





はじめに
夏にAIスペシャリストコースのインターンシップに4週間参加させていただいた沖田と申します。普段は連続最適化の研究をしています。
今回、インターンシップ中に取り組んだ『逆転オセロニア』というゲームのデッキ編成における工夫について執筆したいと思います。
まとめ
- 集合に対する組み合わせ最適化問題として、強化学習および遺伝的アルゴリズムを用いデッキ生成を行った
- 評価関数としてLightGBMと相関トピックモデルを用いた
- 駒単体に対してのアーキタイプ確率を最大化した時と比較し、アーキタイプらしさの向上が確認できた
逆転オセロニアについて
『逆転オセロニア』とは、オセロをベースにしたゲームです。手駒のキャラクターは攻撃力や回復力等、様々なスキルを持ちます。

逆転オセロニア
手駒の合計HPがユーザのHPとなります。相手のHPを先に0にした方が勝ちになり、ユーザは攻守のバランスを考えつつ戦略を練ることが要求されます。
ユーザは、決められたコスト制限の下、16個の駒から成るデッキを構築します。なお駒には高いHPを持つ「神」タイプ、妨害系スキルを持つ「魔」タイプ、高い攻撃力を有する「竜」タイプが存在します。
アーキタイプとは
アーキタイプとは、戦略を反映したデッキタイプです。デッキ属性より細かく、「速攻竜アーキタイプ」、「コンバートアーキタイプ」等の型が存在します。このアーキタイプを反映したデッキを構築することでより戦略的に勝利を狙うことが期待できます。
テーマ概要
本インターンシップでは、ユーザの所持駒から組めそうなアーキタイプ推薦およびデッキ構築を行いました。さらにゲームを始めたての初心者ユーザ向けに、手に入りやすいかつ未所持の駒も含めてデッキレコメンドを行いました。
目的としては以下の3点があります。
- 既存のデッキ構築サービス(オススメ編成)は各4属性のデッキ(神デッキ、魔デッキ、竜デッキ、混合デッキ)を組めるが、これをアーキタイプの種類別(今回は16種類)増やすことで遊び方の幅を増やしたい。
- 自身の所持駒から組めるアーキタイプをユーザが把握でき、かつ実際に構築可能なデッキを提供することでユーザの経験増進につなげる。
- 持っていない駒を初心者ユーザに推薦することで、具体的にどの駒で効果的なデッキを構築できるかをユーザが把握可能にする。
なお、現状の「道場」の「お試しデッキ」でもアーキタイプ別のデッキを試せますが、これはユーザの現在の所持駒を度外視してすべてのユーザに一律にアーキタイプの典型的なデッキを推薦しているので、本インターンシップでは各々のユーザの所持駒(+手に入りやすい駒)から、ユーザにカスタマイズされたアーキタイプ別のデッキを推薦することを目指しました。
問題設計
この問題を解くにあたって必要になることを明確にするため、問題を定式化したものを以下に整理しました。$\boldsymbol{x}, X, \boldsymbol{c}, f$をそれぞれデッキ、所持駒、デッキ駒に対応するコストベクトル、アーキタイプらしさを測る関数とします。アーキタイプを最大にするデッキを求める問題は以下のように定式化できます。ただしデッキ駒の個数は16、コスト制限は200としています。
$$\underset{\boldsymbol{x}}{\text{arg max}} f(\boldsymbol{x})$$ $$ \text{subject to } \boldsymbol{x}\subset X, |\boldsymbol{x}| = 16, \boldsymbol{c}^\top \boldsymbol{x}\leq 200$$
上式において定義しなければいけないのは
- どのようにアーキタイプらしさを定義および定量化するか(関数$ f $)
- 制約下でどのように所持駒からデッキに含める駒を選択するか($ \boldsymbol{x} $)
の二つの要素です。
アーキタイプらしさの定義・設計
相関トピックモデルの導入
まず、最初の要素であるアーキタイプらしさの定義をしました。現状のオセロニアではトピックモデルの一種であるLDA(Latent Dirichlet Allocation)がアーキタイプ分類に用いられています。トピックモデルとは、自然言語処理で用いられる手法で、文章にどのような話題(トピック)が存在しているのかを抽出するために用いられる手法です。
今回、相関トピックモデル(Correlated Topic Model)を用いました。相関トピックモデルは、LDAで用いられているDirichlet分布の代わりに正規分布を用いることで相関をモデル化したトピック分布を生成する手法です[1]。相関トピックモデルを用いる理由として、アーキタイプも神、魔、竜、混合と大別されるのでトピック間の相関が存在することが挙げられます。これを用いてアーキタイプ分類を行った結果が以下になりました。アーキタイプの数は16に設定しています。この値はperplexityやcoherenceの値を見て決定しました。なお、比較対象のLDAはオセロニアで実際に用いられているものとは条件が異なる場合があります。
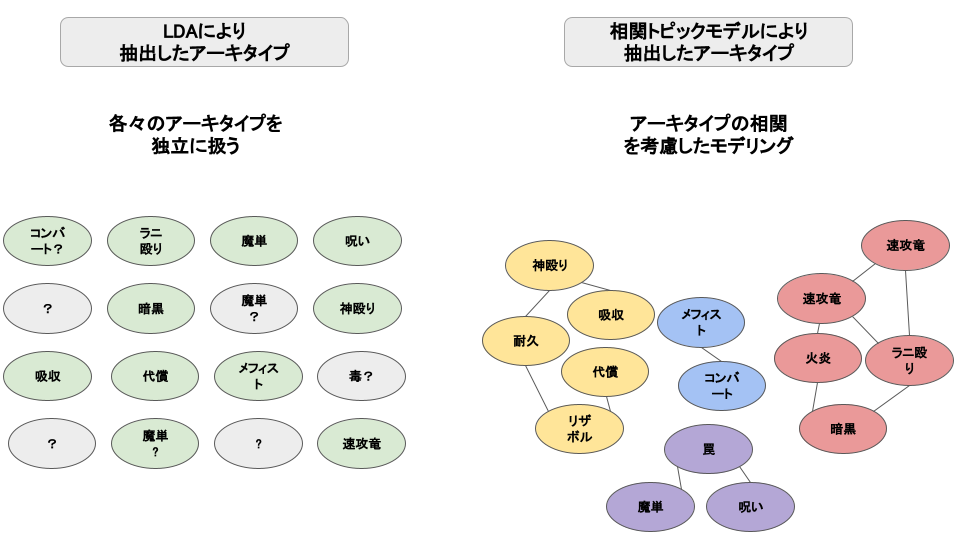
LDAと相関トピックモデルの分類比較(相関の様子はイメージです)
LDAにおける分類では、灰色の部分で示されているどのアーキタイプか判別の困難なトピックがある一方で、相関トピックモデルによる分類では、一部重複したトピックが存在するものの、LDAを用いて行った分類よりはアーキタイプ分類の性能が向上していることがわかりました。なお、アーキタイプが神、魔、竜、混合と大別されるのならばパチンコ配分モデル(Pachinko Allocation Model)のような階層的なモデルを用いた方がより実際に近いのではないか、とも思い実験しましたがアーキタイプ分類に失敗しました。これは、混合アーキタイプが、神、魔、竜にまたがるアーキタイプであることで階層表現が失敗したことが原因かと思われます。これを踏まえ、トピックモデルには相関トピックモデルを用いることにしました。
デッキ情報から推論可能に
ここで、アーキタイプらしさの関数ができましたが、一つ問題がありました。アーキタイプ分類はオセロニアのシーズンマッチ上位のダイヤモンド帯(Di帯)のユーザのデッキデータを用いて行いました。これはユーザのレベルが非常に高くデッキのアーキタイプが完成しているからです。しかし、初心者のデッキにこのモデルを適用すると、ダイヤモンド帯の人々が使わない駒が入力に入ってくるので推論が不可能になります。なぜならLDAや相関トピックモデルは付随する属性を無視し、自然言語処理でいう「単語」のように各々の駒を扱っているからです。
よって、駒の属性を特徴量にするモデルを作成することで未知の駒にも対応できるようにしました。相関トピックモデルの出力はアーキタイプ分類を大幅に表現できていることが確認できているので、入力をデッキの属性、教師を相関トピックモデルの出力として、LightGBMで確率を算出する最終的なモデルを作成しました。これにより、HP合計やATK合計といった、ダイヤモンド帯以外の帯でも観測される「属性」情報からアーキタイプ推論を目指しました。相関トピックモデル出力を教師として扱うことの正当性は、相関トピックモデル出力が妥当なアーキタイプ分類を行えていること、さらに駒の属性からの推論という文脈でLightGBMのような勾配ブースティング木を用いることで表現力の担保が期待できること、の2点を根拠にしています。
なお、HP、ATK、スキル、コンボスキルのみならず、スキルとコンボスキルの共起も特徴量として与えました。これはスキルとコンボスキルは同時に発動するものであり、その共起を取ったほうがコンボスキルが「どのように」発動するかを表現でき、そのデッキの特徴をより明確にできると考えたからです。実際にプレイした時コンボスキルの発動が試合の勝敗を左右する鍵となりますので、この特徴量は重要です(実際に特徴量重要度を見てもこの共起の重要度が高いことがわかりました)。
このLightGBMの出力を以下、「アーキタイプ確率」と定義します。これは、16種類のアーキタイプの各々に対して「そのアーキタイプに分類される確率」を示す値で、総和は1となります。
まとめると、アーキタイプ確率の算出モデルの処理フローを示した図が下になります。
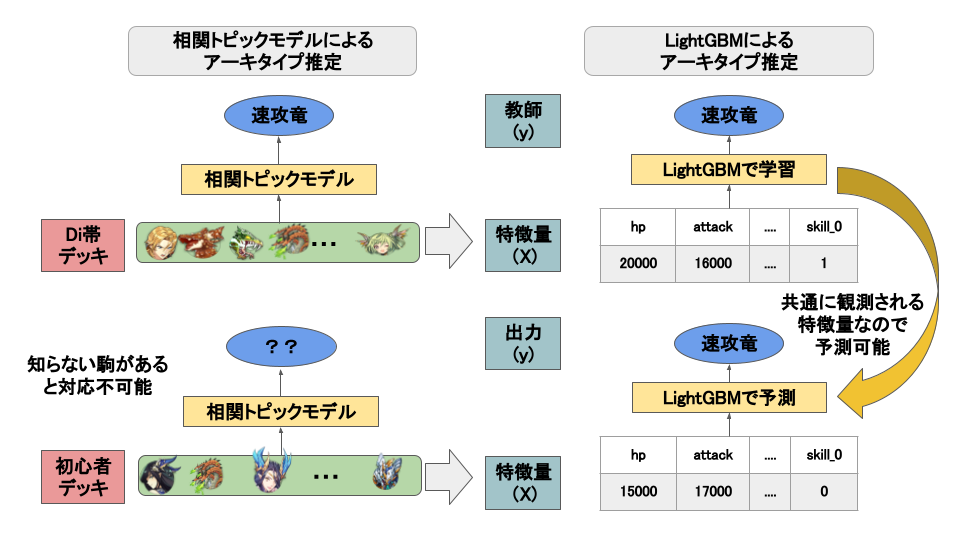
アーキタイプ確率の算出モデルの処理フロー(※画像はイメージです)
駒選択の手法
難点
アーキタイプらしさを定量化するモデルが完成したので、次は所持駒からアーキタイプ確率を最大化するデッキ駒をどのように選択するかを考えました。問題設計の部分で述べた$\boldsymbol{x}$のところです。ここで愚直に駒選択すると、4000個ほどの総駒から16個を選択するので最大で組み合わせが$_{4000}C_{16}\approx 2.0 \times 10^{44}$通りとなり、現実的に試行できる量ではありません。
さらに、駒単体のアーキタイプ確率が高いものを順に入れればいい、というわけでもありません。なぜならコンボスキルの存在等により、駒同士の相関を考慮しなければいけないからです。これらから駒の選択に関して考慮するべき点は以下の2点となりました。
- 探索空間をいかに削減するか
- 駒同士の関連をいかに考慮して集合に対する最適化を実現するか
探索空間の削減
ここでは、アーキタイプで頻出な駒(相関トピックモデルから求まります)と類似している駒にのみ絞る操作を行いました。竜デッキを作りたいのに神駒や魔駒も候補に含めるのは明らかに非効率的です。これにより探索空間を大幅に絞りました。
手法は、PCAとUMAPを用いました。各々の駒の属性を高次元の特徴量にし、これらを適用することで重要な情報を維持しつつ、特徴が似通った駒がより近くに配置されるようになります。この出力から駒同士の距離を計算し、アーキタイプで頻出な駒と類似な駒で、ユーザが所有している駒を絞りました。
なお、オセロニアには「同キャラ使用制限」があります。これは、同じ駒をいくつデッキに用いて良いか、という制限です。これもデッキに含める駒候補を絞り出す際に考慮してデッキ候補を作成しました。
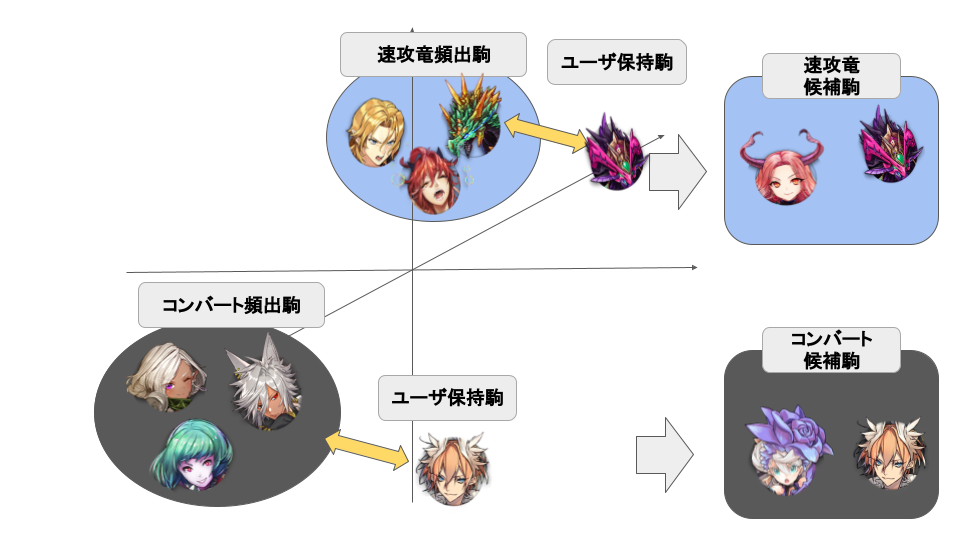
探索空間の削減の様子(※画像はイメージです)
集合に対する最適化
今回は制約の反映のしやすさ等の理由から強化学習と遺伝的アルゴリズムでデッキ生成を行いました。順に説明します。
強化学習
本ブログの主題です。今回、系列最適化問題として強化学習を適用させたのですが、これは論文[2]に着想を得ました。[2]はGoogle Brainから出された論文で、組み合わせ最適化を強化学習やニューラルネットワークを用いて解こうとするものです。論文中ではPointer Networkを用いて巡回セールスマン問題に取り組んでいます。巡回セールスマン問題はセールスマンが全ての場所を回って帰ってくるのに最短な経路は何か、を探す問題で、最小化したいのは総移動距離です。今回取り組んでいるデッキ構築では、デッキ集合に対してアーキタイプ確率を最大化するのが目的です。よって、巡回セールスマン問題同様に一つずつ駒を追加していき、最終的に完成したデッキに対して評価すれば、途中経路は考慮の対象ではないものの強化学習を応用できるのではないか、と考えたのがこの手法で取り組んだきっかけです。
巡回セールスマン問題との類似性
どの点において巡回セールスマン問題を応用可能なのか具体的に説明します。巡回セールスマン問題を強化学習で解く際、以下のように逐次的に地点を選択します。時点$t$における、訪問経路$s_{t}$を状態として、方策$p_{t}$に従い、次移動する地点の選択$a_{t}$を行います。これにより訪問経路$s_{t+1}$が生成されます。以上の処理を逐次的に行い、最終的に全地点を訪問し、総移動距離に対して評価を行います。下の図に概要を示しました。
巡回セールスマン問題を強化学習で解く際の地点選択(※画像はイメージです)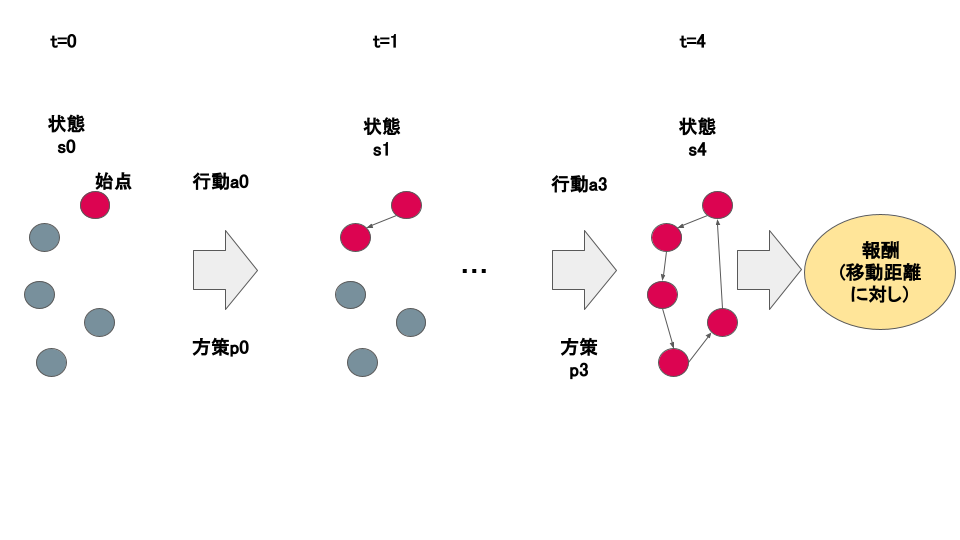
一方本問題の駒選択は以下のように整理できます。デッキの空集合を初期状態$s_{0}$とし、時点$t$において選択されている駒集合$s_{t}$を状態として、方策$p_{t}$に従い、次に選択する駒の選択$a_{t}$を行います。これを逐次的に行い、16個の駒を選択した後、アーキタイプ確率およびコストに対して評価を行います。巡回セールスマン問題は、全ての地点を経由するので初期地点は任意に与えていい一方で本問題では最初に選択される駒も学習する必要がある点と、終了条件(巡回セールスマン問題ではすべての地点が選択された時点ですが、本問題では16個の駒が選択された時点)が異なるものの、下の図と上の図とを比較すると、逐次的に処理を行う点と最終的な状態から得られるもの(巡回セールスマン問題だと総移動距離、本問題だとアーキタイプ確率)に評価を行う点で、巡回セールスマン問題の考え方を応用することができることがわかります。
デッキ構築を強化学習で解く際の駒選択(※画像はイメージです)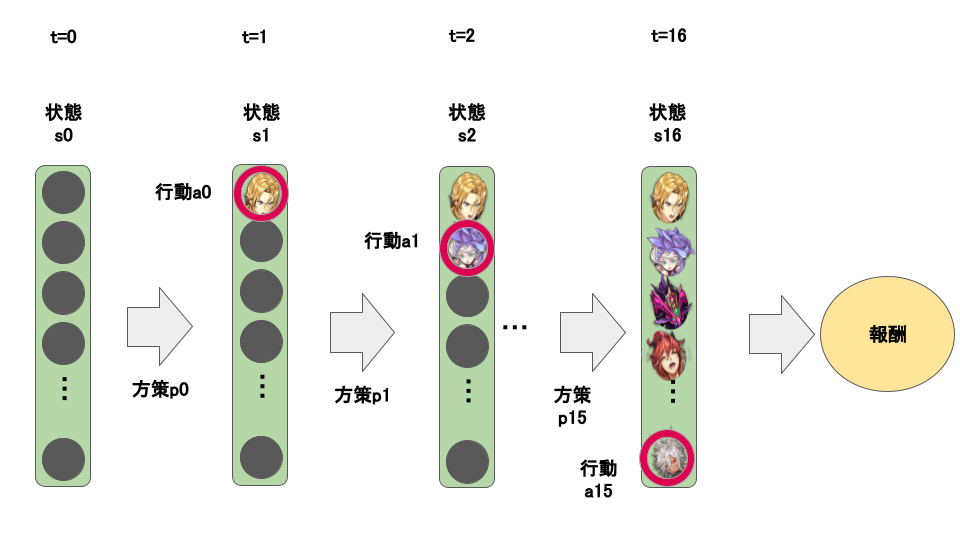
また、強化学習を採用した理由は、コスト制約やアーキタイプ確率といった罰則・報酬を与えれば、最適なデッキを試行錯誤の末に求めてくれることが期待できるからです。本問題はデッキ集合が完成して初めて評価ができる、という途中経過に依存しない難点と、デッキの教師が存在しない(なぜならばユーザが用いているデッキが最適なものとは限らないからです)難点がありました。これらに対して対処できる可能性を鑑み、強化学習を用いました。
具体的なアーキテクチャの話に移ります。先ほどの探索空間の削減で抽出したデッキ候補となる駒の特徴量(HP、ATK、スキル、コンボスキル等)を深層学習モデルに入力しました。深層学習モデルの出力の値が一番高い駒をデッキに含める駒として、この処理をデッキに含める駒数だけ逐次的に行いました。なお、一度選択された駒にはマスクをかけ次回選択されないようにしています。
こうして作成されたデッキに対して先述したLightGBMを適用しアーキタイプ確率を算出し、報酬としました。ここで、デッキのコストが200を超えていた場合や少なすぎる場合には罰則をかけました。最終的に方策勾配法を用い学習を行いました。処理の流れは以下の図に載せています。
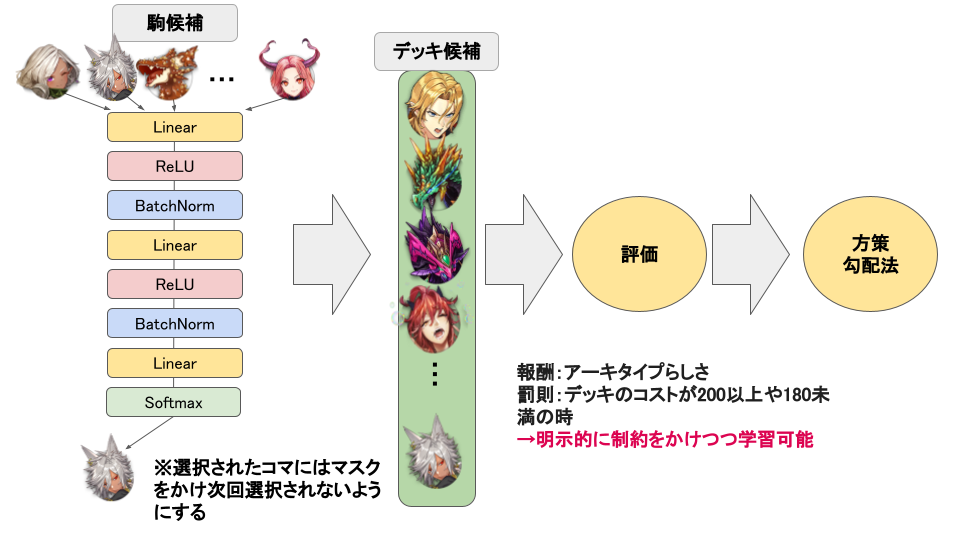
強化学習の処理概要(※画像はイメージです)
遺伝的アルゴリズム
遺伝的アルゴリズムは自然界の集団進化をアナロジーにした手法です。生物の進化過程で発生する「突然変異」等を擬似的に行い、最適な集団を生成するもので、今回のデッキ生成にも応用できるのではないか、と考えました。これは、別のゲームで進化論的アルゴリズムによりデッキ生成をしていき、勝率等の最適化を目指す研究[3]から着想を得ました。ここで、交叉や突然変異を行い集合を進化させていくのですが、単純に行うと、コストの違う駒同士が交換され、コスト制約を超えるデッキが出かねません。そこで交叉、突然変異は同コストの駒に絞り、コスト制約を満たすようにする工夫を行なっています。また、リーダー駒が変更されないようにリーダー駒は交叉や突然変異の対象には含めていません。処理の流れは以下のようになっています。
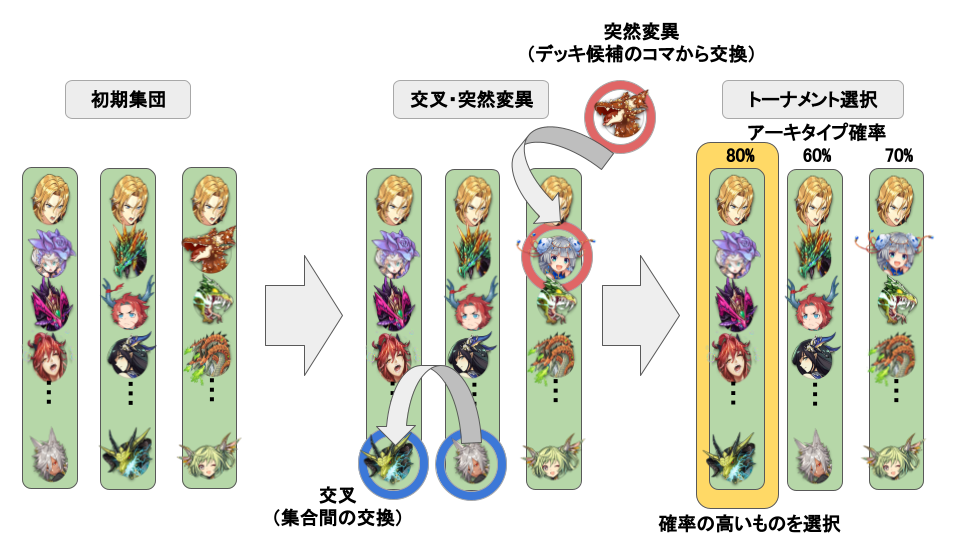
遺伝的アルゴリズムの処理概要(※画像はイメージです)
また、余談ですが[3]を探しているうちに、別のゲームでデッキ生成に強化学習を用いている論文[4]も見つけました。こちらは最大化する関数として、相手に対する勝率を設定していて、Q-Learningで学習させているので今回私が行った手法や目的とは違いますが、興味がある方はご覧になると面白いと思います。
手法の概観
今までの手法をまとめます。
- トピックモデルによりアーキタイプ抽出を行います。
- アーキタイプ毎に類似駒を検索し、探索空間を縮小します。
- 抽出された駒候補から、強化学習や遺伝的アルゴリズムを用いてデッキを構築します。
図に示すと以下のとおりです(CTModelと略されているのは相関トピックモデルのことです)。
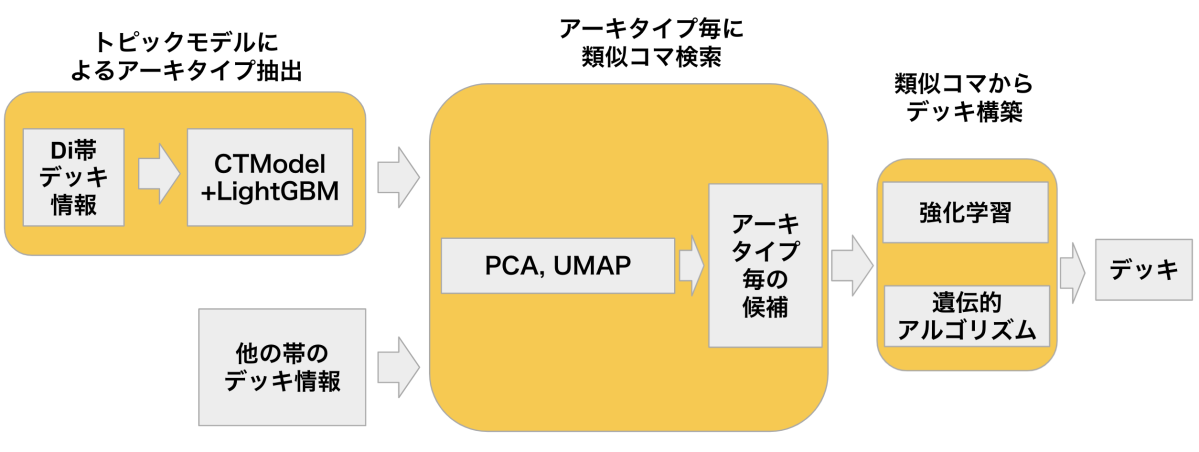
手法概観
初心者向けのデッキ構築
次に初心者向けのデッキ構築をどのように行なっているか述べます。各々のアーキタイプで有名な駒を多くユーザが所有していればデッキは組めますが、そういった駒がない前提で、今ある駒と手に入りそうな駒を合わせて、できるだけアーキタイプらしいデッキを作るという需要はあるのではと思います。この解決のため、他のユーザの所持率の高い駒を、あたかも持っているかのように仮定してモデルに入力しその出力をレコメンドしました。単純ですが、これにより、今組めるアーキタイプに足りない駒で、手に入れやすい駒が何か、をユーザが把握することができます。
結果
比較方法
上の手法を用いてデッキ生成を行った結果について説明します。その前に、本手法の比較対象について述べます。目的は集団内の関係性を考慮して最適化を行うことでした。よって、示したいのは「集団内の駒同士の関係性を無視してアーキタイプ確率最大化をした結果のデッキよりも、アーキタイプらしいデッキを作成できている」ことです。集団内の関係性を無視したデッキ生成は「個数制限付きナップサック問題」とみなせます。これは、各々の駒のコストを「重さ」とし、駒のアーキタイプ確率を「価値」とみなし、合計価値をコスト制限内で最大化する手法です。数式で書くと、以下のようになります。これにより、いかに集団に対してアーキタイプ確率最大化がなされているか、評価します(画像の数式で制約は省略しています。また$N$は本課題では16です)。

個数制限付きナップサック問題との比較
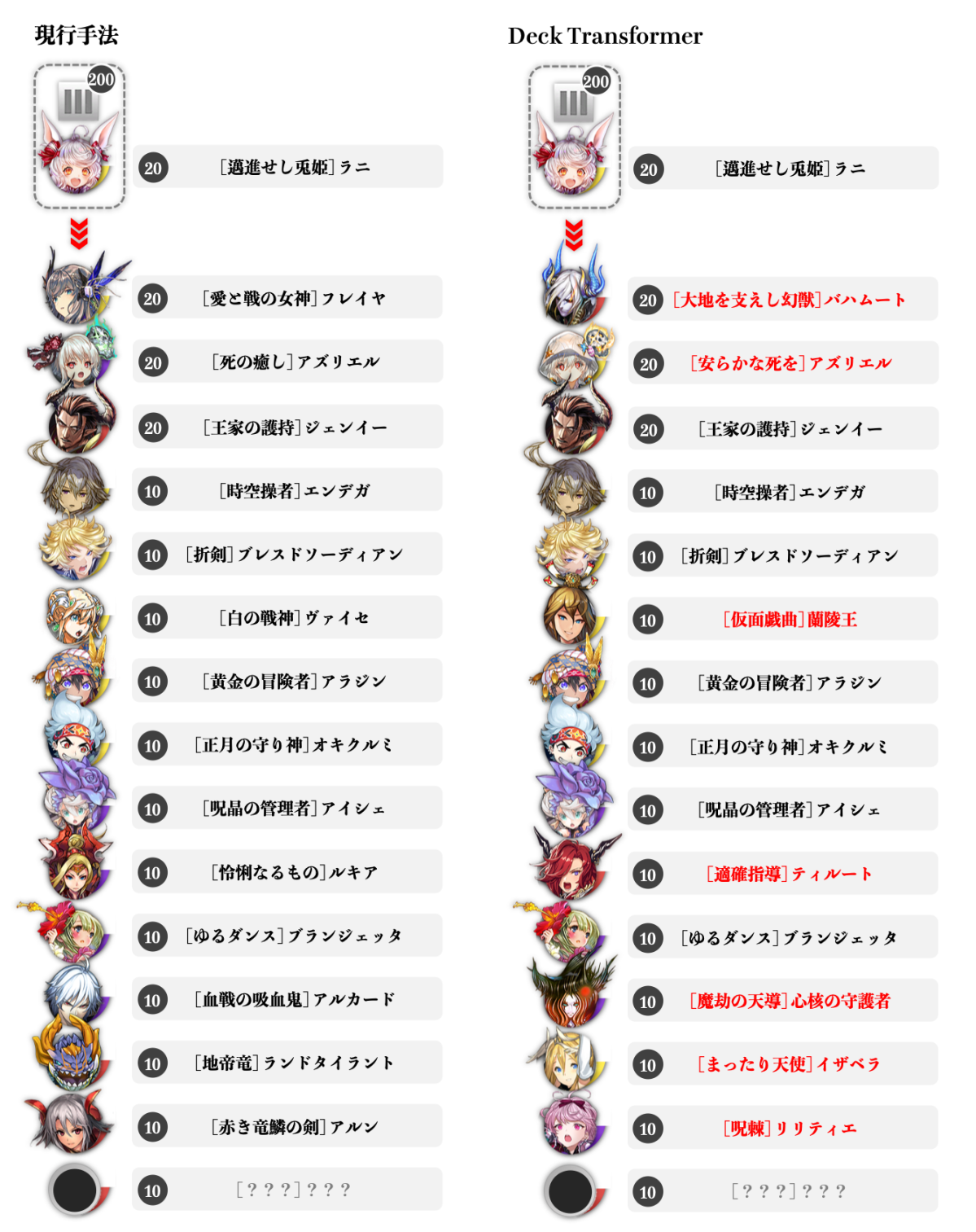
速攻竜アーキタイプ
速攻竜アーキタイプについての結果が以下になります。図の赤丸で囲った駒が、アーキタイプによくいる駒です。これを見ると、個数制限付きナップサック問題として解いたものと比べ明らかに強化学習・遺伝的アルゴリズム共にアーキタイプらしくなっていることがわかりました。また、赤丸で囲まれていない駒も攻撃力が高く、デッキコンセプトに合っていそうです。

速攻竜アーキタイプ(※著作権の都合で掲載していない駒があります。)
コンバートアーキタイプ
コンバートアーキタイプについての結果が以下になります。結果から分かる通り、コンバートアーキタイプによくいる駒を中心に抽出することができています。一方で比較手法は確かにコンバートらしさはあるのですが、コンバート駒が遺伝的アルゴリズムに比べるとやや少ないです。また比較手法と強化学習での結果の、コンバート駒の個数が同じですが、強化学習は時間の都合上数epochしか回せていないので、epoch数を上げたら性能は上がる余地があると思います。

コンバートアーキタイプ(※著作権の都合で掲載していない駒があります。)
初心者向けのレコメンド(速攻竜)
結果を見ると、強化学習、遺伝的アルゴリズムともに速攻竜アーキタイプに合う駒が拾えているのではないかと思います。一方で個数制限付きナップサック問題として解いたものは確かにアーキタイプらしい駒の個数は多いのですが、魔属性のものが混入しており、全て竜属性の時に発動できる「ディーチェ」の攻撃力が無駄になってしまいます。この意味で、集合に対して最適化した強化学習や遺伝的アルゴリズムの利点が発揮できました。

初心者向けの速攻竜アーキタイプ(※著作権の都合で掲載していない駒があります。)
結論・今後の展望
結論として、集団に対してアーキタイプ確率最大化を図ることで、アーキタイプらしいデッキレコメンドに成功しました。また、初心者向けのデッキ構築も可能にしました。
今後の展望として、実用化に向けて求められるもの、という観点で考えてみます。レコメンド速度、アーキタイプらしさの向上の二つの要素があると思います。レコメンド速度に関しては、遺伝的アルゴリズムは2分半程度かかってしまいます。これはスマホアプリへの実導入を考えると遅いです。対して、強化学習に関しては推論時間は一瞬です。この点において、強化学習の方が優れていると考えます。一方でアーキタイプらしさの向上に関しては、遺伝的アルゴリズムの方がやや優れているものの、いずれの手法でもある程度のアーキタイプらしさは担保できたのではないかと思っています。
よって、今後の展望をまとめると、遺伝的アルゴリズムで実用化に耐えうるほどの高速化および、強化学習での精度向上だと考えます。特に強化学習に関しては、今回数epochしか回してないので性能向上は期待できる箇所だと思います。また、今回はコストを超えた時の罰則を、アーキタイプ確率の報酬と同じ段階で与えているのですが、最初にコスト制限に対して、次にアーキタイプ確率に対して、と階層型強化学習を導入することでより性能が向上する可能性があると考えています。というのも、コスト制約を満たすのに学習が苦労していた印象だったので、対策として最初にコスト最適化を組み込むことを検討する価値があると考えています。
最後に
今回のインターンシップは自身にとって非常に実りの多いものでした。様々な論文等読む中、またメンターの方との議論の中で解くべき問題に対して解像度が上がっていくのは大変新鮮でした。メンターの方をはじめとする、ご意見やアドバイスを頂いたDeNAの全ての方々に感謝して結びの言葉とさせていただきます。
参考文献
[1]David M. Blei and John D. Lafferty, 2005, “Correlated topic models,” In Proceedings of the 18th International Conference on Neural Information Processing Systems (NIPS'05). MIT Press, Cambridge, MA, USA, 147–154.
[2] Irwan Bello, et al. 2017, “Neural Combinatorial Optimization with Reinforcement Learning,” ( https://arxiv.org/pdf/1611.09940.pdf )
[3] García-Sánchez, Pablo, Alberto Paolo Tonda, Giovanni Squillero, Antonio Mora García and Juan Julián Merelo Guervós, 2016, “Evolutionary deckbuilding in hearthstone.” 2016 IEEE Conference on Computational Intelligence and Games (CIG) (2016): 1-8.
[4] Zhengxing Chen, et al. 2018, “Q-DeckRec: A Fast Deck Recommendation System for Collectible Card Games,” ( https://arxiv.org/pdf/1806.09771.pdf )
オセロ・Othelloは登録商標です。TM&© Othello,Co. and MegaHouse
© 2016 DeNA Co.,Ltd.



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。