





AIシステム部の加藤倫弘です。私は現在 「DRIVE CHART」 のエッジAIチームのチームリードとして、ドラレコへのAI技術組み込み全般を担当しています。
この記事は、 DRIVE CHARTにおける AI技術の事業応用 ーモデル開発からサービスデプロイまでー Part1 の後編です。 後編では、研究開発しているアルゴリズムをどのようにドラレコに組み込んでいるか、実装観点でご紹介します。
- Deep Learningモデルの安全な変換
- ドラレコへのコンピュータビジョン機能実装
- AIテスト基盤の開発
- 拡張性の高いエッジAIアーキテクチャの設計
Deep Learningモデルの安全な変換
DRIVE CHARTでは、学習時と本番運用時(サーバーサイドとドラレコ)で利用するDeep Learningフレームワークが異なるため、モデルをデプロイする際に変換する必要があります。
Deep Learningフレームワークやそのフォーマット間での変換ツールはメジャーなものが存在するものの、変換ツールの仕様で期待通り変換できない場合があります。 そこで、下図のようなモデル変換パイプラインを構築し、Deep Learningモデルが期待通り変換できることを確認した上でデプロイしています。
モデル変換フレームワークは学習したモデルをいくつかのステージに分けて変換をしていきます。 Deep Learningフレームワーク間の変換に加えて、変換ミスへのパッチや、計算量やファイルサイズ削減のための最適化、変換前後でのテストなど行います。
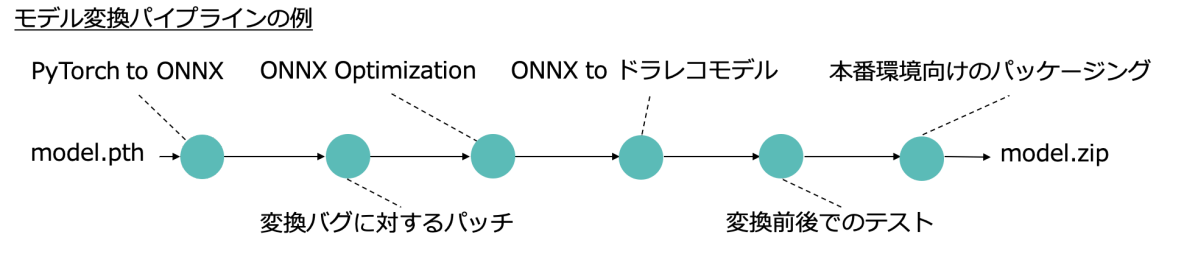
Model Conversion Pipeline
モデル変換パイプラインは、 Digdag を利用して構築しており、以下の例のようにYAMLでモデル変換パイプラインの定義をします。 各ステージは差し替えができるので、異なるDeep Learningフレームワークの試行なども短期間で行うことができています。
+pytorch-to-onnx:
image: chart-edge-model-converter_pytorch
py>: Model.convert
input_shape: [1, 3, height, width]
weight_path: s3://xxxxxxxxxxxxx
+optimize-onnx:
image: chart-edge-model-converter_onnx
py>: ONNXOptimizer.run
ドラレコへのコンピュータビジョン機能実装
私たちは、Pythonでコンピュータビジョンのアルゴリズムの研究開発を行い、ドラレコに組み込むときはRustで再実装しています。 再実装する理由の一つは、ドラレコでは二台のカメラ映像を複数のDeep Learningモデルを使ってリアルタイムに処理するため、実行効率が必要であることです。
ドラレコのコンピュータビジョン機能の実装は、サービス開始時まではC++で実装していました。 しかし、機能増加や品質向上の過程で自分たちのチームではC++を使いこなすのは難しいと判断し、より生産性や安全性が高いと思われたRustに移行して現在次世代の機能を開発中です。
Rust移行の過程については、 Rust.Tokyo 2019 でお話しましたが、現在でも以下のようなメリットを感じています。
- 適切なエラー処理を書きやすく、開発中の実行時エラーが削減できた
- パッケージ分割がしやすく、ビルド時間の短縮や依存関係を適切に保ちながら継続的な開発ができている
- はじめからRustで実装し、Python bindingを用いて他チームに提供し検証してもらうことも増えつつある
Rust.Tokyo 2019の登壇内容はこちら。
AIテスト基盤の開発
私たちは、ドラレコにデプロイしたい開発段階のコンピュータビジョン技術をサーバーサイドで検証するためのシミュレータを開発しています。
ドラレコにデプロイするコンピュータビジョンアルゴリズムを改良した際は、ドラレコからサーバーサイドに渡るAI機能パイプライン全体の性能変化を確認し、必要なら各ステージをチューニングした上でデプロイする必要があります。 そのためには、大規模なデータでの処理を繰り返し試行する必要があり、クラウドを活用して効率的に検証を進めたいと考えました。
具体的には、過去に撮影・保存した動画からドラレコのコンピュータビジョン処理を並列にシミュレートするクラスタとして実装しています。 このクラスタはドラレコとはプラットフォームが異なりますが、Rust自体がマルチプラットフォーム向けにビルドできることや、次の章で説明する設計時の工夫などにより、 ドラレコ用に実装したコンピュータビジョンアルゴリズムの大半をサーバーサイドで検証することができています。

AI Test Platform
拡張性の高いエッジAIアーキテクチャの設計
エッジAIの関連ライブラリは数ヶ月で大きく変わる可能性があるため、それに追従すべくソフトウェアアーキテクチャの工夫もしています。
例えば、エッジ向けのDeep Learningフレームワークは何種類もあり、それぞれが日々機能追加や性能向上しています。 しかし、新しいフレームワークに変更したくとも、システム全体が特定のフレームワークに密結合している場合は変更による影響範囲が多く、費用対効果の点で変更が見送られることもありえます。
そこで、新しい技術への対応を容易にするために、アプリケーションとDeep Learningフレームワークはインターフェースを介して疎結合にするようにDependency Injection(DI)を用いて設計しています(下図)。
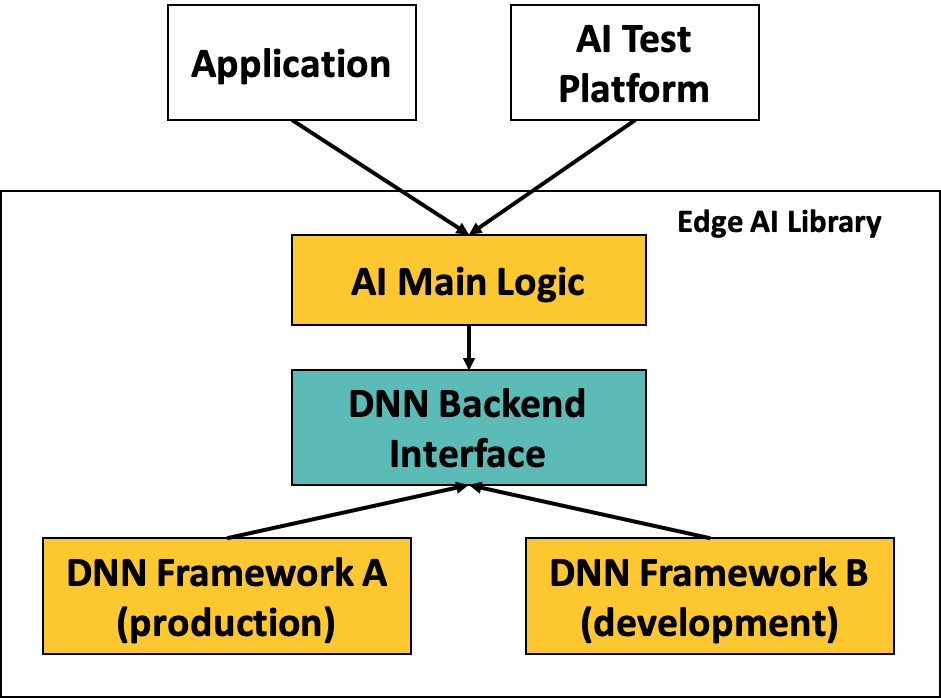
Edge AI Architecture
これにより、次世代向けのDeep Learningフレームワークの検証をする場合も既存のアプリケーションと直接結合でき、研究開発とプロダクション開発をスムーズにつなぐことに貢献しています。。
同様に、AIテスト基盤ではこの仕組みを使って、アプリケーションの変更なしにDeep Learningフレームワークを切り替えています。 これは、AIテスト基盤側はドラレコとはプラットフォームが異なるため、現実的な時間やコストで処理を行うためにはプラットフォームに合ったフレームワークを使う必要があるためです。
この章ではDeep Learningフレームワークを例として挙げましたが、その他にも変更可能性があり強く依存したくないライブラリやテスト時にダミーに差し替えたいプラットフォーム固有の機能は同様の設計をしています。
最後に
以上、研究開発しているアルゴリズムをどのようにドラレコに組み込んでいるかの事例をご紹介しました。
研究開発からプロダクション開発につなげ、それを並行・継続的に行うのはチャレンジングではあります。 しかし、技術的に解決できる課題も多く、開発フェーズによって注力する技術分野も変わるので、幅広い技術に触れたい私としては面白い仕事だと感じています。
私たちエッジAIチームの次の目標のひとつは、ドラレコの機能拡張や安定運用を実現するために、デバイスのリソースを効率的に使うソフトウェアを作ることです。
今以上に早く、価値のあるAI機能をサービスに載せていくために、Deep Learningモデルの高速化技術からソフトウェアアーキテクチャ、エッジだけでなくサーバーサイドのテスト基盤開発まで、手広くやっていきます。
最後まで読んでいただきありがとうございました。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。