





IT基盤部の nodoka です。
私の業務はWebサービスの運用が中心でしたが、数年前からHadoopを中心とした分散基盤環境のインフラも見るようになりました。 当初は巨大なHadoop環境の管理を体系化して引き継ぐことと、運用における属人性を排除することが喫緊の課題でした。 それが落ち着くと、ご多分に漏れずクラウド化を検討・推進するようになったので、その流れをまとめてみようと思います。
- DeNAのHadoop環境と改善策
- Hadoopが抱える課題
- GCPへの移行
- embulk利用におけるTips
DeNAのHadoop環境と改善策
DeNAにおけるHadoop環境の歴史は古く、DeNAのほとんどのサービスが利用しています。 各サービスでは分析したいログやDBのスナップショットをHadoopのファイルシステムであるHDFSに一旦置きます。 そのHDFSに置かれたファイル群をHadoopを代表とする様々な分析ツールを使って解析します。 時代の流れとともに分析ツールは変化していきますが、データを集積するデータレイクの役割は一貫してHadoopが担ってきました。
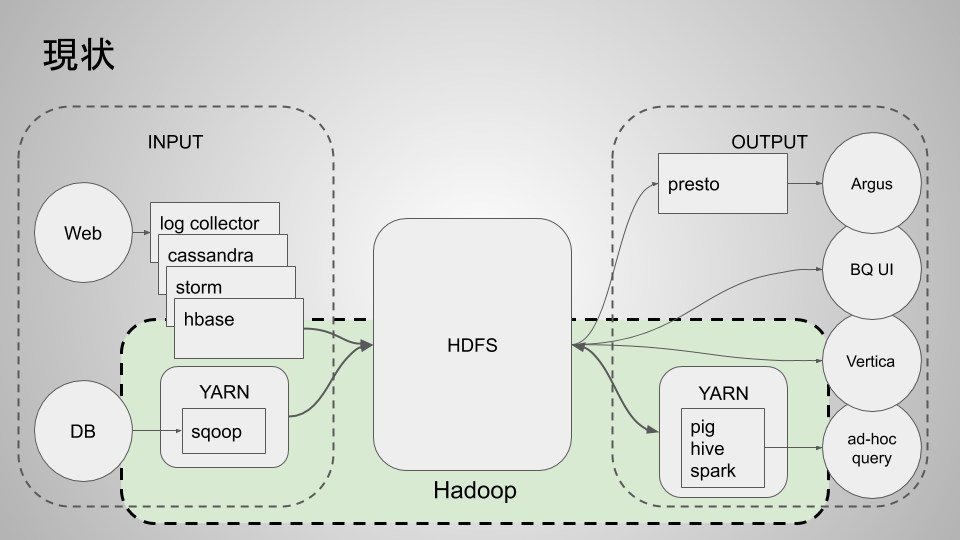
データレイクを構成する数100台のdatanodeサーバたちには、cassandraやelasticsearchなどの様々なコンポーネントが相乗りしていました。 よく言えばリソースをぎりぎりまで使い切る工夫と言えましたが、高負荷なコンポーネントが無関係なコンポーネントの障害を誘発してしまう悪環境でもありました。 また、膨大な数のディスクを抱えているにも関わらず、ディスク障害が即時の手動対応を必要とすることも大きな問題の1つでした。 この現状を踏まえて、以下の改善策を進めていきました。
- ambariによる統合管理の導入
- Hadoopバージョンアップによる不具合の改善
- 相乗りを解消して、コンポーネントごとのサーバ棲み分け
datanodeが大きなディスクI/Oを伴うので、まずはそれと相性の悪いコンポーネントを外出ししました。 それだけでも大部分の不可解な問題は起きなくなり、障害があったとしても速やかに切り分けできるようになりました。 また、バージョンアップによってディスク周りの不具合も減り、ディスク故障についても即時の対応はいらなくなりました。
さらに構造をシンプルにするため、古いデータのパージや圧縮を行って、リソースにばらつきの目立つ古いサーバたちを処分しました。 ambariによって視覚的な構成管理ができるようになったものの、可能な限り構成や設定を単純化してバリエーションを減らしました。 数種類程度のサーバ構成に抑えることで、慣れないエンジニアたちでも罠に陥らずに運用できる体制を築きました。
Hadoopが抱える課題
ようやく落ち着いたところで今後のHadoop運用をどうするか思いを巡らすと、最も大きな課題として浮かび上がったのが、HDFSというファイルシステムの存在でした。
ご存知の通り、Hadoopは分散処理フレームワークの中にHDFSという独自の分散ファイルシステムを内包しています。 このHDFSが良くも悪くもHadoopの特徴となっており、その構造を巨大化・複雑化している一因とも言えます。 分散処理とHDFSが一体化しているが故に、バージョンアップ時にも幾つかの問題を抱えてしまいます。
- バージョンアップ時に長時間ファイルシステムが停止してしまう。
- バージョンアップ時にダウングレードによる切り戻しを行うのが困難。
- ファイルシステムが巨大過ぎるため、バックアップが事実上不可能。
バージョンアップによる効率改善を継続したかったのですが、上記理由でカジュアルにアップグレードという訳にはいきませんでした。 仮にHDFSが長期間使えない障害が起きた場合、その業務影響は計り知れないものになってしまいます。 また、独自性が高く分析処理以外で使うことのないファイルシステムを、積極的に運用したがるエンジニアがいないことも課題でした。
以上の理由で、分散処理としてのHadoopはともかく、HDFSの運用を続けることは難しいという判断を下しました。
GCPへの移行
Hadoopの移行を検討した際に、選択肢に挙がったのはAWSやGCPといったクラウド環境でした。 Hadoopのマネージドサービスを使えば、分散処理とファイルシステムを分離して運用することが可能になるからです。 一方で、並行して分析基盤チームの方でも次期分析ツールの選定を進めており、既に一部で利用していて実績もあるBigQueryへの全面移行が決定しました。
これに伴って、私の方でもBigQueryの利用を前提としたGCPへの移行を検討することにしました。 BigQueryは対象データを自身のストレージに取り込む必要があるのですが、データを展開した状態で保持するので、 圧縮された素のデータファイルよりも格納効率が悪くなってしまう可能性があります。 弊社の実データで比較してみたところ大きな差が出てしまったので、ペタレベルに膨張したデータレイクの移行先としては選択しづらい状況でした。 そこで考えたのがクラウドストレージであるGCSをデータレイクとして併用することです。
直近のデータのみをBigQueryに持って、大部分の古いデータはGCSに置くことにしました。 弊社での利用実績はないものの、BigQueryはGCSのデータも分析対象にすることも出来ることになっています。 何らかの事情でそれが難しい場合は、一時的にHadoopクラスターを組むのもありだと考えました。 BigQuery一本化に比べれば構成的には複雑になってしまいますが、それでも利用頻度やコストを鑑みれば妥当な配置という判断になりました。
データレイクをGCSへ移行する場合、サービス系DBに対して行われていたETL処理も見直す必要がありました。 現在は巨大なHadoopクラスターを利用したSqoopによってDBのスナップショットを毎日取得しています。 しばらくはDBがオンプレに残ることを考えると、クラウドでSqoopを動かすのはリソース及び権限管理、どちらにおいても悩ましい状況でした。 そこで、単体でシンプルに動作し、インプット・アウトプットの選択肢も豊富なembulkへ移行することにしました。
embulk利用におけるTips
embulkでのMySQLからのデータ抽出は、非常に使い勝手がよかったです。 環境さえ整えてしまえば、YAMLファイルを準備するだけで簡単に対象を増やすことが出来ます。 また、抽出処理で問題になりがちなフェッチ数や並列度などもプロパティで制御可能です。 今はデータソースがMySQLだけですが、その気になれば様々なデータに手を広げられるという拡張性も魅力です。
それでも幾つか使い方に悩んだ点はあり、最後におまけとしてそれらを共有させて頂きます。
制御コード問題
まず、初めにつまづいたのは制御コードの問題でした。
旧仕様に合わせてtsvファイルを生成、BigQueryに bq load してみるとエラーで失敗となりました。
該当レコードを確認してみると、エスケープされていない制御コードが含まれていることに気付きました。
tsv以外のフォーマットであればどれもエスケープしてくれたので、利便性を優先してjsonに変更することにしました。
ファイルサイズは圧縮時で1.3倍になってしまったので、ストレージコストが問題になる場合は再検討するつもりです。
文字化け問題
次に問題になったのが、マルチバイトの文字化けでした。
長く続いているサービスはエンコーディングがSJISだったりするので、これにも悩まされました。
文字化けについては、JDBCオプションで characterEncoding を適切に指定すると解消しました。
MySQLのJDBCオプションは結構便利そうなものが少なくないので、一読しておいても損はなさそうです。
具体的には以下のような設定をembulkのliquid.yamlファイルに追加しました。
options: {characterEncoding: Windows-31J}タイムアウト問題
そして、最も苦しんだのがタイムアウト問題でした。
今回のembulk構成は embulk-input-mysql でデータを抽出し、 embulk-output-gcs でデータをアップロードします。
embulk-input-myql は一貫性のある読み出しを行うためにトランザクションを開始してからデータの抽出を行います。
その後に embulk-output-gcs のアップロードが始まるのですが、その完了を待ってからトランザクションを閉じます。
- トランザクション開始
- MySQLからデータ抽出
- GCSへデータアップロード
- コミット
従って、データ量が大きいとアップロード処理に時間を取られてしまい、トランザクションがタイムアウトするという事態に陥ります。
とはいえ、この時点で抽出もアップロードも終わっているので、処理的には何ら問題になりません。
ただ、embulkの終了ステータスが 1 を返してしまうため、エラーハンドリングが難しくなってしまいます。
たかがタイムアウト、何らかのパラメータを変更すればすぐ直ると思っていました。
ところが、MySQLで幾つかのtimeout値を大きくしても一向に改善しません。
途方に暮れて my.cnf を眺めていると、 wait-timeout が100秒に設定されていることを発見しました。
MySQLクライアントで確認したときには8時間になっている認識だったのです。
賢明な諸兄ならお気付きかもしれませんが、インタラクティブなMySQLクライアントの wait-timeout は interactive-timeout で上書きされるんですよね。
つまり、インタラクティブでないembulkのタイムアウトは8時間でなく、100秒で動いていたと考えられます。
MySQLクライアントでtimeout値を確認する場合は、global オプションを付けておくことを強くお勧めします。
show global variables like '%timeout';wait-timeout は意図的に小さくしているようなので、embulkによるDB接続をインタラクティブ扱いすることで回避しようと思います。
今回もJDBCオプションで interactiveClient を設定することで、タイムアウトを interactive-timeout の値に変更することができました。
先ほどの characterEncoding に加えて、以下のような設定をembulkのliquid.yamlファイルに追加しました。
options: {interactiveClient: true, characterEncoding: Windows-31J}以上です。共に日々を戦う皆様の助けになれば幸いです。
備考
記事内に出てくるOSSをまとめておきます。
- MySQL 5.1
- Hadoop HDP 2.6.2
- ambari 2.5.1
- embulk 0.9.16




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。