





はじめに
データ統括部データサイエンス第二グループ所属の横尾です。普段はデータサイエンスやコンピュータビジョンなどを扱う業務をしながら、Kaggleなどのコンペに空き時間を見つけて参加しています。本記事では Facebook AI主催のコンペ で入賞した際の取り組みについて紹介します。
早速ですが、忙しい方のために以下に解法をまとめました:
- Data augmentationを工夫し、画像のコピー&改変をデータセットに忠実に再現
- Contrastive lossとcross-batch memoryを組み合わせた距離学習
- Progressive learningによるEfficientNetV2の学習
- 類似の負例を用いたベクトルに対する後処理
こちらは、本コンペの自分の解法をまとめた技術レポートとコードのリンクです。
※ 一定深層学習分野に関する知識がある読者を想定しているため、基礎的な専門用語や専門知識についての解説については割愛させていただきます。ご了承ください。
コンペの概要
今回私が参加したのは「 Facebook AI Image Similarity Challenge 」というFacebook AI主催のコンペで、約4ヶ月間にわたって画像のコピー検知の性能を競いました。なんと言っても20万ドルという賞金総額の高さには目を見張るものがあり、自分のようにお金に釣られた参加者はたくさんいたのではないでしょうか。また、本コンペは「NeurIPS 2021 competition track」に採択されており、入賞者は NeurIPSのワークショップ で発表できる特典付きとなっています。
本コンペはMatching TrackとDescriptor Trackの2つのトラックに分かれており、それぞれ
- Matching Track: 対象の画像がコピーされたものかどうかの予測結果を含んだCSVファイルを提出
- Descriptor Track: 対象の画像を256次元のベクトルに変換したものを提出
となっていました。Matching Trackはいわば自由形、一方でDescriptor Trackは低次元のベクトルをそのまま提出しなければならないということで、より制約の強いトラックとなっていました。
自分はDescriptor Trackの方を中心に参加していたため、本記事の解説もDescriptor Trackの解説に絞っています。
タスク
今回のコンペは、「コピー検知」というコンピュータビジョンの分野を主な対象としています。コピー検知は言ってしまえば「パクリ」を検知するタスクです。例えば、ある画像が与えられたときに、その画像が他の画像のコピーを改変したものかどうかを検知し、コピー元を特定するタスクとなっています。
ソーシャルメディアが発達した近年、盗作や無断改変などの問題が深刻となっており、違法なコンテンツを精度良く自動的に検知できるような技術は需要が高まってきています。
一方で、画像分類や物体検出などのコンピュータビジョンの他の分野に比べてコピー検知の分野はあまり発達しておらず、「未解決」の問題であると言えます。実際のところコピー検知に関する研究があまり見つからず、サーベイに苦労しました。そのため、今回のコンペでは画像検索や距離学習などの類似の分野に焦点をあてて調査とモデル開発を進めました。
データ
本コンペのデータは、以下の3つのサブセットに分かれていました。
- query: コピー検知の対象画像。画像の枚数は5万枚。
- reference: コピー元の候補の画像のセット。画像の枚数は100万枚。
- training: 学習用セット。画像の枚数は100万枚。分布的にreference setと類似。
モデルの学習は、基本的にはtraining setの利用が推奨されていたのですが、training setには肝心のラベルがありません。ではどうするかと言うと、自分はtraining setの画像を画像処理のライブラリによって加工し、加工前後の画像を正例のペアとして学習させました。画像の加工や学習の詳細については解法紹介のパートで後述します。
そして、いわゆる「パクリ」の画像が含まれるのがquery setです。Query setに含まれる画像には様々な種類・強弱の加工が施されており、元画像とほとんど変わらないものから原型が無いほどに加工されたものまであります。
以下に加工の例を挙げてみます。
- 画像編集ツールによる手動加工
- テキスト・絵文字・画像のオーバーレイ
- 色の変換(グレースケール化・彩度の変更・フィルター処理など)
- 空間的な変換(切り抜き・回転など)
このように画像の加工は自動・手動それぞれで行われており、いかにそれらの加工を手元で再現するかが重要なコンペでした。
以下の画像は元画像と加工後の画像の例で、それぞれreference setとquery setに含まれる画像となっています。

加工前の画像(左)と加工後の画像(右)|画像のクレジット(Flickrのユーザー名): CrusinOn2Wheels(加工前の画像), bortescristian(加工に使用された背景画像)
加工後の画像を見ると、パッと見では気づかないレベルで元画像の存在感が消えてしまっています。実際のところ、このような極端な例は数多く含まれていました(ちなみに、自分の最終モデルはこちらの加工例についても正しく検知することができていました)。
コピー検知のタスクや、データやコンペの詳細論文についてより詳しく知りたい方は こちらの論文 をご参照ください。
解法
では、自分のコピー検知に対する実際のアプローチについての解説に移ります。 Descriptor Trackの最終的な提出物は画像を表すベクトルでした。ここでは、コピー検知に適したベクトルを得るために、どのような手法を用いたか・工夫をしたかについて紹介できればと思います。
モデルの学習
コピー検知のタスクは、画像に対してコピーを検知し、データベースの中からコピー元の画像を特定するタスクとなっています。そのため、「データベースの中から類似した画像を引っ張ってくる」という点では、類似画像検索のタスクと共通性があると言えます。そこで、自分は類似画像検索に用いられる距離学習という手法を用いました。
距離学習
距離学習には embedding lossとclassification loss の2つのタイプがあり、 contrastive loss や triplet loss はembedding lossに、 CosFace , ArcFace はclassification lossに分類されます。最近の類似画像検索に関連するコンペだと、精度の高さから後者のclassification lossが用いられることが多いようです。
ただ、本コンペの場合はそもそもクラスの概念が無く、クラス分類を発展させた手法であるclassfication lossの適用は難しいと考えられます。一方で、embedding lossは正例・負例のペアさえあればクラスが存在しなくても学習可能となっています。そこで、自分はembedding lossの一種であるcontrastive lossを用いることにしました。
余談ですが、本コンペのような場合でも、画像1枚を1つのクラスとして割り振ることで無理やりclassification lossを適用することもできます。ただ、学習データの数に比例してクラス数が増えるためメモリ消費量が爆発する上に、自分が実験した限りでは精度的にもembedding lossと比較して劣るようでした。
ちなみに、lossについては色々と試しはしてみたのですが、contrastive lossが一番精度が良く学習も安定している印象でした。こちらの 論文 やこちらの 論文 でも報告されているように、contrastive lossはシンプルと言えど強力なようです。
Contrastive lossは単体でも充分強力なのですが、効率良く学習させるためには大きなバッチサイズが要求されるという側面があります。距離学習では、「似てるけど違う」ような難しいペアをいかにモデルに学習させるかが重要だからです。とはいえ現実的にはメモリの制約からバッチサイズをそこまで大きくできません。
そこで、 cross-batch memory と呼ばれる手法をcontrastive lossに組み合わせることにしました。
Cross-Batch Memory
Cross-batch memoryを簡単に説明すると、過去の学習イテレーションで計算したembeddingをmemoryと呼ばれるFIFO形式のキューにどんどん貯めていき、学習用のpositive-pair, negative-pairを作る際にmemory内のembeddingも使用する手法です。メリットとしては、メモリの消費量を抑えつつ、あたかも巨大なミニバッチサイズで学習しているときのような効果が得られることにあり、モデルの学習に有益な難しいペアをより作りやすくなります。「過去のモデルのembeddingなんか使って大丈夫なの?」という気もしますが、モデルの学習最初期を除いて、学習経過によるembeddingのdriftは小さいことは実験的に示されています( cross-batch memoryの論文 のFigure 3)。
Cross-Batch Memoryの類似の手法として、自己表現学習手法の一種である MoCo がありますが、MoCoはメインのモデルとは別に、モデルのEMAも使用している点が違います(cross-batch memoryは単一のモデルで学習可能)。
こちらのcross-batch memoryを組み合わせると、モデルの性能が大きく向上しました。また、memoryのサイズは大きければ大きいほど精度的には良くなり、最終的に2万サンプルまで大きくしました。
実装に関しては(contrastive loss含めて) Pytorch Metric Learning というライブラリを使用しました。こちらのライブラリは様々な距離学習のlossの実装をはじめとして、実装が複雑になりがちなサンプリングやDDP対応、学習・推論パイプラインも実装されており、とても使いやすいライブラリになっています。
Data Augmentation
前述のとおり、本コンペで学習用として提供されたデータにはラベルが付与されていませんでした。そのため自前で正例・負例のペアを作り出す必要があり、自分は画像に加工を施し、加工前後の画像を正例のペア、無関係な画像同士を負例のペアとして学習させました(汎化性能向上をねらいとして、厳密には加工前として正例ペアに使っている画像に対しても、弱めのdata augumentationは適用させています)。
画像加工には、 AugLy というdata augmentationのためのライブラリを使用しました。AugLyはFacebook AI謹製のライブラリで、色彩変換などの基本的なaugmentationに加え、絵文字・テキストのオーバーレイや、SNSの画像投稿欄への画像はめ込みなどの変わったaugmentationも用意されています。また、画像の他にも音声・テキスト・動画のデータにも対応しているため、様々なシーンで利用可能なライブラリとなっています。本コンペのコピー画像もAugLyを使って生成されており、できるだけコンペのデータに近づけるためにもAugLyを使わない理由はありませんでした。
Data augmentationとして適用した画像加工の種類ですが、データセット内のコピー画像の生成に実際に用いられた加工を使えるだけ使いました。ただ、手動のペイントツールによる加工の再現については流石に今回は諦めています。画像加工に用いる変換のパラメータ(JPEG Qualityの劣化具合や絵文字をオーバーレイする確率など)は、データセットの画像を目で見ながら雰囲気で調節しました。
Data augmentationの強度については、 progressive learning を参考に、学習が進むにつれてより激しくするという戦略をとりました。また、入力画像の解像度もそれに応じて徐々に上げていきました。入力画像の解像度を徐々に上げていくというアプローチは画像検索コンペの上位解法( GLR20 1st place , GLR21 1st place )でもよく見られ、有効性が示されています。
その他の工夫点としては、とにかくランダム性を重視し、できるだけ多様な画像が生成されるようにaugmentationを適用する順番もシャッフルするようにしました。
実際に、ランダムな加工を施した例を元画像とともに以下に示します。

画像加工例。左上:元画像、それ以外:加工後の画像
こちらの例を見ると、「ここまで原型無くなるぐらい加工しちゃって大丈夫なの?」と心配になるのですが、実際のところコンペのデータにもこのレベルのコピー画像は多数ありました。さらに、コンペは2-stage制となっており、2-stage目の評価対象データには加工の激しい画像を多く含むとのことだったので、このような激しめのdata augmentationが功を奏した形となりました。
モデルの構造
モデルのbackboneには EfficientNetV2 と呼ばれるCNNを使用しました。最近は ViT をはじめとするTransformerベースのモデルが全盛の印象がありますが、今回のコンペではそれらのモデルよりもEfficientNetV2が速度面でも精度面でも優れていました。
モデルの構造はいたってシンプルなものになっており、backboneの最終層にfully connected layerとbatch normalizationが続く、といった構成になっています。 近年の自己表現学習のモデル を参考に、backboneの最終層に3層程度のMLPを繋げて実験してみたりもしましたが、効きませんでした。
後処理
本コンペは前述の通り、画像をベクトル化したものをそのまま提出する形式になっていました。そのため、メトリクスの最適化などの後処理はできないようになっていたのですが、ベクトルそのものに対して手を加えるということは可能でした。
しかし、コンペのルールで「推論時に他のquery, reference setの画像を参照してはならない」と決められていたため、画像検索の後処理で用いられることの多い query expansion は利用できないようになっていました。
一方でtraining setのデータは何に使っても大丈夫とのことだったので、他の参加者と差を付けるために、training setを使って後処理で何かできないかを考えました。
ここで、training setのサンプルは、推論対象となるサンプル(query set, reference set)とオーバーラップが無いように作られている(これはリークを防ぐためだと思われます)ことに注目しました。つまり、training setのサンプルは、負例であることが保証されているということです。この性質によって、推論対象画像に類似したtraining setの画像は、「これはコピー元の画像だ」と誤検知してしまいがちな典型例として捉えることができます。
そこで、推論対象画像のベクトルを、類似のtraining setの画像のベクトルから遠ざけてあげれば良いのでは無いか?と考えました。実際のところ、推論対象画像のベクトルから類似のtraining setの画像のベクトルを減算するだけで大きく精度向上しました。こちらの後処理について、それっぽい手法名が欲しかったのでとりあえずnegative embedding subtractionと名付けました。
これだけではイメージが湧きづらいとは思うので、以下にnegative embedding subtractionの実際のコードを載せます。
def negative_embedding_subtraction(
embedding: np.ndarray,
negative_embeddings: np.ndarray,
faiss_index: faiss.IndexFlatIP,
num_iter: int = 3,
k: int = 10,
beta: float = 0.35,
) -> np.ndarray:
"""
Post-process function to obtain more discriminative image descriptor.
Parameters
----------
embedding : np.ndarray of shape (n, d)
Embedding to be subtracted.
negative_embeddings : np.ndarray of shape (m, d)
Negative embeddings to be subtracted.
faiss_index : faiss.IndexFlatIP
Index to be used for nearest neighbor search.
num_iter : int, optional
Number of iterations. The default is 3.
k : int, optional
Number of nearest neighbors to be used for each iteration. The default is 10.
beta : float, optional
Parameter for the weighting of the negative embeddings. The default is 0.35.
Returns
-------
np.ndarray of shape (n, d)
Subtracted embedding.
"""
for _ in range(num_iter):
_, topk_indexes = faiss_index.search(embedding, k=k)
topk_negative_embeddings = negative_embeddings[topk_indexes]
embedding -= (topk_negative_embeddings.mean(axis=1) * beta)
embedding /= np.linalg.norm(embedding, axis=1, keepdims=True)
return embedding
Negative embedding subtractionは、今回のコンペのような負例であることが保証されているデータセットが手に入る場合に利用範囲が限られてしまいますが、何らかの形でより実用的な手法に発展できればと思っています。
結果
約4ヶ月間続いたDescriptor Trackですが、最終的に526名の参加者に到達しました。 Descriptor Trackの最終結果は以下のようになりました。
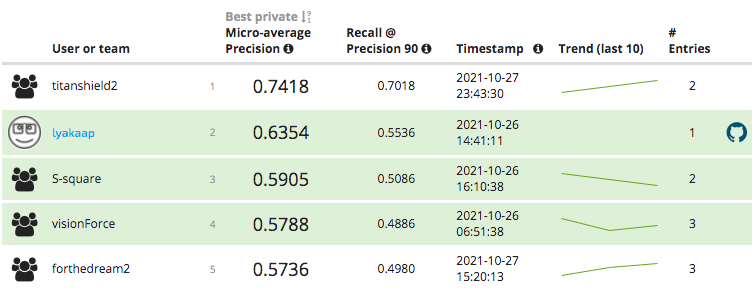
Descriptor Trackの最終結果
最終的に、自分は2位(lyakaap)にランクインすることができました。 ちなみにランキング表示上は2位となっていますが、1位のチーム(titanshield2)は解法の一部をシェアしない意向らしく、ルール上は自分が繰り上げ優勝になるそうです。 スコアで大差を付けられてしまっていることは悔しいのですが、概ね満足の行く結果となって良かったです。
その他
コンペの進め方
本コンペは開催期間が4ヶ月もあった上、試してみたいこともたくさんあったため、タスク管理が重要になると考えました。 そこで、タスク管理ツールである trello を導入することにしました。 タスク管理ツールには色々な種類のものがありますが、普段の業務のチーム開発でも利用していて馴染みがあったことから、このコンペではtrelloを使用しています。
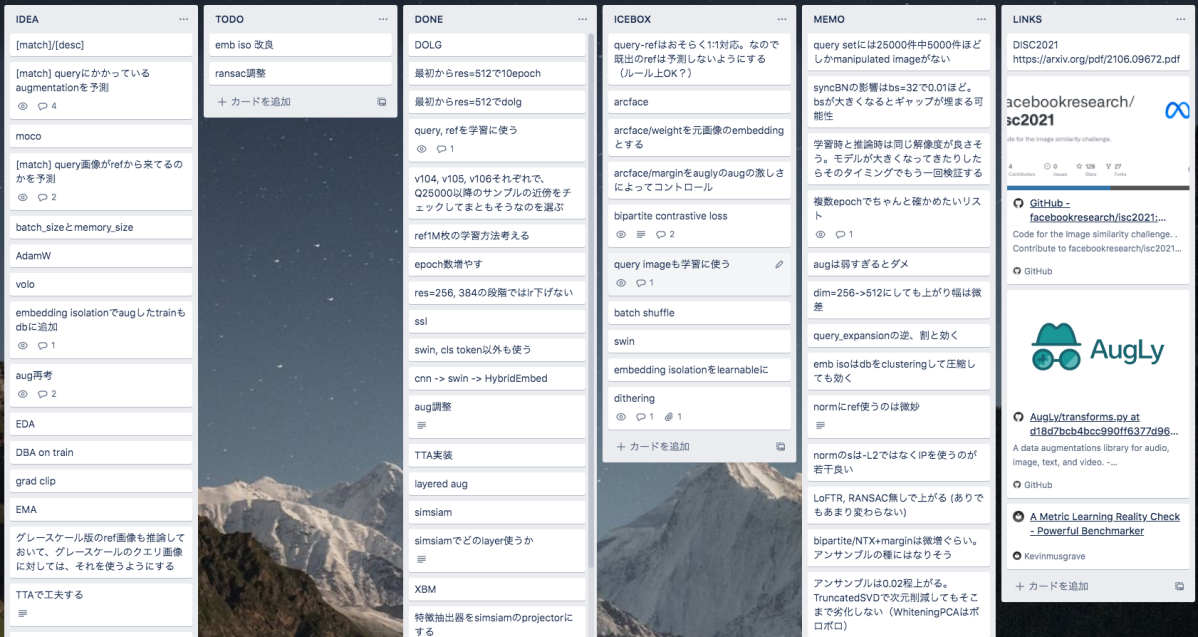
今回のコンペのtrelloボードの様子
何かアイデアを思い付いたらとりあえず「IDEA」に突っ込んで、その中で実験したいものを「TODO」に優先度順にざっくり並べて、実験が終わったら「DONE」に突っ込む、といったシンプルな運用をしています。
タスク管理ツールの導入によって見通しが良くなり、「何からやればいいんだろう」が少なくなったのはかなりプラスでした。 今回のコンペはソロでの取り組みでしたが、チームの場合はより大きな効果を感じることができるかもしれません(一方でタスク管理ツールとか使い出すと急激に仕事感が出てしまいますが…)。
また、今回のコンペではあえて実験管理ツールは使用しませんでした。 というのも、過去のコンペで実験管理環境を整えるだけで満足してしまい、実際のところあまり活用していなかったからです。 そのため、今回のコンペでは実験結果のメモをテキストファイルにベタ書きするだけの原始的なスタイルで臨みました。 自分が管理系のツールをあまり使いこなせていないのもありますが、意外とそれだけでも何とかなりました。
上手く行かなかったこと
今回のコンペでは、self-supervised learningの手法や、画像検索モデルで用いられることの多い GeM pooling は意外にも効きませんでした。 また、画像コンペではアンサンブル・TTA(test time augmentation)が定番になっていますが、今回のコンペの最終提出には使用していません。 というのも、コンペ初期の段階のモデルの精度が低い段階では効き目があったのですが、ある程度精度が高くなった段階で効かないようになったからです。 理由については正直のところよく分かってないのですが、コピー検知のタスクは一筋縄では行かないことを実感しました。 ただ、結果的にシングルモデルのみで構成された軽量なパイプラインになったため、解法がシンプルになって良かったのかなと思います。
おわりに
本記事ではFacebook AI主催のコピー検知のコンペについて、タスクの概要や自分の取り組みについて紹介しました。画像のコピー検知のコンペは過去に例がほとんど無いため、手探りでモデル精度の向上のために試行錯誤を重ねて行く過程は大変でしたが、楽しく取り組むことができました。
今回このような良い結果になったのも、業務時間の一部をコンペ活動にあてることのできる Kaggle制度 や、計算リソースのサポートなど、DeNAのデータサイエンスチーム(Kaggler枠)に所属しているからこその結果だと思っています。
DeNAのデータサイエンスチーム(Kaggler枠)では 中途採用 を絶賛募集中です。社内でチームを組んでコンペに参加することも多々あり、お互いに切磋琢磨できる環境だと思うのでぜひとも!
参考文献
[1] Joanna Bitton and Zoe Papakipos. Augly: A data augmentations library for audio, image, text, and video. https:// github.com/facebookresearch/AugLy , 2021.
[2] Sumit Chopra, Raia Hadsell, and Yann LeCun. Learning a similarity metric discriminatively, with application to face verification. In CVPR, pages 539–546, 2005.
[3] Ondrej Chum, James Philbin, Josef Sivic, Michael Isard, and Andrew Zisserman. Total recall: Automatic query expansion with a generative feature model for object retrieval. In ICCV, pages 1–8, 2007.
[4] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, and Neil Houlsby. An image is worth 16x16 words: Transformers for image recognition at scale. In ICLR, 2021.
[5] Matthijs Douze, Giorgos Tolias, Zo ̈e Papakipos, Ed Pizzi, Lowik Chanussot, Filip Radenovic, Tomas Jenicek, Maxim Maximov, Laura Leal-Taix ́e, Ismail Elezi, Ondˇrej Chum, and Cristian Canton Ferrer. The 2021 Image Similarity Dataset and Challenge. arXiv e-prints, 2021.
[6] Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, and Ross B. Girshick. Momentum contrast for unsupervised visual representation learning. In CVPR, pages 9726–9735, 2020.
[7] Kevin Musgrave, Serge Belongie, and Ser-Nam Lim. A metric learning reality check. In ECCV, pages 681–699. Springer, 2020.
[8] Kevin Musgrave, Serge Belongie, and Ser-Nam Lim. Pytorch metric learning, 2020.
[9] Filip Radenovic, Giorgos Tolias, and Ondrej Chum. Fine-tuning cnn image retrieval with no human annotation. TPAMI, 2018.
[10] Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In CVPR, pages 926–935, 2015.
[11] Mingxing Tan and Quoc V. Le. Efficientnetv2: Smaller models and faster training. In ICML, pages 10096–10106, 2021.
[12] Xun Wang, H. Zhang, Weilin Huang, and Matthew R. Scott. Cross-batch memory for embedding learning. In CVPR, pages 6387–6396, 2020.
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter や facebook、はてなブックマークにてコメントをお願いします!
また DeNA 公式 Twitter アカウント @DeNAxTech では、 Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい!


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。