





はじめまして。9月初旬より約半月にわたり、AIエンジニアコースのインターンに参加させていただいた清水と申します。大学院は情報系の専攻で、最近は幾何学的な深層学習に関する研究に取り組んでいます。その過程で言語的なタスクを出口に用いることも多く、副次的に深層学習を利用した自然言語処理にも多少明るかったりします。
題目にあるTransformerとは、そうした分野にてここ数年にわかに注目を集めている仕組みの名です。自然言語処理の最先端研究ではまず流用されないことなどない、いわば伝家の宝刀レベルのモデルといってよいでしょう。
本記事ではこれを『逆転オセロニア』というゲームのデッキ編成に特化させ、現行手法よりも表現力に富んだ編成システムを実現した経緯についてお話しできればと思います。『日進月歩で強力になっていく機械学習手法の恩恵に与りたいけれど、所望の問題設定にドンピシャな手法なんてそうそうなくて思うようにいかないな』という方へ。タスクの類似点と相違点を丁寧に洗い出せば、最強のモデルは畑違いのフィールドでもちゃんと無双できるという一例をご紹介します。
強いモデルを使ってみんなで幸せになりましょう。
概要
記事構成
課題に関する事前知識等について簡単に触れたのち、本記事は以下の三本柱によって構成されます。
- 集合生成タスクであるデッキ編成と文章生成の類似性を見抜く
- デッキ編成に係る各種制約を搭載すべく、Transformerの訓練・推論の仕組みを改造する
- デッキ生成実験による提案手法の有効性確認と考察
本題の前にちょっとした誘導
同時期にインターンに参加されていたお二人の記事が先行して公開されています。
- 長沢さん──本記事と同じくデッキ編成の性能向上に取り組まれています。組み合わせ最適化の発見的再考。
- 横山さん──逆転オセロニアにおけるキャラクター駒の強さを測る指標について熟考されています。
いずれも逆転オセロニアに関係する課題に取り組まれていますので、併せてご覧になると各々の個性が見えてより面白さが増すのではないかと思います。ご興味のある方はそれぞれのリンクよりどうぞ。本編は次章から始まります。
逆転オセロニア
対戦するプレイヤーが白黒に分かれて盤面の駒をひっくり返し合うオセロの基本構図はそのままに、駒ごとに設定された固有のスキルやステータスによって多彩な展開を可能にした新感覚の対戦ゲーム、それが『逆転オセロニア』です。種類豊富なキャラクター駒を駆使することで広がる戦略性や後半での一発逆転要素が大きな魅力のひとつです。

逆転オセロニア
盤面は6×6の36マス、初めに計4枚以上の無地駒が置かれた状態でゲームはスタートします。プレイヤーは互いに16枚のキャラクター駒から成るデッキを駆使して盤面を支配し合いますが、駒それぞれに攻撃性能が付与されており、基本的には先に相手のHPを削り切った方が勝利を掴むというルールを採用しています。
駒のスキルは多様で、単発で発動するスキルだけでなく、相手駒をひっくり返す際の端点となることで発動するコンボスキルも設定されていることがあります。またデッキにはリーダー駒の設定が必要となり、リーダー時にのみ有効なスキルを持つ駒も存在します。デッキはこうしたスキル同士の相性やシナジーを考慮し、戦い方の方針を練りながら編成されます。特に駒ごとに設定されている属性は重要な指針で、それぞれ以下のように特有のスキル傾向や能力を有しています。
- 神:駒同士の連携や回復に長け、終盤での一発逆転を発生させやすいスキルが豊富。HPは総じて高め。
- 魔:罠や毒、呪いなど、相手を妨害しつつ立ち回ることに長けており、HPと攻撃力のバランスが取れている。
- 竜:短期決戦を得意とする極めて攻撃特化な属性。低HPを代償に、素の攻撃力やその強化に優れている。
さらにデッキは、ある属性が10枚以上含まれていると『神デッキ』などその属性名で呼ばれます。他に、各属性が4枚以上含まれる『混合デッキ』、16枚全てが同じ属性で構成された単色デッキなどが区分として存在します。駒スキルの中にはこうしたデッキタイプを条件とするものもあり、編成の際の制約としてゲームプレイの奥深さに一役買っています。
オススメ編成
このようにデッキ編成はゲームの楽しさの一要因ではありますが、同時にプレイヤーを悩ませる要素という側面も持ち合わせているといえます。特に既に数千体規模でキャラクター駒が存在する現状においては、手持ちの中から俗にいう『強い』デッキを作るのは容易なことではありません。
そこで逆転オセロニアには、プレイヤーが所持している駒の中から自動でデッキを編成してくれる『オススメ編成』という支援機能が搭載されています。オススメ編成ではデッキタイプ、使用したい手持ち駒、デッキコストを指定することで、残りの枠が自動で提案されます。(デッキコストとは、駒ごとに設定されたコストの合計です。ゲーム内コンテンツにより異なるコスト上限が設けられており、プレイヤーはそれぞれに合わせてデッキを複数準備します。)
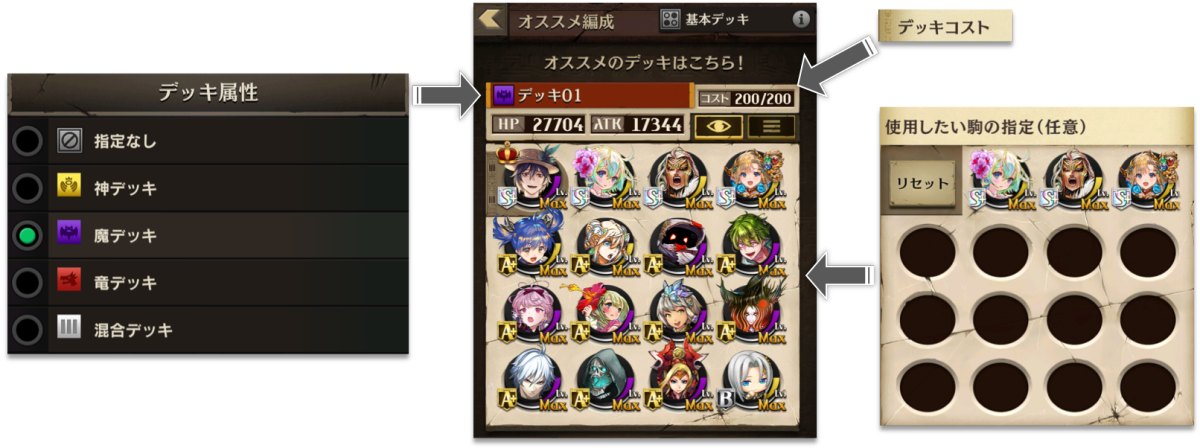
オススメ編成のイメージ(実環境における挙動とは異なる可能性があります)。
現行手法では、実際のユーザーによる使用デッキ履歴に基づいて駒ペアごとの共起指標を算出し、編成設定を満たす駒の中でよく使われる頻度の高いもの同士が集まるようにしてデッキが編成されます。これにより、熟練したユーザーのデッキに近いような構成で自動編成することが可能となります。一方で、共起度の高い順に素直にデッキに逐次投入するピックアップ方法や、アルゴリズムの大部分をヒューリスティックが占めているという状況には改善の余地がありました。
デッキ編成と文章生成の類似点
こうした課題を解決するために、表現力の高い近年の機械学習手法を利用することはできないでしょうか。そのためにはまず、問題設定の近しいタスクを探し出すことが肝要であると考えられます。タスクドリブンに考えることで、自ずと必要機能やそれに適した既存手法が浮き彫りになることが期待できるためです。
細かい制約をいったん取り払って、手持ちの駒を出発点にデッキの残りを埋めたいという簡潔な設定で考えてみることにしましょう。例えば下図のような状況です。

デッキの残りを決めるには?
このときに浮かぶ自然な発想は、デッキに含めたい駒(0~15枚)をもとに、次にデッキに含めるのにもっとも相応しいと思われる駒をひとつ選んでくる、という操作です。これを必要回数繰り返すことで、16枚から成るデッキは完成します。
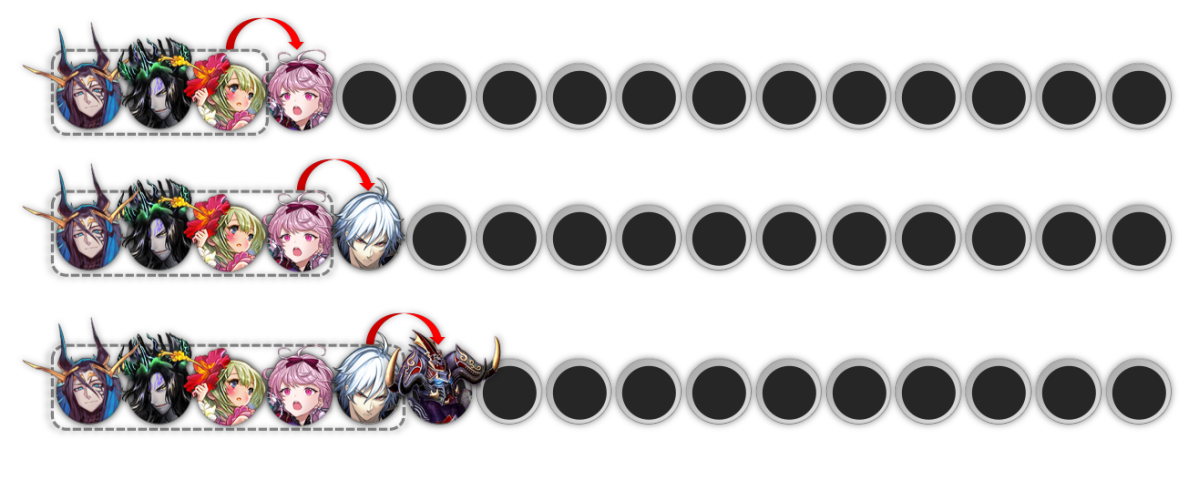
既知の駒からひとつずつデッキを埋めていく。
すると、この操作はある意味で系列生成的であることに気が付きます。すなわち、デッキ自体は駒に順列のない集合であるものの、デッキ編成は擬似的に系列生成タスクと見做せるということです。
これに類似するタスクとはなんでしょうか。そう、文章生成です。

文章の続きを決めるには?
文章生成タスクでは、文章の始まりの語に基づき、それに続くものとして尤もらしい単語列を生成していきます。そのアプローチとして最も広く採用されているのが自己回帰による逐次生成という考え方であり、これは既に判明している単語列をもとに、次に置くべき単語をひとつずつ求めるというものになります。

既知の単語から続く文章を埋めていく。『吾輩は猫である。名前はまだ無い。』
上で見たデッキ生成と、本質が非常に似通っていることがお分かりになるでしょうか。
逆に、デッキ生成を文章生成と見做す観点に立脚するなら、逆転オセロニアの各駒がそれぞれユニークな単語であると考えれば完璧でしょう。そしてデッキは文章そのものです。
我々はこれから、駒という言葉を用いて、デッキという物語を紡ぐのです。
文章生成におけるTransformerモデル
文章生成における最先端の機械学習手法として、本記事では冒頭に述べたようにTransformerモデルを採用することにします。元々Transformerは機械翻訳のために導入されたモデルでしたが、その強力さゆえに近年では文章生成タスクでの利用も一般的になっています。人間と見紛う精巧な文章生成が可能であることを危険視され公開実装が見送られたかのGPT-2は、まさにTransformer機構を文章生成に転用した好例です。
その仕組みや数式の詳細はインターネット上の数多の有用記事に譲るとして、本章ではイメージを掴むことを目的に概要を簡単に説明します。もう知ってるよという方は次章へ飛んでいただいて問題ありません。
他の多くの深層学習手法と同様に、Transformerは単語のような個別要素(単語や文字、単語をいくつかのパーツに区切って得られる短い文字列等がよく用いられ、総じて『トークン』と呼ばれます)を固定次元のベクトルとして扱います。これらは埋め込みベクトルや分散表現と呼ばれ、モデルの学習に従ってそれぞれ座標を移動していきます。モデルアーキテクチャやタスクごとに得られる分散表現は異なるので一概には言えませんが、学習が進むと類似した意味のトークンや同時に用いられやすいトークン同士が近い座標に配置されるなど、直感的な挙動を見せることも多いです。
Transformerでは訓練データから抽出したトークン集合に『BOS(Begin Of Sentence:文章の開始)』と『EOS(End Of Sentence:文章の終端)』といったいくつかの特殊トークンを加えて参照辞書とします。与えられた文章(や文章の集まり)は全てこのふたつのトークンで挟まれることで、モデルにその両端を認識させます。
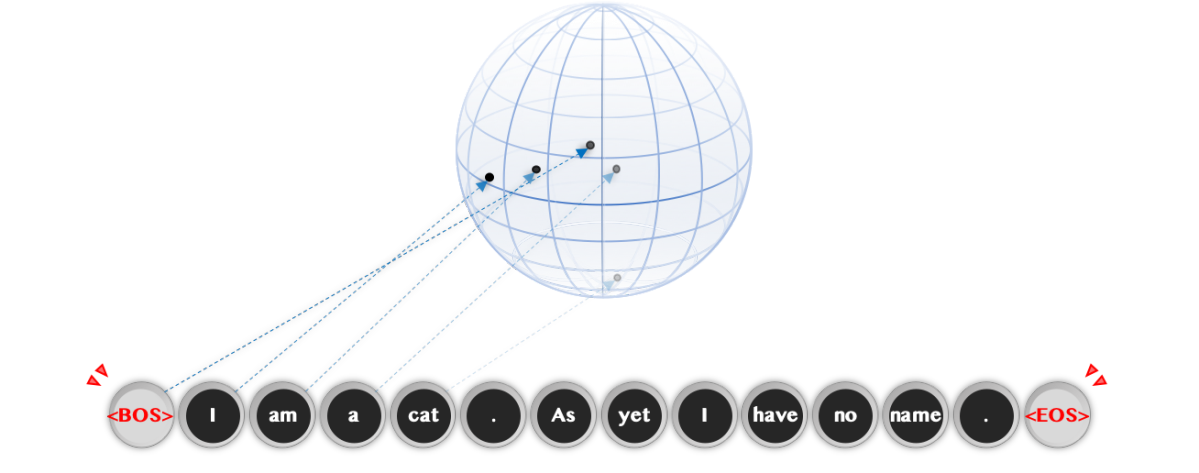
文章がどこから始まりどこで終わるのかを明確にする。各トークンは(高次元)潜在空間に学習可能な座標を持つ。
Transformerは既知のトークン同士の相関関係を幾重にも抽出しながら次に出力すべきトークンを予測します。イメージとしては、入力された各トークンが自分自身の次に来るべきトークンの埋め込みに次第に変化していくことによってこれを実現します。途中までわかっているある文章を例として挙げると下図のようになります。
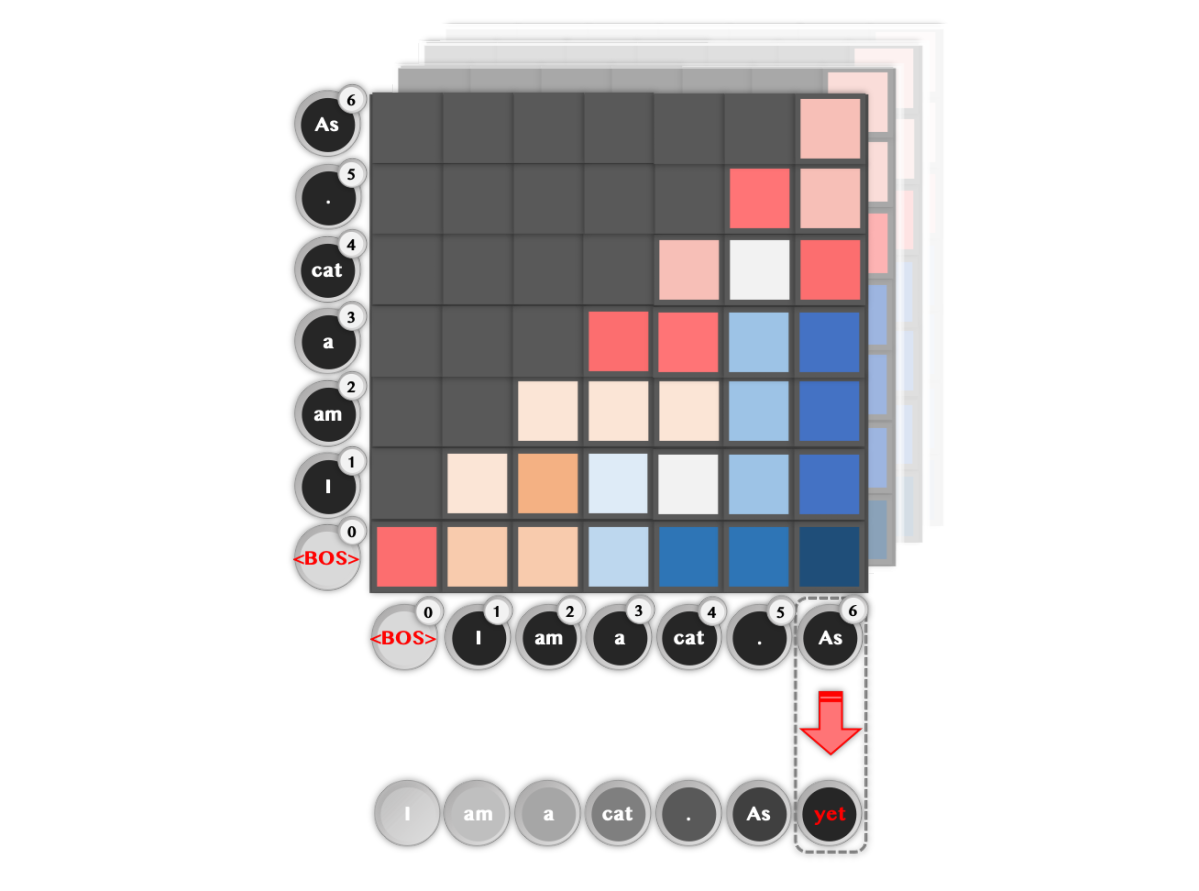
トークン同士の相関関係からひとつ次のトークンを予測する。専門的にはself-attentionと呼ばれる仕組み。
このとき各トークンの肩に付与されている数値は文章内での位置で、Transformerでは位置に関する埋め込みベクトルをトークン埋め込みに加算することで語順を意識した処理が可能となっています。
最終層では、出力されたトークンが何に変化しているのかを定量的に図るため、出力トークンと辞書内の全てのトークンとの間の埋め込みベクトルの類似度に基づいて確率を計算します。モデルの訓練時には正しい出力トークンの確率値が高まるように学習します。このようにして学習されたモデルを推論に用いる際は、基本的に最も高い確率値として評価されたトークンを逐次的に出力することで所望の系列生成を行うことが可能となります。
Deck Transformer
さて、ここまででデッキ編成をTransformerで解くための下準備が完了しました。以降では、具体的に所望のタスクにTransformerを特化させるべくチューニングしていきましょう。便宜上これをDeck Transformerと呼ぶことにします。
駒の表現
前章までに述べたように、Deck Transformerでは逆転オセロニアにおける各キャラクター駒を個別の単語のように扱います。素直な発想としては、各駒にそれぞれ固有の埋め込みベクトルを割り当てることでこれが実現できそうです。
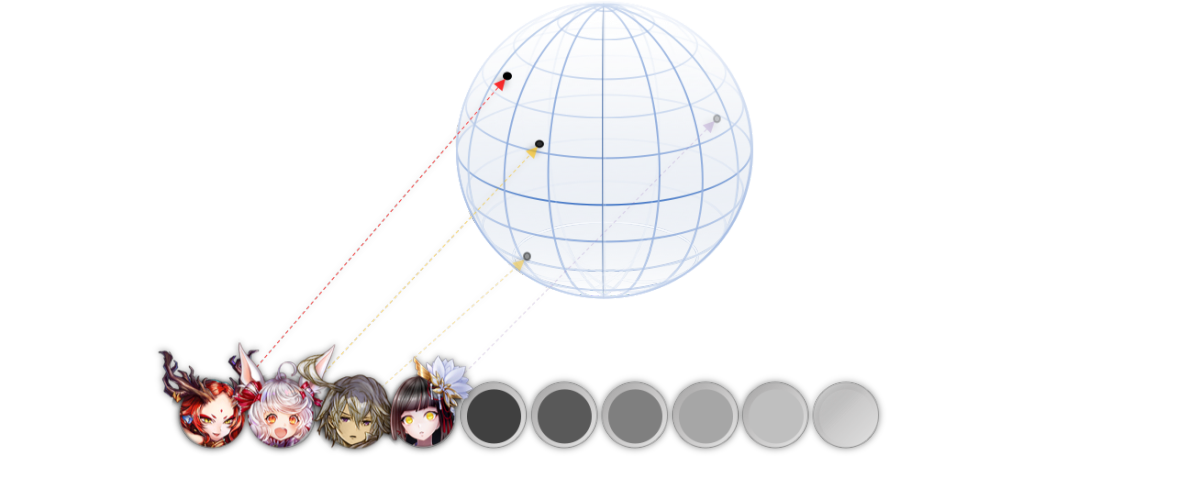
各駒に学習可能な潜在空間内の座標を割り当てる。図は3次元だが実際は数百次元に及ぶので図示できない。
これだけでも十分に思えますが、さらにあらかじめ取得できる駒の属性情報も埋め込みベクトル化してしまいましょう。後々デッキタイプで条件付けする際に助けになることが期待できるためです。
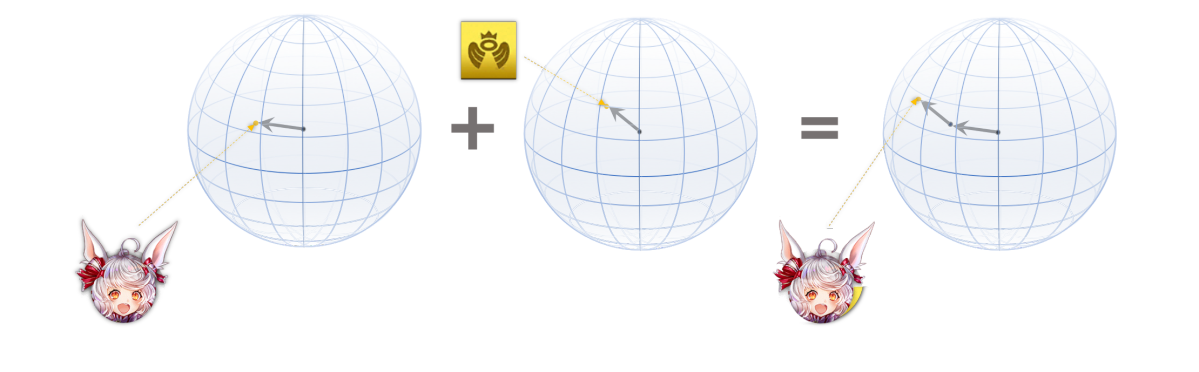
駒ごとの埋め込みと属性埋め込みの和がその駒の表現となる。
Transformerでは単語埋め込みと位置埋め込みを単に加算しましたが、このように異なる表現特性を持つ埋め込みを足し込むという操作は深層学習において広く用いられています。ここでもそれに倣い、駒表現と属性表現を加算しましょう。以上がモデルへの入力となります。
位置に関する変更
文章生成とデッキ編成の主要な相違点のひとつに、位置に関する情報の取り扱いが挙げられます。文章では語順が極めて重要ですが、デッキは逆に、その内容がリーダー駒を除いて駒の並び替えに関して不変でなければなりません。また文章はどれだけの長さの文章を生成するか、換言すればいつ単語の生成を終了するかをモデル自身が決定しなければなりませんが、デッキ生成では駒の総数が定まっているため、この機能は不要になります。
位置表現の廃止
各駒はデッキ内での特定位置を持たないので、Transformerに備わっている位置符号化は撤廃します。文章生成では位置表現がないと『同じ単語から成るが語順が異なる文章』の区別が原理的に付かなくなるという大問題が発生しますが(今夏にTransformerは位置符号化なしでもチューリング完全であるとする論文も出ましたがそれはそれとして)、集合であるデッキ生成でこれはむしろ好都合だといえるでしょう。さらに、デッキ内の駒を予測する順序が偏るとモデルが変な癖を学習してしまう可能性があるため、訓練時に与えるデッキデータも都度並び順をシャッフルすることとします。
ただし、デッキの中でリーダーの役割を持つ駒には留意する必要があると考えられます。リーダー駒はデッキタイプと並んで戦略指針を決定づける比重が大きいためです。これらについては、生成順序が先頭になるよう調整します。
生成停止トークンの廃止
逐次的な文章生成では、モデル自身が『いつ生成を停止するべきか』を判断できるように『EOS(文章の終端)』という特殊トークンを用意します。一方、逆転オセロニアの(そして一般的な)デッキ生成では、生成すべき対象の最大数は固定値として定められているため、既定の系列長に達した時点で生成を打ち切れば十分であることがわかります。したがってDeck TransformerではEOSトークンも廃止します。
逆転オセロニアに関する各種制約の導入
ここまでの基本的な機構の改変により、Deck Transformerは理論上、デッキに含めたい任意個数の駒の情報を受け取り、残りを予測できるモデルになりました。既に数多くの研究により実証されているTransformerモデルの表現力を信頼するならば、この時点で完成としてもよさそうです。しかしながら、本当にそれで十分といえるでしょうか。
実際のユーザーが構築したデッキに基づいて学習したTransformerならばあるいは、我々が特別にルールを教え込まなくとも、逆転オセロニアの各制約を暗黙のうちに学習してしまうかもしれません。ただし、実運用の際はそれらが満足されていることを保証する必要が生じます。すなわち、オススメ編成時に指定されたデッキタイプが確かに実現されているか、デッキコストを超過していないか、等々を判定するのです。そうでなくてはゲーム内で実運用できないからです。
このように考えると、なぜあらかじめわかっているルールを敢えてモデルに対して秘匿し、推論時だけ厳しく取り締まるのかという点が疑問に思えてきます。ならば学習時にも教えてしまえばよいのです。Deck Transformerには制約の学習など迂遠なことは要求せず、それはこちらでサポートしてあげましょう。そうすればモデルはより、個別の駒の表現学習にその学習容量を割くことができるでしょう。
デッキタイプの反映
デッキタイプ指定を反映した生成をすると一口にいっても、そこで考慮しなければならない点はひとつではありません。機械学習的な意味では、どのようにしてデッキタイプという情報をモデルの機構に取り込むかという点を考察する必要が生じます。もう一点は、指定されたデッキタイプによる属性枚数条件をいかにして遵守するかという課題特有の制約です。
デッキタイプ指定を情報として取り込むには、条件付けという基礎に立ち返ればよいでしょう。条件付けとは、モデルの主要な入力の他に補助入力を受け取る流路を設け、なんらかのフォーマットのもとで任意の条件に関する情報を与えるという方法です。条件の表し方も与え方も自由なので漠然とした書き方になってしまいましたが、難しいものではありません。同じ入力を与えても結果が異なるようなスイッチを必要なだけ接続するイメージです。
幸いTransformerには『BOS(文章の開始)』という条件付けトークンが備わっています。これを必要なデッキタイプの数だけ増やしましょう。これがそのままデッキ生成開始に入力される条件付けの役割を果たすはずです。
この条件付けにより、デッキに編成したい所持駒指定が同じでも、作りたいデッキタイプによってはその後の生成結果が大きく変わりうるという事実をモデルが考慮できるようになります。さらに、ここまでは編成に加えたい所持駒が最初にいくつか指定される例で主に説明をしてきましたが、デッキタイプとコストのみを指定しゼロからデッキを構築したいという需要も当然存在します。そのような際、条件付けの有無が結果に重要な影響を及ぼすことは想像に難くありません。
デッキタイプによる条件付けは生成結果を変える。 デッキタイプのみから編成したい場合もある。

次いで、デッキタイプによるゲーム的な制約を実現する方法について考えます。例えば神デッキなら神駒が10枚以上、混合デッキなら各属性駒がそれぞれ4枚以上デッキに含まれていなければならない、という規約を守らなくてはなりません。
この解決法は単純で、デッキタイプごとに含めなければならない属性数のカウンタを設け、既知の駒が増えるたびにそのカウンタを減らしていきます。カウンタがゼロになれば、その属性条件はクリアされたということです。一方で、既知駒の枚数とカウンタの残数の和がちょうど16になると、デッキの残りは常にカウンタが正数の属性だけを出力しないと制約が守れないという状況を意味します。後者の状況になるまでは、モデルにフリーランニングさせればよいでしょう。
ある属性だけを出力しなければデッキタイプ制約が満たせないという状況に陥った場合は、対象属性以外の駒の出力確率に強制的に確率ゼロのマスクをかけます。次いで、確率値と見做せるよう総和を1に正規化し直します(実際の処理ではsoftmax関数への入力のうち該当マスク部分を負の無限大等で置換します)。これにより、出力しなければならない属性以外は今は考慮する必要がないということを明示的にモデル出力に反映させることができます。
指定デッキタイプを保証する仕組み。図は、残り全てが魔属性でなければならなくなった状況の例。
マスクをかける操作の最も重要な点は、ある時点での不要属性の駒についての出力確率がどんな値でもよくなるということです。マスクがなければ、モデルはそれらの確率がゼロになるようにわざわざ学習しなければなりません。しかしマスクによりゼロに置換されれば、元の値がどうであれその出力は学習に影響を及ぼさなくなります。『既知の駒集合的に次に追加すべき最善の駒がAだとしても、デッキタイプを満たすためにはAは選択できない』という状況が存在するとき、マスクがあれば『Aに関する理想的な出力確率は高い』ままに、条件を満たす駒集合についてのみ学習することが可能になります(少し専門的な表現をすれば、駒Aの出力確率を導出する演算部分が微分勾配グラフから切断されます)。
もう少し広い視野で見れば、与えられた制約の種類がなんであれ、マスクをかけることにより制約条件と駒同士の相性を考慮したデッキ生成を切り離すことができるようになるといえるでしょう。この考え方は使えそうです。
デッキコスト上限
前節でのカウンタとマスクの概念をそのまま適用してみましょう。指定デッキコストをカウンタにセットし、既知駒が増えるたびに駒コストを減算していきます。すると各予測ステップでは、『カウンタが示す残コスト』から『現在のステップを予測した後に埋めるべき駒数×駒の最低コスト』を引いた数値が、次に出力できる駒の上限コストとなります。単純にカウンタの残コストとしてしまうと、デッキを完成させる前にカウンタがゼロになりそれ以上駒を増やせないという状況が発生しうるためです。
各ステップにおいて出力可能な上限コストがわかりましたので、これを上回る駒に動的にマスクをかければ所望の処理が得られるでしょう。これにより、最終的な駒の総コストが与えられたデッキコスト以下になることが保証されます。
重複許容上限
逆転オセロニアには、同じ駒をデッキの中に含めてよい枚数が駒ごとに設定されています。基本的に同じ駒はデッキに1枚まで、低コスト駒は2枚までといった具合です。また、性能的には同一駒であるが期間限定などで別駒として扱われている場合など、一部で同時に編成できないという駒も存在します。これらの制約は、デッキではなく駒のユニークアイデンティティごとにカウンタを設けることで実現できます。マスク処理については前節までと同様です。
またこの制約からは、自己回帰モデルが孕む『同じ単語や節を無意味に繰り返してしまう可能性がある』という問題を解消する効果も得られます。とりわけ、『同じ駒ばかり連続して出力してしまわないよう、似ている駒でもある程度埋め込みベクトルを引き離して分離性能を担保しなければならない』ことによる表現力の低下を緩和できることが期待できます。
所持駒による制限
この制約はマスクのみで実現できそうです。条件付けとして所持駒の集合が与えられれば、それ以外の未所持駒については常にマスクをかけることができるためです。
実験比較と考察
前章までに構築したDeck Transformerについて、本章では実験的にその有効性を検証します。初めに、モデルのハイパーパラメータや学習・推論について概観を述べます。次いで実際に逆転オセロニアにおけるデッキ編成タスクに適用し、現行手法との比較も交えながら定性評価をします。
実験設定
本節はやや技術寄りな内容になりますが、実験の全体像が曖昧にならないようにとの目的で記録させていただきます。普段からTransformer関係のモデルを扱っている方々に規模感がお伝えできれば幸いです。詳しい情報は興味ない・よくわからないけれど結果は気になるという方は真っ直ぐ次節へどうぞ。
実装のベースには自然言語処理のオープンソースライブラリであるFairseqを用い、今回提案したDeck Transformerに合わせて全般的(前処理、データセット・データローダー周り、タスク設計、モデルアーキテクチャ、訓練・生成周り)に手を入れました。実験は全てTesla V100 1枚挿しのGCPインスタンスにて実施しています。
モデル概観
Transformer機構は以下のハイパーパラメータでセットアップしました。
| 層数 | 次元数($D$ ) | ヘッド数 | 活性化関数 | 正規化位置 | ドロップアウト |
|---|---|---|---|---|---|
| 12 | 512 | 8 | ReLU | PreNorm | 0.0 |
上記の通り、数万語彙程度の辞書を用いるTransformerBaseモデルと同規模の設定となっています。高々数千程度の駒数から成る今回の実験にはややオーバーキル気味にも思えますが、タスクの特異性がどれだけモデルの表現力を要するかが未知数だったため無難な設定を採用しています。また、埋め込み層と最終分類層の重みは共有しています。
訓練設定
訓練時の各種設定は以下の通りです。
| オプティマイザ | バッチサイズ | ウォームアップ($W$) | 最終エポック数 | ラベルスムージング |
|---|---|---|---|---|
| Adam | 1024 | 4000 | 約500 | 0.1 |
自然言語処理ではバッチサイズではなくバッチ内での総トークン数を設定しバッチサイズは動的にスケールさせることが一般的ですが、本タスクではデッキに含まれる駒は16枚で固定であることから、どちらを設定しても同様となります。最終エポック数は、学習が十分収束した時点でのものを記載しています。所要時間は1~2日程度でした。(他方で、3時間程度の学習でも一定程度の性能が得られることもわかりました。仮に実運用を想定するならば、訓練にかけられる時間資源とモデル精度間のトレードオフを柔軟に考慮できそうです。)
学習率は、訓練の更新回数を$t$とするとき次式に従います。これは原典のAttention Is All You Needにて提案されたスケジュールを踏襲したもので、ウォームアップステップ$W$までは線形増加、以降は逆平方根に従い減衰する挙動を示します。
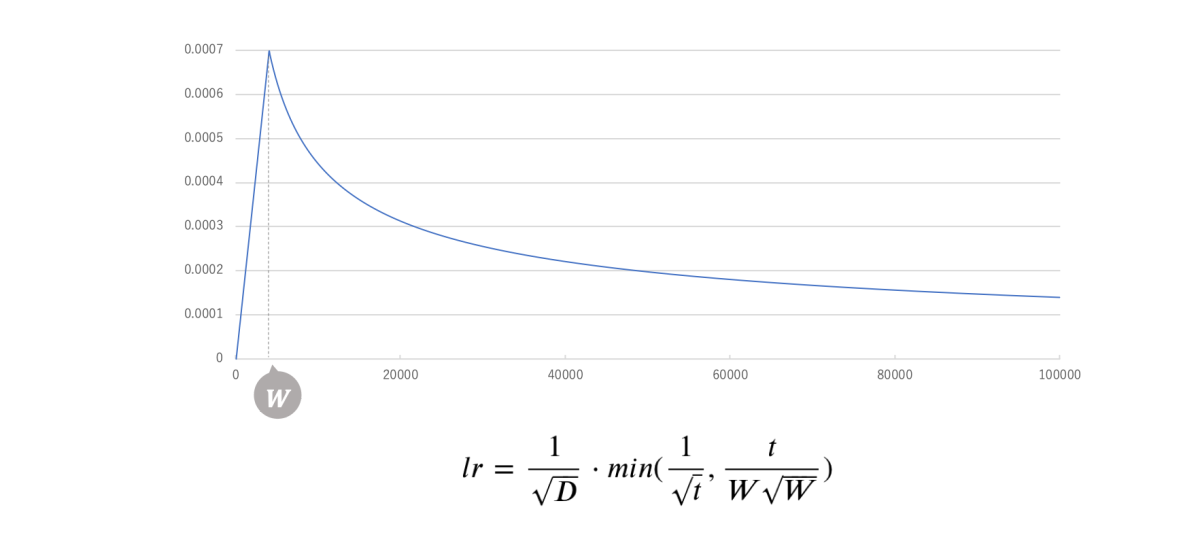
学習率の推移。挙動の切り替わりがわかりやすいよう $t$=100K までの様子を図示している。
バッチサイズと学習率は比例関係が望ましいという知見についても検討しましたが、学習率が小さくなりすぎることを懸念し今回は特に係数を設けませんでした。
訓練データには、逆転オセロニアにおける最高熟練プレイヤーが集うダイヤモンド帯の対戦データを用いました。期間にして2週間程度のものですが、それだけで1M単位のログが蓄積されていたことからもコンテンツの盛況ぶりが伺えます。
推論設定
推論時はビーム幅5のビームサーチを用いてデッキ生成を行います。ビームサーチアルゴリズムに合わせ、前章までの制約マスクもバッチ順序組み換えに対応させました。
定性評価においては、あるランク300プレイヤーの所持駒例を制約条件として用いました。次節以降では、現行手法のデモコードでカバーしている範囲の駒を中心に、いくつかのデッキタイプを指定して生成結果を比較します。(逆転オセロニアはアップデートにより新規駒が高頻度で追加されるため、少し前のデータでも未知駒が複数発生してしまうという事情があります。)そのような駒を含む比較的新しいタイプのデッキ構成についてはDeck Transformerの結果のみ確認します。
デッキ生成結果
本節では訓練済みDeck Transformerを用いた推論結果について考察していきます。前章でデッキタイプに応じた条件付けに触れたように、本節での実験は個別のモデルを訓練しているわけではなく、全て単一のモデルによって行われていることを念頭に置いていただけると幸いです。これからその汎用性をご覧に入れましょう。
闘化ルシファーデッキ
最初に比較するのは『[世界を問う者]ルシファー(闘化ルシファー)』をリーダーとしたデッキ編成です。逆転オセロニアにはデッキの駒が全て魔属性の際に発動する『ミアズマ』という吸収・デバフスキルが存在しますが、闘化ルシファーは盤面で表の間このスキルが常時発動するため、リーダー駒として採用されることの多い駒です。編成ではこれをいかにうまく運用できるかが肝となります。生成デッキの方向性が似通るよう、闘化ルシファーデッキに用いられることの多い吸収持ちの『[永久の愛]籠女』を補助条件として加えました。
結果は下図のようになりました。両手法で相違なる駒が比較しやすいよう、駒を並び替えて表示しています。
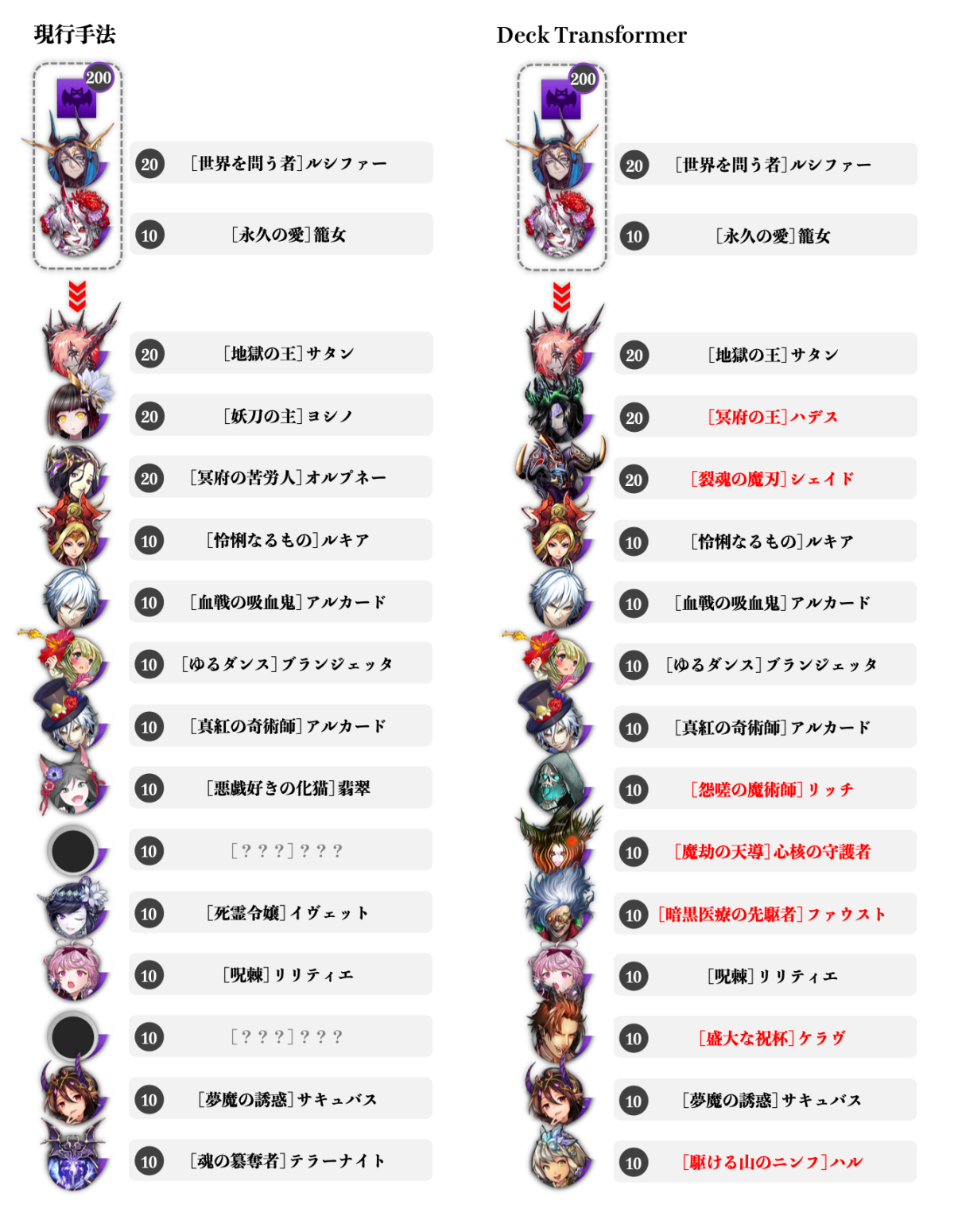
闘化ルシファーを起点とした魔デッキの生成比較。(著作権の関係上、一部未掲載の駒が含まれています。)
まず初めに確認できるのが、魔デッキ指定(魔属性10枚以上で制約は満たされる)と闘化ルシファーが条件となることにより、両手法とも魔単デッキを構築していることです。先に述べたように闘化ルシファーは魔単デッキでこそ効果を発揮するので、この点は第一関門と言えるでしょう。
次に、使い勝手の良い高威力スキルと吸収コンボスキルが強い『[血戦の吸血鬼]アルカード(闘化アルカード)』やデバフを持つ『[夢魔の誘惑]サキュバス』、相手の手駒ロックスキルを持つ『[怜悧なるもの]ルキア』『[真紅の奇術師]アルカード(ハロウィンアルカード)』、さらに相手の盤面の駒数に応じて特大ダメージを与えられることから終盤の決定打として闘化ルシファーデッキによく用いられる『[地獄の王]サタン』等が共通していることも読み取れます。
一方で、両者には複数の差異が見られます。中コスト駒に着目すると、Deck Transformerの結果には、攻撃性能や罠回収性能に優れる『[駆ける山のニンフ]ハル』、中コスト駒では最強クラスの吸収スキルを持つ『[魔劫の天導]心核の守護者(魔の守護者)』、同様に他の類似中コスト駒の上位互換となる特殊ダメージを放つ『[暗黒医療の先駆者]ファウスト』、強力な毒スキルとコンボスキルによる特殊ダメージを持ち高HPな『[怨嗟の魔術師]リッチ』等、魔デッキには是非編成したい使い勝手の良い魔駒が編成されています。さらに、闘化ルシファーのそれと比べるとやや小規模なものの同様にミアズマを持つ『[盛大な祝杯]ケラヴ』が含まれている点も特徴的です。
高コスト駒では、単発ながら闘化ルシファーよりも高効果なミアズマを持ち、高出力なコンボスキルを有する『[冥府の王]ハデス』、魔単条件で中盤以降強力なダメージソースとなる『[裂魂の魔刃]シェイド』が差異となっています。これらは現行手法における高コスト駒よりも総じて高火力で、デッキコンセプトにも合致していると言えるでしょう。
闘化ラニデッキ
次に比較するのは『[邁進せし兎姫]ラニ(闘化ラニ)』を用いた編成です。闘化ラニはリーダーとして手駒にあるとき高倍率で味方の攻撃力を強化するバフスキルを有しており、特に混合デッキのリーダー駒として近年のデファクトスタンダードとなっています。また、リーダーバフスキルを持つ他の駒はコンボスキルが設定されていなかったりあまり有用でないことが多いですが、闘化ラニは強力なコンボスキルも備えており、手駒ロックなどの妨害で盤面に出さざるを得なくなった場合でも活躍が見込める汎用性を持ち合わせています。
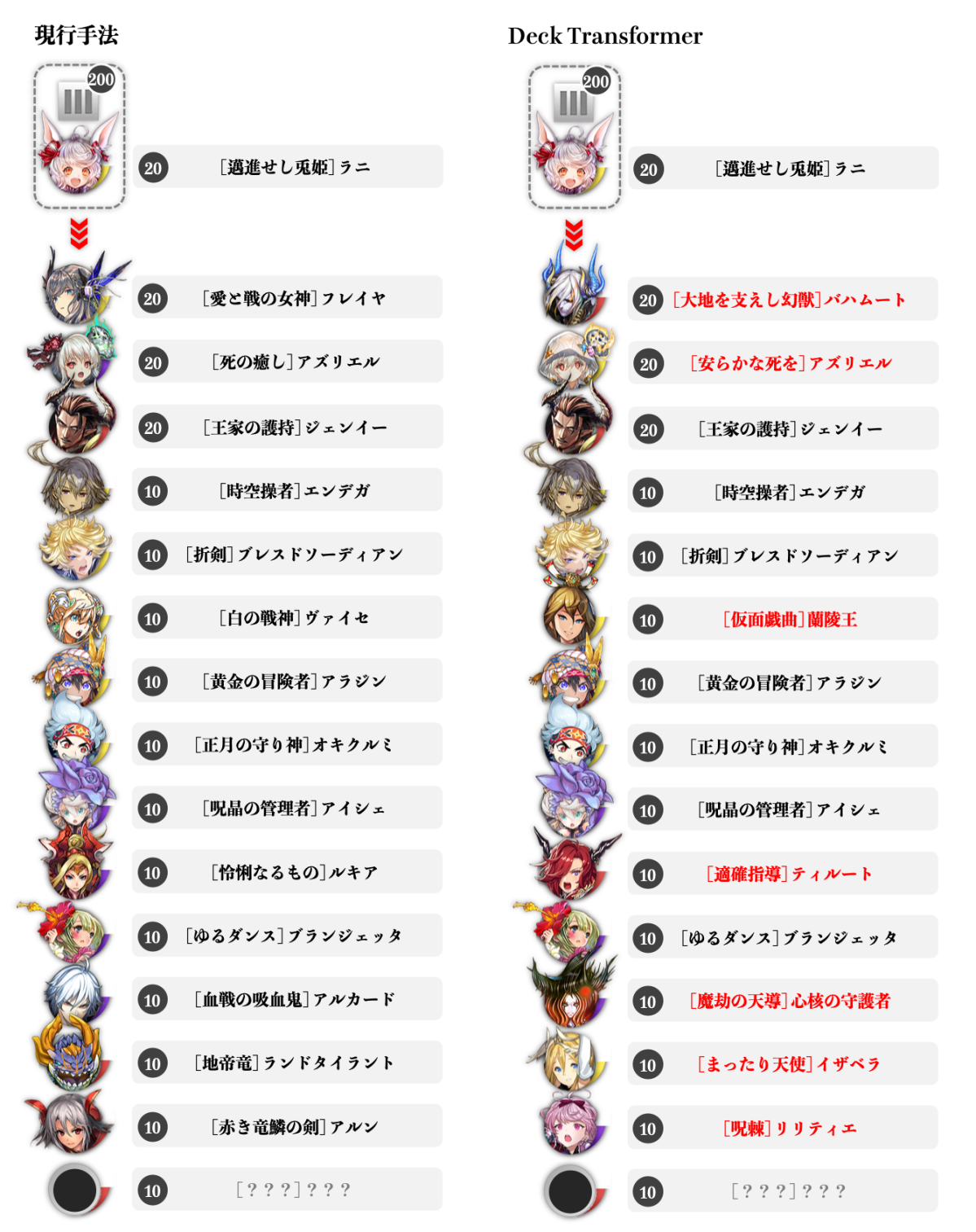
闘化ラニを起点とした混合デッキの生成比較。(著作権の関係上、一部未掲載の駒が含まれています。)
両者に共通する構成としては、序盤の削り役から中終盤にかけての追加ダメージ要因まで担える『[正月の守り神]オキクルミ』や『[黄金の冒険者]アラジン』、デバフと中盤以降のバフ要因になる『[折剣]ブレスドソーディアン』、易しい条件に見合わぬトップクラスの貫通バフスキルで場を圧倒する『[王家の護持]ジェンイー(進化ジェンイー)』、スキル・コンボスキルともに高火力で中コスト駒最強の呼び声も高い『[時空操者]エンデガ』等が挙げられます。いずれも闘化ラニデッキではよく採用される駒です。
中コスト駒における最も顕著な差異は『[仮面戯曲]蘭陵王(闘化蘭陵王)』の存在です。闘化蘭陵王は混合デッキを条件とするコンバートスキルを有しており、ダメージを増幅させつつ場合によっては相手の防御駒をすり抜けて攻撃することができる優秀な駒です。自身のHPが低下するほど倍率が高まるバフコンボスキルも持ち合わせており、混合デッキを構成する上での最有力候補のひとつと言えるでしょう。
他に、盤面にある自身のキャラクター駒数に応じて火力が高まる『[適確指導]ティルート』は竜デッキだけでなく混合デッキでも活躍できる攻撃要因として知られています。闘化ルシファーデッキにも登場した魔の守護者の姿もありますが、これは最強の吸収スキルに加え高倍率のバフコンボスキルも持ち合わせているため、闘化ラニデッキでもよく用いられているようです。さらに少々テクニカルな観点では、魔の守護者は相手に手駒ロックをされても闘化ラニが選択されないための調整駒(敢えて最大強化せず半端に育成を止める)としても扱いやすく、その点でも納得の編成と言えます。
高コスト駒の差異は、盤面にある自身のキャラクター駒数が増える中盤以降で進化ジェンイー以上の倍率を出しうる貫通バフ持ちの『[大地を支えし幻獣]バハムート(進化バハムート)』、汎用性の高い高火力アタッカーである『[安らかな死を]アズリエル(神闘化アズリエル)』となっています。進化ジェンイー、進化バハムート、神闘化アズリエルは互いに高倍率バフを掛け合える相性の良さで大ダメージを狙えることから混合デッキでも好まれており、これらをまとめて編成することで大幅な戦力強化に貢献していると言えそうです。
注意点として、両編成に含まれている『[呪晶の管理者]アイシェ』は、今回用いたデータの収集期間(2020年8月下旬)以降に性能変更が施されたため、現在の環境では異なる結果となる可能性があることを付記しておきます。
余談ですが、Deck Transformerによる闘化ルシファーデッキ、闘化ラニデッキの編成は、逆転オセロニアに精通している社員の方から『ほぼ完璧に見える、こんなデッキを作ってみたいもの』といわしめる完成度を誇りました。頑張ったのはモデルですが私も鼻高々です。
魔フェリヤデッキ
以降はDeck Transformerの編成結果のみを示します。
本項では『[逢魔の少女]フェリヤ(魔フェリヤ)』をリーダーに据えたデッキ編成を試してみることにします。逆転オセロニアには『フェリヤ』と呼ばれる入手難度の高い駒が存在するのですが、これを各属性に闘化させることでそれぞれ無類の強さを誇る駒に変貌します。魔フェリヤは魔属性の中でもトップレベルの毒スキルと吸収コンボスキルを有しており、序盤で盤の辺に置くことで継続して高いダメージを与えられ続ける点が大きな魅力です。
結果は下図のようになりました。各駒はDeck Transformerが出力した順に並んでいます。
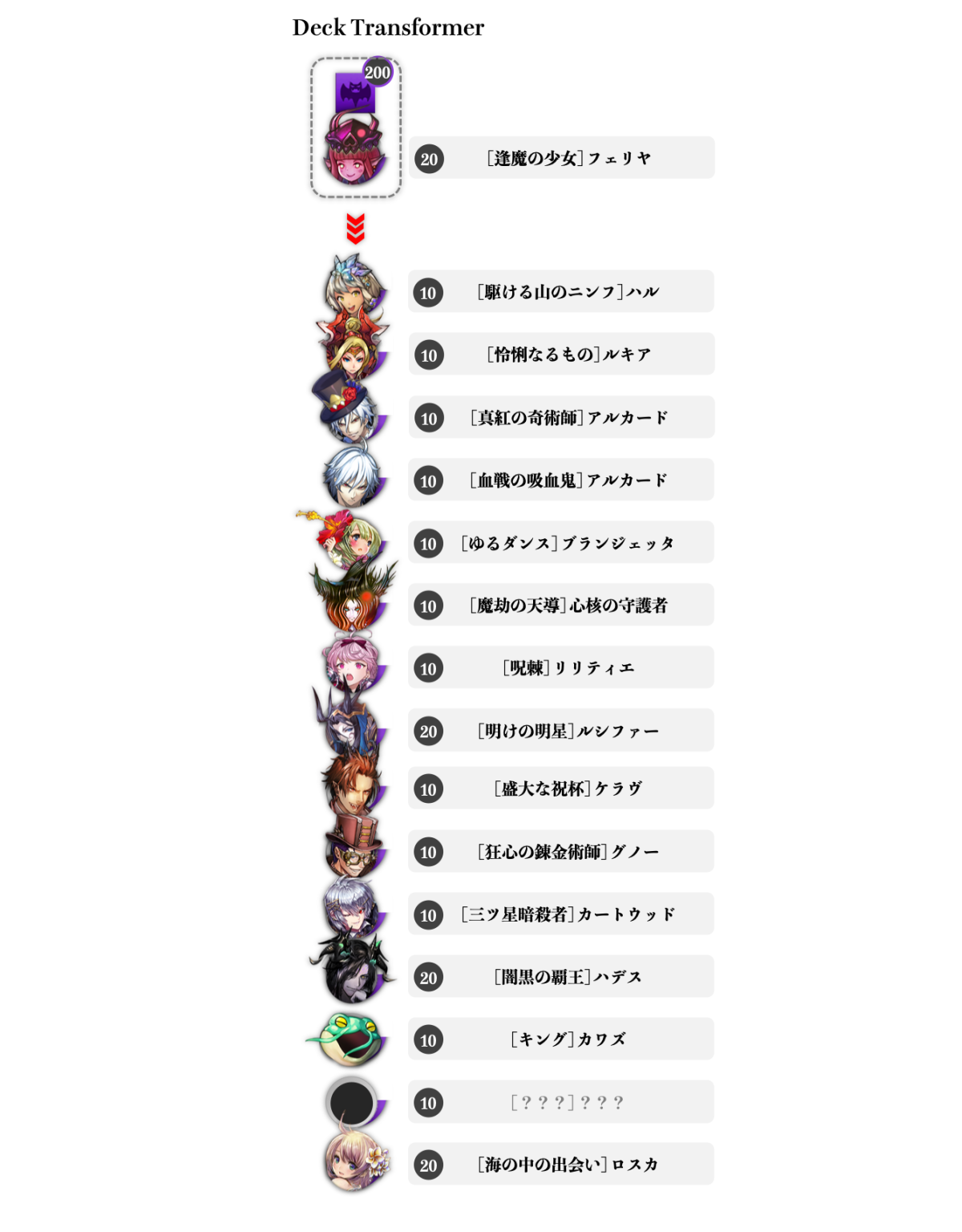
魔フェリヤを起点とした魔デッキの生成比較。(著作権の関係上、一部未掲載の駒が含まれています。)
手駒ロックのルキアやハロウィンアルカード、最強吸収の魔の守護者、ミアズマ持ちのケラヴ、毒と吸収を宿す駒を召喚できる『[ゆるダンス]ブランジェッタ』、コンボを封印する『[狂心の錬金術師]グノー』、優秀な罠スキルとコンボバフを持つ『[呪棘]リリティエ』といった妨害要因、また特殊ダメージで戦況を安定させる闘化アルカードやハルは闘化ルシファーデッキの結果と共通しており、魔単デッキを構築する上で必須級の駒が反映されていることがわかります。
一方こちらでは、強力なデバフスキルとバフコンボを有する『[三ツ星暗殺者]カートウッド』が編成されています。これは終盤での相手の決定打を削ぐ際にも、自身が高威力を出したい際にも役立ちます。また必須級の駒ではないものの、手駒にあるだけで継続毒ダメージを与える『[キング]カワズ』も含まれ、デッキのサポートに余念がありません。
高コスト駒では『[明けの明星]ルシファー(進化ルシファー)』『[闇黒の覇王]ハデス(闘化ハデス)』が特徴的です。進化ルシファーは闘化ルシファーと異なって攻撃特化駒となっており、敵味方・無地駒かキャラクター駒かを問わず盤面上の駒数に比例して増大する特殊ダメージを放つため、決定打に欠けがちな魔フェリヤデッキの貴重なダメージソースとしてよく運用されます。闘化ハデスは毒、吸収、特殊ダメージを駆使して総合的に高火力を狙えるため、やはり魔フェリヤデッキの戦力強化に好まれる駒だと言えます。
また『[海の中の出会い]ロスカ』は回復と攻撃を担える駒を複数召喚できる他、自身も吸収のコンボスキルを持つ非常に強力な駒です。魔フェリヤデッキが孕む耐久戦の側面を支えることが期待できます。
暗黒竜デッキ
最後に生成するのは暗黒竜デッキです。逆転オセロニアでは手駒が『呪い』という状態異常にされることがあり、プレイヤーは手駒全体に蓄積された呪いの数に応じて毎ターンダメージを受けてしまいます。この呪いは基本的に魔デッキの攻撃手段のひとつなのですが、これを逆手にとって自己強化するのが暗黒デッキです。暗黒デッキの構成要素は概ね『自分自身を呪う駒』『呪われていることで強くなる(または味方を強くする)駒』『呪いダメージを軽減する駒』に大別できますが、近年ではこれらの役を全て担える『黒鱗』というリーダースキルを有した駒が台頭してきています。
以下は黒鱗を持つ『[破壊竜]アルイーナル』と『[世界の監視者]アークワン(闘化アークワン)』をそれぞれリーダーとした場合の生成結果についての考察です。いずれもDeck Transformerによる結果であることに注意してください。
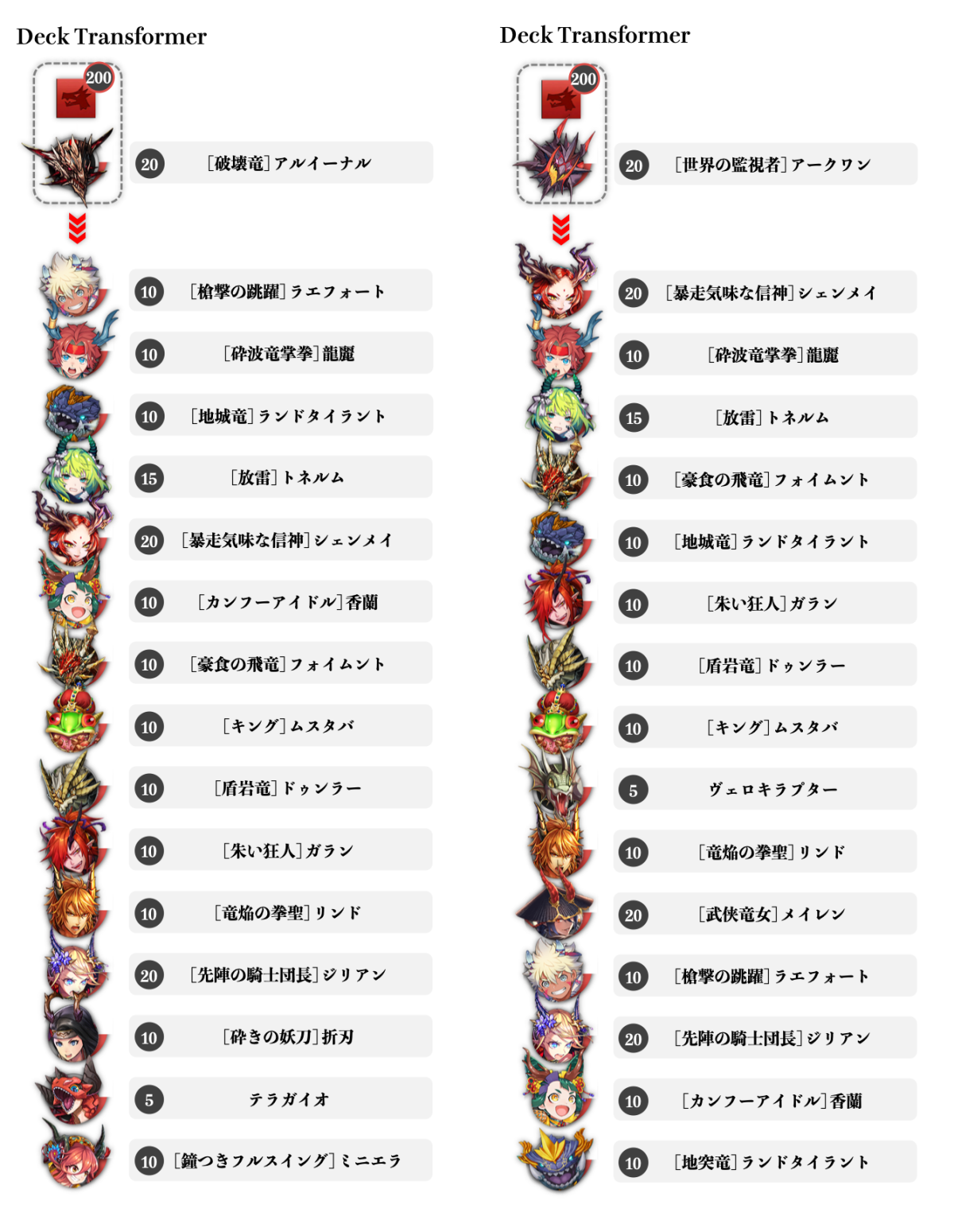
暗黒竜デッキの生成例。共通の駒も多い中で、一部に各々の特色が見られる。
まず第一に、いずれも黒鱗の発動条件である竜単デッキであることを満たしています。さらに、一定以上呪われていることにより大幅な回復を誘発できる捕食スキルを持った『[鐘つきフルスイング]ミニエラ(正月ミニエラ)』『[槍撃の跳躍]ラエフォート』『[カンフーアイドル]香蘭(アイドル香蘭)』『[豪食の飛竜]フォイムント』『[朱い狂人]ガラン』『[竜焔の拳聖]リンド』『[キング]ムスタバ』が編成に含まれ、その大半が両者に共通しています。
呪われていることで火力を増す攻撃駒枠も、『[暴走気味な信神]シェンメイ』『[武侠竜女]メイレン』『[先陣の騎士団長]ジリアン』『[放雷]トネルム(進化トネルム)』『[砕きの妖刀]折刃』等、豊富に確保されていることが確認できます。特に進化トネルムは毒・呪い・吸収によるダメージを軽減する『逆鱗』スキルを持っているため、暗黒竜デッキには必須の駒が編成されていると言えるでしょう。進化トネルムは珍しいコスト設定のため、デッキコストを超過しないために両編成ともひとつだけ低コスト駒が出力されていることも特徴的です。また、バフは付与されないものの同様に呪いを軽減する『竜鱗』を持った『[地突竜]ランドタイラント(3周年ランドタイラント)』も見受けられます。
驚くべきことに、アルイーナルをリーダーとしたDeck Transformerの編成結果は、有名な攻略サイトであるGame8にて紹介されている一軍の暗黒竜デッキ例(記事執筆時現在)と正月ミニエラ、アイドル香蘭、折刃以外が一致しています。さらに正月ミニエラと折刃に関しては代替駒候補として挙げられており、極めて妥当な編成であることが示されたと言えます。
同様に、闘化アークワンをリーダーとして編成した結果も進化ジリアン、アイドル香蘭、3周年ランドタイラント以外が一致しています。進化ジリアンはアルイーナルデッキの構成要素である上、3周年ランドタイラントはやはり代替駒候補として挙げられており、こちらについても実ユーザーの体感に近い有用な編成であることが理解できます。
推論における速度感
速度的な観点では、今回のタスクでは予測対象駒数が最大16枚と一般的にTransformerで用いられる系列長よりも1桁ほど小さいおかげもあってか、CPU上で500ms前後で1デッキぶんの推論が実行できることが確認されました。推論時のミニバッチ処理にも対応しているため、複数クエリを同時処理すればデッキあたりの生成速度はさらに短縮できると見做せるかもしれません。Pythonベースのコードでこれだけの速度が出るのであれば、C++等で推論専用に演算処理をチューニングすれば実環境での動作も十分射程内だと考えられます。
結び
本記事では『逆転オセロニアにおける自動デッキ編成の性能改善』を目的に、タスク設定の確認、類似する機械学習手法の選定、所望の個別タスクに適用するための改造に至るまでを記述しました。またその結果、単一モデルによって様々なタイプのデッキに関して現行手法を上回る表現力を持ったデッキ編成が実現できることを実験的に示しました。さらに、実運用に向けての簡単な所感についても述べました。
インターン自体は既に終了してしまっているため本手法をこれ以上膨らませる機会がないのは残念ですが、個人的に将来の展望として、今回の手法で得られた駒の分散表現は他の機械学習手法全般に効果的に利用されうるだろうという見解があります。例えばDeNAでは深層強化学習を用いて逆転オセロニアのバランス設計を行う取り組みがなされています。その条件付けや学習可能なパラメータの初期値として本手法で得られる埋め込みベクトルを利用すれば、実際のユーザーのプレイログにより蓄積された駒の特性を上手に反映することが可能になるのではないかという期待です。
また、今回は駒を自然言語処理における単語のように、つまり内容不明な個別の対象として扱いましたが、駒の各種ステータスやスキル情報を適切に潜在表現に落とし込めば、より精度改善が見込めるのではないかという考えもあります。特に、仮にあらゆる駒を完全にステータス情報による埋め込みに分解できる(=要素還元的に扱える)のであれば、今後新規駒が登場した際も使用データが得られるより前にデッキ編成への影響を検証することができることが期待されます。
実際は逆転オセロニアのプレイログは凄まじい勢いで更新されているので、新規駒対応は動機としてはあまり強くないかもしれませんが、それはそれとして純粋な学術的な興味は尽きません。
本記事は相当量のボリュームになってしまいましたが、そのぶん丁寧にお伝えできたものと自負しております。皆様が何かひとかけらでも有益な気づきを得られていたなら望外の喜びです。ご覧いただいた方々へ、心よりの謝意を。
インターンという観点から振り返って
私は同期や先輩方と比べて就職に関するモチベーションが低い模範的修士生だったので、インターンも社会経験のつもりで本選考にのみ応募し、幸運にも採用していただくことができたところから今回の取り組みが始まりました。未経験の自分ですら肌で理解できる高水準の環境で手厚いサポートをしていただき、接しやすくスムーズなコミュニケーションに努めていただいたことも相俟って、本当にのびのびと課題に向き合うことができたように思います。
期間の前半、私はなぜか『駒の分散表現を獲得すること』それ自体に異様な興味と執着を燃やしており、一方でこれがどのような応用に結びつくのかの明確なビジョンを持てずにいることに焦り、悩んでいました。機械学習の世界にタスクを持ち込めばいずれ有用な用途に使えるだろうという漠然とした期待と、とりあえず手を動かさなければという闇雲さに突き動かされていたように思います。まさに、本記事の対象読者層としても見据えた『機械学習の恩恵に与りたいけれど、所望の問題設定にドンピシャな手法なんてそうそうなくて思うようにいかないな』を体現していました。
転機が訪れたのは折り返しの週末でした。唐突に今回のタスク設計から実装のアイデアまでが浮かんだのはそれまでの積み重ねがあったからとも言えますが、それ以上に大きかったのは、当時ほとんどないに等しかった(アピールが難しい状態だった)私の進捗をメンター社員の皆さんが咎めることなく、常にアドバイスやバックアップに徹してくださったからだと感じます。そこでは、研究志向の強かった私が『課題として求められることはなにかを意識すること』『手法ドリブンではなくタスクドリブンで考える重要さ』『限られた期間で結果を出すために予期できる遠回りを極力避ける思考』を身につけ始めるまでの全てが詰まっていました。
思いついてからは自身でも驚くほどの速度で実装と実験のサイクルを回し、結果的に期限内に成果をまとめることが叶いました。これもひとえにメンターの方々や同時期に参加されていたインターン生の皆さんのご協力があってこそでした。
本記事はある意味で、それらの過程で私自身が得た気づきや興奮を追体験する形で記述された日記の姿を纏っています。だからこそ、今回のような特殊な課題設定であることを越えて、ご覧くださった皆様に何かしら届くものがあればいいなと願っています。それではまた機会があれば、いずれどこかで。
オセロ・Othelloは登録商標です。TM&© Othello,Co. and MegaHouse / © 2016 DeNA Co.,Ltd.



最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。