





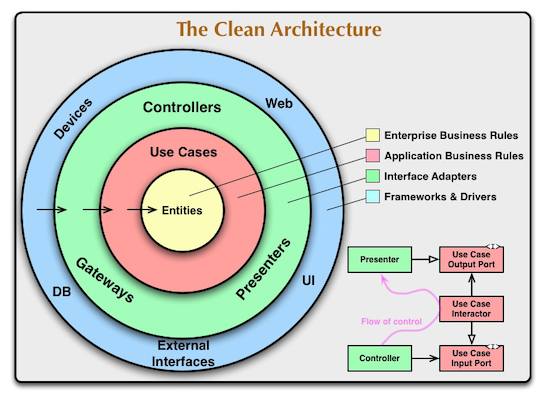
Clean Architecture
You may have ever seen the picture above, or have ever heard/read about Clean architecture somewhere. It’s a very common concept in the software architecture design, there are already many writings about it out there on the internet. This writing is not to explain what is the clean architecture, the purpose of clean architecture, the design principles behind it and why it’s so common, but is to share the reasoning process to go from simplest reasonable working architecture to a full clean architecture on Android. The contents in this writing are extracted from what I have learnt (from books, technical blogs, etc.) and the experiences from applying clean architecture to the project we are working on. Although some concepts using in this writing are specific on Android, the ideas are platform independent, can be applied for web and iOS application.
I simplify and adjust a little to make the diagram closer to the layers of a mobile application:
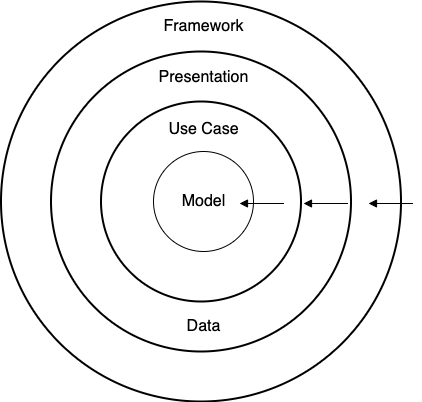
- The main rule that makes the architecture works is the dependency rule: dependencies must point only inward, nothing in an inner circle can know anything at all about something in an outer circle.
- The circle between Model and Use Case are thinner because they can be called Domain layer, together they contain the business logic of the application.
- Presentation: can be ViewModel and State holder classes to deliver optimal UI/UX.
- Data: can be Repository which provides access to local storage and API.
- Framework: including UI components (View, Compose), library for working with database (Room), third-party networking library (Retrofit)…
Notice that the circles in the diagram above are not the same as the layers defined in the architecture we are going to build. For example, in the diagram above, the Presentation and Data are in the same circle because they have the same dependency level (Framework depend on them and they depend on the Use Case), but they are in different layers in the architecture, Present belongs to UI layer and Data belongs to Data layer. At the end, you’ll see where components in each circle are in the architecture.
Now let’s build the architecture step by step.
Building the Architecture
Simplest working architecture
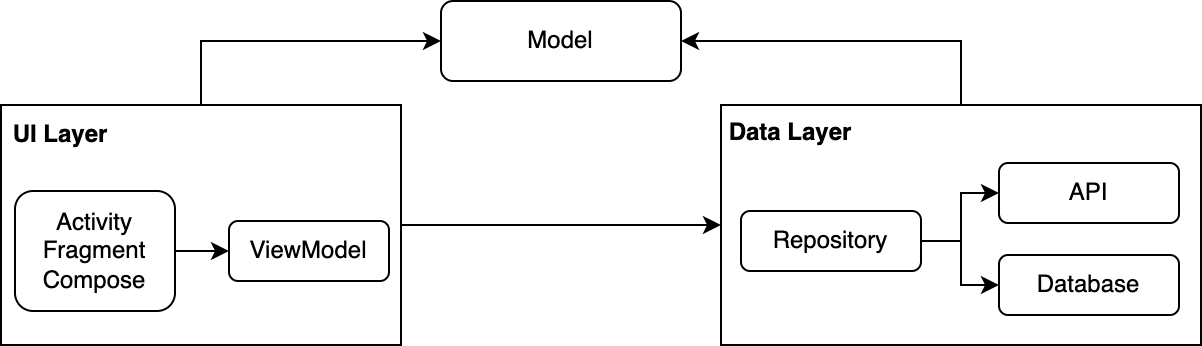
This is the simplest architecture with only 2 layers (UI and Data) and model classes which represent the entities in the the application.
- UI layer displays the application data on the screen. It is made up of UI elements built by the UI library (View, Compose) offered by the Android framework, and ViewModel classes that communicate with the data layer, hold and expose data to UI, handle logic.
- Data layer is made of repositories, which are responsible for exposing data to the UI, handling data from multiple datasource (API, local). Repository also contain business logic. Usually, a repository is responsible for a model in your application. For example, UserRepository contains methods related to the User model.
This architecture works well for small size applications, easy to understand and edit. But when the application scales, there will be limitations:
- All the logics of the application are in ViewModel or Repository, these classes can get complicated and difficult to maintain.
- A Model is used in the whole application, including representing reponses from API and entities in the database, which are not always be the same, the response from the API can be different from the value stored in the database. This causes the tight coupling between layers, a change in the API response can result in the updates of the database and the UI, which is not always be necessary.
There should be a Domain layer?

- Domain models are business objects of the application. They encapsulate the most general and high-level rules. They are platform independent (they should be the same on the backend, iOS or web client), and least likely to change due to the external changes (like UI, API/Database frameworks). They also should be independent from the network models and database models.
- A use case can be considered as a single action we can do within a feature. Use cases contains application specific rules. The same as domain models, they are not expected to be changed by the changes of externalities. Each use case should only have one responsibility.
- Because the domain layer is the most abstract layer and the least likely to be changed, it should be at the root of the dependency graph, that means it should not depend on any other layer, all the other layers depend on it. A change in the domain layer may result in the changes of all the others layers that depend on it. That’s why the domain layer should be the starting point and should be considered carefully at the beginning of the development of any feature.
- Some benefits of using use case:
- Use case can be reused in many ViewModels, which eliminates the code duplication.
- A well defined use cases system screams a lot of about your application. By looking at the use cases, you know what your application does.
- It simplifies the ViewModel and Repository because now the business logics are handled in the use cases.
- Using use cases improves the readability of classes that use them. For example, usually the use cases are injected into the primary constructor of the ViewModel, looking at the definition of the ViewModel we know what actions it (and the corresponding screen) performs.
- Improve the testability of the app.
- It happens quite often that a use case does nothing other than calling a repository method. Even in this case, there are some reasonings which stop us from removing the use case:
- Without using use case, ViewModel accesses directly to the Repository, which usually has methods that the ViewModel doesn’t need. For example, the UserRepository have two methods, to register a user and to login, but in the LoginViewModel (corresponding to the Login screen), only the UserRepository.login() is necessary. By using use case, we expose to the ViewModel only what necessary to complete its work, prevent from calling wrong method in the Repository by mistake.
- Consistency: you don’t want your some of your ViewModels call use cases, while some others call the Repository directly.
- The business rules can be changed in the future, by using the use case now, when the business rules are changes, the update is done in the use case without affecting the ViewModel (which may lead to the change in UI).
Should apply Dependency Inversion?

As stated above, the domain layer should not depend on other layers. But the domain layer in our architecture still depend on the data layer. Now it’s time to utilize the Dependency Inversion (the D in SOLID priciples).
The idea of dependency inversion is to inverting the dependency between high-level components (use cases) and low-level components (repository implementations) by abstracting away the interaction between them, the high-level and low-level components must depend on the same abstraction. This abstraction is the repository interface. Now the use cases depend only on the repository interface, not the concrete implementation, this is how we achieve the loose coupling between the domain layer and the data layer, the changes happen in the data layer do not effect the use cases, as long as the abstract interface is not changed. This is the most important achievement of applying the dependency inversion.
Some other benefits of applying dependency inversion:
- Improve the testability of the app. The unit test for use cases can be implemented independently from repository implementation using fake repository.
- When developing large features which require the participation of many team members, for example, some members work on domain and UI layer, the other members work on the data layer, and they communicate with each other by the repository interface. In other words, they commit to follow an interface that was defined at the beginning of the implementation. By doing this, the development of domain/UI and data can be implemented concurrently without blocking each other, then the integration is implemented when both are done, which speeds up the development.
Add DataSource to Data layer?
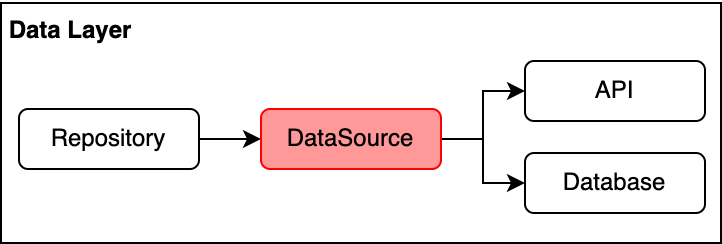
For small applications, it’s ok to call the API services Dao classes directly from the repository. But when the application scales, the repository can become more complicated. This can happen when the model that the repository is responsible for has many actions associated with it, which requires more method in the repository. Or the logic in each method is complicated, may require the data/action from multiple sources (API, database, SharedPreferences) and from other repositories. The repository can be simplified by two solutions:
- Split the repository into smaller and more specific ones. This can be done by grouping related methods based on their function into a specific repositories. This is the Interface segregation principle (the
Iin SOLID). The main purpose of this principle is to expose to the clients of the repository only the methods that they need. We should apply this rule when designing the repository interface, no matter the repository is complicated or not. - Adding the data source classes to abstract away the data related operations from the repository (calling API/Dao methods, handling API errors…). An example of datasources for the User model can be UserRemoteDataSource and UserLocalDataSource. Each data source should define its own data model and converting to domain model before returning data to the repository. For example, UserResponse to handle response from API and UserEntity representing a table in the database, these two models do not know about each other, they depend on the User domain model only. By doing this, the changes happen in the data source models (for example, when API’s response is updated) do not effect other layers of the application, as long as the domain models are not changed.
Apply Dependency Inversion in Data layer?
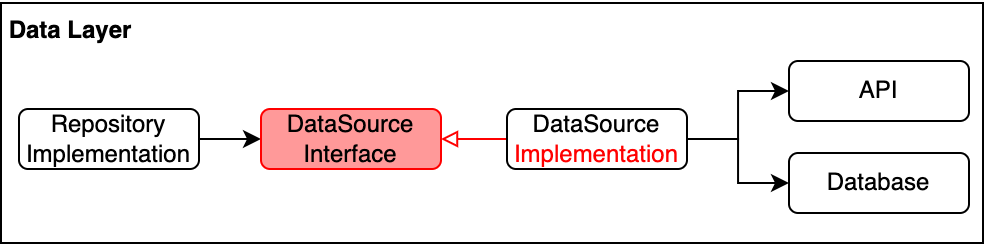
Similar to the dependency inversion between domain layer and data layer, it can be applied to revert the depedency between repository (higher level) and data source (lower level). Data source is considered lower level because it’s closed to the Android framework, for example, Retrofit is used to make API request, Room is used to store and query from local database. Making repository depending on the interface instead of concrete implementation make it easier for unit testing using fake data source.
Full Architecture with Boundary
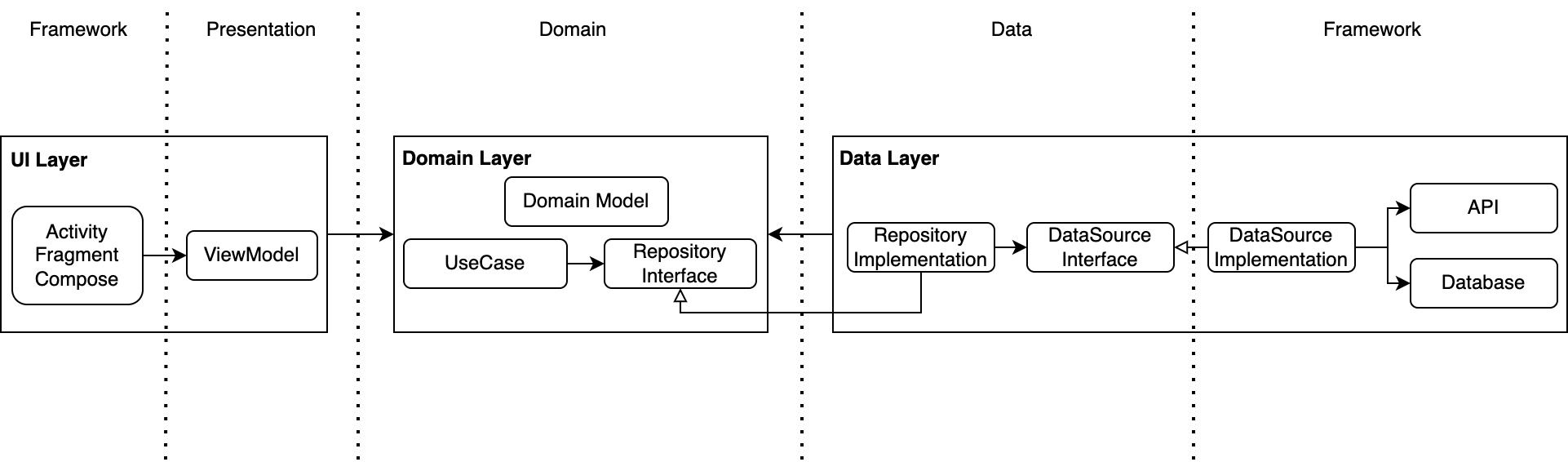
The boundaries (vertical dotted lines) are added to make clear where each circle in the diagram at the beginning lies in our architecture.
Conclusion
It’s not necessary to include all the layers discussed above in an application. Depending on how large is your application, team size, how often the application is updated, etc. you can decide to skip layer(s) you think not necessary.



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。