあると、CA は PDB が残っていないと判断し、レプリカを削除できないのでノードを削除しません。
したがって、PDB の設定が厳しいと、何かしらの理由で Pod のレプリカが全て起動できていない場合にスケールインがブロックされやすくなります。
コード上では下記のように実装されていました。
※ tag=cluster-autoscaler-1.24.2 を確認しています
おわりに
以上で、スケールイン・スケールアウト後にも Pod 集約率が高くなり、ノード数を削減しコストを削減することができました。
IT 基盤部では様々なサービスのインフラを、今回の GKE のような CaaS や IaaS を使って構築・運用しています。
こちらで IT 基盤部の紹介をしていますので、ぜひご覧ください。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。