





はじめに
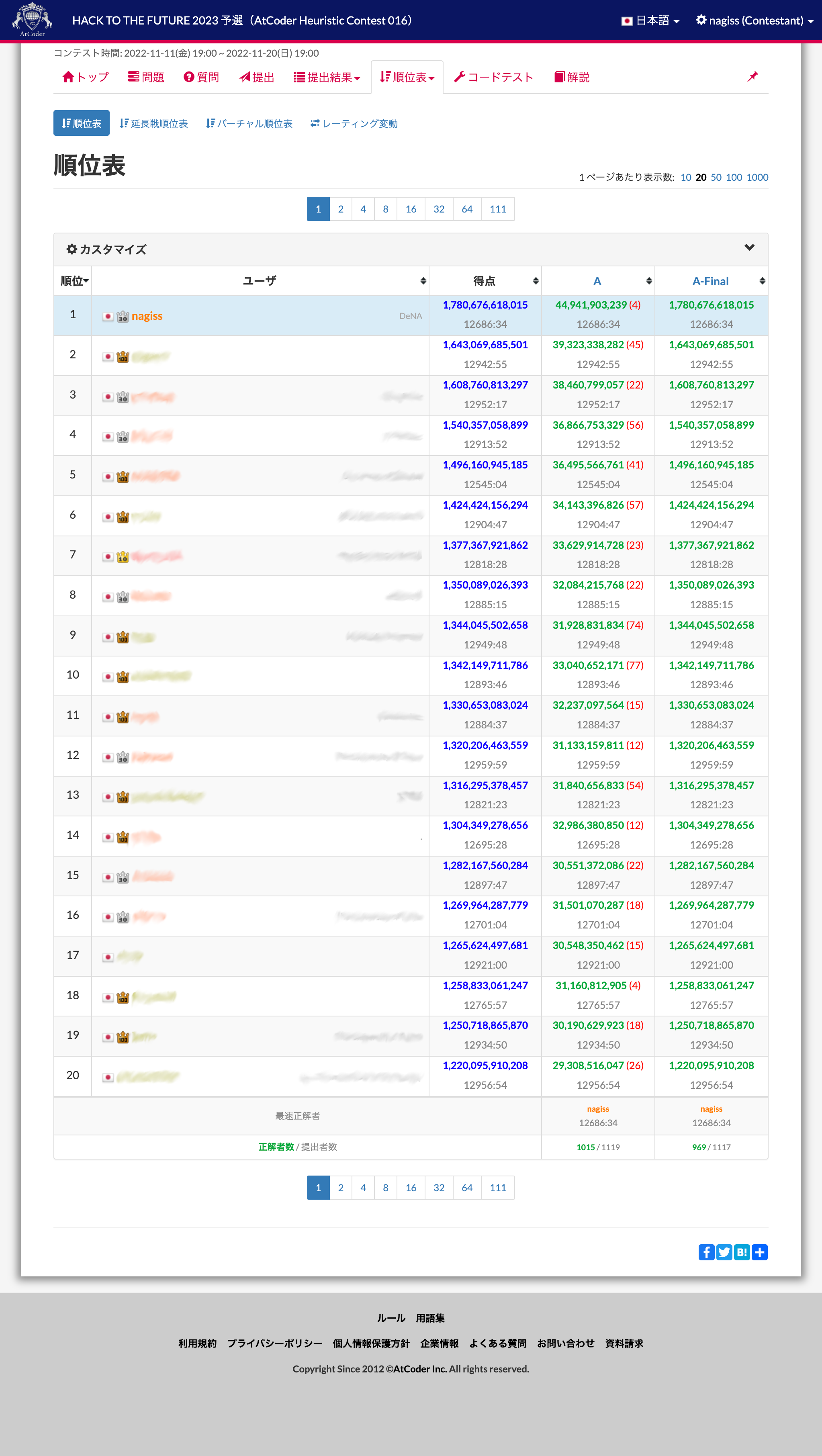
こんにちは。データ本部 AI 技術開発部で nagiss というハンドルネームで活動している者です。 先日行われた HACK TO THE FUTURE 2023 予選(AtCoder Heuristic Contest 016) において 1 位を獲得することができましたので、その解法を紹介します。
HACK TO THE FUTURE とは
HACK TO THE FUTURE は、 フューチャー株式会社 が AtCoder 上で 2018 年から毎年開催しているプログラミングコンテストです。
コンテストでは、問題がただひとつ出されます。 参加者は、この問題に対しどれだけ高いスコアを獲得できるプログラムを書けるかを競います。 (いわゆる"マラソン (ヒューリスティック) 形式"のコンテストです。)
一昨年まで予選の制限時間は 8 時間でしたが、昨年からは 1 週間程度の長さとなり、より凝った解を提出できるようになっています。
問題概要
今回の問題の概要は以下のようなものです。より詳細な内容は 問題ページ を参照してください。
- 整数 $M$ とエラー率 $\epsilon$ が与えられるので、プログラムはまず、整数 $N$ と、頂点数が $N$ であるような $M$ 個の無向グラフ $G_0, G_1, \cdots, G_{M-1}$ を出力してください。
- その後、$N$ 頂点の無向グラフが $100$ 個与えられます。このグラフは、 $G_0, G_1, \cdots, G_{M-1}$ のいずれかに対し、頂点番号のシャッフルと、ノイズの付加 (各頂点間の辺の有無の確率 $\epsilon$ での反転) を行って生成されているので、プログラムは元のグラフがどれであったかを予測して出力してください。
昨年の予選に引き続いて、予測系の問題です。 ただ、昨年は MCMC が 猛威を振るった のに対し、今回は MCMC が得意とする問題とは毛色が違いそうです。
コンテスト中にやったこと
考察
方針
初手での考察はこのような感じでした。
- グラフの同型判定っぽい
- 簡単なケースでは厳密に答えを出せそう
- というか今回どう見ても NN (ニューラルネットワーク) での予測が強そうなタスクじゃない……?
いつもの長期ヒューリスティックコンテストでは方針を立てるのに 3 日はかかるのですが、珍しく今回は早い段階で当たり方針を引けていました。 そして機械学習が使えて他の人と差をつけられそうということで、気合も入ります。
スコアの期待値
今回の目的関数は、頂点数を $N$、予測が外れた回数を $W$ として以下で与えられています。 $$ \mathrm{round}\left(10^9\times \frac{0.9^W}{N}\right) $$
予測の成功確率を $p$ とすると、round を省略すればスコアの期待値 $E$ は以下のように計算できます。2 行目から 3 行目への式変形は 二項定理 を利用しています。
$$ \begin{align*} E &= \sum_{W=0}^{100} {}{100}C_W (1-p)^W p^{100-W} \left(10^9\times \frac{0.9^W}{N}\right) \\ &= \frac{10^9}{N} \sum{W=0}^{100} {}_{100}C_W \{0.9(1-p)\}^W p^{100-W} \\ &= \frac{10^9}{N}\{0.9(1-p) + p\}^{100} \\ &= \frac{10^9}{N}(0.9 + 0.1p)^{100} \end{align*} $$
この計算式は $N$ のチューニングに使うことになります。
具体的な $p$ の値を使って期待値を計算してみると、
- $p=0.8$ のとき $E\approx \frac{0.133 \times 10^9}{N}$
- $p=0.9$ のとき $E\approx \frac{0.366 \times 10^9}{N}$
- $p=0.99$ のとき $E\approx \frac{0.905 \times 10^9}{N}$
となり、少しの精度の違いでスコアの期待値が大きく変わるため、$N$ を大きくしてでも $p$ を $1$ に近づけた方が良さそうということがわかります。
そして、$N$ を上限の $100$ にしても $p$ が $1$ 付近にならないようなケースは、精度の改善が指数関数的にスコアに反映されることになります。 後述の相対スコアの仕組みと合わせると、1 位を狙う場合はここを落とさないことが重要となりそうです。
相対スコア
今回はケースごとに全参加者内の最高点を $10^9$ 点とスケールし直す相対スコアが設定されています。
簡単な ($N$ が小さくて済む) ケースと難しい ($N$ を大きくしなければならない) ケースでは比較ができないので、提出一覧ページの絶対評価スコアは比較に使えません。
相対スコアの仕様のために順位表上のスコアも不安定で、あまり信頼のおけるものではありませんでした。
対策として、ローカルでの評価で、mean(ln(scores)) のような値を使いました。
解法に変更を加えた結果としてこの値が $0.1$ 増えたとしたら、相対スコアはおよそ $\exp 0.1 \approx 1.105$ 倍になるだろうといった見積をとって、安定した評価を行っていました。
$\epsilon$ が小さいケースの攻略
最初に、簡単なケースでほぼ最適な解を求める実装を行いました。 実装するまでは何割程度のケースでこの解法を適用できるか見当をつけられていなかったため、優先度高く試す必要がありました。
……しかし、コンテスト中に私の実装できたのは $N \le 8$ で動作するものでした。問題作成者はより効率の良い方法で $N \le 9$ を処理していたため、ここでは解説を省略し、記事の後半で詳しく見ていくことにします。
$\epsilon$ が大きいケースの攻略
NN を使って予測をします。
入力がグラフとなるので、グラフ畳み込みを使うことを考えますが、1 つ注意しなければならないことがあります。
それは、今回の問題で扱うグラフにおいて、頂点間に辺がある状態と無い状態は、完全に対称だということです。 グラフ畳み込みは、ある頂点に対し、辺で直接繋がれた頂点だけを使って計算を行うアルゴリズムです。 したがって、例えばノイズが加わることによって辺が消失した場合、計算において本来考慮されるべき隣接頂点が全く考慮されなくなってしまいます。
今回の問題で扱うグラフは、「頂点間に辺がある状態と無い状態があり、ノイズによって有無が入れ替わる」と考えるより、「全ての頂点間に辺が張られた完全グラフであって、辺の色は白か黒のいずれかであり、ノイズによって色が入れ替わる」と考えた方が、本質的な理解がしやすいように思います。
アーキテクチャ
実装しているうちに「これ Attention っぽくね?」と思ってグラフ畳み込みを Attention に変えたりした結果、NN のアーキテクチャはこのようになりました。Transformer の Encoder を参考にしています。
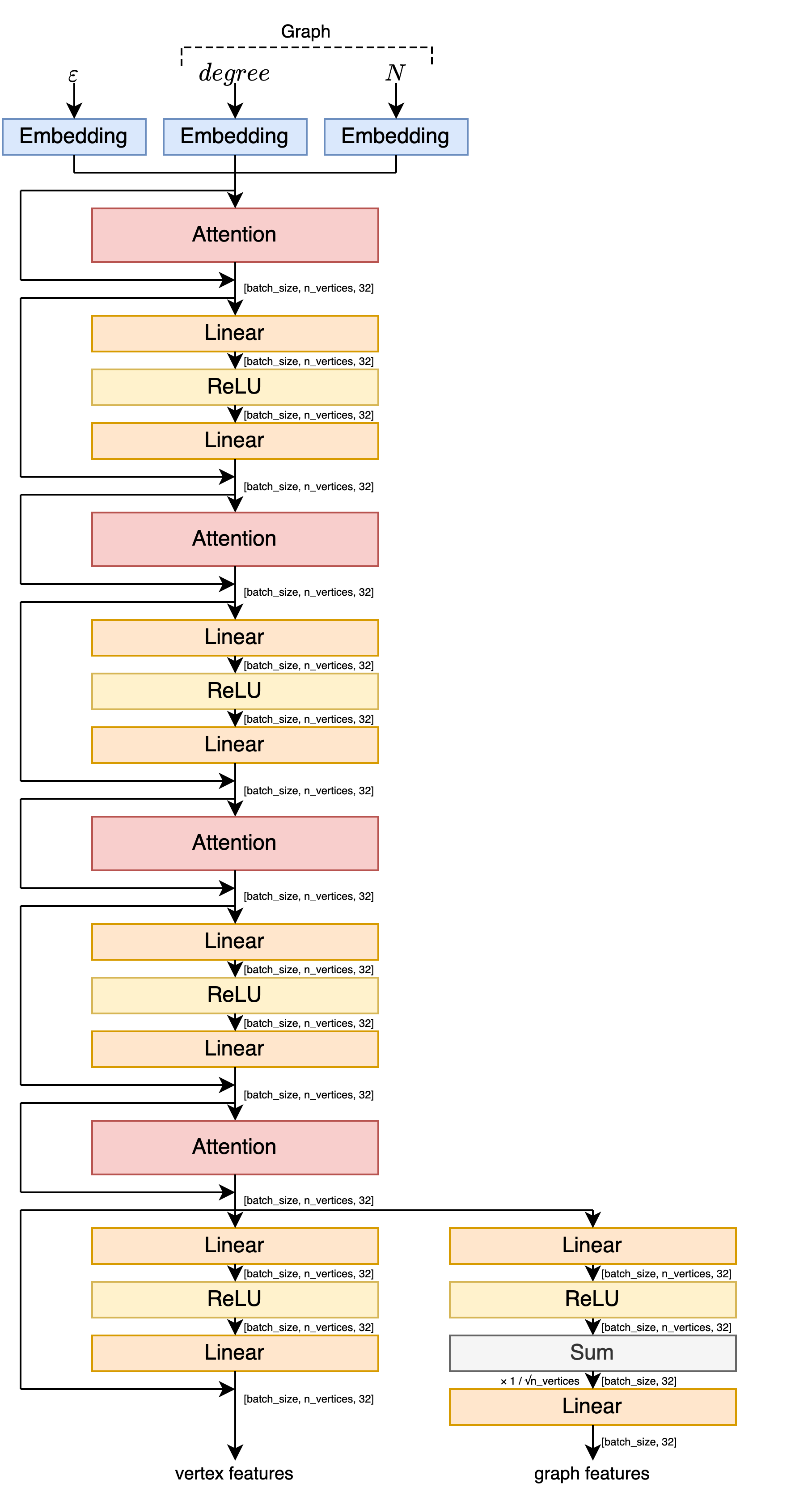
Linear は通常のアフィン変換 (入力の $32$ 次元ベクトルに対し、$32 \times 32$ 行列を掛けて $32$ 次元ベクトルを足す。行列とベクトルの値は学習されるパラメータ)、ReLU はランプ関数 $\max(\cdot, 0)$ です。 Attention は、以下のような動作をするものです。(Attention を知っている人向けに簡単に言えば、辺の有無によって異なる重みの $K$ と $V$ を使う工夫を入れた Self-Attention です。)
- 入力は、各頂点に $32$ 次元の特徴量が割り振られたグラフ
- 出力は、各頂点の新しい $32$ 次元の特徴量
- 全ての頂点に対して、以下を行う
- 他の全ての頂点に対し、自身との関係性の強さを計算する
- 関係性の強さは、自身の特徴量ベクトルを行列 $Q$ でアフィン変換してできたベクトルと、相手の特徴量ベクトルを行列 $K_0$ (間に辺が無い場合) または $K_1$ (間に辺がある場合) でアフィン変換してできたベクトルの内積
- $Q$, $K_0$, $K_1$ は学習されるパラメータ
- 関係性の強さを、後で使いやすいように調整する
- まず、全ての関係性の強さの値を $\sqrt{32}$ で割る
- 内積を取ったときに $32$ 個の値の和を取っており、ひとつひとつの値が独立な分散 $1$ の正規分布に従うとすると、$32$ 個の和を取った後の値は分散が $32$ になるため
- その後、softmax 関数 $f(x_i) = \frac{\exp x_i}{\sum_j \exp x_j}$ を適用する
- 全ての値が正かつ総和が $1$ になる
- まず、全ての関係性の強さの値を $\sqrt{32}$ で割る
- 関係性の強さに応じて、他の頂点の情報を足し合わせ、自身の新しい特徴量とする
- 具体的には、相手頂点の特徴量ベクトルに対し行列 $V_0$ (間に辺が無い場合) または $V_1$ (間に辺がある場合) でアフィン変換して得たベクトルを、関係性の強さを重みにして線型結合する
- $V_0$, $V_1$ は学習されるパラメータ
- 他の全ての頂点に対し、自身との関係性の強さを計算する
推論時の動作
NN は、グラフを入力に取り、グラフ全体を表す特徴量 ($32$ 次元ベクトル) と、各頂点の特徴量 ($N$ 個の $32$ 次元ベクトル) を出力します。 ノイズが加わる前のグラフ $G_s$ とノイズが加わったグラフ $H$ の両方に対して NN で推論を行い、得た特徴量を以下のように使うことで予測を行います。
- 全ての $G_s$ のグラフ全体の特徴量に対して、$H$ のグラフ全体の特徴量と内積を取ることで類似度を計算し、類似度が $17$ 位以下だったものは切り捨てて候補を $16$ 個以下に絞る
- 候補となった $G_s$ に対して、$G_s$ の全ての頂点と、$H$ の全ての頂点の類似度を特徴量の内積をとることで計算する
- $N \times N$ の類似度行列が $16$ 個できる
- 全ての類似度行列に対してハンガリアン法を行って、最適な頂点の割当を求め、そのスコアが最も高かったものを予測結果とする
元々はハンガリアン法で全てのグラフに対してスコアを計算する算段でしたが、$N=100$ で $O(N^3)$ の計算を最大 $10000$ 回回すのは制限時間 $5$ 秒といえど厳しく、後からグラフ全体を表す特徴量の出力を追加して足切りをする羽目になりました。 しかし実際追加してみると、単にグラフ全体を表す特徴量だけを使った予測でも、ハンガリアン法を使った予測と精度に差はほとんどありませんでした。
学習方法
NN の学習は以下のようにして行いました。
- 推論時と同様に、グラフ全体の特徴量を使った予測と、ハンガリアン法を使った予測を行う
- 損失関数は、グラフ全体の特徴量での予測とハンガリアン法での予測それぞれで計算したクロスエントロピーの和
- グラフの候補の数 $M$ は最大で $64$ とし、推論時のような候補の絞り込みは行わない
- $H$ に対して、正解の $G_s$ との間ではハンガリアン法による計算は行わず、真の頂点の割当を使ってスコアを計算する
- NN 自体の計算量は小さく、ハンガリアン法が律速となったため、GPU は使わず学習
グラフの選択
ここはコンテスト中あまり上手くできなかったところだと思っています。 NN は精度良く元のグラフを予測してくれますが、元のグラフ集合をどのように選ぶかは人の手で上手く決めなければなりません。
$\epsilon$ の小さいケースで選択されたグラフを見ると、下図のように対称的な構造を持ったグラフが多く選ばれていたため、まずそのようなグラフをランダムに生成する関数を作成しました。 ( コンテスト中の最後の提出 にも含まれているので、詳細はそちらを確認してください。)
私は 13 がかっこいいと思います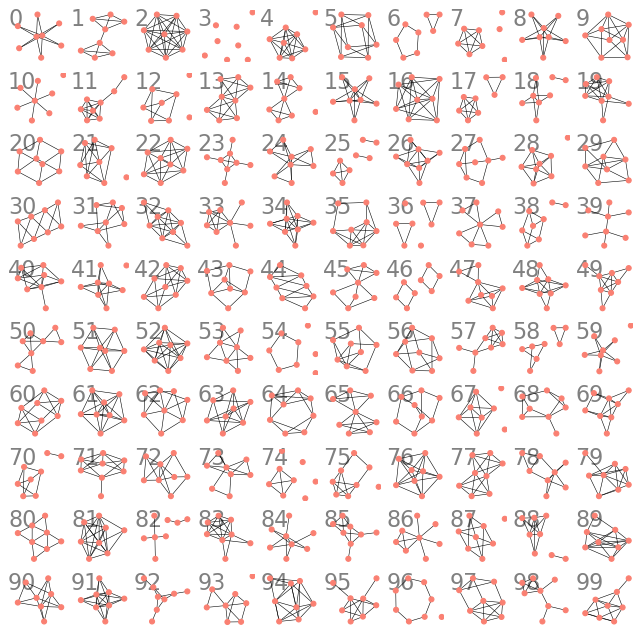
これにより生成された $120$ 個のグラフを使って予測のシミュレーションを行い、
$$ score_{i,j} := \text{正解が $i$ 番目のグラフだった時に NN が出力した $j$ 番目のグラフとの類似度} $$
のような行列を何個も生成します。 実際には入力の $M$ に応じて $1$ 番目から $M$ 番目までのグラフまでを使うとして、$M=10$ から $M=100$ までの精度の平均がなるべく高くなるようなグラフの並べ替えを、$2$ つのグラフの入れ替えを遷移とした山登り法で求めます。山登り法を行った後、後ろの $20$ 個のグラフを新たにランダムに生成したものと入れ替え、これまでのプロセスをまた繰り返すことで、グラフの選択を行いました。 (この並べ替えの方法は、実は最終日に思いついたもので、それまではもっと効率の悪い方法を使っていました。)
回答を AtCoder に提出する際には、グラフを生成するシード値を埋め込みました。
提出への道のり
かなり熱中して取り組んでいたので、ここまでのコードの大枠はコンテスト開始から 3 日くらいでできていました。
解法もできたし、さあ提出するぞ!と行きたいところですが、それはまだできません。 提出のためには、いくつかの面倒な作業が必要でした。
C++ の埋め込み
まず、$\epsilon$ が小さいケースの解法を、Python で提出できるようにします。 最終的な解は Python で提出を行いましたが、途中までは C++ で提出するつもりでいたため、$\epsilon$ の小さいケースを解くためのコードの一部は C++ で書いていました。
幸いにも、2022 年現在の AtCoder のジャッジ環境は Python のコードに C++ のコードを埋め込むことが非常にやりやすくなっています。
AtCoder のジャッジは、提出されたコードに対して、選択された言語に応じて、1 回の「コンパイルコマンド」とテストケースごとの「実行コマンド」が実行される仕組みになっています。
例えば C++ (GCC) であれば、コンパイルコマンドは g++ ./Main.cpp (オプションは省略)、実行コマンドは ./a.out です。
このコンパイルコマンド、Python の場合はどうなっているのでしょうか? その答えは ルール に書かれています。
これを見ると、Python のコンパイルコマンドは bash -c 'python3.8 ./Main.py ONLINE_JUDGE 2>/dev/null' であることがわかります。
すなわち、提出言語に Python を選択した場合は、最初に標準入力無し・ONLINE_JUDGE のコマンドライン引数ありでプログラムの実行が行われるということです。
(Python 以外に Julia も同じような仕様になっているようです。)
これのおかげで、(C++ で constexpr を使ってコンパイル時に計算を行うのと同じように、) Python では入力に依存しない計算を各ケースの実行時間外で予め済ませておくことができます。
import sys
if sys.argv[-1] == "ONLINE_JUDGE":
compile_time_process() # コンパイルコマンドでのみ実行される
この仕様は Numba の AOT コンパイルを行うことを想定して設定されたものと思われますが、今回はこれをありがたく C++ のコンパイルに使わせてもらいます。 加えて、時間のかかる前処理もこの時間で予め済ませておくようにします。
モデルの埋め込み
C++ の埋め込みもできた!さあ提出するぞ!
まだできません。次は、NN を提出できる形にする作業です。
AtCoder 環境で使用できるサードパーティのライブラリは Numba, NumPy, SciPy, scikit-learn, NetworkX のみです。(上記のルール内にリンクのある 言語アップデートテスト用のコンテストページ に記載されています。) NN の学習は PyTorch で行いましたが、AtCoder で PyTorch は使えません。
仕方がないので、NumPy でモデルの推論を書き直します。
また、NN の学習済みパラメータは、全て結合して base64 で文字列にして埋め込みます。
このあたりでモデルの学習コードにバグでリークを起こしていることに気づき、手戻りが発生してしんどくなっていたりします。 また、ハンガリアン法では速度が足りず、グラフ全体の特徴を出力するように変更したのもこのタイミングでした。
アーキテクチャの欠点
ところで、このあたりで NN のアーキテクチャに想定していなかった欠点があることに気づきました。
この NN は、実は $6$ 頂点のサイクルグラフと三角形 $2$ つのグラフを区別することができません。
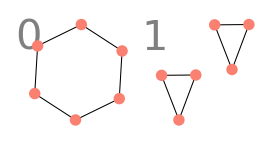
この $2$ つのグラフは、いずれも次数が全て $2$ です。 この場合、NN は全く同じ値を出力することになります。
ここまでかなり強い解法を作れている自信がありましたが、急に不安になります。 良い対応策も思いつかないので、悪影響が軽微であることを願いながら実装を進めていきます。
$N$ の調整
モデルの埋め込みもできた!バグも直した!速度も改善した!さあ提出だ!
まだです。
今回の問題では最初にグラフの数 $M$ とエラー率 $\epsilon$ が与えられ、それに対して「これくらいの頂点数があれば復元できる!」と思える $N$ を自分で決めなければいけません。
これは NN を使った解法と相性の悪いものでした。
NN の精度を高めるには、推論時に実際に NN の入力として与えられるような $M$、$\epsilon$、$N$ の組を使って学習を行いたいです。 簡単すぎたり、難しすぎる問題を NN に与えるのは、恐らくあまり好ましくありません。(もっとも、$M$ は最大でも $64$ とクリップしてしまっていますが……。)
しかし、$M$、$\epsilon$ の組に対してどの $N$ が使われるかは、NN の学習が終わって予測ができるようになってからしかわかりません。つまり、NN の学習のためには $M$、$\epsilon$、$N$ の組が必要で、$M$、$\epsilon$、$N$ の組を求めるためには学習済みの NN が必要です。詰みました。
仕方がないので、最初は色々な条件で学習を行い、それを使ってスコアが最大となるような $N$ の決め方を求めます。これによりできた $M$、$\epsilon$、$N$ の組 (ともう少し厳しい条件となる組) だけを使って学習を行い、改めて $M$ と $\epsilon$ に対応する $N$ を決める……といった繰り返しを行いました。
そして提出へ
$N$ も調整できたぞ!提出していいですか?
いいよ。
OK が出たので提出します。 コンテスト時間は残り 48 時間を切っていました。
コンテスト終了まで
初提出の結果は Runtime Error でした。
コンパイル用の時間で作ったファイルが大きすぎたようです。
直してやって再提出をすると、6 位に入ることができました。
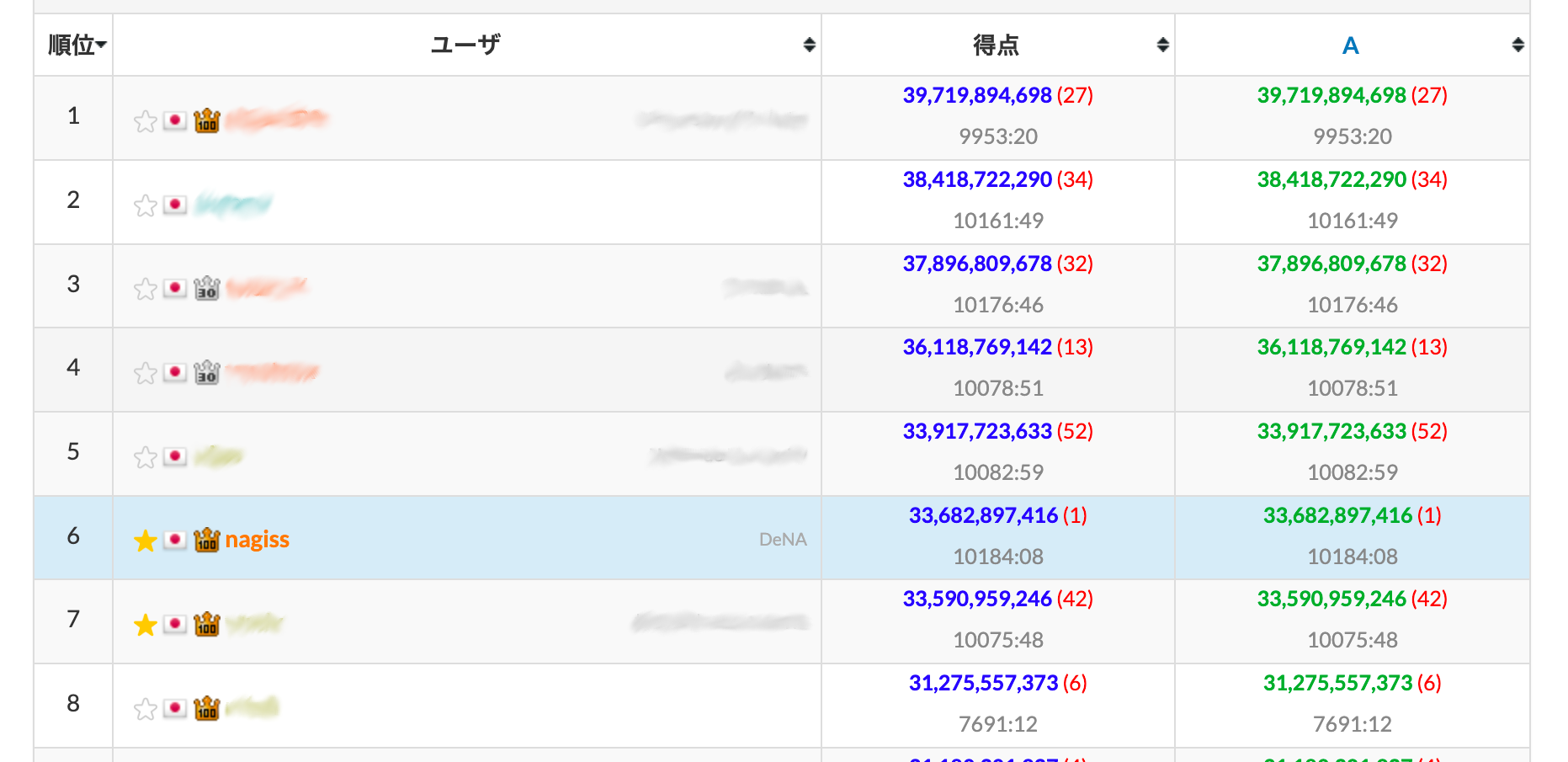
ローカルでの seed 0 から 99 まで 100 ケースの mean(ln(scores)) の値は 16.64 でした。
残り 46 時間、ここから解の改善をしていきます。
$N$ の候補の追加
今回のスコアの計算式では、$\epsilon=0.40$ の場合など、予測成功率が 100% に遠く及ばないようなケースでは、予測成功率の少しの違いがスコアに大きな差を与えます。
これまで、$\epsilon$ の大きいケースは $N$ の候補として ${10, 14, 18, 24, 33, 46, 66, 94}$ の 8 つしか使っていなかったため、候補に $100$ を加え、難しいケースの予測成功率を上げます。
これでローカル評価は 16.73 になりました。 3 回目の提出をしますが、順位表でのスコアはあまり変わりませんでした。 そこまで頻度の高くなく、運要素が大きい上にトップが得点を総取りするケースの改善なので、まあそういうこともあるかと思い直します。 コンテストは残り 41 時間です。つまり、今は夜中の 2 時なので寝ます。
起きました。 さらに、$N$ の刻み幅をより細かく ${12, 14, 16, 18, 20, 24, 28, 33, 39, 46, 55, 66, 79, 94, 100}$ とし、 $M$ と $\epsilon$ から $N$ を決定するチューニングも、$\epsilon$ の幅をより細かくして行うようにしました。 加えて、チューニングが行われていない $M$ と $\epsilon$ の組では、バイリニア補間を使って $N$ を求めるようにしました。
ローカル評価は 16.84 まで上がリました。 今は土曜日の午後 5 時、残り 26 時間です。
ここで、すでにある程度良いグラフの選択はできていると信じて、NN の学習時に使うグラフも固定してしまいます。 ローカル評価 16.89 になります。 提出を行うと、順位は 3 位と 2 位を行ったり来たりする位置まで上がりました。もうちょっと……!
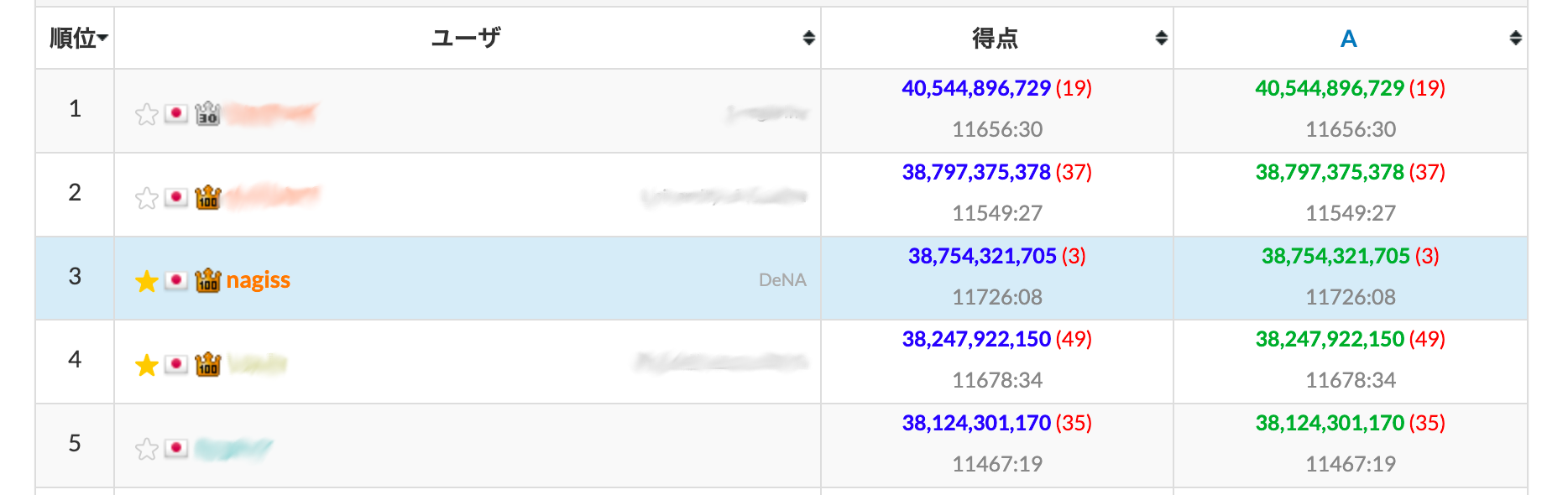
しかし困ったことに、有効そうな改善策のスタックは既に空になっていました。 コンテストは残りはもう 20 時間しかありません。 一体何をすれば……。
最終日
やることが思いつかないので、予測がどれくらい上手くいっているのかを分析してみます。 試しに難しめのケースで混同行列をプロットしてみると、割と均等に間違っています。ん??
これはおかしいです。私の今の解法は、グラフを $100$ 個用意して、その左から $M$ 個を実際に使っています。 うまくグラフの選択を最適化できていれば、$1$ 番目のグラフを $2$ 番目のグラフだと間違って推測してしまう確率は、$99$ 番目のグラフを $100$ 番目のグラフと間違って推測してしまう確率よりも低くなるはず。混同行列で言えば、左上部分はそれ以外よりも対角成分以外の値が小さくなるはずです。
ここで、$100$ 個のグラフの並び替えだけで精度を上げることを思いつきます。 混同行列を並び替えて左上の対角成分に値が集まるようにするイメージです。
これを $N=100$ に適用してスコア 16.92、それ以外の $N$ にも適用してスコア 16.94 を得ます。時刻は午前 4 時、残り 15 時間です。
また、NN の各 embedding をプロットしてみるとあまり綺麗では無かった ($\epsilon$ や次数に対する単調性が見られなかった) ので、一度値を 0 にリセットして再学習を行っていました。 埋め込むモデルをこれに差し替え、スコア 16.95 を得ます。
さらに、グラフの並び替えによる最適化を使って、$100$ 個のグラフ自体の選択も行うようにしました。 (これがグラフの選択の項で説明したものです。) まず $N=100$ に適用して 17.99 と大きくスコアを伸ばします。 全ての $N$ で計算を行うのは時間がかかりましたが、午前 10 時頃に 17.03 のスコアを得ました。 前回の提出からは 0.14 増加しており、順位表でのスコアは $\exp 0.14 \approx 1.15$ 倍程度になることが期待できます。 このあたりで勝ちを確信します。
提出はもう少し引き延ばします。 相手の嫌がることをするのが対戦ゲームの鉄則です。 他のトップ層には、スコアがあと 1.05 倍になれば勝てると思わせておいて、作戦を狂わせましょう。 駄目だ、まだ笑うな……と独りごちながら順位表を眺めるとなお良いです。
全体的に精度が良くなったので、$N$ のチューニングをやり直し、スコアは 17.07 に。 また、グラフ集合を新しいものに替え、学習率も落として学習させたモデルを埋め込むことで、最終的に 17.11 のローカル評価を得ました。
もう眠いので、手元で 2000 ケースを回してエラーが起こらないか確認し、いよいよ提出です。
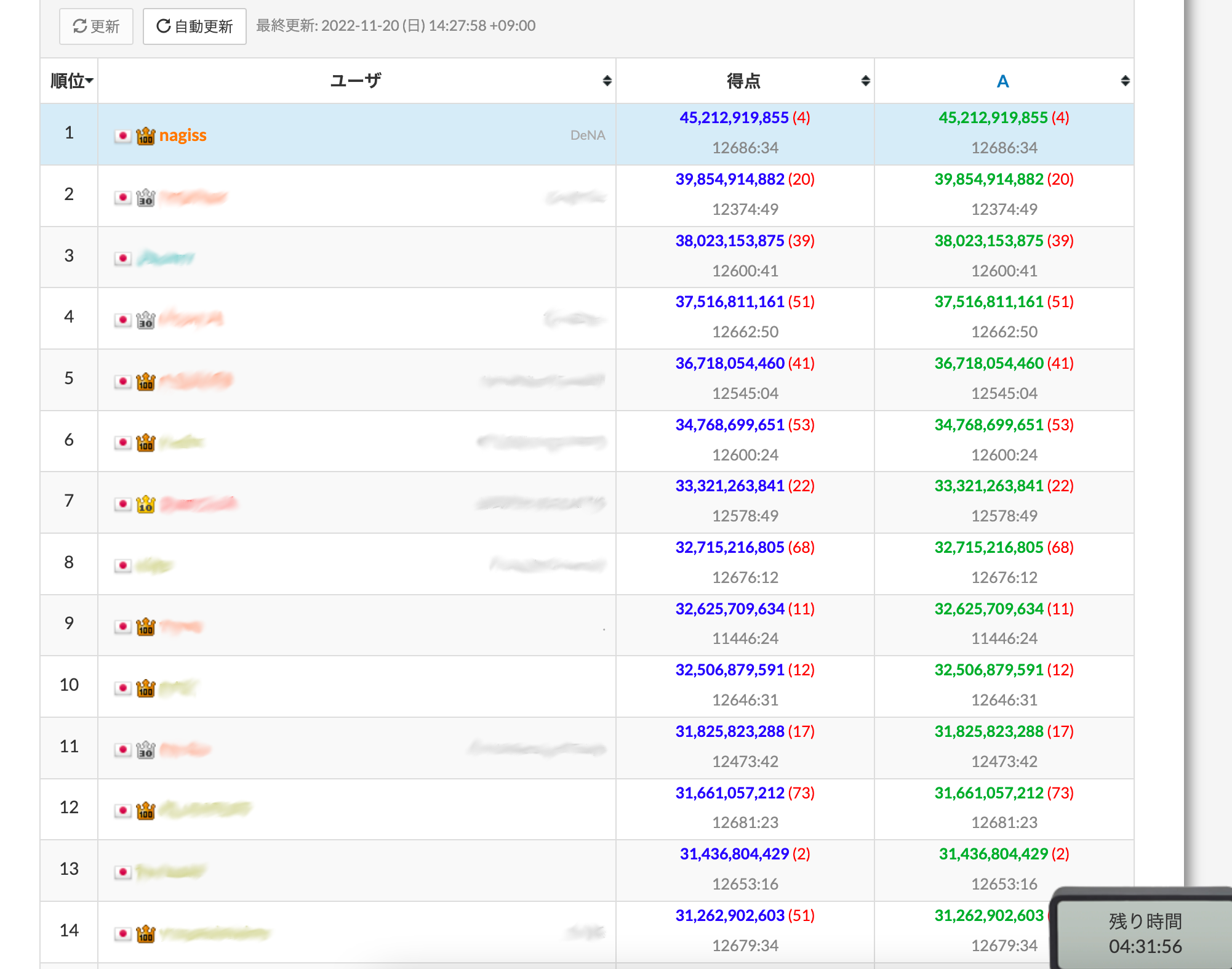
残り 4 時間半、2 位に十分差を付けて 1 位に立つことができました。
コンテスト後の戦い
その後大きな順位の変動も起こらず、コンテストは終了時刻を迎えました。
良い気持ちで Twitter の感想戦 TL を眺めていると、こんなツイートが流れてきます。
【AHC016】ご参加ありがとうございました。解説配信は19:30からの開始となります。皆様の度肝を抜く解説を用意しておりますので、ぜひご期待ください!#AHC016 #HTTF
— AtCoder (@atcoder) November 20, 2022
HACK TO THE FUTURE 2023 予選 解説配信 https://t.co/NYIqyAtlvs
今回のコンテストでは、終了後にフューチャーの ツカモさん と問題作成者の wata さん による解説配信が企画されていました。
それにしても、度肝を抜く解説とは一体何なのでしょうか。 まさか 1 位よりめっちゃ高いスコアが出るとか? いやいやそんなことないでしょ、我 Kaggler ぞ? Kaggler の作った NN モデルぞ?
解説配信を見ます。
wata さん「ちなみに自分の解法はどれくらい出たかっていうと」
「これくらいでました」
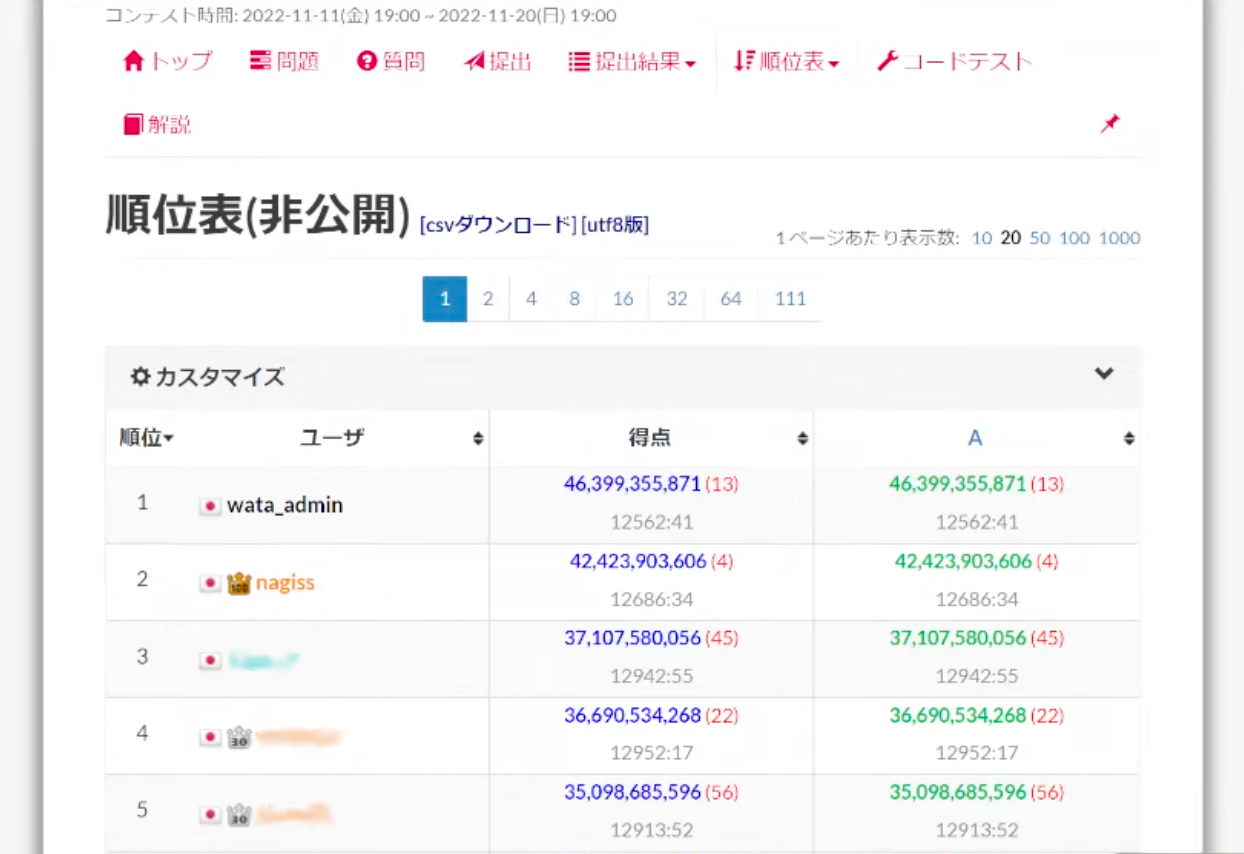
!?!?!?😱🤬🤢🤢🤮🤮🤮🤮😈😣😭😭😭
おしまいです。私は予測モデルの精度で人力を超えられない Kaggler でした。 これからは職人芸の時代としてアナログトランスフォーメーションを推進していきます。
……本当にこのまま終わっていいのでしょうか?
ここまでの内容を堂々と「1 位」解説としていいのか?
配信見てて気持ちよかったところw#HTTF #AHC016 pic.twitter.com/yod6ckYP9V
— chokudai(高橋 直大)🍆@AtCoder社長 (@chokudai) November 20, 2022
1 週間頑張った結果が chokudai さんを気持ちよくさせて終わるのでいいのか?
嫌です。 せめて wata さんの解法と同じくらいの点数を出せるようになってから、1 位解法を書きたい。
ここから HTTF2023 予選は延長戦が始まっていきます。
結果
結論から言えば、解説配信で説明されていた手法をいくつか取り込み、ここまでスコアを上げられました。
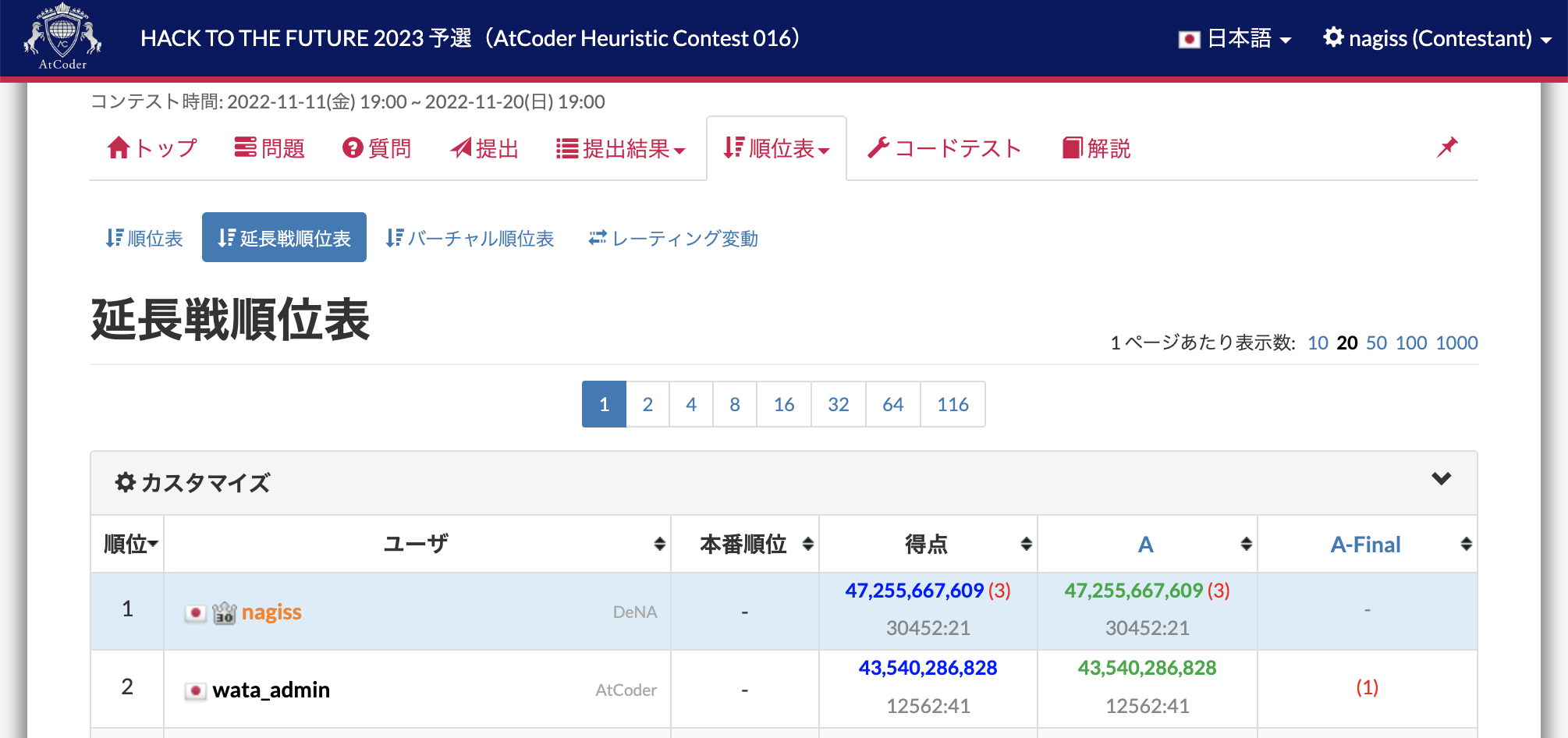
該当の提出コードは こちら です。
ここからは、どのようにしてこのスコアを得られたかの解説になります。
$\epsilon$ の大きいケースの改修
冷静になると、NN を使って予測を行った部分が職人芸に引けを取るとはあまり思えません。
私の解法の中で、最も手応えの無かった部分は、最初に出力する $M$ 個のグラフ $G_s$ をどう選ぶかというところでした。 これが敗因のような気がします。 この部分は、素直に解説配信の wata さんの解を真似することにします。
解説配信によれば、wata さんの解では $5$ 頂点のグラフを $D$ ($3 \le D \le 20$) 倍に冗長化することで $N=5D$ 頂点のグラフを作り、$G_s$ の候補としているようでした。 $5$ 頂点のグラフは $34$ 通りしか無く、$M \ge 35$ の場合に対応できないように思えますが、冗長化後に元の頂点をクリーク (全ての頂点間に辺が張られている) とするか孤立点 (どの頂点間にも辺が張られていない) とするか変えることによって候補は $544$ 通りに増えるようです ( OEIS A000666 )。
赤は孤立点、黒はクリーク
また、予測モデルにも以下のような改善を行いました。
- 予測精度にあまり寄与していなかったハンガリアン法関連の要素を全て取り除く
- 学習が数倍〜十数倍高速化されたのでその分多いステップ数の学習が可能に
- 予測結果の候補となるグラフが実質 $544$ 個に絞られたため、$544$ クラス分類問題として解くようにアーキテクチャ・学習方法を変更
- 埋め込めるデータの大きさにまだ余裕があったため、NN は大きいほど強いと信じて Attention を 1 層増やす
- 推論時、補グラフでも予測を行う Test-Time Augmentation を実施
これにより、最大ケース $(M=100, \epsilon=0.40)$ での予測の成功率は $72 \%$ まで上がりました。
$\epsilon$ の小さいケース
コンテスト中に私の作成した解は、解説配信で解説のあったものと基本的な部分では同じでしたが、解説配信では式変形を非常に上手く行って計算量を削減していました。 このため、私はコンテスト中 $N=8$ までしかこの方法を使えませんでしたが、wata さんは $N=9$ まで (ほぼ) 最適な解を出せていました。
(ほぼ) 最適な解は、以下のようにして得られます。 (解説配信と別の視点での解説です。)
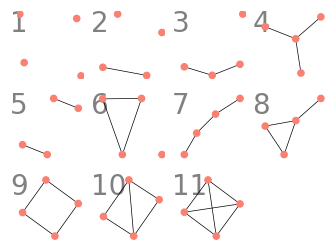
例として、$N=4$、$M=5$、$\epsilon=0.1$ の場合を考えます。 $N=4$ のグラフは以下の $11$ 種類なので、このうち最も識別しやすい $5$ 個のグラフを選び、識別する問題となります。 以降、この $11$ 種類のグラフをそれぞれ第 $1$ グラフ、第 $2$ グラフ、……、第 $11$ グラフと呼ぶことにします。
まず、ノイズが加わることによって第 $i$ グラフが第 $j$ グラフに変化する確率を $i$ 行 $j$ 列の要素とした表 (通信路行列) を作ると、以下のようになります。(求め方は後述)
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | .531 | .354 | .079 | .003 | .020 | .003 | .009 | .001 | .000 | .000 | .000 |
| 2 | .059 | .564 | .242 | .013 | .061 | .013 | .040 | .006 | .001 | .000 | .000 |
| 3 | .007 | .121 | .571 | .061 | .013 | .061 | .124 | .033 | .007 | .003 | .000 |
| 4 | .001 | .020 | .182 | .532 | .002 | .020 | .040 | .182 | .002 | .020 | .001 |
| 5 | .007 | .121 | .053 | .003 | .532 | .003 | .239 | .027 | .013 | .003 | .000 |
| 6 | .001 | .020 | .182 | .020 | .002 | .532 | .040 | .182 | .002 | .020 | .001 |
| 7 | .001 | .020 | .124 | .013 | .060 | .013 | .565 | .124 | .060 | .020 | .001 |
| 8 | .000 | .003 | .033 | .061 | .007 | .061 | .124 | .571 | .013 | .121 | .007 |
| 9 | .000 | .003 | .027 | .003 | .013 | .003 | .239 | .053 | .532 | .121 | .007 |
| 10 | .000 | .000 | .006 | .013 | .001 | .013 | .040 | .242 | .061 | .564 | .059 |
| 11 | .000 | .000 | .001 | .003 | .000 | .003 | .009 | .079 | .020 | .354 | .531 |
仮に、第 $1$ から 第 $5$ までの $5$ つのグラフを元のグラフとして選んだとして、ノイズの加わったグラフから元のグラフを予測する方法を考えてみます。 ノイズが加わる前のグラフが第 $1$ から第 $5$ までであるから、表の $1$ 行目から $5$ 行目に注目します。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | .531 | .354 | .079 | .003 | .020 | .003 | .009 | .001 | .000 | .000 | .000 |
| 2 | .059 | .564 | .242 | .013 | .061 | .013 | .040 | .006 | .001 | .000 | .000 |
| 3 | .007 | .121 | .571 | .061 | .013 | .061 | .124 | .033 | .007 | .003 | .000 |
| 4 | .001 | .020 | .182 | .532 | .002 | .020 | .040 | .182 | .002 | .020 | .001 |
| 5 | .007 | .121 | .053 | .003 | .532 | .003 | .239 | .027 | .013 | .003 | .000 |
ここで、ノイズが加わった後のグラフとして第 $6$ グラフを受け取ったとき、元のグラフはどれであったと考えられるでしょうか?
これは、表の $6$ 列目を見ることで答えることができます。 表の $6$ 列目には、第 $1$ グラフが第 $6$ グラフに変化する確率は $0.003$、第 $2$ グラフが第 $6$ グラフに変化する確率は $0.013$、……、と書かれています。 このうち最も高い確率が書かれている (最も尤度が高い) のは $3$ 行目であるから、ノイズが加わる前は第 $3$ グラフだったと答えることが、最も精度の高い予測となります。
他のグラフを受け取った時も同様に考え、各列で最も精度の高い予測となる番号の行が黒くなるように色を塗り直すと、以下のようになります。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | .531 | .354 | .079 | .003 | .020 | .003 | .009 | .001 | .000 | .000 | .000 |
| 2 | .059 | .564 | .242 | .013 | .061 | .013 | .040 | .006 | .001 | .000 | .000 |
| 3 | .007 | .121 | .571 | .061 | .013 | .061 | .124 | .033 | .007 | .003 | .000 |
| 4 | .001 | .020 | .182 | .532 | .002 | .020 | .040 | .182 | .002 | .020 | .001 |
| 5 | .007 | .121 | .053 | .003 | .532 | .003 | .239 | .027 | .013 | .003 | .000 |
実は、この黒いマスに書かれた値を全て足し合わせ、$M=5$ で割った値は、第 $1$ グラフから 第 $5$ グラフまでを元のグラフとして選んだ場合の予測の成功率になっています。何故でしょうか?
元のグラフが第 $3$ グラフだった場合、表を見ると第 $3$、第 $6$ グラフを受け取った場合は元が第 $3$ グラフと予測することになっているので、第 $3$、第 $6$ グラフに変化した場合のみ予測が成功します。 すなわち、元のグラフが第 $3$ グラフだった場合の成功率は、第 $3$ グラフが第 $3$、第 $6$ グラフのいずれかに変化する確率に等しく、これは $3$ 行目の黒く塗られたマスの値の和です。 同様に、元のグラフが第 $n$ グラフだった場合の成功率は $n$ 行目の黒く塗られたマスの値の和です。 元のグラフは一様な確率で選ばれるため、各確率の平均値を取れば、全体としての予測の成功率が求められます。 結局、操作としては、全ての黒いマスの値を足し合わせ、$M$ で割ったことになります。
さて、これで $M$ 個のグラフを元のグラフとして選んだ時に、予測の成功率が求められるようになりました。 あとは、予測の成功率がなるべく高くなるような $M$ 個のグラフを、山登り法や焼きなまし法などによって求めれば良いです。 今回の設定で実際に計算すると、第 $1,4,6,9,11$ グラフを選んだ時に予測成功率は最大値 $0.798$ を取ります。
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | .531 | .354 | .079 | .003 | .020 | .003 | .009 | .001 | .000 | .000 | .000 |
| 4 | .001 | .020 | .182 | .532 | .002 | .020 | .040 | .182 | .002 | .020 | .001 |
| 6 | .001 | .020 | .182 | .020 | .002 | .532 | .040 | .182 | .002 | .020 | .001 |
| 9 | .000 | .003 | .027 | .003 | .013 | .003 | .239 | .053 | .532 | .121 | .007 |
| 11 | .000 | .000 | .001 | .003 | .000 | .003 | .009 | .079 | .020 | .354 | .531 |
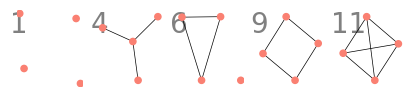
ところで、「グラフ $G$ がグラフ $H$ に変化する確率」というのは、どうやって求めるのでしょうか?
まず、頂点の順序を固定した場合 (どちらのグラフの頂点にも $1$ から $N$ までのラベルが振られていて、頂点の対応付けが取られている場合) に、グラフ $G$ がグラフ $H$ に変化する確率を考えます。
これは、$_NC_2=\frac{N(N-1)}{2}$ 通り全ての頂点のペアに対し、その間の辺の有無の変化の確率を求め (変化があるなら $\epsilon$、無ければ $1-\epsilon$)、全てが同時に起こる確率を求めれば良いです。 辺の有無に変化のあった頂点ペアの個数を $k$ とおけば、この確率は $\epsilon^k (1-\epsilon)^{\frac{N(N-1)}{2}-k}$ と書くことができます。
これで、ラベル付きグラフ $G$ からラベル付きグラフ $H$ に変化する確率は求められました。 そして、ラベル無しグラフ $G$ からラベル無しグラフ $H$ に変化する確率は、 $G$ に対する $2^{\frac{N(N-1)}{2}}$ 通りの辺の変化のうち、$H$ と同型なグラフになるものについて上記の計算を行い、総和を取ることで求められます。
……コンテスト中の私の考察はここまででした。
発想を変えると、ラベル無しグラフ $G$ からラベル無しグラフ $H$ に変化する確率は、以下のようにも求めることができます。
- $H$ へのラベルの振り方を、適当な一つに固定する。
- 全ての $G$ のラベルの振り方に対し、ラベルを付けた $H$ への変化確率を辺の有無の変化の個数 $k$ を使って計算し、平均を取る。
2.で求めた確率に、$H$ へのラベルの振り方の種類の数 ($|L(H)|$、後述) を乗算する。
こちらの方が効率の良い計算ができそうです。 解説配信でこの 2. の値は、
$$ \begin{align} p(H|G) &= \frac{1}{N!} \sum_\pi p_{N,\epsilon}\left(d(\pi(G),H)\right) \\ d(A, B) &:= A と B で異なる辺の数 \\ p_{N,\epsilon}(k) &:= \epsilon^k(1-\epsilon)^{\frac{N(N-1)}{2}-k} \end{align} $$
と表現されています。$\pi$ は頂点の並び替えを表しています。
そして、このアルゴリズムはさらに効率を高めることができます。
先にも述べましたが、この方法を使って山登り法などで選ばれた $M$ 個のグラフを観察してみると、対称的な構造を持ったものが多いことがわかります。
43 もかっこいいですね
グラフ $G$ が対称的な構造を持つということは、$G$ の $N!$ 通りの頂点ラベルの並べ替えの中に、辺の張られ方が (隣接行列が) 等しいものが複数回現れることを意味します。 つまり、上記の計算方法では、途中で何度も同じ計算が発生し、計算時間を無駄にしていることになります。
隣接行列が等しくなるものを同一と見做した、頂点ラベル付きの $G$ の集合を $L(G)$ と書きます。($G$ の隣接行列の集合、と考えた方がわかりやすいかも。) $L(G)$ 自体と、$G$ の $N!$ 通りの並べ替えで $L(G)$ それぞれが何度現れるかが予め分かっていれば、上記の確率計算の計算量を $O(N!)$ から $O(L(G))$ に減らすことができます。 提出プログラムの中でこの計算は最大 $10000$ 回行う必要があるため、$O(N!)$ では $N=8$ が限度ですが、$O(L(G))$ であればそれより大きい $N$ でも厳密な計算が可能になります。 (ここでは辺の数が十分小さく、辺の変化した箇所の数の計算は POPCNT 命令で $O(1)$ としています。)
現れる回数は前計算で数えれば良いですが、実は、$N$ 頂点のグラフ $G$ に対し、$N!$ 通り全ての順列を使って $G$ の頂点へのラベル付けを行うと、隣接行列の等しいラベル付きグラフが同じ個数ずつ現れます。
この個数は $|\mathrm{Aut}(G)|$ で表されます。 $|\mathrm{Aut}(G)|$ は、(頂点に何らかの順序付けをした) グラフ $G$ に対して、作用させた後も元のグラフと隣接行列が等しくなるような頂点の置換の種類数です。 例えば、$G$ が 1-2-3 のような頂点数 $3$ のパスグラフである場合は、置換 $(1, 2, 3)$ または $(3, 2, 1)$ を作用させた時のみ、隣接行列が元と同じ $$ \begin{pmatrix} 0 & 1 & 0 \\ 1 & 0 & 1 \\ 0 & 1 & 0 \end{pmatrix} $$ となるため、$|\mathrm{Aut}(G)| = 2$ となります。
また、グラフ $G$ の隣接行列の種類の数 $|L(G)|$ は、$|L(G)| = \frac{N!}{|\mathrm{Aut}(G)|}$ と表せることがわかります。 これを使うと、解説配信で紹介されていた正解確率の期待値の式 $$ p(success) = \frac{1}{M}\sum_{H:unlabelled} \max_s \frac{|L(H)|}{|L(G_s)|} \sum_{G’ \in L(G_s)} p_{N,\epsilon}(d(G’, H)) $$ を導くことができます。(さらっとこの式が出てくる解説配信、恐ろしいです。)
さて、問題作成者による解ではこれで $N=9$ まで解いているわけですが、先述のコンパイル用時間で前計算する方法を使えばもうちょっと頑張れそうな気がします。 (公式がこんな変なことを想定解としていたら顰蹙を買いそうですが、いちユーザなので無敵です。) 実際に試してみると、$N=10$ までこの方法で解くことが可能でした。
おわりに
今回のコンテストは、AtCoder で開催されたヒューリスティック系のコンテストの中で最も熱中した回でした。 あらゆる領域 (今回であれば機械学習、最尤推定、情報理論、群論) からヒントを得て、 あらゆる手を使ってスコアを伸ばすのがヒューリスティックコンテストの醍醐味だと思っており、 今回はそれを上手く行うことができたので満足です。 (コンテスト中に Writer 解を超えることができなかったのは悔しくありますが。)
最後に、今回コンテストを開催していただき、この記事の公開を許可していただきましたフューチャー株式会社様に深く感謝申し上げます。
フューチャーグループは「ITコンサルティング&サービス事業」と「ビジネスイノベーション事業」を展開するソーシャルデザインカンパニーです。「ITコンサルティング&サービス事業」では、AI、IoTなど最新テクノロジーをベースにデータ活用からビジネスモデルのデザイン、実装、さらにはDX人材育成など様々な業種・業界のお客様のDXを推進しています。2018年からはマラソン形式の競技プログラミングコンテストHTTF(HACK TO THE FUTURE)を主催しています。


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。