





はじめに
はじめまして。9月から10月にかけてAIスペシャリストコースのインターンシップに2週間参加させていただいた田邊拓実です。大学では強化学習のロバスト性に関する研究をしています。 今回のインターンシップでは、Pococha(ポコチャ)におけるライバー推薦に取り組んでいました。 以下は本ブログの概要です。
- Pocochaのライバー推薦問題をバンディット問題として定式化しました。
- 事前にリスナーをセグメントに分割することで、より効果的なライバーの推薦をできるようにしました。
- 新規ユーザを対象とした問題設定でバンディットアルゴリズムを適用しました。
Pocochaについて

Pocochaとは、DeNAが2017年にリリースし、ダウンロード数が321万回(2021年9月末時点)を超えた人気ライブコミュニケーションアプリです。Pocochaを含む多くのライブコミュニケーションアプリには、ライブを行うライバーとライブを視聴するリスナーの2種類のユーザが存在し、ライバーの配信に対してリスナーは自由にコメントを行うことができます。他のライブコミュニケーションアプリと比較した時のPocochaの主な特徴として、「ライブの参加人数に上限が存在するため対話をしやすい」、「ライバーとリスナーの距離感が近い」ということがあります。また、Pocochaではライバーに対してライバーランクというものが付与されます。ライバーランクはEランク帯からSランク帯までの6つに分かれており、それぞれのランク帯の中でもいくつかに分かれています。例えば、Sランク帯はS1からS6までの6つに分かれています。Pocochaのランクは、ライブで獲得したいいね数やコメント数、視聴者数などによって上げることができ、ランクが上がることでライバーにとって様々な特典を得ることができます。
Pocochaについての過去の取り組みとして、
などがあります。
今回のインターンシップでのタスク
Pocochaでは常に多くのライブが行われており、夜間は特に多くなります。 そのため、リスナーは自分好みのライブを多くのライブの中から見つける必要があり、リスナーに対して適したライブを推薦することを考えなくてはなりません。今回のインターンシップでは、Pocochaにおける推薦システムをバンディット問題として定式化し、バンディットアルゴリズムを適用することで解いていきます。
本取り組みは、Pocohaのログデータを用いて実験的に行ったものであり、Pocochaの運営の方針を反映したものではないことに注意してください。
現在のPocochaにおけるライバーの推薦手法
現在のPocochaのライバーの推薦方法を説明していきます。
Pocochaでは、タブとして「ルーキー」や「地域」、「注目50」などの14種類のタブが存在し、ユーザーは好きなタブを選択、そのタブ上で視聴するライバーの選択を行います。
バンディット問題
ここでは、バンディット問題がどのような問題なのか、どのようにしてPocochaのライバー推薦に適用するのかを説明していきます。
バンディット問題について
まず、バンディット問題について説明をしていきます。バンディット問題とは、複数の確率的な報酬を生成する候補(アーム)から累積報酬が最大になるように、エージェントがアームを逐次的に選択していく問題です。主な応用先として今回のような推薦システムに加えて、ゲーム木の探索、プッシュ配信の最適化などがあります。
具体例を用いて説明をしていきます。今、目の前にスロットマシン(アーム)が5台あります。これらのアームを一回引くごとにそれぞれのアームがもつ独立した確率分布から報酬を生成します。ここでは、各アームがもつ確率分布を当たり確率$P_i(i=\{1,2,3,4,5\})$の2項分布とします。エージェントは合計$N$回アームを引くことができ、$N$回の合計で引くことができる報酬の累積の最大化を目指します。この時、エージェントは累積報酬の最大化を目指すために当たり確率$P_i$が最も高いアーム$i$を選択し続けたいのですが、どのアームの当たり確率が最も高いかはわかりません。そのため、どのアームが最も当たり確率が高いのかを調べるための探索(exploration)と最も高いと推定されるアームを引く搾取(exploitation)のジレンマが発生します。
バンディット問題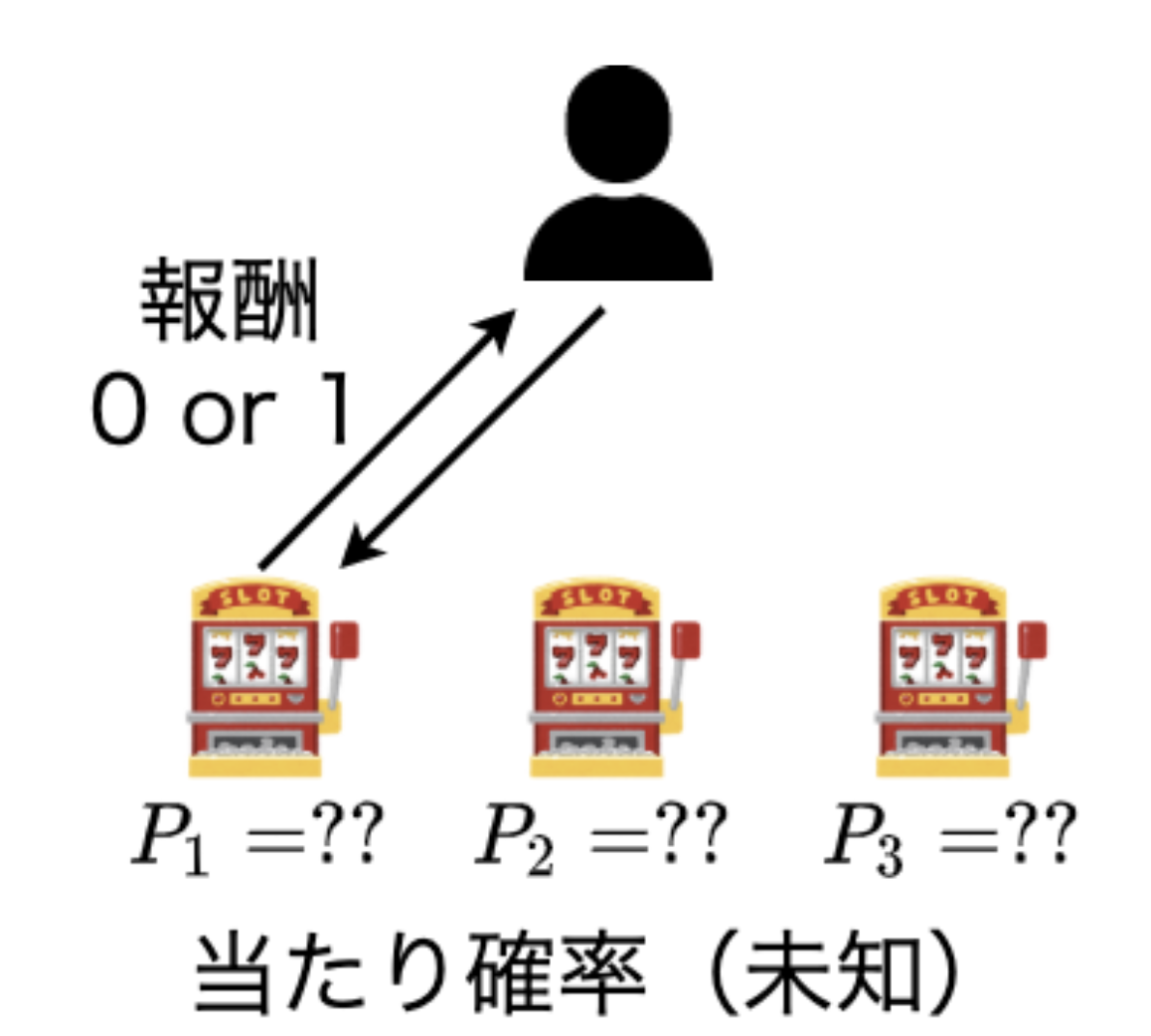
Pocochaにおけるバンディットの適用
ライバーの推薦をバンディット問題として定式化するためには、「アームの設計」や「報酬関数の設計」をする必要があります。
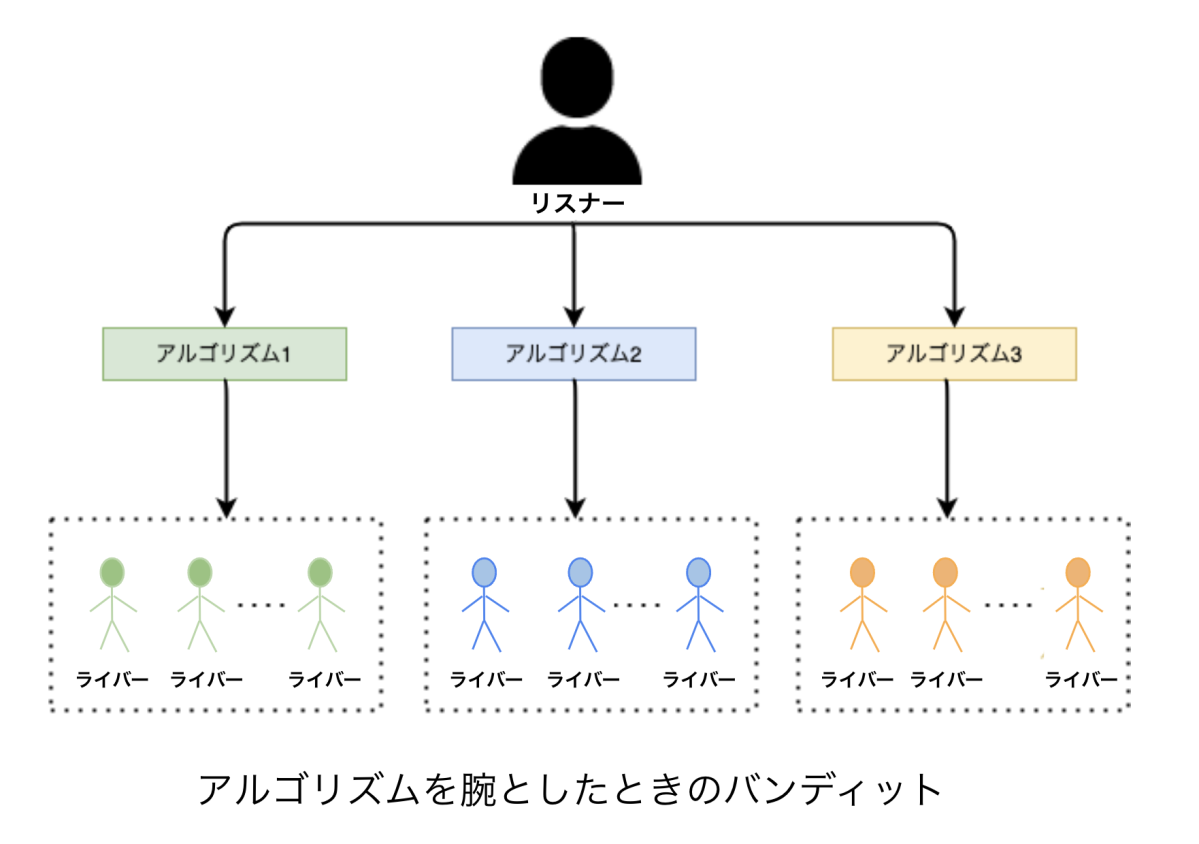
まず、「アームの設計」から説明します。今回は、「ライバーを推薦するためのアルゴリズム」をバンディット問題のアームとしました。ライバーを直接アームとする設計もあるのですが、この設計だと「アームの数が膨大になってしまい、最適化が困難なこと」、「ある一人のライバーのみを推薦し続けてしまう可能性があること」などの問題があります。そのため、今回は「ライバーを推薦するためのアルゴリズム」をアームとしました。
ライバーをアームとした時のイメージ図 アルゴリズムをアームとした時のイメージ図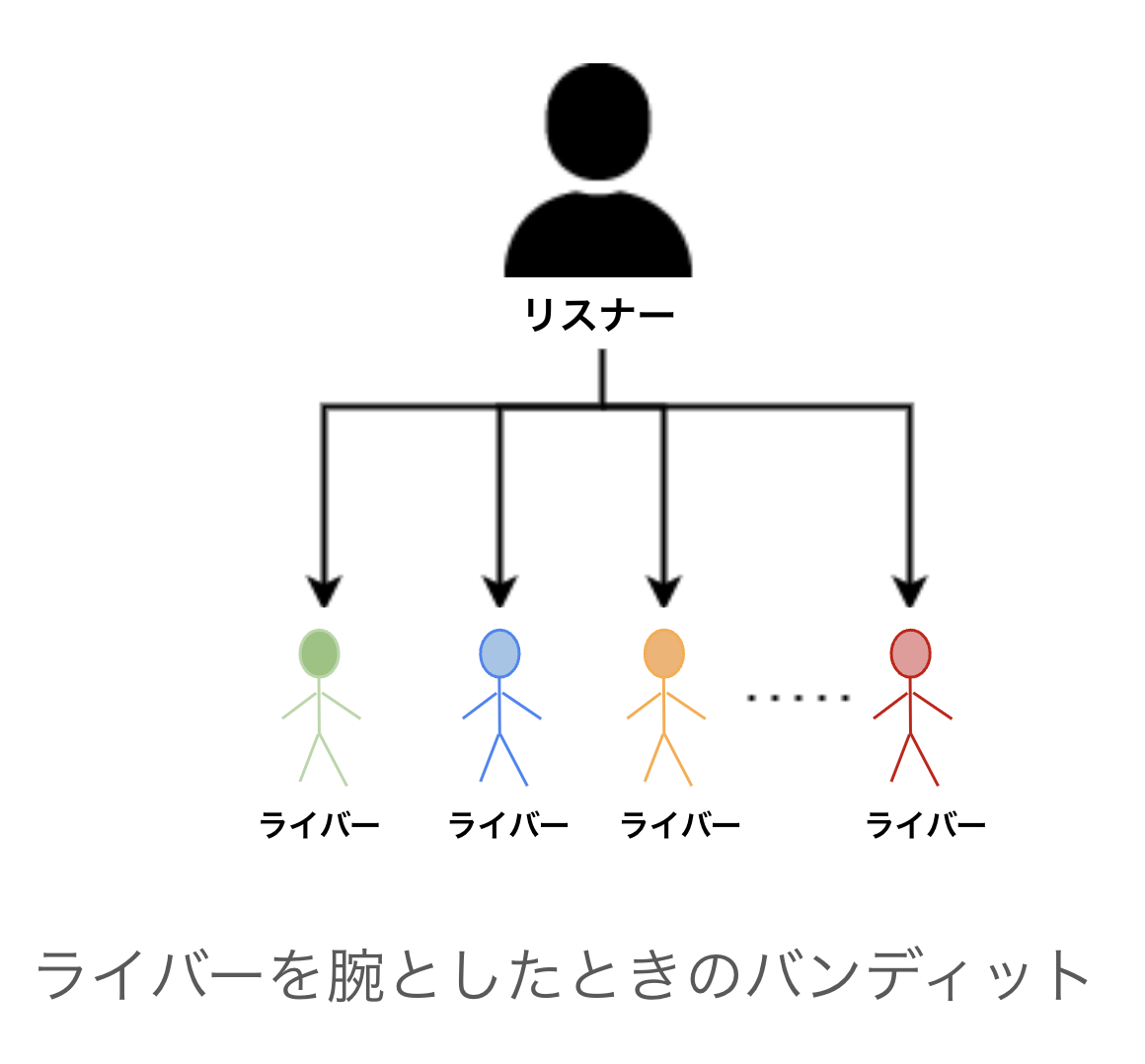
次に、「報酬関数の設計」について説明をします。バンディット問題への定式化をするにあたり、報酬関数の設計は非常に重要です。例えば報酬関数を「5人のライバーを推薦してから一週間以内にリスナーのライブ試聴時間」とすると、リスナーが長時間視聴し続けるようなライブを推薦するように方策は最適化されますし、「5人のライバーを推薦してから一週間以内にリスナーが視聴したライブの数」とすると、ユーザーが視聴しやすいライブを推薦するように最適化されます。また、報酬関数の設計次第では、多様なライバーの推薦なども可能になります。今回は、実験的に「10人のライバーを推薦してから一週間以内にリスナーが10分以上視聴したライブがあれば1、なければ0」としました。上記でも説明した通り、この設計はPocochaの運営の方針を表したものではないことに注意してください。
用いた推薦手法
バンディット問題の中には、ユーザーごとの特徴(コンテキスト)をもとに推薦を行うContextual Banditがあります。Contextual Banditを使うことでユーザーごとの好みに適した推薦が可能になりますが、コンテキストを学習するためのコストが大きいこと、実際にシステムに導入するときに実装が複雑になってしまうなどのデメリットがあります。
今回は、コンテキストなしのバンディットを用いることで、学習や実装のコストを抑えながらも、出来るだけリスナーごとの好みに適した推薦を行うことができるようにユーザのセグメント分割を適用するようにしました。
セグメント分割
セグメント分割とは何らかの基準を用いることで、あらかじめユーザをグループに分割する手法です。分割基準は
- 過去に視聴したライブを開催しているライバーのライバーランク
- 過去に視聴したライブで使用した平均ギフトコイン数
- 複数の特徴量からk-meansなどの教師なし手法を用いて分割
などがあります。今回はセグメントの分割基準を「過去に視聴したライブを開催しているライバーのライバーランク」としました。また、各セグメントで独立にバンディットアルゴリズムを適用することで、それぞれのセグメントに適した方策を学習しました。
セグメント分割xバンディット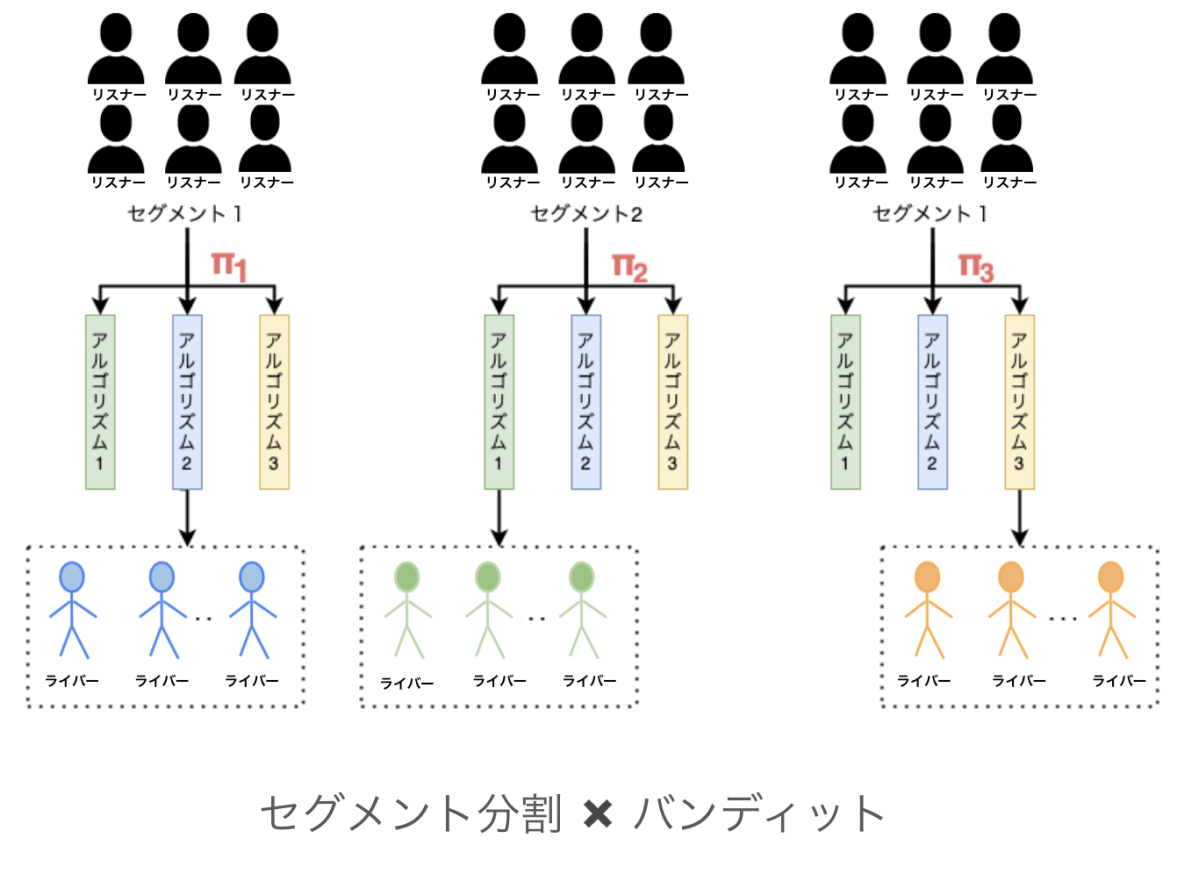
バンディットアルゴリズム
ここではバンディット問題を解くための手法の説明をしていきます。バンディットアルゴリズムには、UCB(Upper Confidence Bound)方策2やThompson Sampling方策3など様々なアルゴリズムがあります。今回はUCB方策を用いました。Thompson Sampling方策との比較実験もインターン期間中に行いましたが、時間の関係上考察が十分ではないため、本記事では省略します。
UCB方策
UCB方策とは以下の式で計算されるUCBスコアが最大となるアームを引く方策で、探索と搾取のバランスをうまく取りながらアームの選択を行なっていき、累積報酬の最大化を行う手法です。 $$\bar{\mu_i} = \hat{\mu_i}(t) + \sqrt{\frac{\log t}{2 N_i(t)}}$$ この時、$\hat{\mu_i}(t)$が時刻$t$でのアーム$i$の標本平均、$N_i(t)$が時刻$t$でのアーム$i$の選択回数を表します。また、第2項は探索のための項であり、選択数が少ないアームほど大きくなるため、標本平均が小さくても選択回数が少なければそのアームが選ばれる可能性があります。
実験
今回のインターンでは以下の3つの実験を行いました。
- コンテキスト付きバンディットとセグメント分割xコンテキストなしバンディットの比較実験
- セグメント分割データに対して適切な推薦ができているかの検証
- 新規リスナーを想定した実験
実験設定
ここでは、全ての実験で共通する設定を説明します。
実験には2021年7月1日 ~ 2021年7月31日の間にクリックされた時点のデータを用い、そこからそれぞれの実験で使用したサンプル数分のデータをランダムな非復元抽出でサンプリングしました。 用いたバンディットアルゴリズムは、コンテキスト付きバンディット問題ではLinUCB4、コンテキストなしバンディット問題ではUCBを用いました。
リスナーのセグメントの分割基準を、リスナーによって新人ライバーを好む人や人気ライバーを好む人など様々な好みがあるだろうという仮定から、「過去に視聴したライブを開催しているライバーのランク平均」としました。具体的には以下の5つのセグメントにリスナーは分割されます。
- EDランクのライバーを好むリスナー
- Cランクのライバーを好むリスナー
- Bランクのライバーを好むリスナー
- Aランクのライバーを好むリスナー
- Sランクのライバーを好むリスナー
アームのアルゴリズムを現在ライブをしている各ライバーランクのライバーを平均ユニークリスナーが多い上位10人を選択するようにしました。具体的には以下の7つのアルゴリズムから1人のリスナーに対して1つのアルゴリズムが選択されます。
- Eランクのライバーで平均ユニークリスナーが多い上位10人
- Dランクのライバーで平均ユニークリスナーが多い上位10人
- Cランクのライバーで平均ユニークリスナーが多い上位10人
- Bランクのライバーで平均ユニークリスナーが多い上位10人
- Aランクのライバーで平均ユニークリスナーが多い上位10人
- Sランク(S1~S5)のライバーで平均ユニークリスナーが多い上位10人
- SSランク(S6)のライバーで平均ユニークリスナーが多い上位10人
実験1
実験1では、コンテキスト付きバンディットとセグメント分割xコンテキストなしバンディットを比較することで、セグメント分割がどれぐらいユーザーごとに有効な推薦を行うことができるかを検証します。
コンテキストなしバンディットでは、各セグメントごとに2万件(約2、3時間分)のデータを用いた実験と各セグメントごとに10万件のデータを用いた実験を行いました。コンテキスト付きバンディット では、5つのセグメントのデータを足し合わせた10万件のデータと50万件のデータを用いた実験を行いました。
以下は実験結果です。
実験1の結果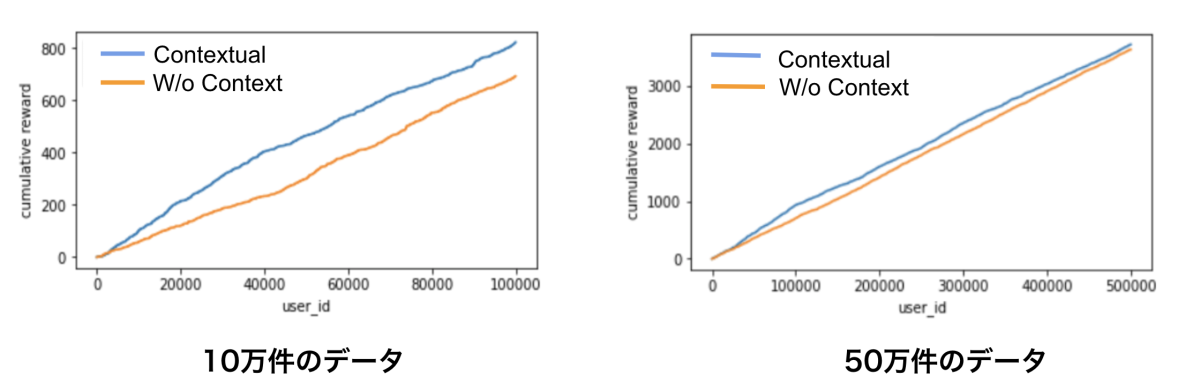
左が合計10万件分のデータの実験、右が50万件のデータでの実験結果です。グラフの横軸がuser_idの数でイテレーション数、縦軸が累積報酬を表しています。
グラフより10万件の比較的小さなデータセットではコンテキスト付きバンディットよりもセグメント分割xコンテキストなしバンディットの方が高い累積報酬を獲得できていることがわかります。これは、10万件のデータではユーザーのコンテキスト情報を十分に学習できなかったためこのような結果になったと考えられます。実際、データ数を増やした50万件での実験ではコンテキスト付きバンディットとセグメント分割xコンテキストなしバンディットの差は縮まっています。
実験2
実験2では、セグメント分割を行ったデータに対して適切な推薦ができているかを検証します。
それぞれのセグメントごとに10万件のデータを用いて実験を行いました。以下は実験結果です。
実験2の結果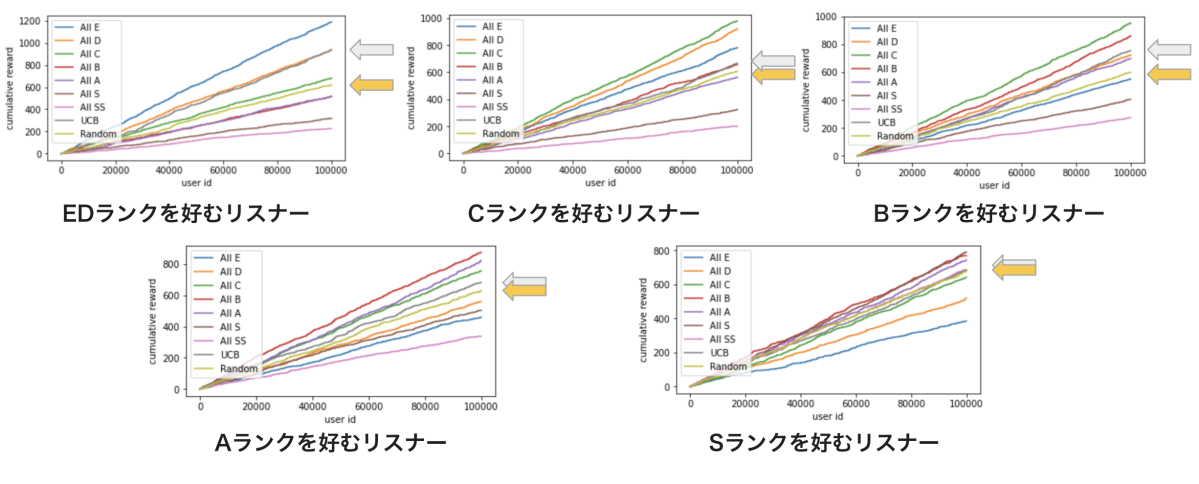
今回用いているセグメントの分割基準は「過去に視聴したライブでのライバーランクの平均」であり、これは「リスナーがどのランクのライバーを好むのか」を表していると言えます。また、アームを「各ランクでのユニークリスナー数の多いライバーを推薦するアルゴリズム」としています。そのため、グラフの左上の「EDランクを好むリスナー」セグメントでは「Eランクのライバーでのユニークリスナー数の多いライバーを推薦するためのアルゴリズム」を表すアームを引き続ければ累積報酬を最も最大化できます。
この実験でのバンディットアルゴリズムはグレーのUCBで全てのセグメントにおいて黄色のランダムアルゴリズム(引くアームをランダムで選択する)よりも高い累積報酬を獲得していることがわかります。
実際、以下のEDランクのライバーを好むリスナーセグメントでの、各イテレーション区間でのアームの選択回数を見ると、探索段階である0~100イテレーション区間を除き、Eランクのライバーを推薦するアームを多く引いていることがわかります。
実験2でのアームごとの選択数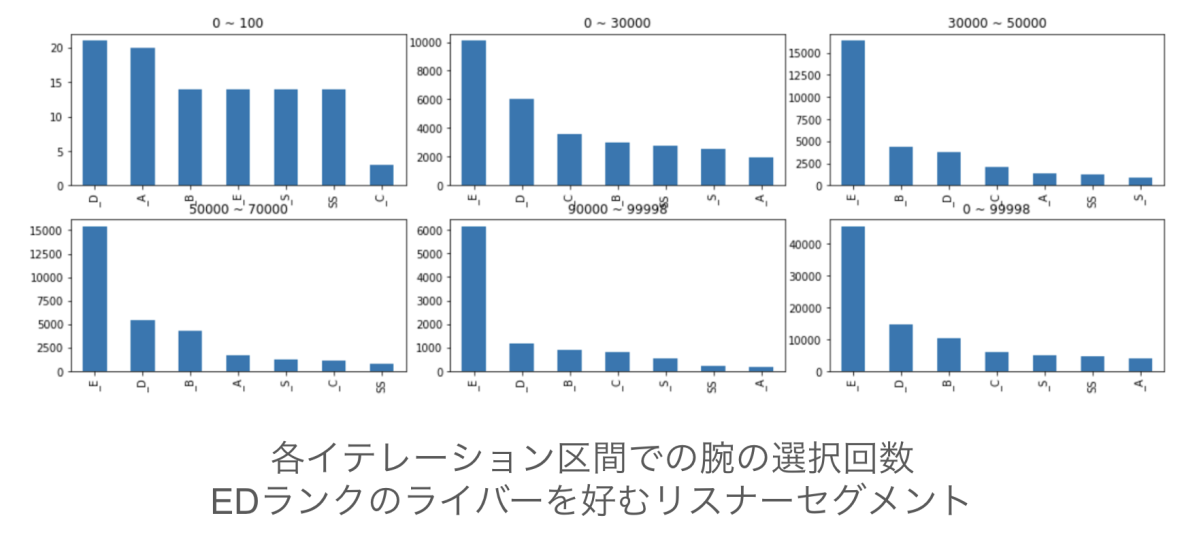
実験3
実験3では新規リスナーを効果的にセグメントに推薦できるかの検証を行いました。 一般的なサービスにおいて新規ユーザーというのは離脱率が高いため、できるだけ早い段階でサービスに対して良い体験をしてもらうことが重要です。しかし、コンテキスト付きバンディットはもちろん、今回用いているコンテキストなしバンディットもセグメントの分割基準にリスナーの過去のライブの視聴履歴を用いるため、新規リスナーをセグメントに分割することができません。そのため、あらかじめオフラインデータを用いてセグメントの作成とそのセグメントにあったライバーの選択アルゴリズムを決定しておき、新規リスナーに対しては、オンラインでどのセグメントに振り分ければ良いかをバンディットのアームとすることを考えます。この方法により、コンテキスト付きバンディットを使用する方法に比べて新規ユーザーのコールドスタート問題を解決することができると考えられます。
実験では、事前に定義するセグメントをEDランクのライバーを好むリスナーセグメント、Cランクのライバーを好むリスナーセグメント、…、Sランクのライバーを好むリスナーセグメントとし、それぞれのセグメントで対応するランクのライバーの中でユニークリスナーが多い上位10人を推薦することにしました。例えば、Aランクのライバーを好むリスナーセグメントでは常にAランクライバーでユニークリスナー数が多い上位10人が推薦されることになります。
そして、新規リスナーを想定したコンテキストを一切持たないリスナーを50人抽出し、それぞれのリスナーに対して100回のセグメントの推薦を行いました。
この実験設定を図に表すと以下のようになり、オレンジで囲った部分に対してバンディットアルゴリズムを適用します。
実験3のイメージ図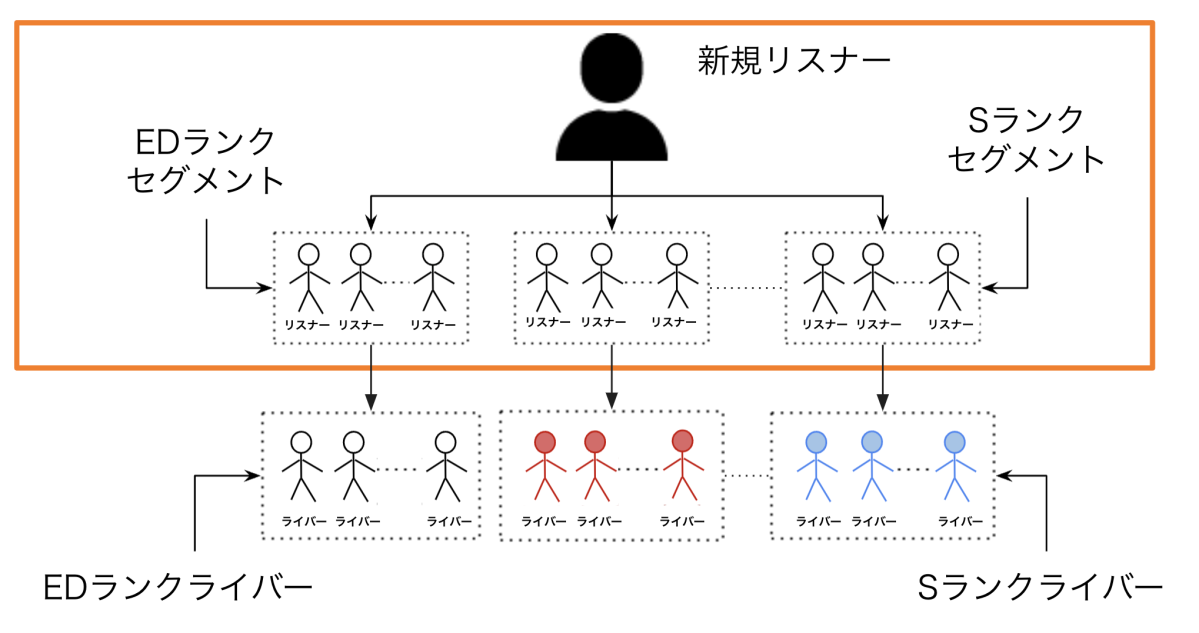
以下が実験結果になります。
実験3の結果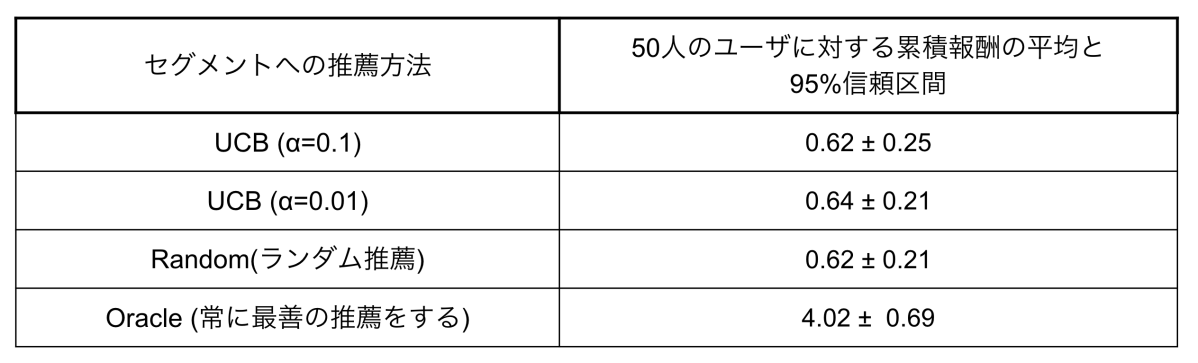
UCBの$\alpha$は探索の強さを調整するためのハイパーパラメータで小さいほどアルゴリズムが探索よりも搾取を重視するようになります。実験結果より、今回の手法はランダム推薦とほとんど変わらない結果になりました。これは、各ユーザ100回の推薦では一回も報酬を得ることなく終了してしまうケースが多く発生し、バンディットアルゴリズムが探索から搾取に移れなかったことが原因だと考えられます。そのため、報酬を得られる条件を緩めたり、セグメントやセグメントに対するライバーの推薦方法を改善することでこの問題は解決できる可能性があります。
まとめ
コンテキストなしバンディットはコンテキスト付きバンディットに比べて、システムに導入する際のコストや学習コストが小さいというメリットがありますが、ユーザーごとの特徴を用いることができないため、効果的な推薦ができないというデメリットがあります。 今回、コンテキストなしバンディットにセグメント分割を組み合わせることでコンテキスト付きバンディットよりも効果的な推薦ができるようになりました。 また、各セグメントにおいて提案した手法はランダム方策よりも効果的な推薦ができていることが確認できました。新規リスナーを想定した実験ではランダム方策とほとんど推薦の性能は変わりませんでしたが、報酬関数の設計やセグメントの軸の決め方によっては改善できる可能性があります。
インターン感想
2週間という限られた時間の中で何をやっていくか取捨選択するというのは、時間を沢山使える普段の大学での研究とは違い大変でした。しかし、メンターさんとのdaily meetingや強化学習相談会での議論のなかで、実験設定や方向性に関して様々なアイディアやアドバイスを頂いたおかげで、効率よく様々な検証を行うことができた他、課題について深く考察することができました。普段のミーティングでお世話になった方々をはじめ、発表会や懇親会に来ていただいた社員さん、インターンを行うにあたり様々なサポートをしてくださった社員さんに心から感謝申し上げます。今回のインターンで学んだこと、反省点などを今後の生活の中で意識しつつ更に精進していきたいと思います。
参考文献
-
Auer, Peter & Cesa-Bianchi, Nicolò & Fischer, Paul. (2002). Finite-time Analysis of the Multiarmed Bandit Problem. Machine Learning. 47. 235-256. 10.1023/A:1013689704352. ↩︎
-
Russo, Daniel, Benjamin Van Roy, Abbas Kazerouni, Ian Osband, and Zheng Wen. “A tutorial on thompson sampling.” arXiv preprint arXiv:1707.02038 (2017). ↩︎
-
Li, Lihong, Wei Chu, John Langford and Robert E. Schapire. “A contextual-bandit approach to personalized news article recommendation.” ArXiv abs/1003.0146 (2010). ↩︎


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。