





この記事は先日開催された「 GCPUG Tokyo Spanner Day May 2020 」で発表した内容のまとめです。
概要
- Cloud Spannerではセカンダリインデックスもテーブル
- インデックスを作成するタイミングには注意が必要
- インデックス設計の際にはクエリの実行プランを確認
Spannerのセカンダリインデックスの基本
Cloud Spanner(以下、Spanner)で特定のレコードを主キー以外の列で見つけたいときにセカンダリインデックスは役に立ちます。 Spannerのセカンダリインデックス(以下、インデックス)は、非インデックスのテーブルと同様に、テーブルとして格納されています。 そのため、通常のテーブルと同様にスキーマ設計では ホットスポット の発生に注意したり、 読み取りパフォーマンス向上のために インターリーブ したりなど考慮することがあります。
インデックスの作成
次のようなテーブル定義を想定します。
CREATE TABLE Singers (
SingerId INT64 NOT NULL,
FirstName STRING(1024),
LastName STRING(1024),
SingerInfo BYTES(MAX)
) PRIMARY KEY (SingerId);
このSingersテーブルのLastNameがSmithのレコードを検索するクエリを発行します。
SELECT SingerId
FROM Singers
WHERE LastName = 'Smith';
このクエリを発行するとテーブル全体のスキャンが行われて対象のレコードが返されます。 そこで、より効率的にレコードを見つけるためにインデックスを作成します。 インデックスの作成は次のように行います。
CREATE INDEX SingersByLastName ON Singers (LastName);
これにより、元のテーブル(ベーステーブル)よりも遥かに小さいサイズのインデックステーブルから効率的に目的のレコードを取得することができます。
インデックスの使用を指定
先程LastName列に対してインデックスを作成しました。 ここで次のようなクエリを発行してみます。
SELECT SingerId, FirstName
FROM Singers
WHERE LastName = 'Smith';
このクエリの実行計画を見てみると、 インデックススキャンではなくテーブルスキャンが実行されていることがわかります。
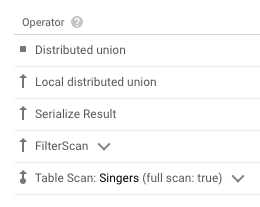
Spannerの場合、インデックスの使用を明示的に指定しない限り、 (執筆時点のクエリオプティマイザでは) カバリングインデックス としてのアクセスでないと自動的に使用されません。
例えば、次のクエリはカバリングインデックスとしてのアクセスではないため、 インデックスが自動的には使用されません。
SELECT SingerId, FirstName -- FirstNameがインデックスSingersByLastNameに含まれない
FROM Singers
WHERE LastName = 'Smith';
そこで、次のように FORCE_INDEX で使用するインデックスを明示的に指定すると、
Spannerのクエリオプティマイザに対してインデックスの指定を強制できます。
SELECT SingerId, FirstName
FROM Singers@{FORCE_INDEX=SingersByLastName}
WHERE LastName = 'Smith';
STORING句
FORCE_INDEXでインデックスの使用を強制できることを紹介しましたが、 先程のクエリの実行計画を見てみると、 インデックススキャンとテーブルスキャンが実行され、 それぞれの結果の結合処理が実行されていることがわかります。 この結合処理は対象となるレコード数が多いと読み取りパフォーマンスに影響がでてきます。
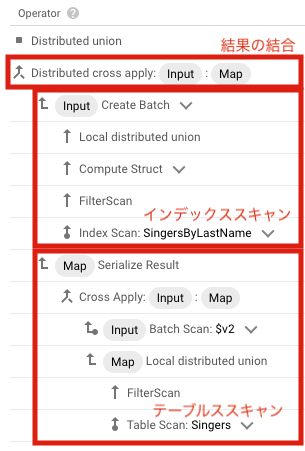
そこで、ベーステーブルとの結合処理を避けたい場合に STORING 句を使用します。
STORINGを使用すると、追加の列をインデックステーブルに格納することができます。
STORINGを使ったインデックスの作成は次のようにします。
STORINGを使用するとベーステーブルとの結合処理を回避できますが、
追加のストレージ費用と書き込みをコストが発生することに注意が必要です。
CREATE INDEX SingersByLastNameStoringFirstName
ON Singers (LastName)
STORING (FirstName);
インデックスのインターリーブ
インデックスは通常のテーブルと同様にテーブルとして格納されており、 通常のテーブルと同様に他のテーブルにインターリーブすることもできます。 インターリーブをすることにより、参照 スプリット が1つに限定されるため、 インターリーブしていない場合にくらべ読み書きの効率が高くなります。 そのため、インデックスのインターリーブが有効なのは、 検索対象が特定のエンティティに絞り込める場合です。
前述の歌手テーブルの子テーブルとして曲テーブルを想定します。 このときインターリーブされたインデックスの作成は次のように行います。
CREATE INDEX SongsBySingersSongName
ON Songs(SingerId, SongName)
INTERLEAVE IN Singers;
インデックスのインターリーブが有効な例をいくつか紹介します。
特定の歌手の曲をリリース日順で並べ替える
特定の歌手の曲を一覧表示する場合、検索対象のエンティティが特定の歌手に絞り込めるため、 インデックスのインターリーブが有効です。
次のように曲テーブルのインデックスを作成します。
CREATE INDEX SongsBySingerCreatedAtDesc
ON Songs(SingerId, CreatedAt DESC),
INTERLEAVE IN Singers;
そして、次のようなクエリを発行します。
SELECT SingerId, SongId, SongName, CreatedAt
FROM Songs@{FORCE_INDEX=SongsBySingerCreatedAtDesc}
WHERE SingerId = 1000
ORDER BY CreatedAt DESC
このときのクエリの実行計画を見ると、結果の結合が行われていますが、 1つのスプリット内で結合処理が完結していることがわかります。
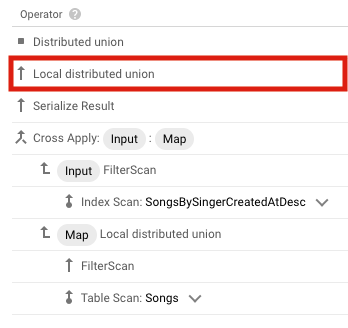
インデックスの設計・使用上の勘所
ここまでインデックスの基本的な内容を紹介してきました。 ここからは、インデックスを設計・使用する上での勘所を紹介していきます。
インデックスの効率的な作成
Spannerのインデックスを作成するとき、 Spannerの内部ではデータの検証やバックフィル処理が行われます。 これらの処理は、ノード数やデータ量に応じて数分から数時間を要します。
したがって、インデックスの作成効率が最も高いのは、データが何も入っていないテーブル作成時に一緒に作成する場合です。 プロダクトのリリース前に予めインデックスを作成しておくと良いです。
ある程度データが入ってからインデックスを作成した方が良い場合
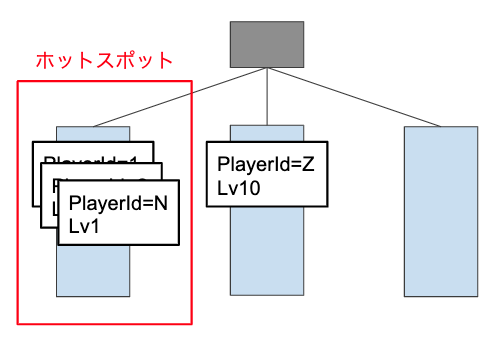
例えばゲームのプレイヤーをレベルごとに検索する場合を考えます。 リリース直後は多くのプレイヤーがレベル1付近に偏っているため、 レベルをキーとしたインデックスを使用するとホットスポットが発生してしまいます。 (負荷ベースでスプリットの作成が行われますが、アクセスの頻度によっては一時的にサービスが重く感じるかもしれませんので事前に検証が必要です。) このような場合は、データがある程度入ってからインデックスを作成する事で、リリース直後のホットスポット発生を回避または軽減することができます。
既存のテーブルにインデックスを追加するときの注意点
レコード数が多いテーブルにインデックスを追加する場合、 インデックスの追加は1日に3つまでを目安にするのが良いです。 3つ以上のインデックスを追加するとSpannerのシステムが利用するリリースが多くなりパフォーマンスに影響が出る可能性があります。
参考: 大規模なスキーマ更新のオプション
STORINGを使ったインデックスの使い所
STORINGを使うとインデックスに追加の列を格納することができ、 参照がメインの場合には非常に有効となります。
一方で、更新頻度の高いテーブルの場合、 ベーステーブルの更新に加えてインデックステーブルの更新も行われるため書き込みコストが高くなってしまうので注意が必要です。 この様な書き込み頻度の高いテーブルはインデックスを使わずに主キーで絞り込むようにしてみてください。
FORCE_INDEXの使用について
前述の通りFORCE_INDEXを使ってインデックスを指定した場合、 インデックステーブルに存在しない列を返すためにベーステーブルとの結合処理が行われます。 そのためFORCE_INDEXの使用は避けてカバリングインデックスにした方が良いのではないかと思うかもしれません。 しかし、一概に使用を避けるのではなく状況によって使い分けるのが良く、クエリの実行計画をみて判断するのが良いです。
例えば、ベーステーブルのレコードを1つだけに絞り込めるような場合は使っても良さそうです。 逆に、インデックススキャンでテーブルの大半のレコードを返してしまう場合は、ベーステーブルも多くのレコードをスキャンすることになるため使用を考えたほうが良いです。
インデックス列の並び順
インデックスの列は取得したい順で予め並べておくと、不要なディスクシークを避けることができるので、並び順にも注意が必要です。
おわりに
この記事ではSpannerのインデックスの基本から、使用・設計上の勘所を紹介しました。 実際設計する際にはGCPコンソールでクエリの実行計画やクエリ統計を観察して最適な設計を検討すると良いでしょう。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。