





はじめに
DeNAのAIスペシャリストコースのサマーインターン2022に参加させて頂きました、中井と申します。
本インターンシップの課題として、ライブコミュニケーションアプリ「Pococha」の新規リスナー向けのリアルタイムレコメンドのロジック提案・開発に取り組みました。
本記事では、取り組んだ内容とその成果について報告させて頂きます。
取り組んだ課題について
私は本インターンシップにおいて、「ライブコミュニケーションアプリ『Pococha』における新規リスナー向けの推薦モデル開発」というテーマに取り組みました。
Pocochaのようなアプリサービスでは、一般的に新規リスナーにいかにサービスに魅力を感じてもらい、利用を継続して頂くかが重要な課題となっています。
そして一般的にユーザーとコンテンツをマッチングする手法の1つとして、ユーザーのデモグラフィクスや行動履歴に基づいてサービスの提供内容をユーザーの嗜好に最適化する、レコメンドと呼ばれる手法がよく用いられています。
Pocochaにおいても視聴履歴が十分に存在するリスナーに対しては、機械学習などを用いてライバーのレコメンドを行なっています。その一方で、新規リスナーの場合は十分な視聴履歴を持たないことから同じロジックを適用することはできず (コールドスタート問題) 、現在はユーザーの嗜好に最適化されたレコメンドの仕組みを導入することができていません。
そこで本インターンシップにおいては、十分な視聴履歴を持たない新規リスナーに対するレコメンドのロジック提案・開発を行い、それらが新規リスナーにPocochaに魅力を感じてもらい、利用を継続して頂くために有効であるかどうかについて、継続率などの数値を用いて考察しました。
新規リスナーの登録一定時間後の継続率
Pocochaの新規リスナーに関する現状分析の結果からも、登録後数時間で新規リスナーをいかにサービスに惹きつけるするかがとても重要であるということが確認できました。
そこで、後の説明では登録一定時間後時点の継続率をKPIとして、提案手法によりそれをどの程度向上できるかについて手法の比較を行いました。
結果として、提案した手法によりこの継続率を3%向上させられることがわかりました。
新規リスナー向けレコメンドの難しさ
視聴履歴が少ない新規リスナーに対して精度良くレコメンドを行うためには、リスナーに提供するレコメンド内容について、その時点での視聴履歴を全て用いて最適化することが効果的であると考えられます。
一方でレコメンドの最適化には一定の計算コストが伴うため、既存のPocochaのレコメンド手法では全リスナーについてある時点の視聴履歴を用いてバッチ計算でこの最適化計算を行なっています。
リスナーからレコメンド内容を取得するリクエストを受けるたびにその時点の全ての視聴履歴を用いてレコメンド内容の最適化計算を行なってその結果を返すような実装方法も考えられますが、これではレイテンシを増加させてしまいユーザー体験を損なってしまうことが懸念されます。
このように、レコメンドの最適化をリスナーの視聴終了のたびにリアルタイムで実現する必要があるという点は、視聴履歴が十分に存在するリスナーに対するレコメンドとは課題設定が大きく異なります。
本インターンシップの成果として、PubSubを用いた非同期のレコメンド最適化基盤を構築することで、最新の視聴履歴を用いてレコメンドの最適化を行う要件・ユーザー体験を損なうことなくレコメンド内容を提供する要件の2つを同時に満足できることを確認しました。
分析設計
まずレコメンドが新規リスナーの継続率向上に与える影響を分析することで、継続率向上と正の相関を持つ指標を定義しました。
次にこの指標の下で、提案する2つのレコメンド手法をベースラインであるPocochaの「注目50」機能と比較しました。
最後に、ベースラインからの指標の向上幅を継続率の向上幅に変換することで、提案したモデルによって新規リスナーの継続率がどれほど向上するかについて試算しました。
比較指標とベースラインモデル
まず提案するモデルを評価するための指標として、Precision@Kを選択しました。
具体的には、Pococha新規リスナーの登録後24時間以内に視聴行動のそれぞれについて、次の手順によりPrecision@Kを算出します。
- よくみるライバーの抽出 : 視聴行動が終了した時点で配信中のライバーを抽出し、対応するリスナーの今後1ヶ月における合計視聴時間で並び替えを行う。
- 上位N件レコメンド : 同様に抽出した配信中のライバーについて、モデルを用いてN人のレコメンドを行う。
- Precision@K : レコメンドしたN人のうち、それが今後1ヶ月でよくみるライバーtopKに含まれる割合を算出する。
次に、item2itemレコメンドとsession-basedレコメンドの2つのレコメンド手法を提案しました。
この選定理由として、前述のように新規リスナー向けのレコメンドにはコールドスタートの問題があるためリスナーに関する特徴量を利用することはできず、この点においてこれらの2手法はリスナーのセッション内の視聴履歴のみからレコメンドを行うことができるという点に着目して選定しました。
その他の候補としてはRNNを用いたsession-basedレコメンド(Hidasi, B. et al., 2015)などが挙げられましたが、今回は時間の都合上対象から除外しました。
以上の評価指標の下で、item2itemレコメンドとsession-basedレコメンドの2つの新手法について、現在Pocochaで用いられている「注目50」機能によるレコメンド結果との比較を行いました。
提案手法1 − item2itemレコメンド
新たに提案する新規リスナーに対するレコメンド手法の1つ目は、ライバーベクトルの近傍探索に基づくitem2itemレコメンドです。
item2itemレコメンドの概要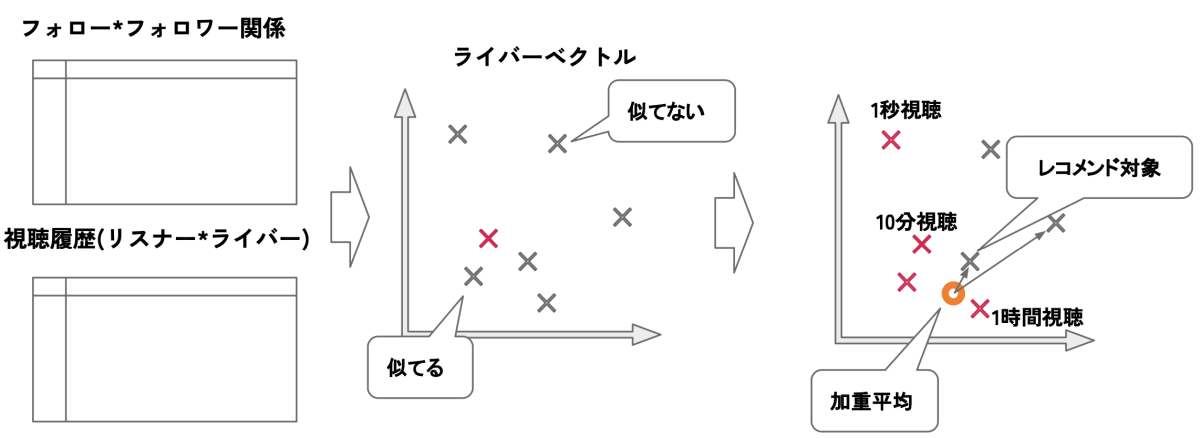
具体的には、まずは過去のフォローフォロワー関係や視聴履歴に関するデータを基にmatrix factorizationという手法を用いることで各ライバーに関して特徴ベクトルを作成します。これによって、似た性質を持つライバーほどベクトル空間中で近くに配置されるような特徴表現を獲得することができます。
レコメンドの際には、過去視聴した全てのライバーの特徴ベクトルについて、視聴時間を係数とした加重平均を計算し、その結果のベクトルに近いライバーをレコメンドします。(上図参考)
リスナーが嗜好に合わず視聴をやめた場合、そのライバーに近いライバーをレコメンドすることは適切ではないと考えられます。そこで、視聴時間を係数とした加重平均を取ることで、リスナーがより長く視聴したライバーを重視しながら、過去の視聴履歴のコンテキストを考慮してレコメンドを行うことを可能にしています。
提案手法2 − session-basedレコメンド
新たに提案する新規リスナーに対するレコメンド手法の2つ目は、同一セッション内のライバーの共起度に基づくsession-basedレコメンドです。
session-basedレコメンドの概要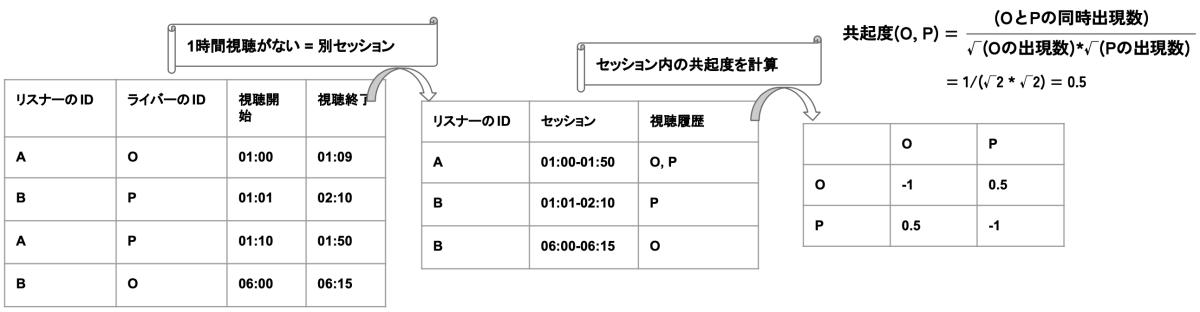
具体的には、リスナーの視聴が1時間以上途切れた場合を別セッションとみなし、各リスナーのセッションごとの視聴履歴をまず集計します。次に、同一セッション内でのライバーの共起度を次の計算式により計算します。
$$ 共起度(ライバー_i, ライバー_j) = \frac{ライバー_iとライバー_jの同時出現数}{\sqrt{ライバー_iの出現数}\sqrt{ライバー_jの出現数}} $$
この式では、$ライバー_i$と$ライバー_j$が全て同時に出現する場合は共起度が$1$に、全て同時に出現しない場合は共起度が$0$になります。
最後に、この事前に計算した共起度を用いて、リスナーがあるライバーを視聴した場合に、そのライバーとの共起度の高い上位N件のライバーをレコメンドします。
また、本アプローチにおいてもリスナーの嗜好を反映するために、視聴時間に基づく加重平均を取り入れました。
分析結果
まず新規リスナーの視聴行動とその後の継続率について分析を行った結果、登録後24時間以内の視聴回数が2倍に増えると継続率は6pt向上するという正の相関を発見しました。
次にベースラインの「注目50」機能と提案した2つの手法について、前述のPrecision@Kを比較指標とした実験を行いました。
まずはitem2itemレコメンドの結果について、次は「注目50機能(緑色)」「視聴時間による加重平均を取らない場合のitem2itemレコメンド(青色)」「視聴時間による加重平均を取る場合のitem2itemレコメンド(オレンジ色)」の3つの手法について、x軸としてレコメンドを上位何件まで表示するか、y軸としてPrecision@Kの数値を示したグラフです。
視聴時間による加重平均の有無によるitem2itemレコメンドのレコメンド性能の比較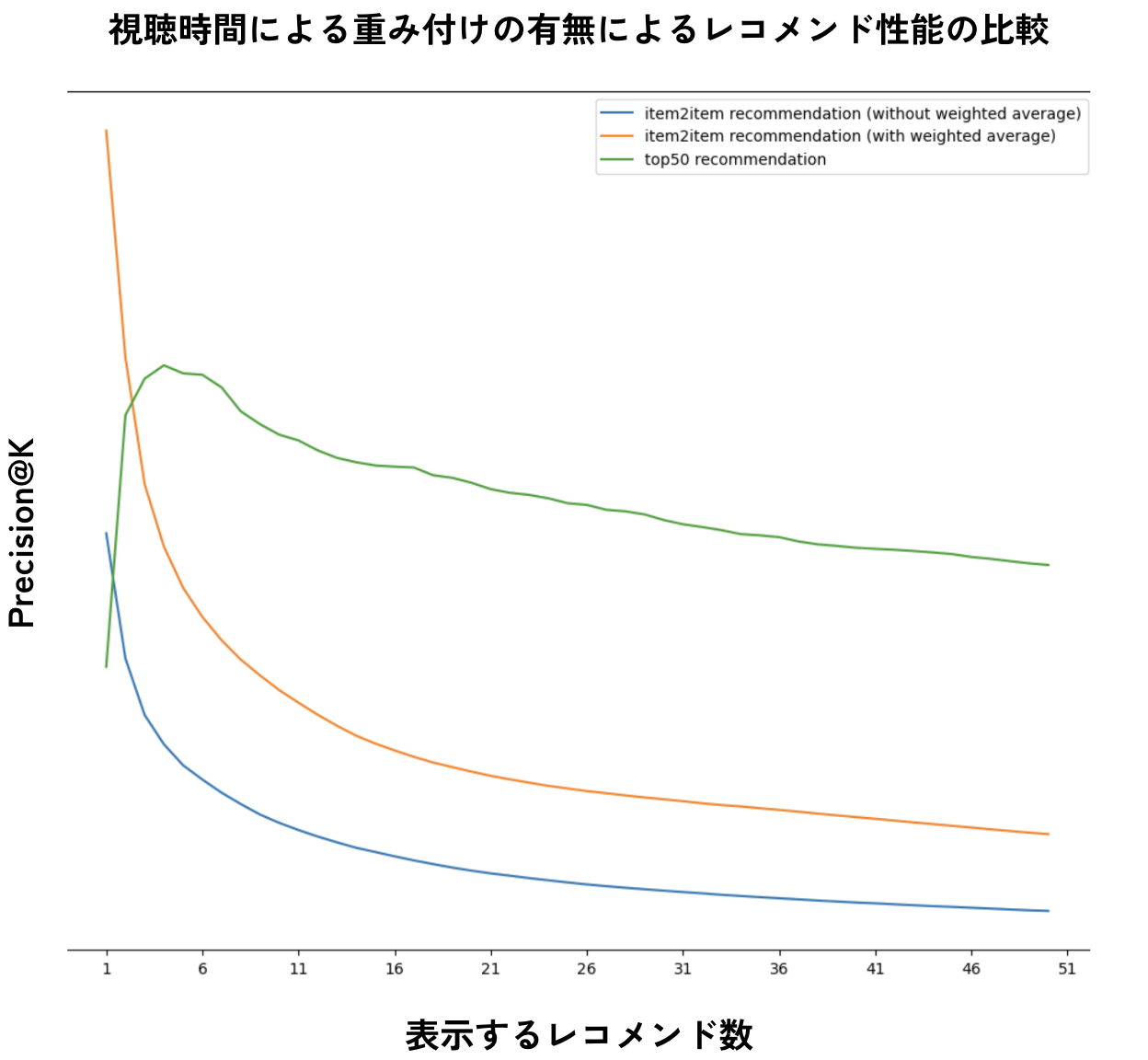
この結果として、
- 視聴時間による加重平均を行った方が精度は高く、最大約1.8倍向上する。
- 上位ではベースの「注目50」機能よりも高い精度を達成することができている。
ことが確認できました。
またsession-basedレコメンドの結果について、次は「注目50機能(緑色)」「視聴時間による加重平均を取る場合のitem2itemレコメンド(青色)」「視聴時間による加重平均を取る場合のsession-basedレコメンド(オレンジ色)」の3つの手法について、x軸としてレコメンドを上位何件まで表示するか、y軸としてPrecision@Kの数値を示したグラフです。
注目50機能、item2itemレコメンド、session-basedレコメンドの3手法のレコメンド性能の比較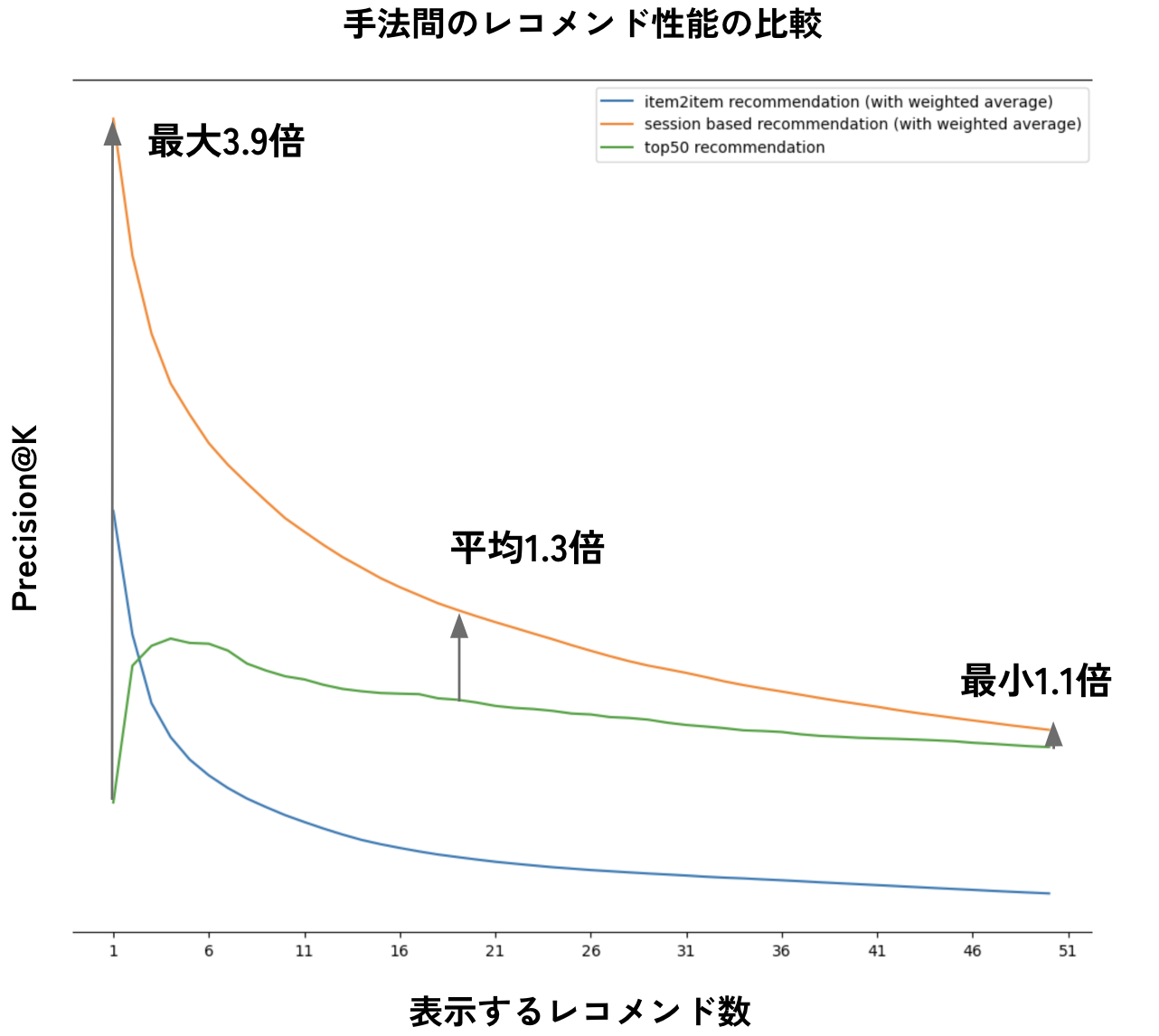
この結果として、
- session-basedレコメンドは、注目50機能・item2itemレコメンドに対して一貫して高い精度を発揮することができている。
- 特に、ベースラインである注目50機能と比較してもPrecision@Kは最小1.1倍から最大3.9倍まで改善することができる。
ことが確認できました。
最後にこのベースラインに対する精度の向上幅を継続率の向上幅に変換することで、提案する新規リスナー向けレコメンドの導入が継続率の改善に与えるインパクトを試算しました。
結果として、今回提案する新規リスナー向けレコメンドの導入によって、継続率が平均で3pt程度改善するということを示すことができました。
API実装
最後に、以上で提案したsession-basedレコメンドモデルについて、リスナーが視聴を終了するたびに最新の視聴履歴を用いて最適化を行い、その結果を許容可能なレイテンシで返すことができるかについて、実際に簡単なAPI基盤を構築することにより実験を行いました。
同期通信によるリアルタイムレコメンドAPIの構築と負荷試験
session-basedレコメンドによる新規リスナー向けのレコメンドを次の手順で行うようなAPIを実装しました。
- 視聴が終了したリスナーについて、過去の視聴履歴を取得する
- 現在配信中のライバーの一覧を取得する
- 過去の視聴履歴中のライバーと配信中のライバーについて共起度を取得する
- 配信中のライバーについて共起度を集約する (視聴時間を係数とする加重平均により集約)
- 共起度の合計が多い順にソートし、上位N件をレコメンド結果として返す
ただし、ライバー間の共起度の計算は日次のバッチ計算で行うこととします。
次にこのAPIのレイテンシがSLOを満たしているかどうかについて、実際に負荷試験を行うことで検証しました。
負荷試験では、次のようなコードにより60[rps]で30秒間リクエストを送り、レイテンシの統計値を算出しました。
// 30秒間のタイムアウト設定
ctx, cancel = context.WithTimeout(ctx, duration)
defer cancel()
// リクエストごとのレイテンシを記録
ls := make([]int64, 0)
// レイテンシの計測結果をgoルーチンから渡すためのgoチャネル
li := make(chan int64)
// 1/60秒のインターバル設定
t := time.NewTicker(interval)
go func() {
for {
select {
case <-t.C:
// 1/60秒ごとに呼び出される
go func() {
// 非同期でリクエストを1回送信してレイテンシをgoチャネルに格納する
now := time.Now()
_, _ = http.Get(url)
li <- time.Since(now).Milliseconds()
}()
case <-ctx.Done():
// タイムアウト時に呼び出される
t.Stop()
close(li)
return
}
}
}()
// goルーチンから受け取ったレイテンシを記録
for l := range li {
ls = append(ls, l)
}
結果は下記の通りでした。
- 50パーセンタイルにおけるレイテンシ : 678 [ms]
- 95パーセンタイルにおけるレイテンシ : 1570 [ms]
以上で、リスナーがレコメンドAPIにGETリクエストを送るたびに最新の視聴履歴を用いてレコメンド内容を最適化して表示可能な同期通信APIを構築することができました。
一方で、負荷試験の結果として計測されたレイテンシはPocochaで定められるSLOの水準には達することができず、API中の処理の高速化が必要でした。
非同期通信によるリアルタイムレコメンドAPIの構築と負荷試験
レイテンシを抑制するための工夫として、リスナーが配信の視聴を終了したタイミングで非同期にレコメンド内容の最適化を行い、レコメンドAPIへのリクエストに対しては最適化された結果を返すようにリアーキテクチャを行いました。
具体的なアーキテクチャの概要としては次の図の通りです。
非同期推論基盤のアーキテクチャ図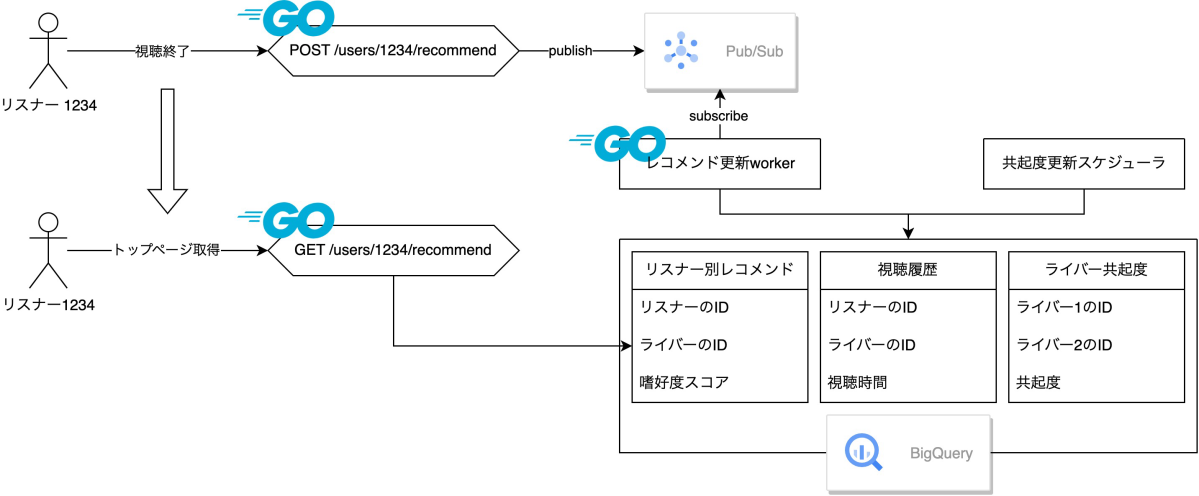
まず、リスナーが配信の視聴を終了するとPubSubのキューにメッセージがpublishされます。次にdaemonプロセスで動くworkerがメッセージをsubscribeし、該当するリスナーについて最新の視聴履歴を取得し、共起度の集約計算を行います。リスナーがレコメンドAPIへリクエストを送ると、APIは事前に集約計算を行った共起度に基づいてレコメンドを行います。
これにより、同期通信中で行っていた最適化計算を非同期で行うことができるようになり、レスポンスの高速化が期待されます。
実際に、次は先ほどと同様の負荷試験を行った結果です。
- 50パーセンタイルにおけるレイテンシ : 622 [ms] (56 [ms] 削減)
- 95パーセンタイルにおけるレイテンシ : 768 [ms] (802 [ms] 削減)
以上のように、リアーキテクチャによりレイテンシを大幅に削減することに成功しました。今回はOLAPであるBigQueryをデータベースとしてレイテンシを計測したため、実際のRDBを用いた本番環境ではより高いパフォーマンスが期待されます。
このようにリアルタイムのレコメンド基盤として十分にプロダクションレディな水準にまで仕上げることができました。
まとめ
本インターンでは、Pocochaにおける新規リスナーの継続率向上というテーマに対して、新規リスナー向けのレコメンドロジックを提案することが有効であるかの分析を行いました。特にここでは、
- 十分な視聴履歴がない新規リスナーの嗜好を適切に反映したレコメンドを行う必要のあるコールドスタートの問題
- リアルタイムで最新の視聴履歴に基づいてレコメンド内容の最適化を行って許容可能なレイテンシで結果を返すことが可能な設計
という2つの大きな課題に取り組みました。
結果として、session-basedレコメンドの導入により既存の「注目50」機能に比べて1.1-3.9倍の高精度化を実現し、それにより継続率が平均で3pt程度改善できることが確認できました。
また実際にPoCとしてAPIの実装を行い、配信の視聴が終了するたびにダイナミックにレコメンド内容が最適化されるようなリアルタイムレコメンドAPIを実現することができました。特に、PubSubを用いた非同期最適化の導入によってパフォーマンスを向上し、プロダクションレディなリアルタイムレコメンドAPIを構築することができました。
一方で今回実装したAPIはPoCに留まり実際にリリースすることはできなかったため、今後の展望としてABテストやオンライン評価を通してモデルの有効性を確認する手順が必要になると考えております。
最後になりましたが、本インターンを通して仮説の立案・検証・評価・改善といったデータサイエンティストとしての一連の業務内容を経験することができ、また自身が特に興味が強かった学習基盤やAPIの提供基盤の構築などのMLエンジニアに近い業務内容も経験することができ、とても多くの学びを得ることができました。ここで学んだことを活かしながら、今後の開発や研究に励んでいきたいと思います。
誠にありがとうございました。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。