






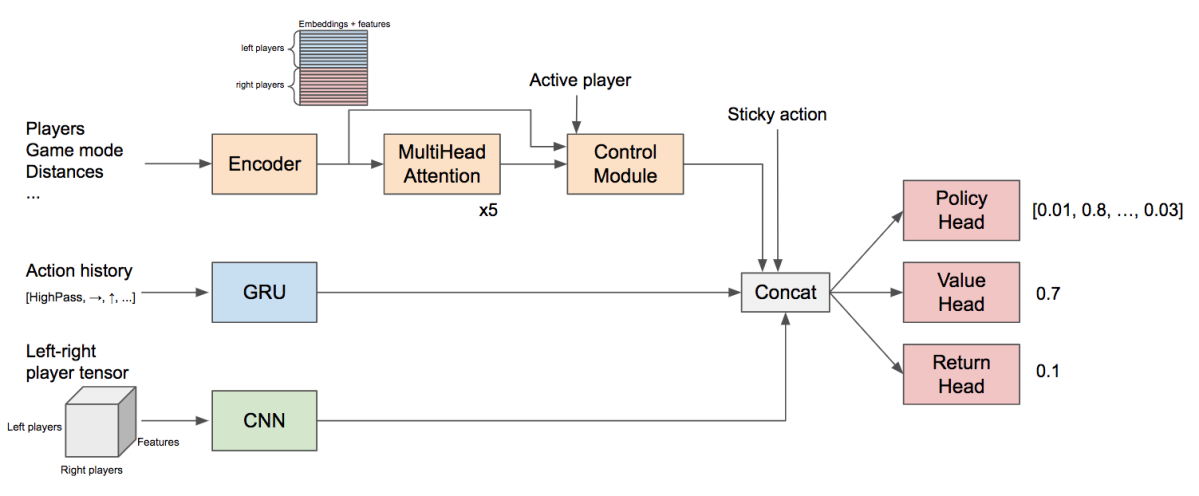
HandyRL は業務の中で並列強化学習を容易にするために生まれ、2020年6月にオープンソースとしてリリースしました。2021年2月にニュースで正式に告知を行い、多くの方にご利用いただいています。今回は、HandyRLによって目指す世界と、私たちが実際にHandyRLを利用して参加したコンペティションの体験記を紹介します。
強化学習の可能性
ゲームのAIと強化学習に関してR&Dに取り組んでいる大渡勝己(quantum社 AI技術顧問、DeNAでもR&Dに従事)です。本記事では私たちが取り組んでいる並列強化学習について紹介します。
強化学習は、環境(ゲームや実世界など)と相互作用するエージェントを自律的に鍛えていく技術の総称です。特に、これまでに多くのゲームで人間を超える成果を上げてきました。チェスや囲碁、将棋で人間のトップを倒したことは大きな話題になりました。
強化学習を扱うライブラリも数多く開発されていますが、特に私たちのHandyRLでは次の三点を目指しています。
① 誰でも強化学習を手軽に扱える
私たちプロの開発者だけでなく、これから強化学習を始める人にもお勧めできる手法を使い、可能な限りシンプルな実装にまとめています。
② 対戦ゲームにおいて強くて勝てるAIが作れる
研究分野では一人視点の環境が扱われることも多いですが、対戦ゲームの用途では二人以上のゲームを扱うケースが多いため、多人数環境で学習効率を上げる仕組みを加えています。
③ 並列度を上げて学習がスケールする
「動かしてみる」から一歩進んで、「実際に強いAIモデルを作る」ためには並列化して大量のCPUコアを使うことが必要な場合がほとんどです。HandyRLではワーカマシンの増減を学習を止めずに行うことができ、試行錯誤を含めながら実験を回すことに簡単にしています。
HandyRLはオフポリシーの方策勾配法という、2016年ごろから頻繁に使われるようになった強化学習の手法を採用しています。この手法は行動を決定するための確率出力(方策)を直接最適化するもので、 StarCraftのAI などで使用され、有効性が示されています。
強化学習には他にも多くの手法があり、多くのアルゴリズムを選択可能にしているライブラリもある一方で、HandyRLでは、本記事の執筆時点において、オフポリシーの方策勾配法とその亜種のみを実装しています。
これは、幅広い問題に対して一定の成果が期待できる手法によって、より多くの人に最初の一歩の成果を得て欲しいという思いがあります。さらに、このアルゴリズムは単純ながら本質的に重要な性質を満たしており、現代的な強化学習の理解においてもまず第一に学ぶ手法として適切と考えています。
以上がHandyRLの概要になります。私たちはHandyRLを社内のプロジェクトで利用するのみならず、HandyRLを使ってゲームAIのコンペティションに参加して実用性を高めてきました。
本記事ではデータサイエンス競技のプラットフォームであるKaggle上にて昨年末に5位入賞したGoogle Research Footballコンペティションと、先日の リリース の通り優勝することができたHungry Geeseコンペティションに対してHandyRLの適用について、大会の動向も交えながら説明します。
Google Research Football への挑戦
2020年秋開催の Google Research Football コンペティション はサッカーをプレーするエージェントを競う競技であり、世界中から1138チームが参加しました。

私はDeNAと別にサポートをいただいているquantum社でサッカーに関わっていたこともあり、 DeNAで強化学習に関わる業務を一緒に進めている 田中一樹さん とTamakEriというチームで参加しました。私、大渡にとってはkaggle実質初参加でしたが、学生時代にkaggle masterを取得しDeNAにkaggleを広めた張本人でもある田中さんの経験とセンスが道を開きました。
黎明期
私たちはコンペティション期間の残り3週間で参加しました。 最初の一週間は、言語や画像処理分野においてに革新的な成果を出したTransfomerをベースとして、選手ごとの情報を集約していくニューラルネットを作成し、HandyRLによってゼロからの自己対戦強化学習を動かして学習するところまでを進め、サッカーらしい動きを獲得できました。
成長期
ランダム同士の対戦では得られにくいスキルがあり、ここで
- 上位プレーヤーの棋譜からの模倣を強化学習中に同時に学習する
- 相手に何もしないプレーヤーや公開されているルールベースモデル等の多様な相手を加える といった工夫を行いました。
さらに、田中さんより、過去のkaggleのスポーツ関係の課題で成果を上げた、各メンバーの特徴を二次元上(サッカーでは11人×11人)に配置して畳み込むニューラルネットの導入があり、特にこのニューラルネットの効果によりプレースキルが一気に向上し、上位10位に食い込むようになりました。このペースでレーティングが向上し続ければ1位も夢ではないと沸き立ちました。
CNNが重要な役割を果たした
停滞期
しかし残り一週間となったところで一度手札が尽き、いくつかの変更を加えましたが少し強くなるだけで大幅な伸びが得られませんでした。 現在のニューラルネットモデルの出力を蒸留(あるモデルの出力を別のモデルの教師とすること。ゼロから学ぶ必要がなくなる)しながら大型のモデルの学習も目指しましたが、こちらがより強くなるまでは時間がかかりそうで、1位との差は全く縮まらず。
ラストスパート
残り一日で、勝敗だけでなく次の得失点を学習ターゲットに加えました。次の得失点に割引率(後の報酬を小さく見積もる係数)の導入により、得点はできる限り早く、失点はできる限り遅らせるような動きを獲得でき、プレーの質が格段に向上しました。
サッカーでは、「勝っている時に堅実なプレーをする」など得点差によりプレーを変えることが理想的なので、得点自体を学習することに前向きではなかったのですが、今の私たちの技術ではその方が近道だったのです。

最終的に1138チーム(1288人)中、日本人チーム最高の5位入賞になりました。 この変更が決まらなければ10~12位だったかもしれず、最後に底力を見せられたことだけは達成感が残りました。
優勝したテンセント社には以前に囲碁AI大会に参加したときにも敗れており(別の開発チームとは思いますが)、リベンジを果たすことができず、サポートしていただいたDeNA、quantumの方々、さらには日本の皆様に申し訳ない気持ちで一杯です。
今回のゲーム環境はゲームのようにボールを持った一人を動かすだけでしたが、サッカーという問題を通じて
- 11人全員が協調して動くマルチエージェントの課題や
- 相手の特徴や昔のプレーを記憶してゲーム中で戦略を変えていく長期的記憶の利用
といった、人工知能の大きな課題に対して立ち向かっていく必要を強く感じました。
Hungry Geese への挑戦
サッカーで優勝ができなかったためkaggleにリベンジするため、引き続いてkaggleで行われた Hungry Geeseコンペティション に再び田中さんとのコンビで参加しました。
今回はただ結果を出すだけでなく同時にHandyRLのアピールを行い、多くの人にサポートを受けて戦いたいという意図から、早い時期からライブラリと同名のHandyRLというチームで参加しました。
Hungry Geeseは4人で対戦するヘビゲームで、7 x 11のトーラス格子上で行います。
ヘビゲームはヘビ(以下、このゲームに合わせて、「ガチョウ」と呼びます)の頭を上下左右に動かして、食べ物を食べて体を長くすることを競うゲームです。ただし相手や自分の体にぶつかったら死んでしまうので、逃げ道を確保しつつ長くしていく必要があります。

HungryGeeseでは四人対戦ですが、対戦結果は長く生き残ることが優先で、規定のターン数まで生き残った場合と同時に死んだ場合のみ長さの比較が行われます。
こう聞くと、生き残ることを最優先にするべきなように聞こえますが、必ずしもそうとは限りません。長さで勝っているガチョウは、短いガチョウと頭同士で衝突して同時に死に、順位を確定させる戦略が可能だからです。そのため、残り二人では長い方が追いかけて短い方が逃げるという戦いになり、短い方は逃げながらも食べ物を拾っていく厳しい戦いを迫られます。もしくは、長い方が食べ物を囲い込んでしまい、手を付けることすらできずに終戦することもあります。三人以上でも、死んで順位を確定させるべき局面は頻繁にあるなど、なかなかに戦略性の高いゲームです。

青は上に動いて緑の頭に衝突することで勝ちが確定する局面
そのため、死なないことを優先しながらも、長さも意識して戦っていく、バランス感覚と思い切りが求められるゲームです。将来のリスクを読んで慎重に戦う姿勢は人間の長所が生きますが、リスクを取る局面では怖いという感情のないAIの判断が勝ることがあります。この辺りは他のゲームでもよく言われることですね。
さて、HandyRLチームでは様々なバージョンのAIを提出しましたが、そのうち代表的なエージェントの仕組みについて以下に解説します。
私たちのAIでは「深層強化学習」「先読み」の二種類のエージェントのアンサンブルにより手を選びました。
深層強化学習エージェント
HandyRLライブラリを用い、深層強化学習によってエージェントを作成しました。
最初に自分同士の自己対戦によって3週間で1600万試合を学習した後、過去に学習したモデルやわざとぶつかってくるエージェントなど多様な相手との対戦によって4日間で300万試合を追加学習しました。
特にこのゲームおいては以下の工夫を行いました。
トーラス盤面に対しての畳み込みネット
HandyRLチームのニューラルネットは、囲碁や将棋などの他のボードゲームでも使われる3x3の畳み込みネットワークを元にしています。ただし、Hungry Geeseはトーラス盤面で行われるゲームのため、盤端の畳み込みの際に盤の反対側のマスの値でパディングを行っています。そうすることで、盤面の平行移動に対して不変のニューラルネットを構成でき、少ないパラメータ数で強くすることが可能になります。
さらに、短時間で4人全員分の計算を行うため、4人全員の行動と期待順位を1つのニューラルネットで計算しています。この工夫は学習と対戦をいずれも効率化します。
ニューラルネットには以下のような特徴を入力しました。
プレーヤー(ガチョウ)ごとの特徴 4 x 8 x 7 x 11
頭の位置, 尻尾の位置,体全体の位置, 体の各マスの向き, 前のステップの頭の位置
全体的な特徴 5 x 7 x 11
食べ物の位置, 残りステップ数, ガチョウが1短くなるまでのステップ数, このターンでガチョウが1短くなるかどうか
特に、残りステップ数は、複数のスケールでTanh関数を掛けて入力することで0~1の値に収めています。
これは、例えばゲームのキャラのHPなど、値が大きくもなるが小さいところで勝負になる、という特徴に対してよく使うやり方です。
モンテカルロ木探索エージェント
深層強化学習モデルは良い直感を持った強力なエージェントですが、弱点もあります。
詰みや得点計算を見切れない
深層強化学習モデルは先を読まないので、人間が少し考えればわかるような詰みの形や、ゲーム終盤の長さの勝負を見誤ることがあります。
相手の動きを強く仮定してしまいがち
四人対戦ゲームにおいては相手の戦略の多様性に対処できることが重要ですが、自己対戦強化学習により学習したエージェントは相手の動きを仮定した協力的動作を学習してしまいます。

白と青が協力的動作(片方だけが食べ物を取る)を学習してしまう局面
一つの食べ物を二人のガチョウが見合っているとき、ゲーム理論ではチキンゲームと呼ばれる状況です。二人とも食べ物を取りに行くのが最悪で、二人とも逃げるのはまだ良いですが、この二人にとっての最良は片方だけが食べ物が取りに行くことです。自己対戦での強化学習を行うと、たまたま両者が協力できた場合に大きな報酬がもらえることで協力する行動を学習してしまいます。
しかし、実際に対戦する相手が自分のやり方で協力してくれるとは限らないので、深層強化学習エージェントは早死にすることが多く見られました。そのため、モンテカルロ木探索エージェントとのアンサンブルによって弱点を補い、総合力を高めました。
多人数ゲームにおけるモンテカルロ木探索
モンテカルロ木探索はゲーム木探索の一種で、バンディットアルゴリズムを各局面に適用し、現在の局面から将来の局面への手の選択を繰り返し行うことで、それぞれの局面における手の選択を収束させていきます。特にHungry Geeseは同時ゲームのため、一つの局面で複数人のバンディットを同時に行う Decoupled UCT (リンク先pdf)の系統の手法を使っています。
多様な相手のいる環境でうまく動かすために、探索では相手の手の選択に工夫を加えました。
相手がバンディットで最大化する目的として、相手自身の勝ちだけではなく自分が負けるような手を選んでくることで、相手が自分を攻撃してくるかもしれないという想定で手を選べるようにしました。
さらに、相手の探索とシミュレーション中の手のランダム性を上げることで、相手は自分よりも少し弱いという前提の手を選ぶようにしました。こうすることで、生き残ることによる期待報酬を高く推定でき、序盤ではリスクを回避する戦略を選びます。
この二重の効果で、深層強化学習モデルの弱点を補う行動選択を行うことを可能にしました。
モンテカルロ木探索では、現局面までバックアップしていく局面評価をゲーム末端までのシミュレーションによって得るやり方と、評価関数によって得るやり方があります。
私たちは詰みや200手終了時の勝敗判定を重視し、シミュレーションによる評価を採用し、秒間に数千回〜数万回のシミュレーションを行うため、囲碁AIの盤面実装法を利用して高速なシミュレーション機構を実装しました。結果、200手終了で長さ1だけリードして勝ったり、長さ1リードで頭同士の衝突を仕掛けたりなど、細かい戦略で強さを発揮することができました。
コンペティションの動向と終了
私たちは最初の月の最後にエージェントを提出し、そのまま約3ヶ月の間1位を譲ることなく独走を続けたため、エージェントの開発を再開したのは他の一つのチームが私たちに追いついた終了2ヶ月前でした。
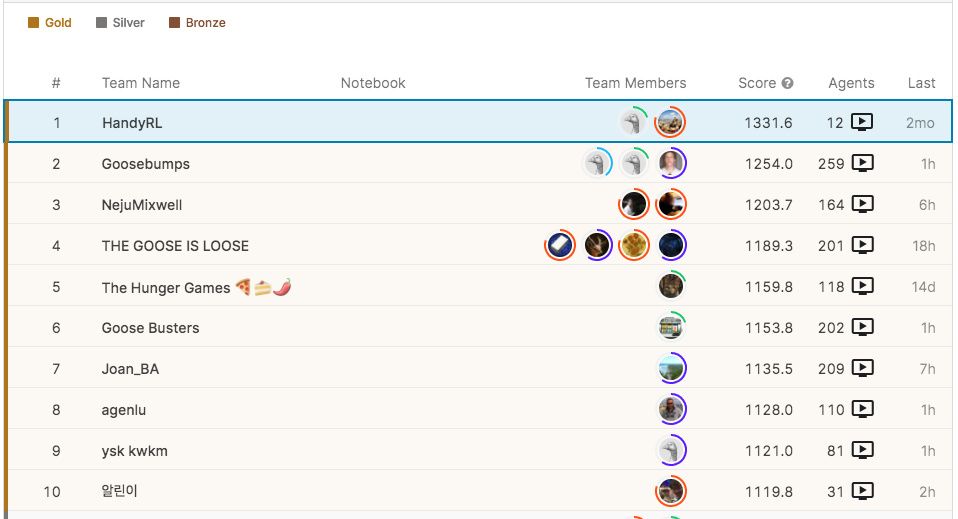
放置で独走を続けた
追いつかれた後は、裏で学習していたモデルを投入するなどしてまたリードましたが、他に試した新たな手法は成果が出るまでやり切れず。最後まで大きなリードを得ることができずに、2チームの一騎討ちの様相で評価期間に入りました。
評価期間では一度リードしたものの、評価期間では段々と対戦が上位同士に絞られていく中で、対戦相手の特徴との相性関係の想定に甘さがあり、私たちのチームはレーティングを伸ばすことができませんでした。
逆に2位のチームの戦略がこの状況にはまり、途中からは実力が逆転しているように見え、順位もいつ逆転してもおかしくない状況に追い込まれてしまいました。
2週間の評価期間中なんとか耐えていたのですが、ついに評価終了の1日前に逆転され、絶対絶命の状況に立たされました。
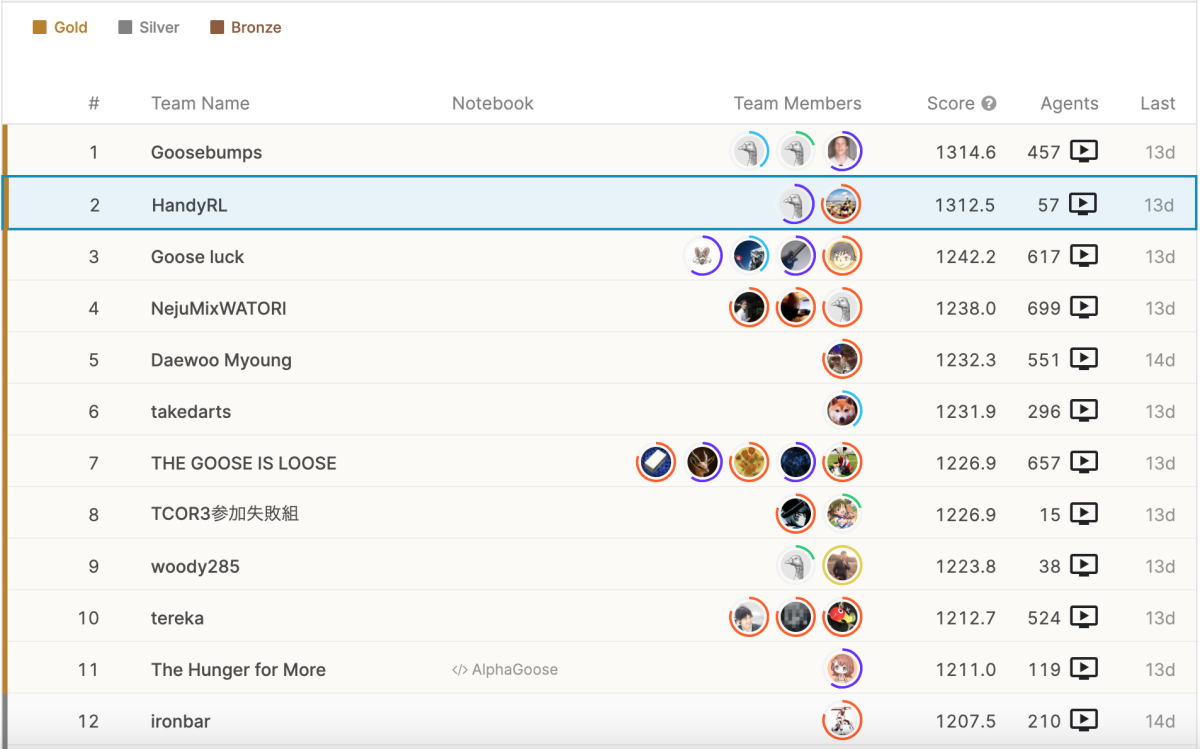
終了一日前
それまでも自分たちが勝った時の掛け声、負けた時の掛け声、ライバルの結果に対しての掛け声は試合結果を確認する度に掛けていましたが、
最終日は徹夜で、応援歌を歌いながらの観戦になりました。
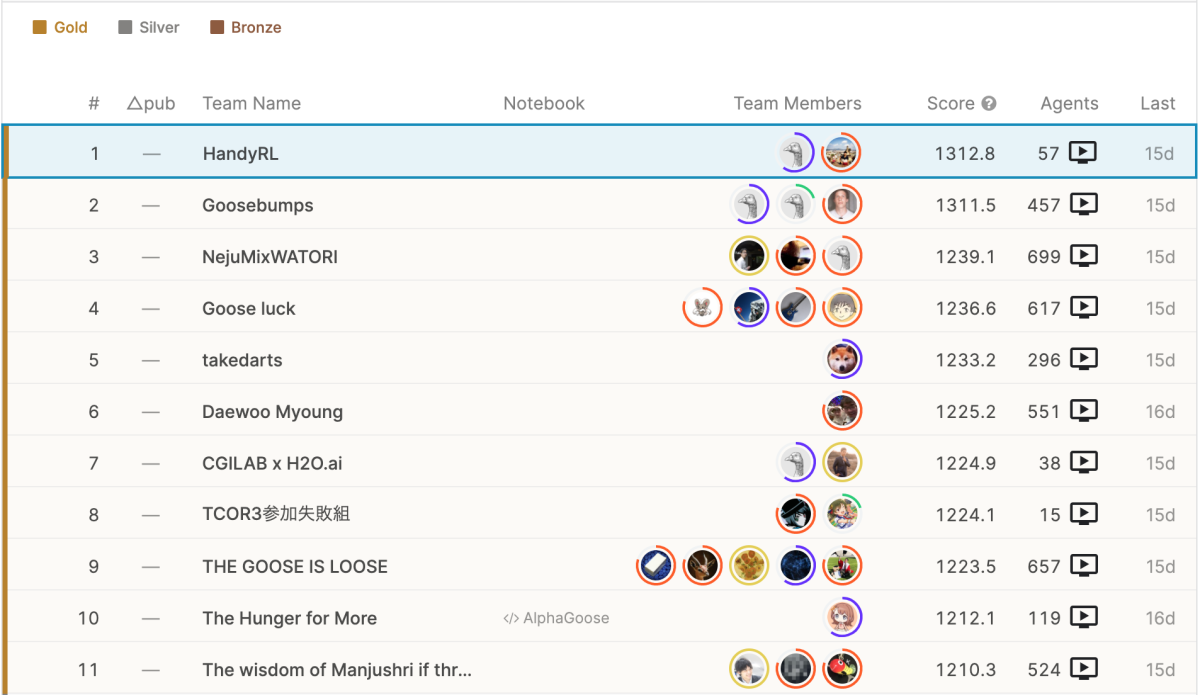
終了
結果として、別チームがライバルを連続して倒してくれたことで、なんとか優勝になりました!
なんとかネット記事や新聞記事等で取り上げていただき、祝福を送ってくれた皆様に対しても本当にありがたい気持ちでいっぱいです。
私自身にとっては苦い経験になりました。
Hungry Geeseは囲碁似のボードゲーム、深層強化学習、高速な木探索、多人数環境、と大渡の過去の経験とぴったり合致していて、まるで自分のために作られた課題のように感じていました。 その中で経験のない技術の利用も挑戦しましたが失敗に終わり、最終的に手持ちのスキルだけのものが出来上がり、力不足を痛感しました。
この経験を活かし、自分自身がさらに上のステージで活躍する姿をこそ、今回サポートしていただいたDeNA、quantum、そして多くの皆様に恩返しできる道なので、これまで以上の挑戦を結果としてまたお見せできるように頑張ります。
さいごに
強化学習の分野は日々進歩を遂げており、ベストと呼べる手法はこれからも更新されていくでしょう。強化学習を使う上では最新技術へのキャッチアップと、根幹となるノウハウの蓄積がどちらも重要になります。私たちはHandyRLを単なるツールではなく「AI」として捉えています。多くの問題を解けるように、人類の成長と共にHandyRL成長させていきます。
強化学習はすごい!楽しい!と感じてくれる人が一人でも多くなると嬉しいです!
DeNAでは今年、2021年度新卒エンジニア・2022年度新卒内定エンジニアの Advent Calendar もあります! 本 Advent Calendar とは違った種類、違った視点での記事をぜひお楽しみください!
▼DeNA 2021年度新卒エンジニア・2022年度新卒内定エンジニアによる Advent Calendar 2021 https://qiita.com/advent-calendar/2021/dena-21x22

最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。