





はじめに
こんにちは、AIシステム部でコンピュータビジョンの研究開発をしている加藤です。我々のチームでは、常に最新のコンピュータビジョンに関する論文調査を行い、部内で共有・議論しています。今回は 2D Human Pose Estimation 編として加藤直樹 ( @nk35jk ) が調査を行いました。
本記事では 2D Human Pose Estimation に関する代表的な研究事例を紹介するとともに、2019年10月から11月にかけて開催されたコンピュータビジョンのトップカンファレンスである ICCV 2019 に採録された 2D Human Pose Estimation の最新論文を紹介します。
過去の他タスク編については以下をご参照ください。
- Human Recognition 編 (2019/04/26)
- 3D Vision 編 (2019/06/04)
- キーポイント検出の手法を用いた物体検出編 (2019/07/08)
- Object Tracking 編 (2019/07/17)
- Segmentation 編 (2019/08/19)
- Single Image Super-Resolution 前編 (2019/09/24)
- 動画認識編 (2019/10/09)
目次
- 前提知識
-
代表的な研究事例
-
Top-down型アプローチ
- DeepPose (CVPR 2014)
- Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation (NIPS 2014)
- Convolutional Pose Machines (CVPR 2016)
- Stacked Hourglass Networks (ECCV 2016)
- Cascaded Pyramid Network (CVPR 2018)
- Simple Baselines for Human Pose Estimation and Tracking (ECCV 2018)
- High-Resolution Network (CVPR 2019)
- Bottom-up型アプローチ
-
Top-down型アプローチ
- ICCV 2019 採録論文の紹介
- おわりに
- 参考文献
前提知識
Human Pose Estimation の位置付け
Human Pose Estimation / 人物姿勢推定 は人物の映った画像や動画から人物の姿勢に関する情報を特定するタスクであり、以下のサブタスクに大別されます。
2D Pose Estimation
2D Pose Estimation は画像中の単一または複数人物の関節点の2次元座標を特定するタスクです。画像中の人物が単一である場合は推定すべき関節点の数が一定であるためそこまで難しい問題設定ではありません。しかし、推定対象が複数人物である場合、人物同士の重なり合いなどによる遮蔽が存在する環境下で不特定多数の人物の関節点座標を過不足なく推定する必要があるため、難度の高いタスクであると言えます。

Pose Tracking
Pose Tracking は映像中の複数人物を追跡しつつ、それぞれの人物の2次元関節点座標を特定するタスクで、2D Pose Estimation よりもさらにチャレンジングなタスクとなっています。今回は Pose Tracking の研究の流れの詳細については触れませんので、ここで代表的と思われる研究事例をいくつかリストアップしておきます。興味のある方は論文を読んでみて下さい。
PoseTrack: Joint Multi-Person Pose Estimation and Tracking [Iqbal et al., CVPR'17]
PoseTrackデータセットを提案するとともに、Pose Tracking のベースライン手法を提案しています。ベースライン手法ではまず動画中の全ての人物の関節点の座標を推定した後、人物関節点のノード、それらを結ぶエッジからなる時空間的なグラフを構築し、整数線形計画問題に基づく最適化を行うことでグラフを分割し、各人物の姿勢情報を含んだ追跡結果を得るというBottom-up型のアプローチを取っています(本記事で紹介するDeepCut/DeeperCutと類似したアプローチです)。
Detect-and-Track: Efficient Pose Estimation in Videos [Girdhar et al., CVPR'18]
動画の数フレームを入力とし、入力された各フレームにおける複数人物の姿勢を人物を同定した上で推定する 3D Mask R-CNN を提案しています。推定された数フレーム分の人物追跡結果をハンガリアン法を用いて時系列的に割り当てていくことにより動画全体に対する人物追跡結果を得ます。ICCV 2017 PoseTrack challenge 首位手法です。
Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields [Raaj et al., CVPR'19]
人物の関節点間の部位 (Limb) の存在を表す Part Affinity Fields、Limbの時系列的な動きをを表現する Temporal Affinity Fields を統合した Spatio-Temporal Affinity Fields を用いて人物の紐付けを行うBottom-up型のオンラインな Pose Tracking 手法を提案しました。本手法は約30fpsでの高速な推論が可能であるとともに、PoseTrackデータセットで最先端手法に匹敵する性能を達成しています。
3D Pose Estimation
3D Pose Estimation は単一または複数視点の画像や動画から人物関節点の3次元座標を特定するタスクです。ここで言う3次元座標には関節点のワールド座標、カメラ座標、腰を原点とした相対座標などが含まれ、研究の目的によって推定対象は異なります。近年CV分野全体において3D認識についての研究が注目されている流れに逆らわず、Pose Estimation においても2Dから3Dへと研究の対象が移りつつある印象を受けます。3D Pose Estimation の中でも特に盛んに研究されているのが単眼カメラを用いた3次元姿勢推定です。単眼カメラを用いる場合カメラからの関節点の奥行きが不定となるため、基本的にはカメラ座標系において人物の腰を原点としたときの各関節点の相対座標を推定する問題設定となります。

Shape Reconstruction
3D Pose Estimation が人物のスパースな関節点の座標を推定するタスクであるのに対して、Shape Reconstruction では人物表面の形状を密に推定・復元します。人物の形状は、人物モデルに基づき大まかな体系が推定される場合や、服装を含んだ詳細な形状まで推定される場合もあります。Shape Reconstruction は Pose Estimation の中でも最も新しく、かつチャレンジングなトピックであり、近年特に盛んに研究が行われています。

本記事のスコープ
今回は上記の中でも最も基本的なタスクである 2D Pose Estimation に焦点を当てて論文を紹介します。まず、代表的な研究事例を時系列順に紹介した後、2019年10月から11月にかけて開催されたコンピュータビジョンのトップカンファレンスである ICCV 2019 に採録された 2D Pose Estimation の最新論文を紹介します。近年注目されているトピックである 3D Pose Estimation、Shape Reconstruction については別の記事で紹介予定です。
関連するデータセット
2D Pose Estimation の論文では主に以下のデータセットが用いられます。この中でも近年はMPIIデータセットとCOCOデータセットを用いて評価が行われることが多い傾向にあります。AI Challenger データセットは他データセットでの評価の際に最終的なモデルの性能を引き上げるために用いられる場合や、その規模の大きさからコンペティションの際の外部データとして用いられる場合があります。
- Leeds Sports Pose (LSP) :2,000枚の単一人物画像から成るデータセット
- MPII Human Pose :約4万人物の関節点座標がアノテーションされた約2万5千枚の複数人物画像から成るデータセット
- MS COCO :約15万人物の関節点座標がアノテーションされた約6万枚の複数人物画像から成るデータセット
- AI Challenger :約70万人物の関節点座標がアノテーションされた30万枚の複数人物画像から成るデータセット
データセット毎の関節点の定義およびアノテーション例は以下のようになっています。
| LSP | MPII | MS COCO | AI Challenger |
|---|---|---|---|
| Right ankle | Right ankle | Nose | Right shoulder |
| Right knee | Right knee | Left eye | Right elbow |
| Right hip | Right hip | Right eye | Right wrist |
| Left hip | Left hip | Left ear | Left shoulder |
| Left knee | Left knee | Right ear | Left elbow |
| Left ankle | Left ankle | Left shoulder | Left wrist |
| Right wrist | Pelvis | Right shoulder | Right hip |
| Right elbow | Thorax | Left elbow | Right knee |
| Right shoulder | Upper neck | Right elbow | Right ankle |
| Left shoulder | Head top | Left wrist | Left hip |
| Left elbow | Right wrist | Right wrist | Left knee |
| Left wrist | Right elbow | Left hip | Left ankle |
| Neck | Right shoulder | Right hip | Top of the head |
| Head top | Left shoulder | Left knee | Neck |
| - | Left elbow | Right knee | - |
| - | Left wrist | Left ankle | - |
| - | - | Right ankle | - |

評価方法
2D Pose Estimation では主に Percentage of Correct Keypoints と Average Precision という評価指標が用いられます。
Percentage of Correct Keypoints
Percentage of Correct Keypoints (PCK) は単一人物姿勢推定において利用される評価指標で、MPIIデータセットでの評価の際に主にこの指標が用いられます。PCKでは、関節点の推定座標と正解座標の距離が、ある閾値よりも小さいときにその関節点の推定を正しいものとし、推定が正しく行われた割合をその評価値とします。PCKの閾値は人物頭部のサイズ(頭部外接矩形の対角線の長さ)に基づき決定されることが多く、これはPCKhと呼称されます。例えばPCKh@0.5の場合、頭部サイズの0.5倍を閾値に設定して評価を行います。
Average Precision
Average Precision (AP) は複数人物姿勢推定の評価に利用される指標で、COCOデータセットと AI Challenger データセットはこの評価指標を採用しています。APは推定姿勢と正解姿勢の類似度を表す尺度である Object Keypoint Similarity (OKS) に基づき算出されます。OKSはアノテーションされている関節点についての推定座標と正解座標の類似度の平均を表す値となっており、次式で表されます。
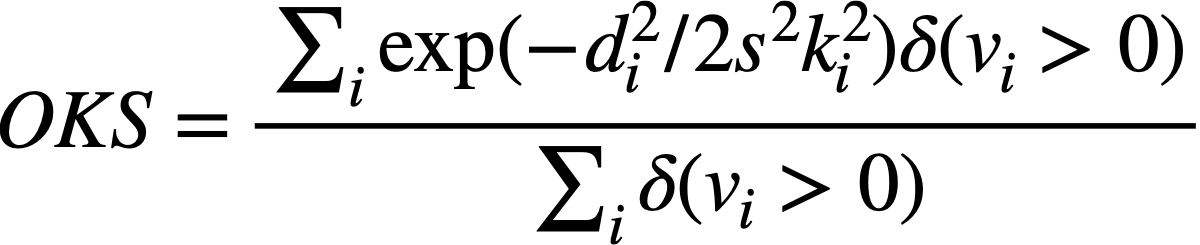
ここで、diは関節点iの推定座標と正解座標の距離、sは人物のサイズ(COCOではアノテーションされている人物領域の面積を用いる)、kiは関節点の種類毎に設定される定数(推定が難しい関節点ほど大きい値を設定する)、viは関節点がアノテーションされているかどうかを表します。OKSは人物の推定姿勢と正解姿勢が完全に一致するとき1となる、物体検出のAPでの評価におけるIoUと同じ役割を持った指標であり、APはこのOKSが閾値を上回っているとき推定結果を正解であるとみなしたときに算出される平均適合率です。COCOの場合、最終的な評価値はOKSの閾値を0.50から0.95まで10段階に変化させたときのそれぞれのAPの値を平均することにより算出されます。
代表的な研究事例
ここでは 2D Human Pose Estimation の既存手法の中でも代表的と思われる手法をピックアップし、それらをTop-down型アプローチ、Bottom-up型アプローチに大別した上でそれぞれを論文が発表された順番に紹介します。今回紹介する手法は全てディープラーニングを用いた手法になっており、ディープラーニング台頭以前の手法については紹介しませんのでご注意ください。使用している図表は紹介論文から引用したものとなります。
Top-down型アプローチ
Top-down型のアプローチでは、まず画像中の各人物を人物検出器などで検出した後、各人物の関節点座標を単一人物用の姿勢推定器を用いて推定します。人物の検出およびそれぞれの人物の姿勢推定を独立して行うシンプルな枠組みとなっており、性能の高い人物検出器を採用することで性能向上が図りやすい点、(畳み込みニューラルネットワークを用いた手法の場合)個々の人物に対する Receptive Field を大きく取ることが容易な点が主な利点です。以下で紹介する研究事例には単一人物姿勢推定を題材としたものも含まれています。
DeepPose (CVPR 2014) [1]
DeepPoseは人物姿勢推定にディープラーニングを適用した初の手法です。この手法では、畳み込みニューラルネットワーク (AlexNet) に固定サイズの画像を入力し、各関節点の2次元座標を回帰により推定します。モデルの出力は(推定すべき関節点数)× 2 次元のベクトルです。このとき、画像の中心が (x, y) = (0, 0)、画像の最も左上の座標、右下の座標がそれぞれ (-0.5, -0.5)、(0.5, 0.5) となるよう正規化された座標を推定します。そして、Mean Squared Error (MSE) をロス関数に用いてモデルを学習します。
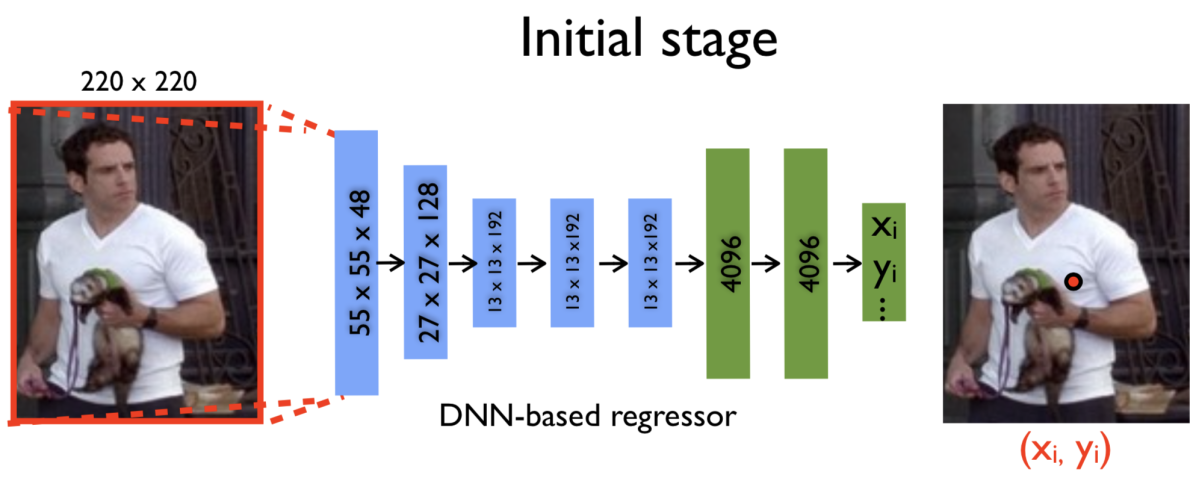
また、この論文ではモデルをカスケードさせることにより、前段ステージで推定された関節点座標をリファインする方法も同時に提案しています。前段ステージで推定された関節点座標を中心に画像をクロップし、前段ステージと同一構造かつパラメータは独立した後段ステージに入力します。後段ステージは前段ステージよりも関節点周辺の高解像度な画像を元に推定ができるため精度向上につながると論文では主張されています。各ステージの学習は第一ステージから順に独立して行います。
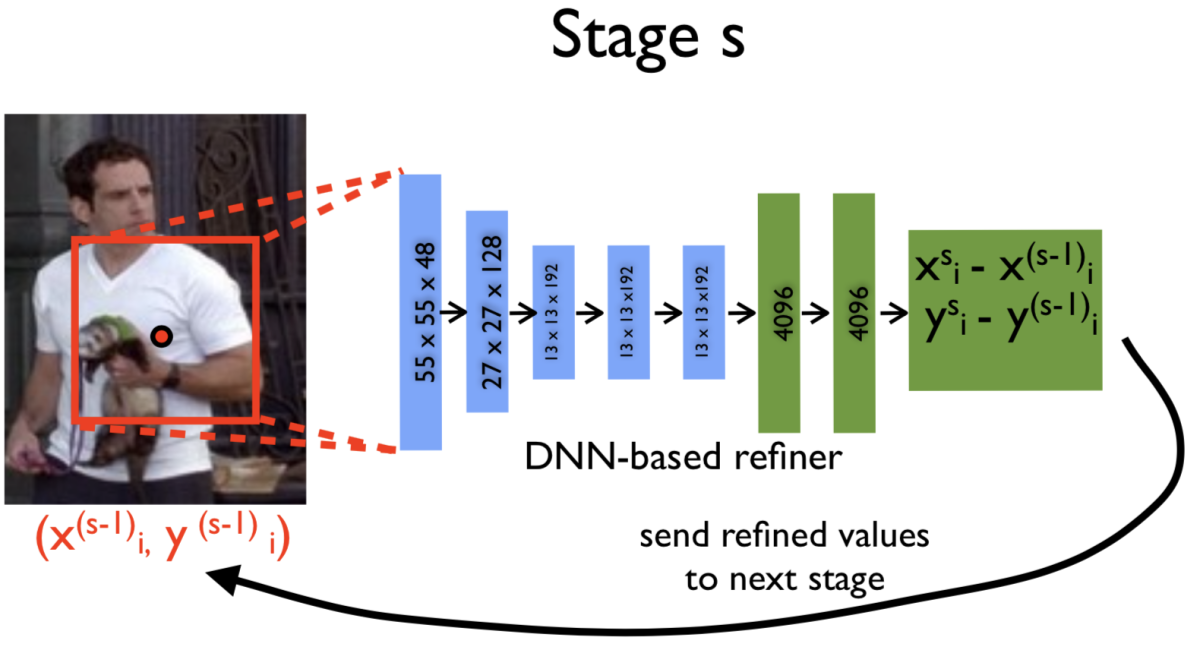
実験では最大3ステージを用いたDeepPoseの性能と既存手法の性能を比較し、カスケードの有効性を実証するとともに、既存の非ディープラーニング手法を上回る性能を達成しました。
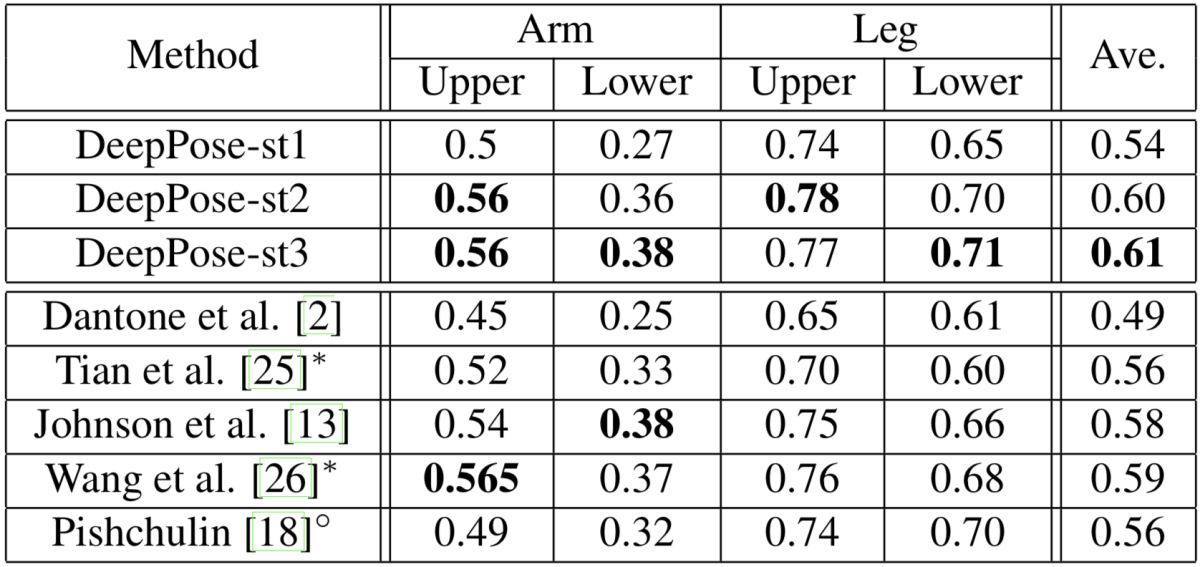
ただ、既存手法と比べた性能の向上幅はそれほど大きくなく、シングルステージの場合は既存手法に劣る性能となってしまっています。この一因として、畳み込みニューラルネットーワークが基本的に画像の位置に不変な特徴抽出を行うものであるため、画像全体を入力としての関節点座標の直接の回帰は学習が難しいことが挙げられます。
Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation (NIPS 2014) [2]
DeepPoseが関節点座標を直接回帰により推定しているのに対し、こちらの研究ではヒートマップを用いた姿勢推定手法を提案しています。モデルの出力は推定すべき関節点数と同数のヒートマップで、各ヒートマップの正解ラベルは関節点座標を中心としたガウス分布により生成されます。ロス関数にはMSEを用いてモデルを学習します。推論時はヒートマップのピーク位置を関節点の推定座標とします。近年の多くの研究でもこの論文で提案されているのと同様のヒートマップの推定に基づく関節点座標推定の枠組みが用いられており、ディープラーニングによる人物姿勢推定の基盤を確立した研究であると言えます。
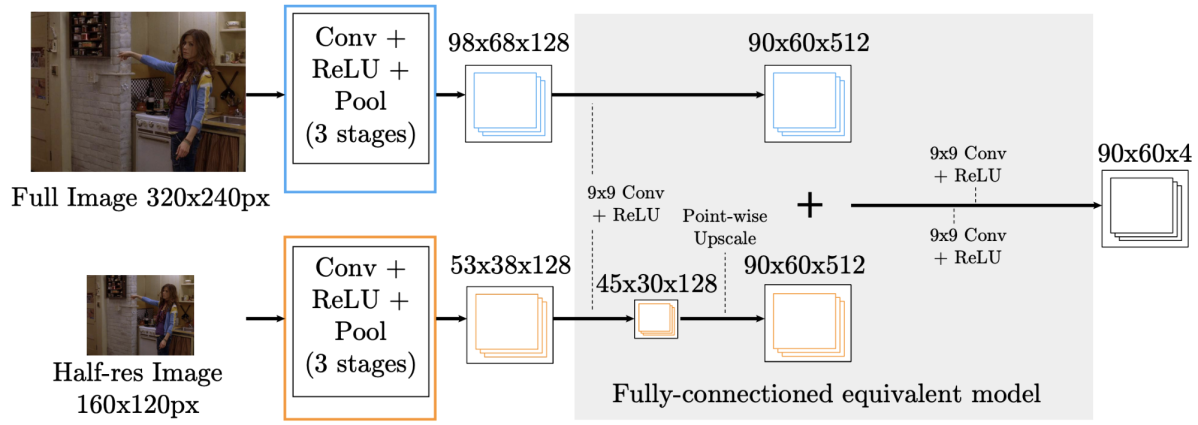
本論文ではそれ以外にも主要な主張として、グラフィカルモデルに基づき上記モデル (Part-Detector) の False Positive を削減するためのモデル (Spatial-Model) を提案し、両モデルを併用することによる性能向上を図っていますが、近年の研究ではこのような方法は用いられない傾向にあります。近年用いられるモデルは層数が増えたことにより広い Receptive Field を持ちコンテキストを捉えた推定が可能であるため、単一のモデルでも十分精度良くヒートマップを推定できることがその要因であると考えられます。
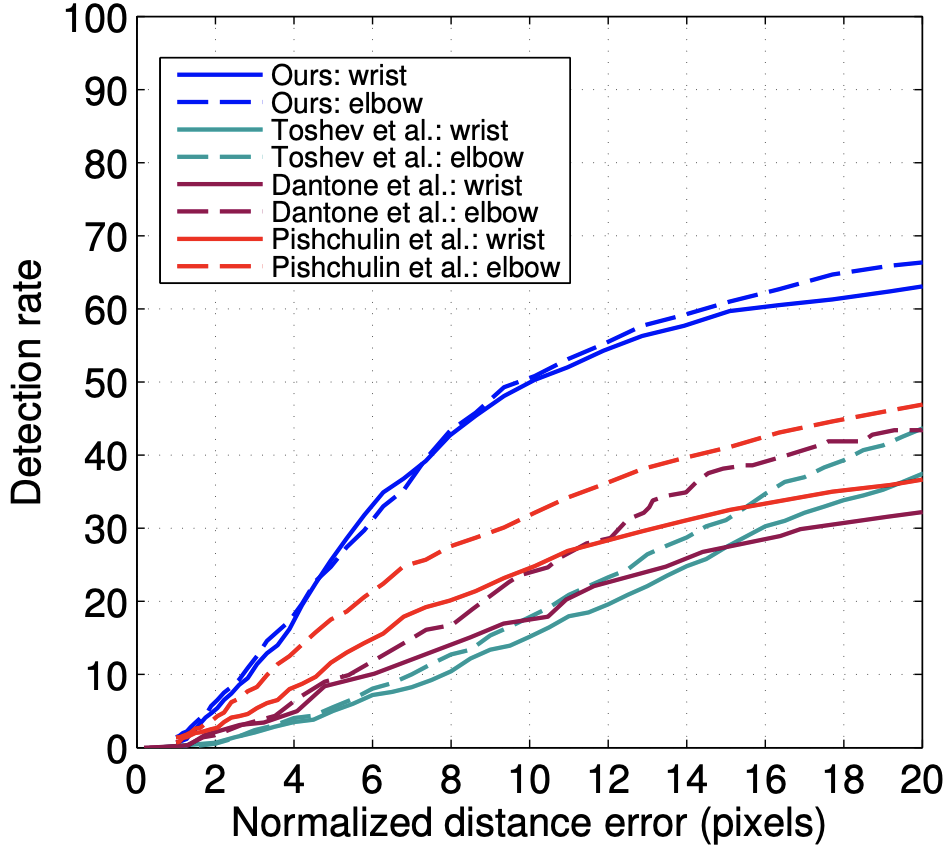
本手法はDeepPose(下図中 Pishchulin et al.)を含めた既存手法を大きく越える性能を達成し、ヒートマップに基づく姿勢推定手法の有効性を示しました。
本研究以降はヒートマップベースの姿勢推定手法が台頭し、ネットワークの構造の改良にフォーカスした研究が増えていきました。
Convolutional Pose Machines (CVPR 2016) [3]
Convolutional Pose Machines (CPM) では複数ステージからなるモデルの各ステージでヒートマップを段階的にリファインしていく、DeepPoseにおけるモデルのカスケードと似たような試みを行なっています。第一ステージは画像のみを入力に関節点毎のヒートマップを推定しますが、第二ステージ以降は特徴マップおよび前段ステージで推定されたヒートマップを入力にヒートマップを推定します。学習の際は、各ステージで推定されたヒートマップに対するMSEの合計をロスとし、全てのステージをend-to-endに学習します。このように、モデルの中間的な出力に対する教師信号の適用 (Intermediate Supervision) により、勾配消失を軽減させる効果があると論文では述べられています。また、カスケードさせた深いモデルを用いることによりモデルの Receptive Field を広げ、人物構造を暗に考慮した推定が可能になると主張されています。
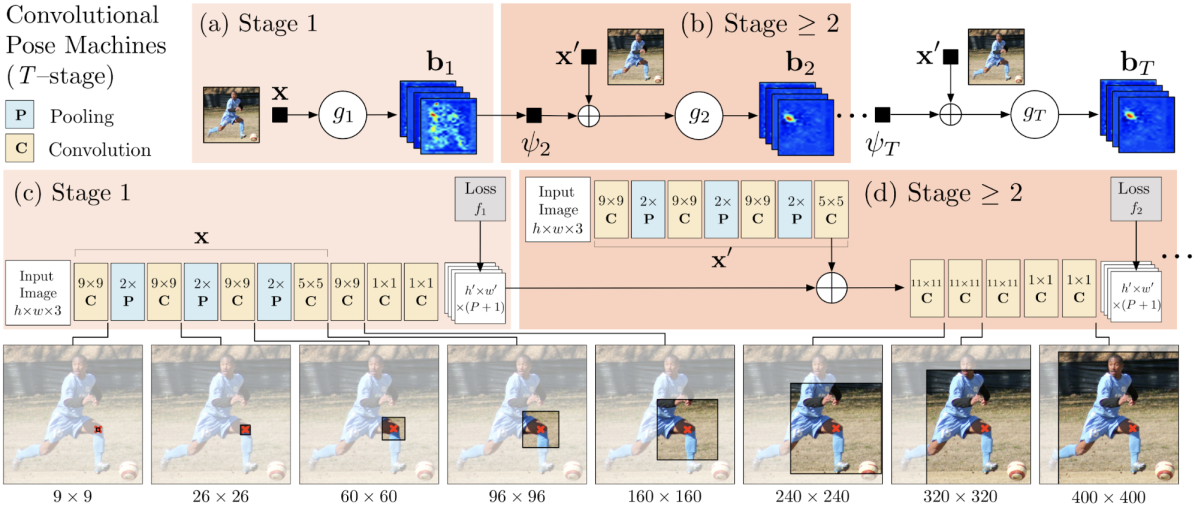
下図のように、左右の判別が難しい部位を後段ステージでは適切に推定できています。

Stacked Hourglass Networks (ECCV 2016) [4]
Stacked Hourglass Network もCPMと同様にモデル構造の改良による性能改善を図っています。このネットワークはその名の通り砂時計型の構造を持ったモジュールである Hourglass Module を複数回連ねた構造となっており、複数スケールの特徴を考慮した特徴抽出が可能であることを特徴としています。
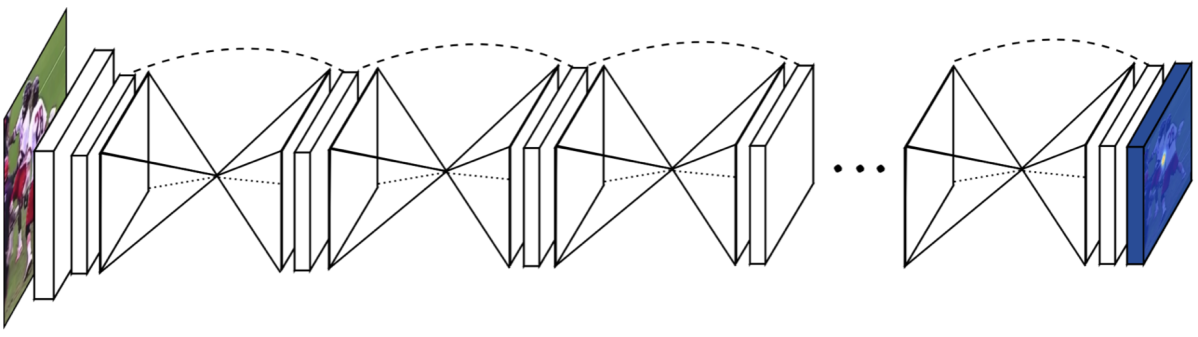
個々の Hourglass Module は下図のように、特徴抽出を行いつつ特徴マップのダウンサンプリングおよびアップサンプリングを行うEncoder-Decoder構造を持ち、アップサンプリングの際にはダウンサンプリング時の同一解像度の特徴マップを足し合わせるSkip-connectionを行います(参考までに、同じくEncoder-Decoder構造を持ったモデルであるU-Netでは特徴マップ同士の結合によるSkip-connectionを行います)。基本的な特徴抽出には Residual Module を利用し、ダウンサンプリングには Max Pooling、アップサンプリングにはニアレストネイバーを使用しています。
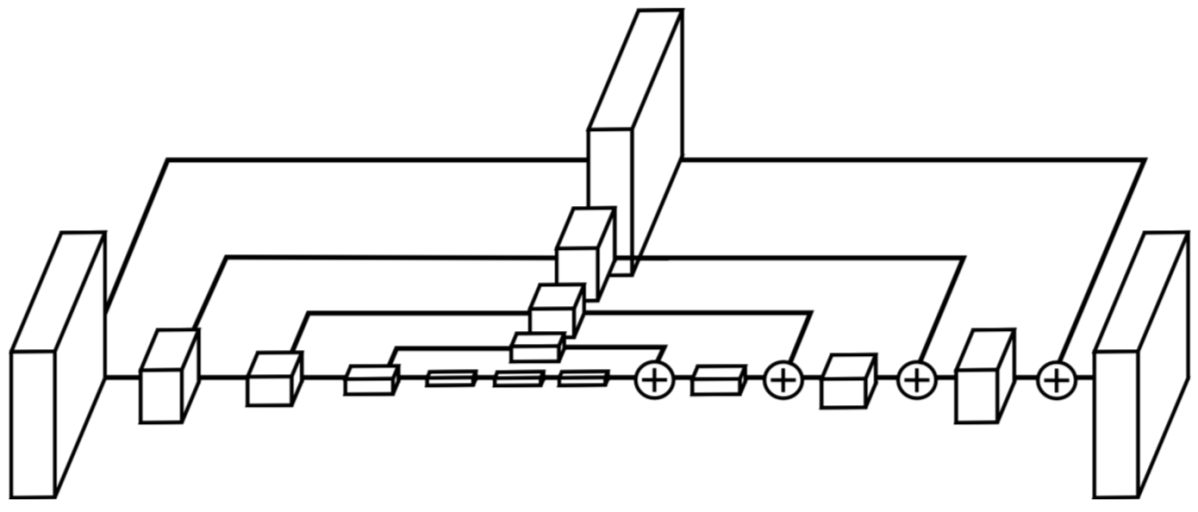
また、各 Hourglass Module の出力特徴マップからヒートマップを推定し(下図青色の部分)、CPMと同様に全ての出力ヒートマップに対するMSEの和をロスとしてモデルを学習します。
実験ではスタック数を変化させたレイヤー数およびパラメータ数が等しい複数のモデルの性能を比較し、スタック数を増やすことにより性能が向上することを示しました。
既存手法との性能比較では、Hourglass Network がCPMを含む既存手法を上回る性能を持つことを示しています。
Cascaded Pyramid Network (CVPR 2018) [5]
Cascaded Pyramid Network (CPN) はGlobalNet、RefineNetの2ステージのネットワークからなるモデルです。GlobalNetは Feature Pyramid Network [26] とほぼ同一のアーキテクチャを持ち、複数スケールの出力特徴マップそれぞれからヒートマップを推定します。一方RefineNetではGlobalNetから出力された各スケールの特徴マップを結合し、リファインされたヒートマップを推定します。ピラミッド構造のGlobalNetによるマルチスケールな特徴抽出、RefineNetにおけるそれらの統合が本モデルの肝であると言えます。
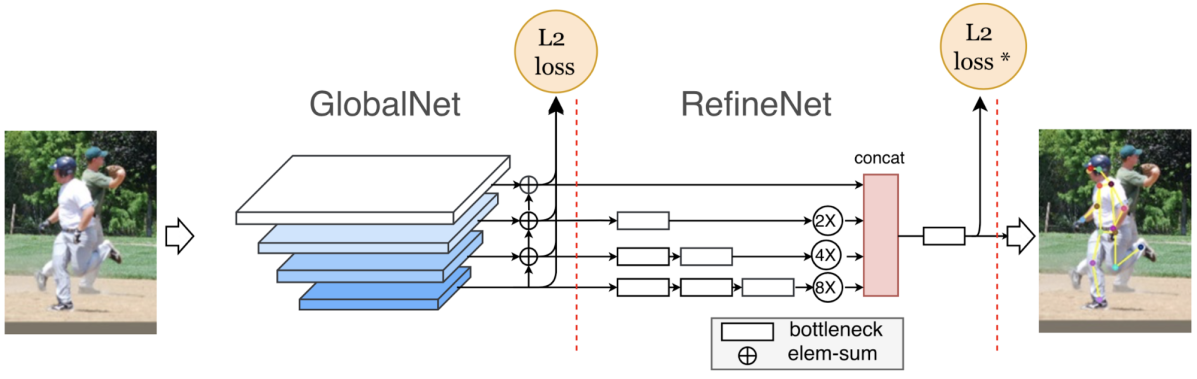
CPNはモデル構造だけでなくロスの与え方にも工夫を行なっており、GlobalNetの出力に対しては通常のL2ロスをかけますが、RefineNetの出力に対してはロスの大きい上位M個の関節点にのみL2ロスをかける Online Hard Keypoint Mining を行います。
GlobalNetとRefineNetに対するロスのかけ方を比較する実験を行い、RefineNetに対する Online Hard Keypoint Mining 適用の有効性を示しています。
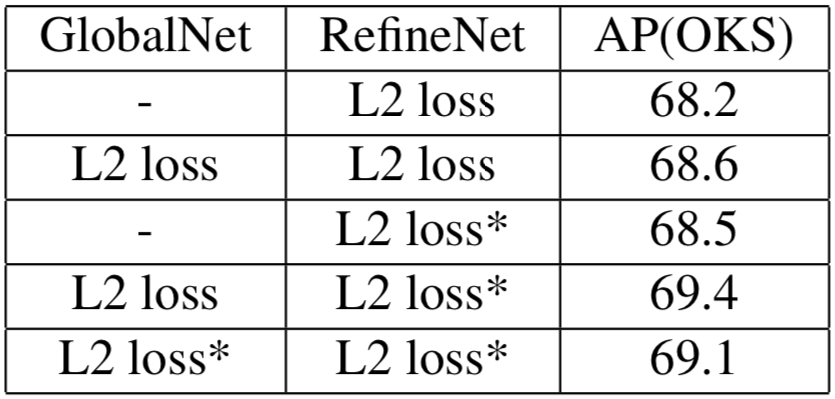
(L2 loss* は Online Hard Keypoint Mining を用いたL2ロス)
アンサンブルされた最終的なモデルは COCO test-dev set で73.0のAPを達成しています。
因みに、ECCV 2018 のワークショップコンペティションとして開催された COCO Keypoint Detection Challenge 2018 では、CPNをベースに用いた手法が首位となりました。
Simple Baselines for Human Pose Estimation and Tracking (ECCV 2018) [6]
CPMや Hourglass Network、CPNはモデルの改良により性能改善を図っていましたが、モデル構造が複雑になっていくについて、それぞれのモデルの各構成要素の性能向上への寄与度やモデル同士の対等な比較がし難くなるという問題が生じてきました。それを踏まえ、この研究では「シンプルなモデルでどれほどの性能を出すことができるのか?」を問いにベースラインとなるモデルを提案し、既存手法を上回る性能を達成しました。
提案されたモデル(下図 )はバックボーンであるResNetの出力特徴マップに複数回のDeconvolutionを行うことで関節点のヒートマップを推定する構造となっており、Hourglass Network やCPNと比べ非常にシンプルな構造となっています。ヒートマップは既存手法と同様、ガウス分布により生成し、L2ロスを用いて学習します。テスト時はFaster R-CNNを用いて人物検出を行い、検出されたそれぞれの人物に対して提案モデルで姿勢推定を行います。
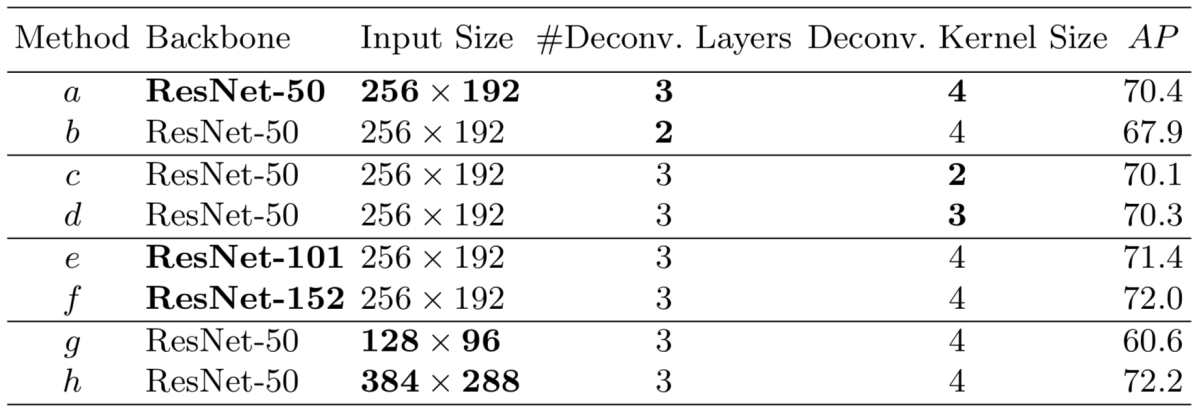
実験ではバックボーンに用いるResNetの層数、入力画像サイズ、Deconvolutionの層数およびカーネルサイズによる性能比較を行う Ablation Study を実施しました。結果は下図のようになっており、特に入力画像の大きさが性能向上に大きく寄与することを確認しました。
また、入力画像サイズが同一の Hourglass Network、CPNと性能比較を行い、本手法の性能が上回っていることを示しました(下図)。既存手法の評価値はそれぞれの論文から参照したものであるため実装の良し悪しが性能に影響をもたらしている可能性があるものの、シンプルなモデルでも既存手法と同等またはそれ以上の性能を得ることができると著者らは結論付けています。
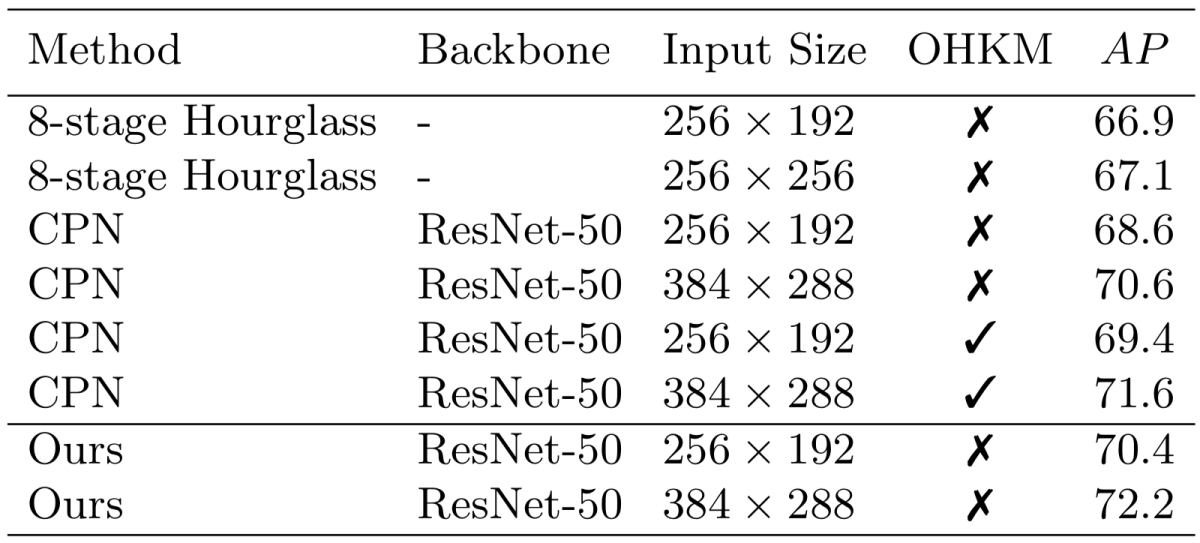
本手法が既存手法の性能を上回った理由については実装の良し悪しである可能性がある以外具体的には明記されていません。また、著者らはあくまでも本研究の目的をアルゴリズム的に優位な手法の提案ではなくベースライン手法の提案であるとしています。実装面が性能に与える影響の大きさ、また適切なベースライン設定の重要性を感じさせられる研究となっています。
High-Resolution Network (CVPR 2019) [7, 8]
High-Resolution Network (HRNet) は Simple Baseline と同一著者らにより発表され、Simple Baseline をベースにモデル構造を改良したものとなっています。
HRNetについては過去のブログ記事や CVPR 2019 の論文調査資料でも解説がありますので、よろしければそちらも併せてご覧ください。
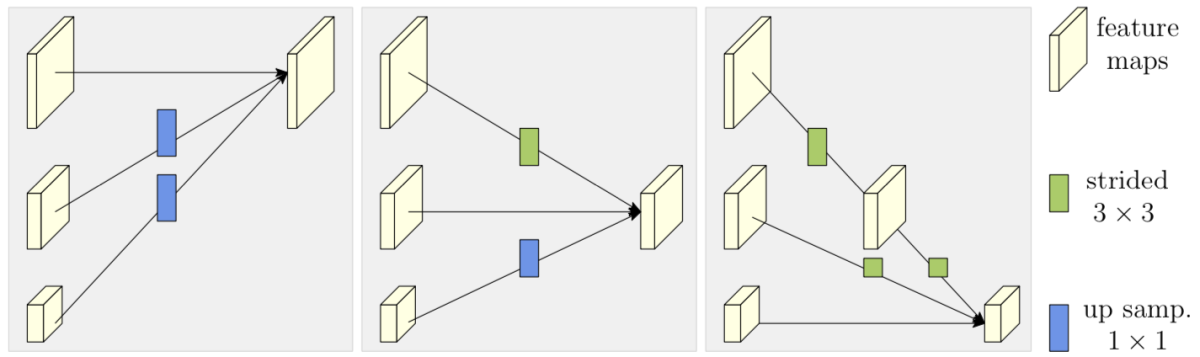
Hourglass Network やCPN、Simple Baseline などの従来のモデルは、一度特徴マップを縮小した後、Deconvolutionやアップサンプリングなどにより特徴マップを拡大することで入力画像のサイズに対して小さすぎない(1/8から1/4程度の)ヒートマップを出力する構造を取っていました。それに対してHRNetは高解像度な特徴マップを保持したまま平行して低解像度な特徴マップを生成していき、それぞれのブランチで特徴抽出を行います。そして、Exchange Unit でのそれぞれのブランチの特徴マップ間での相互な情報のやりとりを複数回に渡り行うことでよりリッチな特徴表現が獲得される構造となっています。

Exchange Unit では下図のように、出力特徴マップのスケールと同一スケールの特徴マップは恒等写像、低解像度な特徴マップはニアレストネイバーによるアップサンプリングを行なった後で 1x1 Convolution、高解像度な特徴マップは複数回のカーネルサイズ3の Strided Convolution を行なった後でそれぞれの特徴マップを足し合わせることで複数ブランチの情報を集約します。各ブランチでの特徴抽出とそれらの統合を複数回に渡り行なった後、最も高解像度な特徴マップを持つブランチからヒートマップを推定します。
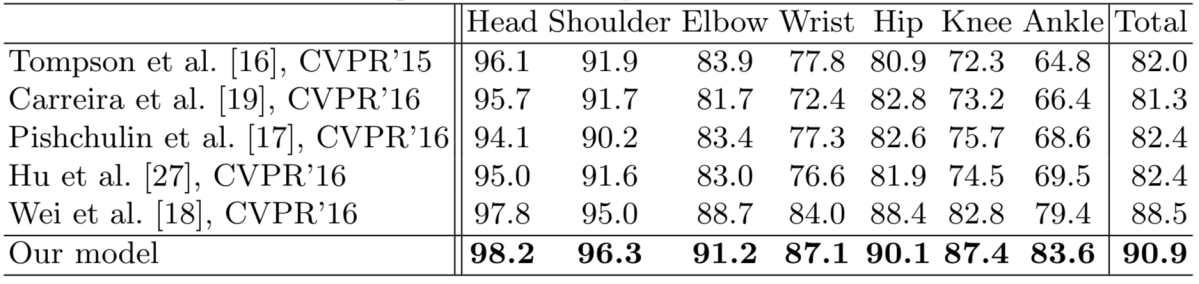
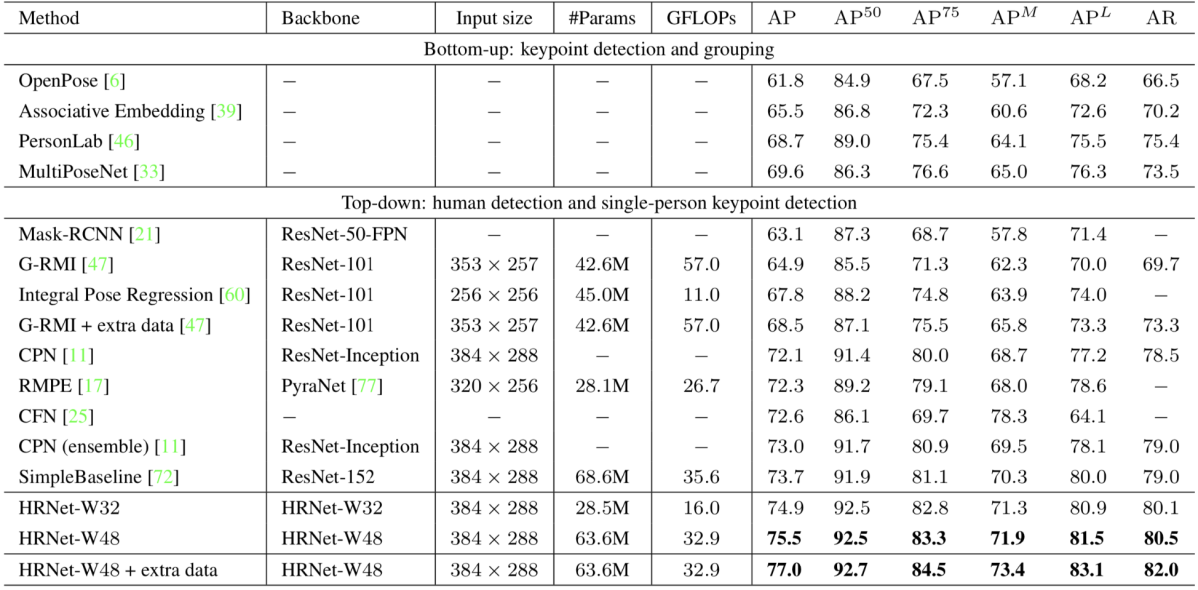
実験では Simple Baseline を含めた既存手法との性能比較を行い、下図のようにいずれの既存手法をも上回る性能を達成しました。AI Challenger データセットを外部データとして用いたときの COCO test-dev set に対するAPは77.0と、非常に高い性能となっています。大きく話題になったOpenPoseの評価値が61.8であることを見ても、その性能の高さが分かるかと思います。
HRNetは姿勢推定だけでなくクラス分類や領域分割、物体検出など様々なタスクのバックボーンとして有効であることが確認されている [8] と共に、既にHRNetを改良 [9]、または転用 [10] した多くの派生研究が存在しています。
Bottom-up型アプローチ
ここまではTop-down型アプローチの研究事例を紹介しましたが、ここからはもう1つの代表的なアプローチであるBottom-up型アプローチの研究事例について紹介します。
Bottom-up型手法では画像中の全ての人物の関節点座標を人物を区別せずに検出した後、それらを人物毎にグルーピングすることにより複数人物の姿勢を推定します。一度のモデルの順伝播で画像中の全ての人物の関節点を検出するため、Top-down型手法と比べ画像中の人物数が増加しても推論速度が落ちにくいという利点があります。Bottom-up型手法では検出した関節点のグルーピングをどのように行うかがアルゴリズムの肝となっており、その点に着眼した研究が数多く存在します。
DeepCut (CVPR 2016) [11] / DeeperCut (ECCV 2016) [12]
DeepCut/DeeperCutはディーブラーニングを用いたBottom-up型姿勢推定の先駆け的な手法です。これらの手法では画像中の人物関節点を人物を区別せずに検出した後、関節点をノードと見なし、それらを全結合するエッジを作成することによりグラフを構築します(下図左)。グラフの人物毎の部分グラフへの分割、関節点ノードの種類のラベリングを整数線計画問題に基づく最適化により行うことで、人物毎の姿勢推定結果を得ます(下図中央、右)。

DeeperCutはDeepCutに対し、主に以下の3点の改善を行っています。
- バックボーンをVGGからResNetに変更することによる関節点検出モデルの改善
- 画像特徴を用いることによるコスト関数の改善
- 最適化を体の部位毎に段階的に行うことによる速度・精度改善
これらの手法では関節点候補の検出を畳み込みニューラルネットワークを用いて行なっていますが、最適化の際に用いるコスト関数は主に関節点ペアの距離や角度などの幾何的な関係に基づいたものであり、ディープラーニングにより得られる特徴を十分に活用しきれていないと言えます。また、最適化の計算コストが高く、Bottom-up型手法の利点である関節点検出の高速性を相殺してしまっているという欠点があります。
OpenPose (CVPR 2017, TPAMI 2019) [13, 14]
OpenPoseは高速かつ高精度な人物姿勢推定手法として一時期大きく話題となった手法で、ご存知の方も多いと思います。この手法の一番の特徴は関節候補点のグルーピングの手がかりとなる Part Affinity Fields (PAFs) を畳み込みニューラルネットワークで推定することで、これにより高性能な関節点のグルーピングが可能となる共に、処理コストの低い簡素なグルーピング方法の利用が可能となり、高速に動作するアルゴリズムとなっています。
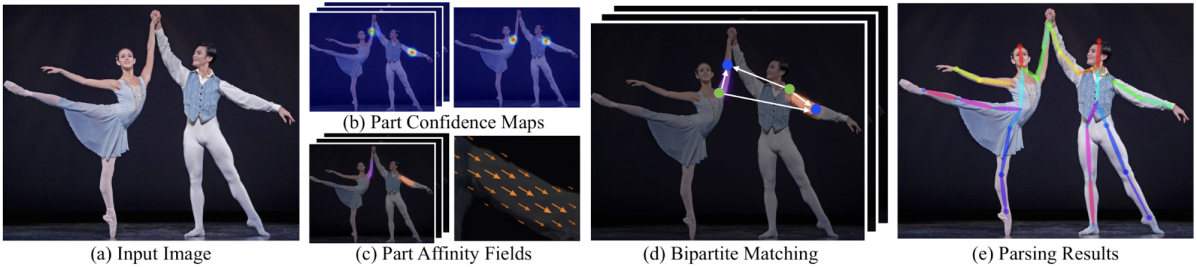
モデルは下図のようにCPMと類似したステージ構造を持ち、各ステージからヒートマップおよびPAFsを推定します。ヒートマップの正解ラベルはTop-down型手法と同様に関節点を中心としたガウス分布により生成されます。PAFは対応関係にある関節点ペア間の部位 (Limb) の存在を表す2次元ベクトル場で、対応関係にある関節点ペア間の矩形内において一方の関節点からもう一方の関節点へと向かう単位ベクトル、それ以外の領域では零ベクトルとして生成されます。よって、モデルの推定対象は関節点と同数のヒートマップとLimbと同数のPAFとなります。学習時はヒートマップ、PAFsに対する全てのステージでのMSEの和をロスとしてモデルを学習します。
推論時はまず、モデルにより推定されたヒートマップの極大点から関節候補点を検出します。次に、対応関係にある全ての関節点ペア間のPAF上で線積分値を求め、それらをそれぞれの関節点ペアを結びつける確信度と見なします。この確信度が大きい関節点ペアから順に結びつけていく工程を関節点ペアの種類毎に行なっていくことにより最終的な人物毎の姿勢推定結果が得られます。
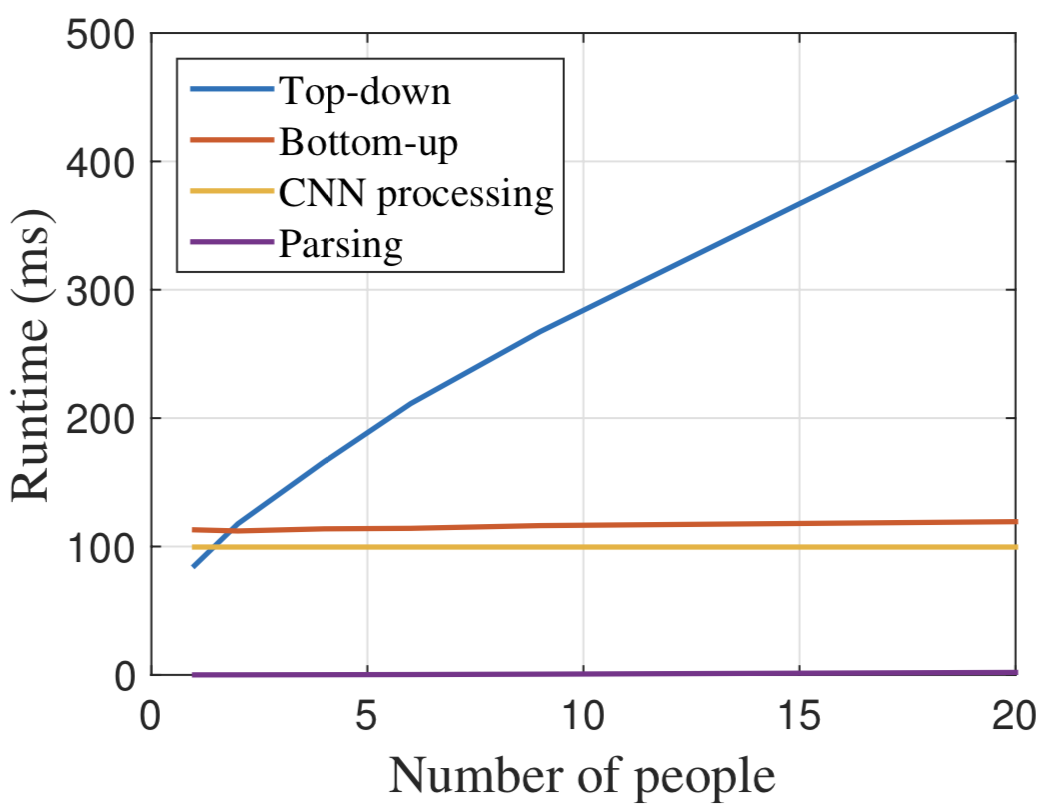
実験ではTop-down型手法であるCPMと処理速度の比較を行い、CPM(下図中Top-down)では画像中の人物数に比例する形で処理時間が増加しているのに対し、OpenPose(下図中Bottom-up)は人物数が増加してもほぼ一定の処理速度(654 × 368 の画像に対して約9fps)で推論ができることを確認しました。
Associative Embedding (NIPS 2017) [15]
Associative Embedding は姿勢推定における関節点のグルーピングやインスタンスセグメンテーションにおけるピクセルのグルーピング問題を埋め込み表現を用いて解決しようと試みた研究です。本研究では姿勢推定とインスタンスセグメンテーションそれぞれに対する手法を提案していますが、ここでは姿勢推定手法についてのみ説明します。

本手法では Hourglass Network を用いて各関節点のヒートマップおよびEmbeddingマップを出力します。Embeddingマップは人物のアイデンティティ情報を持った1次元ベクトルのマップとなっており、同一人物の各関節点の位置に対応するEmbeddingマップの値同士が近くなり、画像中の異なる人物の関節点のEmbeddingマップの値同士が遠くなるようロスをかけます。これにより、Embeddingの値の近さが関節点ペアを結び付ける際の指標となります。
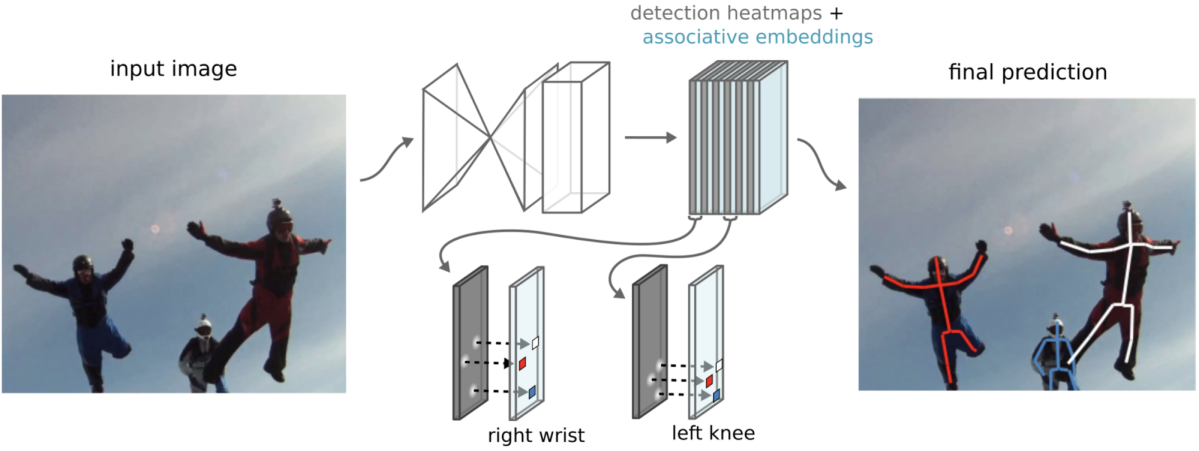
推論時はOpenPoseと同様のグリーディな割り当てをEmbeddingの値の近さに基づき行うことで人物毎の姿勢推定結果を得ます。Embeddingを多次元にすることも可能ですが、性能に大きな違いは見られなかったことが論文で述べられています。
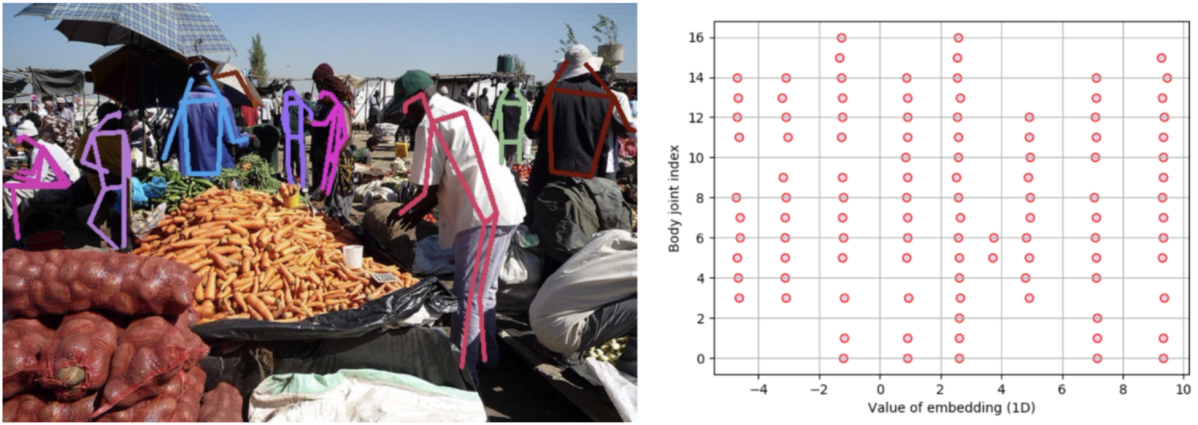
人物毎の各関節点のEmbeddingの値の推定結果は下図右のようになっており、(それぞれの点がどの人物のものであるのか図からは判別できないものの、)人物毎にEmbeddingの値が分離されるようモデルが学習されていることが分かります。
PersonLab (ECCV 2018) [16]
PersonLabは人物姿勢推定とインスタンスセグメンテーションを同時に行うことのできるBottom-up型手法で、各ピクセルからの関節点のオフセット推定(回帰)を特徴とした手法です。ここでは人物姿勢推定の部分についてのみ説明します。
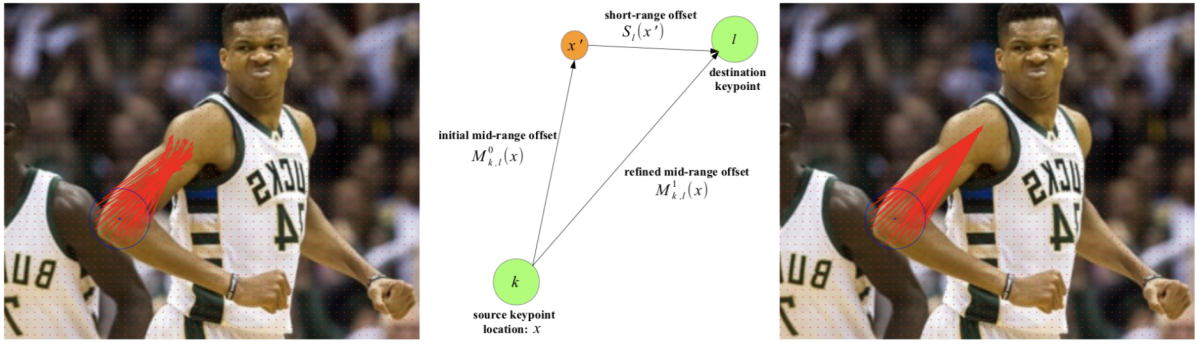
手法の枠組みは下図のようになっており、姿勢推定に必要となるモデルの推定対象はヒートマップ、Short-range offsets、Mid-range offsets の3つです。ヒートマップは Keypoint Disk と呼ばれる関節点を中心とした半径一定の円内において1、それ以外の領域では0の値をとるバイナリのマップで、Binary Cross Entropy ロスを用いて学習します。Short-range offset は各関節点種の Keypoint Disk 内において、その関節点の座標を回帰する2次元ベクトル場で、L1ロスを用いて学習します。Mid-range offset は各関節点種の Keypoint Disk 内において、その関節点と対応関係にある関節点の座標を回帰する2次元ベクトル場で、Short-range offset と同様にL1ロスで学習します。
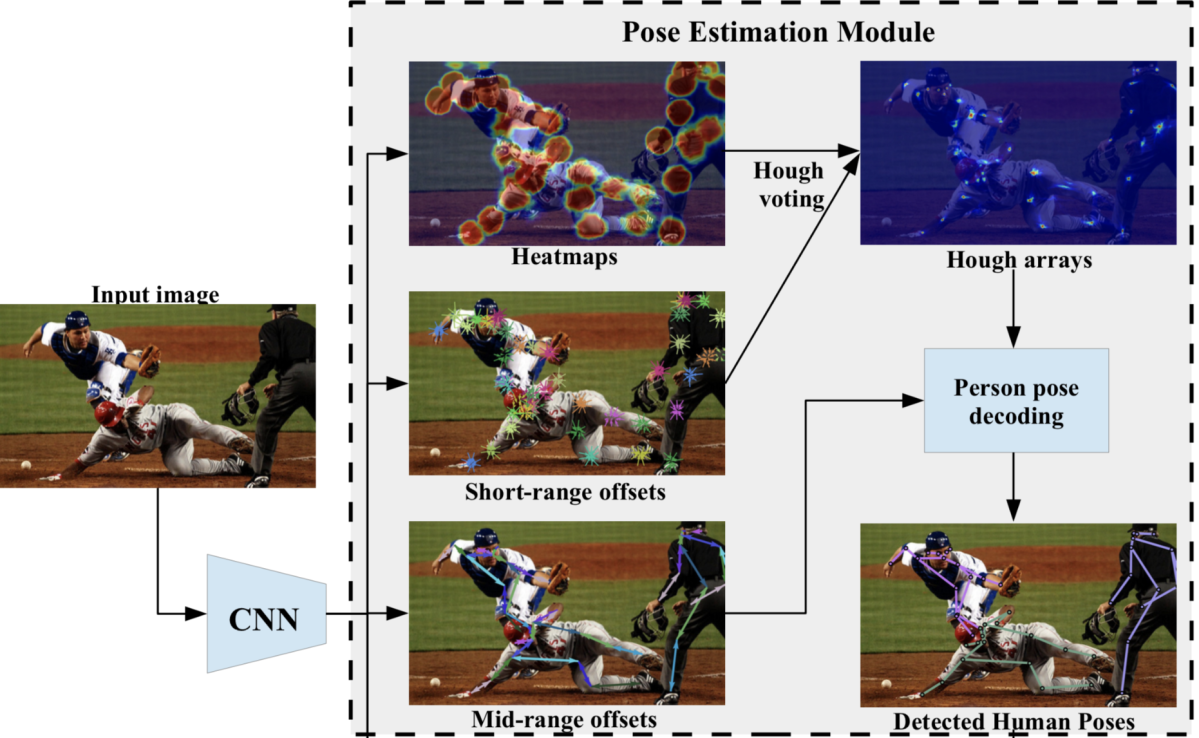
推論時はまずヒートマップと Short-range offsets を用いたハフ投票により関節点毎のスコアマップを求め、スコアマップの極大点から関節候補点を検出します。次に、スコアマップの値が大きい関節候補点から順に Mid-range offset を用いてグリーディに関節点を割り当てていくことにより人物毎の姿勢推定結果を得ます。このとき、下図のように Short-range offset を足しこむことによりリファインされた Mid-range offset を用いることで割り当ての性能改善を図っています。
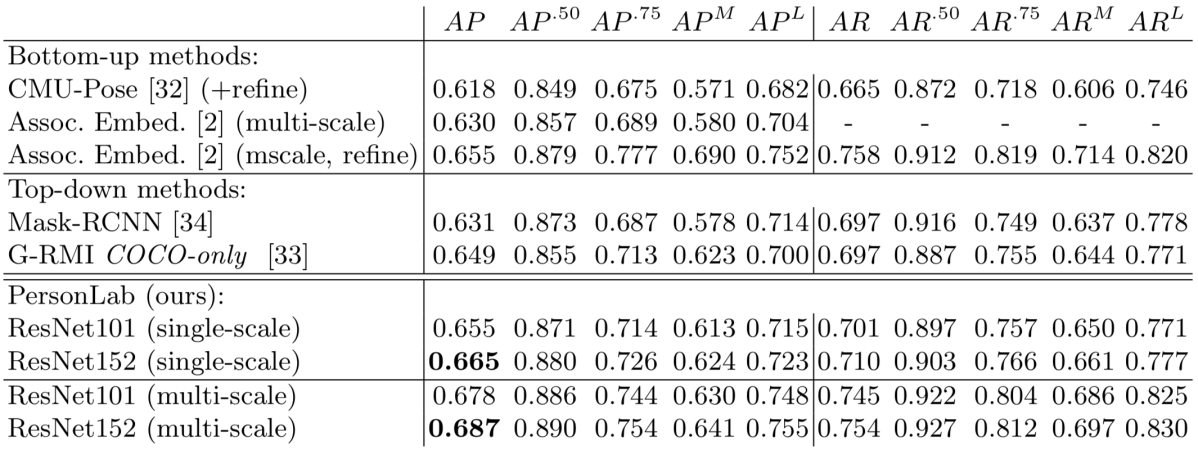
PersonLabは姿勢推定とインスタンスセグメンテーションのマルチタスク学習を行なっているため対等な比較ではないものの、OpenPoseや Associative Embedding を含む既存のBottom-up型手法を上回る性能を達成しています。
本手法は 801 × 529 の画像に対して約3fpsで姿勢推定およびインスタンスセグメンテーションを行うことが可能です。
ICCV 2019 採録論文の紹介
ここからは ICCV 2019 に採録された 2D Pose Estimation に関する論文を紹介します。私の集計した限りでは、当該トピックでの採録論文はここで紹介する4本のみとなっています。
TRB: A Novel Triplet Representation for Understanding 2D Human Body (Oral) [17]
要約
人物の姿勢および輪郭を表現する Triplet Representation for Body (TRB) を定義し、 TRB推定のためのベースライン手法を提案しました。また、TRBを生成モデルの条件に用いることで人物形状の操作ができることを示しました。
提案内容
Triplet Representation for Body
既存の人物姿勢の表現方法である Skeleton Keypoints は人物の姿勢情報を持っていますが、人物の形状情報に欠けるという欠点があります。一方で、Semantic Human Parsing Representation や DensePose Surface-based Representation は人物の形状情報を持つものの関節点座標の姿勢情報を欠いています。また、3次元人体モデルは人物の姿勢および形状双方を表現することができますが、アノテーションにモーションキャプチャシステムが必要であり、アノテーションコストが非常に高いという欠点があります。
上記を踏まえ、本研究では人物の姿勢および形状を表現可能かつアノテーションの容易な Triplet Representation for Body (TRB) を提案しています。TRBは下図のように従来の Skeleton Keypoints に加え、それらの近傍の人物と背景の境界点である2点の Contour Keypoints からなっており、人物の姿勢、形状両方の情報を持った表現方法となっています。

TRB-Net
本研究ではTRB推定手法であるTRB-Netも同時に提案しています。TRB-NetはTop-down型のアプローチを用いており、下図のように人物領域をクロップした画像を入力とし、Skeleton Heatmap と Contour Heatmap を複数ステージからなるモデルで推定する構成となっています。論文には詳細が不明瞭な箇所も多いため、モデルの詳細については要点を絞って紹介します。
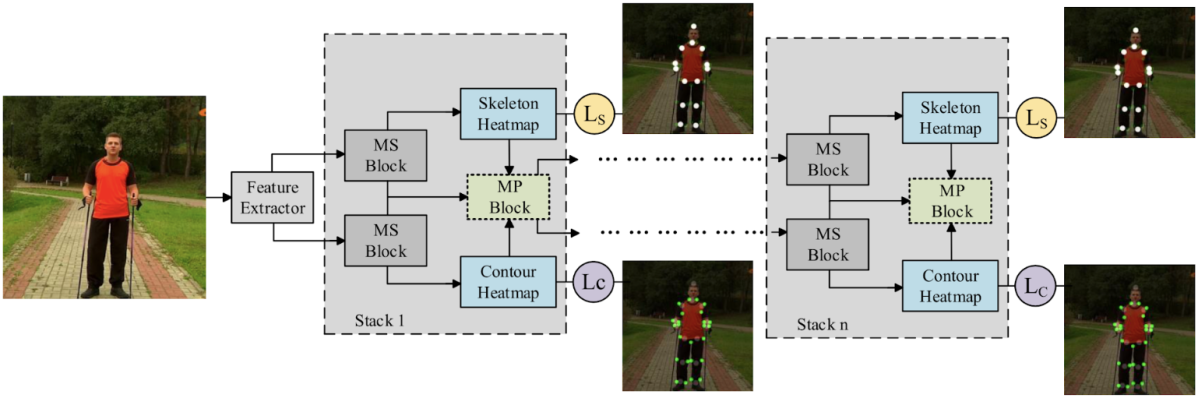
まず、それぞれのモジュールでは2つのブランチの Multi-scale Feature Extraction Block (MS Block) を用いて Skeleton Heatmap および Contour Heatmap を推定します。基本的には推定されたヒートマップに対してL2ロスをかけることによりモデルを学習します。Message Passing Block (MP Block) はそれぞれのブランチ間で相互に情報のやりとりをすることによりヒートマップをリファインするためのブロックで、以下の3つのモジュールを挿入可能です。
- X-structured Message Passing Block
- Directed Convolution Unit
- Pairwise Mapping Unit
X-structured Message Passing Block (Xs MP Block) は下図のようなモジュールで、それぞれのヒートマップに 1x1 Convolution をかけた後特徴マップを結合し、リファインされたヒートマップを推定します。
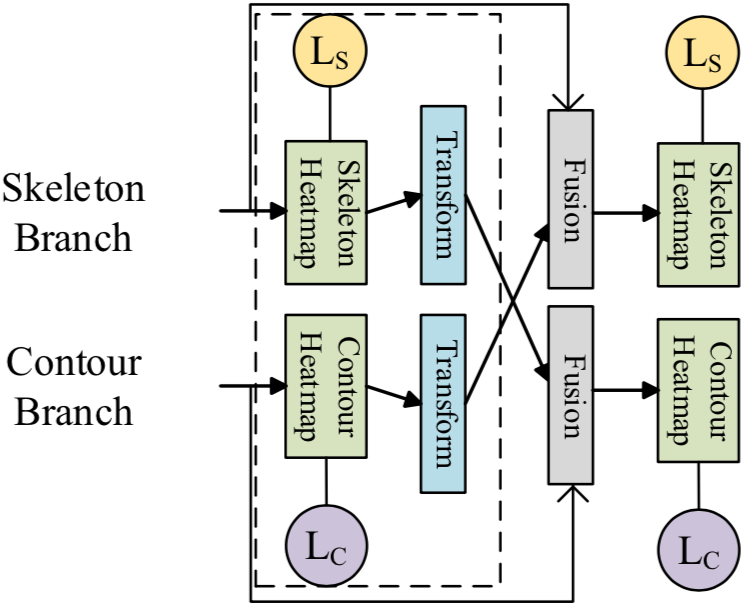
Directed Convolution Unit (DC Unit) は Xs MP Block における Contour Heatmap 推定に Scattering Convolution を、Skeleton Heatmap 推定に Gathering Convolution を用いたモジュールとなっています。
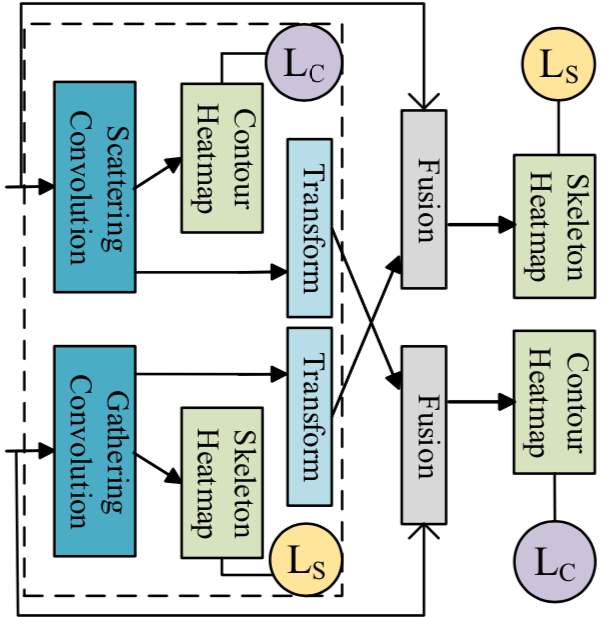
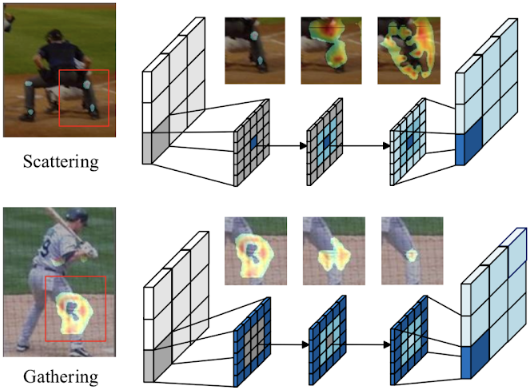
Scattering Convolution と Gathering Convolution は本論文で提案されている Directional Convolution と呼ばれるものの一種で、Skeleton Heatmap では関節点を中心に、Contour Heatmap では関節点の周囲に出るそれぞれのヒートマップの位置合わせを目的に使用しています。Directional Convolution では重みを共有した畳み込みを複数回行いますが、その際に特徴マップにおいて値が更新される位置を Scattering Convolution の場合は内側から外側、Gathering Convolution の場合は外側から内側の順となるよう固定します。
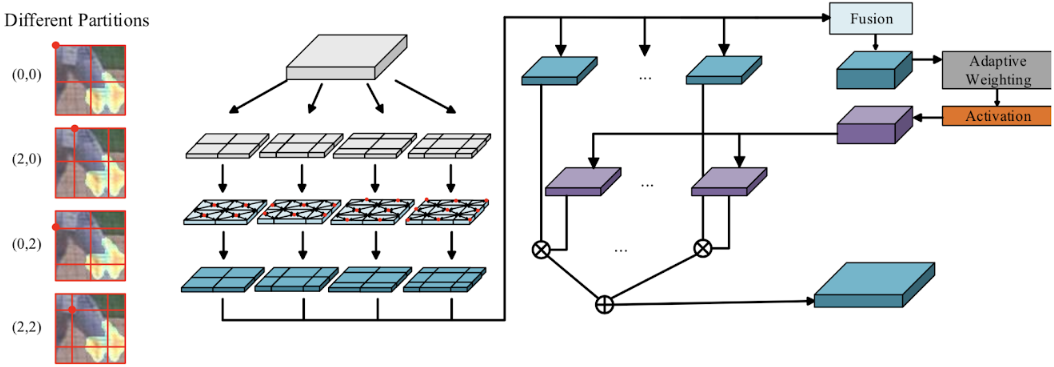
Directional Convolution は下図のようにヒートマップを異なるパターンのグリッドに分割した上で並列して適用し、それらを統合したものを最終的な出力とします。このとき、それぞれの畳み込み結果を結合させた特徴マップから各特徴マップの重みをシグモイド関数を適用することで出力し、その値を用いた各グリッドの特徴マップの重み和により出力が得られます。
Pairwise Mapping Unit (PM Unit) は推定される Skeleton Keypoints と Contour Keypoints の一貫性を高めるためのモジュールで、下図のような構造となっています。このモジュールではそれぞれのブランチから変換関数の推定およびそれを用いたヒートマップの変換を行います(詳細は不明)。ヒートマップの変換はあるKeypointのヒートマップからその近傍のSkeleton/Contourヒートマップを推定するように行い、L2ロスをかけ両者を近づけるようモデルを学習します。
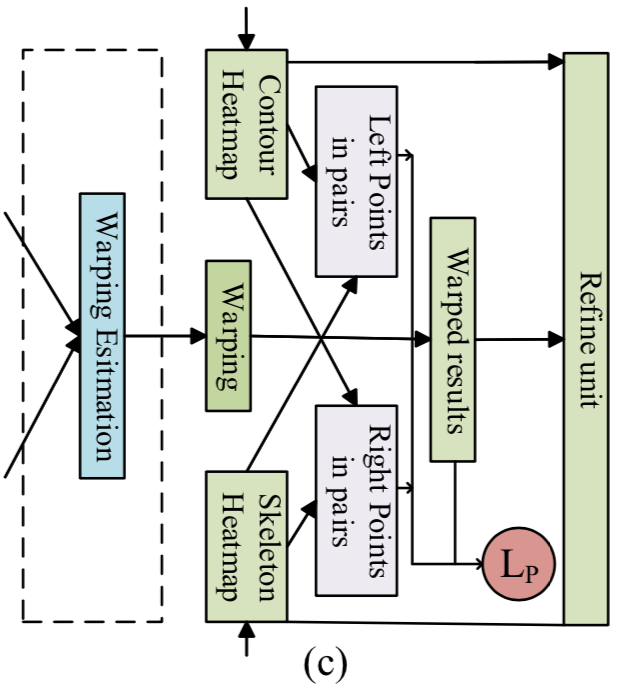
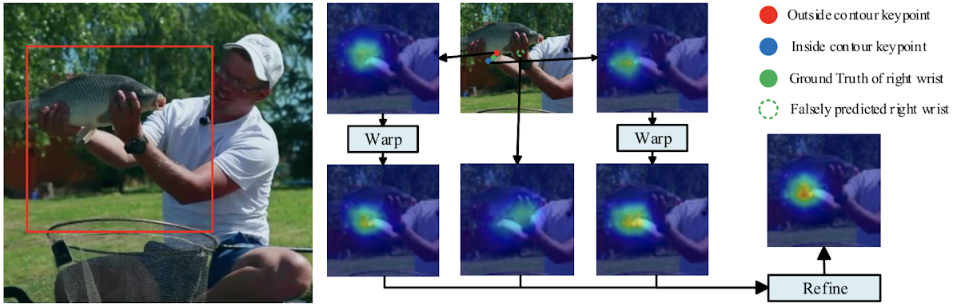
推論時は変換されたヒートマップと変換対象のヒートマップを統合することにより、リファインされたヒートマップを推定します。下図は誤って推定された右手首のヒートマップがContourヒートマップを用いることで修正されている例になります。
実験結果
本研究では実験に際してMPII、LSP、COCOの3つのデータセットに対してTRBをアノテーションすることによりTRBデータセットを構築しています。また、TRB推定の評価には元のデータセットと同一の評価指標を用いています。
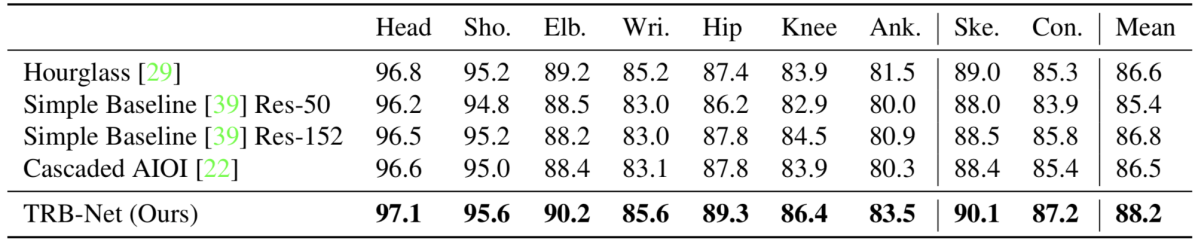
まず、既存の姿勢推定手法をTRBを推定できるよう拡張した上で、TRB-Netとの性能比較を行なっています。Contour Keypoints は Skeleton Keypoints と比べ推定が難しいことを確認すると共に、TRB-Netが既存手法よりも優れた性能を持つことを確認しています。
Directed Convolution に関する Ablation Study では、SkeletonヒートマップとContourヒートマップのマルチタスク学習の有効性、Xs MP Block の有効性、通常の畳み込みに対する Directional Convolution の優位性を確認しています。

Pairwise Mapping に関する Ablation Study では、ヒートマップの初期の推定結果を用いた場合(下表中stack1-c、stack2-c)と比べ、PM Unit によりリファインされたヒートマップを用いることにより性能が向上することを示しています(下表中stack1-f、stack2-f)。また、DC Unit と PM Unit を併用したときに最も性能が向上することを確認しました。

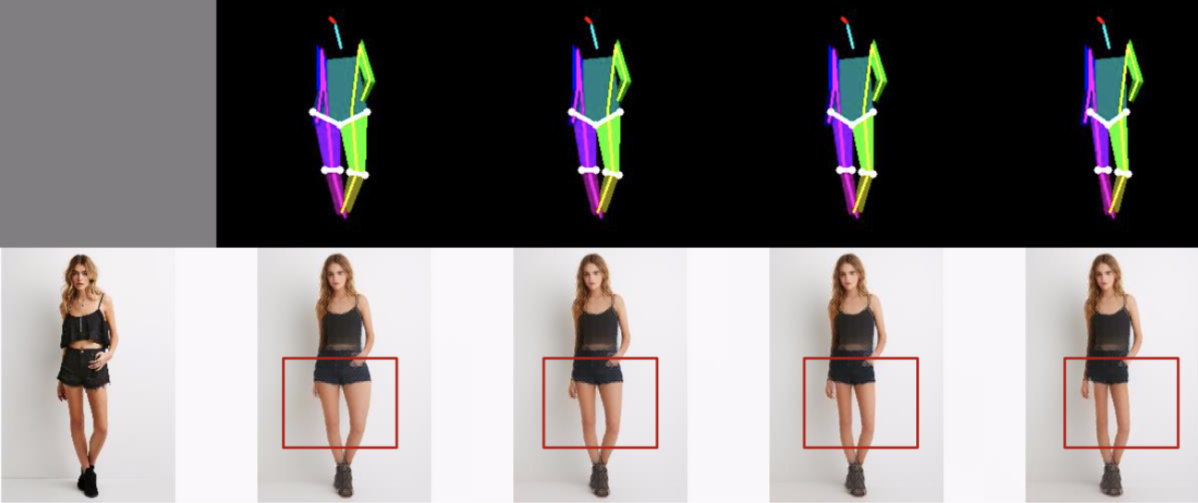
TRBの応用事例としてTRBを条件とした条件付き画像生成を挙げており、Variational U-Net を用いてTRBを変化させたときの生成画像を確認しています。下図のように、TRBを操作することにより人物形状を操作した画像生成が可能です。
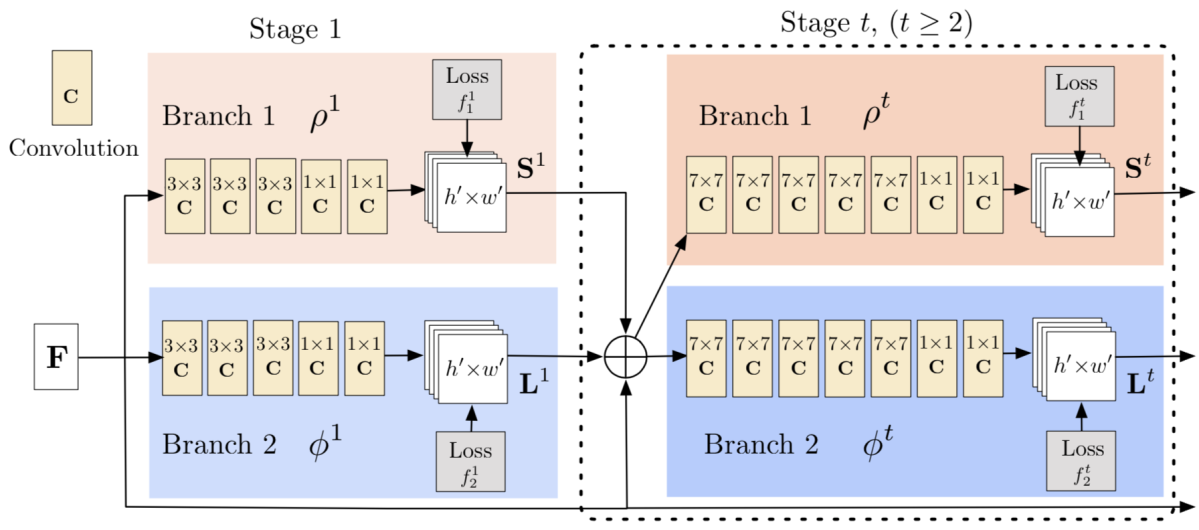
Single-Network Whole-Body Pose Estimation [18]
要約
OpenPoseを拡張した単一のネットワークによる全身(Body, Face, Hand, Foot)のポーズ推定手法を提案し、既存手法と比べ高速かつ高精度な全身のポーズ推定を実現しました。
提案内容
モチベーション
本研究の目的は全身のポーズ推定を高速かつ高精度に行うことです。その際に問題となるのが全身のポーズに関するアノテーションを持ったデータセットが存在しないことであり、Body、Face、Hand、Footなど体の各部位に関するアノテーションを持ったデータセットを組み合わせてモデルを学習する必要があります。体の部位毎のモデルを独立して学習すれば全身のポーズ推定を達成することが可能ですが、計算コストが高くなるという問題があります。そのため、本研究では単一のモデルを用いた全身のポーズを推定に取り組んでいます。
提案システム
提案されたモデルは下図のようになっています。基本的なポーズ推定の枠組みはOpenPoseに基づいており、各キーポイントに対するヒートマップおよびLimbに対する Part Affinity Fields (PAFs) を推定するモデルを学習します。推定対象であるヒートマップおよびPAFsは全身のポーズを推定できるよう、体の各部位に関するものを結合させたものとなっています。その際、モデルの学習方法や構造に複数の変更を加えることにより性能改善を図っています。
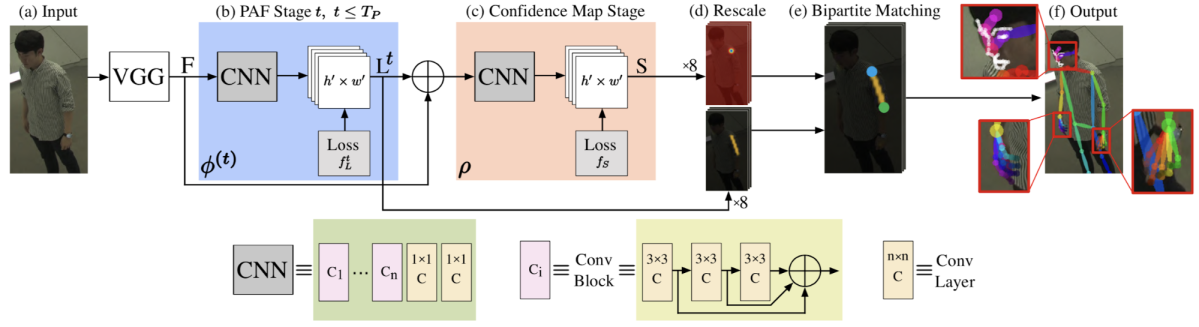
学習データのサンプリング
前述したように全身のポーズのアノテーションを持ったデータセットは存在しないため、モデルを単一のデータセットで学習することができません。そのため、各部位に関するデータセットから一定の確率で学習データをサンプリングしてミニバッチを作成します。学習の際は学習サンプルのデータセットに関連する部位のみでロスを計算し、モデルを学習します。
データセットによるデータ拡張方法の変更
下図のようにデータセットによって各部位の写り方が異なっており、Bodyデータセットでは顔、手などの解像度が低く、Faceデータセットでは顔が大きく写るなどの傾向があります。そのためデータセット毎にデータ拡張時のスケールを調整することでそれぞれのデータセットからデータをサンプリングしたときの各部位のスケールが大きく乖離しないようにしています。

(a) Handデータセット (b) Bodyデータセット (c) Faceデータセット
モデル構造の改善
OpenPoseのモデル構造に以下のような変更を加えています。
- 入力サイズを 368 × 368 から 480 × 480 に変更
- PAFsを推定するブランチの畳み込み層を増やすことによる Receptive Filed の拡大、チャネル数の増加、ステージ数の削減による計算コスト調整
その他の改善
上記以外にも以下のように複数の改善を行なっています。
- 顔、手に関するヒートマップのガウシアンの広がりを小さくする
- 顔、手、足の False Positive の多さを解決するため、Bodyデータセットで人物が存在しない領域ではそれらの部位に対してロスを与える
- 人物が写っていない画像を学習に利用する
- Face, Handデータセットではアノテーションされていない人物が存在するため、Mask R-CNN を用いてそれらをマスクする
実験結果
Body、Foot、Face、Handそれぞれのデータセットを用いて各部位の認識性能を既存手法と比較する実験を行っています。下表において、Shallowはアーキテクチャ改善前のモデル、Deepはアーキテクチャ改善後のモデルです。
Body、Footデータセットでの評価実験では、提案手法の性能はOpenPoseと同等程度の性能となりました。

Faceデータセットでの実験では、OpenPose、提案モデルどちらも実験室環境のデータセットであるFRGGとMulti-PIEに過学習しており、in-the-wildなデータセットであるi-bugに対する性能が低い傾向にあります。提案手法はよりチャレンジングなi-bugにおいてOpenPoseの性能を上回っています。

Handデータセットでの実験では、よりチャレンジングなMPIIにおいてOpenPoseを大きく上回る性能を達成しました。

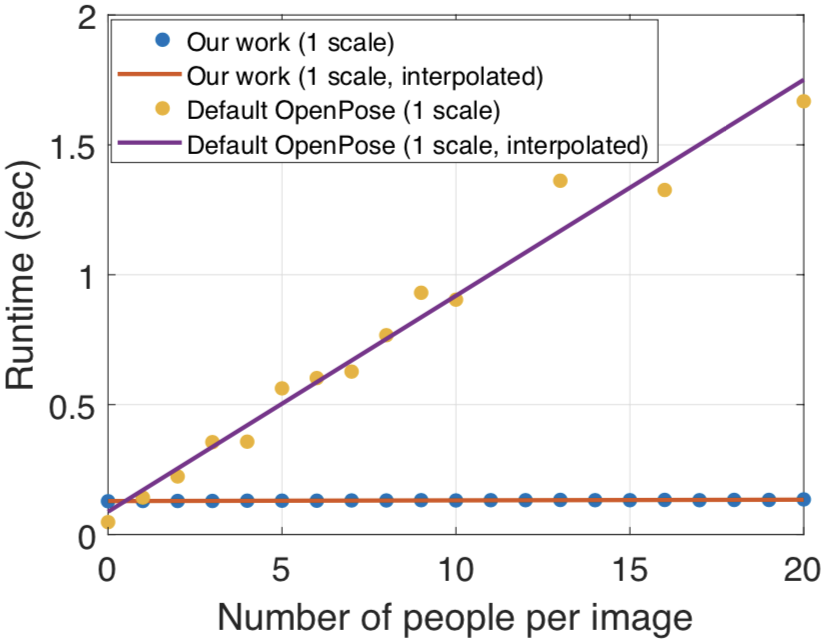
最後に、提案手法とOpenPoseの全身のポーズ推定の速度比較を行っています。OpenPoseは画像中の人物数が増えると顔や手の推定に時間がかかるため人物数に比例する形で処理時間が増加していますが、提案手法は人物数が増加してもほぼ一定の時間で推定ができるていることが分かります。
Single-Stage Multi-Person Pose Machines [19]
要約
Root Joint の推定と Root Joint からその他Jointへのオフセット推定に基づくSingle-stage型の姿勢推定手法である Single-stage multi-person Pose Machine (SPM) を提案し、精度および速度の両面でBottom-up型の既存手法を凌駕しました。
提案内容
モチベーション
人物を検出してからそれぞれの人物の姿勢推定を行うTop-down型手法、関節候補点を検出してからそれらをグルーピングするBottom-up型手法はどちらも二段階の枠組みになっており、十分に効率的ではないと本論文では述べてられています(個人的にはBottom-up型手法における関節点のグルーピングはアルゴリズムによっては処理コストが非常に低くボトルネックにはならないと考えています)。それを踏まえ本研究では、画像中の全ての人物の姿勢を一段階の枠組みで推論するSingle-stage型の姿勢推定手法を提案しています。Single-stage型の既存手法であるCenterNet [20] との差分については後述します。
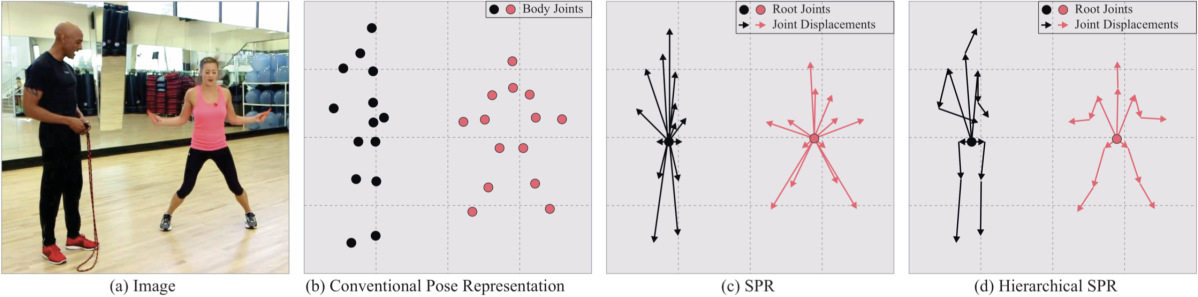
Structured Pose Representation
既存のアプローチでは、人物姿勢は人物毎の各関節点の座標により表現されていました。それに対して本研究では人物姿勢を人物毎の Root Joint と、Root Joint から各関節点への変位によって表現する Structured Pose Representation (SPR) を提案しています。さらに、SPRを Root Joint を起点とする階層的構造にした Hierarchical SPR を提案し、モデルに取り入れています。
Single-stage multi-person Pose Machine
提案手法である Single-stage multi-person Pose Machine (SPM) のパイプラインは下図のようになっています。このモデルではSPRに基づき、各人物の Root Joint、Root Joint から各関節への変位を推定します。Hierarchical SPR を用いる場合、この階層表現において隣接関係にある関節点ペアの変位をそれぞれ推定します。
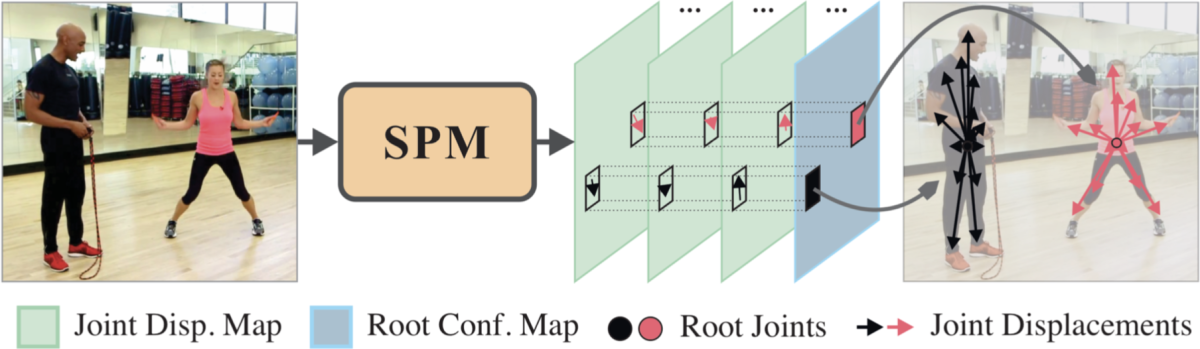
モデルの推定対象は Root Joint Confidence Map とDense Displacement Maps の2つです。Root Joint Confidence Map は Root Joint を中心としたガウス分布に従い生成されるヒートマップです。Dense Displacement Maps は SPR / Hierarchical SPR において隣接関係にある関節点ペアの一方の関節点を中心とする円内からもう一方の関節点の座標を回帰する2次元のマップです。学習時は Root Joint Confidence Map に対するL2ロスと Dense Displacement Maps に対する smooth L1 ロスを重み和してモデルを学習します。
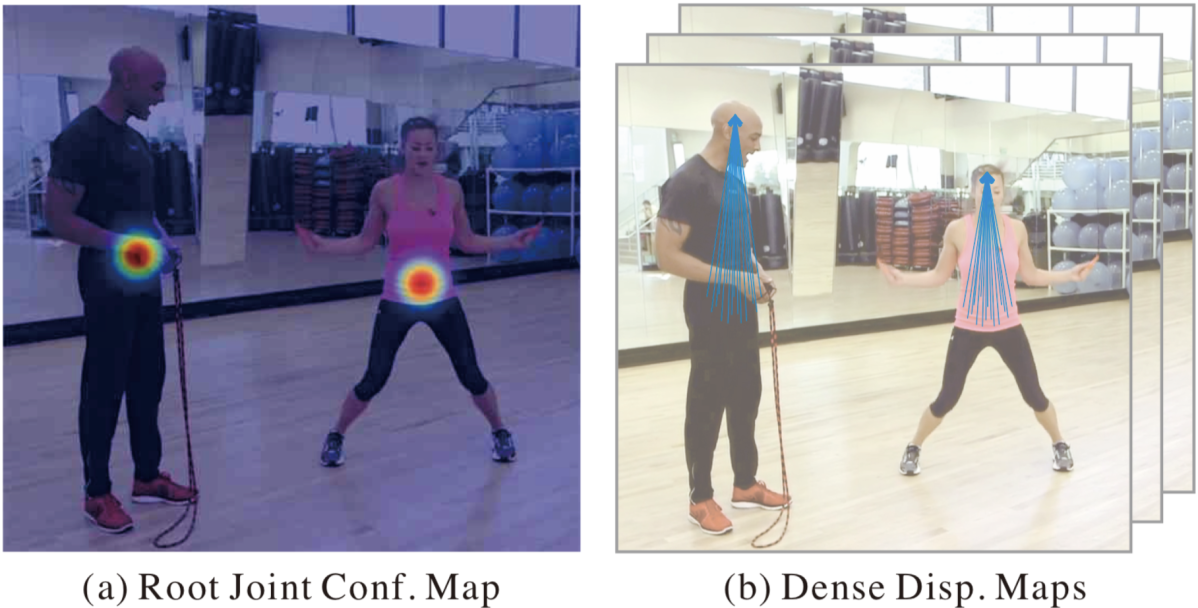
推論時は Root Joint Confidence Map から各人物の Root を検出した後、Dense Displacement Maps を用いて SPR / Hierarchical SPR において隣接関係にある関節点ペアを順番に結び付けていきます。
Single-stage型の既存手法であるCenterNetは人物矩形の中心点から各関節点を回帰する本手法と類似した手法ですが、本手法は以下の点でCenterNetと異なっています。
- Hierarchical SPR を用いて階層的に関節点ペア間の変位を推定する
- CenterNetが人物矩形の中心点のみにL1ロスをかけるのに対し、本手法では関節点を中心とする円内にL1ロスをかける
実験結果
MPIIデータセットで SPR / Hierarchical SPR の性能を比較する Ablation Study を行い、Hierarchical SPR がSPRと同一の処理速度で高い性能を持つことを確認しました。Hierarchical SPR は特に手首や足首など腰から離れた関節点においてSPMよりも優れた性能を示しており、階層的な関節点のオフセット推定の有効性を示す結果となりました。

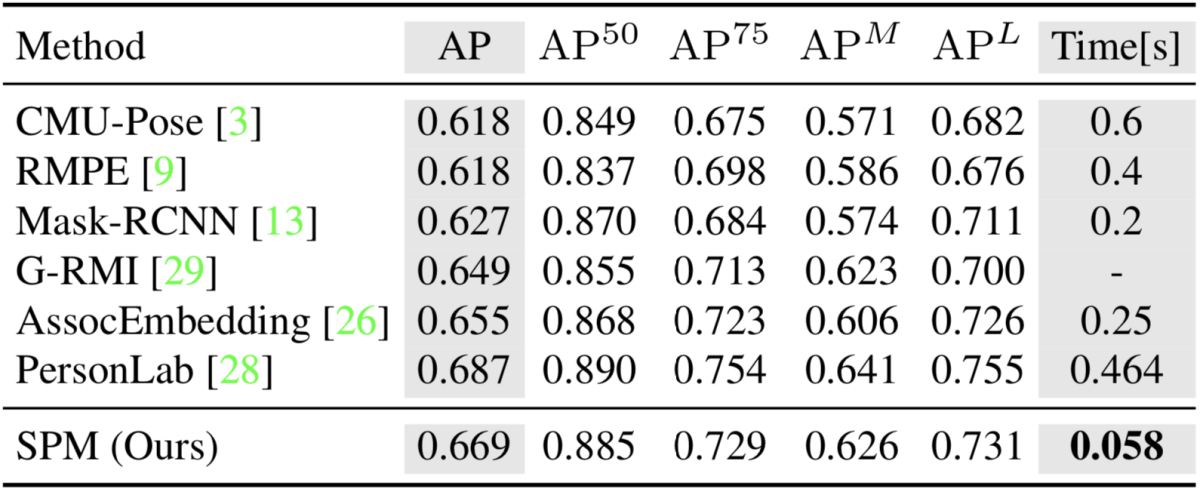
また、COCOデータセットでSPMとBottom-up型の既存手法の精度、速度を比較する実験を行い、SPMが両面において既存手法を上回ることを示しました。特に速度面では比較手法の中で最も高速な Associative Embedding よりも4倍以上高速な約17fpsでの推論が可能です。
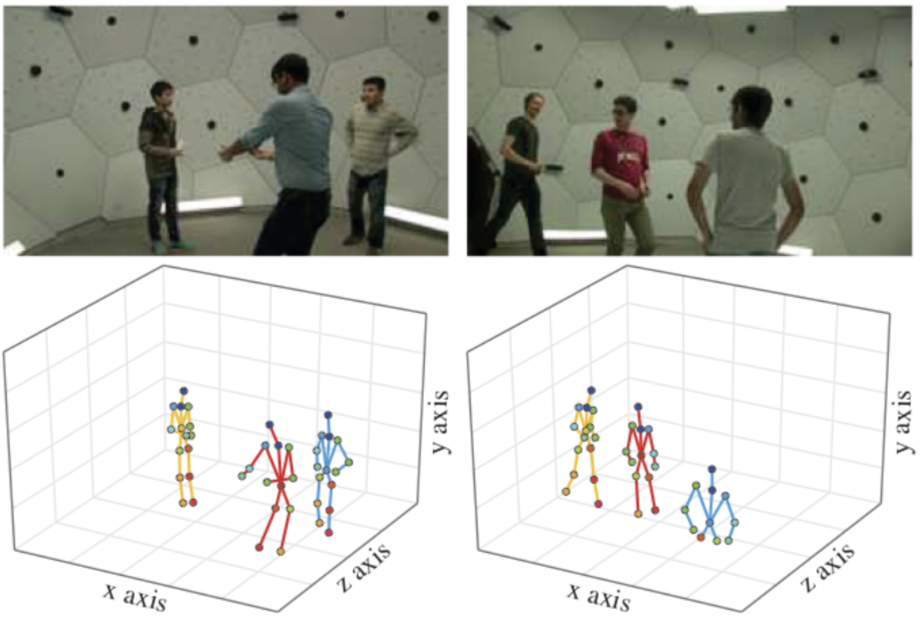
本手法は3次元姿勢推定にも適用可能であり、CMU Panoptic データセットでの複数人物3次元姿勢推定において77.8%の3D-PCKを達成しました。推定結果例は下図のようになっています。
Dynamic Kernel Distillation for Efficient Pose Estimation in Videos [21]
要約
動画ベースの単一人物姿勢推定において、毎フレームに対して規模の大きなモデルを用いるのは非効率的でした。それを踏まえ、前フレームのヒートマップからカーネルを算出し、現在フレームの特徴マップにそれを畳み込むことにより現在フレームのヒートマップを得る Dynamic Kernel Distillation (DKD) と呼ばれるモデルを提案し、軽量なバックボーンを用いても高精度な推定ができることを示しました。また、DKDの学習に Temorally Adversarial Training を導入することで、時系列的に一貫したカーネルの導出および姿勢推定を可能としました。
提案内容
モチベーション
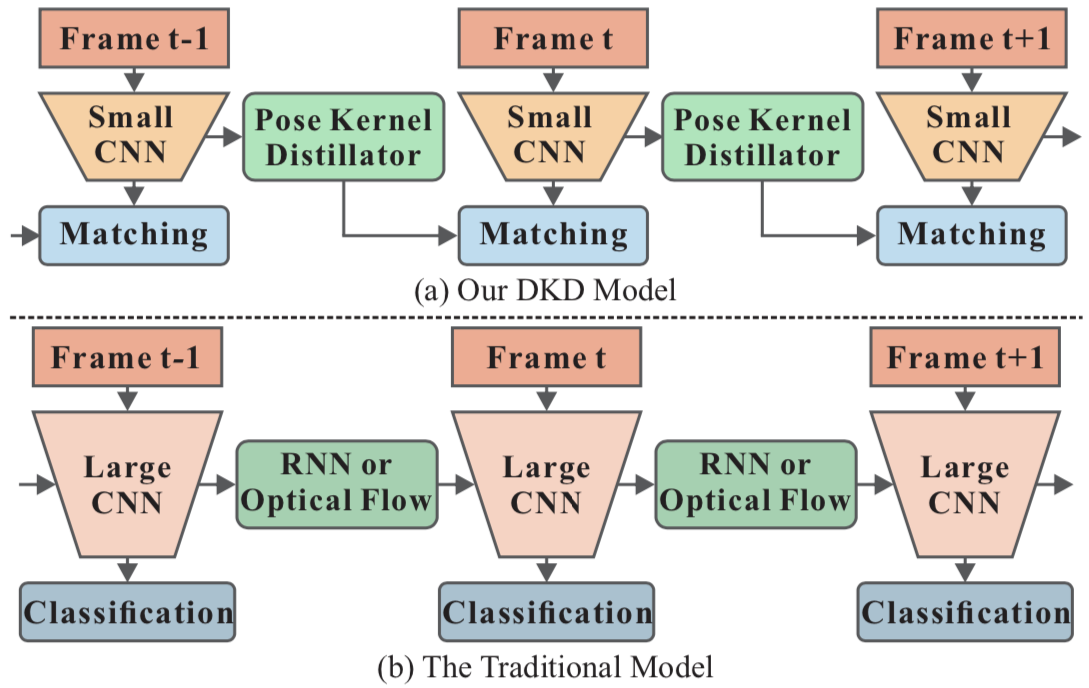
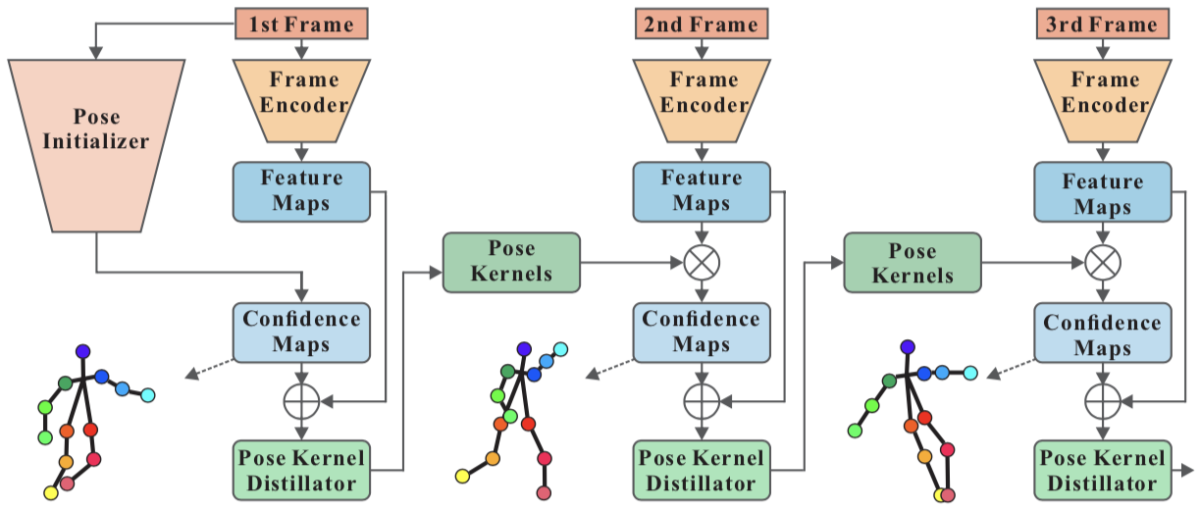
既存の動画ベースの姿勢推定手法では下図 (b) のように動画の毎フレームに対して規模の大きなモデルを用いて推定を行い、RNNや Optical Flow などによる時系列情報を活用していましたが、このような枠組みは計算コストが高く非効率的でした。それを踏まえ、本研究では下図 (a) のように小規模なモデルを用いて入力フレームから特徴抽出を行い、Pose Kernel Distillator により得られたカーネルと次フレームのヒートマップのマッチング(= 畳み込み)を行うことにより次フレームのヒートマップを得ます。提案手法である Dynamic Kernel Distillation (DKD) は小規模なモデルを用いた特徴抽出、カーネルの畳み込みによる時系列情報の活用を行う効率的なアプローチとなっています。
Pose Kernel Distillation
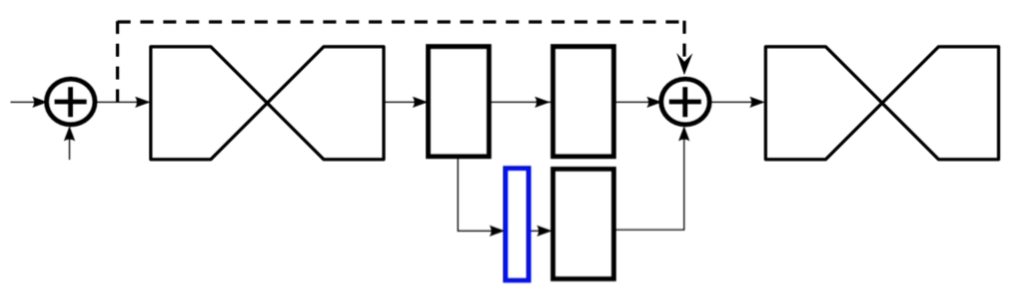
DKDのアーキテクチャは下図のようになっています。まず、動画の第1フレームに対しては比較的規模の大きなモデルである Pose Initializer を用いて各関節点のヒートマップを推定します。Pose Kernel Distillator は各フレームの特徴マップと推定されたヒートマップを入力に Pose Kernel を出力するモジュールです。Pose Kernel は人物の関節点の特徴をエンコードしたテンソルとなっており、第2フレーム以降は前フレームの Pose Kernel を現在フレームの特徴マップに対して畳み込むことによりヒートマップを取得します。Pose Kernel を利用することにより、各フレームの特徴抽出を行う Frame Encoder に小規模なモデルを採用することが可能となります。これらモデルの学習はヒートマップに対するMSEをロスに用いて行い、推論時はヒートマップのピーク位置を各関節点の推定座標とします。
Temporally Adversarial Training
時系列的に一貫した推定を行うことでDKDの性能をより引き上げるための方法として、姿勢推定に Adversarial Learing を適用したChouらの手法 [22] を時系列に発展させた Temporally Adversarial Training を提案しています。Temporally Adversarial Discriminator は連続した2フレームの画像およびそれらに対応した(Ground-truthまたは推定された)ヒートマップを入力とし、ヒートマップの変化を復元します。入力がReal(Ground-truthのヒートマップ)である場合は前後フレームのヒートマップの差分と等しくなるよう復元を行い、入力がFake(推定されたヒートマップ)である場合はヒートマップの差分から乖離した復元を行います。Temporally Adversarial Training を用いる場合、最終的なロス関数はヒートマップに対するMSEロスと Adversarial Loss の和となります。
モデル構造
それぞれのモデルのアーキテクチャは以下のようになっています。
- Pose Initializer:ResNetをバックボーンとし数層のDeconvolution層を加えた Simple Baseline [6] と同一構造のモデルを使用
- Frame Encoder:Pose Initializer と同様のモデルだが、より小規模なバックボーンを使用
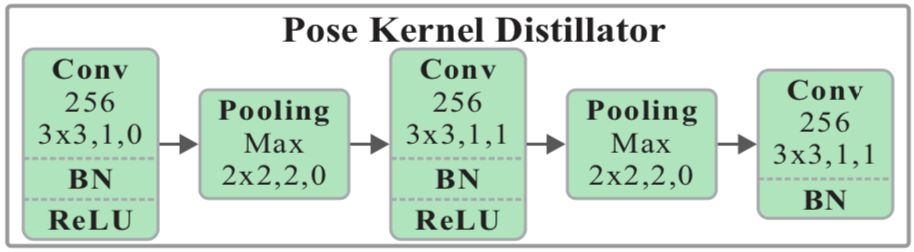
- Pose Kernel Distillator:下図のように3層の畳み込み層およびプーリング層からなる
- Temporally Adversarial Discriminator:Frame Encoder と同一構造のモデルを使用
実験結果
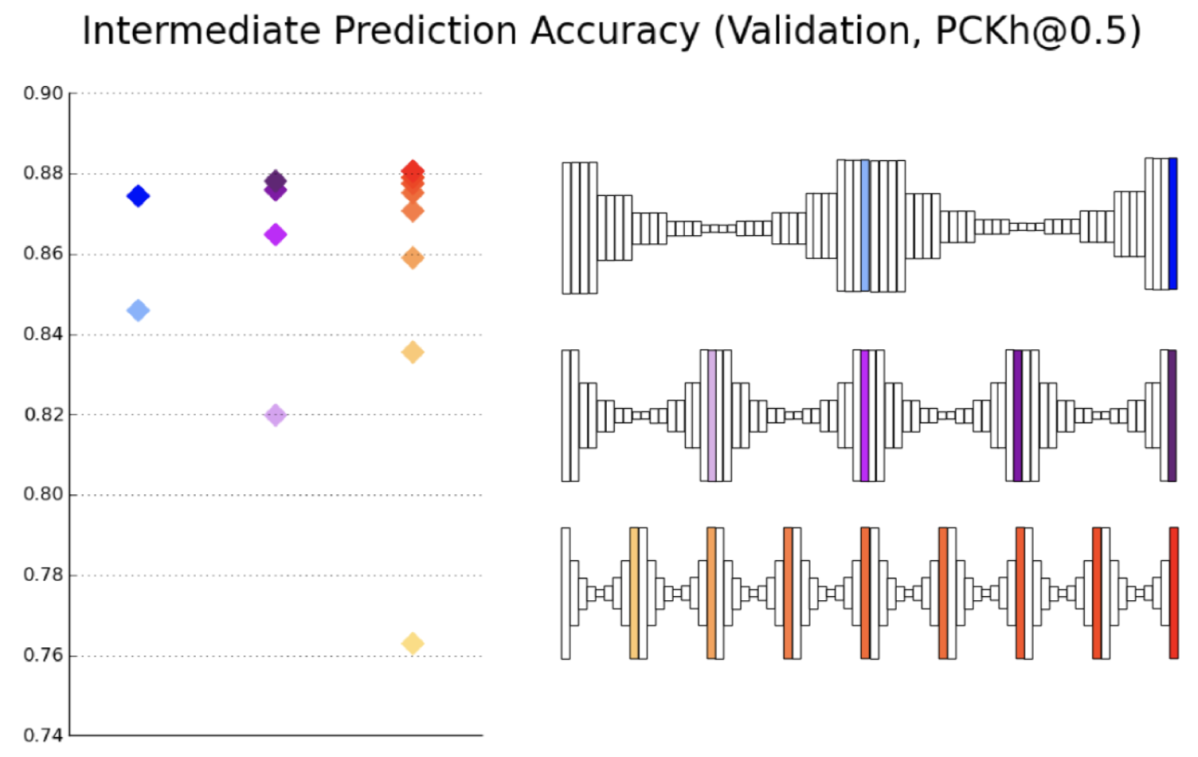
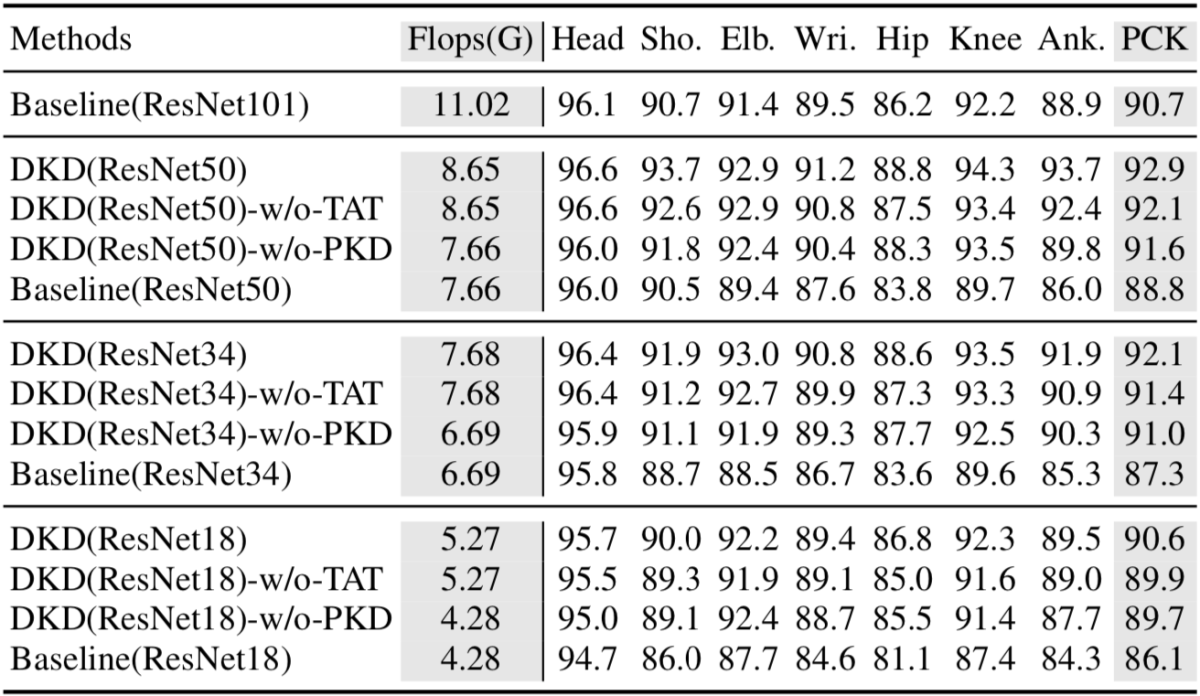
Frame Encoder のバックボーンの層数を変化させながらDKDの各構成要素の有効性を検証する Ablation Study を行なっています。下表においてBaselineは時系列情報を用いないモデル、DKD-w/o-TAT は Temporally Adversarial Training を用いないモデル、DKD-w/o-PKD は Pose Kernel Distillation を用いないモデルです。バックボーンに小規模なモデルを用いた DKD(ResNet50) および DKD(ResNet34) が Baseline(ResNet101) の性能を上回っており、最も小規模なモデルである DKD(ResNet18) は FLOPSを半分以下に削減しつつ、Baseline(ResNet101) と同等程度の性能を達成しており、DKDの有効性が示されています。また、いずれのバックボーンを用いたときにおいても Pose Kernel Distillation と Temporally Adversarial Training はモデルの性能向上に寄与しており、両者を併用した場合は平均5.5%Baselineから評価値が向上してします。
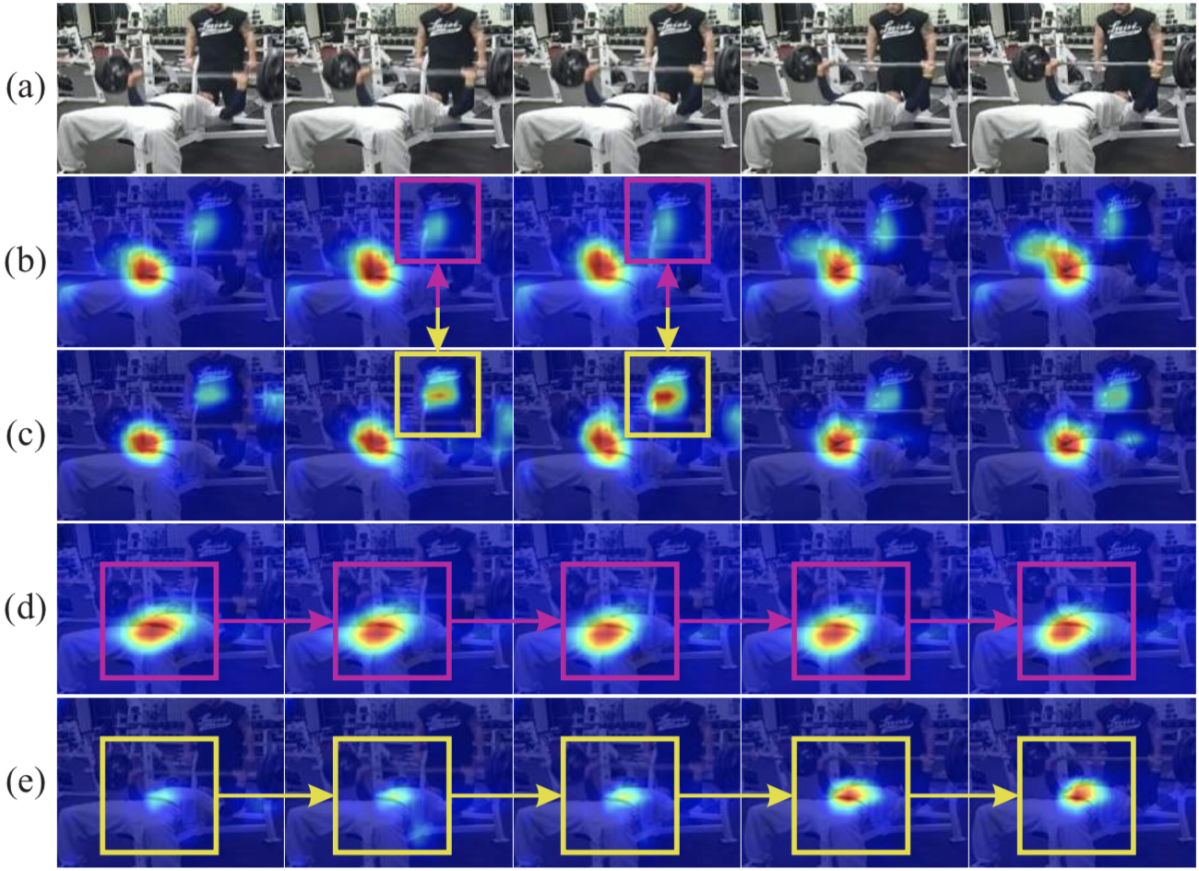
下図は DKD(ResNet34) と Baseline(ResNet34) のヒートマップの定性的な比較結果になっています。(b), (c) を見比べると、DKDは注目人物に対するヒートマップを適切に推定できていることが分かります。また (d), (e) からはDKDが時系列的に一貫したヒートマップを推定できるていることが見て取れます。(ただ、これらモデルは単一人物画像を前提に学習されているため、Baselineの出力が複数の人物に対して出てしまうのは無理もないと思います。個人的にはDKDを複数人物追跡の性能改善に応用できたら面白いと思います。)
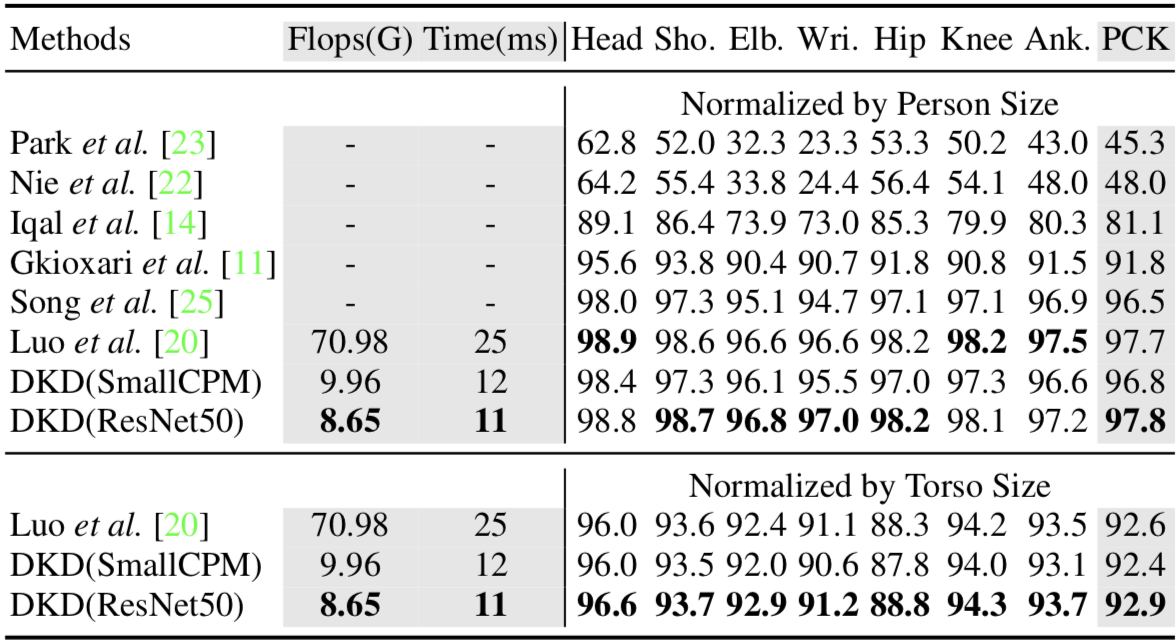
既存手法との性能比較では、Convolutional LSTM を用いた手法(下表中 Luo et al.)や Optical Flow を用いた手法(下表中 Song et al.)と比べ、DKDが精度面、速度面共に優れていることを示しました。
おわりに
今回は 2D Human Pose Estimation に関する代表的な手法および最新論文をご紹介しました。Top-down型の姿勢推定手法では関節点のヒートマップ推定がデファクトスタンダードになっており、モデル構造の改善、とりわけいかに複数スケールの特徴を抽出するかに焦点を当てた研究が数多く存在しました。一方でBottom-up型の手法では関節点のグルーピング方法が肝であり、ベクトル場を用いた手法、埋め込み表現を用いた手法、関節点へのオフセット推定を用いた手法などが存在しました。今後は単に精度を追い求める研究ではなく、 ICCV 2019 に採録された論文にも見られたように、より詳細な人物姿勢の認識や、Single-stageアプローチなどによるモデルの精度と速度のトレードオフ改善などが中心的な研究トピックになっていくのではないかと思われます。Human Pose Estimation における研究トピックとしては 3D Pose Estimation や Shape Reconstruction が主流となりつつありますが、当該分野においても今後さらなるブレイクスルーが起きることに期待したいです。DeNA CVチームでは引き続き調査を継続し、最新のコンピュータビジョン技術を価値あるサービスに繋げていきます。
参考文献
[1] A. Toshev, C. Szegedy, “DeepPose: Human Pose Estimation via Deep Neural Networks,” In CVPR 2014.
[2] J. Tompson, A. Jain, Y. LeCun, C. Bregler, “Joint Training of a Convolutional Network and a Graphical Model for Human Pose Estimation” In NIPS 2014.
[3] Shih-En Wei, Varun Ramakrishna, Takeo Kanade, Yaser Sheikh, “Convolutional Pose Machines,” In CVPR 2016.
[4] A. Newell, K. Yang, J. Deng, “Stacked Hourglass Networks for Human Pose Estimation,” In ECCV 2016.
[5] Y. Chen, Z. Wang, Y. Peng, Z. Zhang, G. Yu, J. Sun, “Cascaded Pyramid Network for Multi-Person Pose Estimation,” In CVPR, 2018.
[6] B. Xiao, H. Wu, Y. Wei, “Simple Baselines for Human Pose Estimation and Tracking,” In ECCV 2018.
[7] K. Sun, B. Xiao, D. Liu, J. Wang, “Deep High-Resolution Representation Learning for Human Pose Estimation,” In CVPR, 2019.
[8] J. Wang, K. Sun, T. Cheng, B. Jiang, C. Deng, Y. Zhao, D. Liu, Y. Mu, M. Tan, X. Wang, W. Liu, B. Xiao, “Deep High-Resolution Representation Learning for Visual Recognition,” In arXiv preprint arXiv:1908.07919, 2019.
[9] K. Zhang, P. He, P. Yao, G. Chen, C. Yang, H. Li, L. Fu, T. Zheng, “DNANet: De-Normalized Attention Based Multi-Resolution Network for Human Pose Estimation,” In arXiv preprint arXiv:1909.05090, 2019.
[10] B. Cheng, B. Xiao, J. Wang, H. Shi, T. S. Huang, L. Zhang, “Bottom-up Higher-Resolution Networks for Multi-Person Pose Estimation,” In arXiv preprint arXiv:1908.10357, 2019.
[11] L Pishchulin, E. Insafutdinov, S. Tang, B. Andres, M. Andriluka, P. Gehler, B. Schiele, “DeepCut: Joint Subset Partition and Labeling for Multi Person Pose Estimation,” In CVPR, 2016.
[12] E. Insafutdinov, L. Pishchulin, B. Andres, M. Andriluka, B. Schiele, “DeeperCut: A Deeper, Stronger, and Faster Multi-Person Pose Estimation Model,” In ECCV, 2016.
[13] Z. Cao, T. Simon, S. Wei, Y. Sheikh, “Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,” In CVPR, 2017.
[14] Z. Cao, G. Hidalgo, T. Simon, S. Wei, Y. Sheikh, “OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields,” In TPAMI, 2019.
[15] A. Newell, Z. Huang, J. Deng, “Associative Embedding: End-to-End Learning for Joint Detection and Grouping,” In NIPS, 2017.
[16] G. Papandreou, T. Zhu, L. Chen, S. Gidaris, J. Tompson, K. Murphy, “PersonLab: Person Pose Estimation and Instance Segmentation with a Bottom-Up, Part-Based, Geometric Embedding Model,” In ECCV 2018.
[17] H. Duan, K. Lin, S. Jin, W. Liu, C. Qian, W. Ouyang, “TRB: A Novel Triplet Representation for Understanding 2D Human Body,” In ICCV, 2019.
[18] G. Hidalgo, Y. Raaj, H. Idrees, D. Xiang, H. Joo, T. Simon, Y. Sheikh, “Single-Network Whole-Body Pose Estimation,” In ICCV, 2019.
[19] X. Nie, J. Zhang, S. Yan, J. Feng, “Single-Stage Multi-Person Pose Machines,” In ICCV, 2019.
[20] X. Zhou, D. Wang, P. Krähenbühl, “Objects as Points,” In arXiv preprint arXiv:1904.07850, 2019.
[21] X. Nie, Y. Li, L. Luo, N. Zhang, J. Feng, “Dynamic Kernel Distillation for Efficient Pose Estimation in Videos,” In ICCV, 2019.
[22] C.-J. Chou, J.-T. Chien, H.-T. Chen, “Self Adversarial Training for Human Pose Estimation,” In CVPR Workshop, 2017.
[23] Y. Raaj, H. Idrees, G. Hidalgo, Y. Sheikh, “Efficient Online Multi-Person 2D Pose Tracking with Recurrent Spatio-Temporal Affinity Fields,” In CVPR, 2019.
[24] I. Habibie, W. Xu, D. Mehta, G. Pons-Moll, C. Theobalt, “In the Wild Human Pose Estimation Using Explicit 2D Features and Intermediate 3D Representations,” In CVPR, 2019.
[25] A. Kanazawa, M. J. Black, D. W. Jacobs, J. Malik, “End-to-end Recovery of Human Shape and Pose,” In CVPR, 2018.
[26] T.-Y. Lin, P. Dollár, R. Girshick, K. He, Bharath Hariharan, Serge Belongie, “Feature Pyramid Networks for Object Detection,” In CVPR, 2017.
[27] Leeds Sports Pose Dataset,
https://sam.johnson.io/research/lsp.html
, 2019.
[28] J. Carreira, P. Agrawal, K. Fragkiadaki, J. Malik, “Human Pose Estimation with Iterative Error Feedback,” In CVPR, 2016.
[29] COCO - Common Objects in Context,
http://cocodataset.org/#keypoints-2019
, 2019.
[30] AI Challenger,
https://challenger.ai/dataset/keypoint
, 2019.




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。