





はじめに
こんにちは。システム本部 分析推進部の鴨志田良和です。
[DeNA TechCon 2020] ( https://techcon.dena.com/2020/ ) にて発表する予定だった内容をBlog記事としてお届けします。 今回は「オートモーティブの大規模データ処理を支える技術」と題して、前後編でお送りします。 (前編は こちら )
後編となる本稿では、 マップマッチ処理で使用される、大規模な地図データを効率よく格納して 扱うための工夫についてご紹介します。
大規模地図データを扱う上での問題
マップマッチ処理(生のGPSデータの誤差を補正して道路上の位置を推定し、経路情報を得る処理) においては、 道路同士の位置や接続関係をグラフ構造のデータとして格納した地図データ (以下、「道路ネットワーク」と呼びます)があらゆる段階で利用されます。
日本全国の地図のように、 扱うデータの規模が大きくなると、 検証用の小さな地図だけを扱っていた初期の実装では見えていなかった、 2つの問題が明らかになりました。
それは、
- 必要なメモリ量の増大
- 初期化(データ読み込み)のための時間の増大
です。
必要なリソースの規模
初期の実装では、道路ネットワークを扱うための事前準備として、 以下の2つの処理を実施していました。
- データ読み込みとグラフ構造構築
- DBより道路の位置や属性のデータを読み込み、 道路間の遷移関係を表したグラフ構造データに変換する
- マップマッチ処理のアルゴリズムは python で記述しているため、 [NetworkX] ( https://networkx.github.io/ ) という python のグラフ分析ライブラリを利用
- 属性情報の事前計算
- 道路長や、曲がるときの角度など
- マップマッチ処理の中で頻繁に利用するため
- グラフ構造をファイルに書き出し
- 標準のオブジェクト直列化ライブラリであるcPickleモジュールを利用
その後、マップマッチシステムを起動する際には、 初期化処理として、上記のデータファイルを読み込んで使用していました。 読み込みにかかる時間は、約50分でした。
また、使用しているメモリは、約90GBでした。 ただし、事前準備フェーズのグラフ構造構築時に、一時的に2倍の量のメモリを必要としていました。
初期化に50分も時間がかかる状態では、柔軟にオートスケーリングを活用することもできませんし、 メモリ使用量も多いため、負荷が低い時間帯でも大きなサイズのインスタンスを立ち上げておく 必要があり、コスト的にも無駄になる懸念がありました。
非効率な部分を探せ!
道路IDの数は約1300万で、道路ネットワークを構築する際には向きを考慮して約2倍の 2500万のIDを格納しています。
単純に割り算をすると、ひとつのIDあたり、3.6KBのメモリを使用していることになります。
道路の位置、長さなどの属性情報、道路間の遷移関係を記述する情報などが IDごとに格納されていますが、 3.6KBというのは思ったよりもずっと大きいです。この理由は何でしょう。
必要なメモリが増える主な要因は、グラフ構造の実装の仕方にあります。 NetworkX は汎用のグラフ分析ライブラリとして、柔軟にグラフの頂点や辺、また、それらの属性情報を 追加・削除できるようになっています。 このために、多段のハッシュテーブル(python の dict)を使って実装されています。
要素が何も入っていない、空のdictでも300B程度のメモリが必要になるため、オブジェクト数が 多い場合は多くのメモリが必要になってしまいます。 また、pythonのオブジェクトヘッダのオーバーヘッドも無視できません。
多段のハッシュテーブル
道路ネットワークを格納するために利用している、NetworkX.DiGraph (有向グラフのためのクラス) は、 以下のように、2段・3段のハッシュテーブルを用いてグラフ構造を表現しています。
- 頂点データ
- 1段目のキー: 頂点ID
- 2段目のキー: 属性名
- 辺データ
- 1段目のキー: 遷移元の頂点ID
- 2段目のキー: 遷移先の頂点ID
- 3段目のキー: 属性名
- 逆向きの辺データ
- 1段目のキー: 遷移先の頂点ID
- 2段目のキー: 遷移元の頂点ID
- 3段目のキー: 属性名
道路ネットワークを格納する際は、 グラフの頂点を道路に、グラフの辺を道路間の遷移関係に対応付けています。
データ構造の例
以下のような道路を例に、実際のデータ構造について説明します。 図1 の青い線で示される道路(道路ID=11223344)は、図の右から左へ進むと、 2つの別な道路(道路ID=22334455と33445566)に分岐しています。
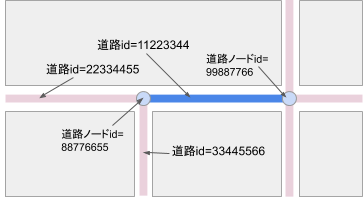
図1. 道路ネットワークの例
- グラフの頂点データ
頂点データは2段のハッシュテーブルです。
道路IDでハッシュテーブルを引くと、その道路IDに紐付けられた、道路長や座標などの属性情報が格納されたハッシュテーブルを取得できます。 2段目のハッシュテーブル(赤点線で囲んだ部分)が道路IDの数(向きを考慮した2500万)だけ必要になります。
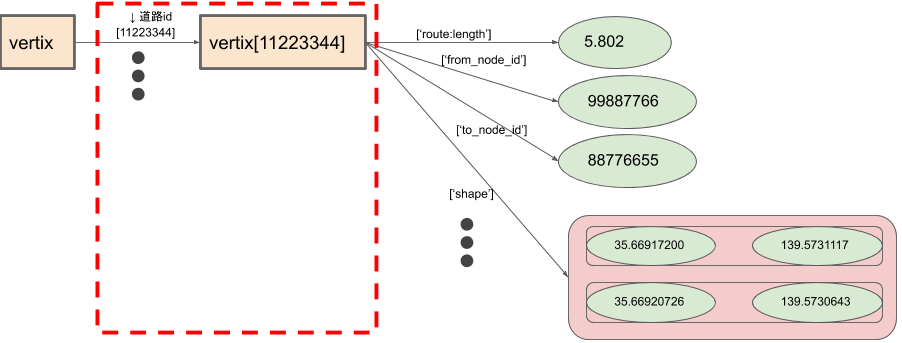
図2. グラフ頂点データの構造
- グラフの辺データ
辺データは3段のハッシュテーブルです。
道路IDでハッシュテーブルを引くと、その道路から遷移可能な隣接した道路が格納されたハッシュテーブルを取得できます。 さらに、その遷移先の道路IDでハッシュテーブルを引くと、その道路遷移に紐付けられた、角度などの属性情報が格納されたハッシュテーブルを取得できます。
道路間の遷移については、Uターンして、同じ道路を逆向きに進むことも考慮します。 (図の中では、正負を逆転させた道路IDへの遷移を、逆向きに進む遷移として表しています。)
3段目のハッシュテーブルについては、約7200万個必要でした。
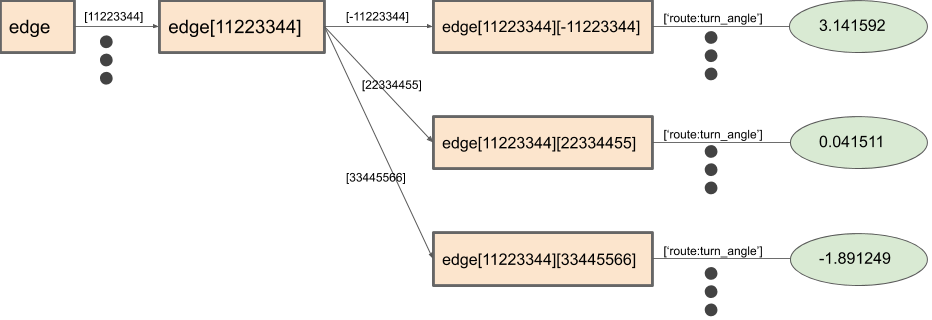
図3. グラフ辺データの構造
オブジェクトヘッダのオーバーヘッド
Pythonのオブジェクトは、ヘッダ情報として、参照カウントと型情報を持っています。 例えば、浮動小数点数(1.2345)のメモリ上の表現は以下のようになります。

図4. 浮動小数点数のメモリレイアウト
オブジェクトあたり、ヘッダのサイズとして16B必要になるため、 もし1億個のオブジェクトあれば、約1.6GBがヘッダ部分のメモリとして必要になります。
初期化時間
オブジェクト数は、データの初期化時間にも影響します。 pickleモジュールで直列化したオブジェクトを読み込む際も、 直列化されたオブジェクト数の回数だけ、 オブジェクト生成のためのメモリ確保や初期化が実行されます。 このため、オブジェクト数が多いと読み込みに時間がかかるのです。
データ構造の変更
初期の実装の調査を通して、以下の2点がデータの大規模化で重要だとわかりました。
- ハッシュテーブル(dict)の多用を避けるべき
- オブジェクト数を減らすべき
また、道路ネットワークは一旦読み込んだあとは変化しない前提とします。
これらをもとに、以下の方針で道路ネットワークを表現するデータ構造を変更することにします。
- 属性名ごとに、データを配列に格納する
- 道路ID→配列の添字を対応付けるdictを用意する
- NetworkX.DiGraphのインターフェースを変えないラッパーを実装する
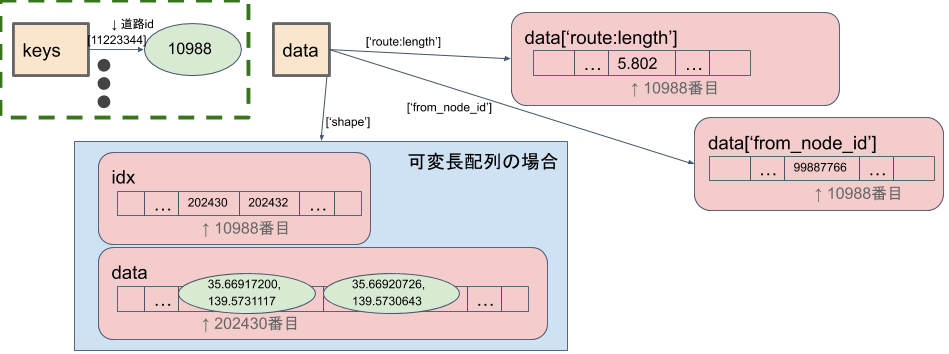
図5. 最適化後のグラフ頂点データの構造
属性名ごとの配列
道路データのそれぞれの属性情報は、
- 「道路長」は浮動小数点数(単位はメートル)、
- 「始点の道路ノード(交差点)ID」は整数、
など、同じ名前の情報は同じ型になっています。 そこで、「道路長だけを格納した配列」のように、 特定の属性値だけをまとめた配列を、 属性の種類だけ作ることにします。(各配列の同じ位置には同じ道路IDに関する情報を格納するようにします。)
ここで、「配列」は、pythonのlistではなく、arrayクラスや、NumPyのndarrayクラス等を指します。
このようにすることで、 同じ型の多数のオブジェクトをひとつの大きな配列オブジェクトにまとめることができます。 オブジェクトの数が削減されるので、ヘッダ部分のメモリ削減と、 読み込み時間短縮の両方が期待できます。
道路の属性情報を参照したい場合は、まず、 道路ID→配列の添字を対応付けるdict(図5の緑色の囲み) を引いて、その配列の添字を使って 属性の配列を参照します。
この方法により、道路IDの数だけ必要だったdictについても、定数個にすることができました。
データが可変長である場合や、欠損がある場合は、図の青の囲みのように、 データを格納した配列の位置を示す、整数の配列を間にひとつ挟むことで表現可能です。
グラフの辺(道路間の遷移関係)のデータも、 可変長配列と同様に格納することができます。
なお、NumPyの構造化配列(structured array)を利用することで、 属性の配列をひとつにまとめることも可能ですが、 実行速度を計測したところ、まとめないほうが高速でした。
評価
道路ネットワーク初期化時の、使用メモリと読み込み速度を評価しました。 読み込み時間については、データ構造を構築したあと、 cPickleモジュールを使ってファイルに書き出したものを最適化前後のそれぞれについて用意し、 そのファイルを読み込む速度を計測しました。
最適化前
- 読み込み時間
- 3243 秒
- グラフ構造構築後の使用メモリ
- 88.3 GB
最適化後
- 読み込み時間
- 31.3 秒
- グラフ構築後の使用メモリ
- 14.8 GB
このように、読み込み時間、使用メモリともに、劇的に改善することができました。
(最適化前 Amazon AWS r4.8xlarge(244GB memory), 最適化後 m4.4xlarge(64GB memory), ローカルファイル(EBS), ファイルシステムキャッシュをクリアしてから実行)
さらなる省サイズ化に向けて
データ構造の見直しにより劇的な改善があったものの、 初期化時に道路ネットワーク全体を読み込む方式では、 依然として以下の問題がありました。
- (30秒に減ったけれど)
pickle.loadでデータをparseしてメモリに展開する時間がかかる - (15GBに減ったけれど) 必要とするメモリサイズが大きい
そこで、「必要なとき、必要な部分だけ」オンデマンドに地図を読み込むことで、1CPU, 2GB memory程度の小さなコンテナ上でサクサク動かすことができないだろうか? という検討を開始することにしました。
オンデマンドな道路ネットワークの読み込み
最初に考えたシンプルなアイデアは、以下のような、 「地図をメッシュに区切り、メッシュごとに pickleファイルを用意しておく作戦」でした。
しかし、以下のような課題があり、実現が困難でした。
- (課題1) ファイルを分割するとメッシュ境界の扱いが面倒
- (課題2) 複数メッシュをまたがる長いGPS軌跡の扱いが面倒
- メモリが足りなくなったらunloadする?
- GPS軌跡を区切ってマップマッチを実行、その後統合する?
- (課題3) メッシュデータを読み込むたびに、
pickle.loadを実行するのが著しく非効率
メモリマップトファイル
そこで着目したのが、「メモリマップトファイル」です。 メモリマップトファイルを使うと、ファイルをOSの仮想メモリの連続領域に直接対応付ける事ができます。
例えば、 $2^{30}$ (=約10億) 要素のfloat配列が格納された、 4GB.dat というファイルがあったとして、
pythonでは以下のように書くことで、配列の要素を参照するようにしてファイルにアクセスすることができます。
data = np.memmap('4GB.dat', dtype=np.float32,
mode='r', shape=(2**30,))
メモリマップトファイルの特徴として、以下のようなことが挙げられます。
- マッピングするだけで、データの読み込みは行わないので、上の文は一瞬で戻ってくる
- 実際に要素にアクセスしたときに、キャッシュにページが存在していなければファイルI/Oが発生する
- 巨大なファイルをマッピングしても、実際にアクセスした部分しか物理メモリを使わない
メモリマップトファイルの利用
道路ネットワークを、memmapできるように作成すれば、前述した オンデマンド地図読み込み実現のために出てきた課題を、以下のように解決できそうです。
- (課題1) メッシュ境界の扱い
- ファイルを分割しなくて済むため、境界の考慮は不要になる
- (課題2) メモリ管理
- 物理メモリが足りない場合に、使われていない箇所を破棄するなどの メモリ管理は、OSのバッファキャッシュの仕組みが自動的にやってくれる
- (課題3) parse時間
- ファイルをマッピングするだけなので、データのparseが不要になる
上述の通り、NumPyには配列をmemmapする機能がサポートされているので、 実装コストもかなり小さく抑えられそうです。
そこで、道路ネットワークをmemmapできるようにするために、以下の2点を実装しました。
- 配列化されていなかったデータの配列化
- データのserializer/deserializer
配列化されていなかったデータの配列化
大きなデータ構造はすべて配列にすることで、 memmapの効果を最大限に活かすようにします。
道路IDから配列添字を引くdict (図5の緑の囲み)
- 道路IDを、$[-2^{24}, 2^{24})$の整数としてエンコード
- dictではなく、通常の配列として格納
- 恒等写像をハッシュ関数とするようなイメージ
- 配列添字として32bit整数を格納すると、高々128MBの配列になる
- 道路がないところには、負の数を入れておく
kd-Tree(2次元空間の探索で使用)の再実装
- これまでSciPyの実装を利用していましたが、小さなオブジェクトをたくさん作っていたため、 データの格納先にNumPyを使って実装し直しました。
データのserializer/deserializer
pickleと同様のインタフェースの、専用のserializer/deserializerを実装しました。 処理の概要は以下のとおりです。
- serializer
- 配列データを書き出す際は、まずファイル内の位置とサイズを決める (これもメタデータとしてファイルに書き出す)
- 書き出したい配列と同じshape, サイズの空の配列を
np.memmapでファイル上に作成する np.copytoを使ってコピー
- deserializer
- 各配列の、データファイル内の位置とサイズなどのメタデータをまず読み込む
- 配列データの読み込み、parseはせず、データファイル内の位置とサイズを指定して
memmapするだけ (なので、とても高速)
最適化後のデータファイルサイズ
オンデマンド読み込み対応後のデータファイルのサイズは、 約7.5GBになりました。この値が、必要な最大メモリサイズとなります。 最初の頃(88.3GB)と比較すると、1/10以下にする事ができました。 さらに、地図を全部キャッシュすることは必ずしも必要ないので、実用上は数百MBもあれば十分です。
初期化時間も、0.1秒以下になりました。 DRIVE CHARTを例に挙げると、一回のマップマッチ処理には数秒から数十秒かかるので、 仮に毎回道路ネットワークの初期化処理が実行されたとしても、 無視できるほど短い時間になりました。
コンテナ間のメモリ共有
memmapされた道路ネットワークは、OSのページキャッシュに乗ります。 同一ホスト内のコンテナはOSレイヤを共有しているため、道路ネットワークに関しても、共有されることになります。 したがって、ページキャッシュ分を考慮したメモリの使い方をすることで、効率的にコンテナ環境でのマップマッチ処理を実行できるようになります。
ページキャッシュを考慮したメモリレイアウト
DRIVE CHARTで本番運用している環境の一構成をご紹介します。
マップマッチ処理用のサーバーインスタンスの場合は、 たとえば、4CPU, 16GBのホストの場合には、1CPU, 2GBのコンテナを4つ動かして、 8GBを、あえてコンテナには割り当てずに空き領域にしておきます。 このようにすることで、他のファイルI/Oがなければ、空き領域の8GBは、道路ネットワーク全体が乗るキャッシュ領域として利用されることになります。

図6. コンテナとキャッシュのメモリレイアウト
道路ネットワークのうち、あるコンテナが一度アクセスした箇所はキャッシュに乗っているので、 別のコンテナが同じ領域にアクセスした場合も I/Oなしでマップマッチ処理を実行できることになります。
まとめ
以上、日本全国規模の道路ネットワークのような、大規模グラフデータを効率良く扱うために実施した、 データ構造の最適化についてご紹介しました。
データ構造をスリム化するだけでなく、メモリマップトファイルを活用することで、 同じホストのプロセス間でデータを共有しつつ、初期化時間も極限まで削減することができました。
さて、本稿では、前後編に渡って、DeNAのオートモーティブの裏側を支える、 マップマッチ処理に関連する、以下の技術を紹介してきました。
- マネージドサービスを活用した、スケーラブルに車両位置情報の収集・処理を行うクラウドアーキテクチャ
- 大規模な地図データについての、データ構造やOSレイヤも考慮した最適化
このように、DeNAのエンジニアリングでは、 クラウド技術、アルゴリズムとデータ構造など様々なレイヤーで技術を使い倒しています!
最後まで読んで頂きましてありがとうございました。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。