





はじめに
こんにちは、AIシステム部の高山、橘です。声からオリジナルグラフィックを生成する「fontgraphy(フォントグラフィー)」を9月13日に公開しました。fontgraphyは、デザイン×AIの取り組みであり、一般公開されています。ぜひスマートフォンのブラウザで体験してみてください。
https://fontgraphy.dena.com
本記事ではfontgraphyを構成する技術をご紹介します。

fontgraphyについて
fontgraphyは、声からオリジナルグラフィックを生成します。まず、声を入力すると、その声の印象を推論します。次に、フォントとイメージ画像を検索します。最後に、そのフォントに対してイメージ画像の画風を転写することでグラフィックを生成します。画風の転写にはスタイル変換という技術を用いています。

声の印象推定
印象語の選定
話者の声の特徴を直感的な言葉で制御できる音声合成技術 [1] を参考に、甘い、クール、落ち着いた、生き生きした、エレガント、渋い、ポリシーのある、優しい、の8つの印象語を選びました。
データセットの作成
印象語がつけられた公開されている音声データがないので、自前でデータを用意する必要があります。まず、音声データの収集にあたり、発話内容を検討しました。発話内容が異なっていると印象語を評価することが難しくなる、また予測も困難となることから、固定としました。発話内容は、印象スコアが予測できるほどの長さを確保する必要があります。そこで感情認識のデータセットSAVEE [2] を参考にしました。このデータセットでは長くとも4秒程であったため、同様の長さとなる発話内容(「私のロゴを作ってください。」)に設定しました。そして実際に社員800人の音声を録音しました。音声は個人データにあたるため、音声の利用に関する許諾確認書にサインしてもらう必要がありました。800人の席まで行き、許諾確認書にサインしてもらった上で、音声を録音するという大変な作業をデザイン本部が主導して進めました。
次に、録音した音声に対して、印象語をつけました。音声一つに印象は一つと定まらないことが多いため、各印象語へのスコア付けすることで評価することとしました。下図はスコア評価ツールを示しています。スコアは、0:感じない、1:かすかに感じる、2:少し感じる、3:感じるの4段階としました。主観評価になるため、各音声に対して最低3人で評価し、その平均を取りました。デザイン本部が作成したウェブページを使って評価データを集めました。

印象語推定手法
音声から声の印象語を予測するにあたり、感情認識の手法 [3] を参考にしました。感情認識では音声から特徴量を抽出し、抽出された特徴量を機械学習モデルに入力し、出力結果から感情を認識します。これを踏襲することとしました。まず余分な区間を削除するため、振幅値ベースの音声区間検出を行い、検出された音声区間から特徴量を抽出しました。そして、その特徴量を入力として、スコア付けした印象語を予測するモデルを学習しました。音声の特徴量は、感情認識で多く用いられているOpenSMILE [4] のopenSMILE/openEAR ’emobase’ set [5]の988次元から、下記に示す音響特徴の統計量からなる731次元を選択しました。
用いた音響特徴
- Intensity
- loudness
- 声の高さ
- ゼロクロス率
- 24次のメルケプストラム係数
- 13次のメル周波数ケプストラム係数とその一次微分
用いた統計量
- 最大値
- 最小値
- 平均
- 分散
- 歪度
- kurtosis
- 1次関数近似の傾きと切片
- 3種のinterquartile range
- 3種のpercentile
また音声分析のために、WORLD [6] (D4C edition [7]) 、SPTK [8]を用いました。 抽出された731次元の特徴量から、印象語のスコアを予測する深層学習モデルを印象語それぞれに対して作成しました。深層学習モデルは隠れ層が128次元の4層からなるFeed-forwardモデルを採用しました。検証データにおいて、予測した各印象語のスコアと人手のスコアの相関係数は0.70となりました。また以下に散布図を示します。横軸が予測スコア、縦軸が人手でつけられたスコアの平均です。この結果からよく予測出来ているとと見てとれます。

感情ごとの相関係数は以下のようになりました。ここから、感情ごとに予測精度に違いあることが確認できます。
| 感情 | 相関係数 |
| 可愛い | 0.61 |
| クール | 0.48 |
| 落ち着いた | 0.65 |
| 生き生きした | 0.57 |
| エレガント | 0.72 |
| 渋い | 0.14 |
| ポリシーのある | 0.71 |
| 優しい | 0.43 |
エレガントが高く、渋いが低い結果となりました。特定の印象語によった結果となっており、この要因を探るため、上記の散布図よりエレガント(下図1枚目)と渋いのみ(下図2枚目)を取り出しました。散布図からもエレガントは相関が強く、渋いは相関が弱いことが分かります。


次に人手でつけたスコア自体に偏りがなかったのかを調査しました。印象語ごとに人手でつけられた評価スコアの平均と分散を示します。この結果から印象語によったばらつきには、上記相関係数と同様の傾向は見られませんでした。印象語による予測精度の違いについては、今後調査が必要です。
| 感情 | 平均 | 標準偏差 |
| 可愛い | 1.85 | 0.25 |
| クール | 1.58 | 0.39 |
| 落ち着いた | 1.92 | 0.37 |
| 生き生きした | 2.33 | 0.33 |
| エレガント | 1.19 | 0.48 |
| 渋い | 1.88 | 0.26 |
| ポリシーのある | 1.39 | 0.59 |
| 優しい | 1.65 | 0.20 |
フォントとイメージ画像の検索
データセットの作成
声の印象に近いフォントとイメージ画像を検索するには、フォントとイメージ画像にも8つの印象のスコアが必要になります。フォントは、Monotype株式会社(米国Monotype Imaging Inc.の日本法人)から提供されたものを利用しました。大量のフォントへのスコアづけは大変な作業となるため、各フォントについた31個のタグとその評価値を、印象語のスコアに変換することにしました。具体的には、word2vecを使ってフォントのタグと音声の印象語をベクトルとして表現し、コサイン類似度を計算します。1つの印象語に対して31個のタグとの類似度が得られるので、評価値での重み付き和をその印象語のスコアとして算出しました。イメージ画像の印象のスコアは、音声データと同様に、デザイン本部のメンバーが4段階評価でスコアをつけました。
印象の距離の計算
音声の印象、フォント、イメージ画像をそれぞれ8次元のベクトルで表現することができるようになったので、実際に音声の印象に近いものを検索します。fontgraphyではユークリッド距離の最も近いフォントとイメージ画像を検索しています。
スタイル変換
コンテンツ画像にスタイル画像の画風を反映させることをスタイル変換と言います。スタイル変換は、物体の形状はコンテンツ画像に近くなるように、色や風合いといった画風はスタイル画像に近くなるように変換します。リアルタイムで様々なスタイルに変換できるよう研究が進められています。いくつかのスタイル変換の手法を試した結果、fontgraphyに最も適したUniversal Style Transfer via Feature Transforms [9] を採用しました。スタイル変換の技術詳細に興味がある方は 「2018年版 深層学習によるスタイル変換まとめ」 をご覧ください。
Universal Style Transfer via Feature Transforms
論文:https://arxiv.org/abs/1705.08086
Universal Style Transferの説明に入る前にオートエンコーダについて説明します。オートエンコーダは、入力画像を復元するニューラルネットワークです。入力画像を表現する特徴を抽出するエンコーダと、抽出した特徴から入力画像を復元するデコーダから構成されます。

Universal Style Transferは、エンコーダとデコーダの間にWCTレイヤーを入れてスタイルを変換します。WCTレイヤーではwhiteningとcoloringという処理をかけます。2つの処理は物体の形状の特徴を変えることなく、色や風合いといったスタイルの特徴を変換します。具体的には以下のステップを踏みます。
- コンテンツ画像とスタイル画像をそれぞれエンコード
- コンテンツ画像の中間特徴を白色化:whitening
- スタイル画像の中間特徴の固有値固有ベクトルを使って白色化した特徴を変換:coloring
- 変換した特徴をデコード
- 1-4の処理を繰り返し

whitening
コンテンツ画像の中間特徴を白色化します。白色化により物体の構造情報を保ったまま画風の情報を削ぎ落とすことができます。以下の画像は白色化した特徴をデコードした結果です。

対角成分に固有値を並べた行列Dc、固有ベクトルを並べた行列Ec、平均ベクトルmcを使って、エンコードした特徴fcを白色化します。
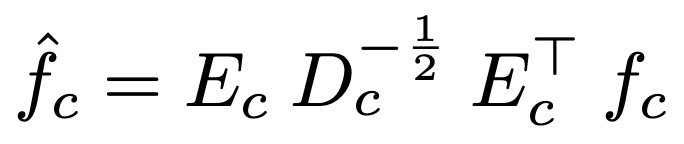
coloring
白色化した特徴をスタイル画像のパラメータで変換します。この変換は、画風の情報を削ぎ落とす白色化と逆の変換になります。対角成分に固有値を並べた行列Ds、固有ベクトルを並べた行列Esを使って、白色化した特徴を変換します。
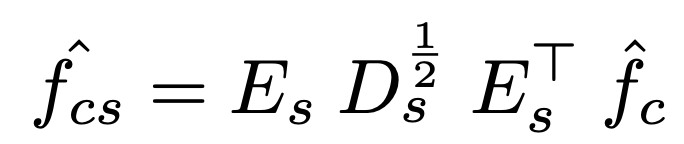
coloringした特徴とコンテンツ画像の中間特徴を混ぜ合わせてからデコードすることで、画風の度合いをコントロールすることができます。
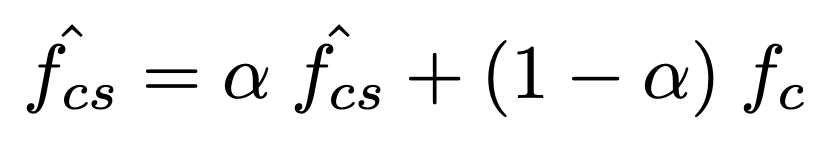
下図のように、alphaが大きいほどスタイル画像の画風が強く反映されます。

生成結果
fontgraphyは、以下のようなグラフィックを生成します。フォントは919種類、イメージ画像は400枚使っています。画風の度合いをコントロールするalphaを0から0.6まで0.1ずつ変化させて7パターンの変換をしています。以下の図はalphaを0.6とした結果です。

おわりに
本記事では声からオリジナルグラフィックを生成するfontgraphyの要素技術についてご紹介しました。DeNAは引き続き技術を蓄積し、デザイン×AIの取り組みに挑戦していきます。
参考文献
[1] Surrey audio-visual expressed emotion (savee) database
[2] 話者の声の特徴を直感的な言葉で制御できる音声合成技術
[3] The INTERSPEECH 2009 Emotion Challenge
[4] openSMILE ‒ The Munich Versatile and Fast OpenSource Audio Feature Extractor
[5] OpenSMILE
[6] WORLD: a vocoder-based high-quality speech synthesis system for real-time applications
[7] D4C, a band-aperiodicity estimator for high-quality speech synthesis




{kind=link}
{kind=link}
{kind=link}
最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。