





はじめに
こんにちは。山本です。 現在、IT基盤部第二グループのマネージャをやらせていただいております。
私のグループではいくつかの領域を扱っていますが、その中で大きな比率を占めるのがオンプレミスのLinuxサーバの管理となります。 業界のトレンドとしてはパブリッククラウド側の基盤が騒がれていますが、まだまだオンプレLinuxも現役であるのは事実。それらのサーバに関して、いかにしてDeNAで管理・運用を実施しているのかという一部を 具体的に かつ 実際に起きている日常の実例を元に お見せしたいと思います。
そもそも管理とはなんなのか?
そもそも、我々が実施している仕事というのがなんなのか、ということですが、大きく分けて以下のものに分類されると考えています。
- 構築・構成管理
新規のサーバ構築
- あるべき構成とのずれの検出・修正
- サービス(事業)側への対応
- 新規のサーバ準備
- その他諸々小さな依頼事項への対応
- 負荷・アラート管理
- サーバの状態レポートの作成
- 異常が発生した場合のその原因検知
この中で「構築・構成管理」は各所でツールなどを利用して実施されていると考えますし、「サービス(事業)側への対応」は依頼内容によって異なることもあると思います。 今回は、「負荷・アラート管理」について、特定の例を挙げた上で我々DeNAインフラエンジニアがどのように判断してどのように対応しているか、といったものを示したいと思います。一部改変していますが、おおむね事実に沿っている例です。
ケーススタディ【メモリに異常あり】
以下のようなメールを受け取りました。これは我々の監視兼ツールの一種であり、空きメモリが一定値を下回った時に自動的に特定の種類のプロセスのうち、メモリを最も大量に確保しているものをkillしてしまうというものです。
[2019/06/15 00:03:13]
KILLED PROCESSES
============================================================================
= 2019-06-15T00:02:25 =
== SYSTEM ==
TOTAL FREE BUFFERS CACHED REALFREE REALFREE%
23989.36 268.39 590.23 285.82 1144.44 4.77%
== KILLED PROCESSES (fat) ==
STATUS USER PPID PID CHILD RSS PRIV SHAR SHAR% START CMD
KILLED xxxx 42482 45594 0 2229.8 255.9 1973.9 88.5% 2019-06-14T23:58:10 index.fcgi上の場合は、メモリの空きが4.77%となっていたので、PID 45594のindex.fcgiというプロセスをkillしたということを示しています。
初動対応
インフラエンジニアは科学者である前に、サービス運用に責任を持つ人物です。
したがって、「この原因はXXXだね」という評論の前に、降りかかる火の粉を払う必要があるのです。どんな時でも次の順序で進んでいきます。
- 状況の確認(特にサービス影響の確認)
- 影響が出ているならば、周囲にシェアした上で緊急処置
- 影響が出ていない(or おさまっている)ならば、調査フェーズに
メモリの場合は緊急処置として以下のようなものが考えられるでしょう。
- 案1:workerがあまっているならばworkerを減らす
- 案2:緊急サーバ増設
- 案3:アプリケーション側での緊急処置
今回のケースでは何度かアラートが飛んできましたが、簡単にできる対応として、まずはworkerを5ほど減らしてもらいました。
一旦おさまった後の調査と恒久対策
一旦おさまったのちには我々のグループでは次の調査を実施します。
- CloudForecastによる短期的・長期的なメモリ推移確認
- ログからリクエスト数推移確認
- サーバ毎に1秒単位で取得しているログの確認(メモリ・CPUなど)
ただ漫然と眺めていてもあまり意味がありませんので、どのような観点で眺めているのかということと判断の基本的な流れを記述します。
- メモリ問題は、リクエスト数増加に伴う自然なものか否か?
- 特定のサーバで起きているのか、満遍なく起きているのか?
- 特定のタイミングで急激にメモリが上昇しているのか、満遍なく上昇しているのか?
これは、我々のグループにおいては「テストに出ます」というレベルで必要な観点です。
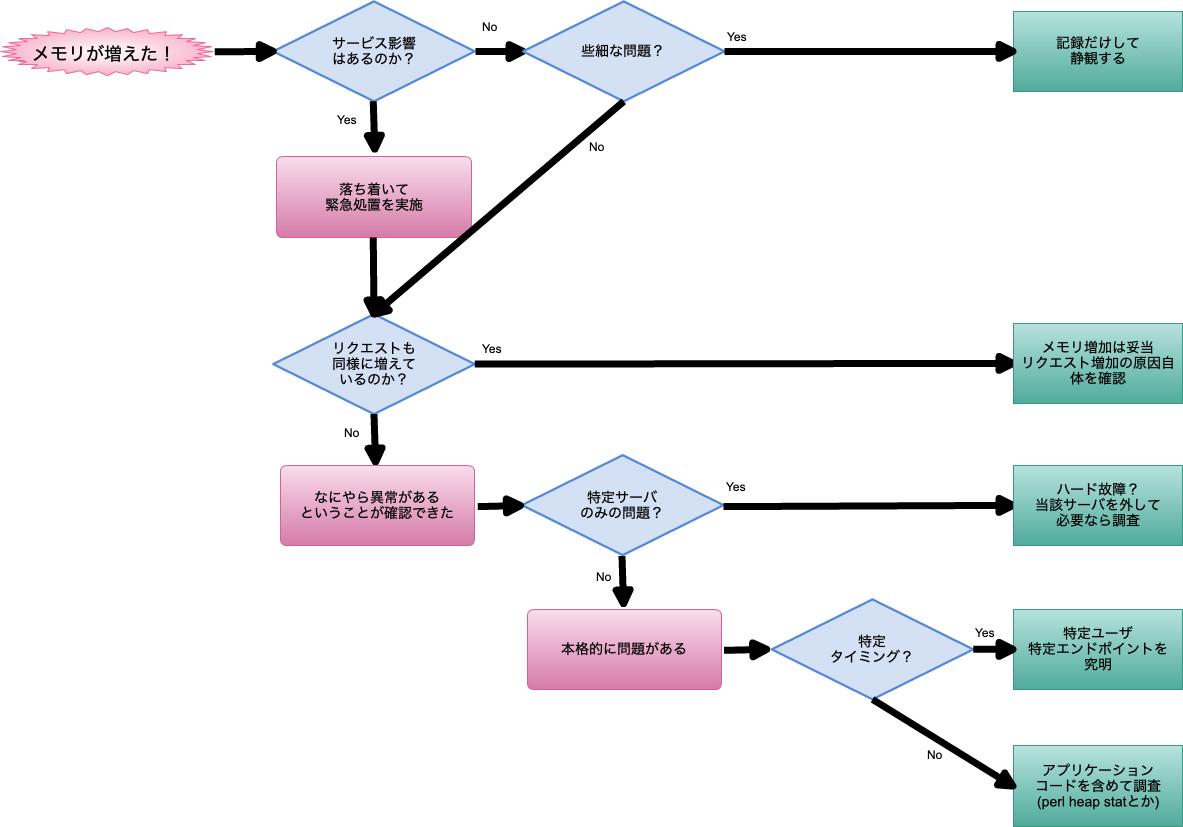
考えてみれば当然の流れだとは思います。アプリケーションコードやプロファイルを即座に眺めて詳細に調査する必要はありません。
今回のケースでは、残念ながら、特定時刻以降でどのサーバでも満遍なくメモリが増えているという状況でしたが、どちらかというとタイミングによってたまにガクッとメモリを確保していることがあるようでした。 これは、何らかのコードを通った時に問題が発生する可能性を示唆します
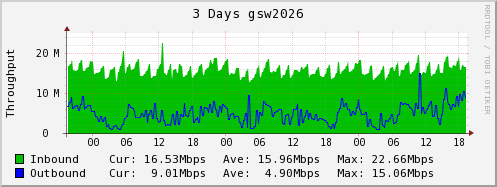
trafficはもちろん上下はあるものの、特段メモリの事象が起きた際に増えているわけではありません。
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free buff cache si so bi bo in cs us sy id wa st
20190614 00:01:40 7 0 0 1595940 678600 428780 0 0 56 228 21715 9998 13 2 84 0 0
20190614 00:01:41 5 0 0 1418176 678600 428816 0 0 4 176 17218 7143 11 2 87 0 0
20190614 00:01:42 5 0 0 1426624 678648 428880 0 0 68 184 18987 7940 13 2 85 0 0
20190614 00:01:43 10 0 0 1207144 678648 429004 0 0 96 860 19715 8138 11 3 86 0 0
20190614 00:01:44 4 0 0 1353092 678648 428940 0 0 100 164 19512 8349 14 2 84 0 0
20190614 00:01:45 9 0 0 999816 678648 428980 0 0 4 212 22501 9151 17 3 80 0 0
20190614 00:01:46 10 0 0 633396 678648 429036 0 0 4 196 24249 9229 18 3 79 0 0
20190614 00:01:47 7 0 0 668244 678648 429056 0 0 0 148 24446 7356 26 3 71 0 0
20190614 00:01:48 10 0 0 375356 678732 428764 0 0 144 1360 22122 11070 15 5 80 0 0
20190614 00:01:49 8 0 0 453368 678736 428900 0 0 44 164 22485 8921 23 1 76 0 0
20190614 00:01:50 8 0 0 475648 629532 417120 0 0 8 200 33972 9238 21 2 77 0 0
20190614 00:01:51 12 0 0 414768 629532 417184 0 0 0 144 27192 11090 15 6 79 0 0
20190614 00:01:52 4 0 0 545636 629616 417188 0 0 92 196 22731 9139 15 4 81 0 0
20190614 00:01:53 8 0 0 171572 629620 417216 0 0 4 720 18312 7093 11 2 86 0 0
20190614 00:01:54 7 0 0 411384 508808 384700 0 0 268 220 25455 7998 15 5 80 0 0
20190614 00:01:55 7 0 0 358036 473876 292412 0 0 596 144 28311 6510 15 6 80 0 0
20190614 00:01:56 6 0 0 489696 473876 292988 0 0 448 164 22794 7818 10 5 85 0 0
20190614 00:01:57 4 0 0 377520 473876 293024 0 0 12 140 22169 8901 15 2 82 0 0
20190614 00:01:58 5 0 0 365716 473916 292848 0 0 92 1352 19942 12584 12 1 87 0 0
20190614 00:01:59 11 0 0 144052 402256 200484 0 0 60 192 20951 6587 12 4 84 0 0
20190614 00:02:00 4 0 0 810580 306132 173364 0 0 256 168 22044 5282 15 3 82 0 0
20190614 00:02:01 9 0 0 685372 306148 173112 0 0 108 228 23284 9098 16 4 80 0 0
20190614 00:02:02 8 0 0 773072 306492 173572 0 0 1360 160 24735 7460 13 7 79 1 0
20190614 00:02:03 7 0 0 689528 306500 175876 0 0 1752 872 24791 8648 11 4 83 2 0メモリは、一気に確保したり解放したりといった瞬間があるようです。例えば00:01:42から一気に空きメモリ(free)が減少しています。
アプリケーションコード
ここまでくると、仕方ないので真面目にアプリケーション側のコードの解析を実施します。 これも、漫然と眺めていても仕方ありませんので、DeNAで利用されているperl heap statを利用してみました。
- perl heap statでの確認
- (場合によっては)nytprofの確認
perl heap stat(phs)ではコードとその行番号を含めて示してくれます。 DeNAインフラの今の話 第2回「性能劣化、障害発生時のプロファイリングツールの紹介」 にはphsの実行例が出ていますが、問題箇所を的確に指し示してくれることがあります。
今回の場合には、特定のアプリケーションの特定のサブルーチンが示されていました。
sub addData {
my ($id) = @_;
(省略)
my $dbh = DA::getHandle($handle);
my $ret;
if (exists($CACHE->{'master'})) {
$ret = $CACHE->{'master'};
} else {
eval {
$ret = SQLを利用し、DBからデータを取得してくるコード
$CACHE->{'master'} = $ret;
};
}
(省略)
}
このPerlコードは、 $CACHE->{master}(グローバルなスコープを持つ変数であり、消えない) が存在すればそれを利用し、存在しなければ、実際にDBからデータを取得してきた上で、 $CACHE->{master}にセットするというものです。
特段問題はないように思えますが、ここのmasterにどの程度のレコードが含まれているかということが重要となります。
SQLで取得してきているテーブルを実際に検索し、そのデータ数を確認すると、これがそれなりに多いということがわかりました。その大量のデータを$CACHE->{master}に保持することによって問題が起きうる、ということが仮説として浮かびます。
といって、どうすれば良いのかということになります。$CACHE->{master}にセットせず、毎回SQLを発行してDBから取得するという方法があります。間違いではありませんが、クエリの増加、速度の下降といった問題があります。
我々がこの例で利用している仕組みでは、Perlはhttpdと別プロセスで動作しており、親となるPerlプロセスが各モジュールを読み込んで初期化しておいたのちに、そのプロセスがforkして、多数のworkerプロセスとなります。
したがって、親プロセスとなるべきプロセスで、 $CACHE->{'master'}をセットしておけば、そのメモリはforkされた子プロセスでもそのまま利用可能であり、なおかつCopy-On-Writeの仕組みによって、実際のメモリコピーはなされず、親プロセスで利用していたメモリを利用してくれます。
ですので、コードを次のように書き換えてもらうこととなりました。
## 高負荷のため、preload化
sub initializeMaster {
my $dbh = DA::getHandle($handle);
my $ret = SQLを利用し、DBからデータを取得してくるコード
if($ret) {
$CACHE->{'master'} = $ret;
}
(省略)
}
initializeMaster();
## こちらは変更しない
sub addData {
my ($id) = @_;
(省略)
my $dbh = DA::getHandle($handle);
my $ret;
if (exists($CACHE->{'master'})) {
$ret = $CACHE->{'master'};
} else {
eval {
$ret = SQLを利用し、DBからデータを取得してくるコード
$CACHE->{'master'} = $ret;
};
}
(省略)
}
つまり、今までの処理は変更せず、単純に $CACHE->{master} をモジュールロード時に実行される initializeMaster() でセットしたということになります。
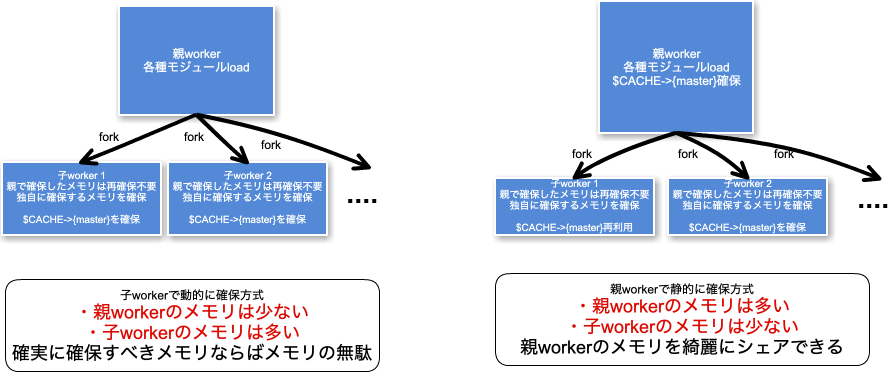
preloadに関連する基本的な知識ではありますが、こういったものを調査して、実際にアプリケーション開発側にお伝えして具体的な再発防止策として実施する、というところまで行けるのがベストです。(その後、再発していないことを確認することももちろん重要です。)
このような問題は、開発環境などでは確認しにくく、また、DBのレコード数が徐々に増加してくることによって顕在化してくるとか、該当のコードを通りやすいようなページ構成になるとかいった要因によって発生するものであり、開発中に気づくのは非常に難しいと言わざるを得ません。したがって我々インフラエンジニアが気づいて、本格的な問題が起きる前に修正してもらうのがベストだと考えています。
なお、実際の運用において、素直に全てのメンバーが一本道でゴールにたどり着くというわけではありませんし、「この問題は調査打ち切りとする」というような場面もあります。
他のケースの場合
今回のケースは実際に日常的に起きている例の一つであり、最終的にアプリケーション開発者に連絡して再発防止策実施にまで至った例ですが、この一つを取ってもインフラエンジニアとして ロジカルに判断 しつつ、 背景として技術的知識を利用 する必要があります。 単純に「よくわからないけれどサーバ増設だ!」「手当たり次第に調べてみるぜ!」といったものではなく、都度状況を判断しつつ必要なものを調査し、ゴールに向かっていくという流れとしたいところです。
また、例としてメモリアラートを出したのは、最近私の管轄内で頻発しているからですが、上に書いた進み方の全体方針の考えは他のアラートでも同様です。 「よくわからないけれどネットワークが切断される」「よくわからないけれど、レスポンスが遅い」といった問題に対して切り込むメソッドを磨くことで、インフラ技術者としての練度を上げるべく努力したいと思います。
今回の話の背景知識
webのバックエンドでworkerを走らせる場合のメモリとworker数の関係
上で、workerを減らすという話があります。 workerがあまっているならばこれはメモリ確保のための非常にお手軽な解決策となります。とはいえ、例えばworker数を2/3にすればメモリの使用量が2/3になるというような簡単なものではありません。
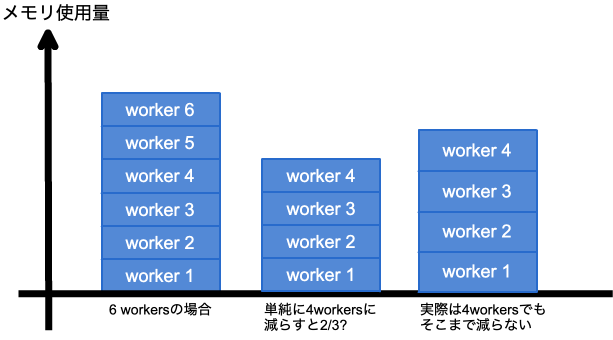
実際には上の図のように、worker数を減らしても、一般に1workerあたりのメモリ使用量は増加するので、そこまでの効果はありません。 これは、いままで6個のworkerで受けていたリクエストが4個のworkerになったので、1 workerあたりのリクエスト処理量が1.5倍に増えるためです。
あとはアプリケーションプログラムの書き方によるのですが、例えば、リクエストを受けるたびに、プロセスメモリ上にキャッシュとして確保などしているとすれば、プロセスが受けるリクエスト数が増えれば、それだけプロセスのメモリ確保は多くなるのです。当たり前ですね。
といって、効果がないわけではありませんし、お手軽に実施可能ですので、まずはじめに検討してみても良いと思います。
workerがあまっているならば…?
お気軽に「workerがあまっているならば」などと書いてしまいましたが、あまっているかどうか、どうやって知ることができるのかという話があります。
DeNAのperl環境においてはperlstackという仕組みがあるので、実際に遊んでいるworker数を正確に算出していますが、どこでもその方法が使えるわけでもありません。 しかし、それがなくとも簡単に概算できます。
- 単位時間あたりのリクエスト数
- 平均レスポンスタイム
この二つがわかれば十分です。単位時間(例えば1分)にリクエストが1000きているとして、平均0.3秒でレスポンスを返しているとしましょう。 すると、1分あたりで、実際に処理が動いているのは「のべ」300秒ということになります。1分(60秒)の間に300秒分の処理をするためには1workerでは足りず、5workersは最低でも必要となります。実際には、リクエストのバラツキもありますから、workerの「待ち時間」というものが発生します。 その分を考えて、余裕を持ったworker数を準備する必要があります。

しかし、例えば「1分に100リクエスト、平均レスポンスタイム0.5秒」という状況で20 workersが用意されているとすれば、それはあまっていると判断して差し支えないでしょう。 もちろん、ピーク時を考慮してリクエスト数は検討する必要がありますが、明らかに過剰と判断すれば、無駄なメモリの肥やしを作る意味はありません。
Perlとメモリ
Perlはメモリの管理が必ずしも先進的ではなく「本物の」Garbage Collector(GC)を持っておりません。 実際に我々の管理しているサーバにおいても、ほっておくとメモリがどんどん溜まってきてしまう例があります。本来的にはメモリに対する全ての参照を破壊すれば、その変数の参照カウントがゼロになるはずですが、おそらくそうなっていない何かが存在することでメモリがどんどん増加するのです。
通常のGCでは、根元から辿って行ってたどり着けるメモリにマークしていって、マークされなかった変数に対して回収をかけます。しかし、Perlの場合には参照の有無をみるだけなので、根元から辿り着けなくとも互いにリファレンスで参照しあっているような変数があれば、最後まで回収されません。一番シンプルな例としては、my $var = \$var; って書いておくと、myのスコープとか関係なくメモリ回収されないということです。
これをどうすべきか、という話では、「もっと近代的な言語に切り替える」「真面目にメモリリーク検出ツールを用いる」といったものもあると思います。しかし、我々の利用しているXSなどを含めたコード全体を見直す手間などを考慮すれば「定期的にプロセスを入れ替える」という現実的な選択肢に落ち着いてしまいました。




最後まで読んでいただき、ありがとうございます!
この記事をシェアしていただける方はこちらからお願いします。