





@mazgi
です。
私が所属する DeNA AI システム部(当時)では、3 月に「
DeNA Data Science Competition #2021 Spring
」と題して土日 2 日間に渡るデータサイエンスのコンペを開催しました。
参加いただいた方、週末に昼夜問わず挑んでいただきありがとうございました。
私は MLOps として、そのコンペのシステムを設計/運用させていただきましたのでご紹介します。
何に気をつけたか?
今回のようなイベントは何回か携わっているのですが、DeNA での就業に興味を持ってくださっている学生の方との交流イベントという側面があるため、参加いただく方の学生比率が高いことが予測されました。
そのような参加者特性も踏まえ次のような点に特に注意してシステムを設計しています。
ユーザビリティ
過去の経験からクラウドや Linux に慣れていない方も参加されると予測できました。
そのため、後述の他の要件を満たした上で出来る限り良いユーザー体験を作り、セットアップや環境のトラブルに時間を取られるのではなく、コンペ自体に最大限時間を使っていただけるよう準備をしました。
公平さ、高性能なワークステーション持ってなくても個人の実力を発揮できる
データサイエンスのコンペではある程度計算機の性能が必要です。
しかし性能が高い PC は当然ながら価格も高くなります。
参加者、特に学生の方がみんな高性能 PC を持っているわけではなく、本イベントではそのような環境的あるいは経済的要因に縛られず実力を発揮していただきたいと考えています。
またオンライン開催なので参加された方が何か困っていた時に実際に PC の画面をみてサポートできないという事情もあります。
そこで DeNA 側でクラウド上の計算環境を用意することで、仮に手元の PC 性能が足りなくてもコンペに参加していただけるようにしました。
クラウド環境に統一することで性能も揃いますし、仮想マシン等の再構築も容易になりオンラインでもサポートが可能になります。
また後述しますがデータの取り扱いに関してセキュリティ面のメリットもあります。
オンラインコンペでのデータの取り扱い
データサイエンスのコンペは同じような課題でも扱うデータの"生々しさ"によって競える幅が変わることがあり、また単純に実データに近いデータを扱った方が面白くなります。
しかし一方で元のデータに関係する個人情報等がしっかりと守られなければならないのは当然のことです。
これはコンペに限らずデータサイエンスやデータ分析を行う上で必須の措置で、DeNA でも厳格な基準が適用されています。
例えば「スーパーマーケットでの買い物傾向を予測する」といったお題であれば、購入者本人を特定できる情報、例えば氏名や会員 ID 等はしっかりと取り除かれなければなりません。
その上で「男性, 30 代, 購入 1,…」といった匿名化したデータを分析し予測します。
このとき、購入された品目の粒度が「食品、飲料、酒、雑貨」くらいしかない場合と、「黒毛和牛タン(焼肉用)、カクちゃんメガ盛り博多とんこつ、スピリタス 500ml 瓶、アリ印マジッククロス、…」などなど具体的な場合、圧倒的に後者の方が想像や試行錯誤の幅が広がります。
”難易度高い課題”歓迎!ビジネスを成功に導く機械学習実践のプロ、Kaggler の実態
普通のデータサイエンティストと世界トップクラスのデータサイエンティストの違い
本イベントでも、必須である匿名化はきちんと行った上で出来る限りリアリティのあるデータにコンペで挑んでいただきたいと考えました。
一方で、元のデータが発生する各サービスの責任者としては、当然ながらデータが流出しないか等の「データを守る」観点で提供可否を判断します。
そこで今回は DeNA が管理するクラウド上でデータの取り扱いを完結させ、クラウドから外に持ち出さないようにすることで調整を行いました。
コスト
クラウドを活用する場合、次に考えるのは金銭的コストです。
本イベントは社内の扱いとしては採用活動に近く、そのため売り上げは立ちません。
したがって「売り上げの x%以内」といった商用サービスのような予算の組み方はできません。
省コストであればあるほど開催規模や頻度に寄与するため、参加してくださる方の利便性を損なわず、かつ VM インスタンス等の起動時間を最小に抑えるよう構成と運用の両面から工夫しました。
どういうシステムを構成したか?
本イベントは内製のコンペシステムを軸として開催されました。
Kaggle と同じように課題とデータを取得し、結果を submit することでスコアが確定します。
また新卒採用への応募を検討してくださる方は、別途実装したコードを提出することで評価材料ともなります。
構成は次の図のようになっています。
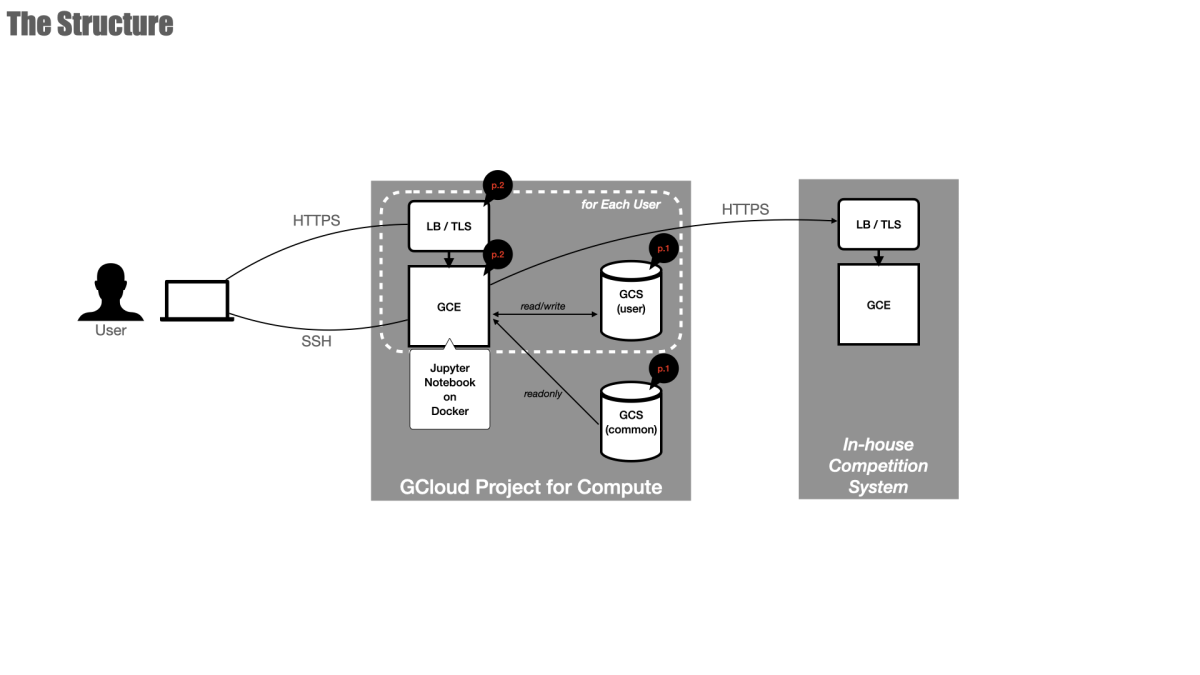
コンペシステムと計算機環境がそれぞれ独立した Google Cloud Project 上に構築されています。
本記事では主に計算機環境の構成についてご紹介します。
利便性と管理容易性とセキュリティの両立
本イベントでは計算から submit まで Jupyter Notebook で行う想定でシステムを設計しています。
これは、体感上 Linux に慣れていない方の参加が多いため、扱うコマンドを最小限に抑えパッケージインストール等で時間を消費しないための工夫です。
また Jupyter Notebook であれば説明を書いたサンプル Notebook を配り、何度か Ctrl+Enter を打っていただくだけで一通りの流れを体験できます。
Jupyter Notebook を含めた必要な環境は 1 つの Docker イメージにまとめています。
Docker で隠蔽することで個々のパッケージのインストール等の環境構築作業を不要にできます。
また docker run … を含めた数行のコマンドで Notebook を起動でき、手順を減らせることも大きな利点です。
Docker イメージには内製コンペシステムのクライアント CLI もインストールされており、前述の通り Jupyter Notebook 上で submit まで行えます。
Docker を起動する VM インスタンスは各参加者専用に同スペックで個別に用意しており、それぞれ SSH でログインしていただきます。
これは、Linux に慣れていない方が参加される一方で、ご自身でパッケージをインストールしたり慣れたツールを使いたいケースを考慮しているためです。
DeNA のデータサイエンティストは Linux や Docker を活用して業務を行っていますので、応用としてこれらを使いこなしてコンペに挑んでいただける方は大歓迎です。
またサンプル Notebook や課題データは図で common と書かれた読み取り専用の GCS バケットに格納されています。
common とは別に各参加者専用の user GCS バケットも用意しており、こちらは自由に読み書きできます。
用途としてはコンペ終了後に任意で Notebook 等を提出していただく他、大きなデータの退避等を想定しています。
各 GCS バケットへのアクセス制御はサービスアカウントによって行っているため参加してくださった方は Google Cloud 上の認証認可を意識する必要はありません。
コストパフォーマンス最大化
前述した通り、本イベントでは決まった予算を公平に出来る限り参加いただいた方の計算リソースとして使いたいと考えています。
そのため運営側の環境構築を 2 つのフェイズに分けています。
図の p.1, p.2 がそれです。
各フェイズで構築している代表的なリソースは以下の通りです。
Phase 1: 永続リソース = DNS, GCS バケット等
Phase 2: 計算リソース = VM インスタンス
Phase 2 の計算リソースはイベント直前に作成し、イベント終了後速やかに破棄することでコストパフォーマンスの最大化を狙っています。
このように工夫することで参加してくださった方に予算内で大きな計算リソースを提供できますし、今後の開催も企画しやすくなります。
社内セキュリティとの兼ね合い
前述した通り、計算用の VM インスタンスには SSH ログイン出来るよう設計しています。
また Jupyter Notebook への Web アクセスは Google Managed な TLS 証明書による HTTPS に限定しています。
これによって、計算機への接続を SSH と HTTPS といった暗号化された経路のみに限定しています。
しかし本イベントはオンライン開催なため、HTTPS はもちろん SSH の接続元も各参加者の自宅等となり、接続元を限定できません。
また今回の要件から OS Login は使いませんでした。
一方、DeNA として不特定の接続元から SSH 接続されるケースは現時点ではあまり想定されていないようで、SSH の接続元は IP アドレスを限定するよう規定されています。
実際のところ DeNA のクラウドセキュリティは日々改善されており、VM インスタンスの SSH ポートを接続元 IP アドレス制限なく解放するとアラートメールを受け取ることになります。
そのため今回アラートメールを受けること自体は諦め、セキュリティ部門に事前連絡することで対応としました。
その他社内のセキュリティ基準と監査に則って次のような設定を行いました。
IAM 権限の recommendations
IAM ユーザーに付与された権限のうち、使われていない権限を一覧し削除できる機能です。
手動で適用しています。
GCS バケットの Uniform bucket-level access
特定の GCS バケットへのアクセス権限を IAM のみで制御する設定です。
これを有効にしています。
無効にした場合は、例えば gs://your-bucket/foo1 と gs://your-bucket/foo2 に違うアクセス権を設定できますが今回の要件では不要です。
最後に
開催したデータサイエンスのコンペについてシステム面をご紹介しました。
コンペでは参加いただいた学生の方にご質問いただいたり社内の雰囲気などをお話ししたり、私自身も楽しく運営させていただきました。
システム面では「クラウド環境が全員同じ性能でフェアだった」「トラブルなく参加できた」等ご好評もいただけた一方で「自分の PC を使いたい」等のご要望もいただいているので、より多くの方が実力を発揮していただけるよう引き続き改善していきたいと考えています。
参加いただいた皆さま、本当にありがとうございました。



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。