





はじめに
2022年の夏にAIスペシャリストコースのインターンシップに参加させていただきました、浜野と申します。 大学では深層学習のロボティクスへの応用を研究しています。
今回、インターンシップにてライブコミュニケーションアプリ「Pococha」のレコメンド改善に取り組みました。 レコメンドの実装自体初めてで、恐らく王道と呼べる手法ではない気がしますが、これも何かの折、せっかくなのでインターンシップでの取り組みを本記事にて報告させていただきます。
ご一読いただけると幸いです。
取り組んだ課題に関して
私はインターンシップにて「ライブコミュニケーションアプリ『Pococha』におけるロングテールプラットフォームを実現するための推薦モデルの開発」というテーマに取り組みました。
(これがDeNAのブログ記事だと思うと若干書きにくいのですが) 本インターンシップにて初めてPocochaをインストールしました。 YoutubeやAmazon Primeはよく視聴しますが、所謂「ライブコミュニケーションアプリ」と呼ばれるものは使ったことがありませんでした。 まずはサービスを知るという意味でも、様々なライバーのライブ配信を見に行きましたが、配信部屋に入った時にライバーの方に挨拶されると、どうにも照れ臭さを感じますね。
アプリを使っていると、それこそYoutubeやAmazon Primeなどと異なり、レコメンドの難しさが垣間見えました。 というのも、当たり前のことですが、事前に内容がわかっている動画コンテンツと異なり、ライブ配信はその内容がその瞬間にならないとわからないという特性があります。 したがって、内容に基づいたレコメンドの実装はかなり困難です。 他のサービスではジャンルごとのレコメンドなどもよく見かけますが、配信の内容にそこまで大きな差異のない特性上こうしたレコメンドも現実的ではありません。 結果、下図からも分かる通り、人気なライバーのレコメンド、盛り上がっている配信のレコメンド、性別ごとのレコメンドなど、十数個のタブに基づくレコメンドに限られており、そこまで幅広いレコメンドの実装ができていないという現状があります。 インターンシップでは、こうした現状のレコメンドモデルを改善する手法の開発を行いました。
PocochaのUI上にあるレコメンド用のタブ
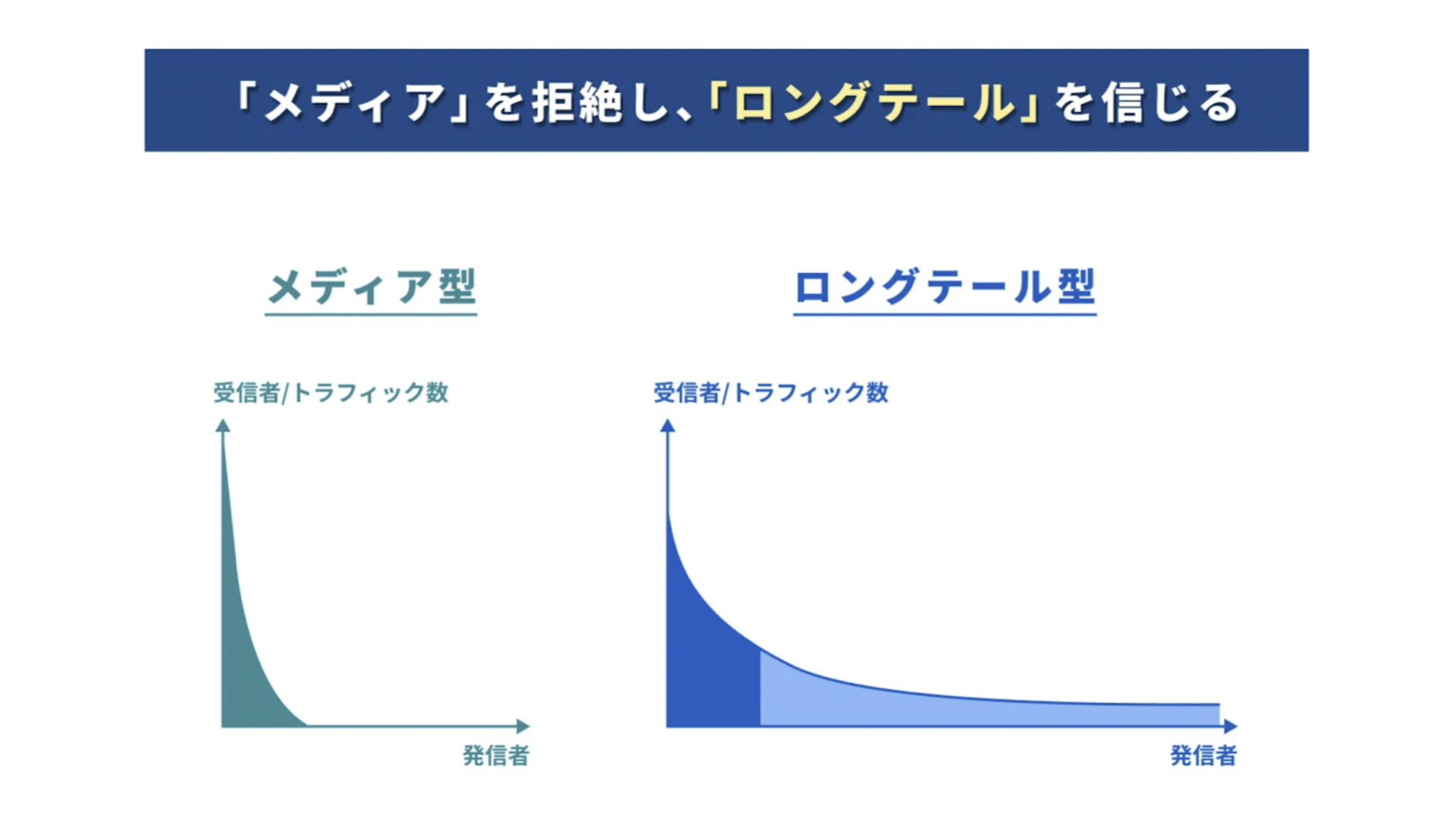
ロングテール
中でも「ロングテールを実現するレコメンドの開発」が今回取り組んだテーマでした。 ロングテールなレコメンドとは、端的に言えば「より多様なライバーをレコメンドする」ということです。 Pocochaでは、一部の人気なライバーばかりにリスナーが集まるのではなく、誰もがクリエイターとして自分の居場所を持っているような"円形の"サービス構造を目指しています。 大事なのは、レコメンドを通して全ての人々にスポットライトを当てることにあります。 人気が高いものを当たり前のように推薦するのではなく、偏りのない多様なライバーのレコメンドを可能にするシステムの実装、これが本テーマの重要課題でした。
チャレンジングな点
本テーマの難しい点は、ただ単純に多様なライバーが満遍なくレコメンドされれば良いわけではないところにあります。 リスナーにライバーをレコメンドし、実際に見てもらう、ここまでできて初めてコミュニティの形成に繋がります。 リスナーがサービスを楽しめるように、興味のあるもの、面白いと思うもの、見たいと思うものをレコメンドしなければなりません。 したがって、それぞれのリスナーが見てくれそうなライバーをレコメンドするという大前提のもとで、人気なライバーばかりに集中しないようなレコメンドシステムを開発する必要がありました。
以上まとめると本テーマでは以下の2つの要件を満たす必要があります。
- 前提として、各リスナーが見てくれそうな配信をレコメンドすること(レコメンドとしての精度が高いこと)
- レコメンドされるライバーが一部のライバーに偏ることなく、ロングテールになっていること
手法
こうした条件を満たすために、今回私はリスナーがあるライバーの配信をどれだけ気に入ったかを示す指標を定義し、これに基づいてレコメンドを行うシステムを開発しました。 指標の定式化において何点か工夫を施すことで、ロングテールの実現を目指しました。
レコメンドアルゴリズムの全体像
今回実装したレコメンドシステムの全体像を説明します。 主に以下のような処理に基づいてレコメンドを行います。
- 事前に取得可能なライバー情報とリスナー情報などから、あるリスナーがそのライバーの配信をどのくらい気に入るかを予測します。
- 各リスナーにつき、候補となる複数のライバーに対してこの指標を予測し、それらをリスナーごとにソートします。
- 指標が上位のライバーをレコメンドします。
なお、レコメンドに使用した、お気に入り度合いを表す指標は便宜上Preference score (PS)と呼ばせていただきます。
レコメンドシステムの概要図
PSの予測にはLightGBMを使用し、以下のような入力・出力を扱いました。
- 入力
- ライバー情報 (ライバーの年齢・性別、ライバーランクなど)
- リスナー情報 (リスナーの年齢・性別、視聴者がよく見るライバーの年齢・性別)
- 配信時間
- 過去のPSのラグ特徴量
- 過去に視聴履歴があるリスナーxライバーのペアに対しては3回前までの視聴時のPSをラグ特徴量として使用しました。
- 出力: PS
Preference score
本手法の一つのキモはPSをどのように定義するかというところにあります。 Pocochaのサービスの中でPSを計測し、記録しているわけではないため、実際に収集されているデータから独自に定義する必要があります。 そこで、今回は実際に集計されている指標をそのまま用いたもの、複数を組み合わせて定式化したもの、機械学習を用いたものなど、合計で8種類の指標(PS)を用意しました。
まず、すでに集計されているデータの中でPSとして使用できそうなものを4つ選択しました。
- Time (あるリスナーがあるライバーの配信を見た視聴時間)
その配信を気に入ったかどうかを表す指標として視聴時間を用いることを考えました。 リスナーが気に入ったライブ配信は長く視聴すると考えたからです。 この場合、実際のレコメンドでは、未来・未知のライバーとリスナーのペアに対してどれくらい視聴するかを予測し、予測した視聴時間が長いライバーをレコメンドすることになります。 - Comment (あるリスナーがあるライバーの配信で送ったコメントの数)
1と同様に、コメント数を利用することも考えました。 Timeと同じように気に入ったライバーの配信には多くのコメントをするのではないかという仮説に基づきます。 - Coin (あるリスナーがあるライバーの配信で送ったコインの枚数)
1と同様に、コイン数の利用を考えました。 TimeやCommentと同じく、気に入ったライバーの配信には多くのコインを使用するのではないかという仮説に基づきます。 - Yell (あるリスナーがあるライバーの配信を視聴した時に、ライバーに対してリスナーが獲得していたエール)
Pocochaにはエールという機能があります。 特定のライバーに対して視聴時間やコメント数など一定の条件を満たすとエールを獲得することができます。 一定以上のエールを獲得するとそのライバーのプチファンやコアファンになることができ、ライバーとより親密になれるのです。 既存の指標としてはYellが最もPSに近いと感じ、こちらも使用することにしました。
このように既存の指標をPSの候補として用意しましたが、これらには長所・短所があります。 例えば、TimeやComment、Coinに関しては、すでに集計済みのデータであるため使い勝手が良い反面、1元的な指標だけでは多様なユーザの行動を捉えにくいという欠点があります。 また、Yellに関して言えば、
- TimeやComment、Coinなどの複数の指標から総合して決定されること
- リスナーがライバーをどれくらい気に入っているかをまさに表していること
という、今回のリコメンドシステムでの運用において強い利点があります。 しかし一方で、エールに基づいたレコメンドでは
- エールが高い人気なライバーばかりがレコメンドされやすくなり、ロングテールになりにくい
- エールは過去の視聴データ(過去配信での視聴時間やコメント数)などに応じて獲得されるので、初めてみるライバーや、新規ライバーのレコメンドが難しい
という欠点があります。そこで、既存の指標をそのままPSとして使うのではなく、独自の定式化を行うことで、ロングテールを意識したPSを作成しました。
-
$ PS_1(yell) $ $$ PS_1(yell) = \frac{Yell}{ライバーランク +\ \delta} $$ ライバーランクで割る、すなわちライバーランクが高い(人気な)ライバーほどPSが小さくなるように補正することで、Yellの問題点の1つであった人気ライバーへの露出の集中を緩和させました。
-
$ PS_{2, LinearRegression}(time, comment, coin) $ $$ PS_{2, LR}(time, comment, coin) = \frac{\alpha \times time + \beta \times comment + \gamma \times coin}{ライバーランク +\ \delta} $$ $PS_1(yell)$ではYellを使用しているため、依然として過去データへの依存性という欠点を孕んでいます。 したがってYellを使用するのではなく、TimeやCommet、Coinを使用することで、過去データへの依存性を無くしました。 過去にそのライバーをどれだけ見ていたかに関係なく、その時のライブ配信が、リスナーにとってどれくらい気に入ったかを示すことになります。 初めて見るライバーの配信でも、視聴時間が長くなれば、コメント数やコイン数が多ければPSも大きくなります。 今回は線形結合により定式化を行いました。 係数に関しては視聴時間、コメント数、コイン数と獲得できるエールの条件から線形回帰により算出しました。 (参考サイト: https://avex.jp/livestar/magazine/pococha_yell )
- $(\alpha, \beta, \gamma) = (-0.0595, 166, -0.132)$
-
$ PS_{3, LinearRegression}(time, comment, coin) $ $$ PS_{3, LR}(time, comment, coin) = \frac{\alpha \times time + \beta \times comment + \gamma \times coin}{ライバーランク +\ \delta} $$ $ PS_{2, LR}(time, comment, coin) $の係数について一部負のものがあり違和感を感じました。 というのも、PSとTime, Comment, Coinには正の相関があるはずだからです。 実際に相関係数に着目するとCommentとの相関が極端に大きく他の指標を活かせていませんでした。 そこで、Time, Comment, Coinとの相関がほぼ同等になるように係数を調整し、これを$ PS_{3, LR}(time, comment, coin) $としました。
- $(\alpha, \beta, \gamma) = (1/7000, 1/150, 1/2500)$
相関係数 $ PS_{2, LR}(time, comment, coin) $ $ PS_{3, LR}(time, comment, coin) $ Time 0.44 0.68 Comment 0.97 0.68 Coin 0.07 0.67
- $(\alpha, \beta, \gamma) = (1/7000, 1/150, 1/2500)$
-
$ PS_{4, LightGBM}(time, comment, coin) $ $$ PS_{4, LightGBM}(time, comment, coin) = LightGBM(time, comment, coin) $$ $ PS_{2, LR}(time, comment, coin) $や$ PS_{3, LR}(time, comment, coin) $ではパラメータチューニングが問題となりました。 日々更新されるデータに対して都度調整するのは非効率的で運用上のコストも高くなってしまいます。 そこで、Time, Comment, Coinから機械学習を用いてPSを計算する手法を考えました。 機械学習はあくまで教師あり学習であり、正解データが必要となります。今回は暫定的にYellを正解データとして使用しました。 すなわち、Time, Comment, CoinからYellを回帰するモデルを作成しました。
- 入力: Time, Comment, Coin
- 正解データ: Yell
- 使用したモデル: LightGBM
様々な指標(PS)が出ましたが、もう一度システムの全体像を確認しておきます。 今回私がやりたかったのは、こうした指標を、ライバー情報やリスナー情報、その他過去のラグ特徴量から予測し、これに基づいてレコメンドを行うということです。 $ PS_{2, LR}(time, comment, coin) $や$ PS_{3, LR}(time, comment, coin) $、$ PS_{4, LightGBM}(time, comment, coin) $では、PSを用意する段階で、入力にTime, Comment, Coinを用いた回帰モデルを使用していますが、指標の定義とレコメンドの実装で2段組みの構造になっていることに注意してください。
まとめるとこのようなステップにて作業を進めました。
- 指標(PS)の定義
Coin, Time, Comment, Yellなどを用いてPSを定義する。
($ PS_{2, LR} $や$ PS_{3, LR} $、$ PS_{4, LightGBM} $では回帰モデルを使用。) - レコメンドの実装
ライバー情報、リスナー情報、過去の視聴情報などからPSを予測する。
実験
今回作成したレコメンドシステムの性能を評価するために、2つの実験を行いました。 どちらの実験でも共通のデータセットを使用したため、まず初めに両実験にて使用したデータセットに関して説明致します。
データセット
今回は、作業時間が短かったということもあり、メモリ等気にせずスムーズに開発するため、小規模のデータセットを作成して実験に使用しました。 以下のような条件にてサンプルを行いました。
-
サンプル期間
- 2022/01/01 ~ 2022/06/30
- うち2022/01/01 ~ 2022/05/31は学習データとして使用し、2022/06/01 ~ 2022/06/30の期間はテストデータとして使用しました。

学習データとテストデータの分割
-
サンプルしたユーザ
- サンプル期間の中で、視聴回数50回以上かつ視聴時間10時間以上を満たしているユーザをランダムに1000人抽出しました。
-
その他
- 学習データには、実際に視聴した・されたの関係性にあるリスナーxライバーのペアのみ含まれております。これらを用いて、PS予測モデルの学習を行いました。
- テストデータには、実際には視聴していないペア(負例)も混入させました。その割合は 正例:負例=1:17 程度となっております。
実験1: Preference scoreの妥当性検証
実際のレコメンドシステムの実装、すなわち、ユーザ情報などからPSを予測するモデルの作成を行う前に、実装した8つの指標についてその妥当性を検証しました。 本実験での目的は、どのPreference scoreがレコメンドとして、またロングテールの実現のために有効なのかを定量的に評価することです。
そこで、100%の精度での予測を前提とした時、すなわち、用意したPreference scoreをそのまま使用した場合のレコメンドとしての性能を調べました。 まず、テストデータに関して、リスナーごとにPS(今回は8種類)に基づいてライバーをソートしました。 次に、ソートされたライバーのうち上位10人のライバーを、各リスナーへのレコメンド結果として出力しました。 最後に、レコメンド結果を2つの評価指標に基づいて評価し、その性能を検証しました。 なお、テストデータに含まれる負例(実際には見た・見られたの関係にないリスナーxライバーペア)のPSはいずれも0としました。 本実験では正解値、つまり実際には事前に知り得ない情報を使用していることに留意していただけると幸いです。
レコメンドとしての性能を評価するために以下の指標を用いました。
- MAP@10
- レコメンドしたもののうちどれくらい当たったか(実際に試聴されたか)を表し、レコメンドとしての性能を示します。
- Cover rate AUC (CRAUC)
- 全ライバーに対してどれくらいのライバーがレコメンドされたかを表し、高いほどライバーの露出が多い(ある意味でロングテールに対応している)ことを示します。
実験1: 結果
以下に実験1の結果を示します。
| Time | Comment | Coin | Yell | $PS_{1}$ | $PS_{2, LR}$ | $PS_{3, LR}$ | $PS_{4, LightGBM}$ | |
|---|---|---|---|---|---|---|---|---|
| MAP@10 | 0.993 | 0.901 | 0.669 | 0.715 | 0.715 | 0.897 | 0.993 | 0.999 |
| CRAUC | 0.218 | 0.208 | 0.162 | 0.167 | 0.169 | 0.216 | 0.231 | 0.221 |
(補足: 本結果はあくまでPSの定義自体の妥当性を検証したもので、実際のレコメンドでは使用できない、ある種正解値をそのまま使用した場合の結果であることにご注意ください。)
今回実装した8つの指標の中では、$ PS_{3, LR}(time, comment, coin) $と$ PS_{4, LightGBM}(time, comment, coin) $を目的変数とすることで高い性能のレコメンドが期待できることがわかりました。 レコメンド単体としての性能(MAP@10)は、$ PS_{4, LightGBM}(time, comment, coin) $を用いる場合の方が高く、CRAUCは$ PS_{3, LR}(time, comment, coin) $を用いたものが高いという結果となりました。 いずれにせよ、両者は一つの指標に基づいてソートするレコメンドアルゴリズムにおいて効果的な指標となりうることが確かめられました。 一方、既存指標を使用したものでは、Time、すなわち視聴時間をもとにソートしてレコメンドしたものが、MAP@10及びCRAUCいずれも高いことがわかりました。 Time, Comment, Coinなどの過去の視聴履歴から決まるYellに関しては、正解値を使用してもMAP@10が0.715、CRAUCが0.167とそこまで高くないことがわかりました。 繰り返しになりますが、本実験ではPSとして定義した8つの指標の妥当性を比較・検証するもので、レコメンドの性能そのものを評価しているわけではないことにご留意ください。
実験2: レコメンドシステムの評価
次に、正解値ではなく、実際にユーザ情報やラグ特徴量からPSを予測し、予測値に基づいてライバーをソート、レコメンドした場合の性能評価を行いました。
「レコメンドアルゴリズムの全体像」の章でも記載しましたが、予測モデルにはLightGBMを使用しました。 本実験では、Yell、$PS_1(yell)$、$ PS_{2, LR}(time, comment, coin) $、$ PS_{3, LR}(time, comment, coin) $の4つの指標を使用しました。 まず、ユーザ情報やそのほかの情報から、各指標を予測するモデルをそれぞれ作成しました。 次に、各予測モデルが、未来の情報、未知のリスナーxライバーペアを含むテストデータに対して、PSを予測しました。 最後に、リスナーごとに、各ライバーのPSを高い順にソートし、上位10名のライバーをレコメンドしました。
なお、$ PS_{4, LightGBM}(time, comment, coin) $に関しては、正解値として使用するPSをLightGBMを用いて出力しており、機械学習モデルの二段組構成となっております。その場合、リークやオーバフィッティングを回避する必要があり、時間内にてこの処理の実装が間に合わなかったので今回はスキップさせていただきました。
実験1と同様に、評価指標としてMAP@10とCURUCを使用しました
実験2: 結果
以下に実験1の結果を示します。
| Yell | $PS_{1}$ | $PS_{2, LR}$ | $PS_{3, LR}$ | |
|---|---|---|---|---|
| MAP@10 | 0.675 | 0.654 | 0.562 | 0.676 |
| CRAUC | 0.156 | 0.157 | 0.149 | 0.180 |
レコメンドそのものの性能(MAP@10)に関しては、Yellと$ PS_{3, LR}(time, comment, coin) $を使用したものが最も高く、両者はほぼ同じ精度を示しました。 しかしながら、CRAUCに着目すると、$ PS_{3, LR}(time, comment, coin) $が0.180と最も高く、他の指標を使うよりもより多くのライバーを露出させていることがわかりました。
実験2: 考察
実験2での結果を受けて、$ PS_{3, LR}(time, comment, coin) $を用いたモデルに関して深掘りを致しました。
特徴量重要度に着目すると、1回前のラグ特徴量つまり、直近1回前の配信を見たときの$ PS_{3, LR}(time, comment, coin) $の値が予測に最も効いていることがわかりました。 これは、一回前に見た同じライバーのライブ配信の反応値が次の配信での反応値の予測に役立っているということであり、過去の視聴履歴が予測に有効であることがわかります。 また、意外にもこれまでに見たライバーのうち男性ライバーの割合を示すmean_liver_gender_1が予測にある程度効いていることがわかります。 女性ライバーの方が多い中で、男性ライバーの視聴情報は希有であるために重要度が高くなったのではないかと考えられます。
PS3の予測における特徴量重要度
一方で、予測値と正解値を比較すると、大きく下振れしていることがわかり、回帰モデルの精度としては不十分であることがわかりました。 $ PS_{3, LR}(time, comment, coin) $の予測に、より効果的な特徴量の探索、深層学習モデルの導入など、モデルの精度改善余地は大いにありそうです。
予測値と正解値の比較
まとめ
本インターンでは、リスナーのライブ配信に対するお気に入り度合いを予測し、これをソートすることでレコメンドを行うシステムの実装を行いました。 加えて、定式化の中で、ライバーランクに基づいた傾斜をかけることでロングテールに対応させました。
どのような指標が役立つのかという足がかりには多少なりましたが、大規模なデータへのスケーリングや今のレコメンドシステムとの比較など、運用にむけたより具体的な検証はできておらず、 定式化やモデリングなど手法そのものにも改善すべきところが散見されるように思います。 今後の展望として、こうした問題点のさらなる深掘り・解決をしていく必要があると考えております。
最後になりましたが、本インターンを通して、アルゴリズムの設計から、データの整形、学習、評価などの実装に至るまで、非常に多くのことを経験し学ぶことができました。 ここで学んだことを活かしながら、今後の開発や研究に励んでいきたいと思います。
誠にありがとうございました。

最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。