





はじめに
こんにちは。DeSCヘルスケアシステム部でインターンをしている中島です。本記事では開発に関わった2つのサービス「ハレトケ」「カラダモ」の負荷テストで得た知見について紹介したいと思います。 負荷テストをこれからやる方や、システムのパフォーマンスチューニングに興味のある方などの参考になると嬉しいです。
負荷テストの目的
まず、負荷テストをどのような目的でやるのかについて抑えておきます。一般的にクラウド環境での負荷テストの目的は以下の5つが挙げられます。(出典:Amazon Web Services負荷試験入門 ――クラウドの性能の引き出し方がわかる Software Design plusシリーズ)
- 各種ユースケースの応答性能を推測する
- 高負荷時の性能改善を行う
- 目的の性能を提供することができるハードウェアをあらかじめ選定する
- システムがスケール性を持つことを確認する
- システムのスケール特性を把握する
ここで5のスケール特性とは何かというのを補足しておきます。負荷テスト中に「インフラ構成においてある部分を補強した結果、システムの性能が向上した」という結果が得られたとします。この情報を知っておけば、例えば、アクセス数が増えたのでスループットを今の2倍にしたい場合、どの部分を増強すべきか、ということが分かるため適切な対処をすることができます。このように「どの部分を増強すれば性能がどれだけ上がるか」という性質をスケール特性と呼びます。
一般的な負荷テストの目的は挙げたとおりですが、限られた時間で負荷テストを行わないといけない場合は、必要性に応じて部分的または1つの目的を重視して行うこともよいでしょう。今回は、3の「目的の性能を提供することができるハードウェアをあらかじめ選定する」の優先度が高かったため、この目的に合うような検証を重点的に行いました。
サービスの性質によって負荷テストのやり方は異なる
まず、大きく分けてシナリオテストが必要かどうかによって、やり方や使用するツールが変わってきます。今回の負荷テストの対象である「ハレトケ」と「カラダモ」はサービスの性質が異なります。それぞれの性質は以下の通りです。
ハレトケ
ハレトケ は働く女性の生活がプライベートも仕事も豊かになるような特典や情報を提供し、自分らしい毎日が送れるよう応援するwebサービスです。システム的な観点から言うと、トップページに多くの情報が掲載されているのがハレトケの特徴で、トップページでは様々な情報を取得するために何種類かのエンドポイントに対してリクエストしています。また、トップページや記事詳細に関しては、アカウントの登録やログインなしでもアクセスできるようになっています。ハレトケを訪れるユーザーの大半がトップページから流入し、そのトップページからサーバに対してリクエストする回数も他のページに比べて多いので、トップページを重点的にテストすべきだということが分かります。閲覧がメインとなり一連の動作でデータを作成したりということもないので、シナリオを作る必要がないと判断しました。また、多くのユーザーに共通の情報を出すことが多くキャッシュが活用できることも分かります。
ハレトケ トップページ
カラダモ
カラダモ は、ゲーミフィケーションを活用し、ユーザーの食生活・ライフスタイルに合わせ運動を提案する、長く続けるためのダイエットサービスです。サービスはネイティブアプリの形で提供されています。アプリの使用にはログインが必須で他のユーザーとのインタラクションはないので、サーバ側では個人の行動を保存したり、その情報から計算したものなどをアプリへ返すなどが中心となってきます。ハレトケのトップページのように多数のユーザー間共通の情報はあまりなくキャッシュの活用が比較的難しいシステムです。また、食事を記録した後に流れで運動のタスクを設定するといった一連の動作があるため、シナリオテストが必要だと判断しました。
カラダモ 食事・タスク記録
システムアーキテクチャ
ハレトケ・カラダモでは主にGoogle Cloud Platformを利用しています。BackendはGoで稼働するマイクロサービスで構成されており、Backendのそれぞれのマイクロサービスとそれらを集約するAPI Gatewayが存在します。また、ハレトケではFrontendで認証やセッションの管理などを行うBFFがあり、Node.jsのランタイム上で稼働しています。BackendのそれぞれのマイクロサービスやハレトケのBFFはCloud Runを使って稼働しています。
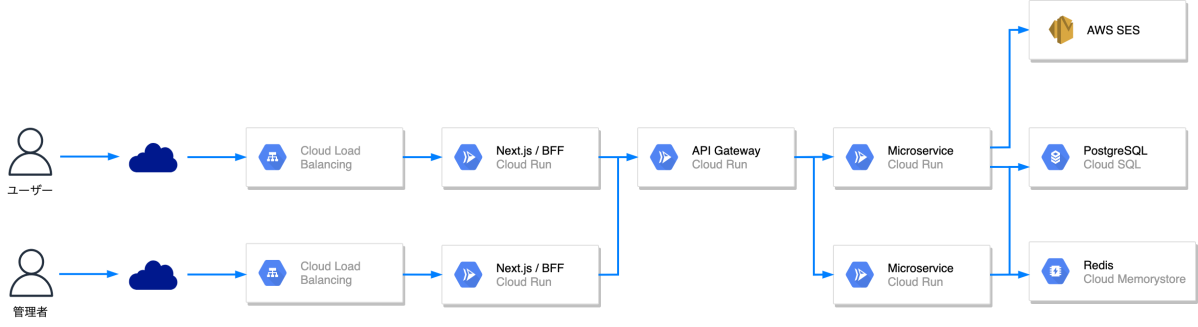
ハレトケ アーキテクチャ
Cloud Runを採用することで、GKEを採用するのと比べて、オペレーションの負担を軽減することができます。負荷テスト時にもスペック調整の容易さであったりオートスケールが手軽に使用できたりと恩恵を感じることができました。微調整のため、スペック変更をコンソール上から行うことも多かったですが、Cloud Runではデプロイ履歴が残っていてすぐロールバックをできる点も使いやすく、またKnativeのマニフェストでスペックを記述することができるためGitOpsや規模が大きくなってからのKubernetes移行もしやすい印象でした。
負荷テストツールの選定
負荷テストツールは有名なものをあげるとApache Bench, Apache JMeter, Locust, Tsung, Gatling, Vegetaなどがありますが、このうちApache BenchとVegetaはシナリオテストができないので今回は要件に合っていません。また、メンテナンス性を考えるとスクリプトを記述する言語も考慮に入れる必要があります。チーム内で使用できる共通の言語はGoなのですが、残念ながらGoでシナリオの書けるツールが見つかりませんでした。JavaScriptであればほとんどの人がかけるとの事だったので、JavaScriptでスクリプトを書くことができ、シナリオも書くことができるk6を選定しました。
k6 はGrafana Labsが開発している負荷テストツールおよびSaaSです。Open Sourceで無料のコミュニティ版と、マネージドで負荷テスト環境を用意してくれるSaaSのk6 Cloudがありますが、今回はOpen Sourceの方を使用しました。SaaS版はGUIがあったりと魅力はありますが、インターネット経由での負荷をかけるためネットワーク距離が遠く、初めて負荷テストをする上ではなるべく不安要素を少なくしたかったため、VPC内に環境を構築できるOpen Source版を採用しました。
負荷テストの流れ
流れを見ていく前に軽く負荷テストのアプローチについて触れておきます。負荷テストのアプローチと目的を挙げてみます。
- 性能テスト:システムが想定している負荷に対し、どの程度のスループットやレイテンシかを確認する
- 限界テスト:処理限界に近い、または超過した負荷に対し、エラーが出るかなど、挙動を確認する
- 耐久テスト:長時間負荷をかけた際の挙動を確認する
次に今回行った負荷テストの流れを見ていきます。ただし、前述したとおりサービスによってシナリオテストの有無などの差分があります。ここではシナリオテストを含むカラダモの例を紹介します。
- 負荷テスト計画書の作成
- 負荷テスト環境の構築・負荷テスト対象のスペックを最低限に変更
- ダミーデータ作成
- 負荷テスト環境と負荷テストツールの検証
- 単一エンドポイントに対するテスト
- オートスケールを有効にした場合のテスト
- シナリオテスト
- 耐久テスト
5から7に関しては、起動クライアント数を徐々に上げ、負荷を上げていくことでスループットが限界となる負荷を探索していくので、性能テストと限界テストを兼ねているものとしています。
スループットとレイテンシ(応答時間)
アプリケーションの性能を測る上での重要な指標としてスループットとレイテンシ(応答時間)があります。一般的にスループットは単位時間当たりの処理能力やデータ転送量のことで、レイテンシは転送要求を出してから実際にデータが送られてくるまでに生じる通信の遅延時間のことです。ここではWebシステムの慣習に従って、スループットは1秒間に処理を行うHTTPリクエストの数、レイテンシをアプリケーションの処理時間によって遅延した時間とします。ただし、レイテンシはユーザーから見た処理時間と、システムから見た処理時間がありますが、今回はUXの観点から前者のレイテンシを使用しています。
以下の図は、例えばシステムがService AからCで成り立つマイクロサービスだった場合にそれぞれのサービスの性能とシステム全体での性能がどのようになるかを表したものです。スループットの値が最も低いService Bに引きずられる形で全体のスループットが決定し、レイテンシはService AからCまでの合計が全体のレイテンシとなります。ここでスループットに関してのボトルネックはService Bだと言えますが、もし、Service Bをチューニングした結果、1000 req/sでリクエストを捌くことができるようになった場合、ボトルネックはService Cに移動します。このようにボトルネックは移動していくので、改善の度に性能を測り直す必要があります。
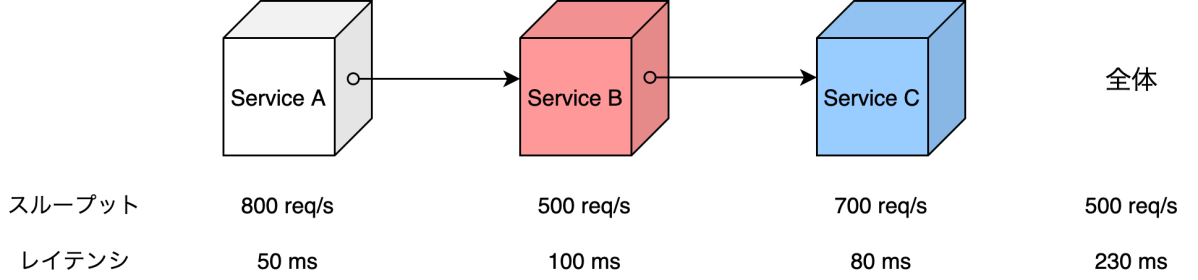
システム全体における性能
進め方
負荷テストの進め方として以下のようなサイクルでチューニングを行いました。まず最初にスループットの限界値を見つけるところから始めます。
チューニングサイクル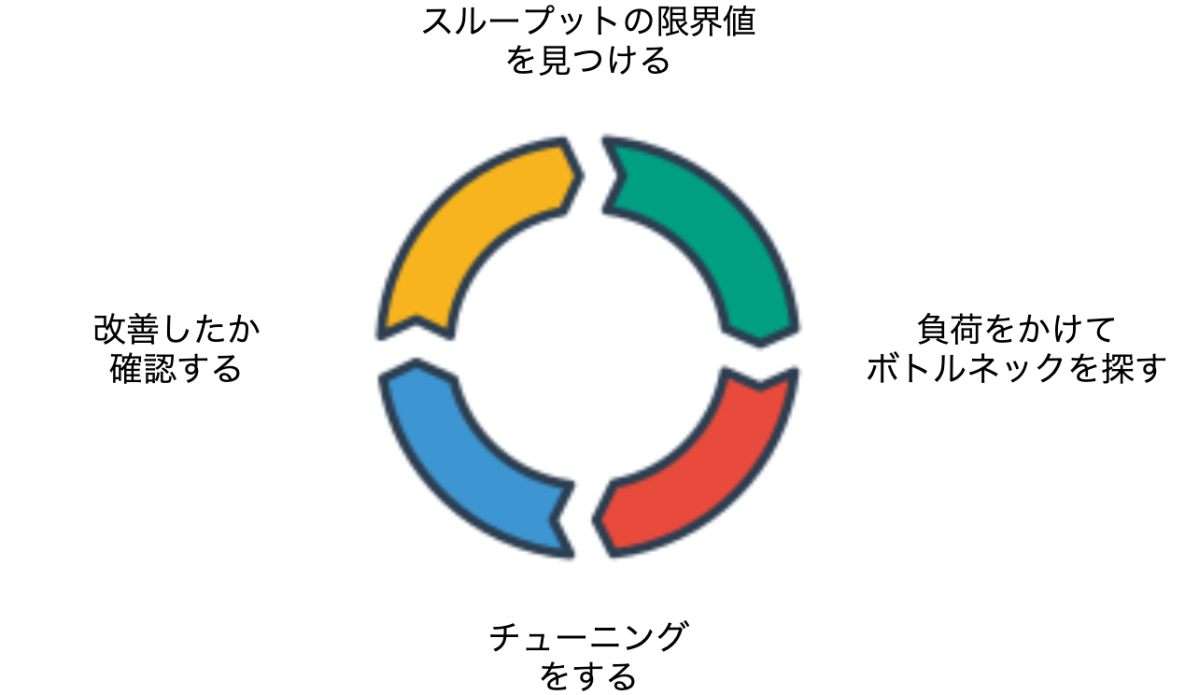
スループットの限界値を見つける
スループットの限界値が出る状態は現時点での性能限界に到達するほど負荷が十分かかっているということであり、ボトルネックを見つけられる状態ということになります。スループットの限界値を見つけるためには同時にアクセスするユーザー数(図ではクライアント数、k6ではVUs)を徐々に上げていくことで発見できます。以下の図は各マイクロサービスのインスタンス数を固定にして負荷をかけたときのグラフです。赤いグラフがレイテンシ、青いグラフがスループットの値で、それぞれ右の縦軸と左の縦軸に対応しています。ここで、スループットが右肩下がりになる部分で点線の部分がスループットの限界値と言えます。この時のクライアント数で負荷をかけた時が過不足なく性能限界を引き出すことができると言えます。
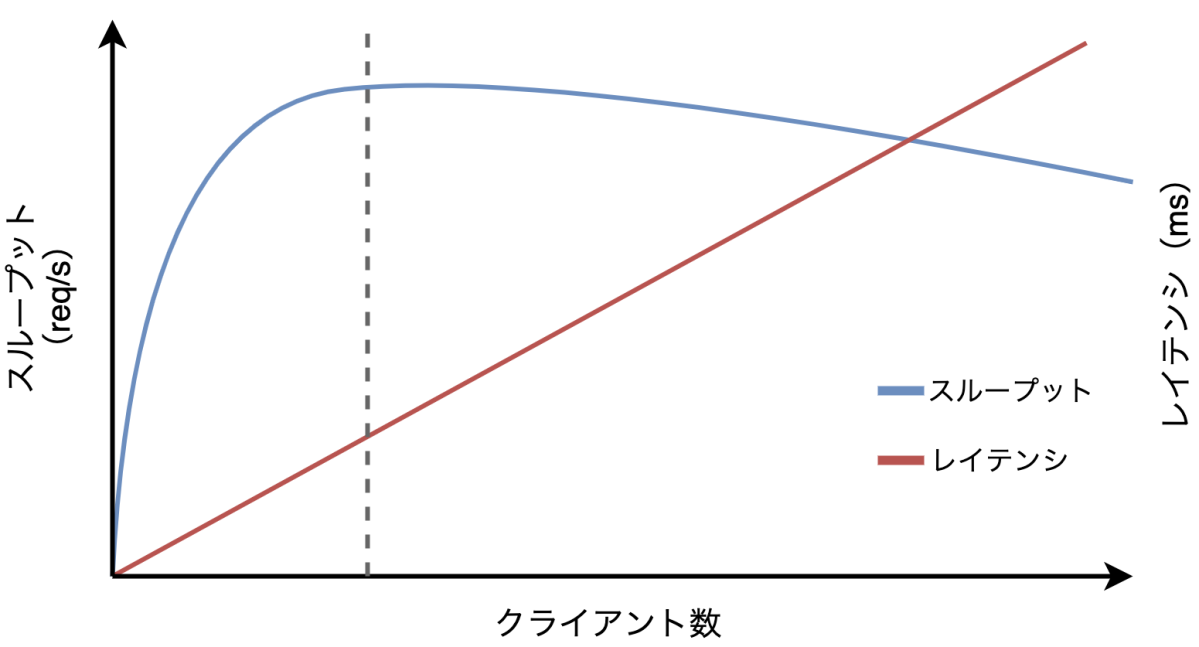
スループットの限界値
チューニング
チューニングに関してはマシンリソースの増強や、ソースコードレベルでアプリケーションをパフォーマンスチューニングするやり方がありますが、リリースまでの期間が限られていることと「目的の性能を提供することができるハードウェアをあらかじめ選定する」ことを念頭に負荷テストを行っているため、ほとんどのチューニングはマシンリソースのチューニングの範囲で行いました。具体的なチューニングすべき点の一例を挙げておきます。
- CPUが足りない
- メモリリソースが足りない
- DBの接続方法が適切でない
- キャッシュ利用方法が適切でない
- SQLが非効率(スロークエリ)
- DBに適切なインデックスが貼られていない
興味深かった点として、オートスケールとDBのコネクション数の話を後ほど紹介します。
負荷テスト実行したときに得られた知見
ここまでの内容はどちらかというと教科書的な内容ですが、ここでは実際に負荷テストを実行した時に得られた知見を紹介します。
負荷テストの目標値設定
負荷テストの計画書作成をすることも、負荷テストを実施するのと同じくらい重要なことです。計画書の前提が崩れてしまうと実施したデータを再計測しなければならなくなるためです。ただ、エンジニアだけではサービスのアクセス数やアクティブ率などを予測できないため、PdMや企画の方とのコミュニケーションが必要になります。アクセス数はマーケティングの動きとも連動するため、どのタイミングでマーケティングに力を入れるかなどの計画を考慮すべきです。また、メディアへの露出もスパイクになる可能性があるため、事前に聞くようにしました。
ユーザー数のシミュレーションの資料をもらい実際に計画を立てていくわけですが、何個か悩む部分がありました。
1つめは、参考にしていた本によるとリリース時であれば1年後あたりのアクセス数を想定して負荷テストするのがよいと書いてありましたが、リリースしていない状態で不確定要素も多く、1年後の数字を使った負荷テストの結果がどれだけ確からしいかを考えたときにやるべきなのか悩ましかった点です。考えた結果、リリース直後の方が考慮する優先順位が高いと判断したため、リリース後3ヶ月を想定した負荷テストを行い、スケジュール的に余裕があれば1年後も行うという形にしました。
2つめは、レイテンシの目標値をどのように設定するかという点です。基本的にはUXをベースとして、例えばハレトケであれば高負荷時でも1秒以内にトップページが表示されるといった目標値にしました。Googleが提唱しているWeb上のUX品質指標である Core Web Vitals のLargest Contentful Paint (最大視覚コンテンツの表示時間)を元に最低限の表示時間を決定しました。
3つめは、MAUやDAUから同時アクセス数とRPSを算出するのが意外と難しく、とくにシナリオが絡むとシナリオ間で差分があるため大まかな算出結果になってしまう点です。最初にやったハレトケでは目標値に関して達成できるかを検証していましたが、シナリオテストを含むカラダモでは限界テストも含めて十分にデータを採りたかったため、前述した同時アクセス数を徐々に増やし、スループットの限界値を探すようなやり方に変えました。そのため、大まかな目標値であっても、ちゃんと限界性能を知っておくことで、ある程度の幅を持って目標値を達成していることを保証できるようになり、シナリオ間の差分を考慮できるようにしました。
メトリクスに注意
負荷テストの中盤でボトルネックが特定できず困った話の紹介です。 ハレトケ、カラダモは共にGCP上でインフラ構築されているため、負荷テスト対象のリソースの監視にはCloud Monitoringを使用しました。Cloud Monitoringはデフォルトで各種Google Cloud サービスのメトリクスを取得しているため、特に設定していなくても使用できます。大体はメトリクスの内容は名前やドキュメントを読むことで理解できますが、今回は自分の意図した挙動をしてないものがあり、それを正しいと思い込んだことでミスに繋がりました。BFFを含めて負荷をかけていた部分をもっとサーバに近い部分の範囲に限定することで、このことに気づくことができましたが、そもそも最初はBFFを含めて負荷テストをしないようにすべきでした。
また、Cloud Loggingに限定した話ですが、時系列のデータを前処理するかによっても表示が変わるため、ダッシュボードを作る際はよく確認した方がいいと思います。負荷テストツール側のスループットやレイテンシと見比べて同じような値になっているか、前述のとおり、負荷をかけるときに関係するコンポーネント数を最小限にすることを意識し変数を少なくすることでミスを起こりにくくすることもできます。
オートスケールとDBコネクション数
インスタンス数の制限なしでスケールアウトできるとすると、先ほどのスループットの曲線で見たような右肩下がりの曲線にならず限界値が現れません。しかし、Cloud SQLには接続数上限があるため、インスタンス数を増やしすぎると接続上限を超えてしまう可能性があります。そのため、ソースコード側で設定したコネクション数(Goであればdb.SetMaxOpenConns()などで設定できる)と最大インスタンス数をかけたものがCloud SQLの接続数上限を超えないようにする必要があります。最大インスタンス数を制限してしまった結果、想定アクセス数などの要件をパフォーマンス面で満たせない場合はスケールアップも組み合わせると良いと思います。
おわりに
負荷テストを全くやったことない状態からの出発でしたが、1ヶ月で負荷テストの感覚を掴むことができました。計画は綿密に行い想定アクセス数やデータ数などの前提が崩れないようにしっかり固めることが大事だと思います。一方で、実行する段階では、なんとなく進めない、違和感があったらデータをよく見てやり方や前提を疑ってみるという感覚が大事だなと感じました。
この記事を読んで「面白かった」「学びがあった」と思っていただけた方、よろしければ Twitter や facebook、はてなブックマークにてコメントをお願いします!
また DeNA 公式 Twitter アカウント @DeNAxTech では、 Blog記事だけでなく色々な勉強会での登壇資料も発信してます。ぜひフォローして下さい!


最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。